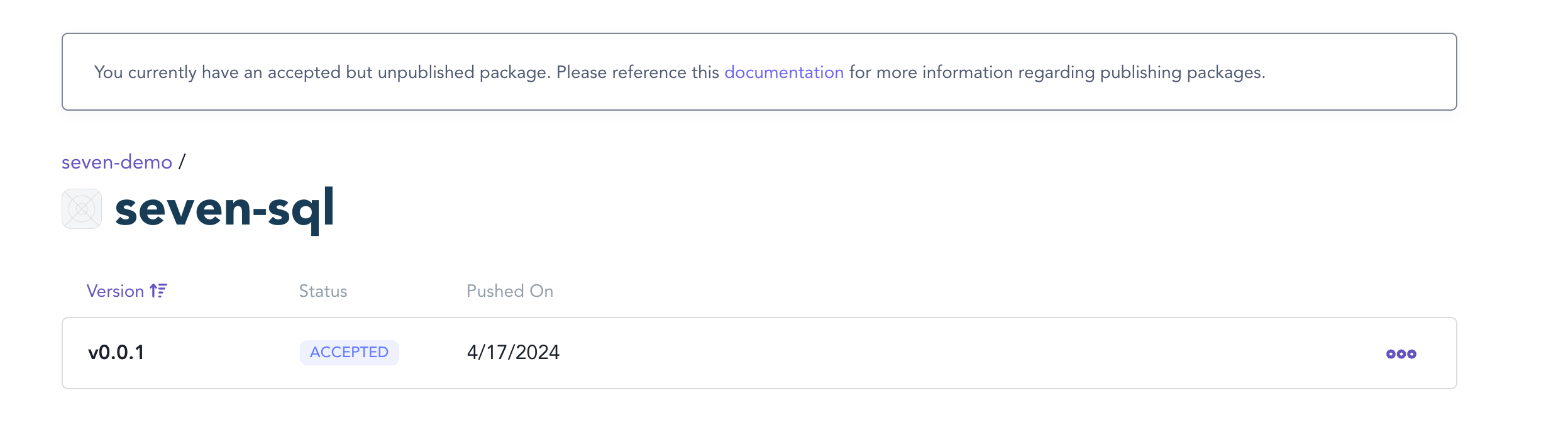
一、什么是对称加密
对称密钥算法(Symmetric-key algorithm),又称为对称加密、私钥加密、共享密钥加密,是密码学中的一类加密算法。
对称加密的特点是,在加密和解密时使用相同的密钥,或是使用两个可以简单地相互推算的密钥。
这一个或一组密钥需要在两个或多个成员之间共享,以便维持专属的通讯联系。
对称加密的优点是速度快,缺点是需要共享密钥,安全性不足。
常见的对称加密算法有 AES、SM4、ChaCha20、3DES、Salsa20、DES、Blowfish、IDEA、RC5、RC6、Camellia。
目前国际主流的对称加密算法是AES,国内主推的则是国标的SM4。
二、对称加密的基本过程
对称加密算法可分为两大类型:
分组加密: 先将明文切分成一个个固定大小的块,再对每个块进行加密,这种方式被称为分组加密或块加密,有的资料称呼为"分组密码"或"块密码"。流加密: 将密钥扩展到与密文等长后,用扩展后的密钥与明文按比特位做异或运算。
相比分组加密,流加密具有速度快,消耗少的优点,在网络通信的某些特定场景比较有优势。然而流加密的发展落后于分组加密,其安全性、可扩展性、使用灵活性上,目前认为还是比不上分组加密的,同时某些分组加密算法可以兼具流加密的部分特点。因此对称加密的主流仍然是分组加密。
常见的流加密算法如RC4、ChaCha20等等,它们的安全强度主要取决于扩展后密钥的随机性。
无线网络通信中常常使用RC4; TLS通信协议的最新版本TLS 1.3中,出现了支持ChaCha20的密码套件。
流加密不是本篇的学习重点,这里只简单了解一下,接下来开始学习分组加密,后文提到对称加密时,一般都是特指分组加密。
2.1 分组加密的基本过程
分组加密的基本流程如下所述:
- 将明文字节数组(byte[])切分为固定长度的块(block),例如每个块16个字节(即128位)。
- 对每一个块进行块加密,块加密的算法需要使用密钥,并且该过程是可逆的,即使用相同密钥可以对加密结果进行解密;块加密不会改变块的长度。
- 将加密后的块拼接起来,得到密文字节数组(byte[])。
解密过程也是一样的,先对密文字节数组进行固定长度的分组,然后对每个块进行块解密,然后将解密后的块拼接起来,得到明文字节数组。
上述过程中的块加密与块解密就是每一种分组加密算法的核心部分。在这里我们先将其视为一种接口,实现的效果是使用密钥Key将一个固定长的块转换为等长的另一个块。
比如16个字节(128位)的块,经过与Key的某种可逆运算,得到一个新的块,也是16字节128位。
由分组加密算法的基本过程,我们可以看到,分组加密有三个重点:
- 一是如何分组,明文的长度是不固定的,当明文长度不是块长度的整数倍时,要不要填充?如何填充?这时就要引入填充算法。
- 二是分组之后的各个块以何种形式组织起来实现整体的加解密,这个就是分组模式。
- 三是如何实现针对每个块的加解密,这个是不同的分组加密算法的核心部分。
这三个重点,就是学习分组加密算法的主要内容,也是后续章节的主要内容。
此外,在上述过程中,明文和密文都是字节数组,在很多应用中并不会直接使用字节数组作为对称加密的对外接口,因此往往还会再封装一层,实现字节数组与字符串之间的转换。
例如对一段文字进行加密,那么执行对称加密之前,需要先将这段文字(即字符串)转为明文字节数组,这时涉及到字符集的问题,比如将这段文字按utf-8的encoding规则转为对应的字节数组;
在对称加密结束后,得到的密文字节数组往往也需要转为字符串,但因为是密文,如果按照utf-8这种人类语言的字符集规则转换的话,得到的往往会是一堆无法表示和识别的字符(比如一堆?),因此这里一般会使用其他编码(encoding)规则,比如转为Hex16进制字符串。
