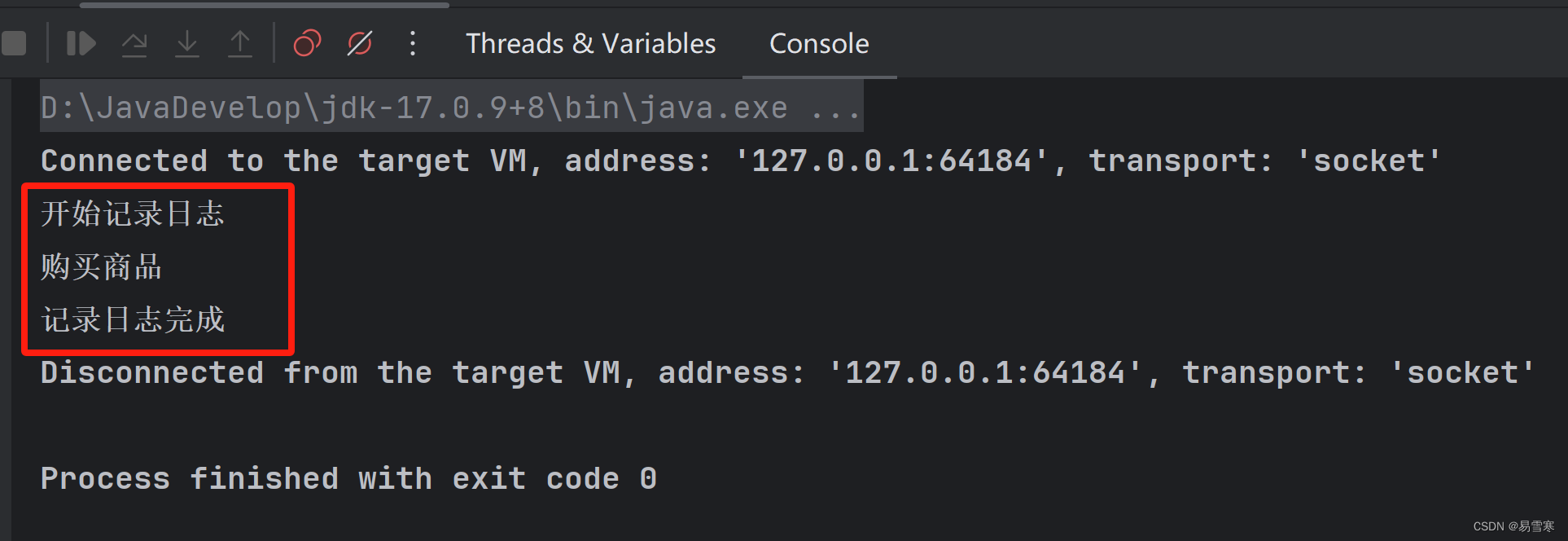
一、CUDA 和 GPU 简介
- CUDA 是显卡厂商 NVIDIA 推出的运算平台,是一种通用并行计算架构,使得 GPU 能够解决复杂的计算问题。
- 开发人员可以使用 C 语言来为 CUDA 架构编写程序,可以在支持 CUDA 的处理器上以超高性能运行,CUDA 3.0 已经开始支持 C++。
- GPU 是图形处理器,显卡的处理核心。
- 电脑显示器上显示的图像,在显示在显示器上之前,要经过一系列的图形计算,这个过程叫渲染,针对图形计算的这些操作设计了一种处理器,也就是 GPU。
二、GPU 工作原理与结构
- GPU 采用流式并行计算模式,可对每个数据行进行独立的并行计算。
- GPU 和 CPU 的区别:
- CPU 基于低延时设计,由运算器(ALU:算数逻辑单元)和控制器(CU),以及若干个寄存器和高速缓冲存储器组成,功能模块较多,擅长逻辑控制,串行运算。
- GPU 基于大吞吐量设计,拥有更多的 ALU 用于数据处理,适合对密集数据进行并行处理,擅长大规模并行计算。
- GPU 为图形图像专门设计,在矩阵运算,数值计算方面具有独特优势,特别是浮点和并行计算上远远优于 CPU,GPU 的优势在于快。
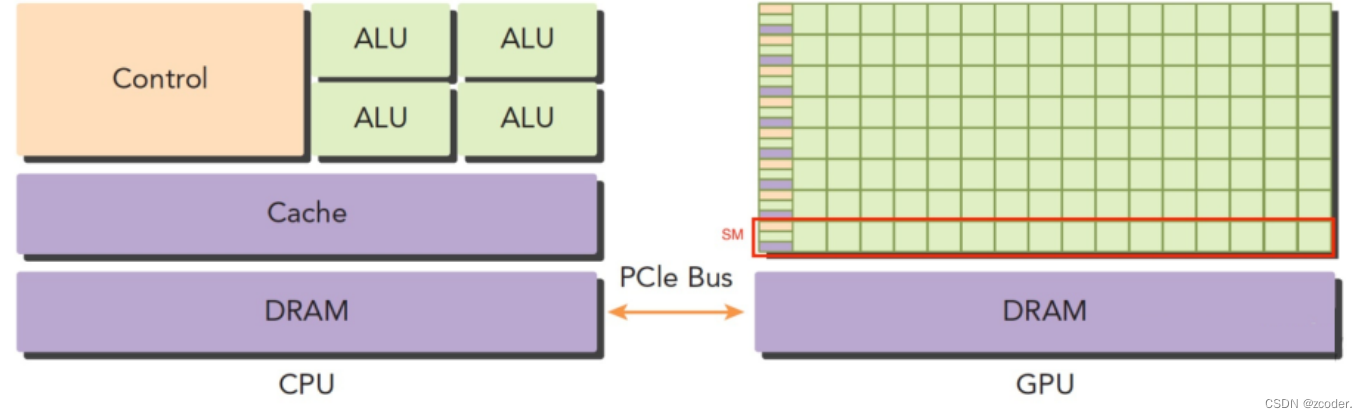
三、GPU 编程模型
- 异构计算 = CPU + GPU。
- 一个 GPU 包含多个 SM(Streaming Multiprocessor),而每个 SM 又包含多个 core。
- 一个 block 只能调度到一个 SM 上运行,直到 block 运行完毕。
- 一个 SM 可以同时运行多个 block,因为有多个 core。
- 每个 block 以 warp(一般为 32 个线程或 64 个线程)作为一次执行的单位(真正的同时执行)。
- 在具体的硬件执行中,一个 core 会同时执行 warp,一个 block 会被绑定到一个 core 上,即使这个 block 内部可能有 1024 个线程,这些线程组会被相应的调度器来进行调度,在逻辑层面上可以认为 1024 个线程同时执行,但在硬件上是 warp 同时执行,这一点其实和操作系统的线程调度是一样的
- 假如一个 core 同时能执行 64 个线程,但一个 block 有 1024 个线程,那这 1024 个线程会分 16 次执行。
- 显存层面:一个 block 内的 thread 共享一块 share memory(一般是 SM 的一级缓存)。GPU 和 CPU 一样有着多级 cache 、寄存器的架构,把全局显存的数据加载到共享显存上再处理可以有效地加速。
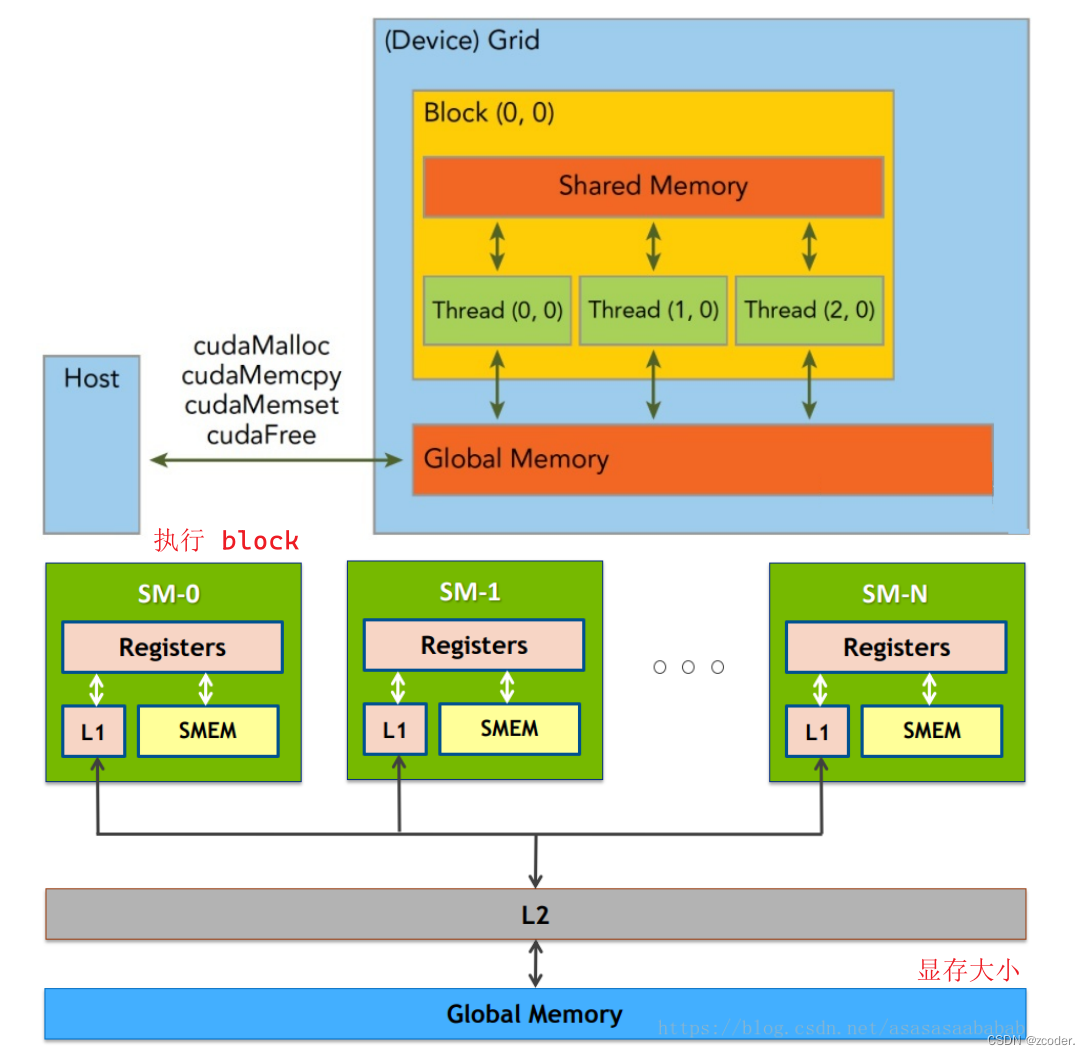
四、Grid、Block、Thread 的关系
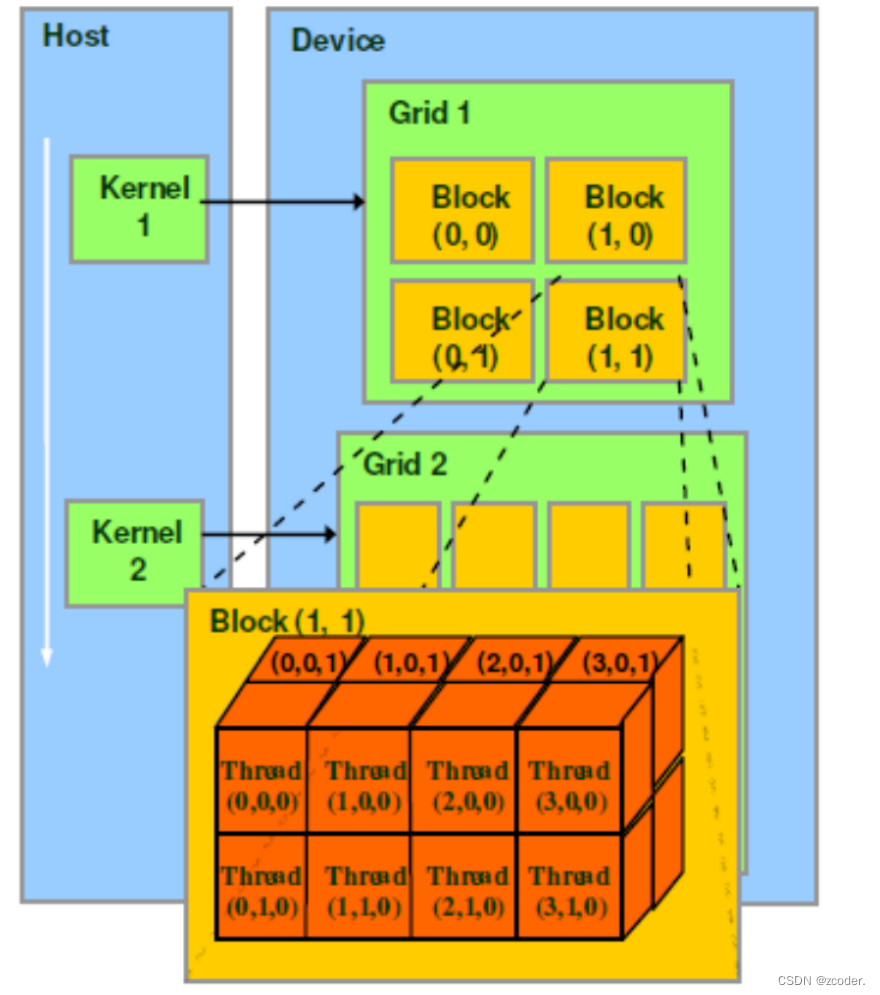
- CUDA 中线程分成三个层次:线程、线程块、线程网格。
- 线程:CUDA 中的基本执行单元,由硬件支持、开销很小,每个线程执行相同的代码。
