链接: 来源:link
1、基础知识
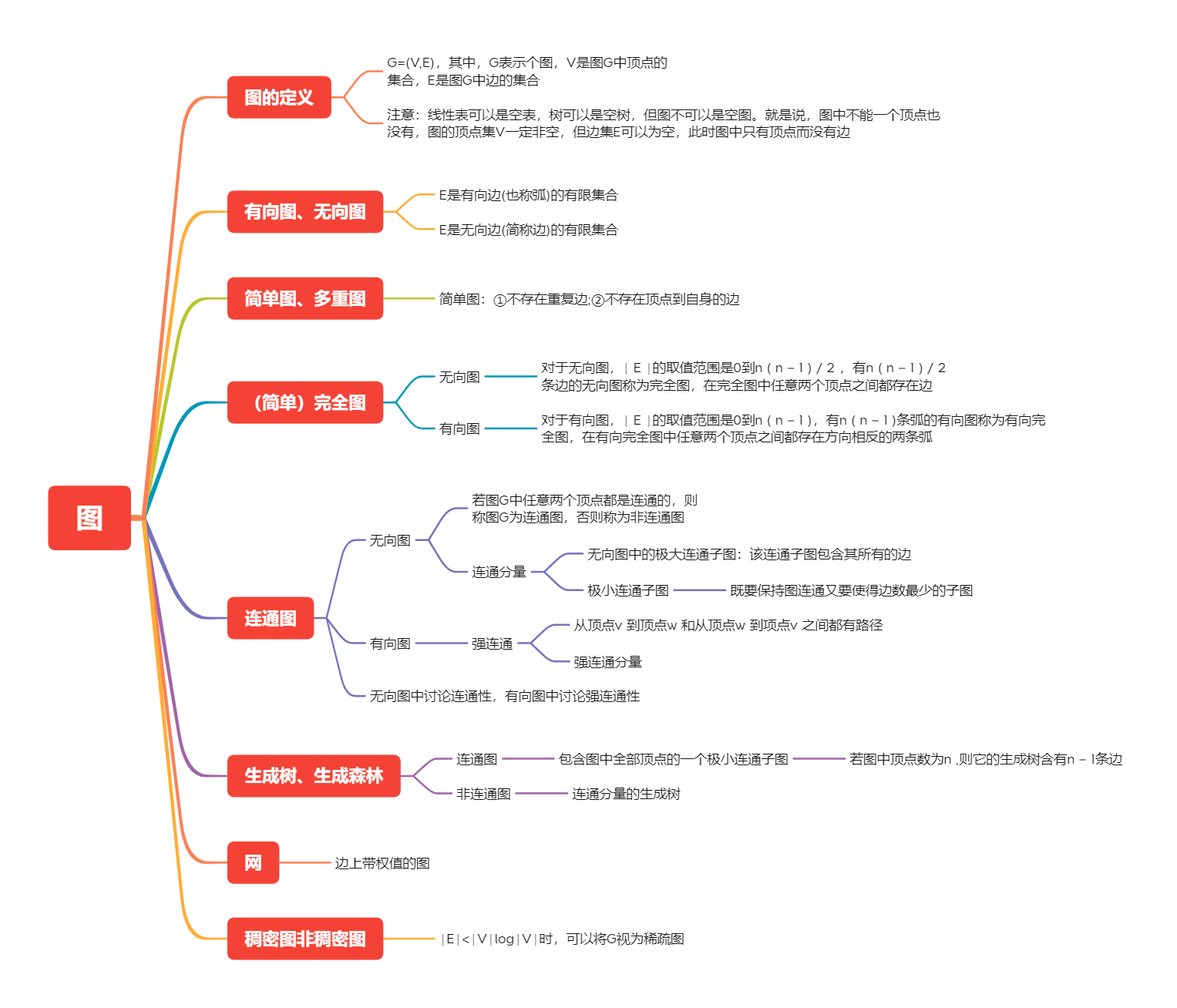
2、图的存储结构
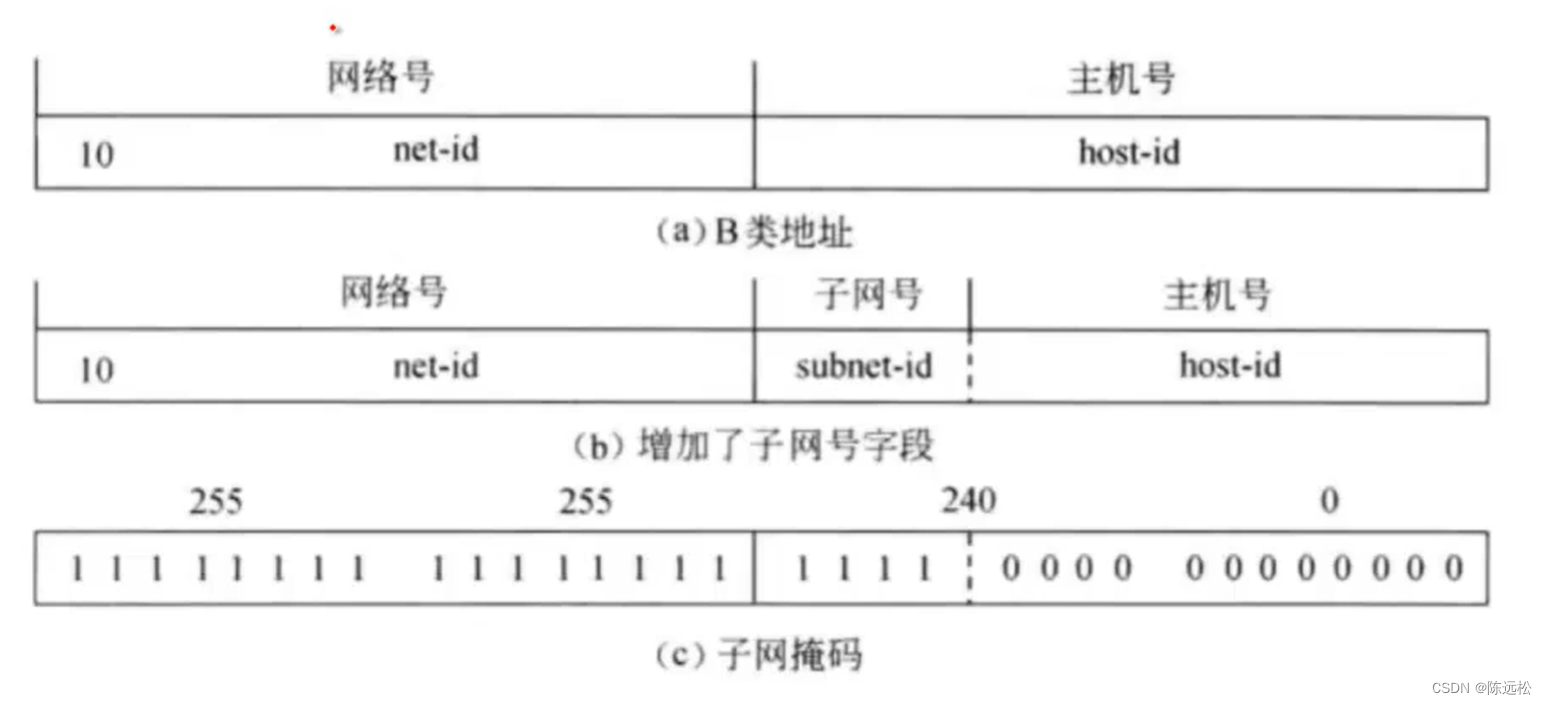
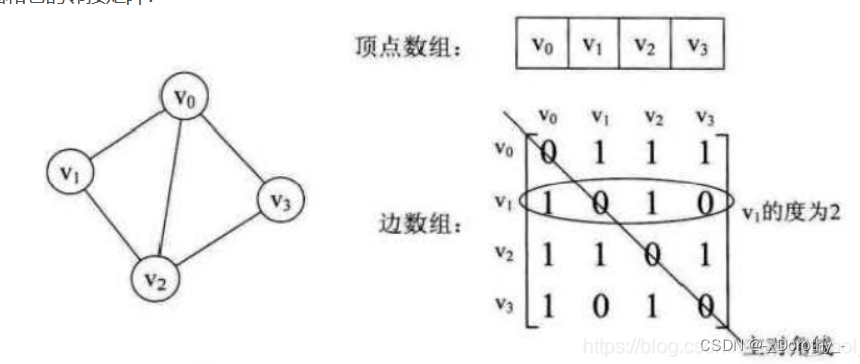
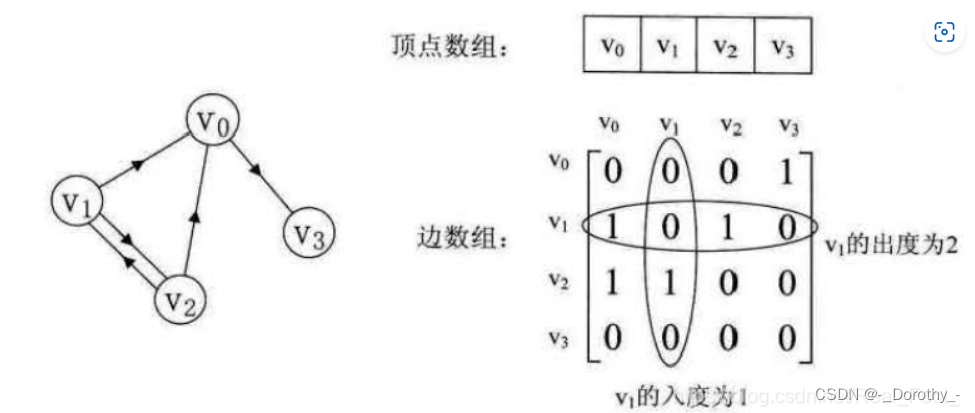
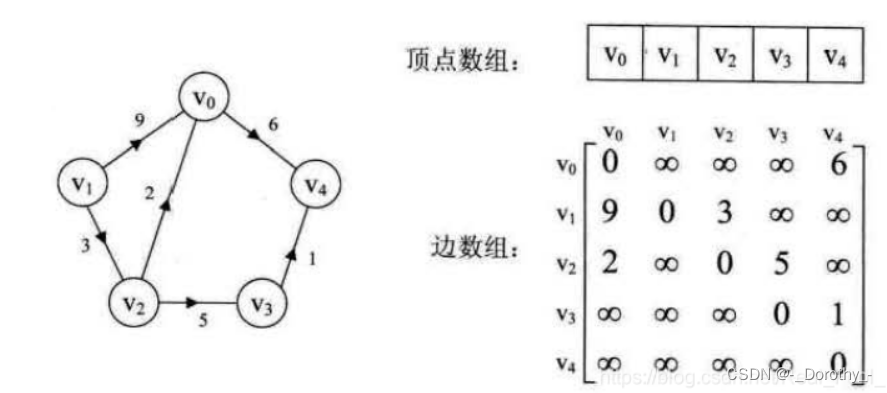
1、邻接矩阵
注意:
- 邻接矩阵表示法的空间复杂度为O(n^2), 其中n为图的顶点数∣V∣。
- 用邻接矩阵法存储图,很容易确定图中任意两个顶点之间是否有边相连。但是,要确定图中有多少条边,则必须按行、按列对每个元素进行检测,所花费的时间代价很大
- 稠密图适合使用邻接矩阵的存储表示。
2、邻接表
所谓邻接表,是指对图G中的每个顶点vi建立一个单链表, 第i个单链表中的结点表示依附于顶点vi的边(对于有向图则是以顶点vi为尾的弧),这个单链表就称为顶点V;的边表(对于有向图则称为出边表)。边表的头指针和顶点的数据信息采用顺序存储(称为顶点表),所以在邻接表中存在两种结点:顶点表结点和边表结点

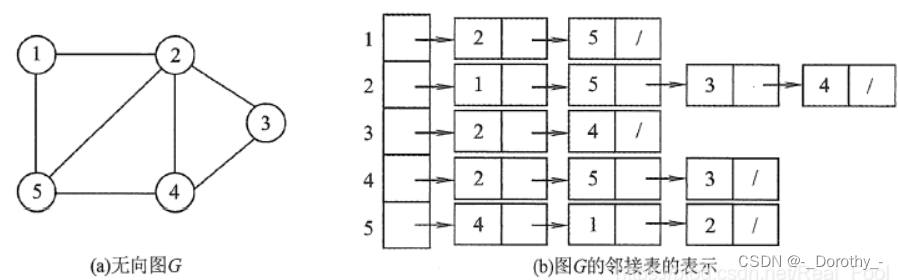
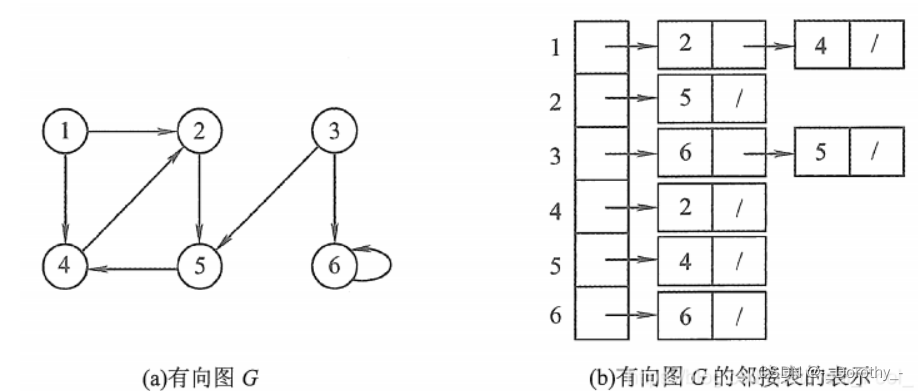
- 1.若G为无向图,则所需的存储空间为O(|V | + 2|E|);若G为有向图,则所需的存储空间为O(|V| + |E|)。前者的倍数2是由于无向图中,每条边在邻接表中出现了两次
- 2.对于稀疏图,采用邻接表表示将极大地节省存储空间。
- 3.在邻接表中,给定顶点,能很容易地找出它的所有邻边,因为只要读取它的邻接表。在邻接矩阵中,相同的操作则需要扫描一行,花费的时间为O(n)。但是,若要确定给定的两个顶点间是否存在边,则在邻接矩阵中可以立刻查到,而在邻接表中则需要在相应结点对应的边表中查找另一点,效率较低。
- 4.在有向图的邻接表表示中,求一个给定顶点的出度只需计算其邻接表中的结点个数;但求其颠点的入度则需要遍历全部的邻接表。因此,也有人采用逆邻接表的存储方式来加速求解给定顶点的入度。当然,这实际上与邻接表存储方式是类似的。
- 5.图的邻接表并不唯一,因为在每 个顶点对应的单链表中,各边结点的链接次可以是任意的,它取决于建立邻接表的算法及边的 输入次序。
邻接表:适合稀疏图,空间复杂度低,但是求出度很容易、求入度要遍历所有边表
邻接矩阵:不适合稀疏图,空间复杂度O(n^2),出度是遍历第i行,入度遍历第i列
3、图的实现——邻接表