常见的对密文的编码方式有Hex, Base64等。注意编码不是加密,编码是将字节数组转换为字符串的一种方式,可以认为是一种特殊的字符集(字符集事实上就是编码规则+字符集合)。Hex是转为16进制数字,Base64是转为事先规定好的64个字符。
关于对明文的字符集处理,对密文的编码处理,不是对称加密的核心内容,后续将不再涉及,都只以字节数组形式描述。
2.2 填充算法
使用分组加密算法对明文进行分组时,有时需要事先对明文字节数组进行填充,使其长度变为块长度的整数倍。这就是分组加密的填充算法,或者说填充规则。
但并不是所有的分组加密算法都需要做明文填充,这取决于分组模式,事实上只有ECB、CBC、PCBC等分组模式需要填充明文。
目前主流的分组加密填充规则是PKCS7Padding。
PKCS7Padding由PKCS#7标准定义,参考https://datatracker.ietf.org/doc/html/rfc5652#section-6.3的6.3. Content-encryption Process一节。
PKCS是Public-Key Cryptography Standards的缩写,是由RSA实验室主导制订的一系列密码学标准。其中PKCS#7是Cryptographic Message Syntax Standard,加密消息的语法标准,其中包含了明文填充的标准。
2.2.1 PKCS7算法
假定分组加密的块长度为BlockSize, 明文字节数组长度为SrcSize, 则按下面的公式计算padding。padding即是明文需要补位的字节数,也是补位的每个字节的数值,解密时通过最后一个字节的数值判断需要去除多少个填充字节。
padding = BlockSize - SrcSize % BlockSizepadding的值范围是[1, BlockSize],即最小值为1,最大值为BlockSize。BlockSize支持的取值范围是[1, 255]。目前主流的对称加密算法的BlockSize是16,如AES与SM4。
举例说明:
假设BlockSize为16,那么:
- 如果padding为1,就在明文尾部填充1个
1; - 如果padding为13,就在明文尾部填充13个
13; - 如果padding为16,就在明文尾部填充16个
16;
特别注意,padding为16代表明文长度正好是16的整数倍,但此时仍然在明文尾部补充16个16,这样在解密时就仍然是通过最后一个字节的数值来判断需要去掉多少个填充的字节,而不需要对明文长度正好是16整数倍的情况做特殊处理。
2.2.2 PKCS5算法
PKCS5是PKCS7的子集,BlockSize值固定为8,其他规则一样。
目前PKCS5基本不再使用,因为主流的AES与SM4的BlockSize都是16。
2.3 分组模式
分组之后,接下来分组加密算法要解决的问题就是: 如何将分组后的各个块组织起来,协同实现明文整体的加解密。这个问题就是分组密码工作模式要解决的问题。常见的分组密码工作模式(简称分组模式或加密模式)有:
ECB: 电子密码本(Electronic codebook)CBC: 密码块链接(Cipher-block chaining)PCBC: 填充密码块链接(Propagating cipher-block chaining), 也被称为 明文密码块链接(Plaintext cipher-block chaining)CFB: 密文反馈(Cipher feedback)OFB: 输出反馈(Output feedback)CTR: 计数器模式(Counter mode), 也被称为 ICM整数计数模式(Integer Counter Mode), 或 SIC模式(Segmented Integer Counter)GCM: 伽罗瓦/计数器模式(Galois/Counter Mode)
