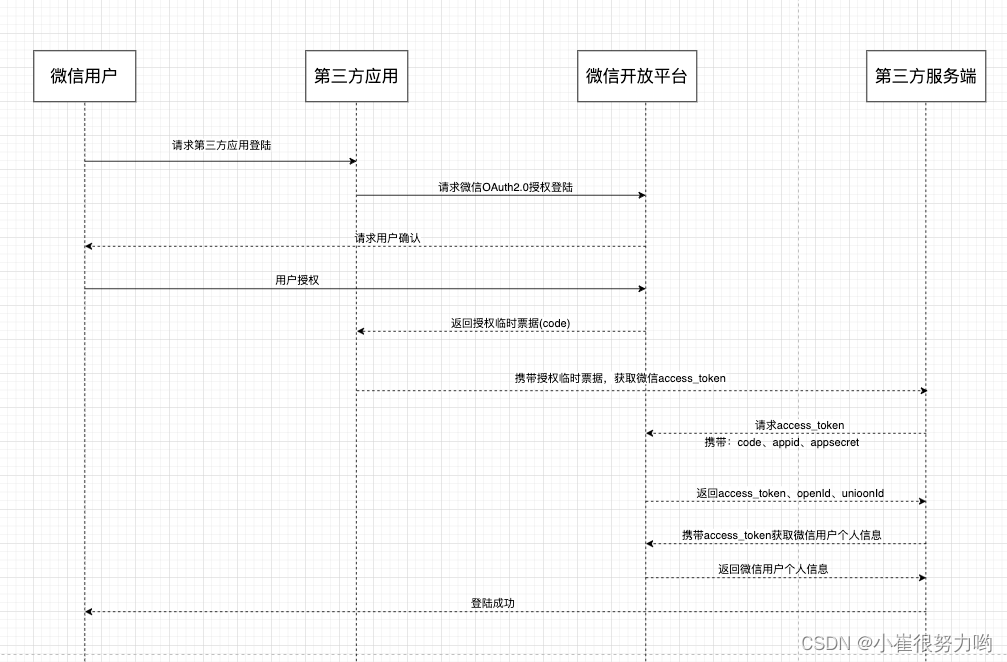
Grounded-Segment-Anything实现目标分割、检测与风格迁移
文章目录
- Grounded-Segment-Anything实现目标分割、检测与风格迁移
- 一、Segment-Anything介绍
- 二、Grounded-Segment-Anything
- 1、简介
- 2、测试
一、Segment-Anything介绍
代码链接:https://github.com/facebookresearch/segment-anything
论文地址:https://arxiv.org/abs/2304.02643
官网地址:https://segment-anything.com/
继2023年4月5日meta AI发布了Segment Anything的论文和源码后,在github上已经超过了25.3k个⭐️

号称分割一切的此模型,打破了传统的分割任务思路,将CV界震撼。不少大佬们也是开始了这个分割大模型的研究与应用。Segment Anything只针对分割任务,那么我们的物体检测、识别也可以与其结合使用。
二、Grounded-Segment-Anything
1、简介
代码链接:https://github.com/camenduru/grounded-segment-anything
这个项目背后的核心思想是结合不同模型的优势,以构建一个非常强大的管道来解决复杂的问题。值得一提的是,这是一个组合强专家模型的工作流程,其中所有部分可以单独使用,也可以组合使用,并且可以替换为任何类似但不同的模型
比如用GLIP或其他探测器替换Grounding DINO /用ControlNet替换Stable-Diffusion /与ChatGPT组合。
比如官方提供的给“坤坤”换衣服,真实完美搭配!

