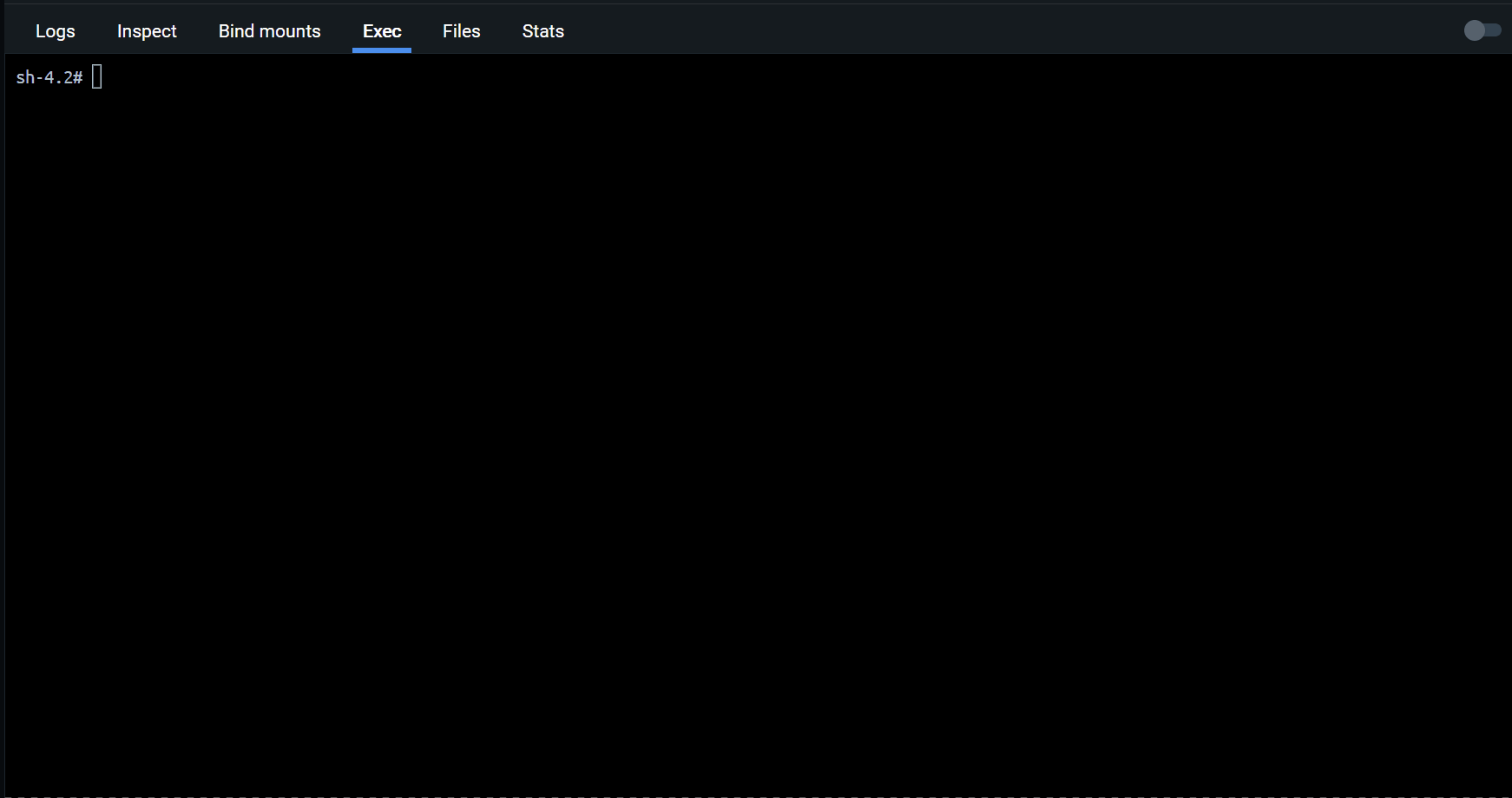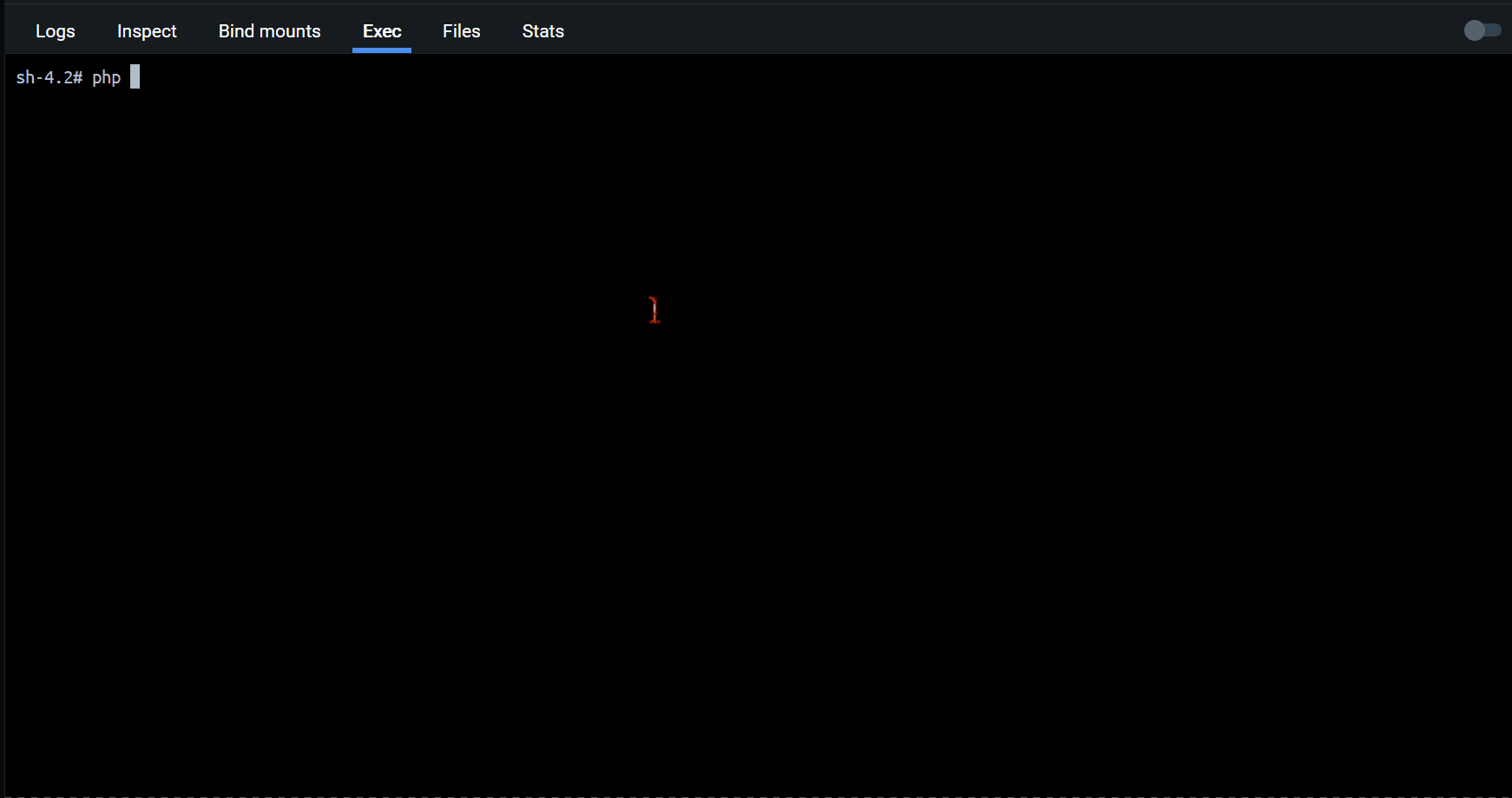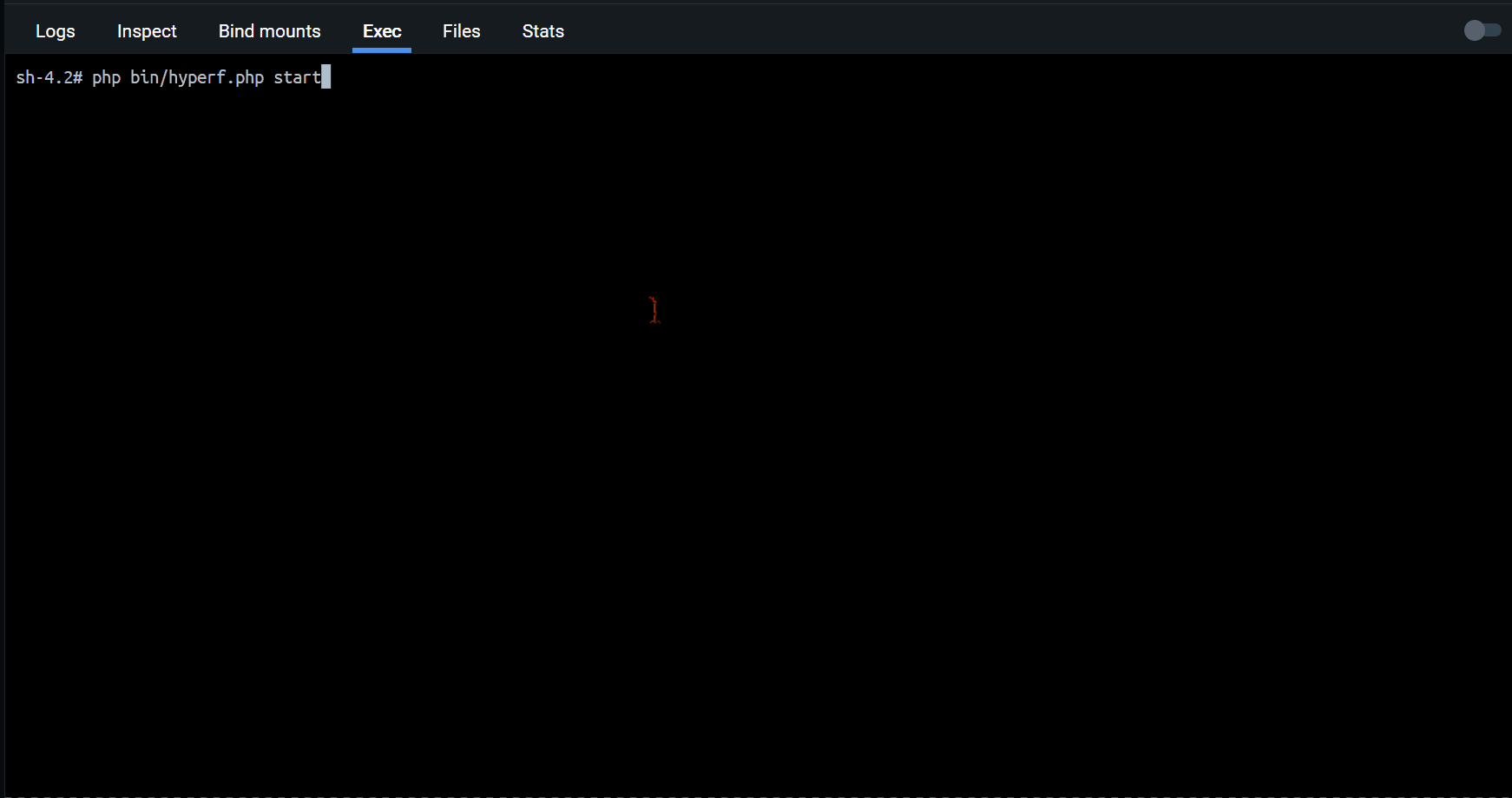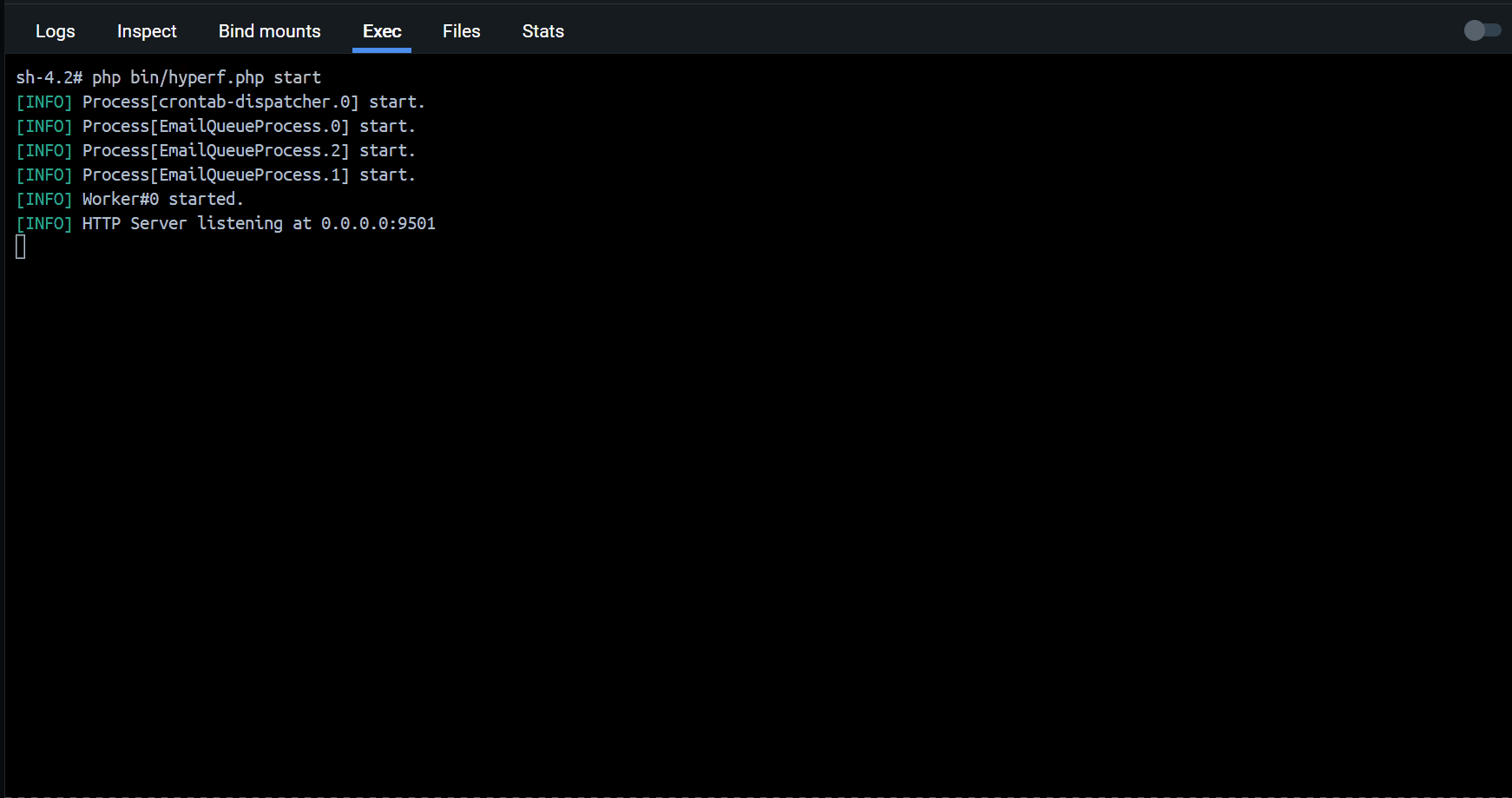
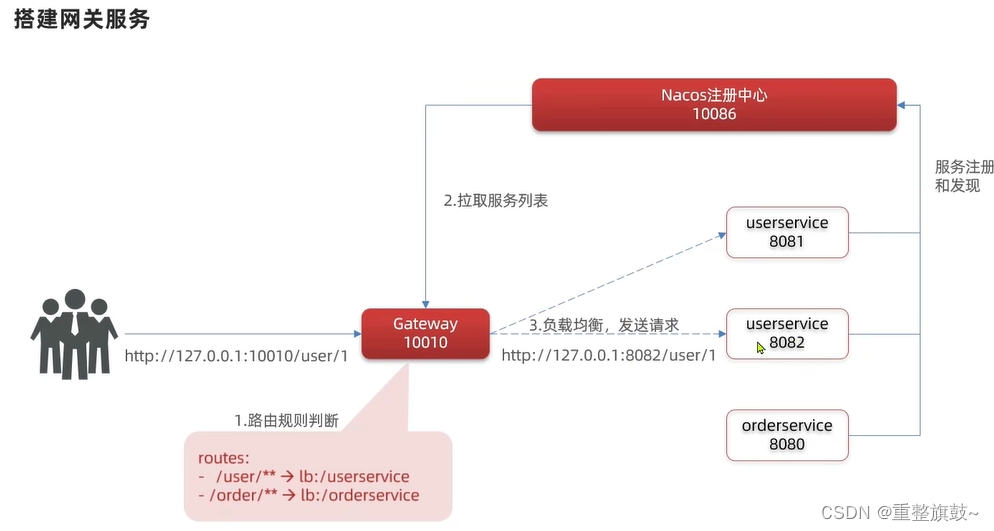
MySQL 简介
学习路径
MySQL 安装
-
卸载预安装的mariadb
rpm -qa | grep mariadb rpm -e --nodeps mariadb-libs -
安装网络工具
yum -y install net-tools yum -y install libaio -
下载rpm-bundle.tar安装包,并解压,使用rpm进行安装
rpm -ivh \ mysql-community-common-5.7.28-1.el7.x86_64.rpm \ mysql-community-libs-5.7.28-1.el7.x86_64.rpm \ mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpm \ mysql-community-server-5.7.28-1.el7.x86_64.rpm -
初始化mysql
mysqld --initialize -
更改所属组
chown mysql:mysql /var/lib/mysql -R -
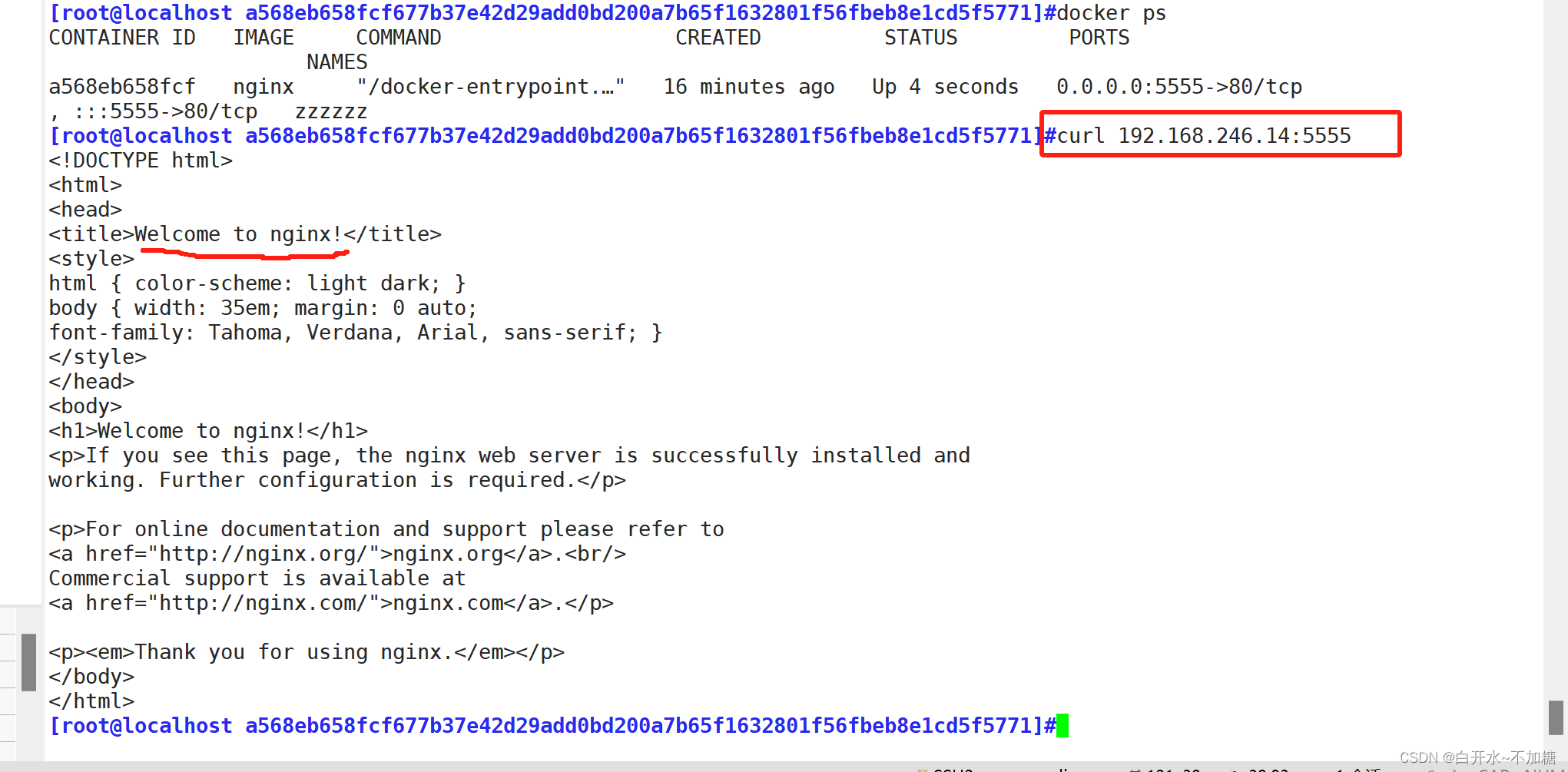
启动 MySQL 服务
systemctl start mysqld.service -
查看生成的初始密码
cat /var/log/mysqld.log | grep password -
登录 MySQL,修改密码并设置允许远程访问
# 修改密码 alter user user() identified by "root";# 设置允许远程访问 use mysql; grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option; flush privileges; -
设置 MySQL 服务开机自启动
systemctl enable mysqld -
查看开机自启动是否设置成功
-
退出 MySQL 服务
systemctl stop mysqld.service
启动mysql
-
启动mysql服务
service mysql start 或 systemctl start mysqld.service -
查看mysql的初始密码
grep "password" /var/log/mysqld.log -
登录数据库
mysql -uroot -p -
修改mysql的默认密码
说明 新密码设置的时候如果设置的过于简单会报错,必须同时包含大小写英文字母、数字和特殊符号中的三类字符。
ALTER USER 'root'@'localhost' IDENTIFIED BY '123456'; -
执行如下命令,创建wordpress库
create database wordpress; -
查看是否创建成功
show database -
输入
exit退出数据库
修改MySQL配置文件(拷贝一份,不修改原配置文件)
cp my-huge.cnf /etc/my.cnf #5.5版本
cp my-default.cnf /etc/my.cnf #5.6版本配置文件名称不一样
如果先建表, 再配置文件改为utf-8, 还是会导致乱码
配置文件介绍
-
二进制日志文件log-bin(主从复制)
