一、Ludwig 介绍
自然语言处理 (NLP) 和人工智能 (AI) 的飞速发展催生了许多强大的模型,它们能够理解和生成如同人类般的文本,为聊天机器人、文档摘要等应用领域带来了革命性的改变。然而,释放这些模型的全部潜力需要针对特定用例进行微调。Ludwig,一个由 Linux 基金会人工智能与数据部门主办的低代码框架,应运而生。并迅速获得了开源社区的广泛关注,在 Github 上已收获 10.9k 颗星。它致力于帮助用户轻松构建定制化的人工智能模型,例如大语言模型 (LLMs) 和其他深度神经网络。

Ludwig 最初由 Piero Molino 于 2019 年在 Uber AI 团队成员 Yaroslav Dudin 和 Sai Sumanth Miryala 的帮助下创建。 如今,Ludwig 已经发展成为一个由 Linux 基金会支持的开源项目,并托管在 Github 上,拥有一个活跃的社区。Ludwig 的开发和维护由 Predibase 的员工和社区贡献者共同完成。
1.1、Ludwig 的主要优势
- 极易上手: 用户仅需使用一个声明式的 YAML 配置文件,即可轻松训练出最先进的 LLM 模型。Ludwig 支持多任务和多模态学习,并提供全面的配置验证功能,能够在运行前检测无效参数组合,避免错误发生。
- 高效性和可扩展性: 自动选择最佳批量大小,支持 DDP、DeepSpeed 等分布式训练策略,并提供参数高效微调(PEFT)、4 位量化(QLoRA)、分页和 8 位优化器等多种优化特性,即使面对超大规模数据集也能轻松应对。
- 专家级控制: 用户可以完全掌控模型的各个方面,细致到激活函数的选择。同时,Ludwig 还提供超参数优化、模型可解释性分析以及丰富的指标可视化工具,满足专业开发者的需求。
- 模块化和可扩展设计: 如同深度学习的“积木”,用户可以通过简单的参数调整尝试不同的模型架构、任务、特征和模态,极大地提升了模型开发的灵活性。
- 面向生产环境: 提供预构建的 Docker 容器,原生支持在 Kubernetes 上使用 Ray 进行模型部署,并支持将模型导出至 Torchscript 和 Triton 等平台,以及一键上传模型至 HuggingFace。