- 线程块(Block):若干线程的分组,Block 内的一个块至多 512 个线程,或 1024 个线程(根据不同的 GPU 规格),线程块可以是一维、二维或者三维的,同一个 block 中的 threads 可以同步,也可以通过 share memory 通信。
- 线程网格(Grid):若干线程块的网格。
- CUDA 中每一个线程都有一个唯一的标识 ID —
ThreadIdx。threadIdx是一个 uint3 类型,表示一个线程的索引。blockIdx是一个 uint3 类型,表示一个线程块的索引,一个线程块中通常有多个线程。blockDim是一个 dim3 类型,表示线程块的大小。gridDim是一个 dim3 类型,表示网格的大小,一个网格中通常有多个线程块。
- grid 划分成 1 维,block 划分为 1 维:
int threadId = blockIdx.x * blockDim.x + threadIdx.x; - grid 划分成 1 维,block 划分为 2 维:
int threadId = blockIdx.x * blockDim.x * blockDim.y + threadIdx.y * blockDim.x + threadIdx.x; - grid 划分成 1 维,block 划分为 3 维:
int threadId = blockIdx.x * blockDim.x * blockDim.y * blockDim.z+ threadIdx.z * blockDim.y * blockDim.x+ threadIdx.y * blockDim.x + threadIdx.x; - grid 划分成 2 维,block 划分为 1 维:
int blockId = blockIdx.y * gridDim.x + blockIdx.x; int threadId = blockId * blockDim.x + threadIdx.x; - grid 划分成 2 维,block 划分为 2 维:
int blockId = blockIdx.x + blockIdx.y * gridDim.x; int threadId = blockId * (blockDim.x * blockDim.y) + (threadIdx.y * blockDim.x) + threadIdx.x; - grid 划分成 2 维,block 划分为 3 维:
int blockId = blockIdx.x + blockIdx.y * gridDim.x; int threadId = blockId * (blockDim.x * blockDim.y * blockDim.z)+ (threadIdx.z * (blockDim.x * blockDim.y))+ (threadIdx.y * blockDim.x) + threadIdx.x; - grid 划分成 3 维,block 划分为 1 维:
int blockId = blockIdx.x + blockIdx.y * gridDim.x+ gridDim.x * gridDim.y * blockIdx.z; int threadId = blockId * blockDim.x + threadIdx.x; - grid 划分成 3 维,block 划分为 2 维:
