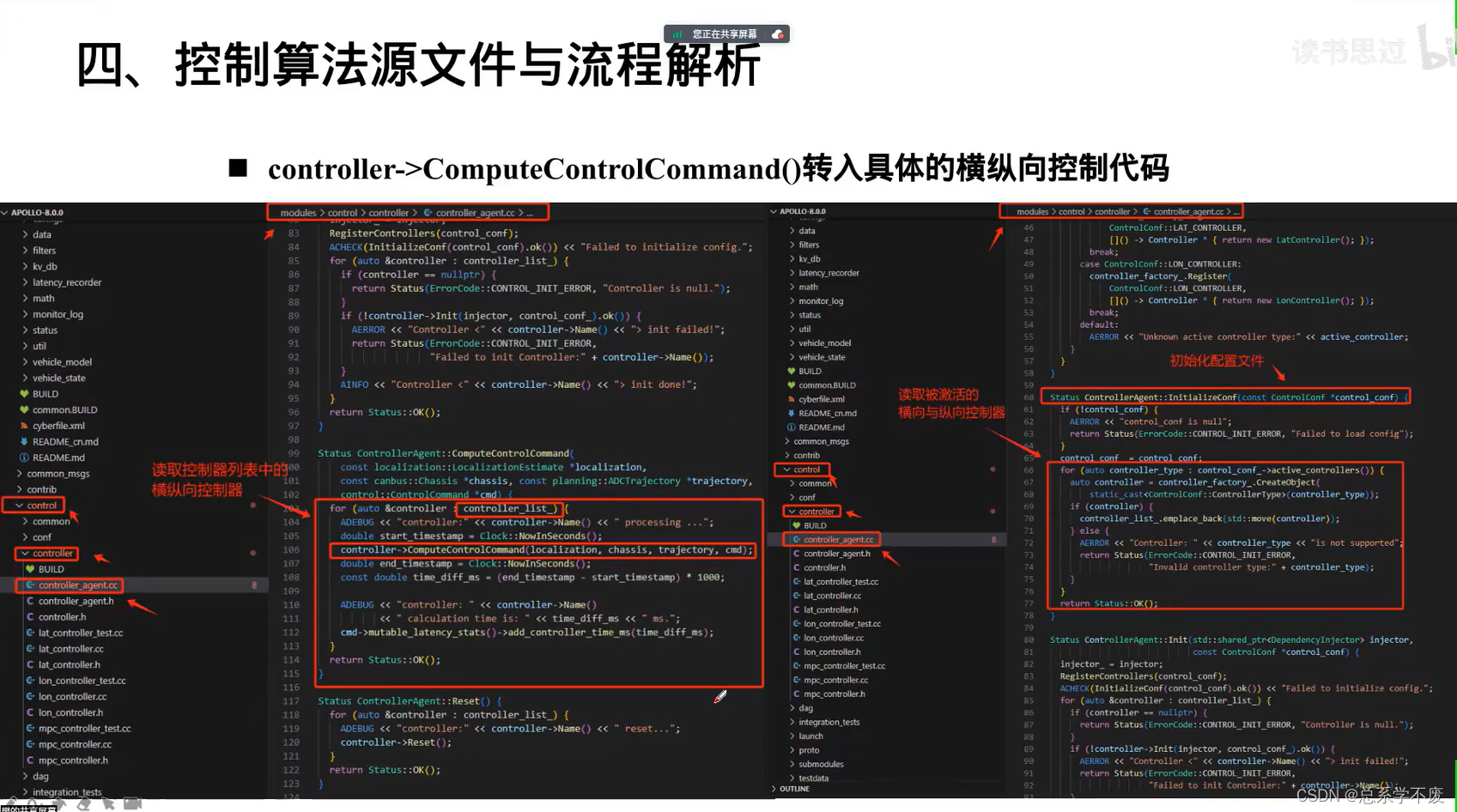
Week 01 of Neural Networks and Deep Learning
Course Certificate

本文是学习 https://www.coursera.org/learn/neural-networks-deep-learning 这门课的笔记
Course Intro
文章目录
- Week 01 of Neural Networks and Deep Learning
- [0] Welcome to the Deep Learning Specialization
- Welcome
- [1] Introduction to Deep Learning
- What is a Neural Network?
- Supervised Learning with Neural Networks
- Why is Deep Learning taking off?
- About this Course
- [2] Lecture Notes (Optional)
- [3] Quiz: Introduction to Deep Learning
- 其他
- 英文发音
- 后记
[0] Welcome to the Deep Learning Specialization
Welcome
Hello and welcome.
As you probably know, deep learning has already transformed traditional internet businesses like web search and advertising. But deep learning is also enabling brand new products and businesses and ways of helping people to be created. Everything ranging from better healthcare, where deep learning is getting really good at reading X-ray images to delivering personalized education, to precision agriculture, to even self driving cars and many others.
Finish the sequence of courses (specialization)
If you want to learn the tools of deep learning and be able to apply them to build these amazing things, I want to help you get there. When you finish the sequence of courses on Coursera, called the specialization, you will be able to put deep learning onto your resume with confidence.
Over the next decade, I think all of us have an opportunity to build an amazing world, amazing society, that is AI-powered, and I hope that you will play a big role in the creation of this AI-powered society. So that, let’s get started.
AI’s benefits

I think that AI is the new electricity. Starting about 100 years ago, the electrification of our society transformed every major industry, everything ranging from transportation, manufacturing, to healthcare, to communications and many more.
And I think that today, we see a surprisingly clear path for AI to bring about an equally big transformation.
And of course, the part of AI that is rising rapidly and driving a lot of these developments, is deep learning. So today, deep learning is one of the most highly sought after skills in the technology world. And through this course, and a few courses after this one, I want to help you to gain and master those skills.
What you will learn in this specialization
So here is what you will learn in this sequence of courses also called a specialization on Coursera.
The first course
In the first course, you will learn about the foundations of neural networks, you will learn about neural networks and deep learning. This video that you are watching is part of this first course, which last four weeks in total.
And each of the five courses in the specialization will be about two to four weeks, with most of them actually shorter than four weeks.
But in this first course, you will learn how to build a neural network, including a deep neural network, and how to train it on data. And at the end of this course, you will be able to build a deep neural network to recognize, guess what? Cats. For some reason, there is a cat meme running around in deep learning. And so, following tradition in this first course, we will build a cat recognizer.
The second course
Then in the second course, you will learn about the practical aspects of deep learning.
So you will learn, now that you have built a neural network, how to actually get it to perform well. So you learn about hyperparameter tuning, regularization, how to diagnose bias, and variants, and advance optimization algorithms, like momentum, armrest, prop, and the ad authorization algorithm.
Sometimes it seems like there is a lot of tuning, even some black magic in how you build a new network. So the second course, which is just three weeks, will demystify some of that black magic.
The third course
In the third course, which is just two weeks, you will learn how to structure your machine learning project.
It turns out that the strategy for building a machine learning system has changed in the era of deep learning.
So for example, the way you split your data into train, development or dev, also called holdout cross-validation sets, and test sets, has changed in the era of deep learning.
So what are the new best practices for doing that? And whether if your training set and your test come from different distributions, that is happening a lot more in the era of deep learning. So, how do you deal with that? And if you have heard of end-to-end deep learning, you will also learn more about that in this third course, and see when you should use it and maybe when you shouldn’t.
The material in this third course is relatively unique. I am going to share of you a lot of the hard-won lessons that I have learned, building and shipping quite a lot of deep learning products.
As far as I know, this is largely material that is not taught in most universities that have deep learning courses. But I think it will really help you to get your deep learning systems to work well.
The fourth course
In the next course, we will then talk about convolutional neural networks, often abbreviated CNNs. Convolutional networks, or convolutional neural networks, are often applied to images. So you will learn how to build these models in course four.