(1)无向图的实现
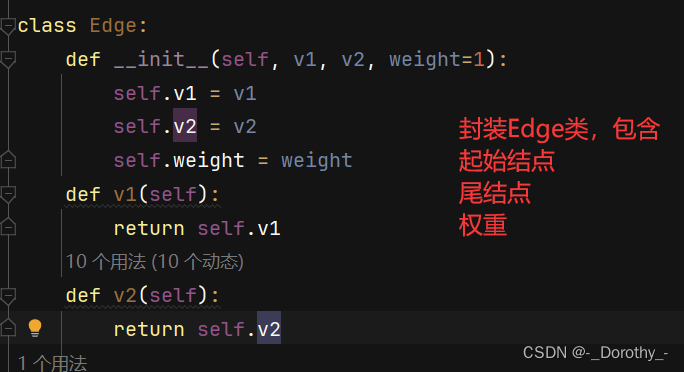
class Edge:def __init__(self, v1, v2, weight=1):self.v1 = v1self.v2 = v2self.weight = weightdef v1(self):return self.v1def v2(self):return self.v2
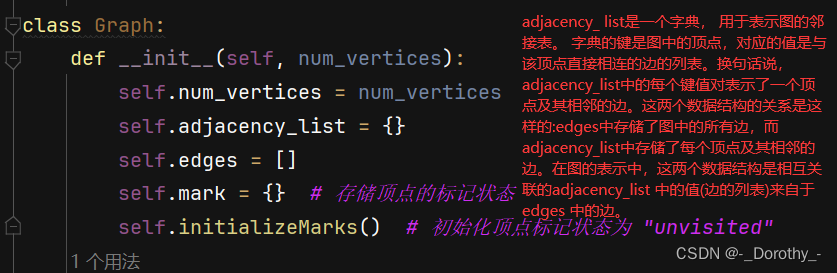
class Graph:def __init__(self, num_vertices):self.num_vertices = num_verticesself.adjacency_list = {}self.edges = []self.mark = {} # 存储顶点的标记状态self.initializeMarks() # 初始化顶点标记状态为 "unvisited"def initializeMarks(self):for i in range(self.num_vertices):self.mark[i] = "unvisited"def n(self):return self.num_verticesdef e(self):return len(self.edges)def first(self, v):if v in self.adjacency_list:edges = self.adjacency_list[v]return edges[0] if edges else Nonereturn Nonedef next(self, w):#边w的下一条边v1 = w.v1v2 = w.v2if v1 in self.adjacency_list:edges = self.adjacency_list[v1]index = edges.index(w)#返回w的索引值return edges[index + 1] if index + 1 < len(edges) else Nonereturn Nonedef isEdge(self, w):return w in self.edgesdef isEdgeByVertices(self, i, j):for edge in self.edges:if (edge.v1 == i and edge.v2 == j) or (edge.v1 == j and edge.v2 == i):return Truereturn Falsedef v1(self, w):return w.v1def v2(self, w):return