目录
leetcode题目
一、数组中两元素的最大乘积
二、最后一块石头的重量
三、数据流中的第 K 大元素
四、前K个高频元素
五、前K个高频单词
六、数据流的中位数
七、有序矩阵中的第K小的元素
八、根据字符出现频率排序
leetcode题目
一、数组中两元素的最大乘积
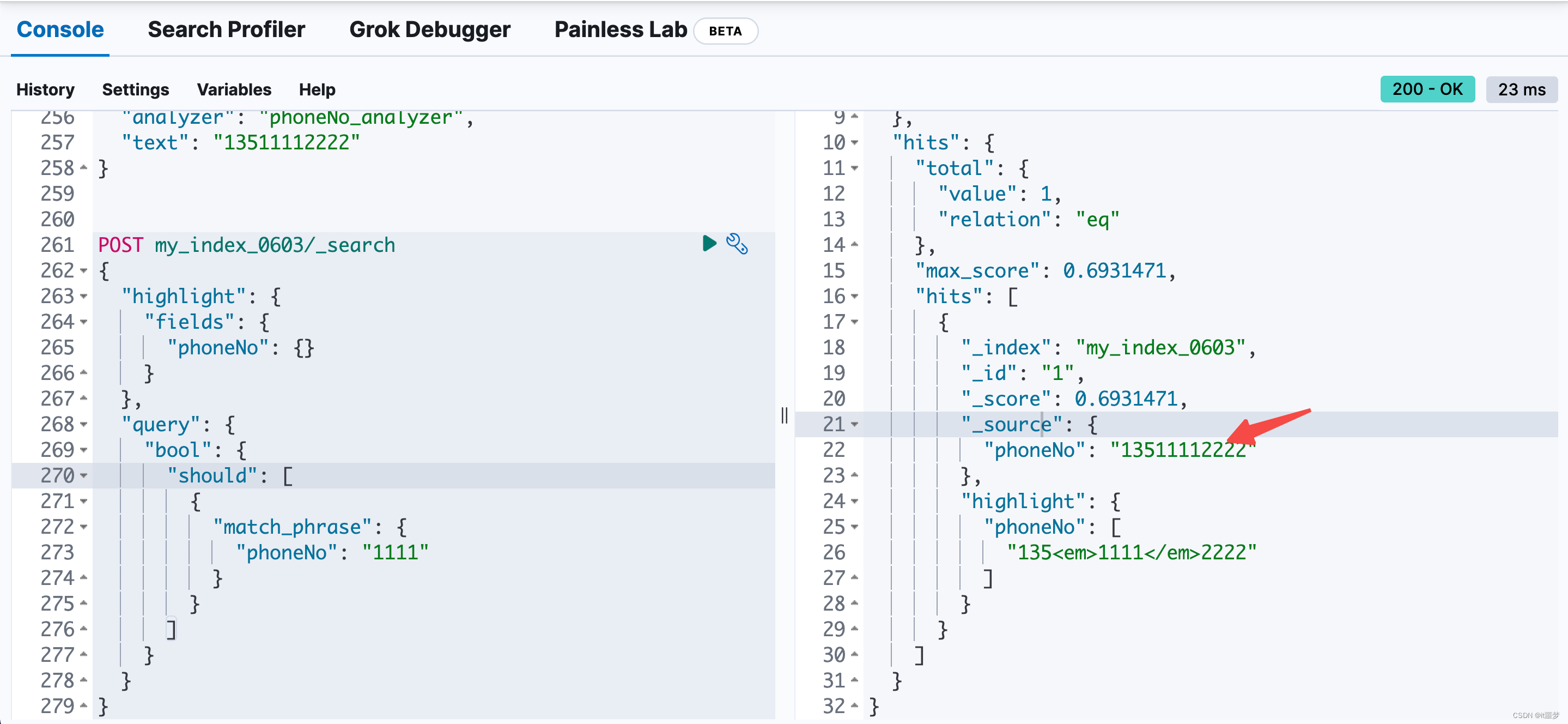
1464. 数组中两元素的最大乘积 - 力扣(LeetCode)![]() https://leetcode.cn/problems/maximum-product-of-two-elements-in-an-array/1.题目解析
https://leetcode.cn/problems/maximum-product-of-two-elements-in-an-array/1.题目解析
求数组中最大的两个元素top1, top2, 返回(top1-1)*(top2-1)
2.算法分析
遍历数组,放入优先级队列中,pop出最大的两个元素,求结果即可
3.算法代码
class Solution {
public:int maxProduct(vector<int>& nums) {priority_queue<int> q;for(auto x : nums)q.push(x);int top1 = q.top();q.pop();int top2 = q.top();q.pop();return (top1-1) * (top2-1);}
};二、最后一块石头的重量
1046. 最后一块石头的重量 - 力扣(LeetCode)![]() https://leetcode.cn/problems/last-stone-weight/description/1.题目解析
https://leetcode.cn/problems/last-stone-weight/description/1.题目解析
每次选取最重的两块石头,两两碰撞,重量小的粉碎,重量大的石头剩余重量为原始重量-重量小的石头的重量,最终如果剩一块石头,就返回该石头的重量;如果没有剩石头,就返回0
2.算法分析
用堆(优先级队列) 模拟即可
3.算法代码
class Solution {
public:int lastStoneWeight(vector<int>& stones){priority_queue<int> heap; //默认大堆for(auto x : stones)heap.push(x);while(heap.size() > 1){int a = heap.top();heap.pop();int b = heap.top();heap.pop();if(a > b) heap.push(a-b);}return heap.size() == 1 ? heap.top() : 0;}
};三、数据流中的第 K 大元素
703. 数据流中的第 K 大元素 - 力扣(LeetCode)![]() https://leetcode.cn/problems/kth-largest-element-in-a-stream/1.题目解析
https://leetcode.cn/problems/kth-largest-element-in-a-stream/1.题目解析
实现一个类, 返回给定数组的第K大元素(排序之后的)(不断新增数据)
2.算法分析
典型的top-k问题,用优先级队列来解决~
详见博客: 独树一帜的完全二叉树---堆-CSDN博客
3.算法代码
class KthLargest {
public:KthLargest(int k, vector<int>& nums) {_k = k;for(auto x : nums){heap.push(x); //小堆if(heap.size() > _k) heap.pop();}}int add(int val) {heap.push(val);if(heap.size() > _k) heap.pop();return heap.top();}
private:priority_queue<int, vector<int>, greater<int>> heap; //小堆int _k;
};
四、前K个高频元素
347. 前 K 个高频元素 - 力扣(LeetCode)![]() https://leetcode.cn/problems/top-k-frequent-elements/1.题目解析
https://leetcode.cn/problems/top-k-frequent-elements/1.题目解析
给定一个数组,返回该数组中出现次数最多的k个元素, 顺序任意
2.算法分析
