˃͈꒵˂͈꒱ write in front ꒰˃͈꒵˂͈꒱
ʕ̯•͡˔•̯᷅ʔ大家好,我是xiaoxie.希望你看完之后,有不足之处请多多谅解,让我们一起共同进步૮₍❀ᴗ͈ . ᴗ͈ აxiaoxieʕ̯•͡˔•̯᷅ʔ—CSDN博客
本文由xiaoxieʕ̯•͡˔•̯᷅ʔ 原创 CSDN 如需转载还请通知˶⍤⃝˶
个人主页:xiaoxieʕ̯•͡˔•̯᷅ʔ—CSDN博客系列专栏:xiaoxie的JAVAEE学习系列专栏——CSDN博客●'ᴗ'σσணღ
我的目标:"团团等我💪( ◡̀_◡́ ҂)"( ⸝⸝⸝›ᴥ‹⸝⸝⸝ )欢迎各位→点赞👍 + 收藏⭐️ + 留言📝+关注(互三必回)!
目录
编辑 一.文件IO概述
1.什么IO
2.什么是文件
1.绝对路径
2.相对路径
编辑
3.如何区分一个文件是二进制文件还是文本文件
3.使用Java操作文件
1.使用Java针对文件系统进行操作
1.构造方法
2.常用API
3.常用方法使用
Java代码
创建文件
删除文件
创建目录
2.Java通过使用流来对文件内容进行操作
1. 字节流 vs 字符流
1.字节流 (Byte Streams)
2.字符流 (Character Streams)
3.区别
2.使用字节流对文件内容操作
1.InputStream的使用(从文件读取数据)
1.read()方法不带参数
2.read()方法带参数
2.OutputStream的操作(从文件中写入数据)
1.write()方法
3.使用字符流对文件内容操作
1.Reader的使用
1.read()方法
2.Writer的使用
1.writer
二.根据文件IO操作和流操作的知识解决问题的案例
1.案例一:
2.案例二:
3.案例三:
 一.文件IO概述
一.文件IO概述
1.什么IO
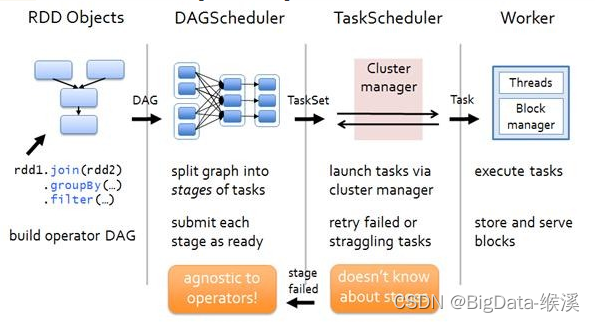