w.v2def setEdge(self, i, j, weight):#创建边的过程中假如没有点会自动创建edge1 = Edge(i, j, weight)edge2 = Edge(j, i, weight)self.edges.append(edge1)if i not in self.adjacency_list:self.adjacency_list[i] = []if j not in self.adjacency_list:self.adjacency_list[j] = []self.adjacency_list[i].append(edge1)self.adjacency_list[j].append(edge2)def setEdgebyweight(self, w, weight):w.weight = weightdef delEdge(self, w):if w in self.edges:self.edges.remove(w)self.adjacency_list[w.v1].remove(w)self.adjacency_list[w.v2].remove(w)def delEdgebyvertex(self, i, j):for edge in self.edges:if (edge.v1 == i and edge.v2 == j) or (edge.v1 == j and edge.v2 == i):self.edges.remove(edge)self.adjacency_list[edge.v1].remove(edge)self.adjacency_list[edge.v2].remove(edge)breakdef weightbyvertex(self, i, j):for edge in self.edges:if (edge.v1 == i and edge.v2 == j) or (edge.v1 == j and edge.v2 == i):return edge.weightreturn Nonedef weight(self, w):return w.weightdef setMark(self, v, val):#用来检验是否被访问过if v in self.mark:self.mark[v] = valdef getMark(self, v):return self.mark[v] # 默认未访问过的顶点标记为 "unvisited"
注意:
- adjacency_ list是一个字典, 用于表示图的邻接表。
