23年11月,Stability AI公司公开了稳定视频扩散模型Stable Video Diffusion(SVD)的代码和权重,视频生成迎来了新时代。SVD是一种潜在扩散模型,支持文本生成视频、图像生成视频以及物体多视角3D合成。从工程角度来看,本文主要提出了一种高质量、大型视频数据集的制作流程,并提出成功训练视频潜在扩散模型Video LDM的三阶段方法:文本到图像预训练、视频预训练和高质量视频微调。
Abstract
我们提出了稳定视频扩散模型Stable Video Diffusion——一种用于高分辨率、最先进的文本到视频和图像到视频生成的潜在视频扩散模型。最近,通过在小的、高质量的视频数据集上插入时间层并对其进行微调,用于 2D 图像合成的潜在扩散模型已经转化为视频生成模型。然而,文献中的训练方法差异很大,该领域尚未就管理视频数据的统一策略达成一致。
在本文中,我们明确并评估了视频LDM成功训练的三个不同阶段:文本到图像的预训练、视频预训练和高质量视频微调。更进一步,我们证明了精心策划的预训练数据集对于生成高质量视频的必要性,并提出了一个系统的策划过程来训练强大的基础模型,包括字幕和过滤策略。
然后,我们探索了在高质量数据上微调基础模型的影响,并训练一个与闭源视频生成有竞争力的文本到视频模型。基础模型为下游任务提供了强大的运动表示,例如图像到视频的生成和对相机运动特定 LoRA 模块的适应性。最后,我们的模型提供了强大的多视图3D先验,可以作为微调多视图扩散模型的基础,该模型以前馈方式共同生成物体的多个视图,计算预算约优于基于图像的方法。

代码和权重:https://github.com/ Stability-AI/generative-models
论文地址:https://arxiv.org/abs/2311.15127
论文名称:Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
本专题由深圳季连科技有限公司AIgraphX自动驾驶大模型团队编辑,旨在学习互助。内容来自网络,侵权即删。文中如有错误的地方,也请在留言区告知。
1. Introduction
在扩散模型生成图像建模技术进步的推动下,生成视频模型在研究领域
- Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models.(Nvidia,23.4)
- CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers(清华,22.5)
- Video Diffusion Models.(Google,22.6)
- Make-A-Video: Text-to-Video Generation without Text-Video Data.(Meta,22.9)
- Masked Conditional Video Diffusion for Prediction, Generation, and lnterpolation.(蒙特利尔大学,22.10)
- Imagen Video: High Definition Video Generation with Diffusion Models(Google,22.10)
和实际应用中取得了重大进展。
- Pika Labs. https://www.pika.art
- RunwayML.Gen-2 by runway, https://research.runwayml.com/gen2
总的来说,这些模型要么从头开始训练,要么通过插入额外时间层预训练图像模型进行微调(部分或全部)。训练通常在图像和视频混合数据集上进行。
然而围绕视频建模改进的研究主要集中在空间和时间层的精确排列上,上述工作都没有研究数据选择的影响。这是令人惊讶的,特别是因为训练数据分布对生成模型的重大影响是无可争议的。此外,对于生成图像建模,已知在大型和多样化的数据集上进行预训练,并在较小但高质量的数据集上进行微调可以显著提高性能。由于许多先前的视频建模方法已经成功地借鉴了图像域的技术,值得注意的是,数据和训练策略的影响,即在低分辨率下视频预训练和高质量微调的分离,还有待研究。这项工作直接解决了这些以前未知的领域。