int blockId = blockIdx.x + blockIdx.y * gridDim.x+ gridDim.x * gridDim.y * blockIdx.z; int threadId = blockId * (blockDim.x * blockDim.y)+ (threadIdx.y * blockDim.x) + threadIdx.x; - grid 划分成 3 维,block 划分为 3 维
int blockId = blockIdx.x + blockIdx.y * gridDim.x+ gridDim.x * gridDim.y * blockIdx.z; int threadId = blockId * (blockDim.x * blockDim.y * blockDim.z)+ (threadIdx.z * (blockDim.x * blockDim.y))+ (threadIdx.y * blockDim.x) + threadIdx.x;
五、CUDA 程序结构
- CUDA 程序的结构大体是:{主机串行 → GPU 并行} + → 主机串行,这样的串并交叉结构。
- 主机串行过渡到 GPU 并行时需要将数据从主机内存上拷贝到 GPU 设备显存上,GPU 执行完毕时也需要把数据拷贝回来。
六、CUDA 核函数和配置
- 主机调用设备代码的唯一接口就是 kernel 函数,使用限定词:
__global__。 - 使用核函数需要在核函数名后面加
<<<>>>指定核函数配置。 <<<>>>运算符完整的执行配置参数形式是<<< Dg, Db, Ns, S>>>。- 参数 Dg:
- 用于定义整个 grid 的维度和尺寸,即一个 grid 有多少个 block。
- Dg 为
dim3类型。 Dim3 Dg(Dg.x, Dg.y, 1)表示 grid 中每行有Dg.x个 block、每列有Dg.y个 block、并且只有一个 grid。- 整个 grid 中共有
Dg.x * Dg.y个 block,其中Dg.x和Dg.y最大值为65535。
- 参数 Db:
- 用于定义一个 block 的维度和尺寸,即一个 block 有多少个 thread。
- Db 为
dim3类型。 Dim3 Db(Db.x, Db.y, Db.z)表示整个 block 中每行有Db.x个 thread,每列有Db.y个 thread,高度为Db.z。Db.x和Db.y最大值为512,Db.z最大值为62。- 一个 block 中共有
Db.x * Db.y * Db.z个 thread。
- 参数 Ns 是一个可选参数,用于设置每个 block 除了静态分配的 shared Memory 以外,最多能动态分配的 shared memory大小,单位为 byte。不需要动态分配时该值为 0 或省略不写。
- 参数 S 是一个
cudaStream_t类型的可选参数,初始值为零,表示该核函数处在哪个流之中。
- 参数 Dg:
- 如
