https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/
Few-shot: 有例子,效果好;增大了context长度,执行变慢;
可能的问题:1. Label不均衡造成生成label的bias;2.最后一个shot的label容易被输出;3. 常见词比生僻词更容易被输出;
few-shot example选择:
1. 当前question,去example库里搜索语义相似的examples,作为few-shot;
2. 用算法找出彼此最diversity的作为few-shot;
few-shot example顺序:
1. 足够随机;(也可每次推理用不同的order)
Instruct LM:
Instructed LM (e.g. InstructGPT, natural instruction) finetunes a pretrained model with high-quality tuples of (task instruction, input, ground truth output) to make LM better understand user intention and follow instruction.
RLHF (Reinforcement Learning from Human Feedback) is a common method to do so.
trying to be specific and precise and avoiding say “not do something” but rather specify what to do.
写上受众人群:给6岁小孩....;工作中用的...;
Sampling:
用大一些的temperature,多采样几次;用majority vote来决定用谁(分类任务的类别使用;生成句子,两次不太可能重合,不太适用);(输出代码,且有现成的test case,那种,可以多retry几次看哪次判对了)
CoT(Chain of Thought)(“新想”、"Thought"也是这类):
适合复杂任务;适合50B以上的大模型;
Few-shot COT:
Question: Tom and Elizabeth have a competition to climb a hill. Elizabeth takes 30 minutes to climb the hill. Tom takes four times as long as Elizabeth does to climb the hill. How many hours does it take Tom to climb up the hill?
Answer: It takes Tom 30*4 = <<30*4=120>>120 minutes to climb the hill. It takes Tom 120/60 = <<120/60=2>>2 hours to climb the hill. So the answer is 2.
===
Question: Jack is a soccer player. He needs to buy two pairs of socks and a pair of soccer shoes. Each pair of socks cost $9.50, and the shoes cost $92. Jack has $40. How much more money does Jack need?
Answer: The total cost of two pairs of socks is $9.50 x 2 = $<<9.5*2=19>>19. The total cost of the socks and the shoes is $19 + $92 = $<<19+92=111>>111. Jack need $111 - $40 = $<<111-40=71>>71 more. So the answer is 71.
===
Question: Marty has 100 centimeters of ribbon that he must cut into 4 equal parts. Each of the cut parts must be divided into 5 equal parts. How long will each final cut be?
Answer:
0-shot COT:
Question: Marty has 100 centimeters of ribbon that he must cut into 4 equal parts. Each of the cut parts must be divided into 5 equal parts. How long will each final cut be?
Answer: Let's think step by step.
结论:
1. 多采样几次,majority vote,能提升效果;
2. 改变few-shot example的顺序,或改变example选择,增加了随机性,多次采样,能提升效果;
3. 只有answer没有推理过程的训练数据,如果用LLM自动生成一些推理过程,并保留那些同时生成了正确answer的,将这些<question, 推理过程, answer>做训练,能提升效果;(如果训练数据不带answer,权宜之计是用多次采样+majority vote来生成近似answer)
4. 推理链每步之间的分隔符也有trick:
When separating reasoning steps, newline
\nsymbol works better thanstep i, period.or semicolon;
5. 只在top-k个最复杂(步数最多)的sampling输出上,majority-vote得出答案,效果好;
6. 复杂的推理样例few-shot,在复杂question上能提升效果,在简单question上反而伤害效果;
7. "Question:"比"Q:"更有效
8. 自问自答:Prompt-->生成问题1-->生成Answer1-->生成问题2-->...-->生成FinalAnswer而不是问题;(这些生成的问题,可以用大模型回答,也可以搜索知识库、搜索引擎等Tools)

9. Tree of Throught
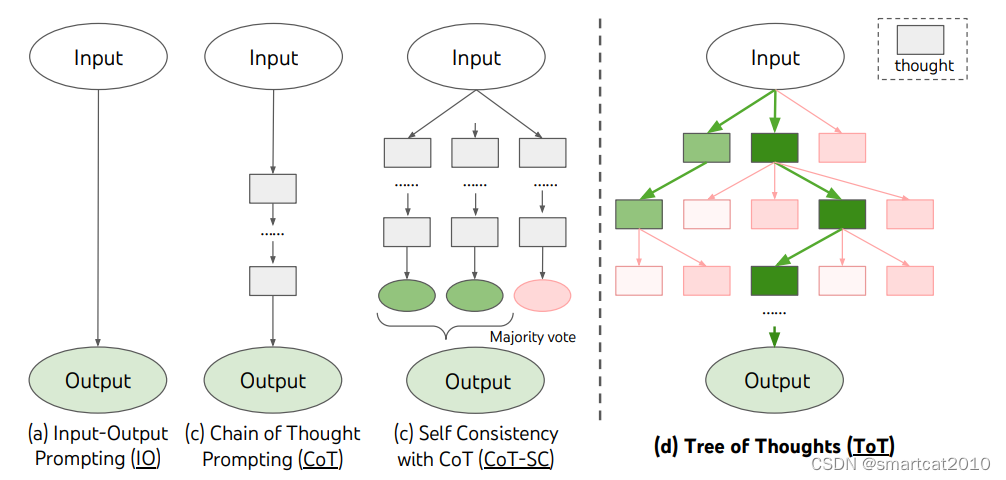

该层的所有节点,放到input-prompt里面,让大模型给出CoT和答案(选谁)。多采样几次,选中最多的那个节点,优先展开。
Automatic Prompt Engineer:
1. 把少量example放到prompt里,让大模型输出instruction:
{{Given desired input-output pairs}}\n\nThe instruction is
2. 对这些种子instruction,进行迭代更新:
Generate a variation of the following instruction while keeping the semantic meaning.\n\nInput: ...\n\nOutput:...
3. 评价每个自动生成的instruction的好坏,用其在validation-set上的生成结果分数之和,来打分;