典型的top-k问题,不过求的不是前K大的元素或前K小的元素,而是求前K个出现次数最多的元素,因此我们先用哈希表绑定每个元素和其出现的次数;然后定义优先级队列, 每个元素类型是pair<int, int> (传仿函数指定比较规则,按照pair中的second也就是元素次数进行比较,由于求的是出现次数最多的k个单词,因此建小堆), 最后从优先级队列中提取结果即可
3.算法代码
class Solution {
public:typedef pair<int, int> PII;struct cmp{bool operator()(const PII& p1, const PII& p2){return p1.second > p2.second; //小堆比较规则}};vector<int> topKFrequent(vector<int>& nums, int k) {//1.哈希表统计次数unordered_map<int, int> hash; //单词-次数for(auto& e : nums)hash[e]++;//2.Top-K的主逻辑priority_queue<PII, vector<PII>, cmp> heap;for(auto& pii : hash){heap.push(pii);if(heap.size() > k) heap.pop();}//3.提取结果vector<int> ret(k);for(int i = k-1; i >= 0; i--){ret[i] = heap.top().first;heap.pop();}return ret;}
};五、前K个高频单词
692. 前K个高频单词 - 力扣(LeetCode)![]() https://leetcode.cn/problems/top-k-frequent-words/1.题目解析
https://leetcode.cn/problems/top-k-frequent-words/1.题目解析
返回前k个出现次数最多的单词,如果出现频次相同,按照字典序从小到大排列
2.算法分析
同样是top-k问题,但是比较规则有所变化,在priority_queue中传递仿函数指定比较规则即可~
仿函数博客: stack 与 queue 与 priority_queue 与 仿函数 与 模板进阶-CSDN博客
1.哈希表统计单词出现次数
2.创建大小为k的堆
比较规则:
①单词频次不同时,由于频次高的往前排,因此创建小根堆
②单词频次相同时,谁的字典序小谁往前排,因此创建大根堆
3. top-K的主逻辑
4. 提取结果(注意在vector中存放的顺序)
3.算法代码
class Solution {typedef pair<string, int> PSI;struct cmp{bool operator()(const PSI& a, const PSI& b) {if(a.second == b.second) //频次相同,字典序按照大根堆的方式排列return a.first < b.first;return a.second > b.second;}};
public:vector<string> topKFrequent(vector<string>& words, int k) {//1.哈希表统计单词频次unordered_map<string, int> hash;for(auto& s : words)hash[s]++;//2.创建大小为k的堆priority_queue<PSI, vector<PSI>, cmp> heap; //3.top-k主逻辑for(auto& psi : hash){heap.push(psi);if(heap.size() > k) heap.pop(); }//4.提取结果vector<string> ret(k);for(int i = k - 1; i >= 0; i--){ret[i] = heap.top().first;heap.pop();}return ret;}
};六、数据流的中位数
295. 数据流的中位数 - 力扣(LeetCode)![]() https://leetcode.cn/problems/find-median-from-data-stream/description/1.题目解析
https://leetcode.cn/problems/find-median-from-data-stream/description/1.题目解析
实现一个类,求数据流的中位数(不断新增数据), 奇数个元素返回中位数,偶数个元素返回中间两个数的平均值
2.算法分析
大小堆维护数据流的中位数

1.当 m == n, 中位数就是两个堆的堆顶元素的平均值
2.当 m == n + 1, 中位数就是大根堆的堆顶元素
细节问题: add()函数, 插入num元素
1. m == n
1.1 num <= x 或 m == 0, 此时进入大根堆, m == n + 1
1.2 num > x, 进入小根堆, 此时 n = m + 1, 因此我们需要调整, 只需要把小根堆的堆顶元素挪到大根堆的堆顶即可~
2. m == n+1
2.2 num <= x, 此时进入大根堆, m == n + 2, 因此我们需要调整, 只需要将大根堆的堆顶元素挪到小根堆的堆顶即可~
2.2 num > x, 此时进入小根堆, m == n
3.算法代码
class MedianFinder {
public:MedianFinder() {}void addNum(int num) {if(left.size() == right.size()){if(left.empty() || num <= left.top())left.push(num);else{right.push(num);left.push(right.top());right.pop();}}else{if(num <= left.top()){left.push(num);right.push(left.top());left.pop();}elseright.push(num);}}double findMedian() {if(left.size() == right.size())return (left.top() + right.top()) / 2.0;else return left.top();}
private:priority_queue<int> left; //大根堆priority_queue<int, vector<int>, greater<int>> right; //小根堆
};七、有序矩阵中的第K小的元素
378. 有序矩阵中第 K 小的元素 - 力扣(LeetCode)![]() https://leetcode.cn/problems/kth-smallest-element-in-a-sorted-matrix/1.题目解析
https://leetcode.cn/problems/kth-smallest-element-in-a-sorted-matrix/1.题目解析
求矩阵中第K小的元素
2.算法分析
优先级队列
3.算法代码
class Solution {
public:int kthSmallest(vector<vector<int>>& matrix, int k) {priority_queue<int> heap;int m = matrix.size(), n = matrix[0].size();for(int i = 0; i < m; i++){for(int j = 0; j < n; j++){heap.push(matrix[i][j]);if(heap.size() > k) heap.pop();}}return heap.top();}
};八、根据字符出现频率排序
451. 根据字符出现频率排序 - 力扣(LeetCode)![]() https://leetcode.cn/problems/sort-characters-by-frequency/1.题目解析
https://leetcode.cn/problems/sort-characters-by-frequency/1.题目解析
把出现频率高的字符排在前面, 输出新的字符串
2.算法分析
优先级队列
3.算法代码
class Solution {typedef pair<char, int> PCI;
public:struct cmp{bool operator()(const PCI& p1, const PCI& p2){return p1.second < p2.second; //大堆}};string frequencySort(string s) {//1.哈希表统计频次unordered_map<char, int> hash;for(auto ch : s)hash[ch]++;//2.top-k的主逻辑priority_queue<PCI, vector<PCI>, cmp> heap;for(auto pci : hash)heap.push(pci);//3.提取结果string ret;while(!heap.empty()){auto top = heap.top();for(int i = 0; i < top.second; i++)ret += top.first;heap.pop();}return ret;}
};


![51 单片机[2-2]:LED闪烁](https://img-blog.csdnimg.cn/img_convert/31b43210cc0f152868ad4d19d8c3dfd0.png)