文章目录
- 一. 张量概念
- 二. 张量的阶数
- 1. 标量(0阶张量)
- 2. 向量(1阶张量)
- 2. 矩阵(2阶张量)
- 3. 3阶张量与更高阶的张量
- 三. 张量属性及操作张量
- 1. 张量的关键属性
- 2. 在NumPy中操作张量
- 2.1. 选择某个图片数据
- 2.2. 截取图像数据
- 2.3. 沿着每个张量轴在任意两个索引之间选择切片。
- 3. 数据批量的概念
- 四. 张量的种类
- 1. 向量数据
- 2. 时间序列数据或序列数据
- 3. 图像数据
- 4. 视频数据
在前面的例子中,我们的数据存储在多维NumPy数组中,也叫作张量(tensor)。一般来说,目前所有机器学习系统都使用张量作为基本数据结构。
本文我们会了解如下概念:
- 张量
- 标量
- 轴、轴的个数:阶
- 维度:轴上元素的个数或轴的个数
- 向量、矩阵
- NumPy中的ndim、shape、dtype
- 张量切片
- 样本轴:第一个轴:每个元素都表示了一个样本(数据)
- 批量轴(批量维度):第一个元素
- 颜色通道
一. 张量概念
张量对这个领域非常重要,重要到TensorFlow都以它来命名。
究竟什么是张量呢?张量这一概念的核心在于,它是一个数据容器。
- 它包含的数据通常是数值数据,因此它是一个
数字容器。- 你可能对矩阵很熟悉,它是2阶张量。张量是矩阵向任意维度的推广
- [注意,张量的维度通常叫作轴(axis)]。
二. 张量的阶数
1. 标量(0阶张量)
仅包含一个数字的张量叫作标量(scalar),也叫标量张量、0阶张量或0维张量。
在NumPy中,一个float32类型或float64类型的数字就是一个标量张量(或标量数组)。
标量张量有0个轴(ndim == 0)。
张量轴的个数也叫作阶(rank)。
## 下面是一个NumPy标量。
>>> import numpy as np
>>> x = np.array(12)
>>> x
array(12)
## 用ndim属性来查看NumPy张量的轴的个数
>>> x.ndim
0
2. 向量(1阶张量)
数字组成的数组叫作向量(vector),也叫1阶张量或1维张量。
1阶张量只有一个轴。
# 下面是一个NumPy向量。
>>> x = np.array([12, 3, 6, 14, 7])
>>> x
array([12, 3, 6, 14, 7])
>>> x.ndim
1
这个向量包含5个元素,所以叫作5维向量。不要把5维向量和5维张量混为一谈!5维向量只有一个轴,沿着这个轴有5个维度,而5维张量有5个轴(沿着每个轴可能有任意个维度)。
- 维度(dimensionality)既可以表示沿着某个
轴上的元素个数(比如5维向量),也可以表示张量的轴的个数(比如5维张量),这有时会令人困惑。 - 对于后一种情况,更准确的术语是
5阶张量(张量的阶数即轴的个数),但5维张量这种模糊的说法很常见。
2. 矩阵(2阶张量)
向量组成的数组叫作矩阵(matrix),也叫2阶张量或2维张量。
矩阵有2个轴(通常叫作行和列)。你可以将矩阵直观地理解为矩形的数字网格。
# 下面是一个NumPy矩阵。
>>> x = np.array([[5, 78, 2, 34, 0],[6, 79, 3, 35, 1],[7, 80, 4, 36, 2]])
>>> x.ndim
2第一个轴上的元素叫作行(row),第二个轴上的元素叫作列(column)。
3. 3阶张量与更高阶的张量