IO就是 Input(输入), Output(输出),至于如何判断一个操作是否为输入还是输出,可以以下图的标准作为参考

我们以CPU 作为基准,进入CPU方向的操作就是Input(输入),从CPU方向出去就是Output(输出).
2.什么是文件
文件是一个很广义的概念,在操作系统中把 软件资源/ 硬件资源 都给抽象为 文件 ,特别是在 Linux 中 一切皆为文件.
在此处我们所提的文件,特指的就是保存在硬盘中的文件,而硬盘上又有非常多的文件和目录(就是我们俗称的文件夹)directory,它们之间又有着嵌套的关系,从而就构成了多叉树的结构.
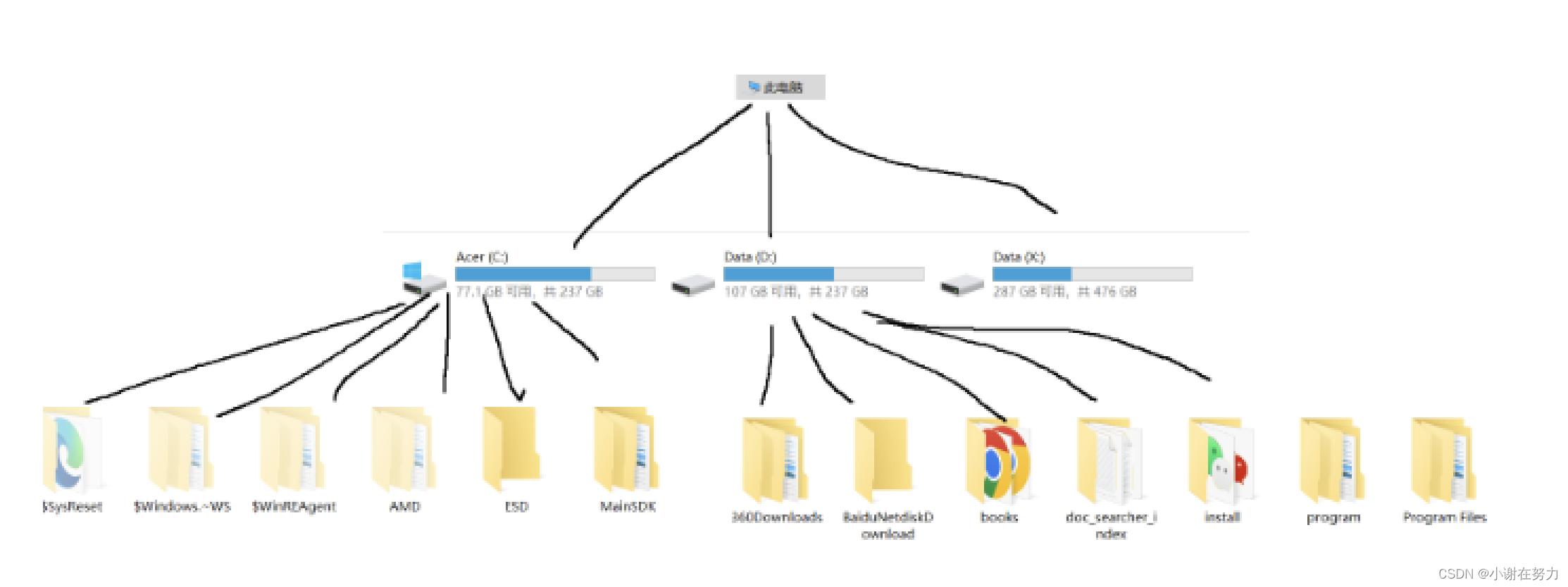 而我们对文件的操作,本质上就是对该多叉树的增删查改,而我们该如何找到文件的具体位置在那呢,这个时候,就引入的两个方法,即绝对路径,以及相对路径
而我们对文件的操作,本质上就是对该多叉树的增删查改,而我们该如何找到文件的具体位置在那呢,这个时候,就引入的两个方法,即绝对路径,以及相对路径
1.绝对路径
在计算机操作系统中,绝对路径是指从文件系统的根目录开始的完整路径,它提供了到达某个特定文件或目录的确切位置。绝对路径是唯一的,并且不依赖于当前工作目录的位置。
例如我们要找到qq.exe的绝对路径
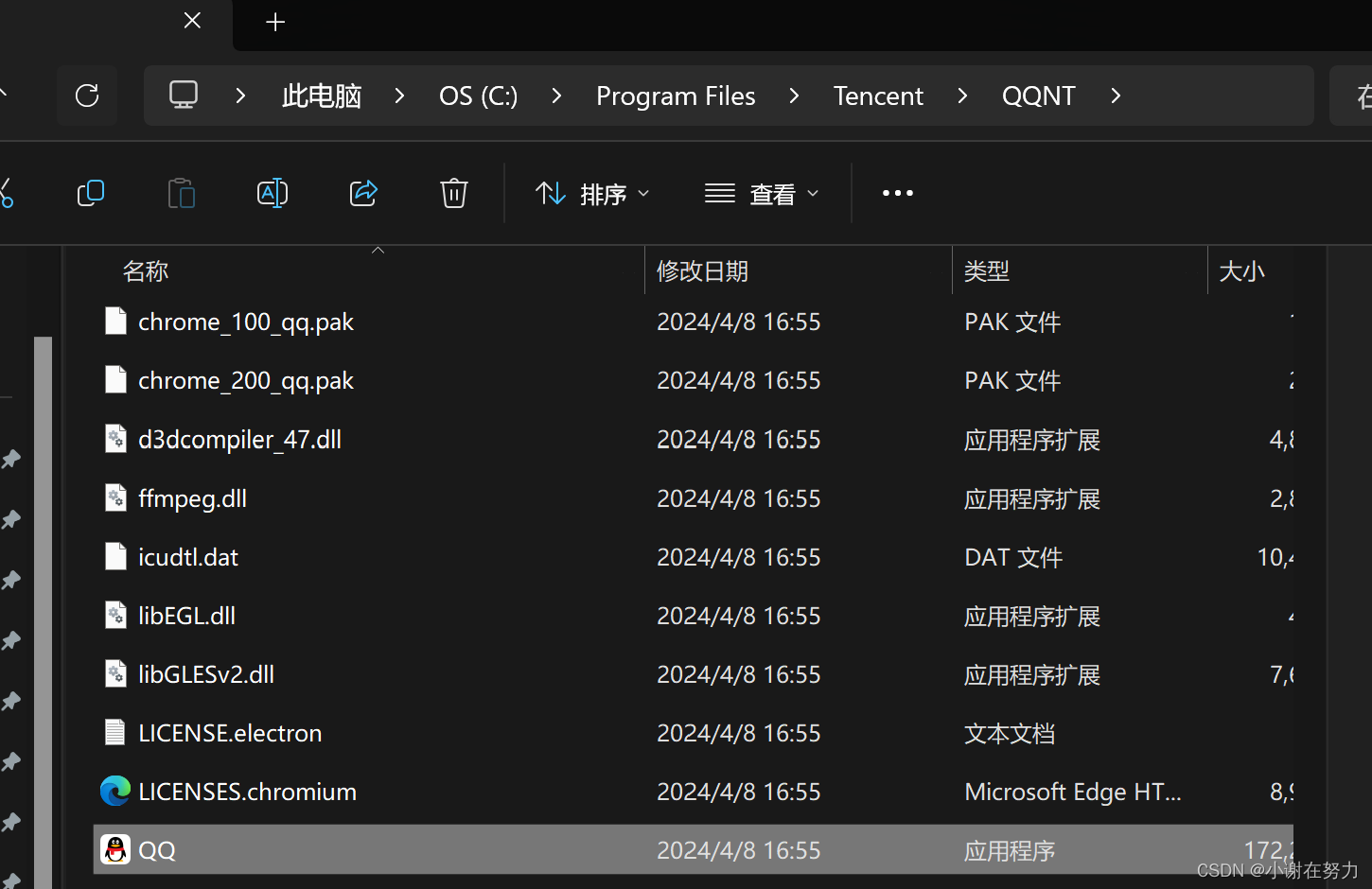
在Windows操作系统中 我们直接点上方搜索框,即可 C:\Program Files\Tencent\QQNT\QQ.exe
这个就为QQ.exe 这个文件的绝对路径了
注意:
这里的 \ 是 路径分割符,这里博主建议应该为 / ,因为只有在Windows操作系统中, \ 这个为路径分割符,而在像Linux中是以 / 这个为路径分割符,我们日后再工作中一般使用的都是 Linux 的环境下的,所以在我们写代码的时候建议使用 / 作为路径分隔符.