<<<DimGrid, DimBlock>>>指定线程网格和线程块维度,若当前硬件无法满足用户配置,则核函数不会被执行,直接返回错误。
七、CUDA 限定符
-
函数限定符。
函数限定符 在何处执行 从何处调用 特性 __device__设备 设备 函数的地址无法获取 __global__设备 主机 返回类型必须为空 __host__主机 主机 等同于不使用任何限定符 -
变量限定符。
变量限定符 位于何处 可以访问的线程 主机访问 __device__全局存储器 线程网格内的所有线程 通过运行时库访问 __constant__固定存储器 线程网格内的所有线程 通过运行时库访问 __shared__共享存储器 线程块内的所有线程 不可从主机访问
八、同步
- CPU 启动 kernel 函数是异步的,它并不会阻塞等到 GPU 执行完 kernel 函数才执行后面的 CPU 部
分。 - 因此如果后续程序立即需要用到上一个 kernel 函数的结果我们需要显式设置同步障来阻塞 CPU 程序。
- 一个线程块内需要同步共享存储器的共享变量
__shared__时,需要在使用前显式调用__syncthreads()同步块内所有线程。 - 同一个 Grid 中不同 Block 之间无法设置同步。
九、CUDA 运行时 API
cudaMemcpy:用于在主机和设备之间拷贝数据,其中cudaMemcpyKind枚举类型常用的有:cudaMemcpyHostToDevice表示把主机数据拷贝到显存,以及逆向的cudaMemcpyDeviceToHost、cudaMemcpyHostToHost、cudaMemcpyDeviceToDevice。__host__ cudaError_t cudaMemcpy( void* dst, const void* src, size_t count, cudaMemcpyKind kind)cudaMalloc:在设备上分配动态显存,两个限定符表示可以在主机或设备上调用。__host__ __device__ cudaError_t cudaMalloc( void** devPtr, size_t size )cudaFree:释放回收在设备上分配的动态显存。__host__ __device__ cudaError_t cudaFree( void* devPtr )cudaThreadSynchronize:等待 GPU 代码运行结束。
十、CUDA 向量加法
cmake_minimum_required(VERSION 3.16.3)project(CUDATest LANGUAGES CXX CUDA)add_executable(vector_add vector_add.cu)
#include <iostream>
#include <random>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"void initDevice(int devNum) {int dev = devNum;cudaDeviceProp deviceProp;cudaGetDeviceProperties(&deviceProp, dev);printf("Using device: %d: %s \n", dev, deviceProp.name);cudaSetDevice(dev);