Ludwig 特别容易上手,即使你不是代码高手,也能用它轻松构建各种机器学习和深度学习模型。 你只需要一个简单的 YAML 配置文件,就可以训练出最先进的 LLM 模型,还能玩转多任务和多模态学习,超级方便!从模型训练、微调、参数优化,到最终的可视化和部署,Ludwig 都能帮你轻松搞定。
1.2、Ludwig 的主要功能
- 训练和微调: 支持多种训练模式,包括对预训练模型进行完整的训练和微调。
- 模型配置: 使用 YAML 文件进行配置,允许用户对模型参数进行详细定义,实现高度的可定制性和灵活性。
- 超参数调整: 集成自动超参数优化工具,以增强模型性能。
- 可解释的人工智能: 提供工具帮助用户深入了解模型决策,提高模型的可解释性和透明度。
- 模型服务和基准测试: 简化模型服务的过程,并支持在不同条件下对模型性能进行基准测试。
Ludwig 的整体设计理念是简化 AI 模型的构建和部署流程,无论是 AI 领域的新手还是专家,都可以轻松上手,快速构建出适用于各种场景的定制化 AI 模型。
二、Ludwig 原理
2.1、ECD 技术架构
Ludwig 的核心建模架构被称为 ECD (编码器-组合器-解码器) 架构。它就像一个高效的信息处理工厂,首先将多个输入特征进行编码,然后将它们送入“组合器”模型进行整合。组合器模型处理完这些编码后的信息后,会将结果传递给针对每个输出特征的解码器,最后输出预测结果并进行后处理。您可以进一步了解 Ludwig 的各种组合器模型,例如 TabNet、Transformer 和 Concat (Wide and Deep learning) 等。
ECD 架构的示意图就像一只翩翩起舞的蝴蝶,因此也被称为“蝴蝶架构”。
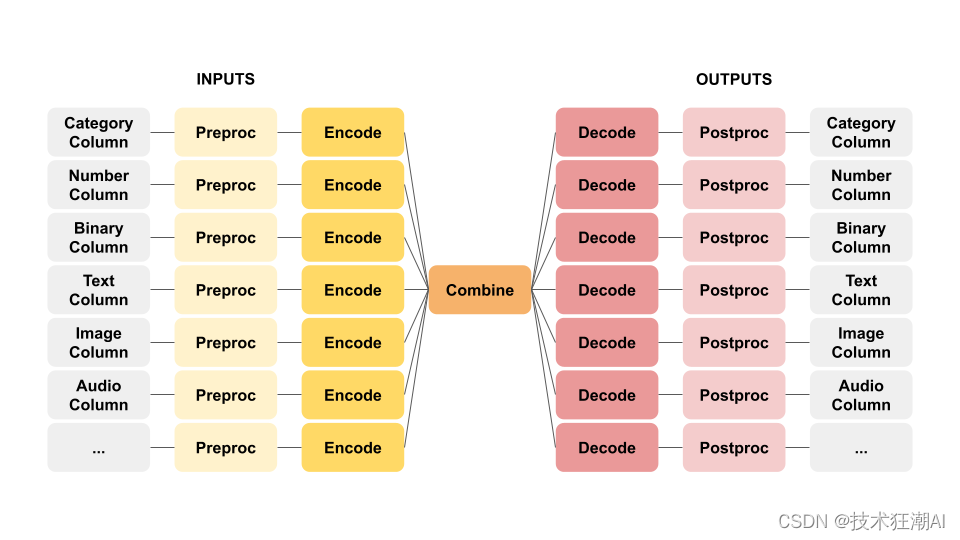
ECD 架构可以灵活处理各种不同类型的输入和输出数据,因此适用于许多不同的应用场景。
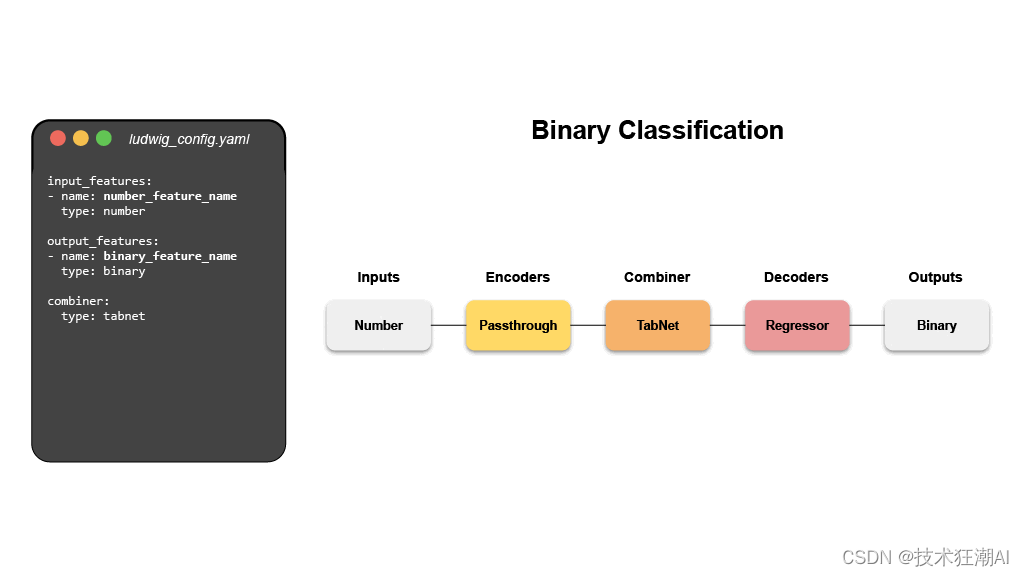
2.2、分布式训练
训练大型 AI 模型,尤其是像 LLM 这种巨无霸,没有分布式训练就像老牛拉破车,效率低得让人心碎。 好消息是,Ludwig 与 Ray 强强联手,完美解决了这个问题,让你的模型训练效率瞬间起飞!
无论你是在轻便的笔记本电脑上,还是在强大的云端 GPU 集群上,甚至是动用成百上千台机器进行史诗级训练,Ludwig 都能轻松应对,而且你不用修改任何代码,就能享受分布式训练带来的速度与激情!
