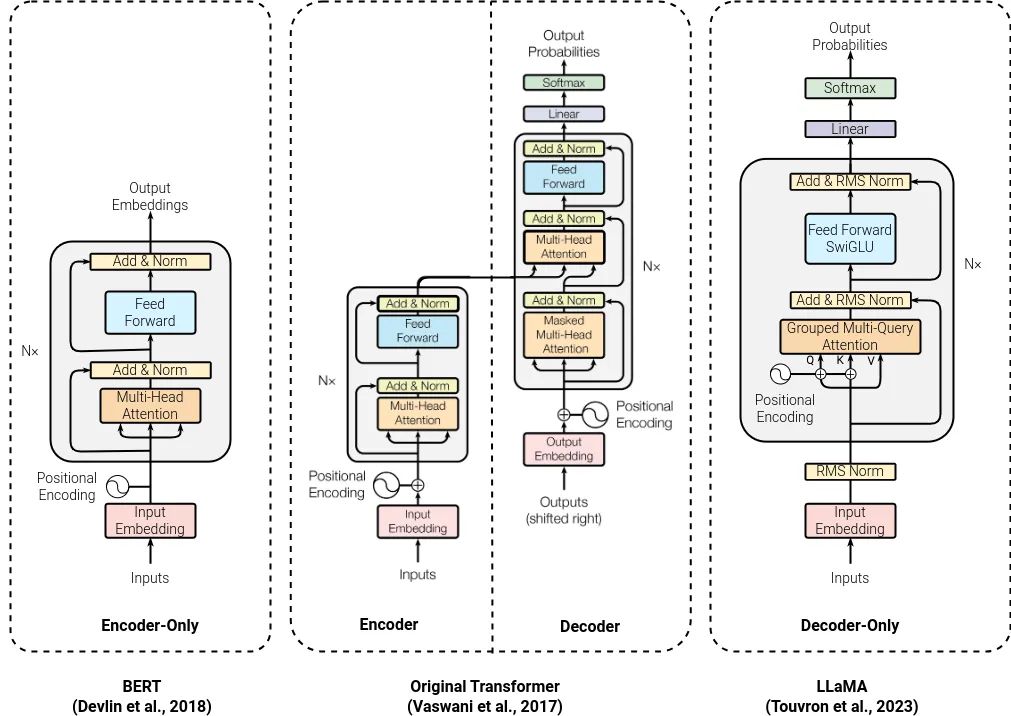
Transformer是一种先进的语言模型,它在预测下一个单词或标记方面与传统的语言模型有所不同,但仍然遵循相同的基本原理。Transformer通过一系列复杂的步骤,将输入的标记序列转换为能够进行预测的丰富向量序列。

在Transformer中,输入的标记首先被转换为词嵌入,形成一组包含不同词嵌入向量的向量。这些向量随后会经历一系列的处理阶段,每个阶段都会为向量添加更多的上下文信息,从而使得每个向量包含更丰富的信息。这样,当向量最终传递给softmax分类层或预测层时,它们已经具备了足够的信息来进行准确的预测。
Transformer的核心是注意力机制,它的作用是衡量序列中每个单词相对于其他单词的重要性和相关性。随着序列通过多个Transformer块,每个块都会进一步丰富向量的信息,使得模型能够更深入地理解序列中的相互作用和上下文关系。
Transformer中的前馈神经网络(Feedforward Neural Network)对每个向量进行非线性变换,增加了模型的复杂性和理解能力。前馈网络的输入宽度与词嵌入的维度相匹配,并且网络的结构和权重在序列中的每个位置上都是相同的,确保了模型能够一致地处理每个标记。
此外,Transformer架构中还包括残差连接和层标准化。残差连接确保了梯度在反向传播期间的自由流动,同时保证了输入序列的信号在处理过程中不会丢失。层标准化则有助于保持训练的稳定性,特别是在处理长序列时。
Transformer的输入是由词嵌入和位置编码组成的,这确保了模型能够保留序列中标记的顺序信息。在输出端,模型通过一个线性神经网络和softmax函数来预测下一个标记,或者根据特定的分类方案对序列进行分类。
Transformer模型拆解使用,包括编码器模型、解码器模型和编码器-解码器模型。编码器模型主要用于理解输入序列而不生成新的标记,解码器模型则专注于生成下一个标记,而编码器-解码器模型则能够将一个输入序列转换为一个完全不同的输出序列,具体取决于任务需求。




![[数据集][目标检测]猕猴桃检测数据集VOC+YOLO格式1838张1类别](https://img-blog.csdnimg.cn/direct/f698b98de7534ab2bd226a25ba7ed7bb.png)