}// 全局随机数引擎
std::default_random_engine engine(static_cast<unsigned>(time(nullptr)));
std::uniform_real_distribution<float> distribution(0.0, 100.0);
void initData(float* arr, int nElem) {for (int i = 0; i < nElem; i++) {arr[i] = distribution(engine);}
}__global__ void vector_add(float* arr1, float * arr2, float* res, int n) {int i = blockIdx.x * blockDim.x + threadIdx.x;if (i >= n) return;res[i] = arr1[i] + arr2[i];
}void vector_add_cpu(float* arr1, float * arr2, float* res, int n) {for (int i = 0;i < n;i++) {res[i] = arr1[i] + arr2[i];}
}void checkRes(float* cpuRes, float* gpuRes, const int n) {double epsilon = 1.0E-8;for (int i = 0;i < n;i++) {if (abs(cpuRes[i] - gpuRes[i]) > epsilon) {printf("Result don't match\n");return;} }printf("match!\n");
}int main() {initDevice(0);int nElem = 2048 * 2048;int nByte = sizeof(float) * nElem;// 主机内存float* h_arr1 = (float*)malloc(nByte);float* h_arr2 = (float*)malloc(nByte);float* h_res = (float*)malloc(nByte);float* res = (float*)malloc(nByte);// 初始化数据initData(h_arr1, nElem);initData(h_arr2, nElem);memset(h_res, 0, nByte);memset(res, 0, nByte);// GPU 内存申请float* d_arr1;float* d_arr2;float* d_res;// 设备显存cudaMalloc(&d_arr1, nByte);cudaMalloc(&d_arr2, nByte);cudaMalloc(&d_res, nByte);// 数据拷贝cudaMemcpy(d_arr1, h_arr1, nByte, cudaMemcpyHostToDevice);cudaMemcpy(d_arr2, h_arr2, nByte, cudaMemcpyHostToDevice);// 