2.相对路径
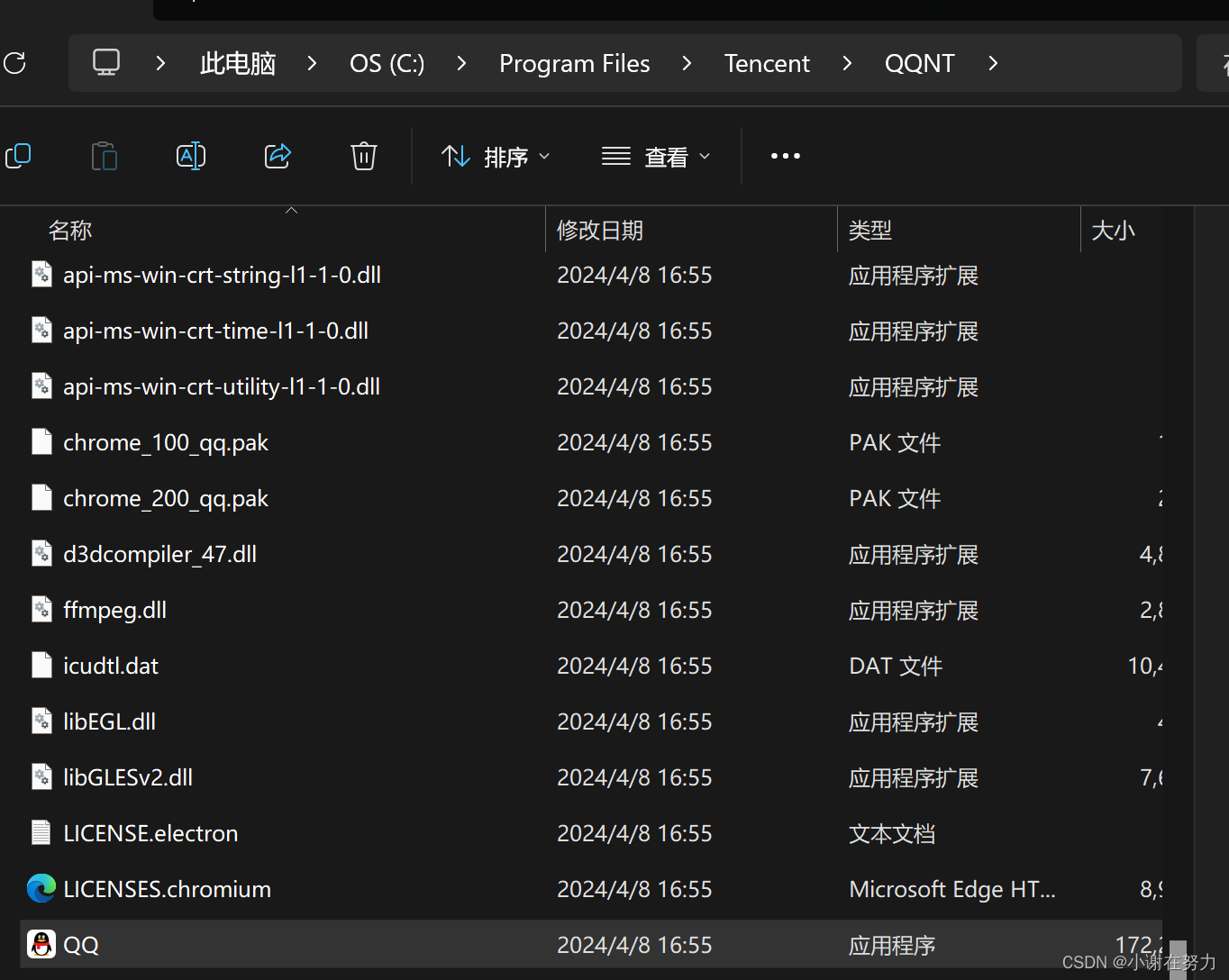
例如我们是以 QQNT 作为基准的, 直接就 ./QQ.exe 就可以找到对于的文件了,这个就是相对路径,就是不是以根路径为基准了, 其中 . 这一个点表示的意思是在当前所在的位置. 或者我们此时在 QQNT的另一个文件中
 我们要想找到QQ.exe的相应位置 就得使用 ../QQ.exe 其中 .. 这两个点的意思就是,回到上一级路径, 相对路径相对来说就比较多表了,根据不同的情况就有不同的相对路径,而绝对路径是唯一的.