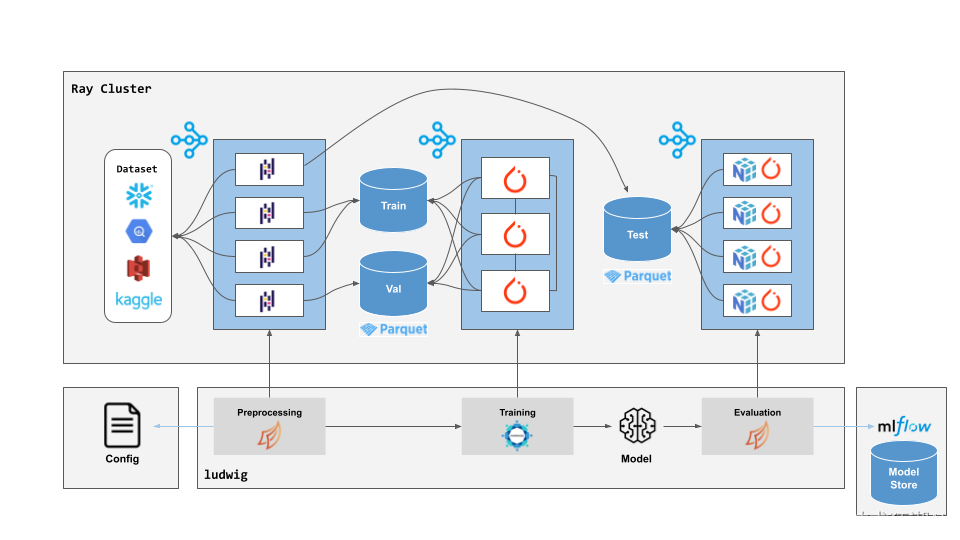
Ludwig 之所以如此优秀,主要归功于与 Ray 的深度整合:
- Ray 集群启动器: 就像一位经验丰富的指挥家,只需一个简单的指令,就能迅速组建起一支强大的计算乐团,为你演奏 AI 的华美乐章。
- Horovod on Ray: 分布式训练的配置过程通常复杂得令人头疼,但有了 Horovod on Ray,一切都变得无比轻松,你只需专注于模型本身,剩下的交给它就好。
- Dask on Ray: 面对海量数据,传统的单机训练就像小马过河,力不从心。Dask on Ray 犹如一座坚固的桥梁,让你轻松跨越数据规模的鸿沟。
- Ray Tune: 寻找最佳超参数就像在迷宫中探索,Ray Tune 为你提供了一盏明灯,在多台机器上并行搜索,快速找到通往成功之路。
三、Ludwig 微调
3.1、微调准备工作
在开始微调之前,让我们先来熟悉一下 Ludwig 及其生态系统。如前所述,Ludwig 是一个用于构建自定义 AI 模型的低代码框架,你可以把它想象成一个 AI 模型的“乐高积木”,它能帮助你构建各种自定义模型,例如大语言模型和其他深度神经网络。从技术角度来看,Ludwig 能够训练和微调任何神经网络,并支持广泛的机器学习和深度学习用例。此外,Ludwig 还提供了可视化、超参数调整、可解释的人工智能、模型基准测试以及模型服务等功能。
Ludwig 使用 YAML 文件来指定所有配置,例如模型名称、要执行的任务类型、微调时的 Epoch 数量、训练和微调的超参数、量化配置等。Ludwig 支持各种以 LLM 为中心的任务,例如零样本批量推理、检索增强生成 (RAG)、基于适配器的文本生成微调、指令微调等。接下来,我们将以 Mistral 7B 模型为例,带你一步步体验如何用 Ludwig 对其进行微调,Ludwig 使用 YAML 文件来配置模型参数,就像写一个简单的清单一样。我们会在后面的例子中详细介绍如何配置。
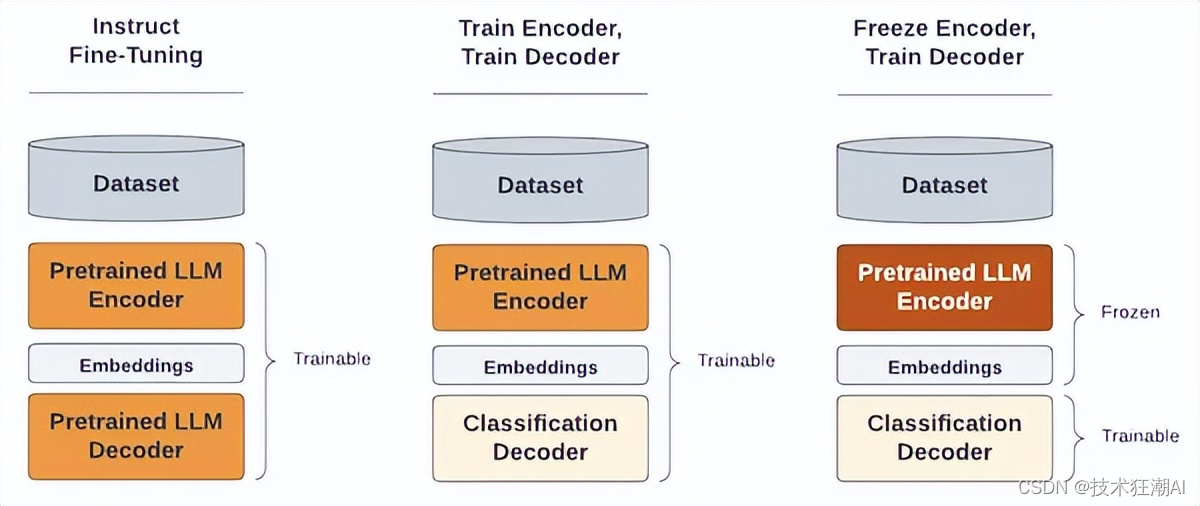
在开始微调你的 AI 模型之前,需要做一些准备工作,一般包括以下几个方面:
- 环境设置: 安装必要的软件和软件包。
- 数据准备: 选择和预处理合适的数据集。
- YAML 配置: 在 YAML 文件中定义模型参数和训练选项。
- 模型训练和评估: 执行微调过程并评估模型性能。
3.2、Ludwig 微调 LLM 详细步骤
请注意,本文中的代码示例将在 VSCode 环境中运行,但您也可以在 Kaggle Notebook、Jupyter 服务器以及 Google Colab 等其他环境中运行这些代码。
3.2.1、安装必要的软件包
如果遇到 Transformers 版本的运行时错误,请执行以下操作。
%pip install ludwig==0.10.0 ludwig[llm]
%pip install torch==2.1.2
%pip install PyYAML==6.0
%pip install datasets==2.18.0
%pip install pandas==2.1.4
%pip install transformers==4.30.23.2.2、导入必要的库和依赖项
import yaml
import logging
import torch
import datasets
import pandas as pd
from ludwig.api import LudwigModel3.2.3、数据准备和预处理