接下来我将演示如何运行在线的项目。如果想要像在segment Anything官网跑一个demo图片,我们可以进到其colab中来在线运行这个demo
2、测试
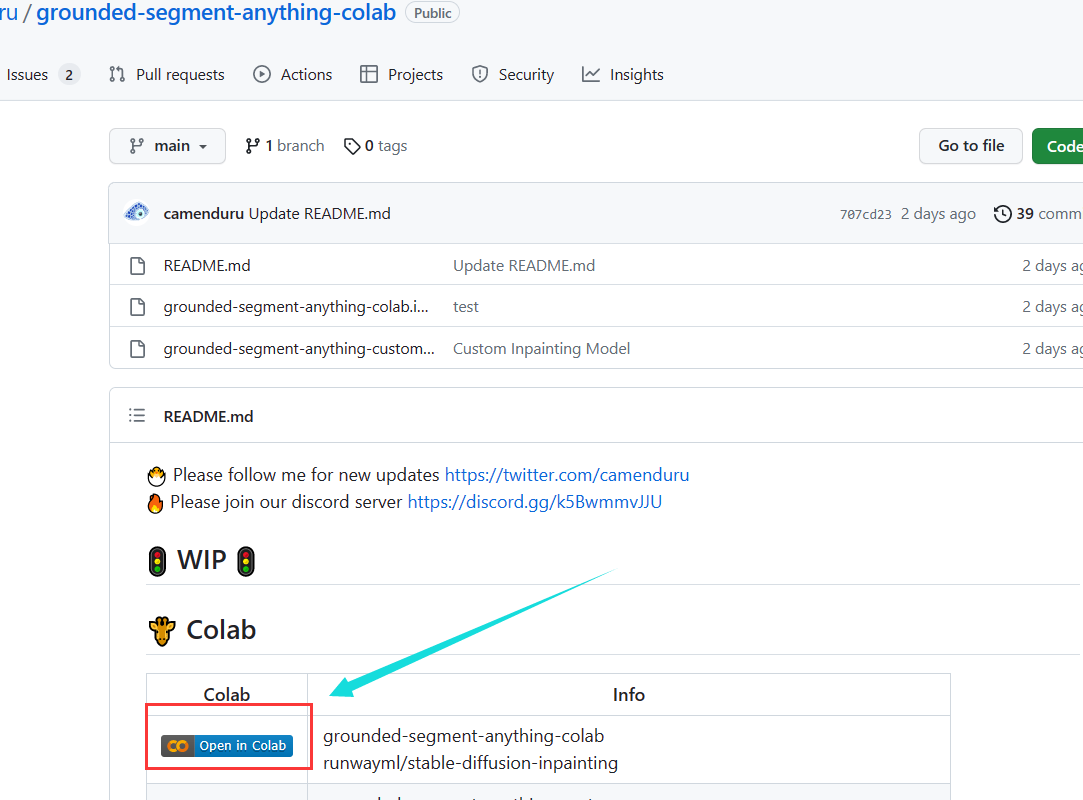
首先进入其在线运行地址:https://github.com/camenduru/grounded-segment-anything-colab
打开后,点击colab中的open in colab进入jupyter notebook
首先得确保你有一个能够正常登录的Google账号,在右上角点击展开并登录。已经登录那么可以直接点击连接按钮,并稍等片刻。

连接成功后即可运行代码

等待运行完成后,运行下一个代码块
