引言
Abstract
文献阅读
1、题目
X-HRNET: TOWARDS LIGHTWEIGHT HUMAN POSE ESTIMATION WITH SPATIALLY UNIDIMENSIONAL SELF-ATTENTION
2、引言
高分辨率表示是人体姿态估计实现高性能所必需的,随之而来的问题是高计算复杂度。特别地,主要的姿态估计方法通过2D单峰热图来估计人体关节。每个2D热图可以水平和垂直地投影到一对1D热图向量并由一对1D热图向量重建。受这一观察的启发,我们引入了一个轻量级和强大的替代方案,空间一维自注意(SUSA),逐点(1× 1)卷积是dependency可分离3×3卷积中的主要计算瓶颈。我们的SUSA将逐点(1×1)卷积的计算复杂度降低了96%,而不牺牲精度。此外,我们使用SUSA作为主要模块来构建我们的轻量级姿势估计骨干X-HRNet,其中X表示估计的十字形注意力向量。COCO基准上的大量实验证明了我们的X-HRNet的优越性,全面的消融研究表明了SUSA模块的有效性。
3、创新点
- 引入了Spatially Unidimensional Self-Attention(SUSA)模块,通过Stripe Context Modeling(SCM)和Spatially Unidimensional Transform(SUT)实现了轻量级人体姿势估计。
- 提出了X-HRNet网络,利用SUSA模块作为主要模块,实现了轻量级的人体姿势估计网络。
4、空间单维自我注意 Spatially Unidimensional Self-Attention(SUSA)
SUSA模块遵循全局上下文块(GC块)的设计模式,其详细结构如下图(a)所示
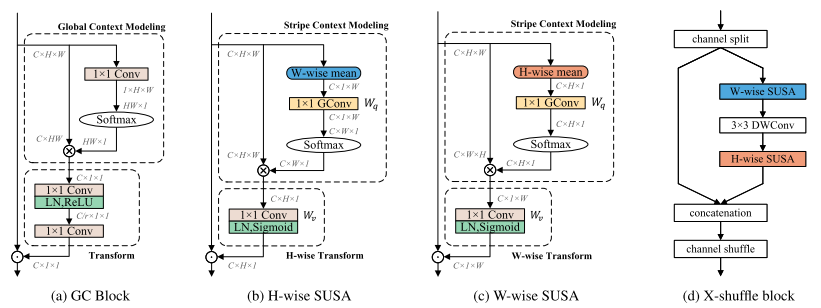
GC块的架构,本文的SUSA和X-shuffle块。为了直观理解,特征被抽象为特征维度,例如,C ×H ×W表示具有通道号C、高度H和宽度W的特征图。表示矩阵内积,表示逐元素乘法,以及表示逐元素加法。
对于输入特征映射x ∈ ,存在两个空间维度:H和W。提出了两个相应的SUSA:H-wise和W-wise SUSA。如上图b和图c所示,除了处理不同的空间维度之外,它们完全相同。SUSA可以分为三个过程:1)条带上下文建模(SCM)。SCM仅使用分组矩阵xq沿沿着一个空间维度(H或W)对特征进行分组,并输出条带上下文特征,这与将所有位置的特征分组在一起的GC块中的全局上下文建模不同。2)空间一维变换(SUT)。SUT通过逐点(1 × 1)卷积对分组特征进行变换,该卷积在剩余的空间维度上学习注意力向量。3)功能聚合。采用逐元素乘法将学习的注意力向量与输入特征图聚合。
本文的SUSA公式如下:
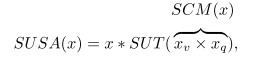
4.1、Stripe Context Modeling (SCM)
为了达到表示容量和效率的折衷,我们采用1 × 1群卷积 (group=C)对
∈
计算分组矩阵
,
由x沿沿着H维加权平均计算得到.随后通过Softmax归一化激活
,以增加注意力的动态范围。
的计算公式如下:
![]()
4.2、Spatially Unidimensional Transform (SUT)
CCW和GC块都使用两个具有瓶颈结构的级联1 × 1卷积来学习条件权重。这个技巧减少了FLOP,但引入了额外的卷积,实际上降低了推理速度。为了简化,本文的H-wise SUT通过单个1 × 1卷积对 进行编码,并输出最终的水平注意力向量
。具体地,ah通过C维上的LayerNorm(LN)(如GC块)来归一化,并通过Sigmoid函数来激活。估计
被广播倍增到x作为横向关注。相应地,W方向的SUT学习垂直注意,并通过按元素相乘将其合并为x。SUT的公式如下:
![]()
4.3、Relationship to global context block
本文的SUSA模块借鉴了GC模块的设计方案,GC块是Non-Local Network 的一个有效变体,它旨在捕获整个2D空间中的长程依赖关系。本文利用的能力,捕获长程依赖成组功能沿着一个空间维度和估计的条纹上下文功能,而不是全局上下文功能。值得注意的是,本文通过乘法将条带上下文特征聚合到输入特征作为水平或垂直注意力向量,而GC Block通过加法聚合全局上下文。下图展示出了一个玩具示例如下
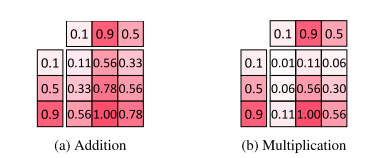
倍增融合产生比加法融合更尖锐的峰值和更小的聚焦区域。融合后对输出值进行归一化处理。
乘法融合比加法融合产生整形器峰值和更小的激活区域。GC块被设计为对长程依赖性进行建模,并且加法融合学习大的感受野。然而,我们的SUSA模块的目标像素级峰值最大化,乘法融合更适合。