前言:继顺序表后的又一个线性结构——链表,这里将单向链表的实现。
目录
链表简介:
多文件实现:
SList.h:
SList.c实现函数的详解:
因为插入数据需要创建节点,很频繁,所以直接将创建新节点分装成一个函数:
尾插:
头插:
将链表中的数据打印:
头删:
尾删:
查找:
插入:
1.在指定位置之前插入节点:
2.在指定位置之后插入节点:
删除指定位置的节点:
删除指定位置之后的节点:
销毁链表:
全部源码:
结语:
链表简介:
图解:

上图是链表的逻辑结构,逻辑上是线性的,而在内存中不是连续的,因为链表的节点都是由malloc函数开辟的,所以在内存中不连续;链表是由一个一个的节点构成,节点就是上图中的一个一个的长方形。
节点的结构:
typedef int SLTDataType;
struct SListNode
{struct SListNode* next;//存放下一个节点的地址SLTDataType data;//存放该节点的数据
}链表与顺序表对比
顺序表在逻辑上和物理上都是线性的,
而链表只在逻辑上是线性的。
顺序表的缺点:
1:顺序表需要增容,增容时,使用的是realloc函数,在原来的空间后没有足够的空间就需要去内存的其他区域去开辟空间,这时需要将原来的数据拷贝进新的空间,效率低:
2:将顺序表中的数据删除,不会释放空间,浪费空间:举个例子,你以前的顺序表中存储了1000个数据,你现在将数据都删除了,那么那块空间现在没有数据并且还没释放,造成了空间浪费。
链表优点:
每想存储一个数据时就需要用malloc开辟一个空间,若删除数据可以直接把存放数据的空间释放。
多文件实现:
| 文件名称 | 负责的功能 |
| SList.h | 链表的定义,需要用到库里的头文件的包含,链表需要实现函数的声明。 |
| SList.c | 链表函数的实现 |
| test.c | 测试接口(这里大家可以自己测,自己写) |
SList.h:
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>typedef int SLTDataType;typedef struct SListNode
{struct SListNode* next;SLTDataType data;
}SLTNode;//头插
void SLTPushFront(SLTNode** pphead, SLTDataType x);
//尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x);
//打印链表中的数据
void SLTPrint(SLTNode* pphead);
//尾删
void SLTPopBack(SLTNode** pphead);
//头删
void SLTPopFront(SLTNode** pphead);
//查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x);
//在指定位置前插入数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);
//在指定位置后插入数据
void SLTInsertAfter(SLTNode* pos, SLTDataType x);
//删除指定位置的数据
void SLTErase(SLTNode** pphead, SLTNode* pos);
//删除指定位置之后的数据
void SLTEraseAfter(SLTNode* pos);
//销毁链表
void SLTDestroy(SLTNode** pphead);SList.c实现函数的详解:
因为插入数据需要创建节点,很频繁,所以直接将创建新节点分装成一个函数:
SLTNode* SLTBuyNode(SLTDataType x)
{SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));if (newnode == NULL){perror("malloc");exit(1);}newnode->data = x;newnode->next = NULL;//使新节点指向的下一个节点为NULLreturn newnode;
}x: 想创建的节点中存储的数据
尾插:
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{assert(pphead);SLTNode* pcur = *pphead;SLTNode* newnode = SLTBuyNode(x);//创建一个新节点//链表为空if (*pphead == NULL){*pphead = newnode;}//链表不为空else{//pcur->nextd等于NULL时跳出循环while (pcur->next){pcur = pcur->next;}//此时pcur指向最后一个节点pcur->next = newnode;}
}为什么要传二级指针呢?
如果尾插时,为空链表,那么尾插时会改变头结点的值,而想在头插函数中改变头结点的值,那么就需要传头结点的地址,头结点是一级指针,一级指针的地址需要二级指针接收,所以参数是二级指针,这一点很重要,以后的函数也有需要传二级指针的。
所以在插入数据时有两种情况:
1,链表为空
2,链表不为空,因为是尾插,所以需要找到最后一个节点,并在其后面插入一个新节点。
头插:
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{assert(pphead);SLTNode* newnode = SLTBuyNode(x);if (*pphead == NULL){*pphead = newnode;}else{newnode->next = *pphead;*pphead = newnode;}
}老问题为什么传二级指针?