其中CBC、CTR、GCM是较为常用的分组模式,他们都需要一个随机初始化向量IV。
分组模式是对块加密的协同组织算法,而块加密的具体算法则是每个对称加密算法的核心。不同的对称加密算法其块加密的算法逻辑自然各不相同,我们将在学习完分组模式后,在后续章节单独学习两个具体的块加密算法,AES和SM4。
2.3.1 ECB模式
ECB, 电子密码本(Electronic codebook), 是最简单的分组模式。它对每个块使用同一个key进行独立的块加密。
ECB需要事先对明文字节数组做填充。
ECB加解密过程如下图所示:

从上图可以看到,ECB对每个明文块做块加密,而块加密会要求明文块的长度必须是BlockSize。这是ECB需要先对明文做填充的原因。
ECB是一种不安全的分组模式,因为对每一个块的加密都是使用同样的key,同样的明文块一定会被加密成同样的密文块,在某些加密场合下极不安全。例如对图像的加密可能会发生如下现象:

ECB不安全演示
从上图可以发现,ECB可能会导致明文的统计学特征被保留在密文中。
此外,ECB模式因为每个块都使用相同的Key做加解密,容易受到重放攻击,增加了密钥被破解的风险。
ECB另一个特点是误差传播小,即一个密文块在传输中产生随机性误差或被篡改,只会影响这一个块的解密结果,而不会影响到其他块的解密结果。
目前传播误差已经是一个不再重要的特征,了解一下即可。
所谓误差传播就是输入的某一个bit发生随机性错误或被篡改时,有哪些输出的bit被影响到。
误差传播小未必是好事,因为它违反了密码学的混淆与扩散原则。有人认为误差传播小在应对随机误差(例如传输噪声)时会是有益的,但也有人认为这使得攻击者更容易篡改消息的一部分。
随着分组模式的发展,当分组模式支持认证加密之后,误差传播已经不重要了。认证加密会确保消息的完整性与真实性,一旦传播过程发生了随机性错误或被篡改,则直接终止解密过程。
认证加密在学习到GCM分组模式时会介绍。
2.3.2 CBC模式
CBC, 密码块链接(Cipher-block chaining)。CBC同样是对每个块使用同一个key进行块加密,但CBC会在块加密之前,先将明文块与前一个密文块进行异或计算,然后再对异或计算结果进行块加密。
对于首个明文块,因为不存在前一个密文块,所以需要额外的一个字节数组来充当"前一个密文块",这个字节数组被称为初始化向量,IV。同一次加密和解密使用相同的IV,但原则上,不同的加解密回合应该使用不同的IV以确保随机性。
初始化向量IV是一个长度为BlockSize的随机字节数组,对应一个伪随机数。
CBC也需要事先对明文字节数组做填充。
其过程如下图所示:

从上图中我们可以看到,每个密文块都依赖于它前面的所有明文块,所以这种模式被称为"密码块链接"。同时,明文块异或之后执行块加密同样要求明文块长度必须是BlockSize,因此CBC也需要先对明文做填充。
注意异或运算的对称性特点:(a xor b) xor b = a。即: a与b做异或运算的结果,再次与b做异或,得到的仍是a。
因此加密过程中的块加密的入参是第一次异或结果,解密过程中的块解密之后得到的即这个第一次异或结果,对其再次进行相同参数的异或运算,得到的就是原来的明文块。
另外要注意的是这里的异或一般有封装,是将两个字节数组以字节为单位一个一个进行异或,所以参与异或的参数的长度其实也是固定的,都是BlockSize。
CBC和ECB一样对每个块使用相同的密钥进行加解密,不同的是CBC对明文块做了异或处理,且每次异或运算的参数是前一个密文块。这样CBC就保证了相同的明文块会经由异或运算得到不同的数组,于是即使密钥相同,加密得到的密文块也是不一样的。
