1,场景描述
假设我们是京东的数据分析师,负责分析母婴产品的购买行为。我们想预测用户是否会购买一款新上线的母婴产品。为了进行预测,我们将利用用户的历史购买数据、浏览行为和其他特征,通过决策树模型进行分析,并提供相应的营销策略建议。
2,具体需求
- 模拟用户数据:包括用户年龄、是否有孩子、浏览母婴产品的频率、历史购买金额、是否参加过促销活动等。
- 构建决策树模型:根据这些数据训练决策树模型,预测用户是否会购买新产品。
- 模型评估与分析:对模型进行评估,并根据模型的结果提供建议。
3,具体代码
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report, confusion_matrix
import matplotlib.pyplot as plt
from sklearn import tree# 模拟用户数据
np.random.seed(42)
num_samples = 1000
data = {'age': np.random.randint(18, 45, num_samples),'has_kids': np.random.choice([0, 1], num_samples),'browse_frequency': np.random.randint(1, 30, num_samples), # 浏览母婴产品频率(次/月)'purchase_history_amount': np.random.uniform(100, 5000, num_samples), # 历史购买金额'participated_promotion': np.random.choice([0, 1], num_samples), # 是否参加过促销活动'bought_new_product': np.random.choice([0, 1], num_samples, p=[0.7, 0.3]) # 是否购买新产品
}
df = pd.DataFrame(data)# 切割自变量和因变量
X = df.drop('bought_new_product', axis=1)
y = df['bought_new_product']# 分割数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 训练决策树模型
clf = DecisionTreeClassifier(max_depth=4, random_state=42)
clf.fit(X_train, y_train)# 预测
y_pred = clf.predict(X_test)# 评估模型
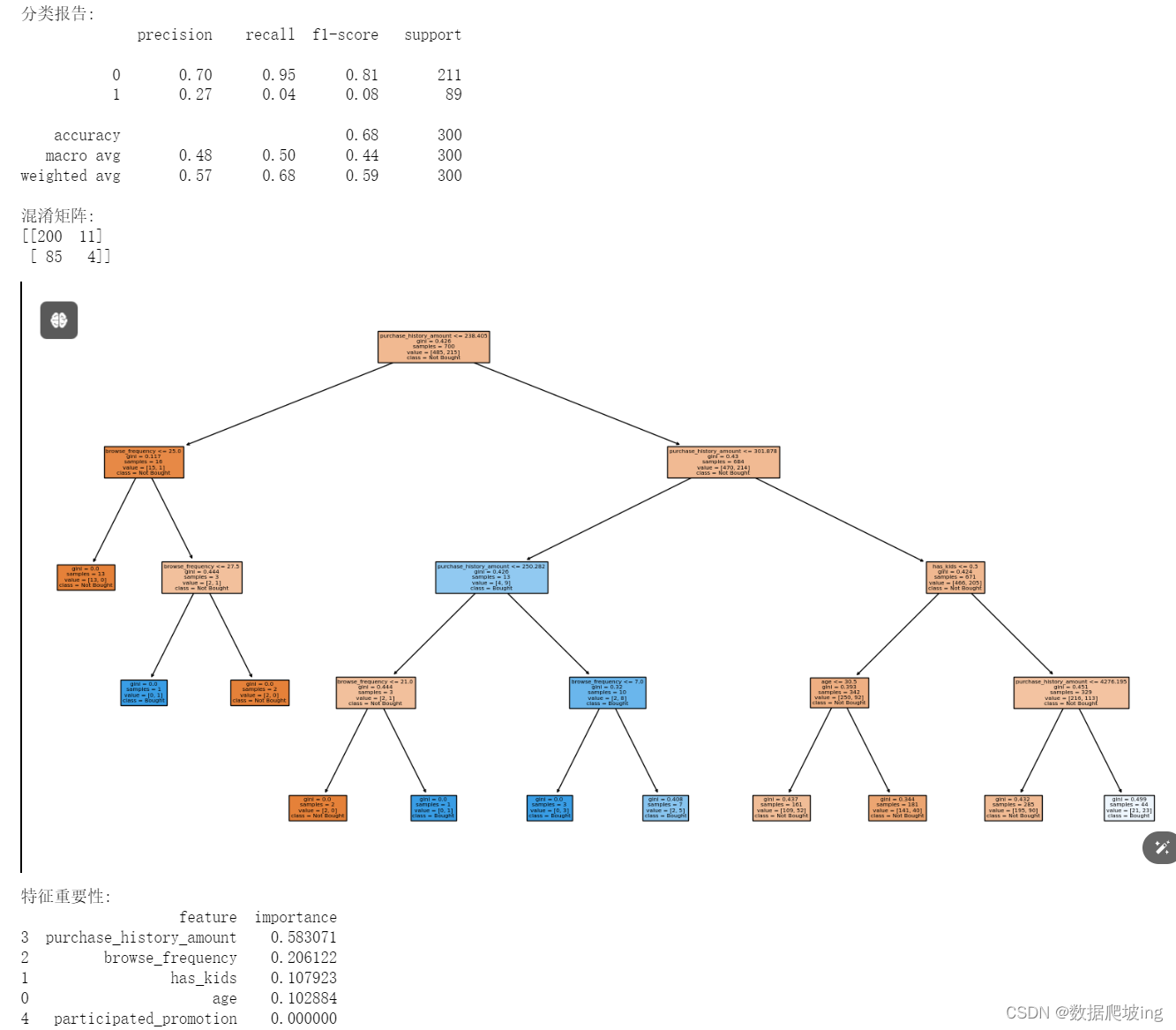
print("分类报告:")
print(classification_report(y_test, y_pred))print("混淆矩阵:")
print(confusion_matrix(y_test, y_pred))# 绘制决策树