将多个矩阵打包成一个新的数组,就可以得到一个3阶张量(或称为3维张量),你可以将其直观地理解为数字组成的立方体。
# 下面是一个3阶NumPy张量。
>>> x = np.array([[[5, 78, 2, 34, 0],[6, 79, 3, 35, 1],[7, 80, 4, 36, 2]],[[5, 78, 2, 34, 0],[6, 79, 3, 35, 1],[7, 80, 4, 36, 2]],[[5, 78, 2, 34, 0],[6, 79, 3, 35, 1],[7, 80, 4, 36, 2]]])
>>> x.ndim
3
将多个3阶张量打包成一个数组,就可以创建一个4阶张量,以此类推。
深度学习处理的一般是0到4阶的张量,但处理视频数据时可能会遇到5阶张量。
三. 张量属性及操作张量
1. 张量的关键属性
张量是由以下3个关键属性来定义的。
-
轴的个数(阶数)。
举例来说,3阶张量有3个轴,矩阵有2个轴。这在NumPy或TensorFlow等Python库中也叫张量的ndim。 -
形状。由整数元组来表达,元组的各元素,表示张量沿每个轴的维度大小(
元素个数)。
举例来说,前面的矩阵示例的形状为(3, 5),3阶张量示例的形状为(3, 3, 5)。向量的形状只包含一个元素,比如(5,),而标量的形状为空,即()。 -
数据类型(在Python库中通常叫作dtype)。这是张量中所包含数据的类型。
举例来说,张量的类型可以是float16、float32、float64、uint8等。在TensorFlow中,你还可能会遇到string类型的张量。
为了更具体地说明这一点,我们回头看一下在MNIST例子中处理的数据。
# 导入数据
from tensorflow.keras.datasets import mnist (train_images, train_labels), (test_images, test_labels) = mnist.load_data()# 张量train_images的轴的个数,即ndim属性。
train_images.ndim3# 形状:6万个矩阵、每个矩阵中有28个向量,每个向量的元素个数28
train_images.shape(60000, 28, 28)# 元素的数据类型
train_images.dtypeuint8train_images是由60 000个矩阵组成的数组,每个矩阵由28×28个整数组成。每个这样的矩阵都是一张灰度图像,元素取值在0和255之间。
数据可视化
我们用Matplotlib库来显示这个3阶张量中的第4个数字。

import matplotlib.pyplot as plt # 显示第4个数字
digit = train_images[4]
plt.imshow(digit, cmap=plt.cm.binary)
plt.show()# 显而易见,对应的标签是整数9。
train_labels[4] 9
2. 在NumPy中操作张量
选择张量的特定元素叫作张量切片(tensor slicing)。 有如下三种方式来操作张量
2.1. 选择某个图片数据
在前面的例子中,我们使用语法train_images[i]来沿着第一个轴选择某张数字图像。
我们来看一下对NumPy数组可以做哪些张量切片运算。
2.2. 截取图像数据
# 下面这个例子选择第10~100个数字(不包括第100个),并将它们放在一个形状为(90, 28, 28)的数组中。
my_slice = train_images[10:100]
my_slice.shape
# (90, 28, 28)# 等同于下面这个更详细的写法——给出切片沿着每个张量轴的起始索引和结束索引。
# 注意,:等同于选择整个轴。
my_slice = train_images[10:100, :, :]
my_slice.shape
# (90, 28, 28)my_slice = train_images[10:100, 0:28, 0:28]
my_slice.shape
# (90, 28, 28)
2.3. 沿着每个张量轴在任意两个索引之间选择切片。
# 举例来说,要在所有图像的右下角选出14像素×14像素的区域,可以这么做:
my_slice = train_images[:, 14:, 14:]# 也可以使用负数索引。
# 与Python列表类似,负数索引表示与当前轴终点的相对位置。
# 要在图像中心裁剪出14像素×14像素的区域,可以这么做。
my_slice = train_images[:, 7:-7, 7:-7]
3. 数据批量的概念
样本轴的概念:
深度学习中所有张量的第一个轴(也就是轴0,因为索引从0开始)都是样本轴(samples axis,有时也叫样本维度(samples dimension))。 在MNIST例子中,
样本轴中每个元素都是一张数字图像。
分批处理数据集:
深度学习模型不会一次性处理整个数据集,而是将数据拆分成小批量。
# 具体来看,下面是MNIST数据集的一个批量,批量大小为128。
batch = train_images[:128]# 然后是下一个批量。batch = train_images[128:256]# 再然后是第n个批量。n = 3
batch = train_images[128 * n:128 * (n + 1)]
对于这种批量张量,第一个轴(轴0)叫作批量轴(batch axis)或批量维度(batch dimension)。
四. 张量的种类
我们来具体看看你以后会遇到的几个数据张量实例。你要处理的数据几乎总是属于下列类别。
[张量种类]
向量数据:形状为(samples, features)的2阶张量,每个样本都是一个
数值向量。时间序列数据或序列数据:形状为(samples, timesteps, features)的3阶张量,每个样本都是
特征向量组成的序列(序列长度为timesteps)。图像数据:形状为(samples, height, width, channels)的4阶张量,每个样本都是一个
二维像素网格,每个像素则由一个“通道”(channel)向量表示。视频数据:形状为(samples, frames, height, width, channels)的5阶张量,每个样本都是
由图像组成的序列(序列长度为frames)。
1. 向量数据
每个数据点都被编码为一个向量,因此一个数据批量就被编码为一个2阶张量(由向量组成的数组),其中第1个轴是样本轴,第2个轴是特征轴(features axis)。
[如下两个例子]
保险精算数据集。我们考虑每个人的年龄、性别和收入。每个人可表示为包含3个值的向量,整个数据集包含100 000人,因此可存储在形状为(100000, 3)的2阶张量中。
文本文档数据集。我们将每个文档表示为每个单词在其中出现的次数。每个文档可被编码为包含20 000个值(每个单词都要排好序?然后记录每个单词出现的次数,总共20000个单词)的向量(每个值对应字典中每个单词的出现次数),整个数据集包含500个文档,因此可存储在形状为(500, 20000)的张量中。
2. 时间序列数据或序列数据
当时间(或序列顺序)对数据很重要时,应该将数据存储在带有时间轴的3阶张量中。每个样本可被编码为一个向量序列(2阶张量),因此一个数据批量就被编码为一个3阶张量,如图所示。
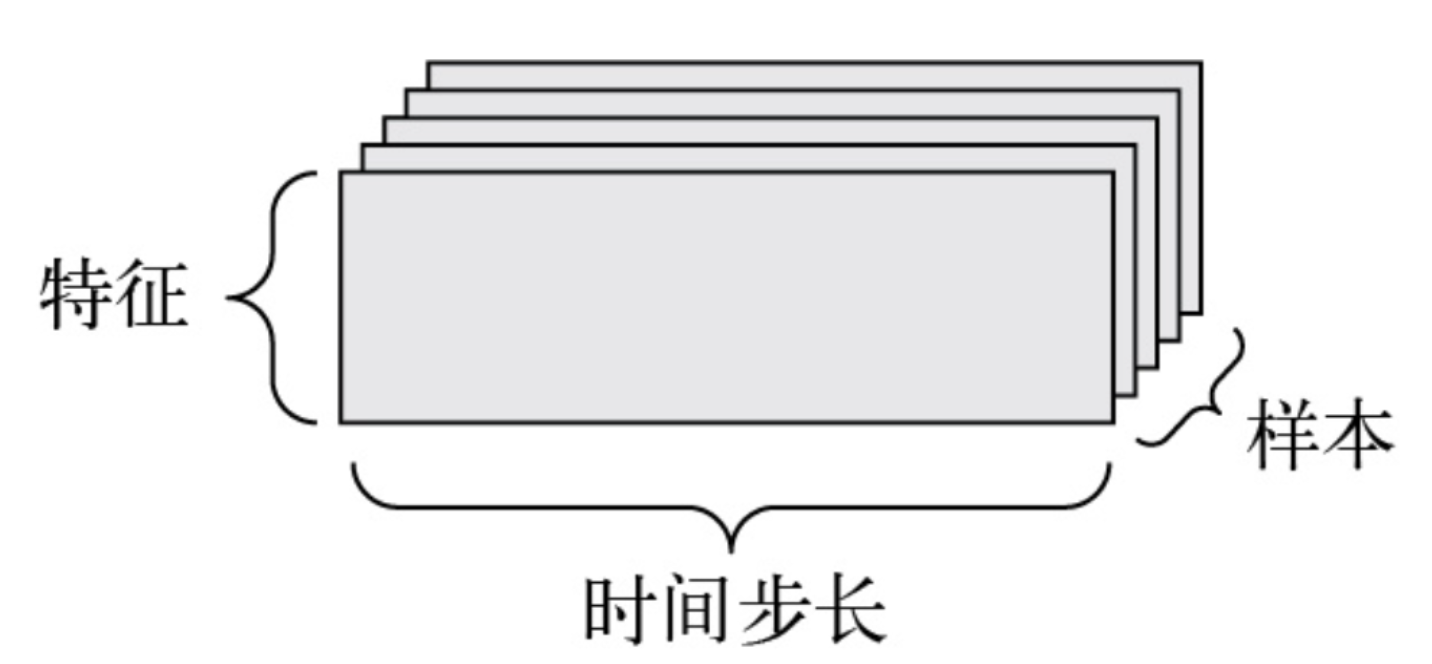
按照惯例,时间轴始终是第2个轴(索引为1的轴)。
[两个例子]
股票价格数据集。每一分钟,我们将股票的当前价格、前一分钟最高价格和前一分钟最低价格保存下来。因此每一分钟被编码为一个3维向量,一个交易日被编码为一个形状为(390, 3)的矩阵(一个交易日有390分钟),250天的数据则保存在一个形状为(250, 390, 3)的3阶张量中。在这个例子中,每个样本是一天的股票数据。
推文数据集。我们将每条推文编码为由280个字符组成的序列,每个字符又来自于包含128个字符的字母表。在这种情况下,每个字符可以被编码为大小为128的二进制向量(只有在该字符对应的索引位置取值为1,其他元素都为0)。那么每条推文可以被编码为一个形状为(280, 128)的2阶张量,包含100万条推文的数据集则被存储在一个形状为(1000000, 280, 128)的张量中。
3. 图像数据
图像通常具有3个维度:高度、宽度和颜色深度。
虽然灰度图像(比如MNIST数字图像)只有一个颜色通道,因此可以保存在2阶张量中,但按照惯例,图像张量都是3阶张量。
对于灰度图像,
其颜色通道只有一维。因此,如果图像大小为256×256,
- 那么由128张
灰度图像组成的批量可以保存在一个形状为(128, 256, 256, 1)的张量中,- 由128张
彩色图像组成的批量则可以保存在一个形状为(128, 256, 256, 3)的张量中,如图所示。
![![[Pasted image 20240504232713.png]]](https://img-blog.csdnimg.cn/direct/1b10d44c3f62431a81ec7812ecacb895.png)
图像张量的形状有两种约定:
- 通道在后(channels-last)的约定(这是TensorFlow的标准)
- 通道在前(channels-first)的约定(使用这种约定的人越来越少)。
4. 视频数据
视频数据是现实世界中为数不多的需要用到5阶张量的数据类型。
视频可以看作帧的序列,每一帧都是一张彩色图像。由于每一帧都可以保存在一个形状为(height, width, color_depth)的3阶张量中,因此一个视频(帧的序列)可以保存在一个形状为(frames, height, width,color_depth)的4阶张量中,由多个视频组成的批量则可以保存在一个形状为(samples,frames, height, width, color_depth)的5阶张量中。
[举个例子]
- 一个尺寸为144×256的60秒YouTube视频片段,以每秒4帧采样,那么这个视频共有240帧。
4个这样的视频片段组成的批量将保存在形状为(4, 240, 144, 256, 3)的张量中。这个张量共包含106 168 320个值!- 如果张量的数据类型(dtype)是float32,每个值都是32位,那么这个张量共有405 MB。好大!
你在现实生活中遇到的视频要小得多,因为它们不以float32格式存储,而且通常被大大压缩(比如MPEG格式)。
参考:
《Python深度学习(第二版)》–弗朗索瓦·肖莱
https://www.redhat.com/zh/topics/digital-transformation/what-is-deep-learning