-
错误日志log-error
默认是关闭, 记录严重的警告和错误信息, 每次启动和关闭的详细信息 -
查询日志log
默认关闭, 记录查询的sql语句,如果开启会降低mysql的整体性能,
-
数据文件
myi文件(存放表索引)
myd文件(存放表数据)myfrm(存放表结构)
-
配置文件路径(linux下是在/etc/my.cnf, 而windows下是my.ini)
基础篇
行式数据库和列式数据库
-
OLAP分析型数据库(列式数据库,数据分析)
计算均值,比较大小,求最大最小值等分析数据的时候速度快,是将一个属性的数据存储到一起。只有取出所有的属性值之后才得到某一个对象的整体信息
-
OLTP事务型数据库(行式数据库,增删改查)
将一个个对象作为存储的单位,在取出一个对象的所有信息的时候速度快。只有当去除所有的对象的属性值之后才能对数据进行求均值,比大小等等
SQL
SQL分类
-
DDL(Data Definition Language,数据定义语言)
用来定义数据库对象:数据库、表、字段
-
DML(Data Manipulation Language,数据操作语言)
用来对表中的数据进行增删改操作
-
DQL(Data Query Language,数据查询语言)
用来对表中的数据进行查询操作
-
DCL(Data Control Language,数据控制语言)
用来创建数据库用户、控制数据库的访问权限
DDL 数据定义语言
-
增(创建数据库)
CREATE DATABASE [IF NOT EXISTS] <数据库名> [DEFAULT CHARSET <字符集>] [COLLATE <排序规则>]; -
删(删除数据库)
DROP DATABASE [IF EXISTS] <数据库名> -
查(查询数据库)
查询所有数据库:
SHOW DATABASES;查询当前数据库:
SELECT DATABASE(); -
使用
USE <数据库名>;
####################################
# 1. 创建
####################################
# 1.1 创建数据库(增)
CREATE DATABASEIF NOT EXISTS `ddl`;USE `ddl`;# 1.2 创建数据表
CREATE TABLEIF NOT EXISTS `user`
(#字段 字段类型 注释id INTCOMMENT 'id主键',name VARCHAR(10)COMMENT '姓名',age TINYINT UNSIGNEDCOMMENT '年龄',gender TINYINTCOMMENT '性别',PRIMARY KEY (id)
)COMMENT '用户表';####################################
# 3. 查询
####################################
# 3.1 查询数据库
# 3.1.1 查询所有的数据库
SHOW DATABASES;
# 3.1.2 查看当前使用的数据库
SELECT DATABASE();# 3.2 查询表
# 3.2.1 查询当前数据库中的所有表
SHOW TABLES;
# 3.2.2 查看特定的表的详细信息
DESC `user`;
# 3.2.3 查看特定表的建表语句
SHOW CREATE TABLE `user`;####################################
# 4. 删除
####################################
DROP DATABASE IF EXISTS `ddl`;
DML 数据操作语言