因为是头插,所以头结点会指向新创建的节点,需要改变头结点的值,若传一级指针,只是头结点的临时拷贝,改变函数中的参数的值不会改变,头结点的值,所以需要传二级指针。
考虑是否为空链表:
1:空链表,只需要在头结点后插入一个新节点
2:不为空链表:不仅需要在头结点后插入一个新节点,还需要让新节点的next指向原来的链表的第一个节点。
图解:
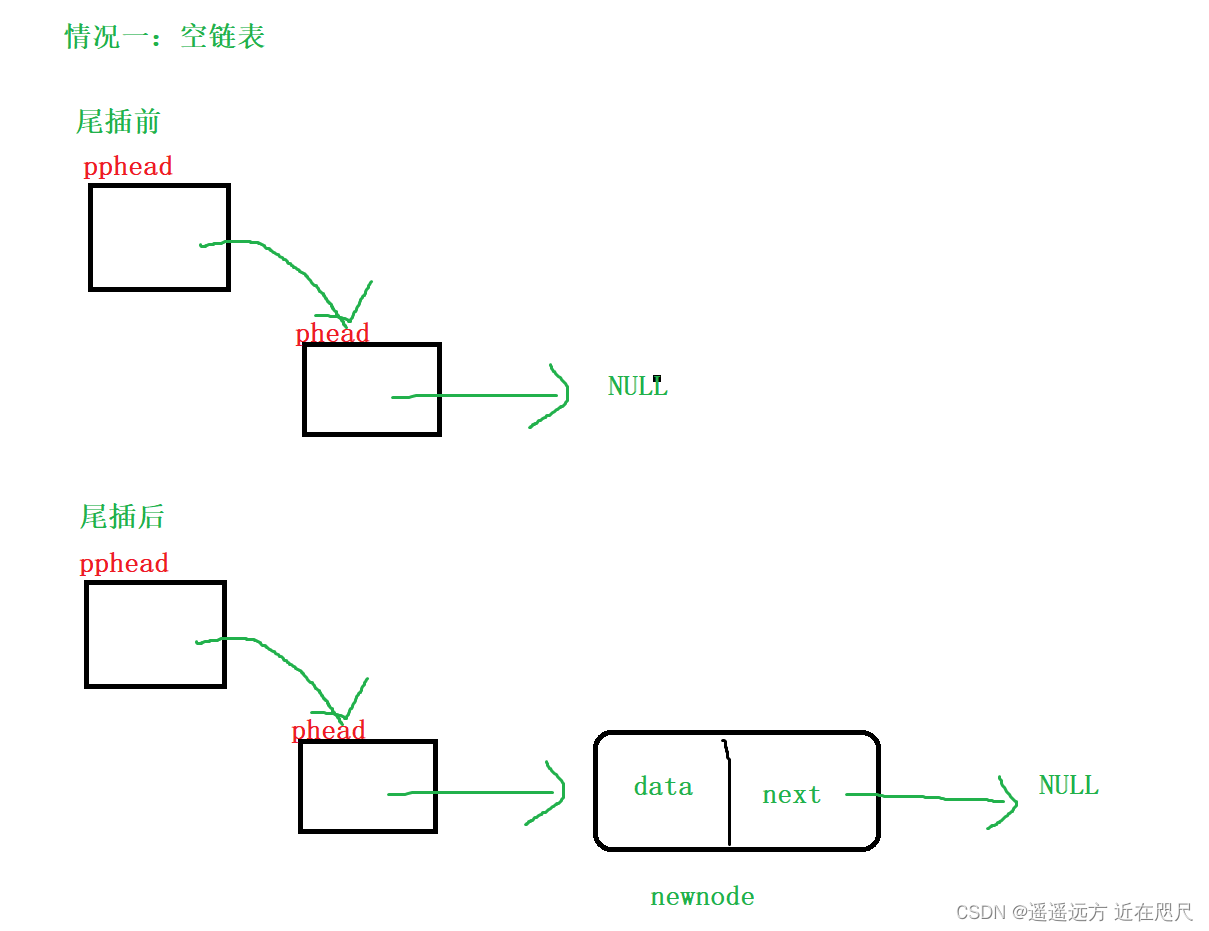

将链表中的数据打印:
void SLTPrint(SLTNode* phead)
{SLTNode* pcur = phead;//直到pcur指向NULL为止while (pcur){printf("%d->", pcur->data);pcur = pcur->next;}printf("NULL\n");
}打印效果:
这里有一段代码:
int main()
{SLTNode* list = NULL;SLTPushBack(&list, 1); SLTPushBack(&list, 2);SLTPushBack(&list, 3);SLTPrint(list);return 0;
}
头删:
void SLTPopFront(SLTNode** pphead)
{assert(pphead && *pphead);//防止是无效链表和空链表SLTNode* tmp = (*pphead)->next;free(*pphead);*pphead = tmp;
}assert(pphead&&*pphead)就相当于assert(pphead!=NULL&&*pphead!=NULL)
pphead!=NULL防止其指向无效链表
*pphead!=NULL防止空链表
这个在之后的函数实现也会有。
为什么传二级指针?
因为是头删需要改变头结点的值,让他指向原来链表的头结点的下一个节点。
尾删:
void SLTPopBack(SLTNode** pphead)
{assert(pphead && *pphead);SLTNode* pcur = *pphead;SLTNode* prev = *pphead;if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;}else{while (pcur->next){prev = pcur;pcur = pcur->next;}free(pcur);prev->next = NULL;}
}为什么要传二级指针?
当链表中有一个数据时,删除这个数据,链表就为空链表了,所以头结点指向空,改变了头结点的值。
为什么要定义prev和pcur指针呢?
在删除最后一个节点后,需要将最后一个节点的前一个节点的next置为NULL,使其成为新的尾结点。
因为链表是单向的所以不能通过最后一个节点找到前一个节点,所以需要引入prev指针,prev指针指向pcur指向的节点的前一个节点,所以当pcur指针指向最后一个节点时,prev指向最后一个节点的前一个节点,所以删除最后一个节点后,再将prev->next=NULL,就可以了。