我们要想找到QQ.exe的相应位置 就得使用 ../QQ.exe 其中 .. 这两个点的意思就是,回到上一级路径, 相对路径相对来说就比较多表了,根据不同的情况就有不同的相对路径,而绝对路径是唯一的.
3.如何区分一个文件是二进制文件还是文本文件
区分一个文件是二进制文件还是文本文件还是特别重要的,文件的不同,我们的代码也大相同,那么如何,快速区分呢,直接使用记事本打开看看是不是乱码就可以区分,如果是,那么就为二进制文件,不是就为文本文件
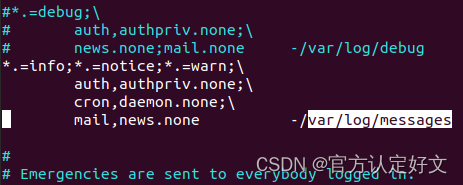
例如我们使用记事本打开一个图片看一下

可以看到我们所看到的记事本的内容为乱码,即这个文件那就是二进制文件
3.使用Java操作文件
1.使用Java针对文件系统进行操作
在Java中,操作文件系统主要涉及Java标准库中的java.io和java.nio.file包。下面是一些常用的API
1.构造方法
| 方法名 | 说明 |
| File(File parent, String child) | 根据⽗⽬录 + 孩⼦⽂件路径,创建⼀个新的 File 实例 |
| File(String pathname) | 根据⽂件路径创建⼀个新的 File 实例,路径可以是绝对路径或者相对路径 |
| File(String parent, String child) | 根据⽗⽬录 + 孩⼦⽂件路径,创建⼀个新的 File 实 例,⽗⽬录⽤路径表⽰ |
我们一般使用第二种方法来创建文件
2.常用API
| 修饰符及返回值类型 | 方法名 | 说明 |
| String | getParent() | 返回 File 对象的⽗⽬录⽂件路径 |
| String | getName() | 返回 FIle 对象的纯⽂件名称 |
| String | getPath() | 返回 File 对象的⽂件路径 |
| String | getAbsolutePath() | 返回 File 对象的绝对路径 |
| String | getCanonicalPath() | 返回 File 对象的修饰过的绝对路径 |
| boolean | exists() | 判断 File 对象描述的⽂件是否真实 存在 |
| boolean | isDirectory() | 判断 File 对象代表的⽂件是否是⼀ 个⽬录 |
| boolean | isFile() | 判断 File 对象代表的⽂件是否是⼀ 个普通⽂件 |
| boolean | createNewFile() | 根据 File 对象,⾃动创建⼀个空⽂ 件。成功创建后返回 true |
| boolean | delete() | 根据 File 对象,删除该⽂件。成功 删除后返回 true |
| void | deleteOnExit() | 根据 File 对象,标注⽂件将被删 除,删除动作会到 JVM 运⾏结束时 才会进⾏ |
| String[] | list() | 返回 File 对象代表的⽬录下的所有 ⽂件名 |
| File[] | listFiles() | 返回 File 对象代表的⽬录下的所有 ⽂件,以 File 对象表⽰ |
| boolean | mkdir() | 创建 File 对象代表的⽬录 |
| boolean | mkdirs() | 创建 File 对象代表的⽬录,如果必 要,会创建中间⽬录 |
| boolean | renameTo(File dest) | 进⾏⽂件改名,也可以视为我们平 时的剪切、粘贴操作 |
| boolean | canRead() | 判断⽤⼾是否对⽂件有可读权限 |
| boolean | canWrite() | 判断⽤⼾是否对⽂件有可写权限 |
3.常用方法使用
首先我先创建好一个 文本文件-> work.txt

Java代码
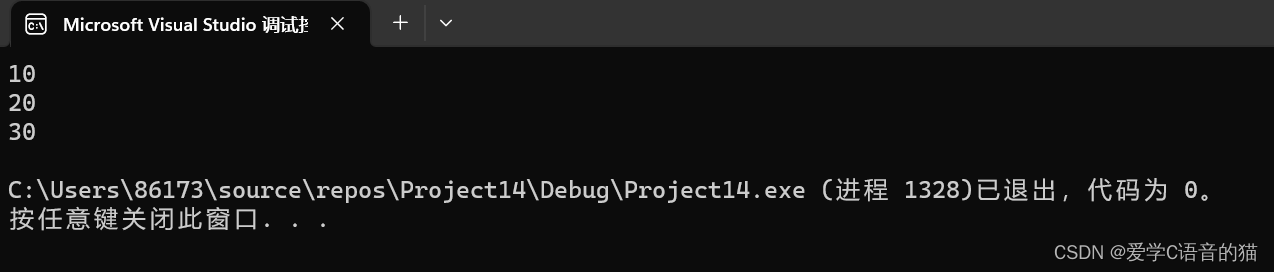
public static void main(String[] args) throws IOException {// 创建一个File对象,这里使用的是绝对路径File file = new File("C:/java/work.txt");// 获取文件所在的父路径System.out.println(file.getParent());// 获取文件名部分System.out.println(file.getName());// 获取从当前工作目录到文件的相对路径,System.out.println(file.getPath());// 获取文件的绝对路径,基于系统的根目录,确保得到完整的路径System.out.println(file.getAbsolutePath());// 获取文件的相对路径System.out.println(file.getCanonicalPath());
}结果为
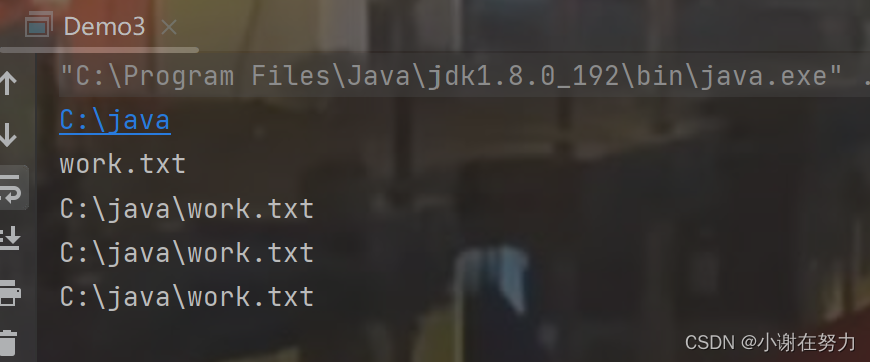
如果我们在构造方法上使用相对路径的话,就会在你的Java工作文件上创建
public static void main(String[] args) throws IOException {File file = new File("./work.txt");System.out.println(file.getParent());System.out.println(file.getName());System.out.println(file.getPath());System.out.println(file.getAbsolutePath());System.out.println(file.getCanonicalPath());}结果为
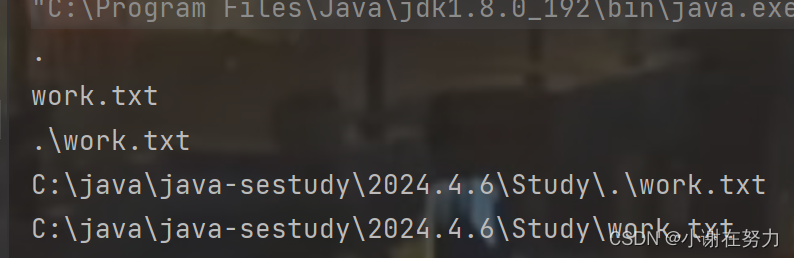
可以看到相对路径和绝对路径就是在Java工作路径和相对路径进行简单的拼接.
创建文件
// 主方法的开始,可以抛出IOException异常
public static void main(String[] args) throws IOException {// 创建File对象file,使用相对路径File file = new File("./work.txt"); // 如果work.txt文件不存在,则创建它;如果已存在,则不执行任何操作file.createNewFile(); // 打印true,如果文件存在(包括文件和目录)System.out.println(file.exists()); // 打印文件是否为普通文件的检查结果System.out.println(file.isFile()); // 打印文件是否为目录的检查结果System.out.println(file.isDirectory()); }结果为:
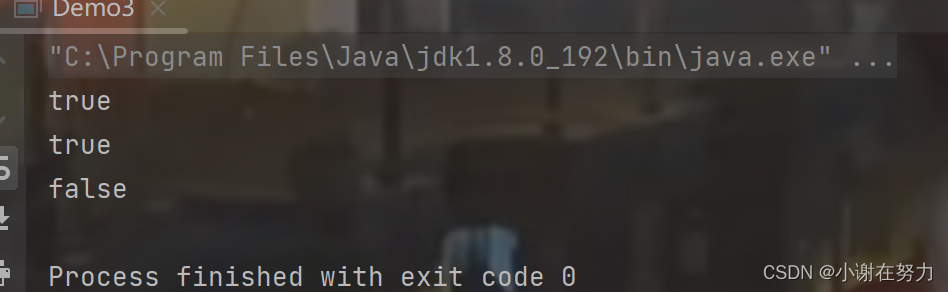
同时还可以看到,在Java工作路径下,work.txt被创建出来了
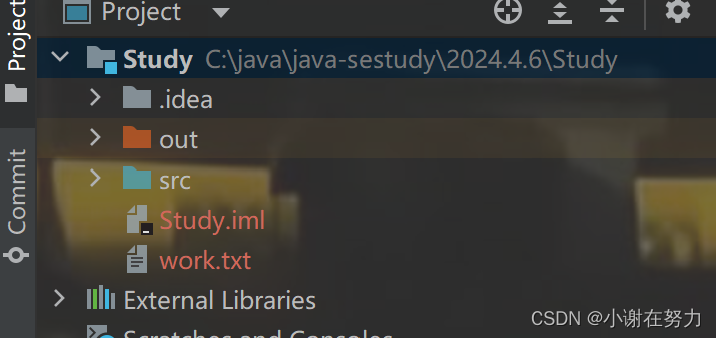
删除文件
实际上,在大多数情况下,delete() 方法就已经足够用于删除文件。然而,deleteOnExit() 方法提供了另一种特殊的删除策略,它的应用场景有所不同:
-
delete()方法:- 直接尝试删除指定的文件或目录(非空目录需先删除其中的所有子文件和子目录)。
- 如果文件正在被另一个进程或线程访问,该方法可能无法成功删除文件。
- 调用该方法后,删除操作立即执行,若失败则会抛出异常。
-
deleteOnExit()方法:- 注册一个请求,指示在虚拟机终止时(当Java应用程序正常退出时)应该删除指定的文件。
- 这种方法适用于你希望在程序退出时清理临时文件或日志文件等资源,但不想在程序运行过程中因删除文件导致的问题而影响程序逻辑。
- 使用此方法时,即使在删除文件时发生异常,也不会立即抛出异常,而是等到JVM关闭时再尝试删除。
所以,是否选择deleteOnExit()取决于你的具体需求。如果你需要立即且确定地删除文件,应使用delete()方法;如果你希望在程序结束时清理某个文件,同时允许在程序运行过程中继续使用该文件,可以考虑使用deleteOnExit()方法。但请注意,deleteOnExit()方法注册的待删文件数量过多或文件较大,可能会消耗较多系统资源,应在适当场景下谨慎使用。
delete()就不过多演示,这里演示一下deleteOnExit()方法
public static void main(String[] args) throws IOException {File file = new File("./work.txt");file.deleteOnExit(); /为了演示,这里让程序暂停一会儿,以便观察文件是否被删除try {Thread.sleep(5000);}catch (InterruptedException e) {e.printStackTrace();}// 请注意,这段代码不会立即删除文件,文件将在JVM退出时删除System.out.println(file.exists());}创建目录