DQL 数据查询语言

DCL 数据控制语言
在 MySQL 中,用户及用户权限信息都保存在 mysql.user 表中,通过对该表的操作即可实现对用户权限的控制管理了。
用户名和主机名两个字段才能唯一标识一个用户,主机名表示该用户可以在哪些主机上访问,如果是 localhost 则表示不可以远程访问,如果是 % 则表示任意主机均可以访问。
用户管理

-
查询用户
USE `mysql`;SELECT * FROM user; -
创建用户
CREATE USER '<用户名>'@'<主机名>' IDENTIFIED BY '<密码>'; -
修改用户密码
ALTER USER '<用户名>'@'<主机名>' IDENTIFIED WITH mysql_native_password BY '<新密码>'; -
删除用户
DROP USER '<用户名>'@'<主机名>';
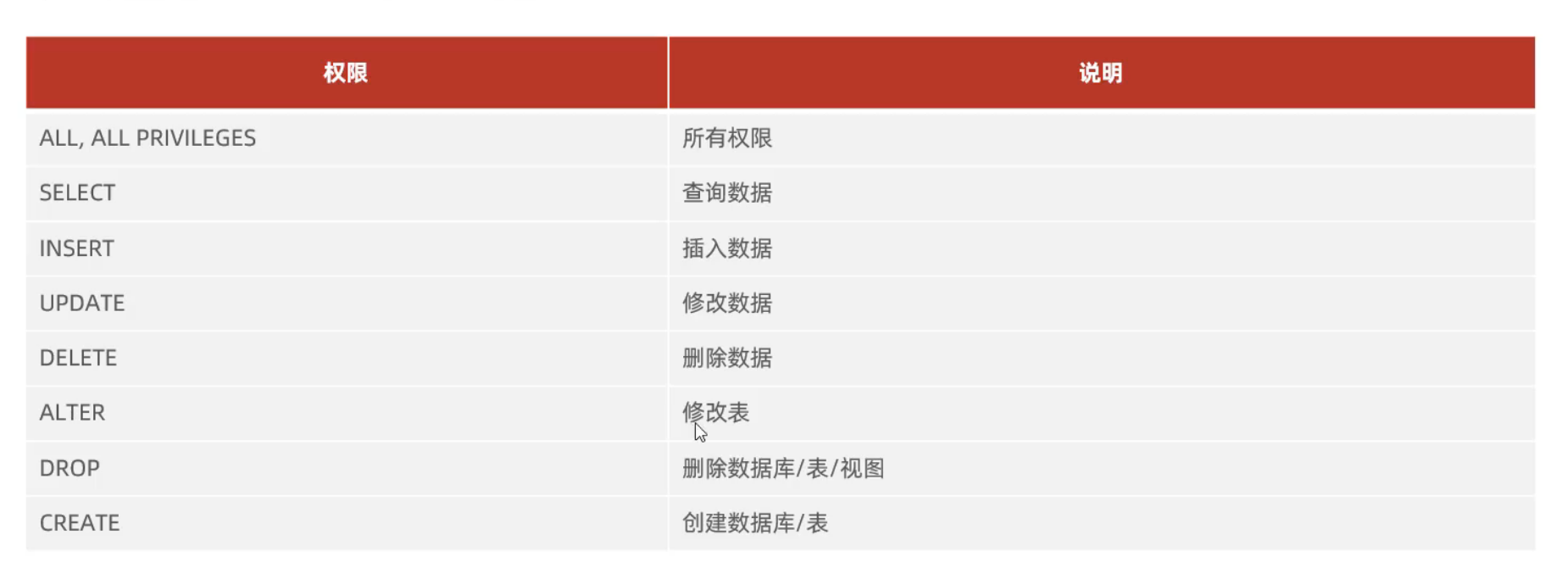
权限控制
-
查询用户拥有的权限
SHOW GRANTS FOR '<用户名>'@'<主机名>'; -
授予用户某种权限(增)
如果需要为所有的数据库和所有的表授予权限,那么需要使用
*.*GRANT <权限列表> ON <数据库名.表名> TO '<用户名>'@'<主机名>'; -
撤销用户某种权限(删)
REVOKE <权限列表> ON <数据库名.表名> FROM '<用户名>'@'<主机名>';
函数