图解:
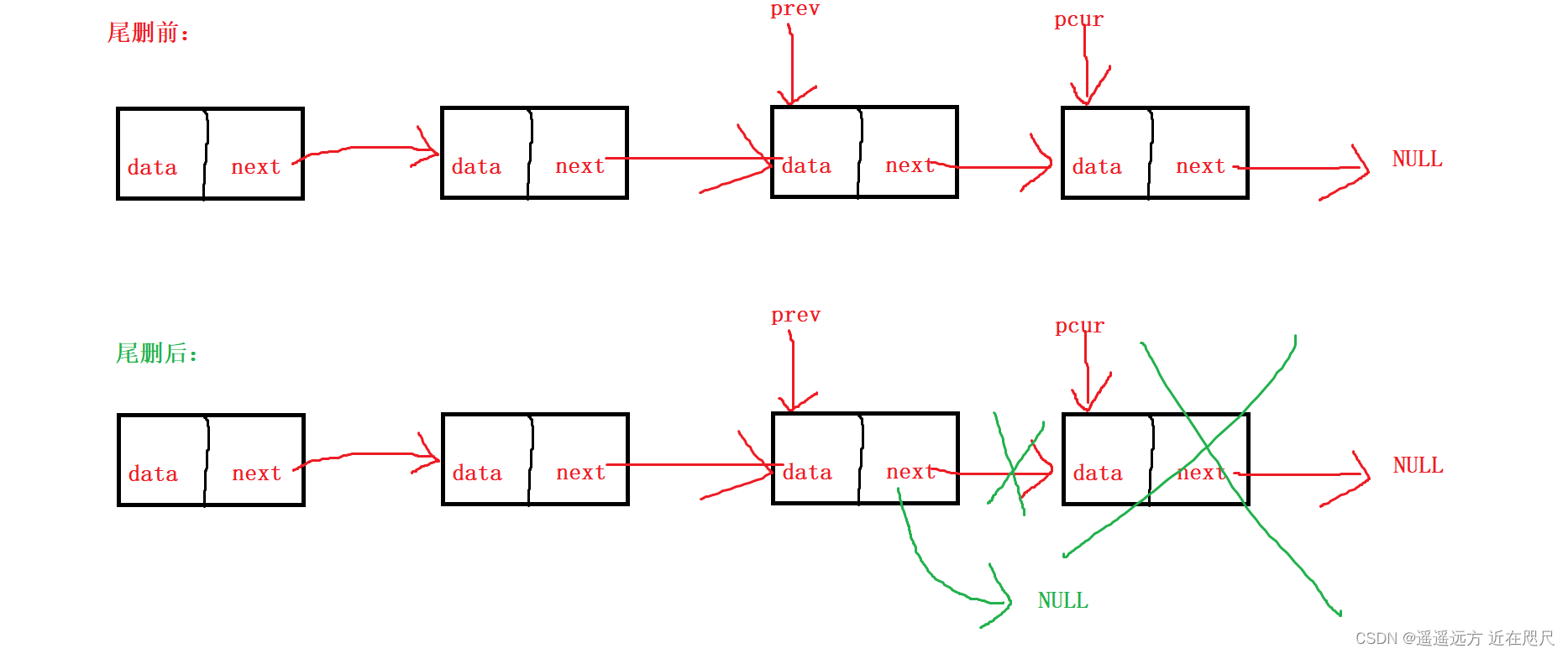
查找:
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{SLTNode* pcur = phead;while (pcur){if (pcur->data == x)return pcur;pcur = pcur->next;}return NULL;
}从头结点开始查找,一个节点一个节点的走,如果中途找到该数据,则直接返回该节点的地址;若走完最后一个节点都没找到该数据,那么返回NULL
插入:
1.在指定位置之前插入节点:
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{assert(pphead&&*pphead);assert(pos);//防止pos为NULLSLTNode* pcur = *pphead;SLTNode* prev = *pphead;SLTNode* newnode = SLTBuyNode(x);if (pos == *pphead){*pphead = newnode;newnode->next = pos;}else{while (pcur!= pos){prev = pcur;pcur = pcur->next;}prev->next = newnode;newnode->next = pos;}
}二级指针:若在头结点之前插入会改变头结点的值,所以用二级指针。
pcur和prev:因为插入需要找到pos的前一个节点,使前一个节点的next指向新的节点
插入分两种情况:
在头结点前插入和在其他位置插入
2.在指定位置之后插入节点:
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{assert(pos);SLTNode* newnode = SLTBuyNode(x);newnode->next = pos->next;pos->next = newnode;
}因为在pos之后插入所以不需要用到prev和pcur,也不需要用到二级指针。
注意代码顺序:如果先改pos->next,那么就找不到pos的下一个节点了。
删除指定位置的节点:
void SLTErase(SLTNode** pphead, SLTNode* pos)
{assert(pphead && *pphead);//该链表不能为空链表assert(pos);SLTNode* pcur = *pphead;SLTNode* prev = *pphead;if (pos == *pphead){*pphead = pos->next;free(pos);pos = NULL;}else{while (pcur != pos){prev = pcur;pcur = pcur->next;}prev->next = pos->next;free(pos);pos = NULL;}