执行向量加法int threads = 32;int blocks = (nElem + threads - 1) / threads; vector_add<<<blocks, threads>>>(d_arr1, d_arr2, d_res, nElem);// 数据拷贝cudaMemcpy(h_res, d_res, nByte, cudaMemcpyDeviceToHost);// cpu 计算vector_add_cpu(h_arr1, h_arr2, res, nElem);cudaThreadSynchronize();// 对比结果checkRes(h_res, res, nElem);// 释放显存cudaFree(d_arr1);cudaFree(d_arr2);cudaFree(d_res);// 释放内存free(h_arr1);free(h_arr2);free(h_res);free(res);return 0;
}
十一、CUDA 矩阵乘法
#include <iostream>
#include <random>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"void initDevice(int devNum) {int dev = devNum;cudaDeviceProp deviceProp;cudaGetDeviceProperties(&deviceProp, dev);printf("Using device: %d: %s \n", dev, deviceProp.name);cudaSetDevice(dev);
}// 全局随机数引擎
std::default_random_engine engine(static_cast<unsigned>(time(nullptr)));
std::uniform_real_distribution<float> distribution(0.0, 100.0);
void initData(float* arr, int nElem) {for (int i = 0; i < nElem; i++) {arr[i] = distribution(engine);}
}__global__ void matrix_mul(float* A, float * B, float* C, int n) {int col = blockIdx.x * blockDim.x + threadIdx.x;int row = blockIdx.y * blockDim.y + threadIdx.y;if (row >= n || col >= n) return;float val = 0.0;for (int i = 0;i < n;i++) {val += A[row * n + i] * B[i * n + col];}C[row * n + col] = val;