字典的键是图中的顶点,对应的值是与该顶点直接相连的边的列表。换句话说,adjacency_list中的每个键值对表示了一个顶点及其相邻的边。这两个数据结构的关系是这样的:edges中存储了图中的所有边,而adjacency_list中存储了每个顶点及其相邻的边。在图的表示中,这两个数据结构是相互关联的adjacency_list
中的值(边的列表)来自于edges 中的边。 - setMark getMark 这两个方法提供了一种在图中附加额外信息的方法,以便在算法中进行状态跟踪或其他操作时使用
(2)实例
# 创建一个图实例
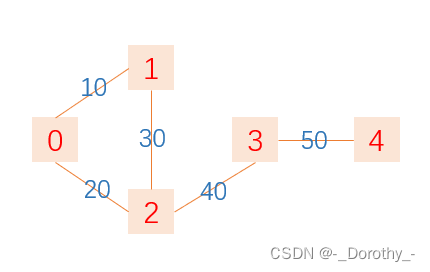
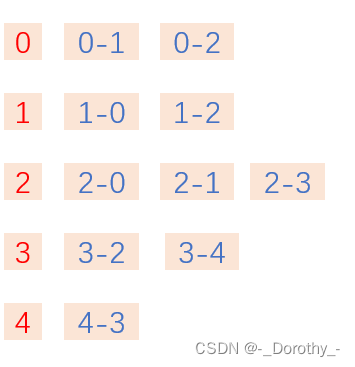
g = Graph(5)
# 添加顶点之间的边
g.setEdge(0, 1, 10)
g.setEdge(0, 2, 20)
g.setEdge(1, 2, 30)
g.setEdge(2, 3, 40)
g.setEdge(3, 4, 50)
# 打印图的顶点数和边数
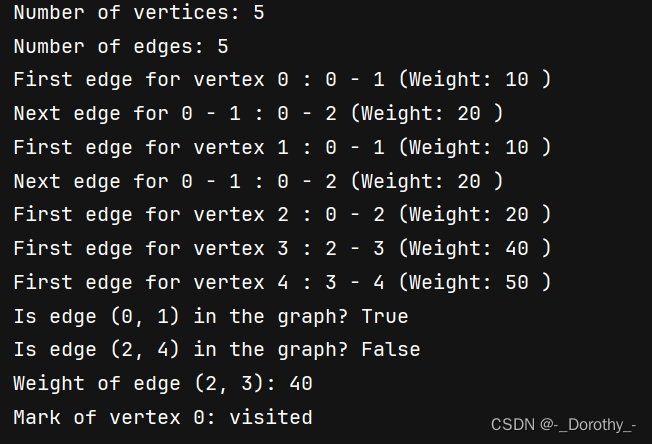
print("Number of vertices:", g.n())
print("Number of edges:", g.e())
# 打印每个顶点的第一条边和每条边的下一条边
for v in range(g.n()):first_edge = g.first(v)if first_edge:print("First edge for vertex", v, ":", first_edge.v1, "-", first_edge.v2, "(Weight:", first_edge.weight, ")")next_edge = g.next(first_edge)while next_edge:print("Next edge for", first_edge.v1, "-", first_edge.v2, ":", next_edge.v1, "-", next_edge.v2, "(Weight:", next_edge.weight, ")")next_edge = g.next(next_edge)
# 判断是否存在某条边
print("Is edge (0, 1) in the graph?", g.isEdgeByVertices(0, 1))
print("Is edge (2, 4) in the graph?", g.isEdgeByVertices(2, 4))
# 获取边的权重
print("Weight of edge (2, 3):", g.weightbyvertex(2, 3))
