适用场景
耗时长,非核心业务,生产者不会用到消息处理结果的情况下,可以将消息交给异步服务去缓存与消费
部署MQ服务
version: "3.0"
services:rabbitmq:container_name: rabbitmq-15672-1image: rabbitmq:3-managementports:- "15672:15672"- "5672:5672"environment:RABBITMQ_DEFAULT_USER: rootRABBITMQ_DEFAULT_PASS: root12315672是rabbitmq server的图形化界面端口
5672是向rabbitmq server发送消息的端口
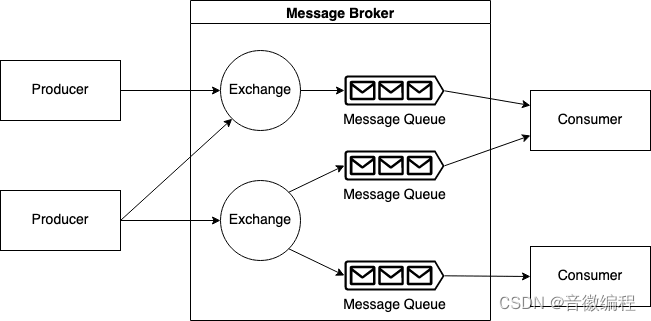
架构
exchange交换机维护生产者列表和队列列表,queue消息队列维护消费者列表
生产者只需要把消息交给交换机,由交换机决定将消息转发给哪一个队列,最后再由队列根据消费者列表,转发消息
类似于数据库或者容器,不同的项目或者服务独占一组交换机和队列,为了避免各组交换机和队列相互影响,采用虚拟主机进行隔离
一个管理员用户对应一个虚拟主机,每个管理员只能操作自己对应的那个虚拟主机中的交换机和队列
消息只能缓存在队列中,如果消息无法到达队列,就会出现消息丢失的问题
客户端
rabbitMQ提供了多种语言的代码客户端,这些客户端通过网络与rabbitMQ服务端进行交互
SpringAMQP
Spring封装了官方提供的API
AMQP:advanced MQ protocol
是一种有关消息队列的高级网络协议,规定了消息如何从生产者出发,经过交换机和队列,最终到达消费者的过程
换句话说,只要遵循了AMQP规范,就能用任何语言,实现消息队列的功能
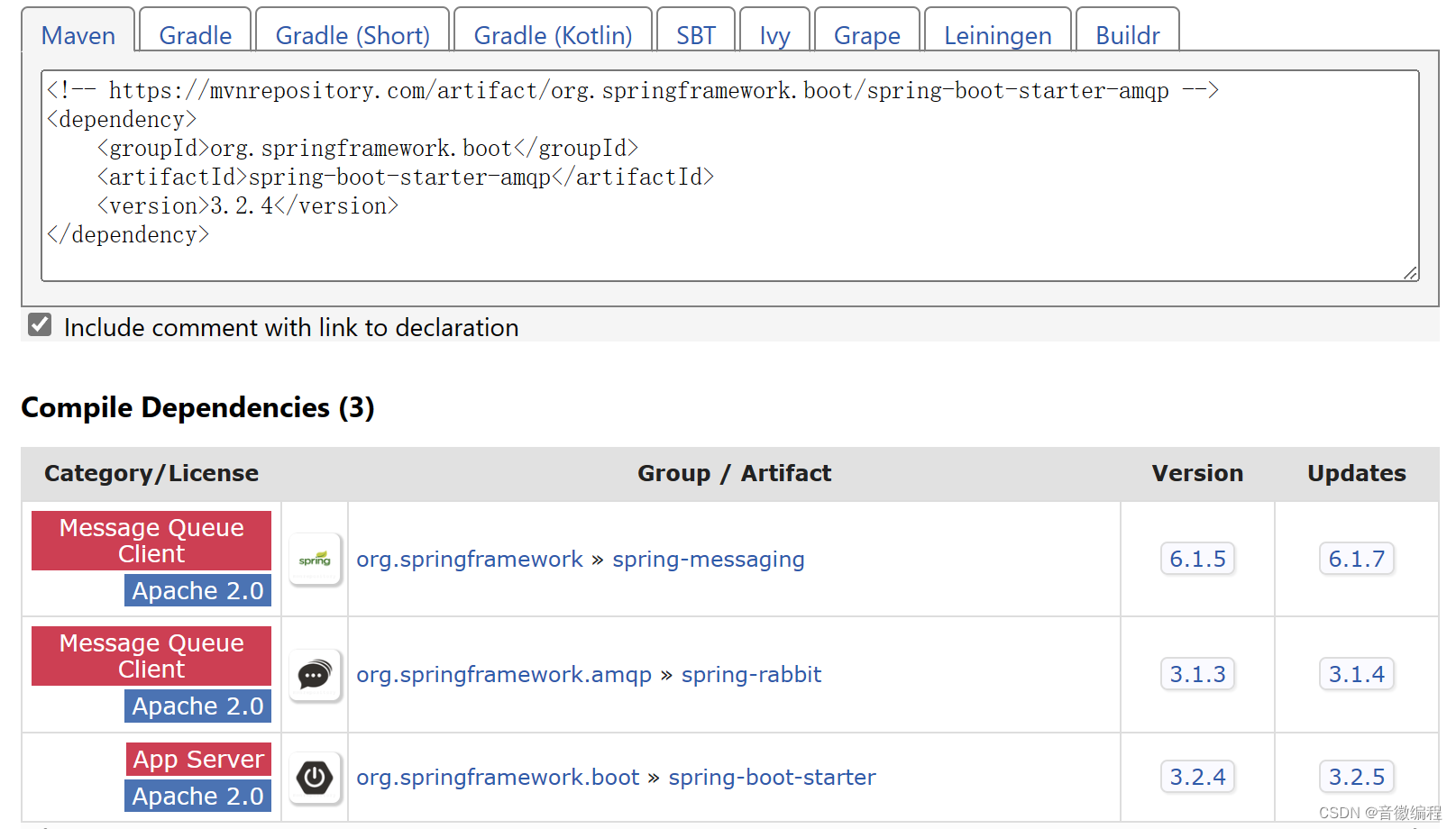
<!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-amqp -->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId><version>3.2.4</version>
</dependency>配置文件
RabbitMQ暴露的用于发消息的端口是5672
spring:rabbitmq:host: localhostport: 5672virtual-host: /v1username: u1password: u1
RabbitTemplate
Spring将功能封装在模板类RabbitTemplate中
生产者
convertAndSend方法实现消息发送到RabbitMQ服务器,并且缓存起来
这个方法需要指定服务端的一个消息队列,以及消息内容
String queue = "test.queue1";String message = "支付成功3";rabbitTemplate.convertAndSend(queue, message);
底层是单独开一个异步线程用来发送消息
/*** 将指定消息发送到交换机** @param channel 单个网络连接中的一个缓存区* @param exchangeArg 目标交换机名称* @param routingKeyArg 路由键值* @param message 待发送的消息* @param mandatory 标记字段* @param correlationData 数据*/public void doSend(Channel channel, String exchangeArg, String routingKeyArg, Message message,boolean mandatory, @Nullable CorrelationData correlationData) {String exch = nullSafeExchange(exchangeArg);String rKey = nullSafeRoutingKey(routingKeyArg);Message messageToUse = message;MessageProperties messageProperties = messageToUse.getMessageProperties();if (mandatory) {messageProperties.getHeaders().put(PublisherCallbackChannel.RETURN_LISTENER_CORRELATION_KEY, this.uuid);}if (this.beforePublishPostProcessors != null) {for (MessagePostProcessor processor : this.beforePublishPostProcessors) {messageToUse = processor.postProcessMessage(messageToUse, correlationData, exch, rKey);}}setupConfirm(channel, messageToUse, correlationData);if (this.userIdExpression != null && messageProperties.getUserId() == null) {String userId = this.userIdExpression.getValue(this.evaluationContext, messageToUse, String.class);if (userId != null) {messageProperties.setUserId(userId);}}if (logger.isDebugEnabled()) {logger.debug("Publishing message [" + messageToUse+ "] on exchange [" + exch + "], routingKey = [" + rKey + "]");}observeTheSend(channel, messageToUse, mandatory, exch, rKey);// Check if commit neededif (isChannelLocallyTransacted(channel)) {// Transacted channel created by this template -> commit.RabbitUtils.commitIfNecessary(channel);}}
消费者
在IoC容器中注册一个监听器bean,绑定消息队列,当消息队列接收到消息时,会通知Spring,由Spring将对应的消息交给监听器处理
/**
* 消息队列监听器bean
* */
@Component
@Slf4j
public class SpringRabbitListener {@RabbitListener(queues = {"test.queue1"})public void listenOnTestQueue1(String message){log.info("接收到test.queue1队列的消息:{}",message);}}
消息分配策略
RabbitMq默认采用轮询的机制向同一队列的多个消费者分配消息,属于平均分配消息,但是,实际生产环境中,各个消费者的处理速度并不一样,那么,最优性能的做法,应该是让处理速度快的消费者处理更多的消息,而不是平均分配
需要设置预分配消息数量,消息队列默认一次性将消息全部平均分配给消费者,这样会导致消费者一次接受过多的消息而处理不过来,而且也不是一种最优的消费方式
可以限制发送给消费者的消息数量,这本质上是一种限流策略
底层是交给channel的basicQos实现限流
void basicQos(int prefetchSize, int prefetchCount, boolean global) throws IOException;
- 请求特定的“服务质量”设置。这些设置对服务器在要求确认之前将交付给使用者的数据量施加了限制。因此,它们提供了一种由消费者发起的流量控制手段。请注意,预取计数必须介于
0 和 65535 之间(AMQP 0-9-1 中的无符号短行)。Params: prefetchSize –
服务器将交付的最大内容量(以八位字节为单位),0 if unlimited prefetchCount – 服务器将传递的最大消息数,0
if unlimited global – true 如果设置应应用于整个通道而不是每个使用者 Throws: IOException
队列
一个队列负责绑定同一类服务的消费者,执行同一个功能
一个交换机可以给多个队列发送消息,也就是可以通知多个不同类型的服务
代码创建队列
SpringAMQP提供了一套用于创建队列的Api
/**
* 创建交换机以及绑定交换机关系
* */
@Configuration
public class FanoutConfiguration {@Beanpublic FanoutExchange fanoutExchange(){return ExchangeBuilder.fanoutExchange("v1.fanout2").build();}@Beanpublic Queue fanoutQueue3(){return QueueBuilder.durable("fanout.queue1").build();}@Beanpublic Binding fanoutBinding1(Queue queue,FanoutExchange exchange){return BindingBuilder.bind(queue).to(exchange);}}
也可以适用注解指定交换机和队列的定义信息和绑定信息
@RabbitListener(bindings = {@QueueBinding(value = @Queue(name = "direct.queue1",durable = "true"),exchange = @Exchange(name = "v1.direct",type = ExchangeTypes.DIRECT),key = {"china.#","japan.#"}),@QueueBinding(value = @Queue(name = "direct.queue2",durable = "true"),exchange = @Exchange(name = "v1.direct2",type = ExchangeTypes.DIRECT),key = {"china.#","japan.#"}),@QueueBinding(value = @Queue(name = "direct.queue3",durable = "true"),exchange = @Exchange(name = "v1.direct3",type = ExchangeTypes.DIRECT),key = {"china.#","japan.#"})})
