命名空间的设置:
避免冲突
命名空间:
如果将变量全部定义在全局可能不安全,都可以进行修改。
如果将变量定义在局部,当出了大括号就不能使用。
所以说在定义一个命名空间的时候
定义函数,变量,命名空间,都称为命名空间中的实体
//命名空间的定义方式
namespace hh
{
int val1 = 0;
char val2;
}// end of namespace hh大括号后面可以加;也可以不加
定义的时候是没有缩进的,可以在最后一行添加注释使得结尾更加清晰
命名空间的使用方式:三种方式
1.作用域限定符
例如使用std命名空间中的cout 使用std::cout
准确但是繁琐
如果命名空间中套命名空间,需要 :: ::
2.using编译指令 using name space
尽量写在局部,既可以在局部(放在{}中)使用保证在用到的时候才能出来
可能会出现的问题是可能会和全局变量名出现冲突,借助于方式一作用域限定符帮助确定
当不清楚命名空间中的具体情况的时候,不要使用using,因为可能出现命名空间中的实体和自定义的变量和函数出现冲突。
3.using声明机制
初学阶段使用using声明机制,需要什么就添加什么,避免出现using冲突,同时避免每次使用加::
using std::cout;
using std::endl;
仍然是建议将using声明语句放在局部作用域中
【注意】即使命名空间中实体与全局位置实体重名,在局部位置也遵循“就近原则”形成屏蔽
#include <head.h>int num = 10;void test0(){//using声明语句using wd::num;using wd::func;//直接写函数名,不加括号//即使全局作用域存在同名的实体//此处也可以形成屏蔽效果//访问到时wd::numcout << "wd::num:" << num << endl;func();
}int main(){test0();
}对比使用using编译机制如果全局变量和namespace中变量名字相同会出现冲突,但是使用using声明机制在局部使用的时候会对于全局变量形成屏蔽。
命名空间的嵌套使用
//嵌套命名空间设置
namespace wd
{
int num = 100;void func(){cout << "func" << endl;
}namespace cpp
{
int num = 200;void func(){cout << "cpp::func" << endl;
}
}//end of namespace cpp}//end of namespace wd//调用方式
//方式一,使用作用域限定精确访问实体
void test0(){cout << wd::cpp::num << endl;wd::cpp::func();
}//方式二,using编译指令一次性引入cpp的实体
void test1(){using namespace wd::cpp;cout << num << endl;func();
}//方式三,using声明语句
void test2(){using wd::cpp::num;using wd::cpp::func;cout << num << endl;func();
}【注意】在using编译机制中,指明使用哪一个命名空间的需要具体
匿名命名空间(与有名命名空间合在一起称为有名命名空间)
匿名命名空间和static定义的静态有点像,不会被跨文件使用到
匿名空间中的变量以及函数的使用,直接用就可以不像有名空间三种方式。
【注意】全局变量和匿名空间同名的变量和函数时,也就是冲突的时候,会有问题!!
【注意】如果使用::作用域限定符,也无法访问到匿名空间中重名的实体,只能访问到全局的实体。
跨模块调用
(1)跨模块调用函数和变量
【注意】如果是在一个文件中定义一个static变量或者函数那么也不能通过extern引入
【注意】匿名空间同理,这两类只能从本模块使用,不能跨模块使用
1. 可以定义在头文件中,是现在别的文件,然后在该文件中直接调用就可以
出现的问题就是把头文件中的内容全部引入进来,开销比较大
2. 可以使用extern的方式,
//externA.cc
int num = 100;void print(){
cout << "print()" << endl;
}//externB.cc
extern int num;//外部引入声明
extern void print();
void test0(){
cout << num << endl;
print();
}告诉编译器我这有一个缺口,可以进行编译,但是谁来编译填补这个缺口,是在链接的时候确定
g++ externA.cc externB.cc
【注意】大型项目使用的方式往往还是头文件的方式实现,小型文件使用extern方式。因为跨模块调用的关系不清晰,容易出错,比如说如果说多个文件都有同一个变量会出现冲突,外部引用时
(2)跨模块调用有名命名空间
【注意】不能直接用extern wd::val直接引用,需要在该文件中依然定义一个同名命名空间,在文件中使用extern int val;
【注意】在不同的文件中多次定义同名命名空间,多次定义都是放在这一个命名空间中。
【注意】不能跨模块调用匿名命名空间
命名空间中的内容可以进行定义或者声明,命名空间中不能使用实体,也不能对于声明的实体赋值。
命名空间的作用:
1.避免冲突的作用
2. 版本控制,一个版本中的代码保存在一个命名空间中另一个命名空间中
3. 声明主权的作用,命名空间名字(很特别的命名方式)注释可以表明是谁的
命名空间的使用方式:
1. 最好放在命名空间中,而不是全局
2. 尽量在局部使用而不是全局
3. 如果非要使用using编译指令,建议放在所有#include预编译指令后