CBC加密过程中,每个密文块都依赖于它前面的明文块加密后的密文块,因此加密过程只能串行计算,无法并行化。而无法并行化意味着无法利用现代CPU的多核性能,对于性能优化有负面影响。这是CBC的主要缺点。CBC的解密过程则可以并行化。
CBC的误差传播比ECB大。一个密文块的误差或篡改会影响当前密文块和下一个密文块的解密结果,其他密文块的解密结果不会受到影响。
CBC模式的代码实现可以参考golang源码:
https://go.dev/src/crypto/cipher/cbc.go
2.3.3 PCBC模式
PCBC, 填充密码块链接(Propagating cipher-block chaining), 也被称为明文密码块链接(Plaintext cipher-block chaining)。
PCBC在CBC的基础上,对异或计算的参数进行了改变。它在对明文块进行异或计算时,不是直接和前一个密文块进行异或,而是先将前一个明文块和密文块进行异或计算得到一个中间数组,然后再和当前明文块进行异或运算,然后再做块加密。
PCBC同样需要初始化向量IV,也同样需要事先对明文字节数组做填充。
其过程如下图所示:

从上图中同样可以看出为什么这种分组模式被称为"填充密码块链接"或"明文密码块链接"。
PCBC的加解密过程都只能串行,不能并行化。
PCBC的误差传播比较大。一个密文块发生误差或篡改时,会影响当前密文块和后续所有密文块的解密结果。
2.3.4 CFB模式
CFB, 密文反馈(Cipher feedback), 该模式的流程与CBC类似,但对异或、块加密的使用则完全不同。
CBC是先对明文块和前一个密文块做异或计算,再对异或结果做块加密,而CFB是先对前一个密文块做块加密,再和明文块做异或计算。
CFB需要初始化向量IV,不需要事先对明文字节数组做填充。
其过程如下图所示:

注意,CFB的解密过程并没有使用块解密,而是仍然使用块加密,因为CFB中使用块加密仅仅是为了得到异或运算参数。而异或运算要满足两次运算得到原本的明文,就需要保证异或参数的一致。即,CFB实际上用异或做"块的加密"与"块的解密",原本的块加密则是用来计算异或参数用的。
这种前一个密文块不直接参与"块的加密",而是反馈到明文块的异或参数去的模式,就称之为"密文反馈"。
而正是由于CFB模式明文块不参与块加密,因此CFB是不需要对明文做填充的。
从分组加密和流加密的区别看,CFB实际上是将块加密变成了某种程度上的"流加密"。虽然还是分组了,但并没有对明文块做块加密,而是直接异或,相当于对这个明文块做流加密。也正是由于这个原因,最后一个明文块是不需要填充满BlockSize的。
某些实现者在实现CFB模式时,还是会先给明文做填充,原因可以理解但不推荐。
CFB正常的处理逻辑中,在最后一个明文块不满BlockSize时,需要一些额外的特殊处理。
以BlockSize=16为例,CFB对每个明文块做的异或运算的参数是块加密结果,由于块加密结果也是16字节,因此如果最后一个明文块不满16字节,就需要在异或前做特殊处理,比如将块加密结果按明文块长度做截取然后再异或(因为这里的异或是按字节为单位一个一个异或的)。
有的实现者会觉得这样增加了程序的复杂度,也更容易出错,所以即使是CFB模式,也事先做了PKCS7填充,这样加密时不需要对最后一个块做特殊处理,解密时也只是简单地按照PKCS7规则去除填充字节。
但这样做会有一个问题,就是降低了程序的通用性。比如A端的CFB模式加密做了填充,密文传输到B端解密,但B端的算法是按照CFB标准来实现的,没有去除填充的步骤,那么解密就可能会失败。