我们认为,尽管在大规模训练视频模型时,数据选择在从业者中得到了广泛认可,但在当今的视频研究领域中,数据选择的重要贡献仍未得到充分体现。因此,与之前的工作相比,我们利用了简单的潜在视频扩散基线[Align your Latents],我们为其确定了架构和训练方案,并评估了数据管理的效果。为此,我们首先确定了三个不同的视频训练阶段,我们发现这三个阶段对良好的性能至关重要:文本到图像的预训练;低分辨率、大数据集上视频预训练;小数据集、高质量视频上进行高分辨率视频微调。借鉴大规模图像模型训练,我们引入了一种系统的大规模视频数据管理方法,并对视频预训练过程中的数据管理进行了实证研究。我们的主要发现表明,在精心策划的数据集上进行视频预训练可以显著提高性能,并在高质量视频微调后会更一步提升效果。
A general motion and multi-view prior 根据这些发现,我们将管理方案应用于包括大约6亿个样本的大型视频数据集,并训练一个强大预训练文本到视频基础模型,该模型提供了通用的运动表示。我们利用这一点,并在较小、高质量的数据集上微调基础模型,用于高分辨率的下游任务,如文本到视频(见图1顶端)和图像到视频,在这些任务中我们从单个条件图像预测一系列帧(见图1中间)。人类偏好研究表明,由此产生的模型优于最先进的图像到视频模型。
此外,我们还证明,我们的模型提供了强大的多视图先验,可以作为微调多视图扩散模型的基础,该模型以前馈方式生成对象的多个一致视图,并优于Zero123XL和SyncDreamer等专门的新视图合成方法。最后,我们证明了模型通过运动线索特别提示时间层,以及在仅类似于特定运动的数据集上训练LoRA模块来进行显式运动控制,这些模块可以有效地插入模型中。
总之,我们的核心贡献有三个方面:
- 我们提出了一个系统的数据管理工作流程,将大型未分级视频集转化为用于生成视频建模的高质量数据集。
- 训练最先进的文本到视频和图像到视频模型。
- 通过进行特定领域的实验,探索了运动和3D理解的强大先验。具体来说,预训练的视频扩散模型可以转化为强大的多视图生成器,这可能有助于克服通常在3D领域观察到的数据稀缺性。
2. Background
最近关于视频生成的大多数工作都依赖于扩散模型联合生成来自文本或图像条件的多个一致帧。扩散模型通过学习从正态分布逐渐去噪样本来实现迭代细化过程,并已成功应用于高分辨率文本到图像和视频合成。
在这项工作中,我们遵循这一范式,并在我们的视频数据集上训练一个潜在视频扩散模型。在以下段落中,我们简要概述了利用潜在视频扩散模型(视频LDM)的相关工作。
Latent Video Diffusion Models 在计算复杂度降低的潜在空间中训练主要生成模型。大多数相关工作使用预训练的文本到图像模型,并将各种形式的时间混合层插入到预训练的架构中。
- Latent-shift: Latent diffusion with temporal shift for efficient text-to-video generation.
- Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models.
- Preserve Your Own Correlation: A Noise Prior for Video Diffusion Models.
- Reuse and Diffuse: lterative Denoising for Text-to-Video Generation.
- AnimateDiff: Animate Your Personalized Text-to-lmage Diffusion Models without Specific Tuning.
A Noise Prior for Video Diffusion Models 依赖于时间相关噪声来增加时间一致性并简化学习任务。在这项工作中,我们遵循Align your latents提出的架构,并在每个空间卷积和注意力层之后插入时间卷积和注意层。与仅训练时间层或完全不训练的工作相反,我们对整个模型进行了微调。特别是对于文本到视频的合成,大多数工作直接在文本提示上调整模型或使用额外的文本到图像先验。
在我们的工作中,我们遵循前一种方法,并表明所得到的模型是一个强大的通用运动先验,可以很容易地微调为图像到视频或多视图合成模型。此外,我们引入了对帧速率的微调。我们还采用了EDM框架,并显著地将噪声调向更高噪声值,我们发现这对于高分辨率微调至关重要。关于后者的详细讨论,见第4节。
3. Curating Data for HQ Video Synthesis
在本节中,我们介绍了一种在大型视频数据集上训练最先进的视频扩散模型的通用策略。
- 介绍了数据处理和管理方法。
- 确定了生成视频建模的三种不同训练机制。
- 第一阶段:图像预训练image pretraining,即2D文本到图像的扩散模型。
- 第二阶段:视频预训练video pretraining,对大规模视频训练集进行训练。
- 第三阶段:视频微调video finetuning,以更高的分辨率在少量高质量视频上优化模型。
3.1. Data Processing and Annotation

图 2: 我们的初始数据集包含许多静态场景和剪辑,这损害了生成视频模型的训练。左图:剪辑的必要性。右图:平均光流分数分布,其中包含许多静态剪辑。
Data Curation 在大规模数据集上进行预训练是一些强大模型的重要组成部分,如判别性文本到图像和语言建模。通过利用高效的文本图像对表示如CLIP,数据管理也同样成功地应用于生成图像建模。然而,在视频生成文献中,关于此类数据管理策略的讨论在很大程度上是缺失的,并且处理和过滤策略是以特别的方式引入的。在可公开访问的视频数据集中,WebVid-10M数据集一直是一个受欢迎的选择,尽管它带有水印且大小不理想。此外,WebVid-10M经常与图像数据结合使用,以实现联合图像视频训练。然而,这增加了在最终模型上分离图像和视频数据效果的难度。为了解决这些缺点,本工作对视频数据管理方法进行了系统的研究,并进一步介绍了生成视频模型的一般三阶段训练策略,从而产生了最先进的模型。
我们收集了一个长视频的初始数据集,该数据集构成了视频预训练阶段的基础数据。为了避免剪辑和渐变泄漏到合成视频中,我们以级联Cascaded的方式在三个不同的FPS级别上应用剪辑检测cut detection流程。
图2(左)为剪辑检测的必要性提供了证据:在应用我们的剪辑检测流程后,我们获得了显著更高数量(~4×)的剪辑,这表明未处理数据集中的许多视频剪辑超出从元数据中获得的剪辑。
接下来,我们用三种不同的合成字幕方法synthetic captioning methods对每个片段进行标注:首先,我们使用图像字幕CoCa对每个片段的中间帧进行标注,并使用V-BLIP以获得基于视频的字幕。最后,我们通过前两个captions,基于LLM的摘要生成剪辑的第三个描述。
### 换成通俗的说法就是:利用image-caption对中间帧进行标注,该模型很好地描述了空间方面;利用VideoBLIP对视频进行标注,该模型很好的捕获了时间方面;最后为克服前两个标注各自的缺陷,利用大语言模型LLM总结前两标注。
由此产生的初始数据集,我们称之为大型视频数据集(LVD),由580M个带标注的视频剪辑对video clip pairs组成,形成212年的内容。
然而,进一步的调查表明,所得到的数据集包含的示例可能会降低我们最终视频模型的性能,例如运动较少、文本存在过多或美学价值普遍较低的片段。因此,我们还用密集光流dense optical flow对我们的数据集进行了标注,我们以2 FPS的速度计算该光流,并通过去除平均光流幅度低于特定阈值的视频来过滤掉静态场景。事实上,当通过光流分数考虑LVD的运动分布(见图2,右)时,我们在其中确定了接近静态剪辑的子集。
此外,我们应用光学字符识别optical character recognition来剔除包含大量书面文本的片段。最后,我们用CLIP嵌入来标注每个片段的第一帧、中间帧和最后帧,从中我们计算美学得分aesthetics scores以及文本图像相似性。表1提供了我们数据集的统计数据,包括剪辑的总大小和平均持续时间。
### 继续对大型视频数据集LVD进行操作,自此本论文的核心工作初步完成。
- 用dense optical flow估计FPS并过滤掉一定比例的低分视频。
- 用optical character recongnition筛选掉包含大量文字的视频。
- 用CLIP标注第一、中间和最后帧,计算美学得分和文本图像相似度。

### 经过处理、标注、筛选过滤后生成了一个动作连贯、精准文本描述的约1.5亿大型视频预训练数据集LVD-F。
- Cascaded Cut Detection
- Synthetic Captioning
- dense optical flow
- optical character recongnition
- Caption similarities and Aesthetics
- Calibrating Filtering Thresholds
3.2. Stage I: Image Pretraining
我们将图像预训练视为训练流程中的第一阶段。因此,根据视频模型的并行工作,我们将初始模型建立在预训练图像扩散模型上,即Stable Diffusion 2.1,以使其具有强大的视觉表示。