交换机
交换机只负责将同样的消息发给多个队列,并且不会缓存消息
根据交换机转发消息的策略的不同,可以将交换机分类
RabbitMQ也提供了convertAndSend的重载方法,用于指定交换机
Fanout广播交换机
广播:交换机会将同样的消息发送给所有与它绑定的消费者
public void publish() throws Exception{String exchange = "v1.fanout";for (int i = 0; i < 50; i++) {String message = "消费者消息:"+i;rabbitTemplate.convertAndSend(exchange,"", message);Thread.sleep(20);}}
Direct定向交换机
通过进一步划分消息队列,实现消息的精准投递,划分的关键是RoutingKey和BindingKey的配对,只有RoutingKey和BindingKey匹配时,交换机才会向该队列发送消息
生产者发送的消息都带上一个RoutingKey,那么,这条消息只能发送给拥有配对的BindingKey的队列
类似于,客户端向某个端口发送消息,服务端监听某个端口
Topic交换机
与Direct交换机的投递机制相同,只不过,Topic交换机的key可以是以点分隔的多个单词,并且,支持通配符匹配
*匹配一个单词
#匹配0个或多个单词
序列化和反序列化
消息通过网络传输,以二进制数据形式传输,所以,需要先将消息序列化成字节数组
RabbitMQ客户端默认先将消息转成message对象,再进行序列化,适用默认的SimpleMessageConverter
/*** 根据提供的消息对象创建message对象*/@Overrideprotected Message createMessage(Object object, MessageProperties messageProperties)throws MessageConversionException {byte[] bytes = null;if (object instanceof byte[]) {bytes = (byte[]) object;messageProperties.setContentType(MessageProperties.CONTENT_TYPE_BYTES);}else if (object instanceof String) {try {bytes = ((String) object).getBytes(this.defaultCharset);}catch (UnsupportedEncodingException e) {throw new MessageConversionException("failed to convert to Message content", e);}messageProperties.setContentType(MessageProperties.CONTENT_TYPE_TEXT_PLAIN);messageProperties.setContentEncoding(this.defaultCharset);}else if (object instanceof Serializable) {try {bytes = SerializationUtils.serialize(object);}catch (IllegalArgumentException e) {throw new MessageConversionException("failed to convert to serialized Message content", e);}messageProperties.setContentType(MessageProperties.CONTENT_TYPE_SERIALIZED_OBJECT);}if (bytes != null) {messageProperties.setContentLength(bytes.length);return new Message(bytes, messageProperties);}throw new IllegalArgumentException(getClass().getSimpleName()+ " only supports String, byte[] and Serializable payloads, received: " + object.getClass().getName());}
核心序列化代码:
new ObjectOutputStream(stream).writeObject(object);
可以看出rabbitMQ默认使用jdk的序列化流将对象转化成二进制数据,底层实际是通过字节码进行计算得到一串二进制数
jdk序列化缺点太多,在很多业务中都不适用,缺点有以下:
篡改序列化后的数据,将导致无法通过反序列化还原数据
序列化后的数据体积会增大很多倍
序列化后的数据可读性差
最优的解决方案是选择将对象序列化成Json字符串
通过配置类,来替换rabbitMQ默认的序列化器