CFB与CBC一样,加密只能串行,解密可以并行。
CFB在误差传播上类似CBC,一个密文块的误差或篡改会影响当前密文块和下一个密文块的解密结果,其他密文块的解密结果不会受到影响。
CFB模式的实现可以参考golang源码:
https://go.dev/src/crypto/cipher/cfb.go
2.3.5 OFB模式
OFB, 输出反馈(Output feedback)。
OFB在CFB的基础上,对块加密的参数进行了改变。它在做块加密得到异或参数时,使用的不再是前一个密文块,而是前一个块加密得到的异或参数。
OFB和CFB一样,需要初始化向量IV,不需要事先对明文字节数组做填充。
其过程如下图所示:

和CFB一样,OFB的解密过程也没有使用块解密。和CFB不同的是,CFB在加密过程中向下一个块反馈的是密文块,而OFB反馈的是本次块加密结果,因此叫"输出反馈"。而由于块加密不再使用前一个密文块,而异或运算又具备对称性,因此OFB的解密过程与加密过程完全相同。
OFB与CFB一样可以认为是将分组后的块加密变成了"流加密",不需要对明文做填充。
OFB的加解密过程中,由于异或参数没有明文块或密文块,因此可以先从IV开始串行计算出每个块对应的异或参数并缓存,而在实际加解密过程中则可以直接使用缓存的各个块的异或参数,直接并行地对明文块或密文块做异或运算。即OFB的加解密可以实现部分并发处理。
OFB的误差传播很小,一个密文块的误差或篡改只会影响当前密文块的解密结果。
OFB模式的实现可以参考golang源码:
https://go.dev/src/crypto/cipher/ofb.go
2.3.6 CTR模式
CTR, 计数器模式(Counter mode), 也被称为ICM整数计数模式(Integer Counter Mode), 或SIC模式(Segmented Integer Counter)。
CTR模式与OFB类似,不同的地方在于,CTR使用块加密计算异或参数时,不再使用前一个异或参数作为块加密参数,而是用计数器获取的计数作为块加密参数。计数器的计数通过某种累加计算得出,首次计算使用初始化向量IV。计数器需要保证相同的块拿到相同的计数,不同的块拿到不重复的计数。
CTR对IV的随机性要求低一些,可以使用 Nonce,不重复即可。
CTR需要初始化向量IV,需要计数器,不需要事先对明文字节数组做填充。
其过程如下图所示:

CTR与CFB、OFB一样的地方在于,它们都是将分组后的块加密变成了"流加密",因此也不需要对明文做填充。不同的地方在于,它使用计数器来生成每个块的异或参数,每个块的加解密相对独立。
CTR的优势是加解密过程都可以并行化处理,适合用于多核处理器。
CTR需要一个计数器,但CTR本身并没有设计这个计数器的实现逻辑,因此这个计数器会带来额外的,CTR不能控制的风险。
CTR的误差传播很小,一个密文块的误差或篡改只会影响当前密文块的解密结果。
CTR模式的实现可以参考golang源码:
https://go.dev/src/crypto/cipher/ctr.go
2.3.7 GCM模式
GCM, 伽罗瓦/计数器模式(Galois/Counter Mode)。
GCM是在CTR模式的基础上,增加了认证操作的分组模式,这种模式也被称为认证加密模式。
在TLS协议中,握手结束后的通信使用的是对称加密。在较低的TLS版本中,主要使用CBC这种单纯的分组模式。这些分组模式不能保证消息的完整性与真实性,因此在对称加密结束后,还需要一个HMAC算法,用来计算消息的MAC并将MAC附在消息后面。这是起初的认证加密(Authenticated encryption, AE)的思路,加密和认证是分开的。