# 设置顶点的标记
g.setMark(0,"visited")
print("Mark of vertex 0:", g.getMark(0))
结果
(3)有向图的实现
在next方法处做修改
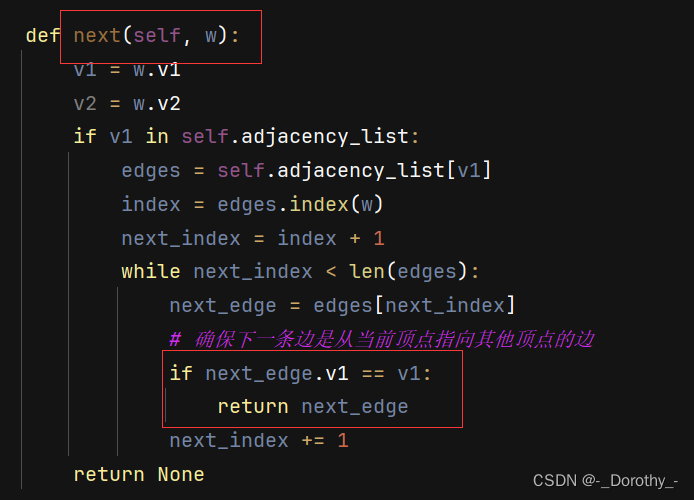
from graphviz import Digraphclass Graph:def __init__(self, num_vertices):self.num_vertices = num_verticesself.adjacency_list = {}self.edges = []self.mark = {}self.initializeMarks() # 初始化顶点标记状态为 "unvisited"def initializeMarks(self):for i in range(self.num_vertices):self.mark[i] = "unvisited"def n(self):return self.num_verticesdef first(self, v):if v in self.adjacency_list:edges = self.adjacency_list[v]return edges[0] if edges else Nonereturn Nonedef next(self, w):v1 = w.v1v2 = w.v2if v1 in self.adjacency_list:edges = self.adjacency_list[v1]index = edges.index(w)next_index = index + 1while next_index < len(edges):next_edge = edges[next_index]# 确保下一条边是从当前顶点指向其他顶点的边if next_edge.v1 == v1:return next_edgenext_index += 1return Nonedef isEdge(self, w):return w in self.edgesdef setEdge(self, i, j, weight):edge = Edge(i, j, weight)self.edges.append(edge)if i not in self.adjacency_list:self.adjacency_list[i] = []self.adjacency_list[i].append(edge)def setMark(self, v, val):if