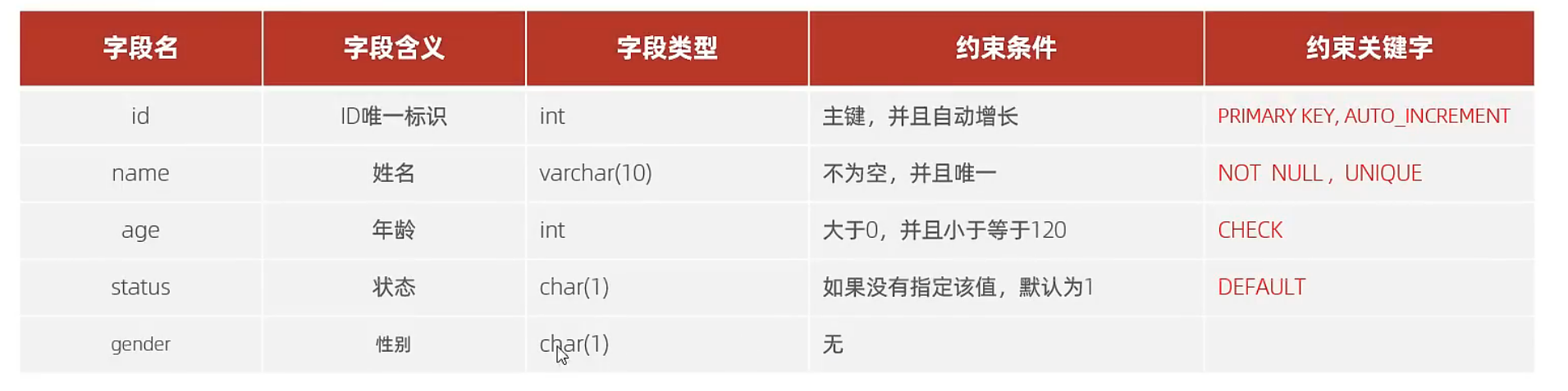
约束

事务
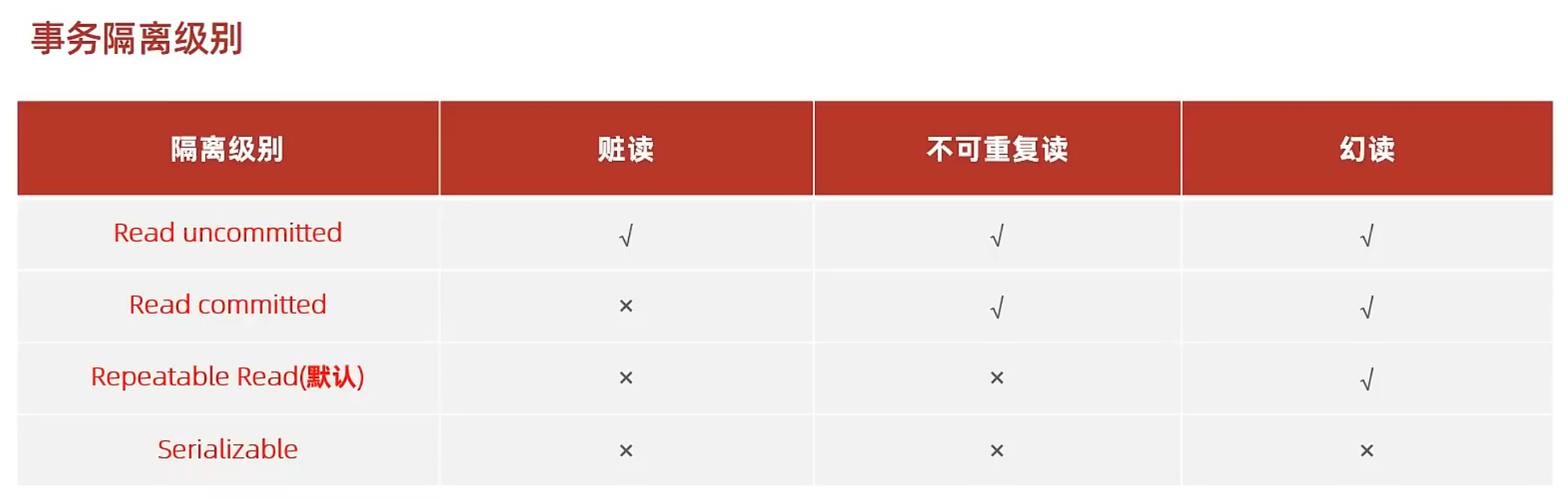
隔离级别
设置不同的事务隔离级别这种功能的底层原理是什么?如何实现的?是对修改后的数据写入磁盘文件的时间点决定的吗?例如,读未提交级别,则事务中执行的修改操作都会立即写入磁盘,此时其它事务就可能在该事务提交前感知到这个修改操作,因此出现脏读问题?
-
脏读问题:
事务A中读取到事务B中未提交的数据。具体来说,在t1时刻,事务A中读取到事务B中未提交的数据,并将该数据用于计算得到一个结果值;而在t2时刻,事务B执行回滚,那么事务A中得到的结果值就没有任何意义,这种现象就称为脏读。
-
不可重复读:
事务A在一次事务的执行过程中,两次读取结果不相同。具体来说,在t1时刻,事务A读取数据x1;在t2时刻,事务B将数据修改为x2并提交事务;在t3时刻,事务A再次读取数据得到x2;站在事务A的角度,可能在t1时刻到t3时刻并没有对数据进行修改,却得到两个不同的值(都是正确值),这种现象称为不可重复读。
-
幻读:
解决了不可重复读的问题,即在一次事务中,可以保证对数据的两次读取的结果是相同的。但是会出现幻读的问题。幻读问题是指事务A在查询时明明没有查到该数据,但是却无法插入成功。具体来说,在t1时刻,事务A查询是否有id=1的数据,发现没有;在t2时刻,事务B插入一条id=1的数据并提交;在t3时刻,事务A再次查询是否有id=1的数据,还是发现没有(因为可重复读),因此事务A打算插入一条id=1的数据,但是此时插入失败并报错,这时事务A就会纳闷,明明查询id=1的结果是没有,但是插入又报错说id=1的数据已经存在,这种现象称为幻读。
三个问题,对应四种方案,分别是解决0个问题(读未提交)、解决1个问题(读已提交)、解决2个问题(可重复读)、解决3个问题(串行化)。
串行是一切并行问题的终点,没有并行就不会有并行导致的伴生问题
SELECT @@autocommit;# 关闭自动提交(开启事务)
SET @@autocommit=0;# 提交事务
COMMIT;# 回滚事务
ROLLBACK;# 查看事务的隔离级别
SELECT @@TRANSACTION_ISOLATION;# 设置事务的隔离级别
SET [SESSION|GLOBAL] TRANSACTION ISOLATION LEVEL {READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE}
进阶篇
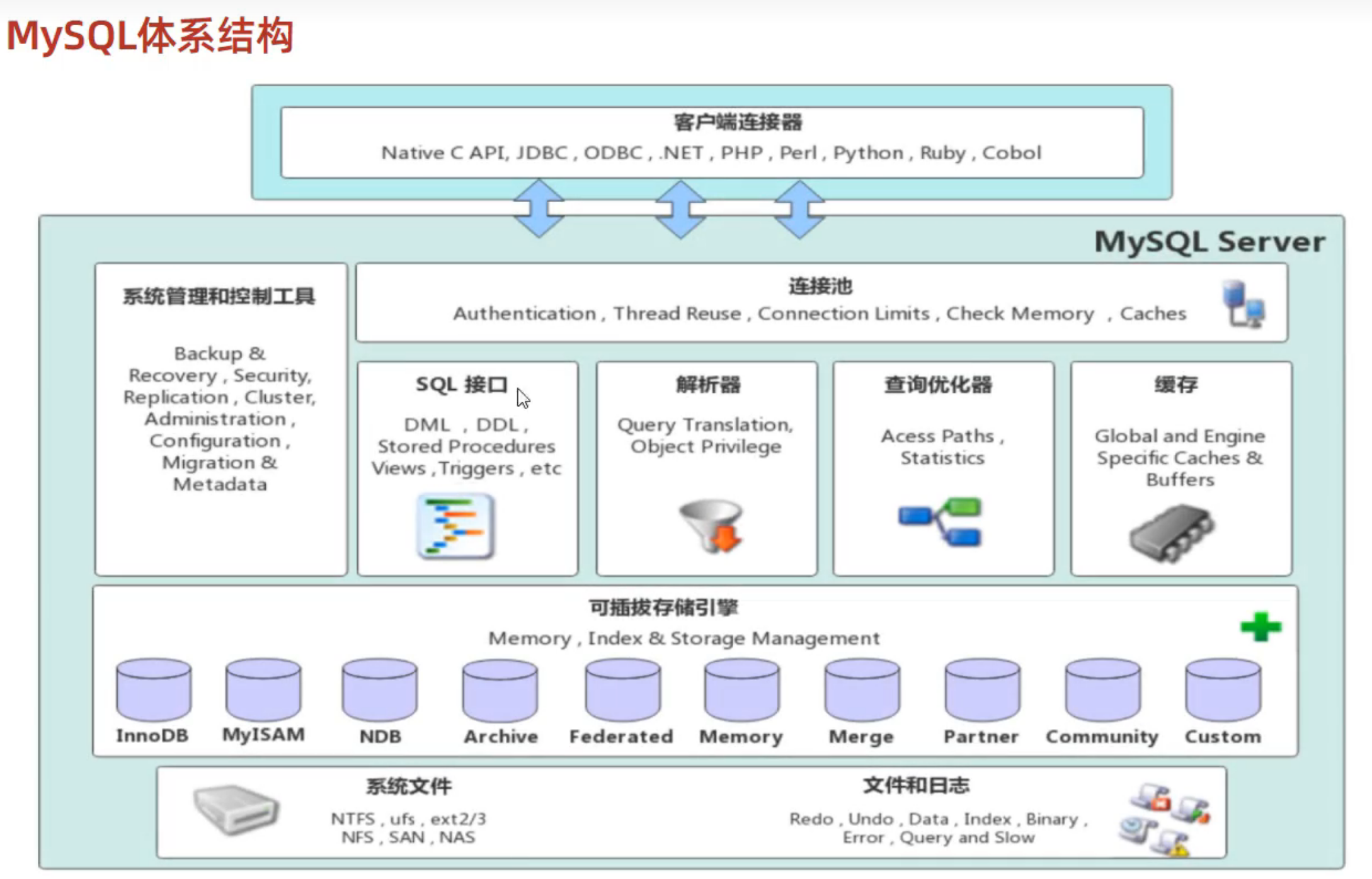
- 连接层
- 服务层
- 存储引擎层(索引、表级别)
- 存储层
存储引擎
不同的存储引擎有着不同的使用场景,各有优缺点。存储引擎就是存储数据、建立索引、更新、查询数据等技术的实现方式。存储引擎是基于表的,不是基于库的,因此存储引擎又被称为表类型。
SHOW ENGINES;

InnoDB 引擎
特点
- DML 操作遵循 ACID 模型,支持事务;
- 支持行级锁,相较于表锁而言可以提高并发访问性能
- 支持外键约束,保证数据的完整性
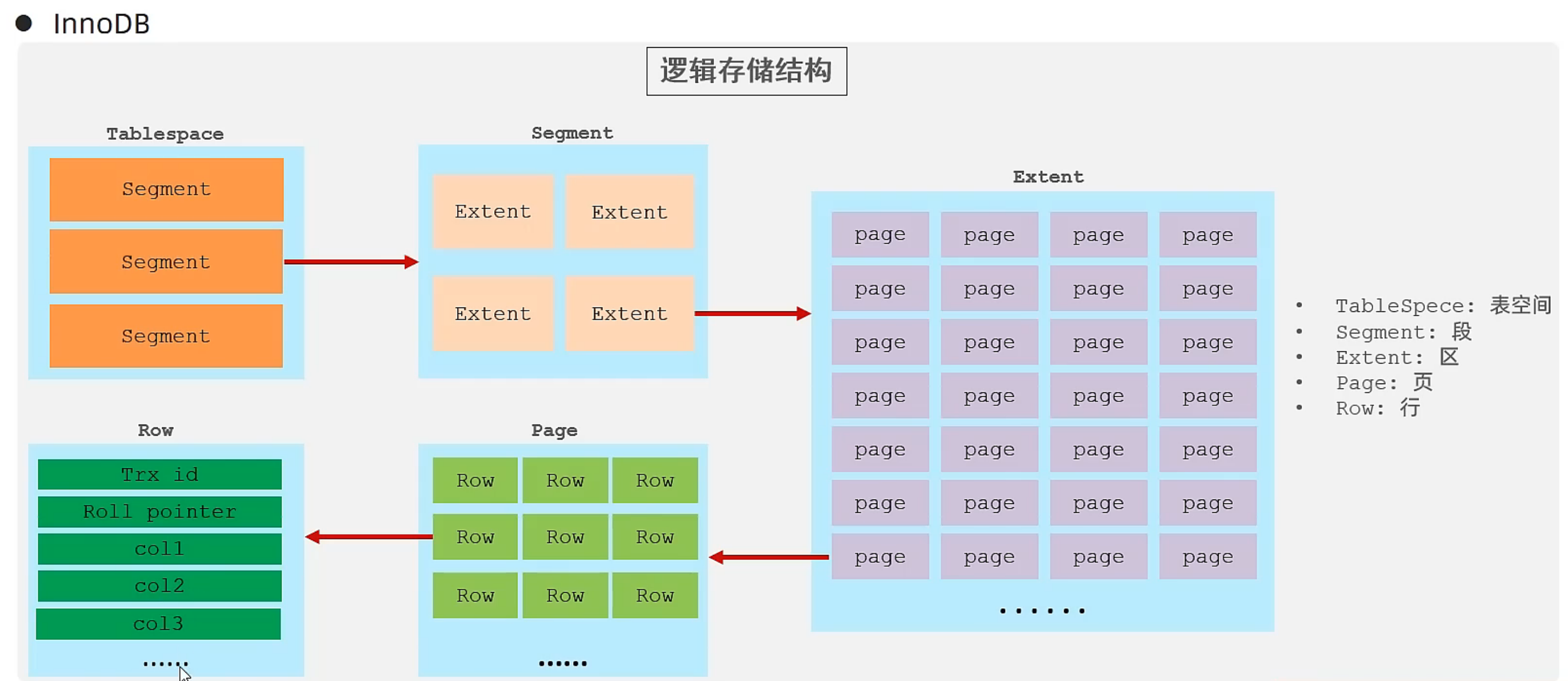
- xxx.idb:xxx代表表名,InnoDB引擎的每张表都会对应一个表空间文件(TableSpace),存储该表的表结构(frm、sdi)、数据和索引。
逻辑存储结构
MyISAM 引擎(可被MongoDB替代)
特点
- 不支持事务、不支持外键、不支持行级锁
- 支持表锁
- 访问速度快
- xxx.sdi:存储表结构信息(本质上是一个JSON文本数据)
- xxx.MYD:存储数据
- xxx.MYI:存储索引
Memory 引擎(可被Redis替代)
特点
- 表数据信息存储在内存中,会受到断电等问题的影响,因此这些表只适合用于作为临时表或缓存表
- 支持hash索引(默认)
- xxx.sdi:表结构信息(Memory 引擎只会有这一个文件,因为数据保存在内存中)
索引
提高了查询速度,但同时提高了增删改的成本,因为需要维护B+树这种数据结构
不需要建立索引的情况
- 表记录太少的时候
- 经常增删改的表
- 某个数据列包含许多重复的内容,那这个表字段就没有必要建立索引
索引结构
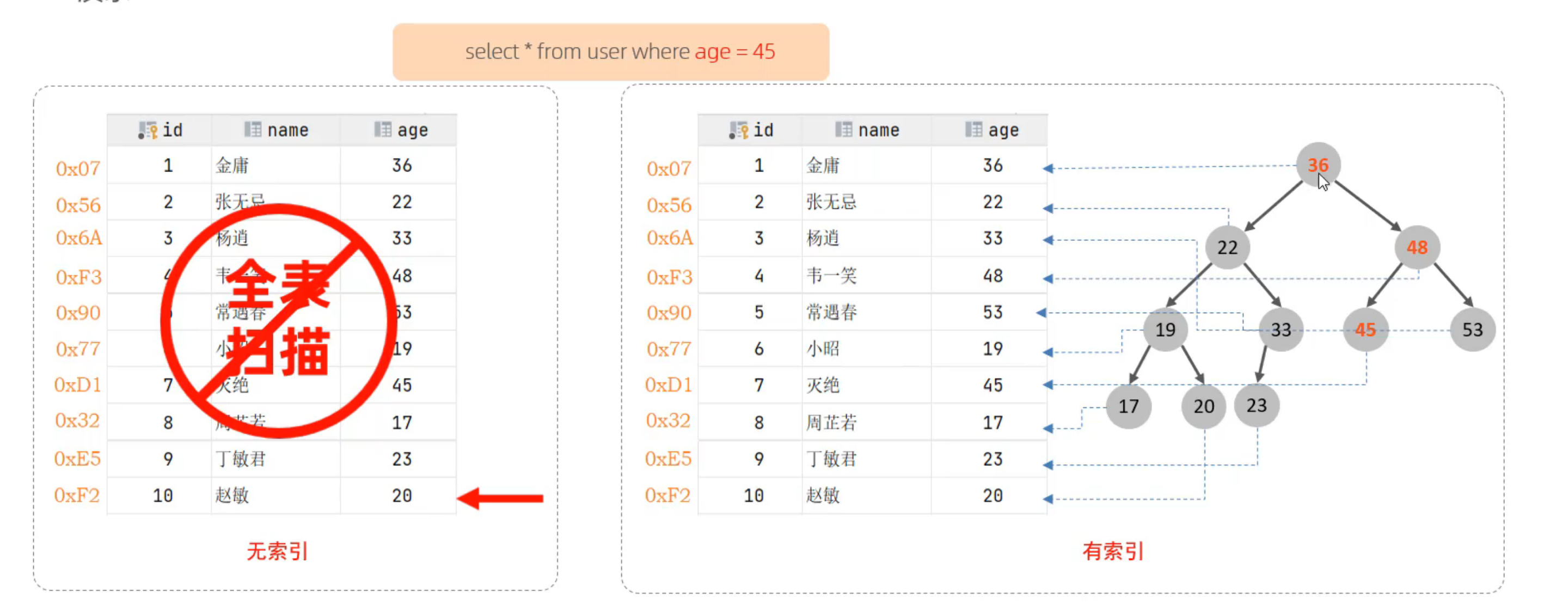
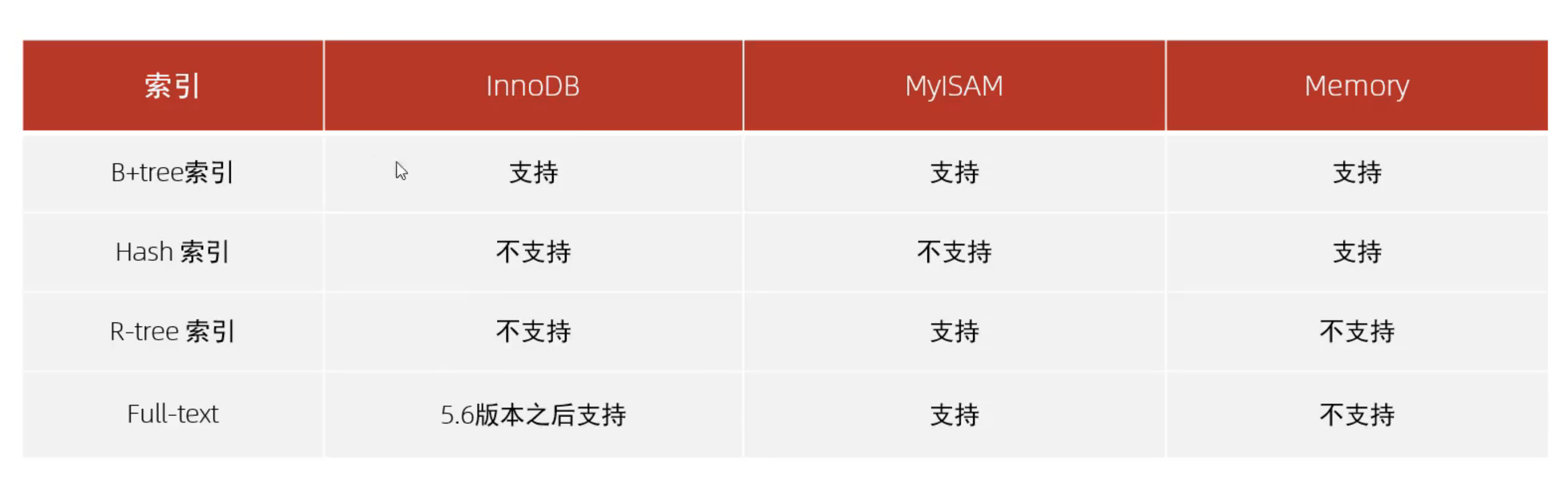
一张表对应一种存储引擎,而存储引擎之间可能使用相同或不同的索引。那如果使用相同索引的不同存储引擎之间有区别吗?还是可以认为存储引擎只是不同索引的集合,而如果两个不同的存储引擎使用相同的索引,则效果完全相同呢?暂时把索引和存储引擎的关系理解成接口和实现类的关系,即使是使用相同的索引结构,不同存储引擎对于该索引结构的实现和优化可能是不同的。这种区别应该只局限于效率,应该不会有功能上的不同。
InnoDB 存储引擎虽然不支持 hash 索引,但是具有 自适应hash 的功能,即根据 B+ Tree 索引在指定条件下自动构建 hash 索引。
面试题:为什么 MySQL 索引采用 B+ Tree,而不使用 RB Tree 或 B Tree?
- B+ Tree 和 B Tree 是一种多叉平衡树,相较于二叉树和RB Tree而言,每层节点数更多,因此树的高度会更少,搜索效率会更高些。
- B+ Tree 和 B Tree 相比,由于在非叶子结点上不存储数据,因此一个页面能够存放更多的索引,即用更少的页面就能够完全保存索引,搜索效率也会更高些。(假设用B Tree保存,那1个页面保存2条索引;而用B+ Tree保存,一个页面保存200条索引,显然保存20000条索引,B Tree需要10000个页面,而B+ Tree树只需要100个页面)
索引分类

聚集索引(唯一)
聚集索引的选取规则:
- 如果存在主键,那主键索引就是聚集索引
- 如果不存在主键,那第一个unique索引是聚集索引
- 如果上面两种索引都不存在,那么InnoDB存储引擎会自动生成一个rowid作为隐藏的聚集索引。

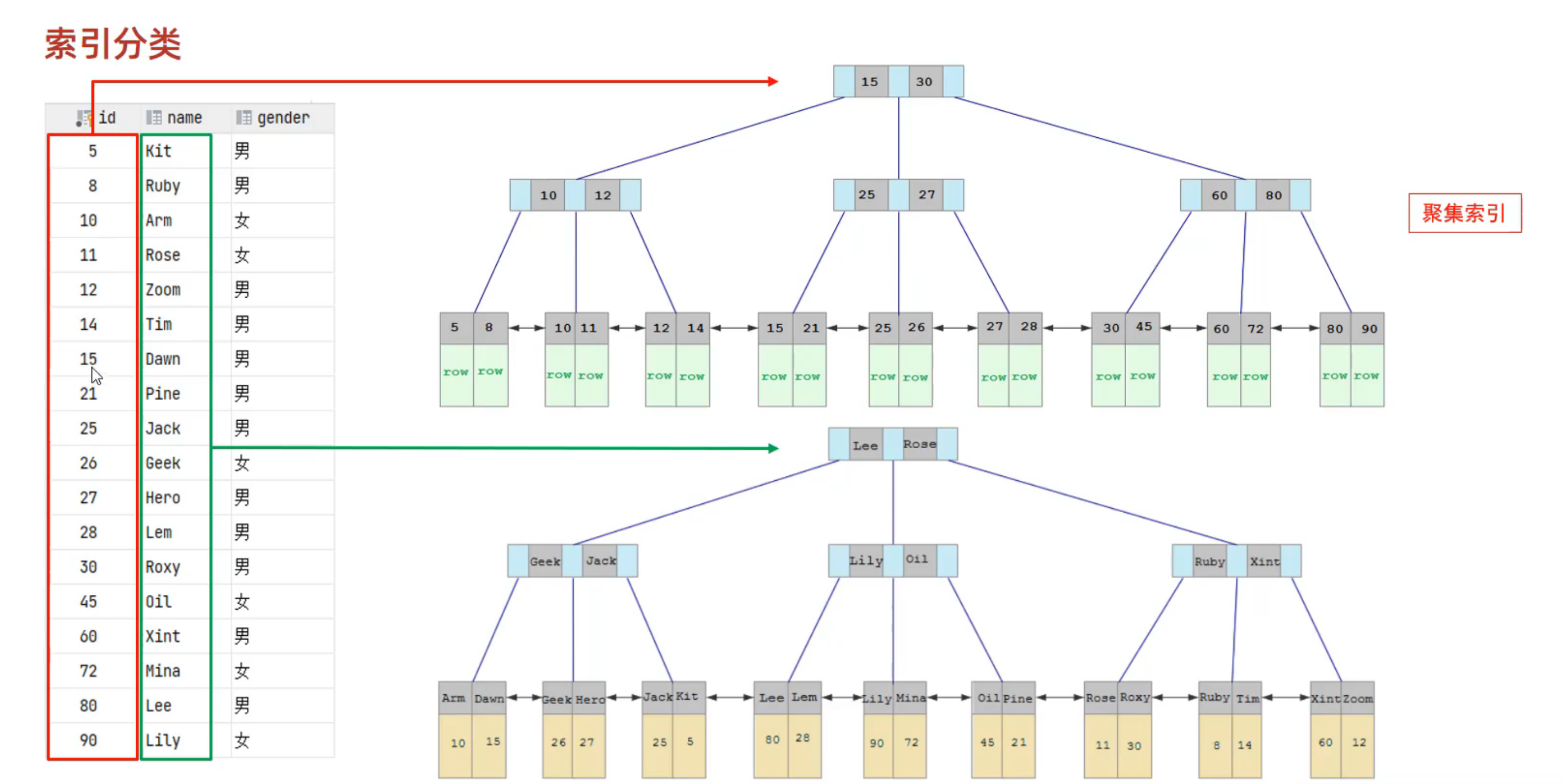
对于非主键字段上建立的索引,同样按照 B+ Tree 的结构去建立索引,但是在叶子结点上保存的不是数据,而是聚集索引(Clustered Index)中节点的id。而只有在聚集索引中,叶子结点上才保存这一行的所有数据。
查询案例:使用
SELECT * FROM user WHERE name='root';这条 SQL 语句进行查询,其中在 user.name 字段上已经建立了索引。展示通过二级索引来查询数据的过程,这个过程也称为回表查询。现在二级索引树中查到id,然后在聚集索引树中查询。二级索引也称为辅助索引。
索引语法
-
创建索引
CREATE [UNIQUE | FULLTEXT] INDEX <索引名> ON <表名>(<列名1>, <列名2>...);注:普通索引不添加
UNIQUE和FULLTEXT即可创建 -
查看索引
SHOW INDEX FROM <表名>; -
删除索引
DROP INDEX <索引名> ON <表名>;
SQL 性能分析(重点)
SQL 优化主要是优化查询操作,要进行 SQL 优化,需要先对数据库的特点进行分析。优化不是拍脑袋,而是以事实为依据。
查看 SQL 执行频率
SHOW [GLOBAL|SESSION] STATUS LIKE 'Com_______';# 每个下划线"_"代表一个字符, 为什么非得是7个下划线呢? 有什么含义吗?
# 目前来看, 返回结果会是Com_update、Com_insert, 正好每一个操作都是6个字符
# session表示查看当前会话的状态信息
慢查询日志
在确定了哪些查询操作占比大的数据库之后,可以通过慢查询日志来定位哪些 SQL 操作耗费时间。
在Linux系统中,慢查询日志文件的文件地址为 /var/lib/mysql/localhost-slow.log,可以通过tail -f命令来实时监控日志的新增信息。
可以通过 SHOW VARIABLES LIKE 'slow_query_log来查看慢查询日志是否开启。MySQL 的慢查询日志默认没有开启,需要在配置文件中配置如下信息:
# 开启 MySQL 慢查询日志
# 1表示开启, 0表示关闭
show_query_log=1
# 设置慢查询的阈值, 超出指定时间则被认为是慢查询, 会被记录到慢查询日志中
long_query_time=2
常见的慢查询:select count(*) from xxx;
Profile 详情
慢查询日志的局限在于,只有 SQL 语句的执行时间超过了阈值,才会被认为是慢查询。但有些简单的 SQL 语句可能没有超过阈值,但是超出期望的时间,例如期待执行时间是1ms,实际执行时间是1s。这种情况下,需要使用 Profile 来进行分析,帮助我们了解时间都消耗在什么地方上。
# 查看是否开启
SELECT @@have_profiling;# 将其设置为开启
SET profiling = 1;
# 查看每一条SQL的耗时情况, 返回结果中可以看到query_id
SHOW PROFILES;# 查看指定query_id的SQL语句各个阶段的耗时情况
SHOW PROFILE FOR QUERY <query_id>;# 查看指定query_id的SQL语句的CPU使用情况
SHOW PROFILE CPU FOR QUERY <query_id>;
Explain 执行计划
SQL 执行时间的长短并不总是能够反映 SQL 的性能,执行时间稍长的 SQL 可能是由于业务逻辑极其复杂导致的。往往通过 explain 执行计划作为 SQL 性能判断的依据。通过 explain 执行计划,可以看到在 SQL 的执行过程中,表是如何连接的,以及连接顺序是怎样的等信息。
Explain 作用:
- 表的读取顺序
- 数据读取操作的操作类型
- 哪些索引可以使用
- 哪些索引被实际使用
- 表之间的引用
- 每张表有多少行被优化器查询
使用方法:在 SQL 语句前面添加关键字 EXPLAIN 或 DESC
字段解释
| explain返回结果中的字段 | 字段含义 |
|---|---|
| id | 代表不同表的操作顺序,涉及多表查询的 SQL 才有实际意义。 id 大的先执行;如果 id 相同,则执行顺序从上到小 |
| select_type | |
| table | derived2表示的就是id为2的表的衍生表,相当于临时变量 |
| type(重点) | 最好到最差:system>const>eq_ref>ref>range>index>ALL 一般来说,得保证查询至少达到range级别,最好能达到ref,再往上比较理想,实际情况不太可能实现 const:主键索引或unique索引 ref:非unique索引 range: index:全索引扫描 all:全表扫描 |
| possible_keys和key | possible_keys:理论上可能用到的索引 key:mysql实际使用的索引,如果为null则表示索引失效,没有使用索引; 如果查询中使用了覆盖索引,则该索引仅仅出现在key列表中 |
| key_len | key_len显示的值为索引字段的最大可能长度,并非实际使用长度 在不损失精确度的情况下,长度越短越好 |
| ref | 显示索引的哪一列被使用,可以的话最好是常量const |
| rows | 大致估算出找到所需的记录所需要读取的行数 |
| Extra(重点) | 1. Using filesort:尽可能优化sql, 这是一个糟糕的信息 2. Using temporary:比上面的更糟糕,使用了临时表保存中间结果 3. Using index:效率不错 1. 如果同时出现Using where表明索引被用来执行索引键值的查找 2. 如果没有同时出现Using where表明索引用来读取数据而非执行查找动作 4. Using where:表明使用了where过滤 5. using joing buffer:使用了连接缓存,当sql语句中的join过多时,可以调大配置文件中的joining buffer 6. impossible where:where子句的值是false, 相当于逻辑错误 7. distinct:找到第一匹配的元组后即立即停止找同样值得动作 8. null表示回表查询 |
索引使用规则(重点)
最左前缀法则(复合索引)
假设为 name、age 和 gender 建立联合索引,那么在查询时,索引顺序分别是 name -> age -> gender,如果查询条件中缺少某个字段,那么索引链将会断链,例如,缺少name,则不使用索引;缺少age,则仅仅使用name索引,不会使用gender索引。有种先按name分类,再按age分类,最后按gender分类。
WHERE子句中的字段顺序不会对联合索引产生影响,只需要字段存在即可,例如,gender=1 AND age=18 AND name='root'。
满足最左前缀法则的字段可以出现在不同的子句中,例如WHERE和GROUP BY
范围查询(复合索引)
在复合索引中,出现了范围查询(>或<),则范围查询右侧的列索引失效。
和上面的索引顺序链的逻辑相同,相当于破坏索引链的方式不仅仅是某个字段没有出现,同时如果某个字段使用了范围查询,则其右侧的所有失效。
解决方式:尽可能使用 >= 或 <=。例如,>30 在某些情况下可以改写为 >= 31
为什么复合索引中,使用
>会使得右侧的索引失效,而使用>=右侧的索引仍然有效呢?
索引失效的情况
- **对索引字段进行运算时,索引失效。**例如使用字符串函数等操作
substring(name, 0, 4),此时会使得name字段上的索引失效 - 如果字符串类型的数据不添加单引号
''时,索引失效。 - 使用
LIKE %xxx进行头部模糊匹配时,索引失效。但是尾部的模糊匹配LIKE xxx%,索引有效。解决方法是什么? OR连接的条件中,如果其中有一个字段没有索引,那么所有的索引都失效。
前缀索引
使用场景:长字符串、大文本等
TODO
覆盖索引
在 SELECT 中尽量使用建立了索引的字段,而不是使用 SELECT *。本质上就是对于SELECT涉及的数据建立除主索引外的复合索引。例如下面案例中,id作为主索引,会出现在二级索引的叶子结点中,因此id字段不需要复合索引中。如果id字段作为复合索引的第一列,往往WHERE条件中不会出现id,根据最左前缀法则,此时还会造成复合索引失效。因此对username和password建立复合索引,且username作为复合索引的第一列是最优方案。

复合索引
复合索引优于单列索引:涉及多个字段时,即使每个字段上都有一个单列索引,但此时只会选择使用其中一个效率比较高的索引,然后通过回表查询找到其他的属性。创建联合索引的时候应该考虑各个列的先后顺序。
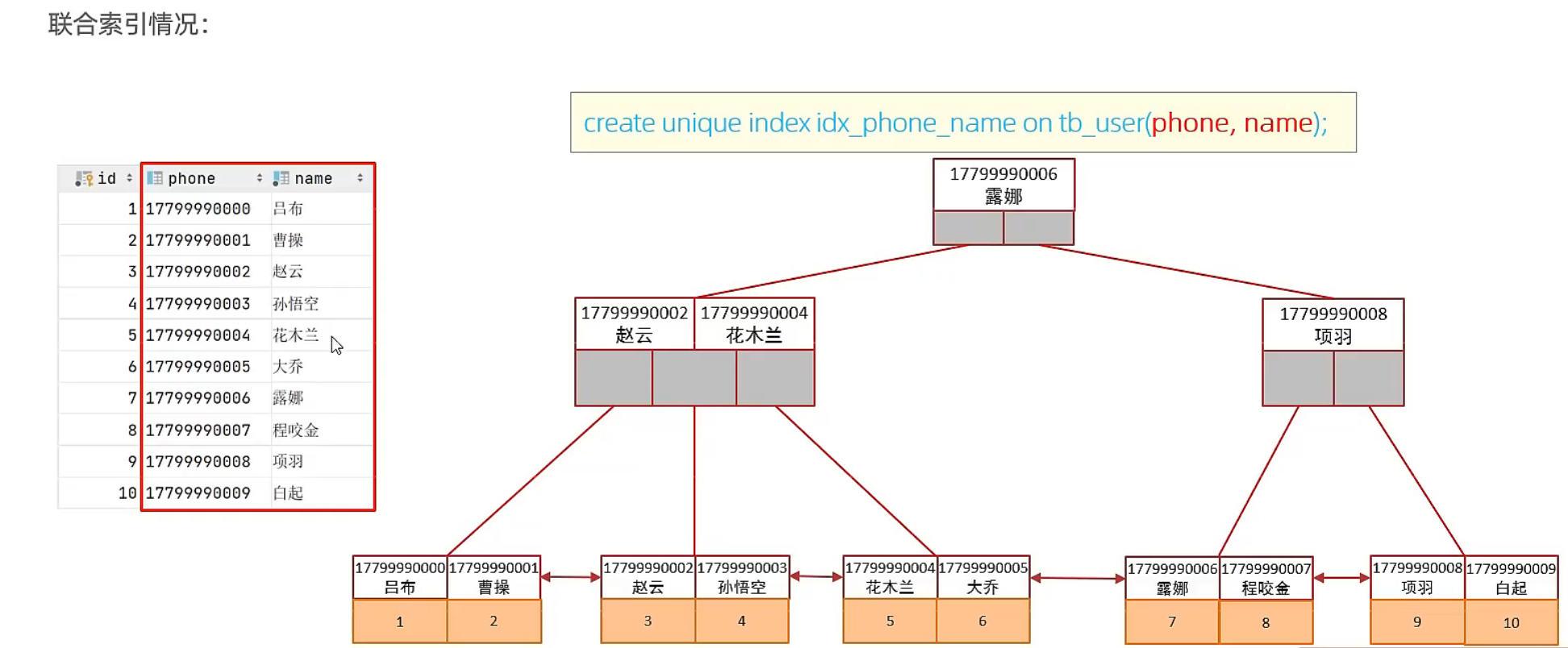
索引设计原则

SQL 优化
插入数据(注意)
-
不要一条一条数据插入,而是通过insert批量插入,即一条insert插入多条数据(建议保持在1条insert对应1000条数据左右)
-
手动提交事务:执行insert前,开启事务;执行完毕后,提交事务。避免一条insert对应一次自动提交
-
主键顺序插入:主键顺序插入 > 主键乱序插入
-
大批量插入数据时不使用
insert,而是使用load# 使用load需要一些配置# 在连接MySQL客户端时添加上--local-infile参数 mysql --local-infile -uroot -proot# 查看是否开启加载本地数据文件 SELECT @@local_infile;# 开启从本地加载数据文件 SET GLOBAL local_infile=1;# 加载本地数据文件到表结构中 LOAD DATA LOCAL INFILE '/root/sql01.log' INTO TABLE `my_user` FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n';
主键优化
为什么主键顺序插入的性能优于主键乱序插入?
主键乱序插入的情况下,可能会出现页分裂的现象。页分裂的原因是,主索引在叶子结点中是有序的双向链表。
主键设计原则:
- 在满足业务需求的情况下,尽量降低主键的长度。(主键会存在于各个二级索引的叶子结点中,因此主键长度减少可以减少索引占用的空间)
- 插入数据时,尽量选择顺序插入,选择使用AUTO_INCREMENT自增主键
- 尽量不要使用UUID作为主键,或者是其他自然主键
- 业务操作时,避免对主键进行修改
ORDER BY 优化
Using filesort:通过读取出满足要求的数据,然后在排序缓冲区Sort Buffer中完成排序操作。(取出的数据还要额外经过一个排序步骤)
Using index:通过有序索引顺序扫描,直接获得有序的目标数据。这种情况下不需要额外的排序操作,效率更高。
索引默认情况下按照字段升序排序
GROUP BY 优化
LIMIT 优化
在大数据量下,分页查询中越往后的页面查询时间越长
COUNT 优化
UPDATE 优化
索引优化
-
单表索引优化案例
range类型的索引后面的索引失效 where id>1
id = 1 and name_length>2 order by name这部分失效
-
双表索引优化案例
-
三表索引优化案例
日期时间数据
# 查找某一天的数据
SELECT *
FROM `table_x`
WHERE DATE_FORMAT(date, '%Y%m%d') = 'xxxx-xx-xx'
上面 sql 语句存在的问题:
- 一般表中对于日期类型数据都有一个索引,但上面的代码将不会使用索引来查询数据,造成查询效率低下。
生日问题
根据某个用户出生日期和当前日期,计算他最近的生日。
重叠问题
视图/存储过程/触发器
视图
存储过程
触发器
触发器是在DML语句(insert、update、delete)之前或之后执行的一段 SQL 代码。触发器的这种特性可以应用在:
- 实现数据的动态完整性约束
- 日志记录
- 进行数据校验
MySQL 中的触发器目前还只支持行级触发,不支持语句级触发 。使用预定义的 OLD 和 NEW 来引用修改前和修改后的记录。
-
创建触发器
CREATE TRIGGER <触发器名> BEFORE|AFTER INSERT|UPDATE|DELETE ON <表名> FOR EACH ROW BEGIN<触发器操作> END; -
查看触发器
SHOW TRIGGERS; -
删除触发器
DROP TRIGGER <数据库名>.<触发器名>
练习
锁(保证隔离性)
锁是一种解决并发导致的各种冲突问题的通用方法。并发问题本质上是多线程、多进程、多事务等环境下,对共享资源的访问造成的数据不一致问题,具体来说,有读写冲突、写写冲突。
共享锁和排他锁
# FOR SHARE 表示添加共享锁
SELECT *
FROM `user`
FOR SHARE;# FOR UPDATE 表示添加排他锁
SELECT *
FROM `user`
FOR UPDATE;
MySQL 8.0 新特性,可以添加后缀 NOWAIT 或 SKIP LOCKED,分别表示加锁不等待直接报错、忽略掉加锁的记录。
全局锁
整个 MySQL 数据库实例都添加上读锁,只允许 DQL 语句。类似 insert、update、commit 等可能改变数据库状态的语句都会被阻塞。
典型使用场景:做全库的备份,保证数据一致性
# 添加全局锁
FLUSH TABLES WITH READ LOCK;# 释放全局锁
UNLOCK TABLES;
// 备份数据库
mysqldump -uroot -proot <数据库名> > <导出文件名.sql>
存在的问题:
- 如果在主库上备份,那么在备份期间都不能执行更新操作,业务只能提供读取服务。
- 如果在从库上备份,那么在备份期间,从库不能执行从主库同步过来的 binlog 日志中的写操作,导致主从库之间的延迟。
在 InnoDB 引擎中,可以在备份时添加 --single-transaction 来完成不加锁的一致性数据备份。(实现原理是快照读snapshot read)
表锁
读锁和写锁
如果使用 InnoDB 引擎,由于 X 锁和 S 锁有更细粒度的行锁,所以一般不会使用到表级别的 X 锁和 S 锁。表锁可以避免死锁,而行锁可能产生死锁问题。
# 为表添加读锁/写锁
LOCK TABLES <表名> READ|WRITE;# 释放锁
UNLOCK TABLES;# 查看表级别的锁, 其中in_use字段表示锁
SHOW OPEN TABLES;
MySQL 中的读锁会禁止当前 session 的写操作,会阻塞其它 session 的写操作。而对于当前 session 和其它 session 的读操作,则都可以执行。(感觉为表添加 S 锁的 session 是一个倒霉蛋,没有享有什么特权,写入操作的优先级还给让出去了。)
MySQL 中的写锁相比于读锁更能体现专属的感觉,添加写锁的 session 可以读写表中的数据,而其它 session 既不可以读,也不可以写。
思考:为什么写锁是当前session可以读写,而其它session不可以读写?
其实在并发控制中,读操作和写操作本身就是不可以并发的,因此当前session添加写操作后,其它session不能读写是很好理解的。所以主要解释为什么当前session可以读写呢?这是因为在一个session内,顺序是天生的,而并发问题的根源是由于顺序的不确定性,对于一个session内是不存在并发问题的(类似:单线程不需要考虑并发问题)
元数据锁
执行 DDL 语句时使用的并不是表级别的 X 锁、S 锁,而是称为元数据锁(Metadata Locks,简称MDL)。
总结:
- DML、DQL语句对应的是操作表中的数据,此时添加MDL中的共享锁。
- SELECT FOR SHARE:共享读锁
- SELECT FOR UPDATE:共享写锁
- INSERT、DELETE、UPDATE:共享写锁
- SELECT:不添加任何锁
- DDL 修改表结构,例如添加、删除列,此时添加MDL中的排他锁。

# 查看元数据锁
SELECT *
FROM performance_schema.metadata_locks;

意向锁
在事务A为表添加行锁后,如果事务B此时想要为表添加表锁,那么事务B需要判断表中每一行是否添加了行锁,这样效率太低,因此产生了意向锁。
意向锁是事务A在添加行锁后,再为表添加一个意向锁。事务B检查表的意向锁与当前想要添加的表锁之间是否兼容,如果兼容则事务B添加表锁成功;否则事务B阻塞。
意向共享锁(IS)
意向排他锁(IX)
意向锁产生是作为一种辅助工具,或称为行锁的副产品,因此意向锁之间都是兼容的,例如,对行1读和对行2写,分别产生IS和IX锁,但本质上都是对独立的行进行处理。只有IS锁能够和表锁中的S锁兼容,其它都不兼容。
# 查看意向锁以及行锁的加锁情况
SELECT *
FROM performance_schema.data_locks;

总结:
- 同级别的锁,只有S锁和S锁是兼容的
- 低级别的锁在高级别中对应的锁可能会降级(也可能不会),例如,行锁中的X锁,在MDL中降级为S锁,而在意向锁中仍然对应IX锁。(这里写的有点不清楚,并不是说行锁中X锁是MDL中的S锁。而是某一个行为,导致行锁中添加X锁,MDL中添加S锁,意向锁中添加IX锁。)
行锁
InnoDB 的数据是基于索引组织的,行锁是通过对索引上的索引项加锁来实现的,而不是对记录加的锁。(查询数据最终都要落到主索引上)
InnoDB的行锁是针对索引加的锁,如果不通过索引条件检索数据,那么行锁会自动升级为表锁,InnoDB引擎会对表中的所有记录添加锁。
-
在唯一索引上(UNIQE)进行等值查询,给不存在的记录加锁时,会添加间隙锁
例如,数据库中存在id=3和id=8的数据,此时给id=5的记录(不存在的数据)添加锁,这把锁即为间隙锁。在其它事务insert一条id=7的数据时,会因为间隙锁的存在而被阻塞,在这个场景下,间隙锁的范围是(3,8)。
-
在非唯一索引上进行等值查询时,会在前后都添加间隙锁
例如,数据库中存在age=1、age=3、age=8的数据,现在对age=3的数据进行操作,由于age上的索引是非唯一索引,因此除了对age=3的数据本身添加记录锁外,还会添加(1,3)和(3,8)的间隙锁,相当于(1,8)的范围全部被锁住。实际实现中,将分为两把锁
(1,3]的临键锁和(3,8)的间隙锁。 -
在唯一索引上进行范围查询时,可能会添加大量的锁
例如,存在数据 [1,3,5,19,25,38],执行 id > 19 时,会在 25、38、supremum pseudo-record(+∞) 上都添加临键锁。
25 上的临键锁只锁 (19,25] 这部分范围,38 上的临键锁只锁 (25,38] 这部分范围,因此需要多把临键锁才能满足 id > 19 的范围表示。
SELECT * FROM `user` WHERE id >= 19 FOR SHARE;
记录锁
Record Lock
S锁
X锁
间隙锁
Gap Lock
间隙锁不锁记录,是为了确保索引记录之间的间隙不变,防止其它事务在这个间隙进行insert,避免产生幻读现象。
间隙锁的目的是防止其它事务插入间隙,间隙锁可以共存。

临键锁
记录锁和间隙锁的组合,锁住数据的同时还锁住间隙。
InnoDB 存储引擎
逻辑存储结构
架构

内存结构
Buffer Pool(缓冲池)
Buffer Pool 是主内存的一个区域,在执行增删改查操作时,先操作缓冲区中的数据,然后以一定的频率刷新到磁盘,从而减少磁盘IO。
缓冲池以 Page(页)为单位,底层采用链表结构管理。根据状态,将 Page 分为三种类型:
- free Page:空闲页,没有将磁盘数据导入,处于未使用状态
- clean Page:磁盘数据导入,但是只执行了查询操作,并没有执行修改操作
- dirty Page:脏页,缓冲池中的数据和磁盘中的数据不一致。所谓的 dirty page,就是本应该直接写入磁盘的数据暂时还保存在内存缓冲区中,此时内存中的page 称为 dirty page。将 dirty page 刷新到磁盘中即可以实现数据的一致。(TODO:但这样似乎 dirty page 应该称为 real page 才对吧?哪里的理解不对呢?)
Change Buffer(更改缓冲区)
Change Buffer 是针对非 UNIQUE 索引的二级索引页。在执行 DML 语句时,如果
TODO
Log Buffer(日志缓冲区)
日志缓冲区,用来保存写入到磁盘中的 log 日志数据(redo log、undo log)。默认大小为 16 MB。
日志缓冲区中的数据会定期刷新到磁盘中,增加日志缓冲区的大小可以节省磁盘I/O。
# 设置日志缓冲区大小
innodb_log_buffer_size=16MB
# 设置日志刷新到磁盘的时机
# 0: 每秒写入并刷新一次
# 1: 每次事务提交时写入并刷新到磁盘
# 2: 每次事务提交后写入, 每秒刷新一次
innodb_flush_log_at_trx_commit=0|1|2
磁盘结构
System Tablespace(系统表空间)
TableSpace(表空间)
CREATE TABLESPACE <表空间名>
ADD DATAFILE '<idb文件名>'
ENGINE = INNODB;
Doublewrite Buffer Files(双写缓冲区)
InnoDB 引擎在将 Buffer Pool 中的 Page 刷新到磁盘前,会先将数据也写入双写缓冲区文件中,便于系统异常时恢复数据。
事务原理(InnoDB的价值)
-
ACD 特性:由 redo log 和 undo log 实现
-
I(隔离性):由 锁 和 MVCC 实现
redo log(保证持久性)
-
redo log buffer(重做日志缓冲区)
保存在内存中
-
redo log file(重做日志文件)
保存在磁盘中
当事务提交后,所有的修改信息都保存在 redo log file 中。当脏页(dirty page)刷新到磁盘时,如果不幸发生错误,可以使用 redo log file 进行数据恢复使用。这里的发生错误是指,数据在内存中已经被成功保存,事务提交成功,并且告知用户事务执行成功,但是实际上在将内存数据保存到磁盘这个过程中发生错误时,持久性就没有得到保障。
大致流程:
- 对某个数据执行 update、delete 等操作
- 在 Buffer Pool 中查找是否存在该数据的缓存;如果不存在,则通过后台线程从 idb 文件中将 page 读取到 buffer pool 中
- 对 buffer pool 中的 page 进行相应的操作(update、delete等),修改 buffer pool 中的数据,此时 buffer pool 和 idb 文件存在差异,即 page 称为 dirty page。
- 每隔一定的时间间隔,后台线程会将 dirty page 刷新到 idb 文件中。
redo log 的功能在于:步骤3到步骤4之间,添加一个redo log buffer,将当前数据执行的操作的信息保存到 redo log buffer 中,然后 redo log buffer 中的数据立即刷新到磁盘中的 redo log file 中保存。保存成功后,才向用户返回事务提交成功?
**redo log buffer 是顺序的追加方式,操作 I/O 的效率高。**而执行数据的 update、delete 等操作时,数据所在的 page 是随机分布的,需要执行大量的随机读写 I/O,而这种效率低。因此每次事务提交后,可以将 redo log buffer 中的数据刷新到磁盘中,但是出于效率考虑,而 buffer pool 中的数据则是每隔一段时间刷新一次。换言之,如果每次刷新都提交 buffer pool 中的数据,那 buffer pool 作为缓冲的价值也就没有必要了。
在 dirty page 成功刷新到磁盘中后,实际上 redo log file 也就没有存在意义了,可以认为 redo log file 是一个环形队列,会覆盖掉原来的数据,文件不会无限制增长。
undo log(保证原子性)
undo log 用于记录数据被修改前的信息,用于事务回滚或MVCC(多版本并发控制)。
与 redo log 记录实际执行的物理操作不同,undo log 并不是记录实际执行的数据操作,甚至是记录与当前操作相反的操作(逆操作),例如当前实际执行的是delete 操作,那 undo log 中需要对该操作进行还原,因此记录 insert 操作。
-
insert undo log:保存插入记录的主键值,回滚时只需要删除该主键对应的记录即可
-
update undo log:保存记录的旧值,回滚时将记录更新回旧值
-
delete undo log:理论上将记录的旧值保存下来,回滚的时候重新插入记录即可(主键变化怎么办呢?)。但实际为了效率并没有这么处理。
设置删除标志位(隐藏字段),InnoDB 引擎通过专门的 purge 线程来清理这些删除标志位被设置true的记录。这种情况下如何实现回滚呢?
undo log 在事务提交之后,并不会立即删除,因为这些日志还可能用于 MVCC。undo log 采用 segment(段)的方式进行管理和记录,存放在 rollback segment (回滚段)中,内部包含 1024 个 rollback segment。这里是什么的内部?
undo log 日志中,insert undo log 日志只在事务回滚的情况下需要,因此在事务commit之后,insert undo log 可以被立即删除。但是 delete undo log 和 update undo log 不仅在回滚的时候需要,在快照读的时候也需要,因此不能被立即删除。
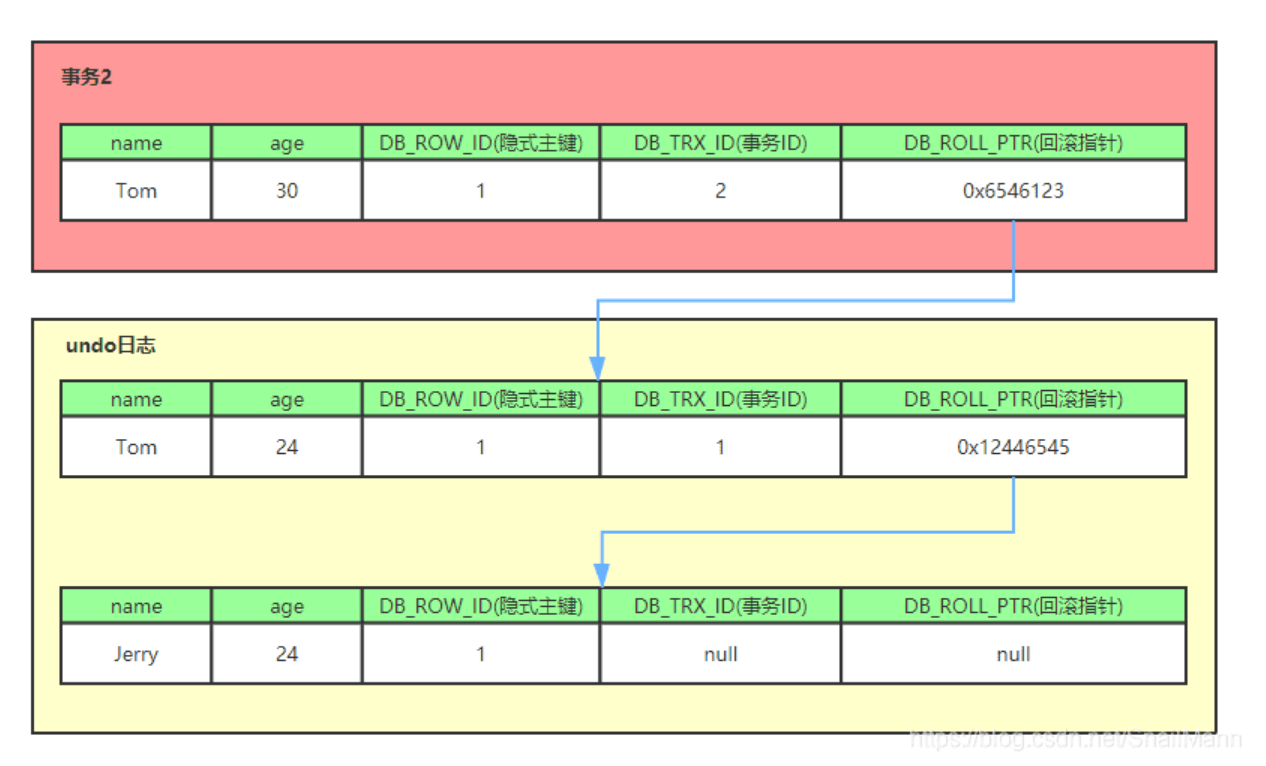
MySQL 管理
面试题
- 什么是事务?事务的四大特性是什么?
- 事务的隔离级别有哪些?MySQL 默认是哪个?
- 内连接和左外连接的区别是什么?
- 常用的存储引擎有哪些?InnoDB 和 MyISAM 的区别?
- MySQL 默认 InnoDB 引擎的索引是什么数据结构?
- 如何查看 MySQL 的执行计划?
- 索引失效的情况有哪些?
- 什么是回表查询?
- 什么是 MVCC?
- MySQL 的主从复制的原理是什么?
- 主从复制之后的读写分离是如何实现的?
- 数据库的分库分表是如何实现的?






![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-5](https://img-blog.csdnimg.cn/direct/4e7f027b22d8431ba6068716f791f717.png)