The fifth course
Finally, in course five, you will learn sequence models and how to apply them to natural language processing and other problems. So sequence models includes models like recurrent neural networks, abbreviated RNNs, and LSTM models, stands for a long short term memory models.
You will learn what these terms mean in course five and be able to apply them to natural language processing problems. So you will learn these models in course five and be able to apply them to sequence data. So for example, natural language is just a sequence of words, and you will also understand how these models can be applied to speech recognition, or to music generation, and other problems.

So through these courses, you will learn the tools of deep learning, you will be able to apply them to build amazing things, and I hope many of you through this will also be able to advance your career. So with that, let’s get started. Please go on to the next video where we will talk about deep learning applied to supervised learning.
[1] Introduction to Deep Learning
What is a Neural Network?

The term, Deep Learning,
refers to training Neural Networks, sometimes very large Neural Networks. So what exactly is a Neural Network? In this video, let’s try to give
you some of the basic intuitions.
Housing price prediction
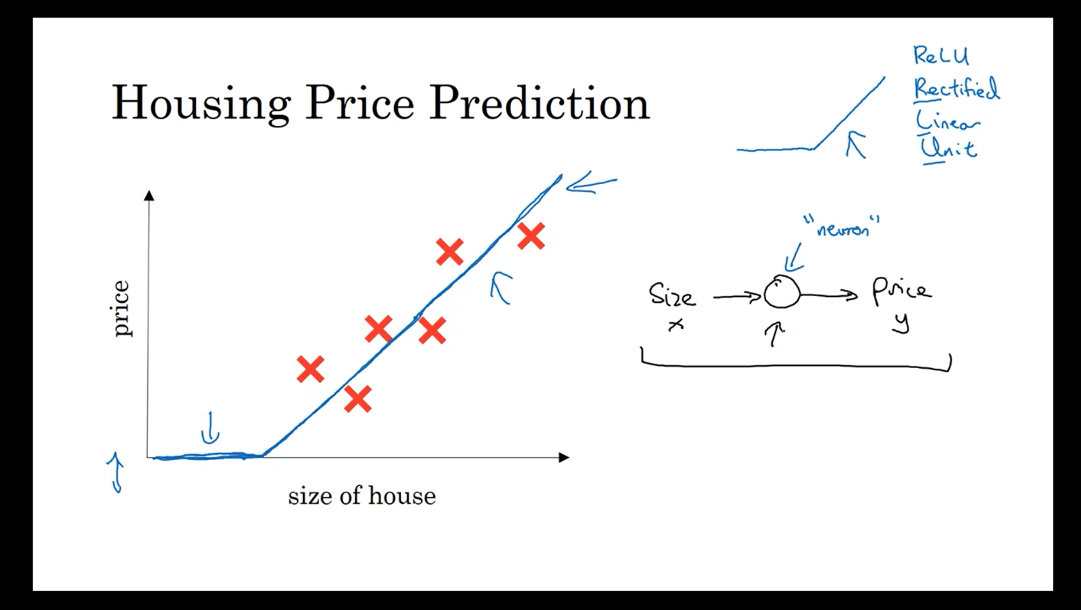
Let’s start with a
Housing Price Prediction example.Let’s say you have a data set with six
houses, so you know the size of the houses in square feet or square meters and you
know the price of the house and you want to fit a function to predict the price
of a house as a function of its size.
So if you are familiar with linear
regression you might say, well let’s put a straight line to this data, so,
and we get a straight line like that.But to be put fancier, you might
say, well we know that prices can never be negative, right? So instead of the straight line fit,
which eventually will become negative, let’s bend the curve here. So it just ends up zero here. So this thick blue line ends
up being your function for predicting the price of the house
as a function of its size.Where it is zero here and then there is
a straight line fit to the right. So you can think of this function that
you have just fit to housing prices as a very simple neural network.It is almost the simplest
possible neural network. Let me draw it here. We have as the input to the neural network
the size of a house which we call x. It goes into this node,
this little circle and then it outputs the price which we call y. So this little circle, which is
a single neuron in a neural network, implements this function
that we drew on the left.
Relu
And all that the neuron does is it inputs
the size, computes this linear function, takes a max of zero, and
then outputs the estimated price. And by the way in the neural network
literature, you will see this function a lot.This function which goes
to zero sometimes and then it’ll take of as a straight line. This function is called a ReLU
function which stands for rectified linear units. So R-E-L-U.
And rectify just means taking a max of 0 which
is why you get a function shape like this. You don’t need to worry
about ReLU units for now but it’s just something you
will see again later in this course.
Stack many of the single neurons
So if this is a single neuron,
neural network, really a tiny little neural network,
a larger neural network is then formed by taking many of the
single neurons and stacking them together.So, if you think of this neuron that’s
being like a single Lego brick, you then get a bigger neural network by stacking
together many of these Lego bricks.
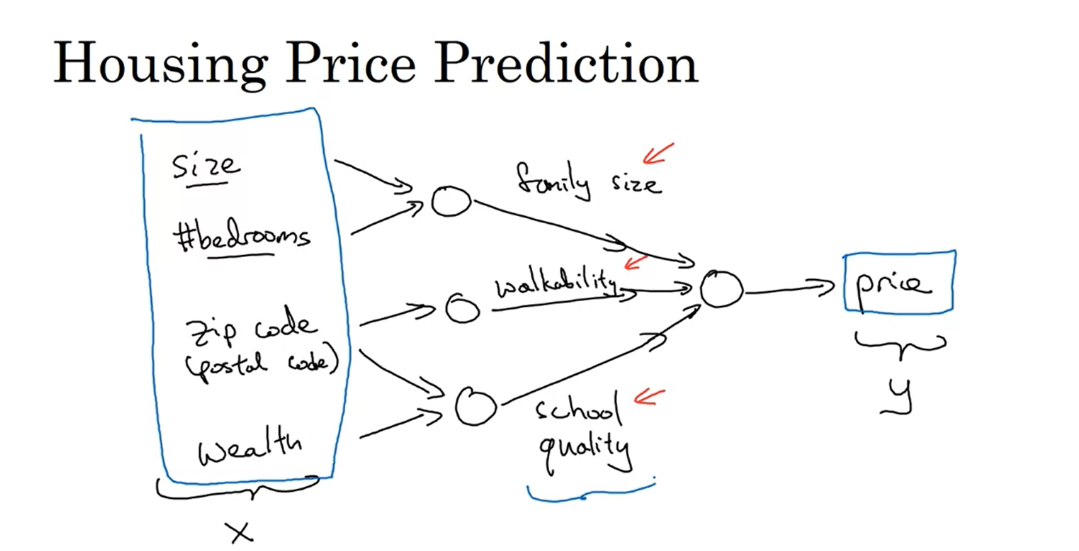
Have other features about the house, let’s predict the housing price
Let’s see an example.
Let’s say that instead of predicting
the price of a house just from the size, you now have other features. You know other things about the house,
such as the number of bedrooms, which we would write as “#bedrooms”,
and you might think that one of the things that really affects the price of
a house is family size, right? So can this house fit your family
of three, or family of four, or family of five? And it’s really based on the size in
square feet or square meters, and the number of bedrooms
that determines whether or not a house can fit your
family’s family size.And then maybe you know the zip codes, in different countries it’s
called a postal code of a house. And the zip code maybe as a feature tells you, walkability? So is this neighborhood highly walkable? Think just walks to the grocery store? Walk to school? Do you need to drive? And some people prefer highly
walkable neighborhoods.And then the zip code as well as
the wealth maybe tells you, right. Certainly in the United States but
some other countries as well.Tells you how good is the school quality.