v in self.mark:self.mark[v] = valdef getMark(self, v):return self.mark[v]class Edge:def __init__(self, v1, v2, weight=1):self.v1 = v1self.v2 = v2self.weight = weightdef visualize_graph(graph):dot = Digraph()for v, edges in graph.adjacency_list.items():for edge in edges:dot.node(str(edge.v1))dot.node(str(edge.v2))dot.edge(str(edge.v1), str(edge.v2), label=str(edge.weight))dot.render('directed_graph', format='png', cleanup=True)# 创建一个图实例
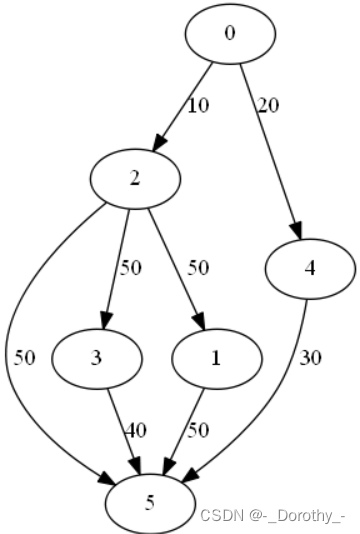
g = Graph(6)
# 添加顶点之间的边
g.setEdge(0, 2, 10)
g.setEdge(0, 4, 20)
g.setEdge(4, 5, 30)
g.setEdge(3, 5, 40)
g.setEdge(2, 3, 50)
g.setEdge(2, 5, 50)
g.setEdge(2, 1, 50)
g.setEdge(1, 5, 50)# 可视化有向图
visualize_graph(g)结果
4、图的遍历
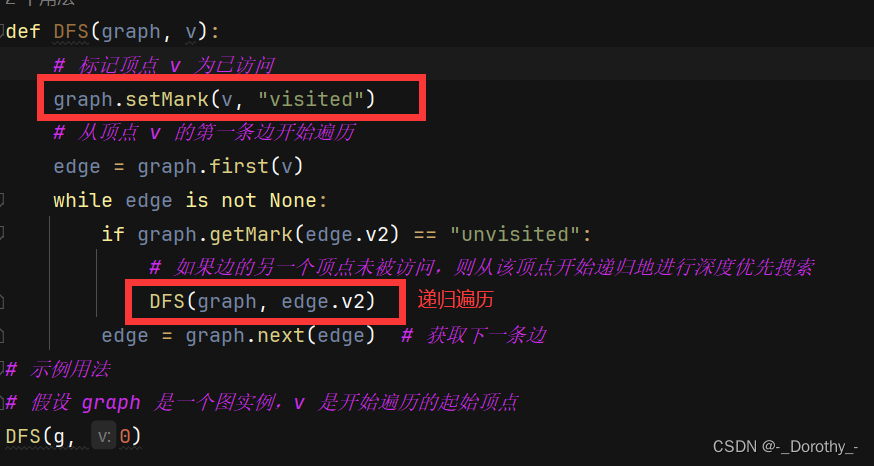
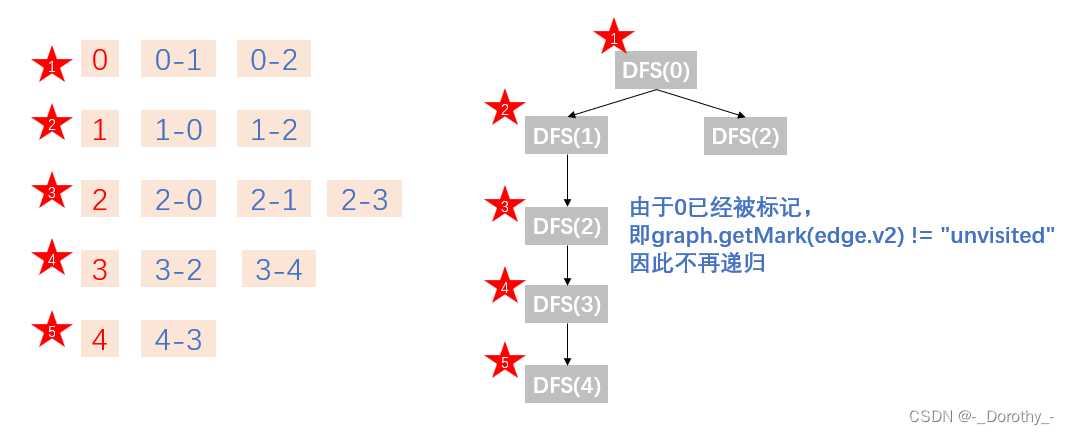
(1)DFS(depth first search)深度优先搜索
(类似二叉树的先序遍历)
结果

复习二叉树的DFS先/中/后序遍历
链接: 二叉树的遍历——DFS深度优先搜索——先(根)序遍历、中序遍历、后序遍历
注意
若图不是连通图,从顶点v发起的遍历结束并不意味着图的遍历结束,如果还有v到达不了的,要在剩余的中间重新选一个
DFS生成树
# 创建一个图实例
g = Graph(6)
# 添加顶点之间的边
g.setEdge(0, 2, 10)
g.setEdge(0, 4, 20)
g.setEdge(4, 5, 30)
g.setEdge(3, 5, 40)
g.setEdge(2, 3, 50)
g.setEdge(2, 5, 50)
g.setEdge(2, 1, 50)
g.setEdge(1, 5, 50)