但无论是先对明文做HMAC再加密,还是先加密再进行HMAC,后来都被认为不够安全。于是密码学家们开始设计一种将加密和认证放在一起完成的模式,这就是authenticated encryption with associated data,简称AEAD,是AE的变种。TLS1.3的密码套件开始支持这种AEAD的模式,如GCM。
AEAD是一种设计,一种接口;而GCM模式就是AEAD的一种具体实现。
无论是AEAD还是AE,只要支持认证加密,一旦传播过程发生随机性误差或被篡改,那么解密过程就直接终止,因此误差传播这个特征就没有意义了。
GCM需要初始化向量IV,需要计数器,不需要事先对明文字节数组做填充。
其加密过程如下图所示(解密过程与加密过程相同):

GCM模式的加密过程与CTR基本相同,不同之处是在密文块生成之后添加了生成校验块的逻辑:
- 首个计数
Counter 0通过块加密得到的值作为GMAC函数的密钥H。 GMAC函数是伽罗瓦消息验证码函数,利用伽罗华域(Galois Field,GF,有限域)乘法运算来计算MAC。- 每个块做完块加密与异或得到密文块之后,将密文块与前一个块的GMAC值做异或,然后计算这个异或结果的GMAC值;首个块使用
Auth Data附加验证消息的GMAC值作为"前一个块的GMAC值"。 - 最终得到的GMAC值再做一次GMAC运算以及异或运算后得到的
Auth Tag作为本次消息加密的认证码,与加密结果一起作为加密的最终结果(密文+认证码)。 - 解密过程会在上述步骤完成后,验证再次计算出的
Auth Tag是否与加密过程的Auth Tag相同。
GCM拥有CTR的优势,支持并行化计算;此外,由于加入了认证操作,还同时确保了消息的完整性与真实性。
GCM模式的实现可以参考golang源码:
https://go.dev/src/crypto/cipher/gcm.go
三、AES加解密过程
AES是目前最流行的对称加密算法,它支持前面描述的各种分组模式,而AES的核心算法,就是上述分组模式中的块加密与块解密。
AES块加密的基本逻辑是:先将密钥扩展为4个一组的N轮密钥;在执行块加密时,将输入的16个字节的明文块进一步拆分为4个小块,然后利用准备好的每一轮密钥对这四个小块做N轮的加密运算。
3.1 AES块加密过程
AES的BlockSize是16字节(128位),密码支持128/192/256位,其块加密过程:
- 对密钥进行扩展(
expandKey)得到轮密钥,128/196/256位的密钥分别是16/24/32字节,会被扩展为长度为44/52/60的轮密钥数组(元素是int整数),会在后续的n轮计算中按4个一组分开使用,使用11/13/15轮。 - 将明文块以4个字节为单位切分为4个小块,并将每个小块转为整数int。
- 第一轮计算,将4个小块的整数值与分别与轮密钥的前四个整数(即第一轮密钥)进行异或运算,这个计算被称为
密钥加法层(也叫轮密钥加,英文Add Round Key)。 - 从轮密钥的第5个元素开始,每四个元素一轮,与前一轮计算结果做设计好的系列运算,分别是
字节代换层(SubByte)、行位移层(Shift Rows)、列混淆层(Mix Column)和密钥加法层,实际在代码中就是一个复杂的含有各种位移、异或等运算的公式。128/196/256位的密钥得来的轮密钥分别会在这里重复9/11/13轮。 - 最后一轮计算,使用轮密钥中最后4个元素,只做
字节代换层、行位移层、密钥加法层。 - 将最终的结果拼接起来,就是本次块加密的结果密文块。
整个过程如下图所示:

图中涉及算法:
密钥加法层: 数学上是扩展域加法,这里实现时与异或运算等价。由于异或运算的对称性,在块解密时的密钥加法层也是异或。字节代换层: 让输入的数据通过S_box表完成从一个字节到另一个字节的映射,这里的S_box表是通过某种方法计算出来的(参考资料:https://csrc.nist.gov/publications/fips/fips197/fips-197.pdf)。代码实现中通常会事先计算好两个S_box表的数据,一个S盒一个逆S盒,块加密时用S盒,块解密时用逆S盒(逆字节代换层)。行位移层: 将输入数据作为一个4*4的字节矩阵进行处理,然后将这个矩阵的字节进行位置上的置换。块解密时行位移处理与块加密时的处理相反,称为逆行位移层。通常将行位移层与列混淆层统一称为扩散层,目的是将单个位上的变换扩散到整体,从而达到雪崩效应。列混淆层: AES算法中主要的扩散元素,它混淆了输入矩阵的每一列,使输入的每个字节都会影响到4个输出字节。行位移层和列混淆层的组合使得经过三轮处理以后,矩阵的每个字节都依赖于16个明文字节成可能。其中包含了矩阵乘法、伽罗瓦域内加法和乘法的相关知识。块解密时的处理相反,称为逆列混淆层。expandKey: 将AES的密钥(16/24/32)按4个字节为单位拆分为4/6/8个小块,转为一组int整数,再通过G函数(利用字节翻转、S盒代换等运算)以及异或等算法对这组整数做递增式运算,最终扩展出一个长度为原密钥长度+28 = 44/52/60的int数组,称为轮密钥。轮密钥每4个算作一组,用于块加密的一轮计算。对这个轮密钥的每一组做反转(包含S盒映射)得到一个新的轮密钥,用于块解密时的每一轮计算。具体算法参考FIPS-197, Figure 11。
通过AES的块加密算法,我们可以进一步理解密码学算法的两个原则: 混淆与扩散。
混淆的目的,是隐藏输出(这里就是密文)与输入(这里是明文和密钥)之间的映射关系,使之变得尽可能复杂而难以分析。一个合格的对称加密算法,在使用混淆手段之后,应达到这样的效果: 密文中的每个比特位都同时依赖于密钥和明文数据的多个部分,密文和明文/密钥之间无法建立直接映射。混淆常用的方法是替换与排列。
扩散的目的,是隐藏输出(这里就是密文)与输入(这里是明文)之间的统计学关系,使输入原本的统计结构扩散到输出全局中去,从而无法根据输出的统计学特征分析输入的统计学特征。一个合格的对称加密算法,在使用扩散手段之后,应达到这样的效果: 明文单个比特位或密钥单个比特位的影响扩大到大部分密文的比特位,如果改变输入(明文或密钥)的某一个比特位,则会引起密文中大部分比特位的变化。扩散常用的方法是置换。
AES块加密算法中行位移层与列混淆层的算法设计,其主要目的,就是实现混淆和扩散。
3.2 AES块解密过程
AES块解密的过程与加密过程正好相反,将块加密的图示从后往前倒推即可。不同的地方在于:
- 块解密时轮密钥的使用顺序与块加密时轮密钥的使用顺序相反。
- 每轮使用的算法是块加密中使用的算法的逆算法,如逆字节代换层、逆行位移层、逆列混淆层;密钥加法层实际就是异或,不需要逆算法。
3.3 AES代码实现与使用
具体的AES块加解密实现,可以参考golang源码:
https://go.dev/src/crypto/aes/block.go
golang的crypto库,将分组模式与块加解密做了抽象分离,分组模式相关包只负责各种分组模式的实现,具体的块加解密则由对应的包来实现。比如这里的crypto/aes/block.go,里面只有AES的块加解密的实现,而没有分组模式的实现。在使用时,按照golang设计的方式组装分组模式与块加解密算法即可。示例如下:
// 使用IV与key对明文字节数组s做AES对称加密,分组模式为CBC。
// 需要事先对明文字节数组做填充,建议使用PKCS#7;
// key支持128/192/256位;
// IV必须128位;
// 返回值是 IV + 密文数组.