}void matrix_mul_cpu(float* A, float * B, float* C, int n) {int sum = 0;for (int i = 0;i < n;i++) {for (int j = 0;j < n;j++) {for (int k = 0;k < n;k++) {sum += A[i * n + k] * B[k * n + j];}C[i * n + j] = sum;sum = 0;}}
}void checkRes(float* cpuRes, float* gpuRes, const int nElem) {double epsilon = 1.0E-8;for (int i = 0;i < nElem;i++) {if (abs(cpuRes[i] - gpuRes[i] > epsilon)) {printf("Result don't match\n");return;} }printf("match!\n");
}int main() {initDevice(0);int n = 64;int nElem = n * n;int nByte = sizeof(float) * nElem;// 主机内存float* h_A = (float*)malloc(nByte);float* h_B = (float*)malloc(nByte);float* h_C = (float*)malloc(nByte);float* C = (float*)malloc(nByte);// 初始化数据initData(h_A, nElem);initData(h_B, nElem);memset(h_C, 0, nByte);memset(C, 0, nByte);// GPU 内存申请float* d_A;float* d_B;float* d_C;// 设备显存cudaMalloc(&d_A, nByte);cudaMalloc(&d_B, nByte);cudaMalloc(&d_C, nByte);// 数据拷贝cudaMemcpy(d_A, h_A, nByte, cudaMemcpyHostToDevice);cudaMemcpy(d_B, h_B, nByte, cudaMemcpyHostToDevice);// 执行矩阵乘法dim3 threads(32, 32);int blockX = (threads.x + n - 1) / threads.x;int blockY = (threads.y + n - 1) / threads.y;dim3 blocks(blockX, blockY);matrix_mul<<<blocks, threads>>>(d_A, d_B, d_C, n);// 数据拷贝cudaMemcpy(h_C, d_C, nByte, cudaMemcpyDeviceToHost);// cpu 计算matrix_mul_cpu(h_A, h_B, C, n);cudaThreadSynchronize();// 对比结果checkRes(C, h_C, nElem);cudaFree(d_A);cudaFree(d_B);cudaFree(d_C);free(h_C);free(C);return 0;
}