# 设置顶点的标记
g.setMark(0, "unvisited") # 重置标记状态
for v in range(g.n()):if g.getMark(v) == "unvisited":root = TreeNode(v)DFS(g, v, parent=root)break
dot = Digraph()def build_tree(node, parent=None):dot.node(str(node.vertex))if parent is not None:dot.edge(str(parent.vertex), str(node.vertex))for child in node.children:build_tree(child, parent=node)build_tree(root)# 显示图形
dot.render('graph_tree', format='png', cleanup=True)
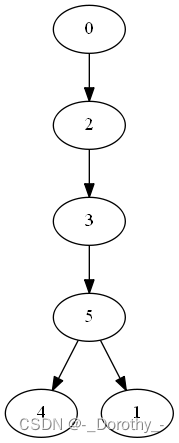
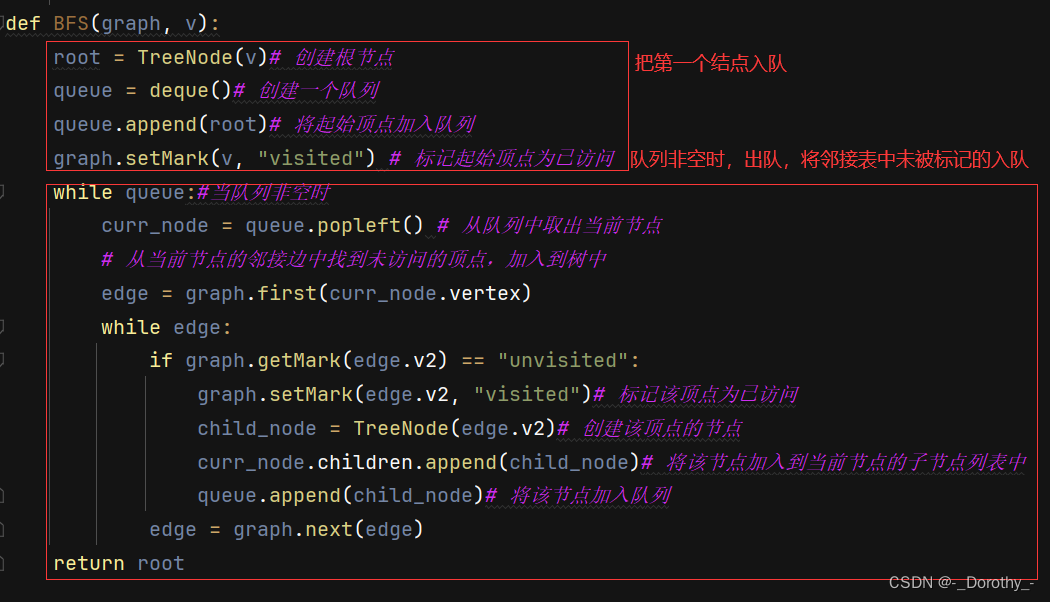
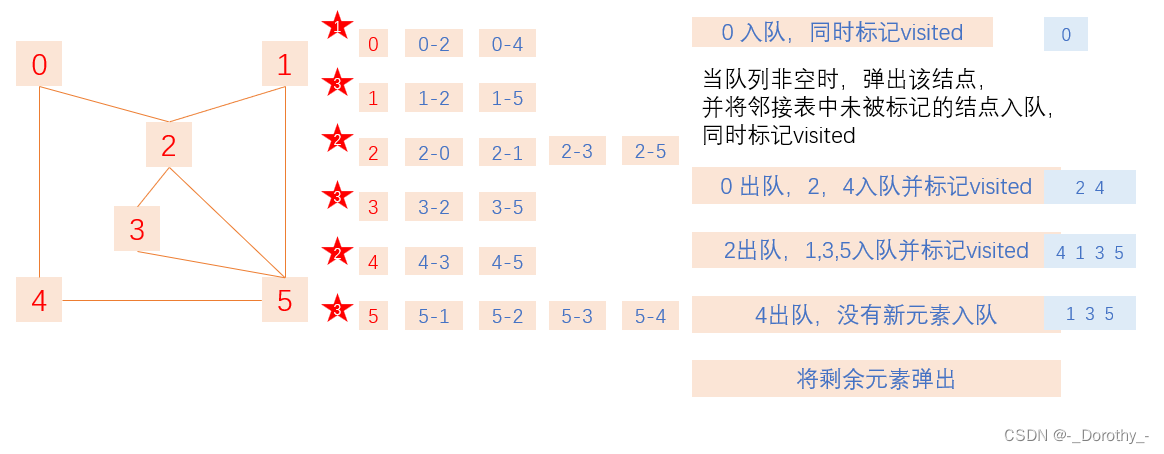
(2)BFS(breadth first search)广度优先搜索
如果说图的深度优先遍历类似树的前序遍历,那么图的广度优先遍历就类似于树的层序遍历了。

注意
- pop():这是列表方法,用于从列表的末尾删除并返回元素。如果列表为空,则会引发 IndexError。
popleft():这是双端队列(deque)方法,用于从队列的左侧删除并返回元素。如果队列为空,则会引发 IndexError。
因此,主要区别在于 pop() 是列表方法,而 popleft() 是双端队列方法。如果你需要在队列的左侧执行弹出操作,你应该使用
popleft() 方法。
BFS生成树
def visualize_bfs_tree(root):dot = Digraph()# 使用 BFS 遍历生成树,构建图形def build_tree(node, parent=None):dot.node(str(node.vertex))if parent is not None:dot.edge(str(parent.vertex), str(node.vertex))for child in node.children:build_tree(child, parent=node)build_tree(root)# 显示图形dot.render('bfs_tree', format='png', cleanup=True)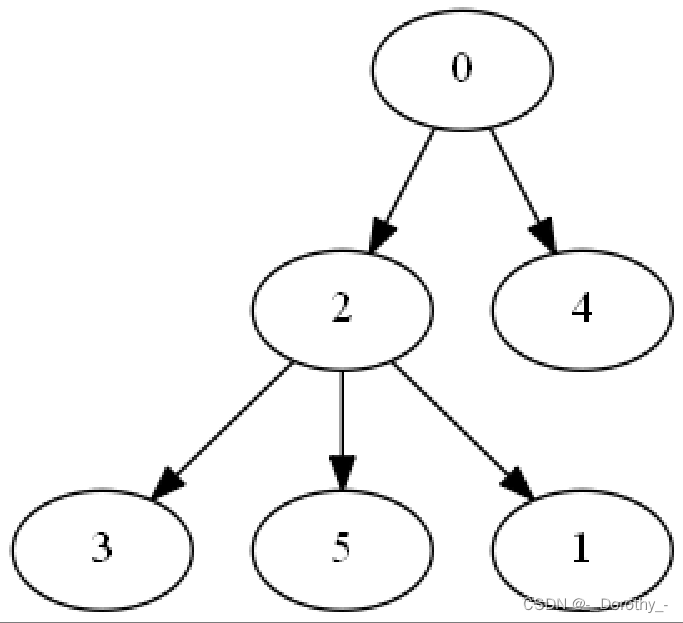