func aesCBCEncryptWithIV(IV []byte, key, s []byte) ([]byte, error) {// 检查明文字节数组是否已填充if len(s)%aes.BlockSize != 0 {return nil, errors.New("invalid plaintext. It must be a multiple of the block size")}// IV长度检查if len(IV) != aes.BlockSize {return nil, errors.New("invalid IV. It must have length the block size")}// 初始化AES块加解密器block, err := aes.NewCipher(key)if err != nil {return nil, err}// 为密文数组申请空间,会在开头附上IV,因此长度是BlockSize+len(s)ciphertext := make([]byte, aes.BlockSize+len(s))// 将IV复制到密文数组的前BlockSize个字节copy(ciphertext[:aes.BlockSize], IV)// 使用CBC模式mode := cipher.NewCBCEncrypter(block, IV)// 调用加密函数,注意传入的密文数组是从BlockSize个字节后开始的mode.CryptBlocks(ciphertext[aes.BlockSize:], s)return ciphertext, nil
}四、SM4加解密过程
SM4是我国国家标准的商用密码体系中提供的一种分组密码算法,可以参考国标GB/T 32907-2016。
GB/T 32907-2016在线文档:
http://c.gb688.cn/bzgk/gb/showGb?type=online&hcno=7803DE42D3BC5E80B0C3E5D8E873D56A
SM4的BlockSize为16字节128位,密钥长度也是16字节128位,不支持其他长度。SM4的块加密的计算轮次固定为32轮,块加密和块解密使用相同的轮密钥,只是块解密时将轮密钥逆序使用即可。
SM4的块加密过程:
- 对密钥进行扩展,得到一个长度为32的int数组作为轮密钥数组。每轮计算使用一个int整数作为轮密钥。
- 对明文块做4个字节为单位的切分,得到4个
字,SM4里定义一个字为4字节。 - 对4个
字做32轮迭代计算,每轮通过轮函数F,输入最近4个字和本轮密钥计算下一个字。如第一轮输入前四个字和第一轮密钥计算第5个字,第二轮输入第2~5个字和第二轮密钥计算第6个字,以此类推,计算32轮后,一共有36个字。 - 将32轮迭代后的最后4个
字进行反序拼接,得到16个字节的密文块。
整个过程如下图所示:

图中涉及算法:
轮函数: 接收4个字和一个轮密钥,输出一个字。计算逻辑是对输入参数做异或与合成置换(由非线性变换和线性变换复合而成),从而在重复32轮后,将单个位上的混乱因素扩展到整体。其中非线性变换就是对输入的每个字节做S盒映射;线性变换则是将非线性变换的结果作为输入,再进行连续的位移和异或运算。具体的公式可以在GB/T 32907-2016的文档中查看。expandKey: SM4的密钥长度固定为16字节,即4个字,其密钥扩展算法类似轮函数,对四个字进行32轮迭代,生成32个轮密钥。每次迭代的计算逻辑也类似轮函数,从既有的四个字开始,通过异或与合成置换不断计算出新的轮密钥。这里的合成置换中的非线性变换与轮函数中的非线性变换相同,线性变换的逻辑则略有不同。具体的公式同样可以在GB/T 32907-2016的文档中查看。
可以看到,SM4的混淆与扩散是通过32轮迭代的轮函数实现的。
五、对称加密的密钥与IV
对称加密算法的密钥和IV通常都要求使用一个伪随机数,最好是密码学安全的伪随机数。有时直接用某个PRNG或CSPRNG生成,有时则使用密钥派生算法派生。
以CSPRNG为例,在golang中可以这样获取指定长度的密钥或IV:
import (..."crypto/rand"...
)func GetRandomBytes(len int) ([]byte, error) {if len < 0 {return nil, errors.New("len must be larger than 0")}buffer := make([]byte, len)n, err := rand.Read(buffer)if err != nil {return nil, err}if n != len {return nil, fmt.Errorf("buffer not filled. Requested [%d], got [%d]", len, n)}return buffer, nil
}上面获取伪随机数的语句n, err := rand.Read(buffer)使用的是golang的crypto/rand包,对应的是使用系统熵值的CSPRNG,生成的是一个密码学安全的伪随机数。
六、小结
对称加密是加密和解密都使用同一个密钥的加密算法,目前主流的对称加密算法是分组加密,如AES与SM4。分组加密是将明文分组后,对每个明文块做加密再拼接的加密算法。分组加密支持多种分组模式,常用的有CBC/CTR/GCM等。对称加密具有速度快的优点。在安全性方面,对称加密能够确保消息的保密性。此外,如果使用了GCM这样具有认证功能的分组模式,那就还可以确保消息的完整性与真实性。但对称加密的密钥共享是一个问题。
参考文章:
密码学学习笔记_04_对称加密 - 知乎