public static void main(String[] args) {File dir = new File("./testDir/aaa/bbb/ccc/ddd");// mkdir 只能创建出一级目录// dir.mkdir();// 可以创建多级目录dir.mkdirs();System.out.println(dir.isDirectory());}2.Java通过使用流来对文件内容进行操作
Java主要通过字节流 和 字符流 来对文件内容进行操作
1. 字节流 vs 字符流
1.字节流 (Byte Streams)
字节流用于处理二进制数据,它们不关心数据的编码或字符集。字节流可以处理任何类型的数据,包括文本、图片、视频等。字节流在Java中由java.io包提供,主要的类有:
InputStream: 字节输入流的基类。(抽象类)OutputStream: 字节输出流的基类。(抽象类)FileInputStream: 用于从文件中读取字节的类。FileOutputStream: 用于向文件中写入字节的类。
2.字符流 (Character Streams)
字符流用于处理文本数据,它们处理的是字符而不是字节。字符流可以自动处理不同平台间的字符编码差异。字符流在Java中由java.io包提供,主要的类有:
Reader: 字符输入流的基类。(抽象类)Writer: 字符输出流的基类。(抽象类)FileReader: 用于从文件中读取字符的类。FileWriter: 用于向文件中写入字符的类。
3.区别
- 处理数据类型: 字节流处理二进制数据,字符流处理文本数据。
- 编码问题: 字符流可以自动处理字符编码,而字节流不关心编码。
- 效率: 字节流通常比字符流更高效,因为它们直接处理字节,不需要进行字符编码转换。
- 使用场景: 字节流适用于处理非文本文件,如图片、音频、视频等;字符流适用于处理文本文件。
2.使用字节流对文件内容操作
1.InputStream的使用(从文件读取数据)
1.read()方法不带参数
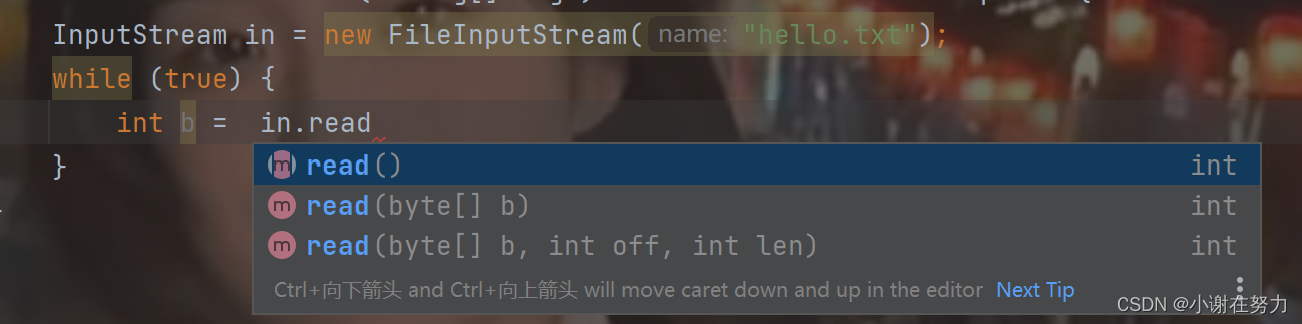
public static void main(String[] args) {try(InputStream in = new FileInputStream("hello.txt")) {while (true) {int b = in.read();if(b == -1) {//读取完毕break;}System.out.printf("0x%X ", b);}}catch (IOException e) {e.printStackTrace();}}几个需要解释的地方
1.try(InputStream in = new FileInputStream("hello.txt") 这里的hello.txt 需要我们提前准备好模拟接收到文件的过程.所以里面需要写好一些数据,同时这里使用 try()是因为 InputStream 实现了Closeable 接口,可以让系统帮你关闭文件.防止你忘记关闭文件,或者可能因为别的原因没有关闭文件导致,出现问题
2.这里的 int b 是in.read()的返回值 如果成功读取到了字节,则返回该字节对应的十进制数值(范围是0-255,因为一个字节有8位,最高位为符号位,实际能表示的无符号整数范围是0-255)。但如果已经到达了流的末尾,也就是文件的结尾,并且没有更多的数据可供读取时,read()方法会返回-1。
2.read()方法带参数
public static void main(String[] args) {try(InputStream in = new FileInputStream("hello.txt")) {byte[] bytes = new byte[1024];int n = in.read(bytes);for (int i = 0; i < n; i++) {System.out.printf("0x%x ", bytes[i]);}}catch (IOException e) {e.printStackTrace();}}几个需要解释的地方
1.定义一个大小为1024的字节数组bytes,用于存放从文件中读取的数据。数组的大小决定了每次读取的最大字节数。意思就是不是一个字节的读了,而是一次性读最多读1024个字节,如果超过1024个字节,可以写一个循环,循环读取,直到 n = -1;
while ((n = in.read(bytes)) != -1) {for (int i = 0; i < n; i++) {System.out.printf("0x%x ", bytes[i]);}
}2.带参数的方法,还可以控制,每次读取操作的起始位置和读取长度可以更精细的控制其他的和别的方法无太多差别.