为了分析图像预训练的效果,我们训练并比较了两个相同的视频模型。在LVD的10M子集上;一个具有和一个不具有预训练空间权重。我们使用图3a中的人类偏好研究对这些模型进行了比较,这清楚地表明,图像预训练模型在质量和即时跟随方面都是首选的。

3.3. Stage II: Curating a Video Pretraining Dataset
A systematic approach to video data curation 一种系统的视频数据管理方法。对于多模态图像建模,数据管理是许多强大判别和生成模型的关键元素。然而在视频领域中,由于没有同样强大现成的表示可以过滤掉不需要的样本,我们依靠人类的偏好作为信号来创建合适的预训练数据集。具体来说,我们使用下面描述的不同方法来管理LVD的子集,然后考虑在这些数据集上训练的基于人类偏好的潜在视频扩散模型排名。
更具体地说,对于第3.1节中介绍的每种类型的标注(即CLIP分数、美学分数、OCR检测率、合成字幕、光流分数),我们从未经过滤的、随机采样的9.8M大小的LVD子集LVD-10M开始,并系统地删除最底层的12.5%、25%和50%的样本。请注意,对于合成字幕,我们不能从这个意义上进行过滤。相反,我们评估了第3.1节中不同字幕方法的Elo排名。为了使总子集的数量易于处理,我们将此方案分别应用于每种类型的标注。我们在这些过滤的子集中的每一个上使用相同的训练超参数来训练模型,并将同一标注类中所有模型的结果与人类偏好投票的Elo排名进行比较。基于这些投票,我们因此为每个标注类型选择性能最佳的过滤阈值。将这种过滤方法应用于LVD,产生152M训练样本的最终预训练数据集,我们称之为LVD-F,如表1。
Curated training data improves performance.在本节中,我们展示了上述数据管理方法改进了视频扩散模型的训练。为了说明这一点,我们将上述过滤策略应用于LVD-10M,并获得小四倍的子集LVD-10M-F。尽管LVD-10M-F也比这些数据集小四倍,但如图4b所示,在时空质量和即时对齐方面,相应的模型是人类评估者的首选。
Data curation helps at scale. 为了验证我们上面的数据管理策略也适用于更大、更实际的相关数据集,我们重复上面的实验,并在具有50M个样本和相同大小的非管理的过滤子集上训练视频扩散模型。我们进行了一项人类偏好研究,并在图4c中总结了这项研究的结果,我们可以看到,数据管理的优势也在大量数据中发挥作用。最后,我们展示了在图4d中对精选数据进行训练时,数据集大小也是一个关键因素,其中在50M精选样本上训练的模型优于在LVD-10M-F上训练的相同步数的模型。

3.4. Stage III: High-Quality Finetuning
在上一节中,我们展示了系统数据管理对视频预训练的有益效果。然而,由于我们主要对视频微调后的性能优化感兴趣,我们现在研究第二阶段后的这些差异如何转化为第三阶段后的最终性能。在这里,我们借鉴了潜在扩散建模中的训练技术,并提高了训练样本的分辨率。此外,我们使用了一个小型微调数据集,该数据集包括250K个具有高视觉逼真度的pre-captioned视频片段。
为了分析视频预训练的影响,在这个阶段,我们对三个相同的模型进行了微调,它们只是在初始化方面有所不同。
- 我们用预训练的图像模型初始化第一个的权重,并跳过视频预训练,这是最近许多视频建模方法中的常见选择。
- 剩下的两个模型是用上一节中潜在视频模型的权重初始化的,特别是在50M和未系统管理视频剪辑上训练的模型。
我们对所有模型进行了50万步的微调,并在微调的早期(10万步)评估了人类的偏好排名,最后测量了微调过程中性能差异的进展情况。我们在图4e中显示了获得的结果,其中我们绘制了用户偏好相对于排名最后的模型的Elo改进,该模型是从图像模型初始化的模型。此外,从精心策划的预训练权重恢复的微调级别始终高于从未分级训练后的视频权重初始化的微调级别。给定这些结果,我们得出结论:
- 视频模型训练在视频预训练和视频微调中的分离,有利于微调后的最终模型性能;
- 视频预训练理想情况下应在大规模、精心策划的数据集上进行,因为预训练后的性能差异在微调后仍然存在。
4. Training Video Models at Scale
4.1. Pretrained Base Model
如第3.2节所述,我们的视频模型基于Stable Diffusion 2.1。
