File类只能对文件本身进行操作,不能读写文件里面存储的数据
IO流就是对文件进行读写的
一. File类
(一)创建对象
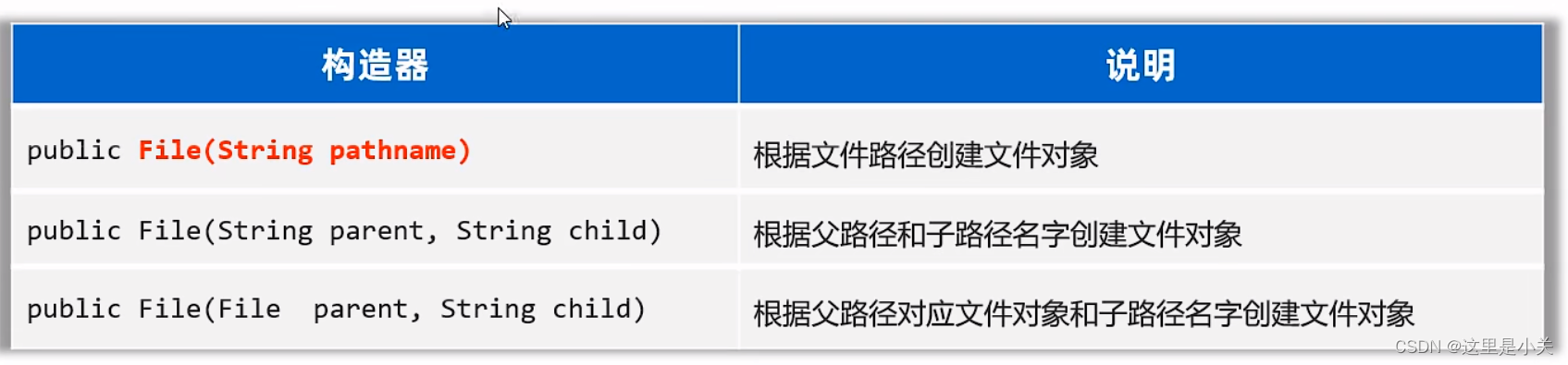
import java.io.File;public class FileTest1 {public static void main(String[] args) {// 1. 创建一个File对象,指代某个具体文件File f1 = new File("/Users/guan/Desktop/ab.txt");System.out.println(f1.length());// 2. 路径分隔符File f2 = new File(File.separator + "Users" + File.separator +"guan" + "Desktop" + "ab.txt");// 3. 指代某个文件夹File f3 = new File("/Users/guan/Desktop/");System.out.println(f3.length()); //此处的大小取的是文件夹本身的大小,不会记录文件夹中所有文件的大小// 4. File对象可以去指向一个不存在的文件File f4 = new File("/Users/guan/Desktop/aaaaaa.txt");System.out.println(f4.length()); //由于文件不存在,所以大小为0System.out.println(f4.exists()); //返回false,判断文件是否存在// 5. 我现在要定位的文件是在模块中,应该怎么定位呢File f5 = new File("guan.txt"); //相对路径}
}(二)常用方法1:判断文件类型,获取文件信息
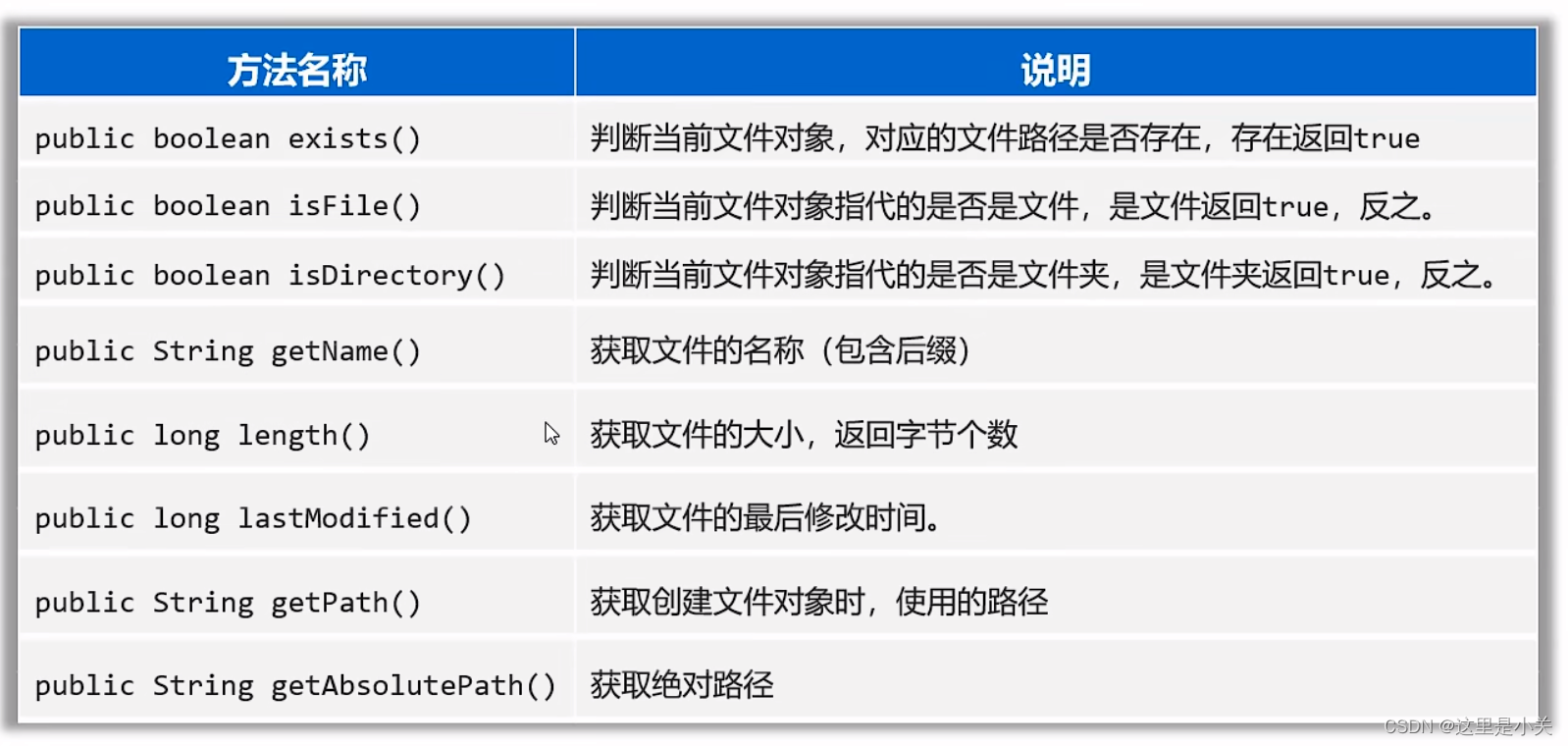
import java.io.File;
import java.text.SimpleDateFormat;public class FileTest2 {public static void main(String[] args) {// 1. 创建文件对象,指代某个文件File f1 = new File("/Users/guan/Desktop/ab.txt");// 2. 判断当前文件对象,对应的文件路径是否存在,存在返回trueSystem.out.println(f1.exists());// 3. 判断当前文件对象指代的是否是文件,是文件返回true,反之。System.out.println(f1.isFile());// 4. 判断当前文件对象指代的是否是文件夹,是文件夹返回true,反之System.out.println(f1.isDirectory());// 5. 获取文件的名称(包含后缀)System.out.println(f1.getName());// 6. 获取文件的大小,返回字节个数System.out.println(f1.length());// 7. 