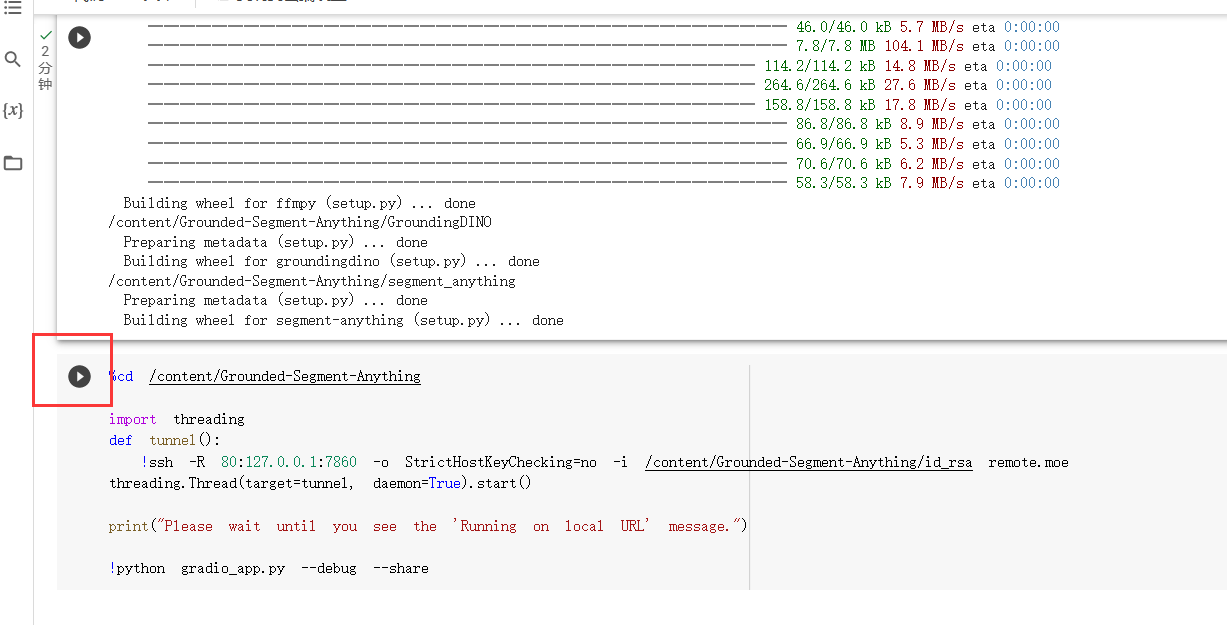
出现下方链接后点进去即可运行demo(两个都可以)
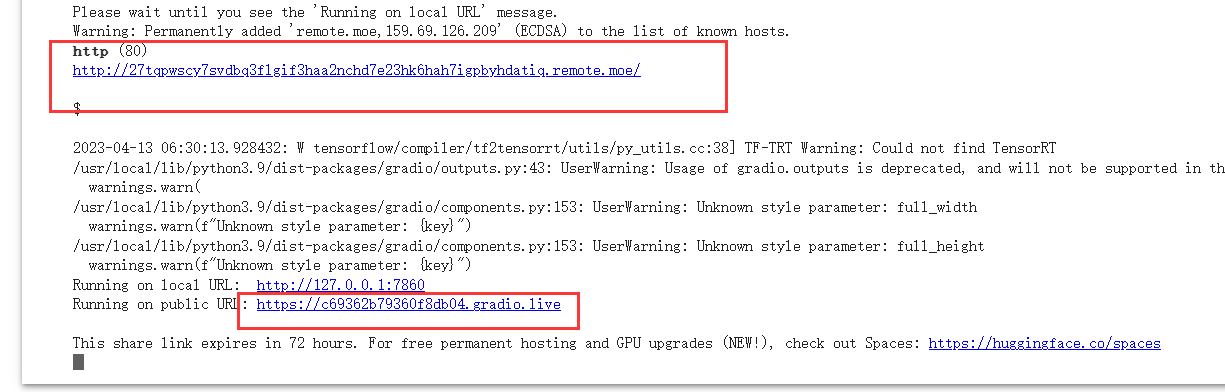
进入demo之后我们可以传入图片,并输入描述的内容
分割任务例如:a door /a person
描绘任务例如:A man in a jacket
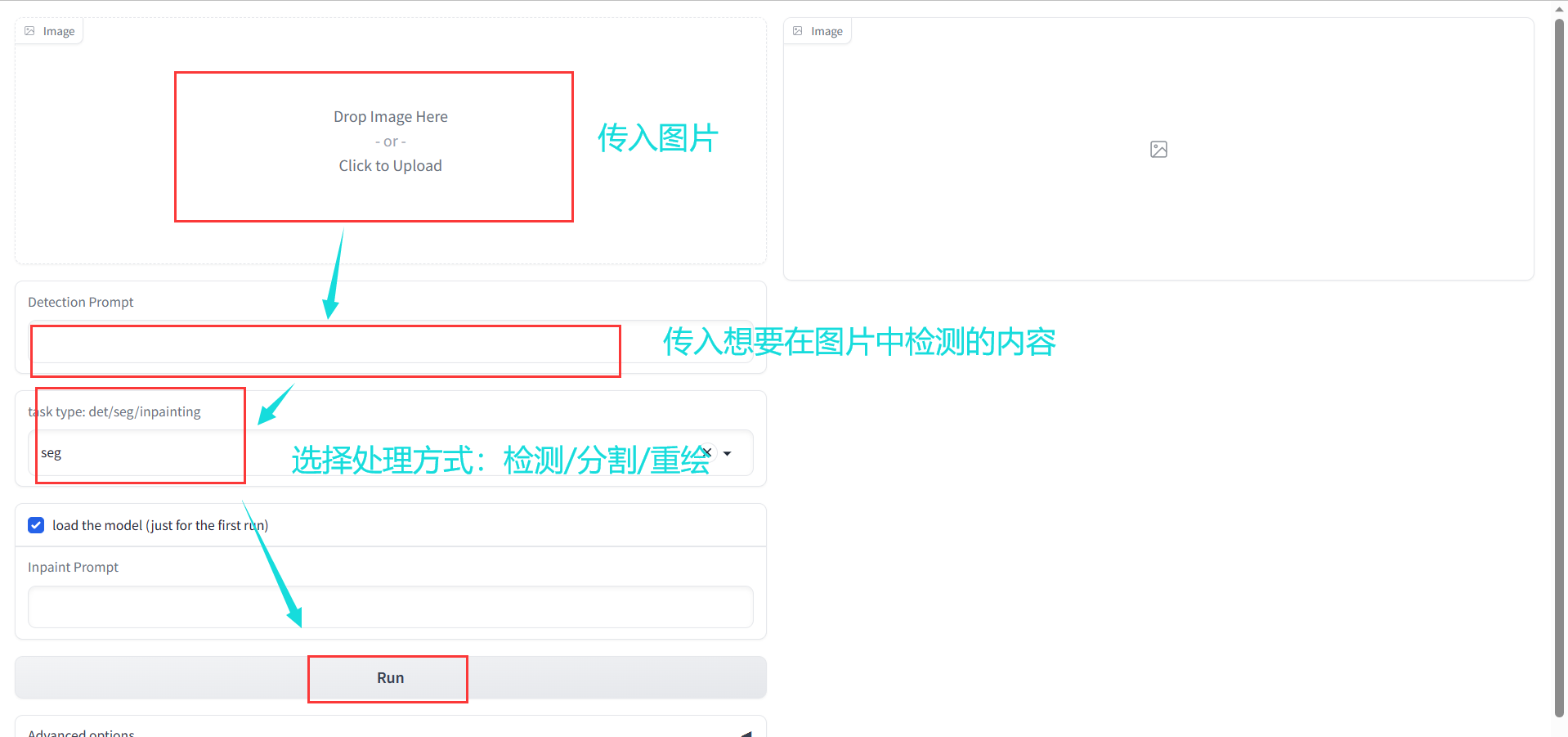
但毕竟是免费的在线运行平台,右侧执行的速度会很慢,取决于分配给你的算力大小。如果需要处理比较复杂的图像或输入的关键词,可能会显示算力不够。
下面是我在上课时随意拍了张照片并传入,运行的一个简单分割demo处理结果(用了5分钟,输入为:a door)

可见,结合GPT、Segment Anything与detection
官方使用inpaint绘制运行结果,传入的目标是 one girl
渲染语句是:mermaid with beautiful face(美丽的美人鱼)
就将检测出的一个女孩渲染成了美人鱼。
但我这里没有运行出来绘制的功能,可能是因为目前模型才刚刚试运行两天,不足以免费让我们跑这种费算力的模型,只能说期待后续的优化吧。

](https://img-blog.csdnimg.cn/20190122162025774.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzI3MTg1ODc5,size_16,color_FFFFFF,t_70)