4. 不要在头文件中使用using编译指令,这样,使得可用名称变得模糊,容易出现二义性
【注意】头文件的使用规则include多个头文件,首先放自定义的头文件,再放C的头文件,再放C++的头文件,最后放第三方库的头文件。
const关键字
const修饰内置类型(系统原有的int)
书写方式:const int num = 10; int const num = 10;对于int和double来说效果是一样的。
使用方式:const关键字必须在一开始的时候就进行赋值,也是一个变量
与宏定义的比较:1.宏定义是在预处理的时候进行替换,const是在编译的时候进行处理 2.宏定义不能明确指明类型容易出错
【重点】const修饰指令类型
对于指针而言不同的书写方式会得到不同的效果。
int num1 = 10;
const int * p = &num1;
//可以修改指向不能修改指向的内容num1 = 20;
//这样也是可以的int const * p = &num1;
//这样也是一样的效果
//point to const 就是指针指向一个const类型元素,也就是不能修改元素值
//理解为围着int转不能修改值const int num3 = 1;
const int * p2 = &num3;
//此处设置指针的时候必须要加上constint num2 = 1;
p2 = &num2;
//const 指针也可以修饰非常量类型数据int num1 = 10;
int * const num = &num1;
//可以通过指针修改指针指向的内容,但是不能修改指向
//称为常量指针 const to point
//可以从右向左看,先看到const再看到*const int num3 = 1;
int * const p2 = &num3;//error
//因为这样定义的时候会理解为可以修改p2指向的内容,但是这个地方在定义num3的时候是不能改变值
//所以这样得话是会报错的const int num3 = 1;
const int * const p2 = &num3;
//双重const无论是是值还是指向都是不改变的区分:数组指针和指针数组
int arr[3] = {2, 3, 4};
arr 是指向第一个元素的地址
&arr是指向整个数组的指针
int *p = arr; //首元素指针
int (*p)[3] = &arr;//数组指针
//使用数组指针获取元素
for(int i = 0; i < num; i++){cout << (*p)[i] << endl;
}
//下标的优先级是比较高的,所以说对于解引用加括号//指针数组
//元素为指针的数组
void test5(){int num1 = 4, num2 = 5, num3 = 6;int * p1 = &num1;int * p2 = &num2;int * p3 = &num3;int * arr[3] = {p1,p2,p3};for(int idx = 0; idx < 3; ++idx){cout << *arr[idx] << " ";}cout << endl;
}函数指针和指针函数
void print(){cout << "print()" << endl;
}void show(){cout << "show()" << endl;
}
int display(int x,int y){return x + y;
}//函数指针
void test6(){//定义函数指针时要确定指向的函数类型和参数信息void (*p)() = print;p();//完整写法void (*p2)() = &print;(*p2)();/* p2 = display; */p2 = show;p2();int (*p3)(int,int) = &display;cout << (*p3)(4,5) << endl;
}//指针函数
//要确保返回的指针所指向的变量的生命周期
//比函数的生命周期更长
int Num = 600;int * f(){return &Num;
}void test7(){cout << *f() << endl;
}
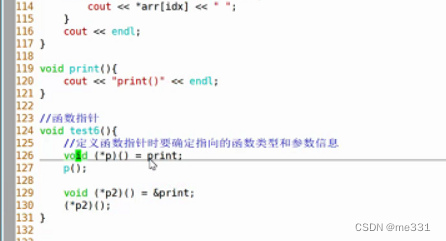
【注意】函数指针需要注意就是返回值的类型和参数的类型,需要是对应的
指针函数:返回值是一个指针
【注意】不能只能返回在局部定义(栈)的变量的指针会指向一个已经销毁的变量的地址,也就是确保返回的指针的声明周期比该函数的生命周期时间更长

new和delete
申请变量int char
int *p2 = new int(); // 在括号中是进行赋初值,有时会出现兼容性不强的int *p2 = new int同样的效果
cout << *p2 ; //如果没有进行赋初值的话就初始化为0,char类型是NULL
【对比】在c语言中int *p = (int *)malloc(sizeof(int)),需要说明申请大小,以及还需要进行类型的转换
1. new是一个表达式,没有括号。返回相应类型的指针,可以传参初始化也可以默认初始化为默认值
2.malloc对应相反。
借助于memcheck来确定内存损失多少内存,主要使用1,2,4情况
1)绝对泄漏了;(2)间接泄漏了;(3)可能泄漏了,基本不会出现;(4)没有被回收,但是不确定要不要回收;(5)被编译器自动回收了,不用管
间接泄漏的情况就是自定义的对象可能泄漏的情况
【注意】通过new获得内存空间也可以free释放内存,但是不匹配不要使用
申请数组空间
int * p = new int[3]();
for(int i = 0; i < 3; i++){
cout << p[i] << " ";
}
如果需要赋初值的话
int *p = new int[3]{1,2};
对于字符串的处理