改进——增加外循环使其对非连通图同样适用
def BFS(graph, v):roots = [] # 存储所有连通分量的根节点while True:# 找到一个未被访问的顶点作为起始顶点start_vertex = Nonefor vertex in range(graph.n()):if graph.getMark(vertex) == "unvisited":start_vertex = vertexbreak# 如果所有顶点都已被访问,则退出循环if start_vertex is None:breakroot = TreeNode(start_vertex) # 创建一个连通分量的根节点queue = deque() # 创建一个队列queue.append(root) # 将根节点加入队列graph.setMark(start_vertex, "visited") # 标记起始顶点为已访问while queue: # 当队列非空时curr_node = queue.popleft() # 从队列中取出当前节点# 遍历当前节点的邻居顶点edge = graph.first(curr_node.vertex)while edge:if graph.getMark(edge.v2) == "unvisited":graph.setMark(edge.v2, "visited") # 标记邻居顶点为已访问child_node = TreeNode(edge.v2) # 创建邻居顶点的节点curr_node.children.append(child_node) # 将该节点加入到当前节点的子节点列表中queue.append(child_node) # 将该节点加入队列edge = graph.next(edge)roots.append(root) # 将当前连通分量的根节点加入列表return roots
(3)图的遍历与连通性
图的遍历算法可以用来判断图的连通性。
对于无向图来说,若无向图是连通的,则从任一结点出发, 仅需一次遍历就能够访问图中的所有顶点;若无向图是非连通的,则从某一个顶点出发,一次遍历只能访问到该顶点所在连通分量的所有顶点,而对于图中其他连通分量的顶点,则无法通过这次遍历访问。对于有向图来说,若从初始点到图中的每个顶点都有路径,则能够访问到图中的所有顶点,否则不能访问到所有顶点。
5、最小生成树Minimunspanning—tree
- 带权、连通、无向图的生成树中——权值之和最小的那棵
- 最小生成树的性质: