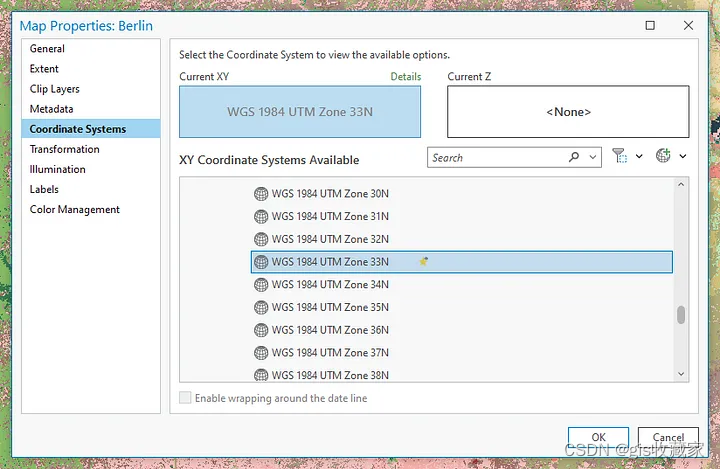
注意力机制
- 为什么需要注意力机制
- Seq2Seq问题
- Transfomer
- Attention注意力机制
- 分类
- 软硬注意力
- 注意力域
为什么需要注意力机制
这个可以从NLP的Seq2Seq问题来慢慢理解。
Seq2Seq问题
Seq2Seq(Sequence to Sequence):早期很多模型中,样本特征维度通常都是一致的。但是在机器翻译中,输入和输出的长度都是不固定的,例如输入英文“school”会输出中文“学校”,输入一个单词却输出两个汉字。如何解决这种输入输出特征维度可变的情况,并可以把一个序列直接转换到另一个序列,这就是Seq2Seq要解决的问题。
经典的Seq2Seq模型:使用的是两个循环神经网络(Recurrent Neural Network,RNN),下面是其的Encoder-Decoder结构图。编码器将输入序列转换为一个固定长度的向量表示,解码器将该向量转换为长度不固定的输出序列。

Encoder部分是一个多输入单输出的RNN结构,把词向量x依次输入到Encoder,隐藏神经元A输入是由当前输入x和上一个隐藏神经元的输出组成,最后输出最后一个隐藏神经元的输出作为Decoder的输入。这样的Encoder结构可以模拟人类的阅读顺序去读取序列化数据,只保留最后一个隐藏状态,相当于将把整个序列浓缩在了一起。
Decoder结构和Encoder结构几乎是一样的,不同的地方在于输入的x是前面的结果。如果是训练阶段那么输入的x就是前面输出的label(标准答案),如果是测试阶段那么输入的 x ∗ x^* x∗就是前面输出的结果。这样Decoder结构也可以模拟人类说话的顺序,输出不同长度的序列。

存在的问题:当使用RNN处理长文本序列的时候,会出现两个问题。首先,第一个问题就是其顺序结构导致无法捕捉长序列上下文信息。Decoder做预测非常依赖于Encoder最后的输出,但是如果句子过长,Encoder最后的输出状态会忘记前面的句子内容,也就是信息丢失。第二个问题就是并行处理序列困难。因为RNN的内部循环结构,所以只能顺序处理序列,无法对序列整体进行并行计算。
补充:Seq2Seq是一个端到端(end-to-end)的网络模型,所谓的端到端神经网络是指能够直接从原始数据中提取特征并输出最终结果的模型,不需要显式地进行手动特征提取或分步骤处理。
Transfomer
Transfomer:Transfomer的核心就是Attention注意力机制,在RNN的Encoder-Decoder基础上加入了注意力机制,能实现长序列的并行处理,从而来解决前面提到RNN的两个问题。
为什么能解决RNN处理长文本序列的问题:加入Attention注意力机制后的Seq2Seq模型,不会忘记原始输入句子信息,而且Decoder也能够知道句子中哪些词比较重要,但是会增加额外的计算量。
应用:除了前面提到的自然语言处理(Natural Language Processing,NLP),Transfomer还在计算机视觉(Computer Vision,CV)中也有所应用。卷积神经网络(Convolutional Neural Network,CNN)作为计算机视觉领域中一个热门的研究方向,非常擅长特征提取,但是其更关注局部的信息。CNN的核心是卷积,而Transformer的核心是自注意力机制。自注意力机制允许模型从图像中任意位置获取信息,更好地处理长距离依赖关系。而CNN则需要在多层卷积之后,才能将图片中距离比较远的像素点关联起来。
Attention注意力机制
Attention介绍:就是模仿人的注意力机制设计,人看到一个东西,会把注意力放在需要关注的地方,把其它无关的信息过滤掉。下面的图是人类看到图片注意力热力图。

Attention原理:在Seq2Seq模型介绍的时候,会发现Encoder只会把最后一个隐藏状态输出,对于前面隐藏状态全部都舍弃了,而Attention做得就是把舍弃掉的隐藏信息给利用起来。在Seq2Seq举的翻译例子中,把“Hellow world”翻译为“哈喽世界”,“Hellow”对“哈”、“喽”、“世”和“界”每个字的贡献都是一致,但是实际上“Hellow”应该对“哈”和“喽”的贡献要多些,而对“世”和“界”的贡献要少些。如何分配这些贡献程度并得到合适的向量传递给Decoder,这就是Attention要实现的,主要是用在Encoder部分。
Attention机制:
Attention机制的核心就是QKV。
Q(Query):Query包含了读者的问题的信息。
K(Key):Key与Value相关联,Key是原始信息所对应的关键性信息,相当于对原始信息做了某种转换得到的词向量。
V(Value):Value理解为原始捕捉到的信息,不受到任何注意力的干扰。
计算步骤:
- Query和Key进行相似度计算,得到Attention Score。
- 对Attention Score进行Softmax归一化,得到权值矩阵,相当于每个贡献程度。
- 权重矩阵与Value进行加权求和计算。
看过一个比较好的比喻,可以把Attention过程比作我们在浏览器搜索文章的过程。
Value相当于浏览器里面所有的文章,Key相当于每个文章对应的标题,标题是从文章张提炼的,而Query相当于我们输入到浏览器中的问题。Attention搜索过后,就会对每个文章和问题匹配度进行一个得分,来对原来的文章筛查。
总结QKV:Query相当于问题,Value相当于一组答案,Key相当于该答案所对应问题的关键字
分类
软硬注意力
软注意力(Soft Attention):加权图像的每个像素。 高相关性区域乘以较大的权重,而低相关性区域标记为较小的权重。注意力模块相对于输入是可微的,所以通过标准的反向传播方法进行训练。
大多数软注意力模块都不会改变输出尺寸,从而可以很灵活的插入到卷积网络的各个部分。但会增加训练参数,从而导致计算成本有所提高。
硬注意力(Hard Attention):一次选择一个图像的一个区域作为注意力,设成1,其他设为0。通常是不可微的,硬注意力相对软注意力更难训练,不能反向传播,但是可以借助如强化学习的手段去学习。
注意力域
注意力机制中的模型结构分为三大注意力域来分析。
主要是:空间域(spatial domain),通道域(channel domain),混合域(mixed domain)。
- 空间域:将图片中的的空间域信息做对应的空间变换,从而能将关键的信息提取出来。对空间进行掩码的生成,进行打分,代表是Spatial Attention Module。
- 通道域:类似于给每个通道上的信号都增加一个权重,来代表该通道与关键信息的相关度的话,这个权重越大,则表示相关度越高。对通道生成掩码mask,进行打分,代表是SEnet, Channel Attention Module。
- 混合域:空间域的注意力是忽略了通道域中的信息,将每个通道中的图片特征同等处理,这种做法会将空间域变换方法局限在原始图片特征提取阶段,应用在神经网络层其他层的可解释性不强。代表主要是BAM(Bottleneck Attention Module)和CBAM(Convolutional Block Attention Module)。