获取文件的最后修改时间long time = f1.lastModified();SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");System.out.println(sdf.format(time));// 8. 获取创建文件对象时使用的路径File f2 = new File("/Volumes/Guan/学习/JAVA/JAVA学习/class p152/class p152/src/d1_file/guan.txt")File f3 = new File("guan.txt");System.out.println(f2.getPath());System.out.println(f3.getPath());// 9. 获取绝对路径System.out.println(f2.getAbsolutePath());System.out.println(f3.getAbsoluteFile());}
}
(三)常用方法2:创建文件,删除文件

import java.io.File;
import java.io.IOException;public class FileTest3 {public static void main(String[] args) throws IOException {// 1. 创建一个新文件(文件内容为空),创建成功返回true,反之File f1 = new File("test_file");System.out.println(f1.createNewFile());// 2. 用于创建文件夹,注意:只能创建一级文件夹File f2 = new File("aaa/bbb/ccc");System.out.println(f2.mkdir()); //会返回false,因为mkdir()只能创建一级文件夹// 3. 用于创建文件夹,注意:可以创建多级文件夹File f3 = new File("aaa/bbb/ccc/ddd/eee");System.out.println(f3.mkdirs());// 4. 删除文件,或者空文件,注意:不能删除非空文件夹System.out.println(f1.delete());System.out.println(f3.delete());}
}(四)常用方法3:遍历文件夹

import java.io.File;public class FileTest4 {public static void main(String[] args) {// 1. public String[] list(): 获取当前目录下所有的“一级文件名称”到一个字符串数组中去返回File f1 = new File("/Users/guan/Desktop");String[] names = f1.list();for (String name : names) {System.out.println(name);}// 2. public File[] listFiles(): (重点)获取当前目录下所有的“一级文件对象”到一个文件对象数组中去返回(重点)File[] files = f1.listFiles();for (File file : files) {System.out.println(file.getAbsolutePath());}}
