一、数据字段类型
数据类型 :LanguageManual Types - Apache Hive - Apache Software Foundation
-
基本数据类型
-
数值相关类型
-
整数
-
tinyint
-
smallint
-
int
-
bigint
-
-
小数
-
float
-
double
-
decimal 精度最高
-
-
-
日期类型
-
date 日期
-
timestamps 日期时间
-
-
字符串类型
-
string
-
varchar
-
char
-
-
布尔类型
-
BOOLEAN 表示真假 只能存储0或1
-
-
-
复杂类型
-
array 数组类型
-
[1,2,3]
-
['a','b','c']
-
-
map
-
{key:value}
-
-
-- hive中的数据类型演示
use itcast;
-- 创建表
create table tb_test(id tinyint comment 'id值',age smallint comment '年龄',phone int comment '手机号',name varchar(20),gender string,weight decimal(10,2),create_time timestamp,hobby array<string> comment '兴趣爱好', -- [数据1] arrary<数组中的数据类型>hero map<string,int> comment '游戏英雄' -- {key:value} 指定key值类型,指定value值类型
)comment '数据类型测试表';
-- 写入数据进行类型测试
insert into tb_test values(1,20,13711111111,'张三','男',180.21,'2020-10-01 10:10:10',array('篮球','足球'),map('关羽',80,'小乔',60));
insert into tb_test values(2000,20,13711111111,'张三','男',1800.21,'2020-10-01 10:10:10',array('篮球','足球'),map('关羽',80,'小乔',60));
select * from tb_test;
select hobby[1] from tb_test;
select hero['关羽'] from tb_test;
二、分隔符指定
对hdfs上的文件数据存储时的分割符进行指定
hive在将行数据存储在hdfs上时,默认字段之间的数据分隔符 \001
在创建表时可以指定分割符
row format delimited fields terminated by '分割符'
create table tb_row_field (id int,name string,age int,gender string ) row format delimited fields terminated by ','; -- 指定分隔符 固定格式 insert into tb_row_field values(1,'aa',20,'男');
三、表的修改
名字修改,字段名修改,字段类型修改
alter 关键字
alter table 表名 rename to 新的表名 alter table 表名 add columns(字段名 字段类型) alter table 表名 change 旧字段名 新字段 字段类型 alter table 表名 set 属性设置
-- 表的修改修改操作
create table tb_ddl(id int,name string,age int,gender string
);
desc formatted tb_ddl2;
-- 修改表名
alter table tb_ddl rename to tb_ddl2;
-- 增加字段
alter table tb_ddl2 add columns(phone string);
-- 修改字段
alter table tb_ddl2 change id id bigint;
desc tb_ddl2;
-- 修改字段类型是,只能将小字节的类型修改为大字节的类型
-- alter table tb_ddl2 change id id int;
-- 修改表属性
alter table tb_ddl2 set tblproperties('age12'='20');
desc formatted tb_ddl2;
-- hdfs://node1:8020/user/hive/warehouse/itcast.db/tb_ddl2
alter table tb_ddl2 set location 'hdfs://node1:8020/tb_ddl2';
desc formatted tb_ddl2;
insert into tb_ddl2 values(1,'aa',20,'ccc','123123123');
alter table tb_ddl2 add columns(create_time date comment '创建时间',price decimal(10,2));
desc tb_ddl2;
alter table tb_ddl2 change age age1 string after phone;
desc tb_ddl2;
alter table tb_ddl2 change age1 age double after id;
desc tb_ddl2;
四、表的删除
-- 表删除 会删除表的目录和表的元数据信息 drop table tb_ddl2; select * from tb_ddl2; -- 表清空数据 把存储数据的文件一并删除 select * from tb_row_field; truncate table tb_row_field;
五、表的分类
内部表 Managed Tabel
外部表 External Tables
区别:
在删除表时,
内部表会把表的所有数据删除(元数据和行数据)
外部表会把表的元数据删除,保留hdfs上的文件数据
默认创建的表都是内部表
创建外部表需要使用关键字External
create external table 表名(字段 字段类型 )
-- 创建内部表 create table tb_managed(id int,name string ); -- 创建外部表 create external table tb_external(id int,name string ); desc formatted tb_managed; desc formatted tb_external; drop table tb_managed; drop table tb_external;
-- 修改表的类型
desc formatted tb_managed;
alter table tb_managed set tblproperties('EXTERNAL'='TRUE'); -- 设置为外部表
alter table tb_managed set tblproperties('EXTERNAL'='FALSE');-- 设置为内部表
六、表数据写入
在对表数据写入时有两张方式
方式一 直接将数据文件上传到指定的表目录下
方式二 通过insert将数据写入的表目录的文件中
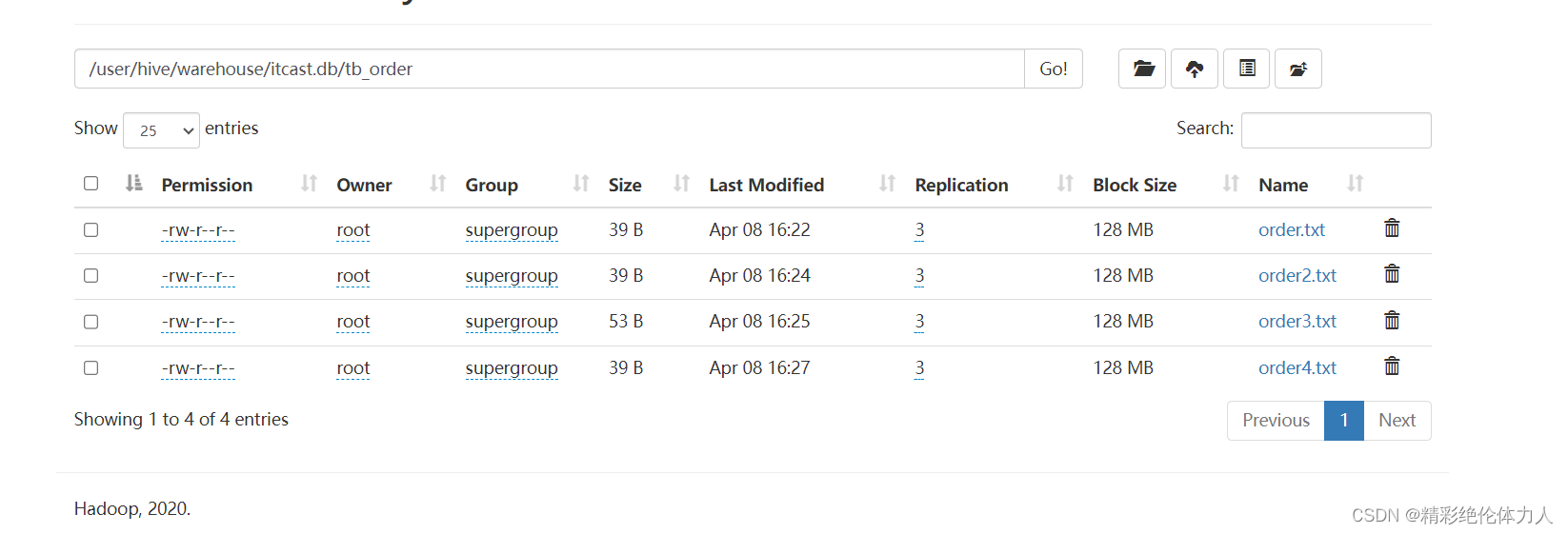
6-1 方式一 将数据文件上传到对应的表目录下
-
可以使用hdfs上传
-
可以使用hivesql的load语句上传
-
hive运行的位置就文件上传的位置
-
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] -- filepath 指定本地服务器的数据文件位置 ,本地指的是hive运行的服务器
-- 使用load语句将文件数据上传表中 -- file:// 是本地文件的路径协议,是一个固定写法 load data local inpath 'file:///root/order5.txt' into table tb_order; -- 覆盖上传文件 load data local inpath 'file:///root/order5.txt' overwrite into table tb_order;
6-2 方式2 使用insert指定数据导入
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement; INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;
insert into tb_order values (1,123.23,5,'北京'); insert overwrite table tb_order values (2,123.23,5,'上海'); -- 写入数据是在values中指定 -- 也可以将一个select 查询结果写到表中 create table tb_order_new(id int,total_price decimal(10,2),total_number int,address string )row format delimited fields terminated by ','; insert into tb_order_new select * from tb_order; -- 通过该方式可以实现计算结果的保存 create table tb_result(cnt int comment '总数' ); insert into tb_result select count(*) from tb_order; select * from tb_result;
6-3 将表数据导出到服务器
insert overwrite local directory 'file:///root/data' row format delimited fields terminated by ',' select * from tb_order;
七、表的分区
在公司会产生大量数据,数据存储在hdfs上时,需要对数据进行拆分,在进行数据查询时就可以快速查询到需要的内容
如果需要进行数据的分区操作,就需要再建表的时候指定分区字段
-- 创建分区表 create table tb_user_partiton(id int,name string,age int,create_time date )partitioned by(gender int)row format delimited fields terminated by ','; -- 静态分区数据写入 -- 手动指定分区数据 insert into tb_user_partiton partition(gender=0) values(1,'张三',20,'2024-10-10 14:21:21'); -- 动态分区数据写入,可以根据select中指定的字段数据最为分区的依据 -- 需要进行设置开启 set hive.exec.dynamic.partition.mode=nonstrict; insert into tb_user_partiton partition(gender) select id,name,age,create_time,gender from tb_user; -- 多层分区 create table tb_user_partiton_many(id int,name string,age int,gender int,create_time date )partitioned by (y string,m string,d string)row format delimited fields terminated by ','; insert into tb_user_partiton_many partition(y,m,d) select id,name,age,gender,create_time,year(create_time),month(create_time),day(create_time) from tb_user limit 100; select * from tb_user_partiton_many where y=2015 and m=10;
![[Algorithm][链表][两数相加][两两交换链表中的节点][重排链表][合并K个升序链表][K个一组翻转链表] + 链表原理 详细讲解](https://img-blog.csdnimg.cn/direct/be48d7e25fb04aaba0863d1b0abda4b5.png)