So each of these little circles I’m
drawing, can be one of those ReLU, rectified linear units or
some other slightly non linear function. So that based on the size and
number of bedrooms, you can estimate the family size,
their zip code, based on walkability, based on zip code and
wealth can estimate the school quality.And then finally you might think that well
the way people decide how much they’re willing to pay for a house, is they look at
the things that really matter to them. In this case family size,
walkability, and school quality and that helps you predict the price.
So in the example x is
all of these four inputs. And y is the price you’re
trying to predict.And so by stacking together a few of the
single neurons or the simple predictors we have from the previous slide, we now
have a slightly larger neural network.
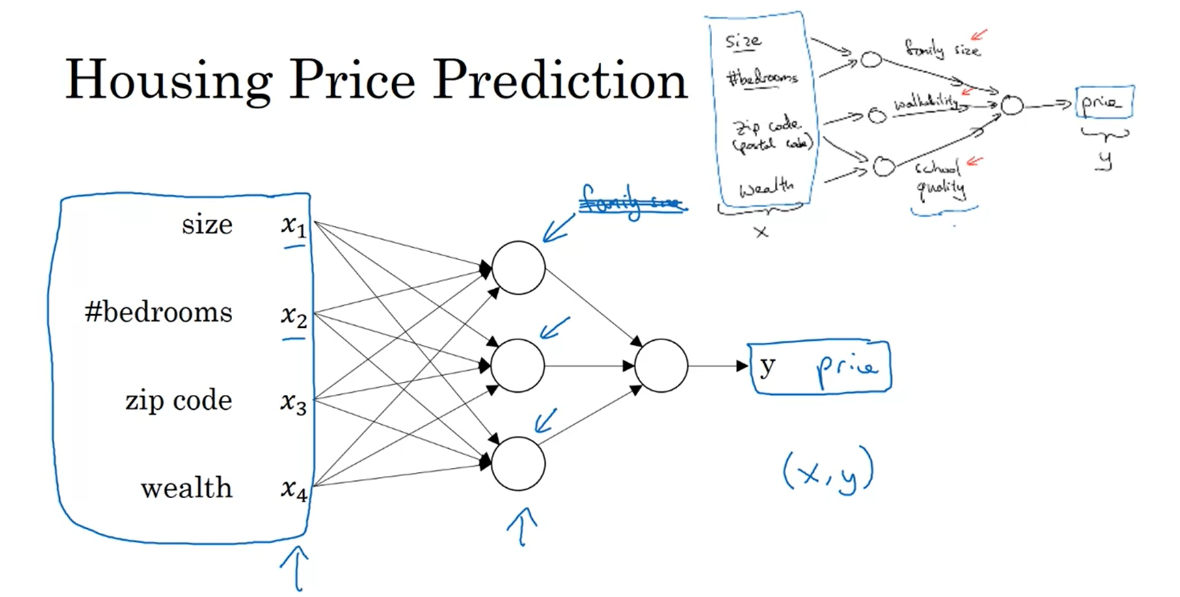
All the hidden units, the network will figure out by themselves.
How you manage neural network
is that when you implement it, you need to give it just the input x and the output y for a number of
examples in your training set and all these things in the middle,
they will figure out by itself.
Every input feature is connected to every one of these hidden units in the middle.
So what you actually implement is this. Where, here, you have a neural
network with four inputs. So the input features might be the size,
number of bedrooms, the zip code or postal code, and
the wealth of the neighborhood. And so given these input features, the job of the neural network
will be to predict the price y.And notice also that each of these circles,
these are called hidden units in the neural network, that each of them
takes its inputs all four input features.So for example, rather than saying this
first node represents family size and family size depends only
on the features X1 and X2. Instead, we’re going to say,
well neural network, you decide whatever you
want this node to be. And we’ll give you all four input features
to compute whatever you want.So we say that layer that
this is input layer and this layer in the middle of the neural
network are densely connected.Because every input feature
is connected to every one of these circles in the middle.
Given enough training data, neural network are remarkably good at figuring out functions that accurately map from x to y.
And the remarkable thing about neural
networks is that, given enough data about x and y, given enough training examples
with both x and y, neural networks are remarkably good at figuring out
functions that accurately map from x to y.So, that’s a basic neural network. It turns out that as you build
out your own neural networks, you’ll probably find them to be most useful,
most powerful in supervised learning incentives, meaning
that you’re trying to take an input x and map it to some output y, like we just saw
in the housing price prediction example.
In the next video let’s go over some
more examples of supervised learning and some examples of where you might find your
networks to be incredibly helpful for your applications as well.
Quiz
Supervised Learning with Neural Networks
Supervised learning
There’s been a lot of hype
about neural networks. And perhaps some of that hype is
justified, given how well they’re working. But it turns out that so far, almost all the economic value created
by neural networks has been through one type of machine learning,
called supervised learning.Let’s see what that means, and
let’s go over some examples.In supervised learning,
you have some input x, and you want to learn a function
mapping to some output y.So for example, just now we saw the
housing price prediction application where you input some features of a home and
try to output or estimate the price y.
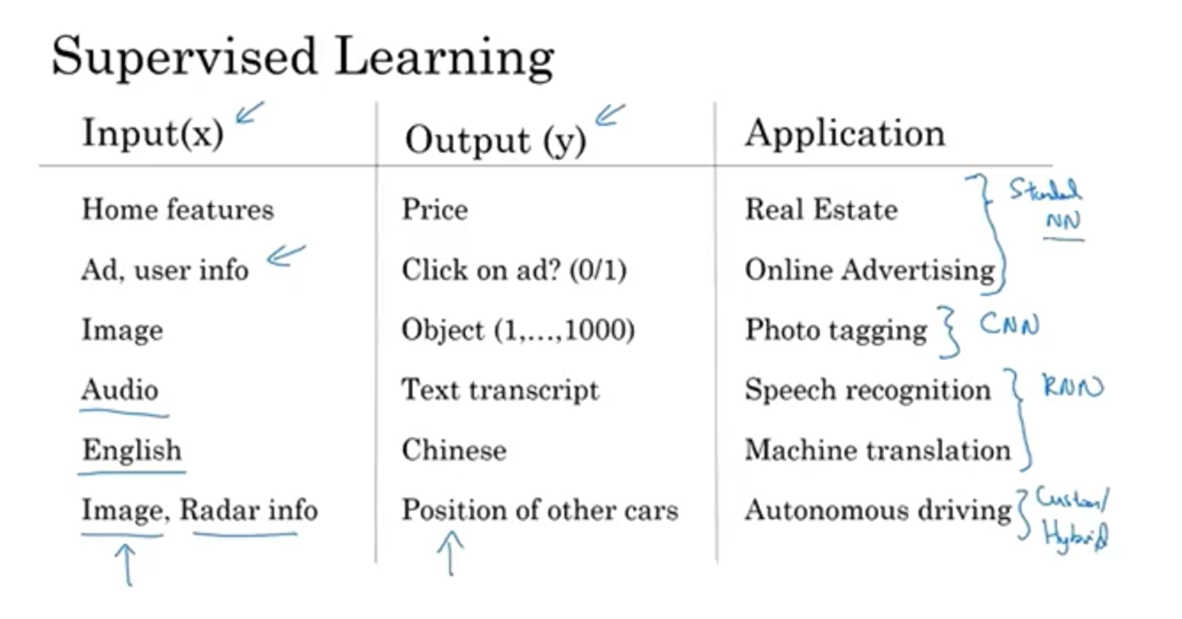
Here are some other examples that neural
networks have been applied to very effectively.
Possibly the single most lucrative
application of deep learning today is online advertising, maybe not the most
inspiring, but certainly very lucrative, in which, by inputting information about
an ad to the website it’s thinking of showing you, and some information
about the user, neural networks have gotten very good at predicting whether or
not you click on an ad. And by showing you and showing users the ads that you are most
likely to click on, this has been an incredibly lucrative application of
neural networks at multiple companies. Because the ability to show you
ads that you’re more likely to click on has a direct impact on the bottom line of some of the very large
online advertising companies.
Computer vision has also made huge
strides in the last several years, mostly due to deep learning. So you might input an image and
want to output an index, say from 1 to 1,000 trying
to tell you if this picture, it might be any one of,
say a 1000 different images.So, you might us that for photo tagging.
I think the recent progress in speech
recognition has also been very exciting, where you can now input an audio
clip to a neural network, and have it output a text transcript.
Machine translation has also made huge
strides thanks to deep learning where now you can have a neural network input an
English sentence and directly output say, a Chinese sentence.
And in autonomous driving, you might input
an image, say a picture of what’s in front of your car as well as some
information from a radar, and based on that, maybe a neural network
can be trained to tell you the position of the other cars on the road. So this becomes a key component
in autonomous driving systems.
So a lot of the value creation through
neural networks has been through cleverly selecting what should be x and
what should be y for your particular problem, and then fitting
this supervised learning component into often a bigger system such
as an autonomous vehicle.
It turns out that slightly different
types of neural networks are useful for different applications.
For example, in the real estate
application that we saw in the previous video, we use a universally standard
neural network architecture, right? Maybe for real estate and
online advertising might be a relatively standard neural network,
like the one that we saw.For image applications we’ll often
use convolutional neural networks, often abbreviated CNN.And for sequence data. So for example,
audio has a temporal component, right? Audio is played out over time, so
audio is most naturally represented as a one-dimensional time series or
as a one-dimensional temporal sequence. And so for sequence data,
you often use an RNN, a recurrent neural network.Language, English and Chinese, the
alphabets or the words come one at a time. So language is also most naturally
represented as sequence data. And so more complex versions of RNNs
are often used for these applications.
And then, for more complex applications,
like autonomous driving, where you have an image, that might suggest more of a CNN,
convolution neural network, structure and radar info which is
something quite different. You might end up with a more custom, or some more complex,
hybrid neural network architecture.So, just to be a bit more concrete
about what are the standard CNN and RNN architectures. So in the literature you might
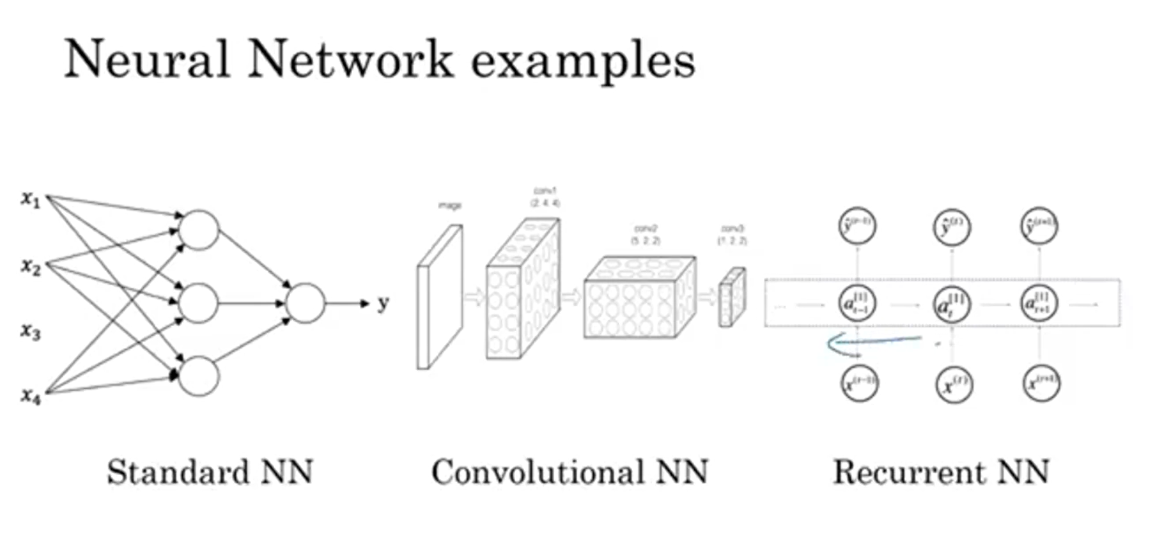
have seen pictures like this. So that’s a standard neural net. You might have seen pictures like this. Well this is an example of a Convolutional
Neural Network, and we’ll see in a later course exactly what this picture
means and how can you implement this. But convolutional networks
are often used for image data. And you might also have
seen pictures like this. And you’ll learn how to implement
this in a later course.Recurrent neural networks
are very good for this type of one-dimensional sequence
data that has maybe a temporal component.
Neural Network examples
Structured data and Unstructured data
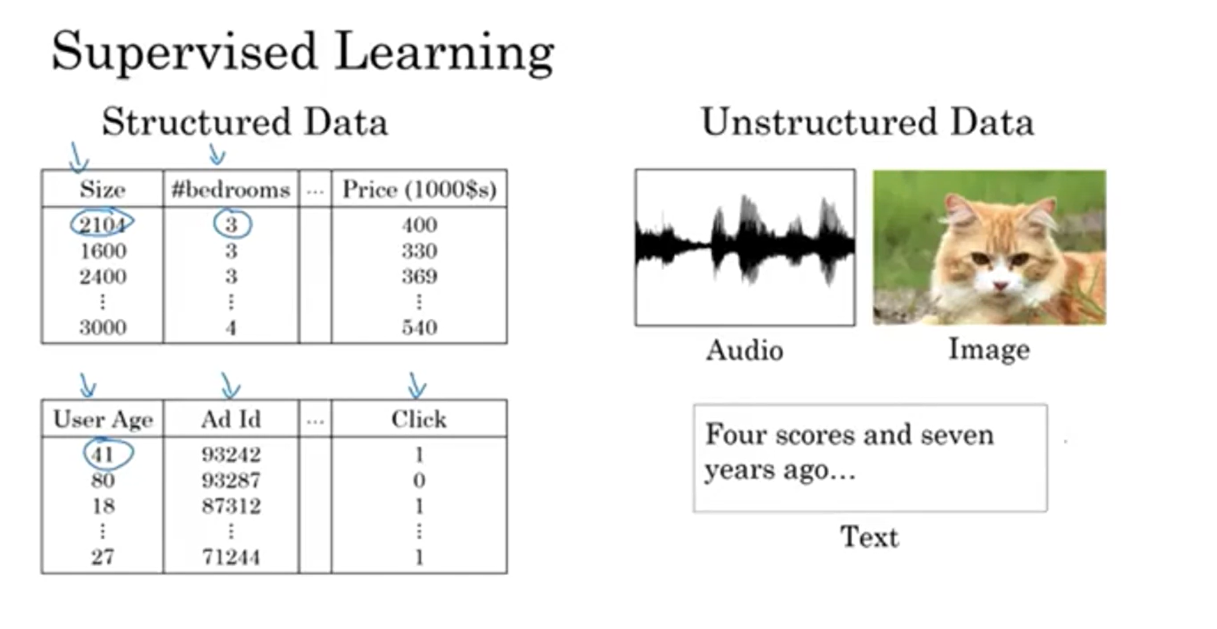
You might also have heard about
applications of machine learning to both Structured Data and
Unstructured Data.
Here’s what the terms mean.
Structured Data means
basically databases of data.So, for example, in housing price
prediction, you might have a database or the column that tells you the size and
the number of bedrooms. So, this is structured data, or
in predicting whether or not a user will click on an ad, you might have information
about the user, such as the age, some information about the ad, and then
labels why that you’re trying to predict.So that’s structured data,
meaning that each of the features, such as size of the house,
the number of bedrooms, or the age of a user,
has a very well defined meaning.
Unstructured data: audio, image, text
In contrast, unstructured data refers
to things like audio, raw audio, or images where you might want to
recognize what’s in the image or text. Here the features might be
the pixel values in an image or the individual words in a piece of text.Historically, it has been much harder for computers to make sense of unstructured
data compared to structured data. And in fact the human race has evolved
to be very good at understanding audio cues as well as images. And then text was a more recent invention,
but people are just really good at
interpreting unstructured data.
And so one of the most exciting things
about the rise of neural networks is that, thanks to deep learning, thanks to neural
networks, computers are now much better at interpreting unstructured data as
well compared to just a few years ago.And this creates opportunities for
many new exciting applications that use speech recognition, image recognition,
natural language processing on text, much more than was possible even
just two or three years ago.I think because people have a natural
empathy to understanding unstructured data, you might hear about neural
network successes on unstructured data more in the media because it’s just cool
when the neural network recognizes a cat.We all like that, and
we all know what that means. But it turns out that a lot of short
term economic value that neural networks are creating has
also been on structured data, such as much better advertising systems,
much better profit recommendations, and just a much better ability to
process the giant databases that many companies have to make
accurate predictions from them.
So in this course, a lot of
the techniques we’ll go over will apply to both structured data and
to unstructured data.For the purposes of
explaining the algorithms, we will draw a little bit more on
examples that use unstructured data.But as you think through applications of
neural networks within your own team I hope you find both uses for them in
both structured and unstructured data.So neural networks have transformed
supervised learning and are creating tremendous economic value.
It turns out though, that the basic
technical ideas behind neural networks have mostly been around,
sometimes for many decades.So why is it, then, that they’re only
just now taking off and working so well? In the next video, we’ll talk
about why it’s only quite recently that neural networks have become this
incredibly powerful tool that you can use.
Question
Why is Deep Learning taking off?
If the basic technical ideas behind deep learning behind your networks have been around for decades why are they only just now taking off ?
in this video let’s go over some of the main drivers behind the rise of deep learning, because I think this will help you to spot the best opportunities within your own organization to apply these tool
over the last few years a lot of people have asked me “Andrew why is deep learning suddenly working so well?” and when I am asked that question this is usually the picture I draw for them.
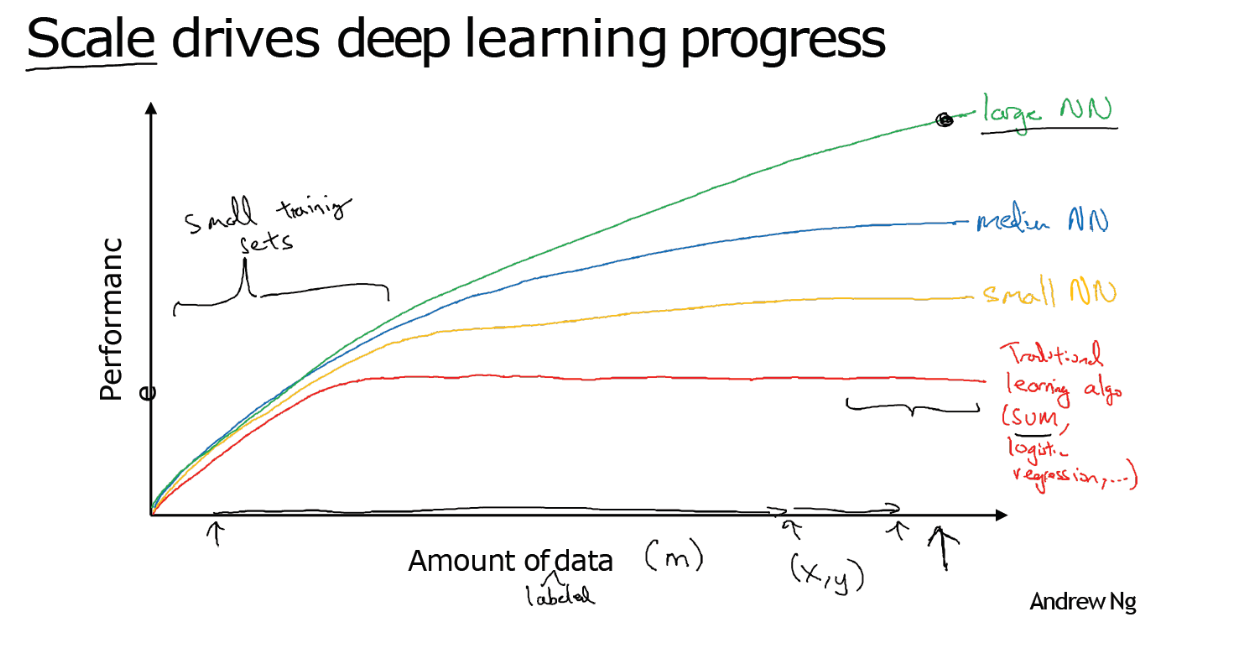
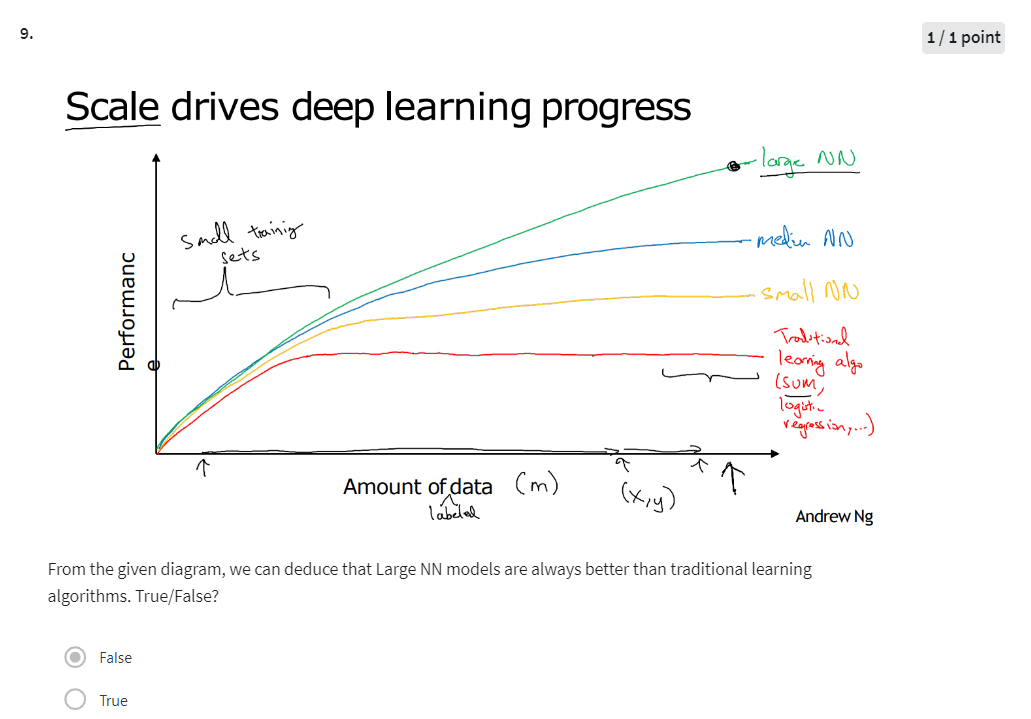
The figure axis
Let’s say we plot a figure where on the horizontal axis we plot the amount of data we have for a task and let’s say on the vertical axis we plot the performance on involved learning algorithms such as the accuracy of our spam classifier or our ad click predictor or the accuracy of our neural net for figuring out the position of other cars for our self-driving car.
It turns out if you plot the performance of a traditional learning algorithm like support vector machine or logistic regression as a function of the amount of data you have you might get a curve that looks like this where the performance improves for a while as you add more data but after a while the performance you know pretty much plateaus right
suppose your horizontal lines enjoy that very well you know was it they didn’t know what to do with huge amounts of data and what happened in our society over the last 10 years maybe is that for a lot of problems we went from having a relatively small amount of data to having you know often a fairly large amount of data and all of this was thanks to the digitization of a society where so much human activity is now in the digital realm
We spend so much time on the computers on websites on mobile apps and activities on digital devices creates data and thanks to the rise of inexpensive cameras built into our cell phones, accelerometers, all sorts of sensors in the Internet of Things.
We also just have been collecting one more and more data. So over the last 20 years for a lot of applications we just accumulate a lot more data more than traditional learning algorithms were able to effectively take advantage of and what new network lead turns out that if you train a small neural net then this performance maybe looks like that.
If you train a somewhat larger Internet that’s called as a medium-sized net. To fall in something a little bit between and if you train a very large neural net then it’s the form and often just keeps getting better and better.
So, a couple observations.
One is if you want to hit this very high level of performance then you need two things
first: often you need to be able to train a big enough neural network in order to take advantage of the huge amount of data and second you need to be out here, on the x axis you do need a lot of data so we often say that scale has been driving deep learning progress and by scale I mean both the size of the neural network, meaning just a new network, a lot of hidden units, a lot of parameters, a lot of connections, as well as the scale of the data.
A big network or throw more data into our model
In fact, today one of the most reliable ways to get better performance in a neural network is often to either train a bigger network or throw more data at it and that only works up to a point because eventually you run out of data or eventually then your network is so big that it takes too long to train.
小的数据集,传统的机器学习算法,需要很好的特征工程技巧,对模型的细节掌握得很好。
But, just improving scale has actually taken us a long way in the world of learning in order to make this diagram a bit more technically precise and just add a few more things I wrote the amount of data on the x-axis.
Technically, this is amount of labeled data where by label data I mean training examples we have both the input X and the label Y I went to introduce a little bit of notation that we’ll use later in this course. We’re going to use lowercase alphabet m to denote the size of my training sets or the number of training examples this lowercase M so that’s the horizontal axis.
A couple other details, to this figure, in this regime of smaller training sets the relative ordering of the algorithms is actually not very well defined so if you don’t have a lot of training data it is often up to your skill at hand engineering features that determines the performance so it’s quite possible that if someone training an SVM is more motivated to hand engineer features and someone training even larger neural nets, that may be in this small training set regime, the SEM could do better so you know in this region to the left of the figure the relative ordering between gene algorithms is not that well defined and performance depends much more on your skill at engine features and other mobile details of the algorithms and there’s only in this some big data regime.
Very large training sets, very large M regime in the right that we more consistently see large neural nets dominating the other approaches.
And so if any of your friends ask you why are neural nets taking off I would encourage you to draw this picture for them as well.
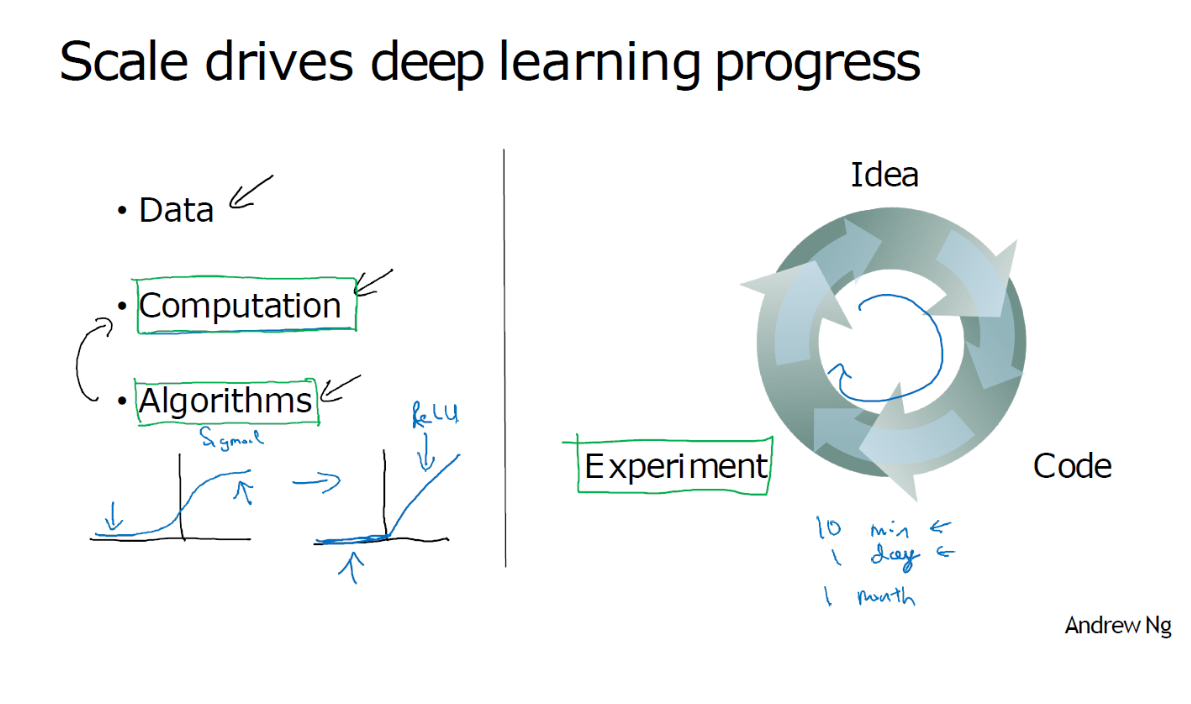
So I will say that in the early days in their modern rise of deep learning, it was scaled data and scale of computation just our ability to train very large neural networks either on a CPU or GPU that enabled us to make a lot of progress.
But increasingly, especially in the last several years, we’ve seen tremendous algorithmic innovation as well so I also don’t want to understate that.
Interestingly, many of the algorithmic innovations have been about trying to make neural networks run much faster so as a concrete example one of the huge breakthroughs in neural networks has been switching from a sigmoid function, which looks like this, to a ReLU function, which we talked about briefly in an early video, that looks like this.
Sigmoid函数,有些地方梯度为零,学习就很慢
If you don’t understand the details of one about the state don’t worry about it but it turns out that one of the problems of using sigmoid functions and machine learning is that there are these regions here where the slope of the function where the gradient is nearly zero and so learning becomes really slow, because when you implement gradient descent and gradient is zero the parameters just change very slowly.
ReLu 让梯度下降更快
And so, learning is very slow whereas by changing the what’s called the activation function the neural network to use this function called the value function of the rectified linear unit, or RELU, the gradient is equal to 1 for all positive values of input. right.
And so, the gradient is much less likely to gradually shrink to 0 and the gradient here. the slope of this line is 0 on the left but it turns out that just by switching to the sigmoid function to the RELU function has made an algorithm called gradient descent work much faster and so this is an example of maybe relatively simple algorithmic innovation.
But ultimately, the impact of this algorithmic innovation was it really helped computation. so there are actually quite a lot of examples like this of where we change the algorithm because it allows that code to run much faster and this allows us to train bigger neural networks, or to do so the reason will decline even when we have a large network roam all the data.
Go around a circle quickly
The other reason that fast computation is important is that it turns out the process of training your network is very intuitive. Often, you have an idea for a neural network architecture and so you implement your idea and code. Implementing your idea then lets you run an experiment which tells you how well your neural network does and then by looking at it you go back to change the details of your new network and then you go around this circle over and over and when your new network takes a long time to train it just takes a long time to go around this cycle and there’s a huge difference in your productivity.
Building effective neural networks when you can have an idea and try it and see the work in ten minutes, or maybe at most a day, versus if you’ve to train your neural network for a month, which sometimes does happen, because you get a result back you know in ten minutes or maybe in a day you should just try a lot more ideas and be much more likely to discover in your network.
And it works well for your application and so faster computation has really helped in terms of speeding up the rate at which you can get an experimental result back and this has really helped both practitioners of neural networks as well as researchers working and deep learning iterate much faster and improve your ideas much faster.
So, all this has also been a huge boon to the entire deep learning research community which has been incredible with just inventing new algorithms and making nonstop progress on that front.
So these are some of the forces powering the rise of deep learning but the good news is that these forces are still working powerfully to make deep learning even better.
Take data… society is still throwing out more digital data.
Or take computation, with the rise of specialized hardware like GPUs and faster networking many types of hardware, I’m actually quite confident that our ability to do very large neural networks from a computation point of view will keep on getting better
and take algorithms relative to learning research communities are continuously phenomenal at elevating on the algorithms front.
So because of this, I think that we can be optimistic answer is that deep learning will keep on getting better for many years to come. So with that, let’s go on to the last video of the section where we’ll talk a little bit more about what you learn from this course.
About this Course
Outline of this Course

So you’re just about to reach the end of the first week of material on the first course in this specialization.
Let me give you a quick sense of what you’ll learn in the next few weeks as well.
As I said in the first video, this specialization comprises five courses. And right now, we’re in the first of these five courses, which teaches you the most important foundations, really the most important building blocks of deep learning.
So by the end of this first course, you will know how to build and get to work on a deep neural network.
So here the details of what is in this first course. This course is four weeks of material. And you’re just coming up to the end of the first week when you saw an introduction to deep learning. At the end of each week, there are also be 10 multiple-choice questions that you can use to double check your understanding of the material. So when you’re done watching this video, I hope you’re going to take a look at those questions.
In the second week, you will then learn about the Basics of Neural Network Programming. You’ll learn the structure of what we call the forward propagation and the back propagation steps of the algorithm and how to implement neural networks efficiently.
Starting from the second week, you also get to do a programming exercise that lets you practice the material you’ve just learned, implement the algorithms yourself and see it work for yourself. I find it really satisfying when I learn about algorithm and I get it coded up and I see it worked for myself. So I hope you enjoy that too.
Having learned the framework for neural network programming in the third week, you will code up a single hidden layer neural network. All right. So you will learn about all the key concepts needed to implement and get to work in neural network.
And then finally in week four, you will build a deep neural network and neural network with many layers and see it work for yourself.
So, congratulations on finishing the videos up to this one. I hope that you now have a good high-level sense of what’s happening in deep learning. And perhaps some of you are also excited to have some ideas of where you might want to apply deep learning yourself.
So, I hope that after this video, you go on to take a look at the 10 multiple choice questions that follow this video on the course website and just use the 10 multiple choice questions to check your understanding. And don’t review, you don’t get all the answers right the first time, you can try again and again until you get them all right. I found them useful to make sure that I’m understanding all the concepts, I hope you’re that way too. So with that, congrats again for getting up to here and I look forward to seeing you in the week two videos.
[2] Lecture Notes (Optional)
Have downloaded locally, and git push them to GitHub repo.
[3] Quiz: Introduction to Deep Learning

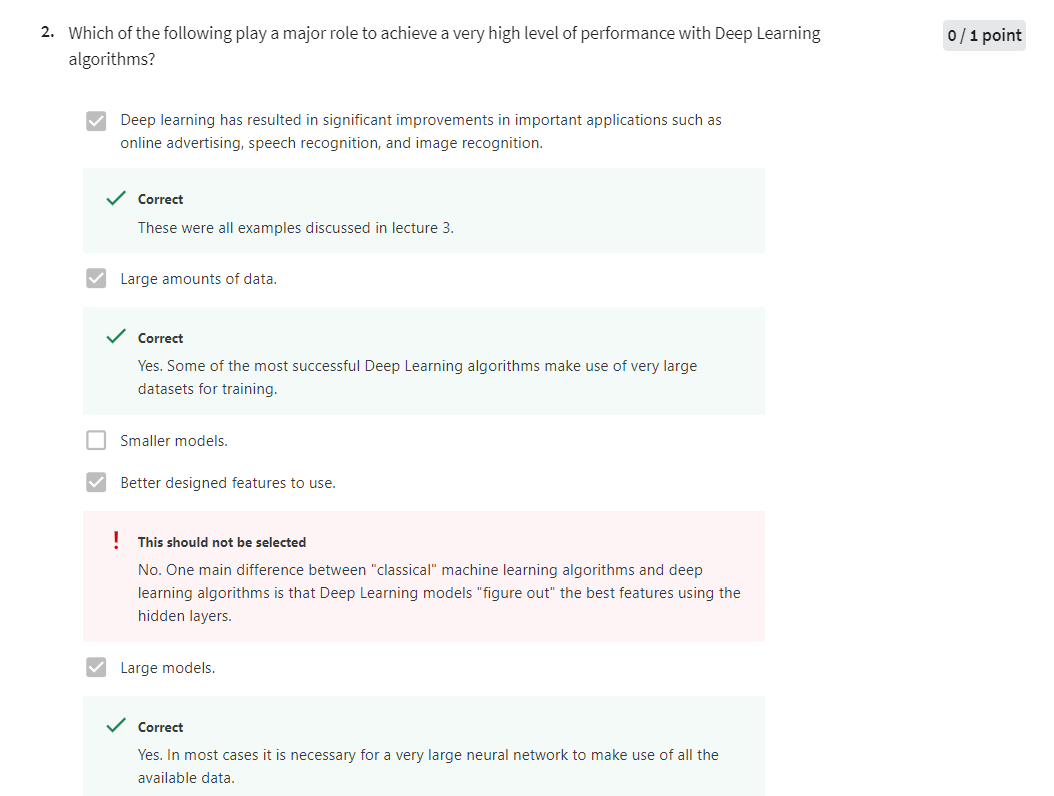
第二题:正确的选项有三个,就是上图中的三个正确的选项。
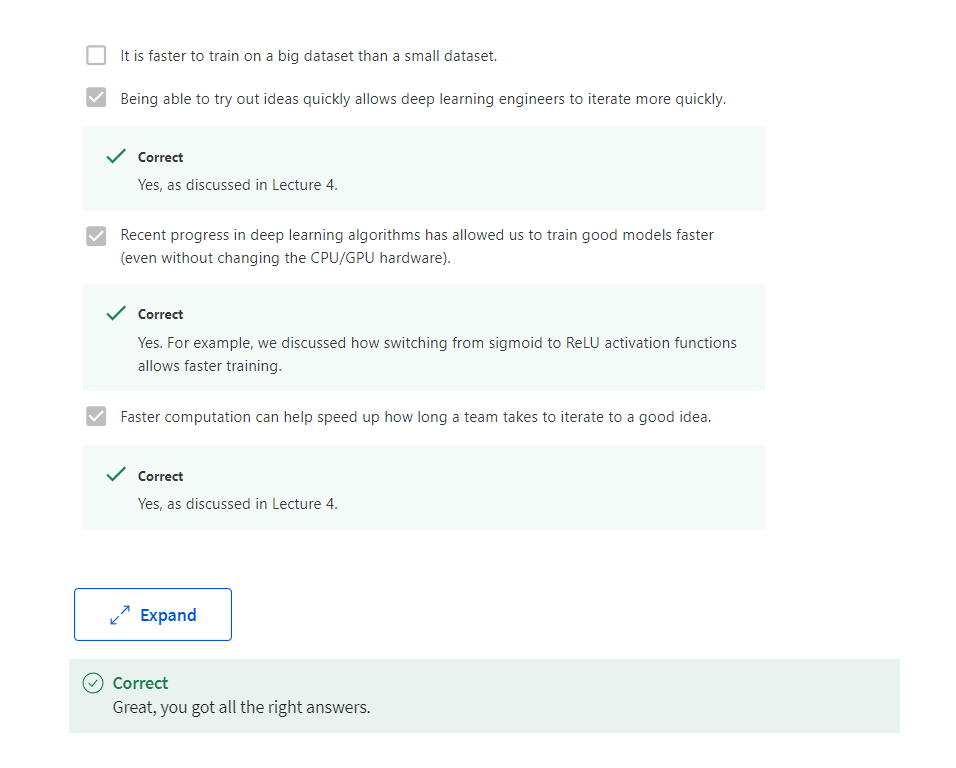

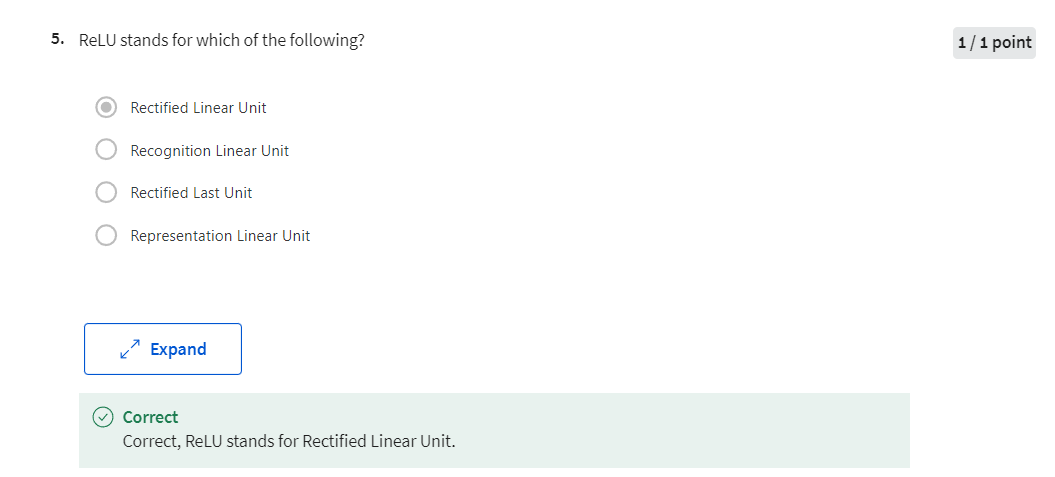

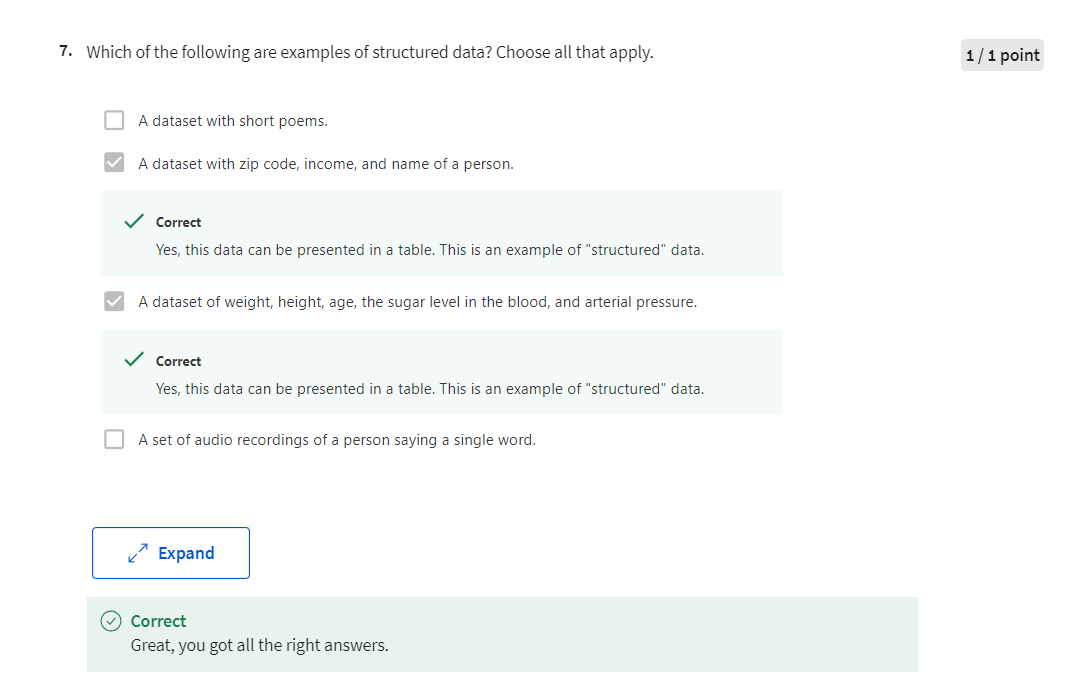

Correct
Yes, when the amount of data is not large the performance of traditional learning algorithms is shown to be the same as NN.
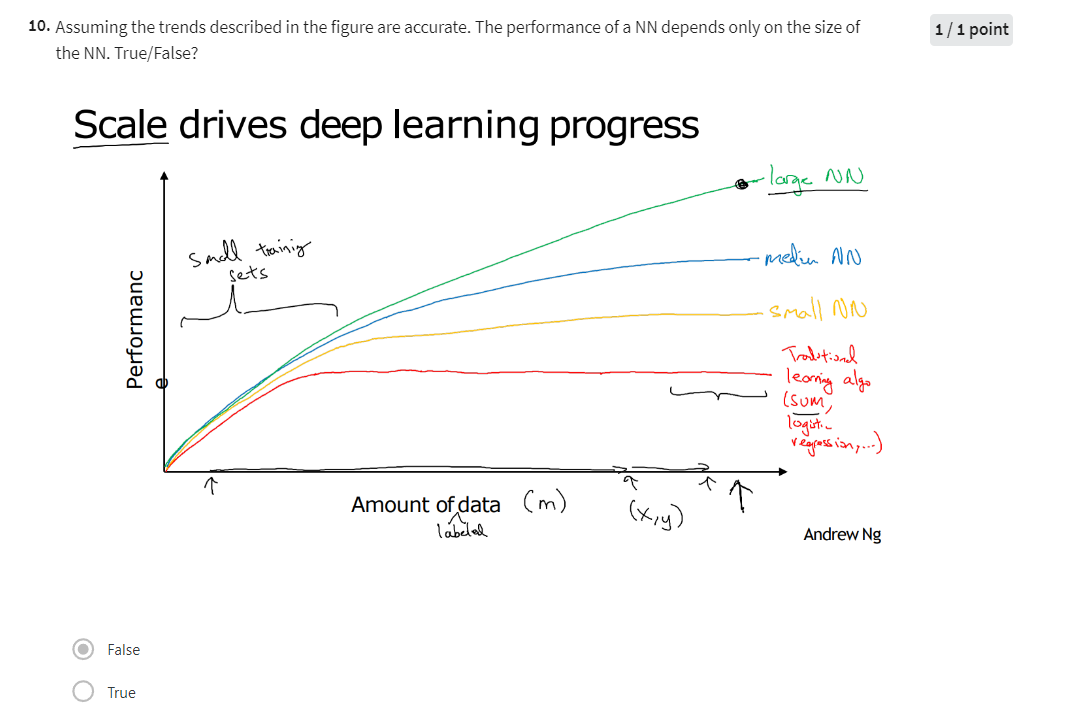
Yes. According to the trends in the figure above, It also depends on the amount of data.
其他
Commit template
git commit -m "Finish learning notes of Week 01 of Neural Networks and Deep Learning"
英文发音
remarkably: rəˈmärkəblē 显著地
malignant: məˈliɡnənt 恶性的,有害的
walkability: 步行性
real estate:美 [ˈriːəl əsteɪt] 房地产,房产
后记
完成NLP专项后,再回来学习深度学习专项,有点降维打击啦。