}当删除的位置为头结点时,删除该节点会改变头结点的值,所以需要二级指针。
所以删除时分两种情况:1,pos为头结点 2,pos 不为头结点
删除指定位置之后的节点:
void SLTEraseAfter(SLTNode* pos)
{assert(pos&&pos->next);SLTNode* del = pos->next;pos->next = del->next;free(del);del = NULL;
}注意:pos->next不为NULL否则就会对NULL进行解引用引发错误。
要用del保存要删除的节点的地址否则就会找不到该节点。
图解:

销毁链表:
void SLTDestroy(SLTNode** pphead)
{assert(pphead && *pphead);SLTNode* pcur = *pphead;SLTNode* prev = *pphead;while (pcur){prev = pcur;pcur = pcur->next;free(prev);}*pphead = NULL;
}思路:用前后指针prev和pcur防止,如果只用一个指针pcur,先释放则找不到下一个节点了,若先使pcur走到下一个节点则找不到上一个节点。
所以用前后指针的释放prev指向的节点,然后再让prev指向pcur,pcur在指向下一个节点,直到pcur走到NULL为止。
图解:
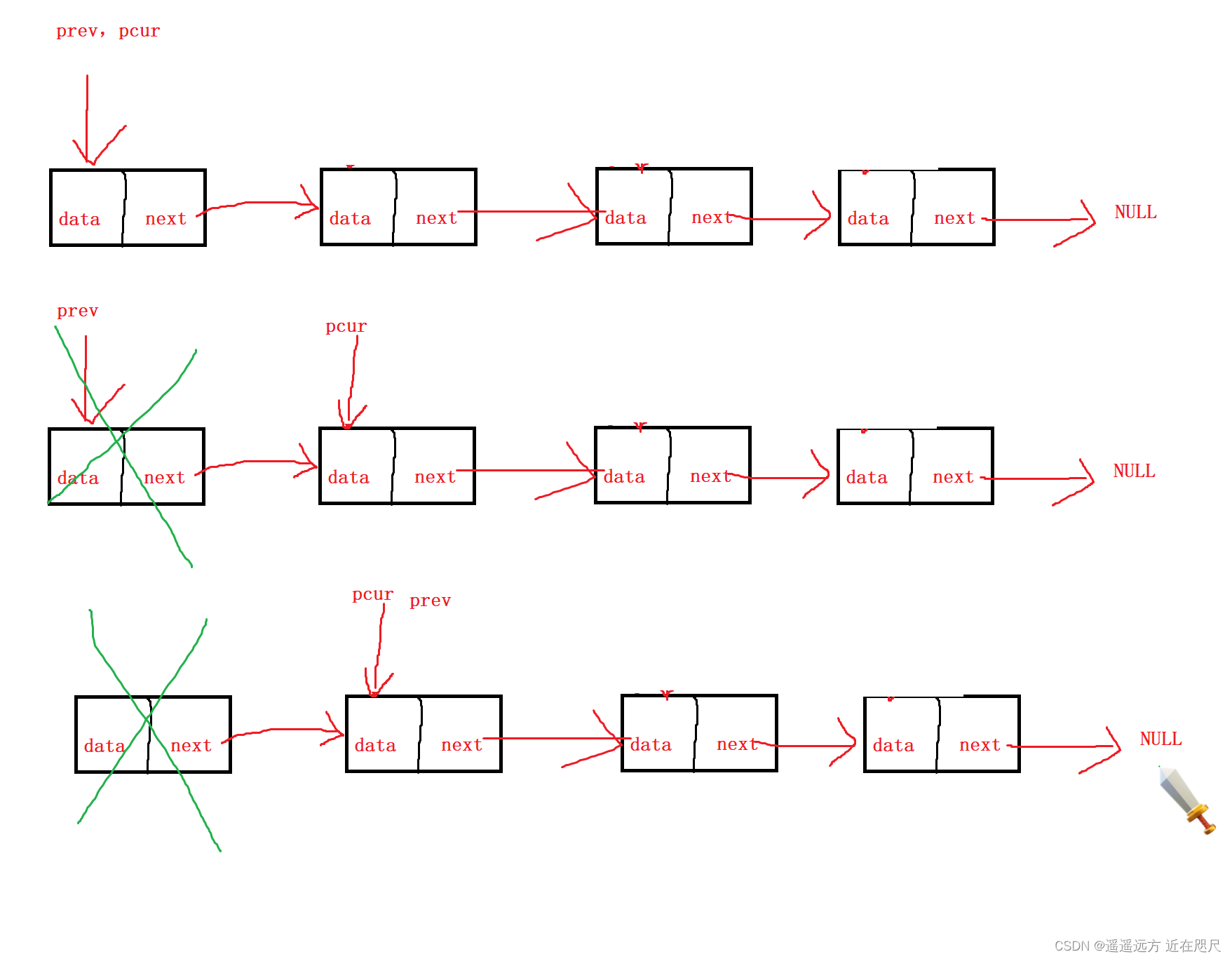
全部源码:
SList.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>typedef int SLTDataType;typedef struct SListNode
{struct SListNode* next;SLTDataType data;
}SLTNode;//头插
void SLTPushFront(SLTNode** pphead, SLTDataType x);
//尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x);
//打印链表中的数据
void SLTPrint(SLTNode* pphead);
//尾删
void SLTPopBack(SLTNode** pphead);
//头删
void SLTPopFront(SLTNode** pphead);
//查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x);
//在指定位置前插入数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);
//在指定位置后插入数据
void SLTInsertAfter(SLTNode* pos, SLTDataType x);