最近的工作表明,在训练图像扩散模型时,采用噪声调度是至关重要的,对于更高分辨率的图像,它会向更大的噪声转移。作为第一步,我们使用网络预处理,将固定离散噪声从图像模型微调为连续噪声。在插入时间层之后,然后我们在分辨率为 256 × 384 的 14 帧上训练 LVD-F 的模型。我们使用150K次迭代、标准EDM噪声调度、Batch size 1536。接下来,我们对模型进行微调,以生成320 × 576的14 帧,用100k次迭代,Batch size 768。
我们发现,在这个训练阶段,将噪音调度转向更大的噪音是很重要的,Hoogeboom也证实了这一结果。我们将此模型称为我们的基础模型,它可以很容易地针对各种任务进行微调。
基础模型已经学习了强大的运动表示,例如,它显著优于UCF-101上零样本文本到视频生成的所有基线(表2)。

4.2. High-Resolution Text-to-Video Model
我们在约1M样本的高质量视频数据集上微调基础文本到视频模型。数据集中的样本通常包含大量的对象运动、稳定的相机运动和对齐良好的字幕,并且总体上具有高视觉质量。我们使用批batch size 768,576×1024,50k次迭代对基础模型进行微调。

4.3. High Resolution Image-to-Video Model
除了文本到视频,我们还微调了图像到视频生成的基础模型,其中静态输入图像作为条件。因此,我们用条件的CLIP图像嵌入来替换输入到基础模型中的文本嵌入。此外,我们将条件帧的噪声增强版本按通道连接到UNet输入。我们不使用任何掩码技术,只是在时间轴上复制帧。我们微调了两个模型,一个预测14帧,另一个预测25帧。我们偶然发现,标准的无分类器引导会导致伪影:引导过少可能导致与条件框架不一致,而引导过多可能导致过饱和。我们发现,在整个帧像素上线性增加引导标度(从小到高)是有帮助的,而不是使用恒定的引导标度。
与最先进的封闭源视频生成模型,特别是 GEN-2 和 PikaLabs进行比较,并表明我们的模型在人类评分的视觉质量方面是首选。
### 两个开源Stable Video Diffusion模型,都基于Stable Diffusion V2.1进行训练。SVD版本,14帧;SVD-XT版本,25帧。从人工评测结果看,效果超过runaway GEN2和Pika Labs开源模型。
4.3.1 Camera Motion LoRA
为了便于图像到视频生成的受控相机运动,我们在模型的时间注意块内用LoRA微调各种相机运动。我们在具有丰富的摄影机运动元数据的小数据集上训练这些附加参数。特别是,我们使用了三个子集的数据,其中相机运动被归类为“水平移动”、“缩放”和“静态”。在图7中,我们展示了相同条件框架下的三种模型的样本。

4.4. Frame Interpolation
为了获得高帧率下的平滑视频,我们将高分辨率文本到视频模型调整为帧插值模型。我们遵循Align your latents论文方法并通过掩码将左、右帧连接起来作为UNet的输入。该模型在两个条件帧内学习预测三帧,有效地将帧率提高了四帧。令人惊讶的是,我们发现非常少量的迭代(≈10k)就足以得到一个好的模型。
4.5. Multi-View Generation
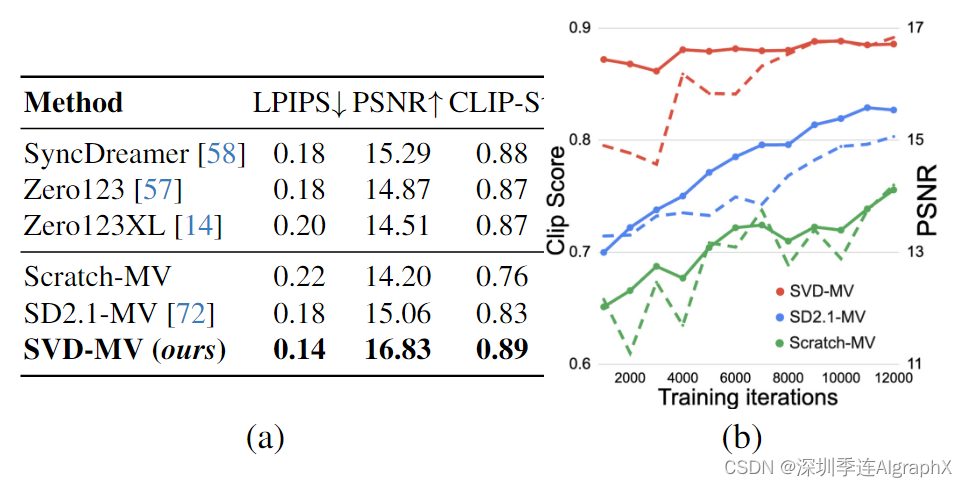
为了同时获得一个物体的多个新视图,我们在两个数据集Objaverse、MVImgNet上对我们的SVD模型进行了微调。我们将微调多视图模型称为SVD-MV。我们对SVD的视频先验在多视图生成中的重要性进行了初步研究。为此,我们比较了来自SVD-MV的结果。
### 多视角渲染:生成同一个物体的多个观察角度视频镜头,呈现 3D 视频效果。
5. Conclusion
我们提出了稳定视频扩散Stable Video Diffusion,这是一种用于高分辨率,最先进的文本到视频和图像到视频合成的潜在视频扩散模型。为了构建其预训练数据集,我们进行了系统的数据选择和缩放研究,并提出了一种方法来管理大量的视频数据,并将大而有噪声的视频集合转化为适合生成视频模型的数据集。此外,我们介绍了视频模型训练的三个不同阶段,我们分别分析了它们对最终模型性能的影响。稳定视频扩散SVD提供了一个强大的视频表示,我们从最先进的图像到视频合成和其他高度相关的应用微调视频模型。最后,我们对视频扩散模型的多视图微调进行了开创性的研究,并表明SVD构成了一个强大的3D先验,它在仅使用少量计算情况下就可以获得最先进的多视图合成结果。我们希望这些发现将在生成视频建模文献中广泛有用。