plt.figure(figsize=(20,10))
tree.plot_tree(clf, feature_names=X.columns, class_names=['Not Bought', 'Bought'], filled=True)
plt.show()# 模型结果分析与建议
def analyze_feature_importance(model, feature_names):importance = model.feature_importances_feature_importance = pd.DataFrame({'feature': feature_names, 'importance': importance})return feature_importance.sort_values(by='importance', ascending=False)feature_importance = analyze_feature_importance(clf, X.columns)
print("特征重要性:")
print(feature_importance)# 建议
print("建议:")
print("1. 根据特征重要性分析,历史购买金额和浏览母婴产品的频率对新产品购买行为有较大影响,应重点关注这些高频浏览和高消费的用户。")
print("2. 对于没有孩子但有较高浏览频率的用户,可以推送相关的促销活动,增加购买可能性。")
print("3. 针对参加过促销活动但未购买新产品的用户,分析促销活动的效果,优化活动策略。")
print("4. 通过数据分析识别出高潜力用户,重点进行精准营销,提高新产品的销售量。")
4,代码解释
- 模拟用户数据:生成了包含用户年龄、是否有孩子、浏览母婴产品的频率、历史购买金额、是否参加过促销活动和是否购买新产品的数据集。
- 数据预处理:将数据集分为自变量和因变量,并将数据集分为训练集和测试集。
- 训练模型:使用训练集训练决策树模型,并使用测试集进行预测。
- 评估模型:输出分类报告和混淆矩阵,评估模型性能。
- 绘制决策树:展示决策树结构,帮助理解模型的决策过程。
- 特征重要性分析:分析各特征对新产品购买行为的重要性,提供有针对性的营销建议。
5,分析结果与建议
通过对决策树模型的分析,可以得到以下建议:
- 重点关注高频浏览和高消费的用户:这些用户更有可能购买新产品,应针对他们制定个性化的营销策略。
- 推送相关促销活动:对于没有孩子但浏览频率较高的用户,可以推送相关的促销活动,以提高他们的购买意愿。
- 优化促销活动:分析参加过促销活动但未购买新产品的用户,了解促销活动效果,进一步优化促销策略。
- 精准营销:通过数据分析识别高潜力用户,进行精准营销,提升新产品的销售量。
通过这样的分析,可以帮助京东更好地了解用户的购买行为,从而制定更有效的营销策略,提高新产品的销售业绩。
(交个朋友/技术接单/ai办公/性价比资源)