int read(byte[] b, int off, int len)2.OutputStream的操作(从文件中写入数据)
1.write()方法
public static void main(String[] args) {try(OutputStream outputStream = new FileOutputStream("hello.txt",true)) {outputStream.write(97);outputStream.write(100);outputStream.write(99);outputStream.write(98);System.out.println("写入完毕");}catch (IOException e) {e.printStackTrace();}}几个解释的地方
1.OutputStream outputStream = new FileOutputStream("hello.txt",true) ,这里除了加上了相对路径,后面还有一个参数为 true,这里要是没设置,就默认为false 也就是如果为true 就可以在原来的文件内容后面加上你写入的内容,如果为false 就直接先清空了之前的内容了,再写入了.
2.outputStream.write(97);这里写入的数字是 ascii
3.这里写入数据也可以不用一个一个的写入可以使用byte数组,一次性将数组内的数据写入到文件中.同时也一样可以精准控制,这里就不过多的介绍了.
3.使用字符流对文件内容操作
1.Reader的使用
1.read()方法
public static void main(String[] args) {try(Reader reader = new FileReader("hello.txt")) {while(true) {int n = reader.read();if(n == -1) {break;}char ch = (char) nSystem.out.println(ch);}}catch (IOException e) {e.printStackTrace();}}几个解释的地方
1.Reader reader = new FileReader("hello.txt")一样继承了closeable 接口可以使用try()的方法来自动关闭文件.
2.read()方法不同参数也一样可以一个一个字符的读取,也可以一个char数组的形式读取这里就不演示了

2.Writer的使用
1.writer
public static void main(String[] args) {try(Writer writer = new FileWriter("hello.txt",true)) {writer.write("你好CSDN");}catch (IOException e) {e.printStackTrace();}}和上述的内容没什么差别,就是write的参数不一样,根据实际情况选择相应的参数
二.根据文件IO操作和流操作的知识解决问题的案例
这里主要是通过三个案例来巩固一下文件IO和流操作的知识
1.案例一:
扫描指定目录,并找到名称中包含指定字符的所有普通文件(不包含目录).
public static void main(String[] args) {Scanner scanner = new Scanner(System.in);System.out.println("请输入要查找的目录的路径: ->");String rootPath = scanner.next();System.out.println("请输入你要查找的普通文件的单词: ->");String fileWord = scanner.next();File rootFile = new File(rootPath);if(!rootFile.isDirectory()) {System.out.println("路径非法请重新在输入");return;}search(rootFile,fileWord);}private static void search(File file,String str) {//列出当前的有哪些文件File[] files = file.listFiles();if(files == null) {return;}for(File f : files) {if(f.isFile()) {String fileName = f.getName();if(fileName.contains(str)) {System.out.println("找到了" + f.getAbsolutePath());}}else if(f.isDirectory()) {search(f,str);}}}主要逻辑
-
主方法(
main)启动时,通过Scanner类从控制台接收用户输入的两个参数:rootPath:指定需要搜索的目录路径。fileWord:用户想要在文件名中查找的特定单词。
-
创建一个
File对象rootFile,其路径为用户输入的rootPath。接着,检查rootFile是否为一个有效的目录。若不是,输出错误提示信息并直接结束程序运行。 -
若
rootFile确实是一个目录,调用私有方法search进行递归文件搜索。该方法接受两个参数:当前处理的目录(file)和待查找的单词(str)。 -
在
search方法内部,首先使用listFiles()获取当前目录下的所有文件及子目录(以File数组形式返回)。如果返回值为null,说明目录为空或无权限访问,此时直接返回。 -
遍历得到的
File数组,对于每个元素:- 如果是普通文件(
isFile()返回true),则提取其文件名,检查是否包含用户指定的str。如果包含,输出该文件的绝对路径,表示已找到匹配文件。 - 如果是目录(
isDirectory()返回true),则递归调用search方法,继续在该子目录中查找含有指定单词的文件。
- 如果是普通文件(
2.案例二:
public static void main(String[] args) {Scanner scanner = new Scanner(System.in);System.out.println("请输入你要复制的文件路径");String rootPath = scanner.next();System.out.println("请输入你要复制到那个文件的目标路径");String destPath = scanner.next();File rootFile = new File(rootPath);if(!rootFile.isFile()){System.out.println("复制的文件路径非法");return;}File destFile = new File(destPath);if(destFile.getParentFile().isDirectory()) {System.out.println("输入的复制目标路径非法");return;}try(InputStream inputStream = new FileInputStream(rootPath);OutputStream outputstream = new FileOutputStream(destPath)) {while (true) {byte[] bytes = new byte[1024];int n = inputStream.read(bytes);if(n == -1) {break;}outputstream.write(bytes,0,bytes.length);}}catch(IOException e) {e.printStackTrace();}}-
使用
Scanner类从控制台接收用户输入的两个路径:rootPath:用户要复制的源文件路径。destPath:用户指定的目标文件路径。
-
创建一个
File对象rootFile,其路径为用户输入的rootPath。接着,检查rootFile是否为一个有效的文件(非目录)。若不是,输出错误提示信息并直接结束程序运行。 -
同样创建一个
File对象destFile,其路径为用户输入的destPath。接下来,检查destFile的父目录是否存在且为目录。若不符合条件(即父目录不存在或非目录),输出错误提示信息并返回。 -
使用
try-catch结构处理可能出现的IOException。在try块内,创建InputStream(inputStream)和OutputStream(outputstream)对象分别用于读取源文件和写入目标文件。这里使用FileInputStream和FileOutputStream构造函数传入对应的路径。 -
使用无限循环(
while (true))逐块读取源文件内容并写入目标文件。每次读取1024字节(byte[] bytes = new byte[1024];),通过inputStream.read(bytes)方法读取数据并返回实际读取的字节数(n)。 -
将读取的数据块写入目标文件:
outputstream.write(bytes, 0,n);将读取的数据写入到要复制的目标文件中 -
如果n = -1 就代表以读取完成,退出循环
3.案例三:
扫描指定⽬录,并找到名称或者内容中包含指定字符的所有普通⽂件
public static void main(String[] args) {Scanner scanner = new Scanner(System.in);System.out.println("请输入要查找的目录的路径: ->");String rootPath = scanner.next();System.out.println("请输入要查询的单词: ->");String fileWord = scanner.next();File rootFile = new File(rootPath);if(!rootFile.isDirectory()) {System.out.println("路径非法请重新在输入");return;}search(rootFile,fileWord);}private static void search(File file,String str) {//列出当前的有哪些文件File[] files = file.listFiles();if(files == null) {return;}for(File f : files) {if(f.isFile()) {machWord(f,str);}else if(f.isDirectory()) {search(f,str);}}}private static void machWord(File f,String str) {try(Reader reader = new FileReader(f)) {StringBuilder ret = new StringBuilder();while(true) {int n = reader.read();if(n == -1) {break;}ret.append((char) n);}if(ret.indexOf(str) >= 0) {System.out.println("找到了" + f.getAbsolutePath());}}catch (IOException e) {e.printStackTrace();}}-
主方法(
main)启动时,通过Scanner类从控制台接收用户输入的两个参数:rootPath:指定需要搜索的目录路径。fileWord:用户想要在文件内容中查找的特定单词。
-
创建一个
File对象rootFile,其路径为用户输入的rootPath。接着,检查rootFile是否为一个有效的目录。若不是,输出错误提示信息并直接结束程序运行。 -
若
rootFile确实是一个目录,调用私有方法search进行递归文件搜索。该方法接受两个参数:当前处理的目录(file)和待查找的单词(str)。 -
在
search方法内部,首先使用listFiles()获取当前目录下的所有文件及子目录(以File数组形式返回)。如果返回值为null,说明目录为空或无权限访问,此时直接返回。 -
遍历得到的
File数组,对于每个元素:- 如果是普通文件(
isFile()返回true),则调用machWord方法检查该文件内容是否包含用户指定的str。 - 如果是目录(
isDirectory()返回true),则递归调用search方法,继续在该子目录中查找含有指定单词的文件。
- 如果是普通文件(
-
私有方法
machWord负责检查单个文件内容是否包含查询单词。具体步骤如下:- 使用
FileReader创建一个Reader对象,用于读取文件内容。 - 初始化一个
StringBuilder对象ret,用于存储文件内容。 - 使用无限循环(
while(true))逐字符读取文件内容。当reader.read()返回-1时,表明已到达文件末尾,此时跳出循环。 - 将读取的字符追加到
ret中。 - 检查
ret中的字符串是否包含查询单词str。如果包含,输出该文件的绝对路径,表示已找到匹配文件。 - 使用
try-catch结构捕获并打印可能抛出的IOException。
- 使用
感谢你的阅读,祝你一天愉快!