}
(五)案例:
改变某个文件夹下视频的序号,要求从19开始
import java.io.File;public class Test {public static void main(String[] args) {File dir = new File("/Videos");// 1. 拿到下面全部的视频,一级文件对象File[] videos = dir.listFiles();// 2. 一个一个的找for (File video : videos) {// 3. 拿到他的名字,改成新名字String name = video.getName();String index = name.substring(0,name.indexOf("."));String lastName = name.substring(name.indexOf("."));String newName = (Integer.valueOf(index)+18)+"."+lastName;// 4. 正式改名video.renameTo(new File(dir, newName));}}
}二. 案例(文件搜索):

import java.io.File;public class RecursionTest2 {public static void main(String[] args) {searchFile("D:/","QQ.exe");}/*** 去目录下搜索某个文件* @param dir 目录* @param fileName 要搜索的文件名称*/public static void searchFile(File dir,String fileName) {//1. 把非法的情况都拦截住if (dir == null || !dir.exists() || !dir.isDirectory()) {return; //代表无法搜索}//2. dir不是null,存在,一定是目录对象File [] files = dir.listFiles();//3. 判断当前目录下是否存在一级文件对象,以及是否可以拿到一级文件对象if (files != null && files.length > 0) {//4. 遍历全部一级文件对象for (File file : files) {//5. 判断文件是文件还是文件夹if (file.isFile()) {//是文件,判断这个文件名是否是我找的if (file.getName().contains(fileName)) {System.out.println("找到了:" + file.getAbsolutePath());}} else {// 是文件夹,继续重复这个过程searchFile(file,fileName); }}}}