//删除指定位置的数据
void SLTErase(SLTNode** pphead, SLTNode* pos);
//删除指定位置之后的数据
void SLTEraseAfter(SLTNode* pos);
//销毁链表
void SLTDestroy(SLTNode** pphead);SList.c
#include "SList.h"SLTNode* SLTBuyNode(SLTDataType x)
{SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));if (newnode == NULL){perror("malloc");exit(1);}newnode->data = x;newnode->next = NULL;return newnode;
}void SLTPrint(SLTNode* phead)
{SLTNode* pcur = phead;while (pcur){printf("%d->", pcur->data);pcur = pcur->next;}printf("NULL\n");
}void SLTPushFront(SLTNode** pphead, SLTDataType x)
{assert(pphead);SLTNode* newnode = SLTBuyNode(x);if (*pphead == NULL){*pphead = newnode;}else{newnode->next = *pphead;*pphead = newnode;}
}void SLTPushBack(SLTNode** pphead, SLTDataType x)
{assert(pphead);SLTNode* pcur = *pphead;SLTNode* newnode = SLTBuyNode(x);if (*pphead == NULL){*pphead = newnode;}else{while (pcur->next){pcur = pcur->next;}pcur->next = newnode;}
}void SLTPopBack(SLTNode** pphead)
{assert(pphead && *pphead);SLTNode* pcur = *pphead;SLTNode* prev = *pphead;if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;}else{while (pcur->next){prev = pcur;pcur = pcur->next;}free(pcur);prev->next = NULL;}
}void SLTPopFront(SLTNode** pphead)
{assert(pphead && *pphead);SLTNode* tmp = (*pphead)->next;free(*pphead);*pphead = tmp;
}SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{SLTNode* pcur = phead;while (pcur){if (pcur->data == x)return pcur;pcur = pcur->next;}return NULL;
}void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{assert(pphead&&*pphead);assert(pos);SLTNode* pcur = *pphead;SLTNode* prev = *pphead;SLTNode* newnode = SLTBuyNode(x);if (pos == *pphead){*pphead = newnode;newnode->next = pos;}else{while (pcur!= pos){prev = pcur;pcur = pcur->next;}prev->next = newnode;newnode->next = pos;}
}void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{assert(pos->next);assert(pos);SLTNode* newnode = SLTBuyNode(x);newnode->next = pos->next;pos->next = newnode;
}void SLTErase(SLTNode** pphead, SLTNode* pos)
{assert(pphead && *pphead);assert(pos);SLTNode* pcur = *pphead;SLTNode* prev = *pphead;if (pos == *pphead){*pphead = pos->next;free(pos);pos = NULL;}else{while (pcur != pos){prev = pcur;pcur = pcur->next;}prev->next = pos->next;free(pos);pos = NULL;}
}void SLTEraseAfter(SLTNode* pos)
{assert(pos&&pos->next);SLTNode* del = pos->next;pos->next = del->next;free(del);del = NULL;
}void SLTDestroy(SLTNode** pphead)
{assert(pphead && *pphead);SLTNode* pcur = *pphead;SLTNode* prev = *pphead;while (pcur){prev = pcur;pcur = pcur->next;free(prev);}*pphead = NULL;
}结语:
又写完一篇数据结构的实现,cheers!