char *p = new char[4]();需要多申请一个空间通过默认\0字符表示字符串的结束
const char *p = new char[4]{“hello”}; cout << p << endl;可以进行赋初值
输出流运算符对于char*指针有默认重载功能,当cout << p char指针的时候,会输出字符串。
cout其他类型的指针,会返回地址
堆上空间写入字符串方式
const char *p = "hello world!";
char *p2 = new char[strlen(p) + 1]();
strcpy(p2, p);
cout << p2 ;
delete [] p;回收空间的注意事项
1.申请和回收形式尽量一致,存在无法正常free的问题
malloc-----free
new--------delete
new char[5] --- delete [ ] p;
2. 安全回收指针的方式
当free的时候指针指向的内容是无效的,但也可以访问,在运行时会报错
所以说每次在使用完以后就将指针置位nullptr,更加安全,如果在访问的时候在编译时就会报错
引用(最重要)(就是对于变量进行取别名,对于两者的操作是一样的相当于作用在一个实体)
引用的底层本质就是一个指针,只是不能更改指向。
//定义方式: 类型 & ref = 变量;
int number = 2;
int & ref = number;【注意】
1.是引用符号&,此除非取地址
2.引用类型和绑定的类型相同
3.声明引用的时候必须对于引用进行初始化,否则编译报错
一个实体可以有多个引用,也可以在引用的基础上再引用
4. 引用一经绑定,无法更改绑定。引用的地址和原数据的地址是相同的
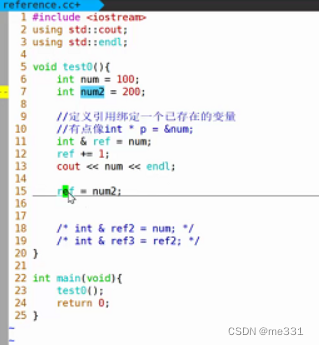
//上面的情况就是赋值而没有进行更改绑定
引用的本质
C++中的引用本质上是一种被限制的指针。
多定义一个指针,多占据存储空间。编译器拒绝访问引用,也不能访问这个指针所在的地址只会返回本题的地址,但是实际上占据了一个指针大小的地址。
引用变量会占据存储空间,存放的是一个地址,但是编译器阻止对它本身的任何访问,从一而终总是指向初始的目标单元。在汇编里,引用的本质就是“间接寻址”。
引用和指针的联系和区别
联系:都有地址的概念,引用时一个受限的指针
区别:引用必须进行初始化,引用不能修改绑定,引用表面对于引用取地址也只是可以取到变量的地址
引用的使用:引用作为函数的参数(重点)
引用传递不会发生复制,效果和指针传递效果相同,就是对于变量本身进行操作。
//例如swap函数
int swap(int & a, int & b){int temp = a;a = b;b = temp;
}问题:一个自定义的对象,如果占据空间比较大的话,就可以使用引用传递的方式。
需要改变传入参数的时候可以使用引用本身就相当于常量指针
void func(int &ref){ref = 100;
}
//如果不想在这个函数体修改ref对应的数据
void func(const int &ref){ref = 100;
}
当数据比较大的时候需要使用引用避免减少效率,同时又可以像值传递一样避免修改。
引用作为函数的返回值
int func(){//...return a; //在函数内部,当执行return语句时,会发生复制
} int & func2(){//...return b; //在函数内部,当执行return语句时,不会发生复制
} 在第一种情况下是返回一个临时值,是一个右值,是不能取地址的。
但是在第二种情况下是左值,执行return 语句时并没有发生复制,返回的是绑定到本题的引用,对于本体的任何操作都可以对于引用。
【注意事项】
1. 不要返回局部变量的引用,生命周期需要比函数更长
2. 不要轻易返回一个堆上空间的指针,容易出现内存泄漏
//下述是对于堆上的空间的处理
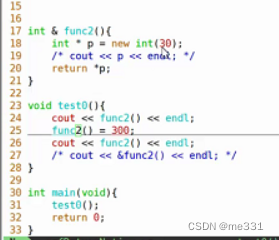
泄漏12字节,每次调用func2就会泄漏4个字节,调用几次就new了几次。

这样话,也不能释放堆上的空间,因为需要返回一个值所以不能在函数内部delete
但是后面回收的时候就访问不到那个堆上的变量了。
可以通过这样的方式来实现使用堆上的空间:直接就是引用接收函数值

引用的作用
引用的主要作用就是用于作为参数传递的,不会产生副本并且使用const更安全,底层的实现和指针类似但是比指针更简洁。
强制转换
c语言的这种强制类型转换是不安全的
#include <iostream>
using std::cout;
using std::endl;void test0(){const int num = 10;const int * p = #/* int * p1 = (int*)p; *//* *p1 = 100; *///c语言的类型转换比较强大,可以将const指针转换为非const//这个时候就可以对于数据进行改变数值//static_cast相比于C风格的类型转换//不安全的转换直接不允许//1.比较安全//2.方便查找/* int * p2 = static_cast<int*>(p); */
}void test1(){int * p = (int*)malloc(sizeof(int));*p = 1;//<>中是目标类型//()中是待转换的内容int * p2 = static_cast<int*>(malloc(sizeof(int)));*p2 = 2;
}int main(void){test0();return 0;
}c++中的这种类型转换可能更加安全一些,不需要这种情况存在,一般不会使用。
static_cast可以限制一些类型转换,可以方便查找当查找这样的关键字的时候。
实际上工作中还是使用c风格转换