}
三. IO流
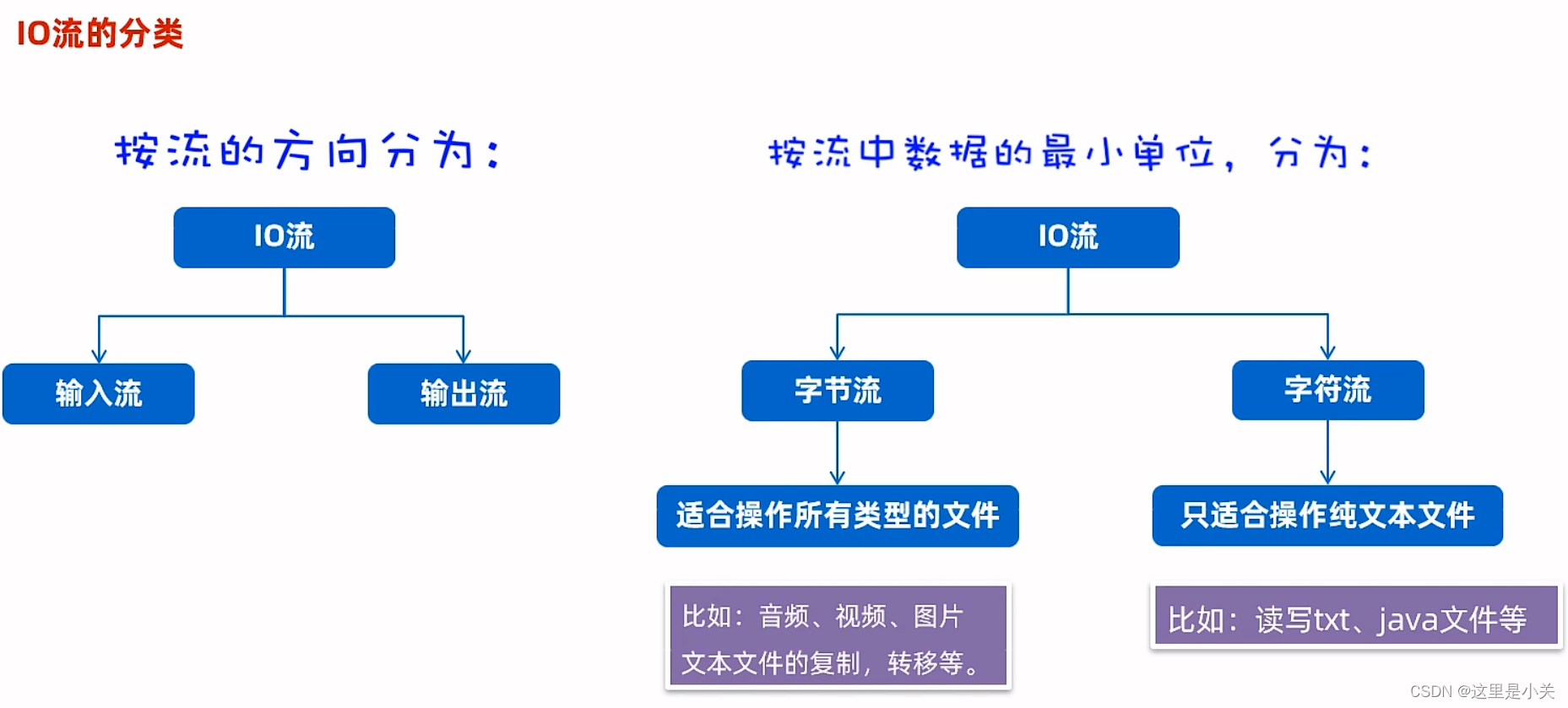
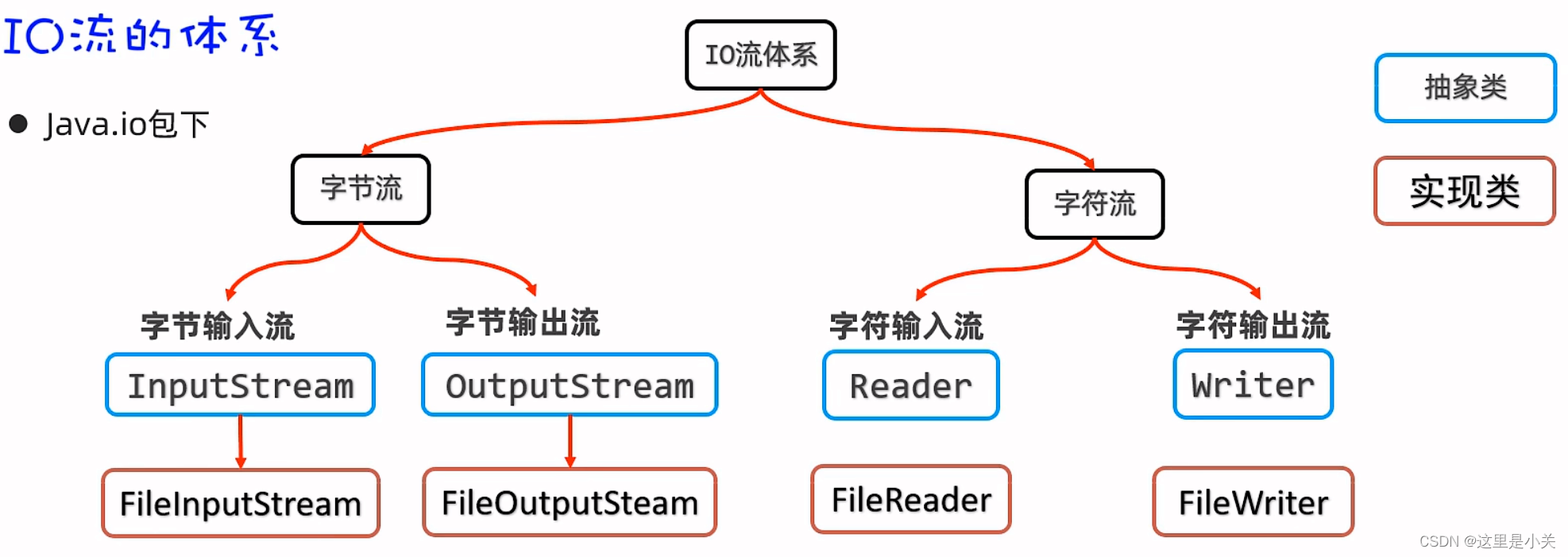
(一)字节流
1. 文件字节输入流
FIleInputStream
作用:以内存为基准,可以把磁盘文件中的数据以字节的形式读入到内存中去。

import java.io.*;public class FileInputStreamTest1 {public static void main(String[] args) throws IOException {// 1. 创建文件字节输入流管道,与源文件接通//简化写法,无需自己创建对象:InputStream is = new FileInputStream("src/text.txt");// 2. 开始读取文件的字节数据int b1 = is.read();System.out.println((char)b1);int b2 = is.read();System.out.println((char)b2);int b3 = is.read();System.out.println((char)b3);// 3. 使用循环改造上述代码int b; //用于记住读取的字符while ((b = is.read()) != -1) {System.out.println((char)b);}// 读取数据的性能很差// 读取汉字会输出乱码!无法避免的!// 流使用完毕之后,必须关闭!释放系统资源!!is.close();}
}
2. 文件字节输入流:每次读取多个字节
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;public class FileInputStreamTest2 {public static void main(String[] args) throws IOException {// 1.创建一个字节输入流对象代表字节输入流管道与源文件接通InputStream inputStream = new FileInputStream("src/text.txt");// 2. 开始读取文件中的字节数据,每次读取多个字节byte[] buffer = new byte[3];int len = inputStream.read(buffer);String rs = new String(buffer);System.out.println(rs);System.out.println("当次读取的字节数量: " + len);int len2 = inputStream.read(buffer);//注意: 第一次读了多少,就倒出多少String rs2 = new String(buffer,0,len2);System.out.println(rs2);System.out.println("当次读取的字节数量: " + len2);}