这里我们使用斯坦福大学的 Alpaca 数据集来进行微调。 这份数据集就像是专门为基于指令的 LLM 微调而设计,它是由 OpenAI 的 text-davinci-003 引擎生成的,包含了 52,000 多个指令、每个条目包含指令、对应的任务以及 LLM 的输出。

为了有效地管理计算资源,我们将重点关注前 5,000 行数据。我们将使用 Hugging Face 的数据集库来访问和加载数据集到 Pandas DataFrame 中。
data = datasets.load_dataset("tatsu-lab/alpaca")
df = pd.DataFrame(data["train"])
df = df[["instruction", "input", "output"]]
df.head()3.2.4、创建 YAML 配置文件
我们需要创建一个名为 model.yaml 的 YAML 配置文件,就像一份“训练秘籍”,告诉 Ludwig 如何训练我们的模型。这份秘籍包括以下内容:
- 模型类型: 我们要训练的是 LLM 模型,所以这里要设定为 llm。
- 基础模型: 我们选择使用 Hugging Face 模型库中的 mistralai/Mistral-7B-Instruct-v0.1 模型作为基础,你也可以选择其他预训练模型或者自己训练的模型。
- 输入和输出特征: 这里需要指定模型的输入和输出类型,我们将其分别定义为 instruction 和 output ,代表文本类型,用于处理数据集的输入和模型的输出。
- 提示模板: 这部分就像给模型的“行动指南”,告诉它如何理解你的指令并给出正确的回应。
- 文本生成参数: 这里可以设置一些参数来控制模型生成文本的方式,例如 temperature 参数控制文本的随机性,max_new_tokens 参数控制生成文本的最大长度。
- 适配器和量化: 为了提高模型的效率,我们会使用 LoRA 适配器和 4 位量化技术来优化模型的大小和计算量。
- 数据预处理: 我们会将 global_max_sequence_length 参数设置为 512,将所有输入文本的长度标准化,并将数据集随机划分为训练集和验证集。
- 训练器设置: 最后,我们将模型配置为使用大小为 1 的批次进行一个 Epoch 的训练,使用带预热的余弦学习率调度器和 paged_adam 优化器。
model_type: llm
base_model: meta-llama/Llama-2-7b-hfquantization:bits: 4adapter:type: loraprompt:template: |### Instruction:{instruction}### Input:{input}### Response:input_features:- name: prompttype: textoutput_features:- name: outputtype: texttrainer:type: finetunelearning_rate: 0.0001batch_size: 1gradient_accumulation_steps: 16epochs: 3learning_rate_scheduler:warmup_fraction: 0.01preprocessing:sample_ratio: 0.1这份 YAML 配置文件涵盖了模型训练和微调所需的所有必要参数。 如果你想深入了解更详细的自定义选项,可以参考 Ludwig 的官方文档。
3.2.4.1、在 YAML 文件中“写秘籍”
还记得我们之前提到的“训练秘籍”——YAML 配置文件吗? 我们可以直接在里面定义模型的各种设置,就像这样:
import os
import logging
from ludwig.api import LudwigModel# 在此处设置您的Hugging Face认证令牌
hugging_face_token = <your_huggingface_api_token>
os.environ["HUGGING_FACE_HUB_TOKEN"] = hugging_face_tokenqlora_fine_tuning_config = yaml.safe_load(
"""
model_type: llm
base_model: mistralai/Mistral-7B-Instruct-v0.2input_features:- name: instructiontype: textoutput_features:- name: outputtype: textprompt:template: >-下面是描述任务的指令,与输入配对提供更多背景信息。适当地写一个回复完成请求。### Instruction: {instruction}### Input: {input}### Response:generation:temperature: 0.1max_new_tokens: 64adapter:type: loraquantization:bits: 4preprocessing:global_max_sequence_length: 512split:type: randomprobabilities:- 0.95- 0- 0.05trainer:type: finetuneepochs: 1 # Typically, you want to set this to 3 epochs for instruction fine-tuningbatch_size: 1eval_batch_size: 2optimizer:type: paged_adamgradient_accumulation_steps: 16learning_rate: 0.0004learning_rate_scheduler:decay: cosinewarmup_fraction: 0.03
"""
)3.2.5、使用 LoRA 微调 LLM
万事俱备,只欠东风!现在,我们只需要召唤出 Ludwig 的力量,就可以开始训练模型了。
首先,我们需要实例化一个 Ludwig 模型对象,把我们精心准备的 YAML 配置文件作为参数传递给它,同时,别忘了带上记录器,以便随时跟踪训练进度。 接下来,只需一行简单的代码 model.train(), 就可以启动训练过程啦!
如果遇到错误,请安装以下 Transformers 运行时:
%pip install transformers==4.30.2model = LudwigModel(config=qlora_fine_tuning_config, logging_level=logging.INFO)results = model.train(dataset=df[:5000])仅需两行代码,我们就可以初始化 LLM 微调过程。为了加快训练速度,节省时间和计算资源,我们暂时只用了前 5000 行数据进行训练。这里我使用了 Kaggle 的 P100 GPU 来加速微调过程,您也可以选择使用它来提升微调的速度和性能!
3.2.6、评估模型性能
test_examples = pd.DataFrame([{"instruction": "列举三种不同类型的云.","input": "",},{"instruction": "给以下菜谱提出三个改进建议","input": "鸡肉蔬菜汤:将鸡肉、胡萝卜、芹菜和土豆放入水中煮沸,然后小火慢炖一小时。",},{"instruction": "解释一下什么是量子计算。","input": "",},{"instruction": "用不超过 20 个字描述这张图片","input": "一只金毛猎犬在沙滩上奔跑,背景是夕阳。",},{"instruction": "比较并对比巴洛克和古典音乐的特点。","input": "",},
])predictions = model.predict(test_examples, generation_config={
"max_new_tokens": 64,
"temperature": 0.1})[0]for input_with_prediction in zip(test_examples['instruction'], test_examples['input'], predictions['output_response']
):print(f"Instruction: {input_with_prediction[0]}")print(f"Input: {input_with_prediction[1]}")print(f"Generated Output: {input_with_prediction[2][0]}")print("\n\n")四、模型部署
现在,我们可以将微调后的模型部署到 Hugging Face 平台。请按照以下步骤操作:
4.1、在 Hugging Face 上创建模型仓库
- 访问 Hugging Face 网站并登录您的账号。
- 点击您的个人资料图标,选择 "New Model"。
- 填写必要的信息,并为您的模型指定一个名称。

4.2、生成 Hugging Face API 密钥
- 在 Hugging Face 网站上,点击您的个人资料图标,然后选择 "Settings"。
- 选择 "Access Tokens" 并点击 "New Token"。
- 在生成 Token 时,选择 "Write" 权限。
4.3、使用 Hugging Face CLI 进行身份验证
- 打开命令行终端。
- 使用以下命令登录 Hugging Face,将 <API_KEY> 替换为您生成的 API 密钥:
huggingface-cli login --token <API_KEY>4.4、将您的模型上传到 Hugging Face
使用以下命令将您的模型上传到 Hugging Face,将 <repo-id> 替换为您的模型仓库 ID,将 <model-path> 替换为本地保存模型的路径:
ludwig upload hf_hub --repo_id <repo-id> --model_path <model-path>五、模型微调扩展
现在,你已经掌握了用 Ludwig 微调 LLM 的基本招式。但是,江湖路漫漫,想要训练出独步天下的 AI 模型,还需要不断修炼,拓展训练思路。
好在 Ludwig 非常灵活,就像可塑性极强的武学奇才,可以根据你的需求进行各种调整和扩展。以下是一些修改建议:
- 数据:修炼的根基: 不同的 AI 模型就像不同门派的武功,需要不同的内功心法。根据你想要训练的模型类型和目标,选择合适的数据集至关重要。
# Huggingface datasets and tokenizers
from datasets import load_dataset
from tokenizers import Tokenizer
from tokenizers.models import WordLevel
from tokenizers.trainers import WordLevelTrainer
from tokenizers.pre_tokenizers import Whitespace- 任务:挑战自我,突破瓶颈: 不要局限于指令微调,尝试用 Ludwig 完成更复杂的 NLP 任务,例如文本分类、问答系统等等,不断挑战自我,突破模型的极限。
- 模型:博采众长,融会贯通: Hugging Face 模型库就像一个武学宝库,里面有各种各样的预训练模型。你可以根据自己的需要选择合适的模型,甚至可以将不同的模型组合起来,创造出更强大的模型。
- 超参数:精雕细琢,追求极致: 超参数就像武功招式中的细节,微小的调整就能对模型的性能产生巨大的影响。Ludwig 内置了超参数优化工具,可以帮助你找到最佳的超参数组合,让你的模型发挥出最大威力。
六、总结
Ludwig 就像一位武功高强的引路人,为你打开了 AI 世界的大门。它简单易用,功能强大,即使是初学者也能轻松上手。Ludwig 的低代码框架为将大语言模型 (LLM) 微调至特定任务提供了一种高效便捷的途径,它在易用性和强大的自定义能力之间取得了良好的平衡。通过利用 Ludwig 全面的模型开发、训练和评估功能,开发人员可以构建出针对特定用例量身定制的强大且高性能的 AI 模型,以满足各种现实世界应用场景的需求。
以下是 Ludwig 的核心优势:
- 低代码: 你不需要写大量的代码,只需要一个简单的 YAML 配置文件,就能轻松构建各种 AI 模型。
- 全流程: 从模型训练、微调、超参数优化,到模型可视化和部署,Ludwig 覆盖了 AI 模型开发的整个生命周期。
- 高性能: Ludwig 提供了丰富的优化工具和策略,可以帮助你最大限度地提升模型性能。
- 灵活性: 你可以根据自己的需求调整和扩展 Ludwig,使其适应各种 NLP 任务。
无论你是想要构建聊天机器人、开发文档摘要工具,还是探索其他 AI 应用,Ludwig 都能助你一臂之力。 踏上这段激动人心的 AI 旅程,让 Ludwig 与你并肩作战,共同创造无限可能!
参考资料
[1]. Hugging Face Repo:https://huggingface.co/nitinaggarwal12/ludwig-llm-fine-tuning
[2]. Ludwig Git Repo:https://github.com/nitinaggarwaldbx/ludwig-llm-fine-tuning
[3]. Ludwig AI Framework Documentation:https://ludwig.ai/latest/
[4]. Hugging Face Base Model:https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2
[5]. Stanford Alpaca Dataset:https://huggingface.co/datasets/tatsu-lab/alpaca