}read()方法每次读取多个字节到字节数组中去,返回读取的字节数量,读取完毕会返回-1
对上面的代码进行优化,使用循环:
//3. 使用循环改造:byte[] buffer = new byte[3];int len; //记住每次读取了多少个字节while ((len = inputStream.read(buffer)) != -1) {// 注意:读取多少,倒出多少String rs = new String(buffer, 0, len);System.out.println(rs);}3. 文件字节输入流:一次读取完全部字节
我们会发现在上面两个方法中都不能很好的读取汉字,因为汉字的字节比英文字母要更多,既不能一个字节一个字节的读取,又不能一次读取固定字节,这样都有可能出现问题。而最好的避免的方法便是一次读取完全部字节。
方式一:自己定义一个字节数组与被读取的文件大小一样大,然后使用该字节数组,一次读取完文件的全部字节。

import java.io.*;public class FileInputStreamTest03 {public static void main(String[] args) throws IOException {InputStream is = new FileInputStream("src/text.txt");// 1. 准备一个字节数组,大小与文件的大小正好一样大File f = new File("src/text.txt");long size = f.length();byte[] buffer = new byte[(int) size];int len = is.read(buffer);System.out.println(new String(buffer));System.out.println(size);System.out.println(len);}
}方式二:Java官方为InputStream提供了如下方法,可以直接把文件的全部字节读取到一个字节数组中返回

import java.io.*;public class FileInputStreamTest03 {public static void main(String[] args) throws IOException {InputStream is = new FileInputStream("src/text.txt");byte[] buffer = is.readAllBytes();System.out.println(new String(buffer));}
}为了防止文件太大超过了内存大小,那么他会抛出异常。
学了这么多,其实字节流只适合做数据的转移,如文件的复制等。读写文本内容更适合用字符流!
4. 文件字节输出流:写字节出去
作用:以内存为基准,把内存中的数据以字节的形式写出到文件中去
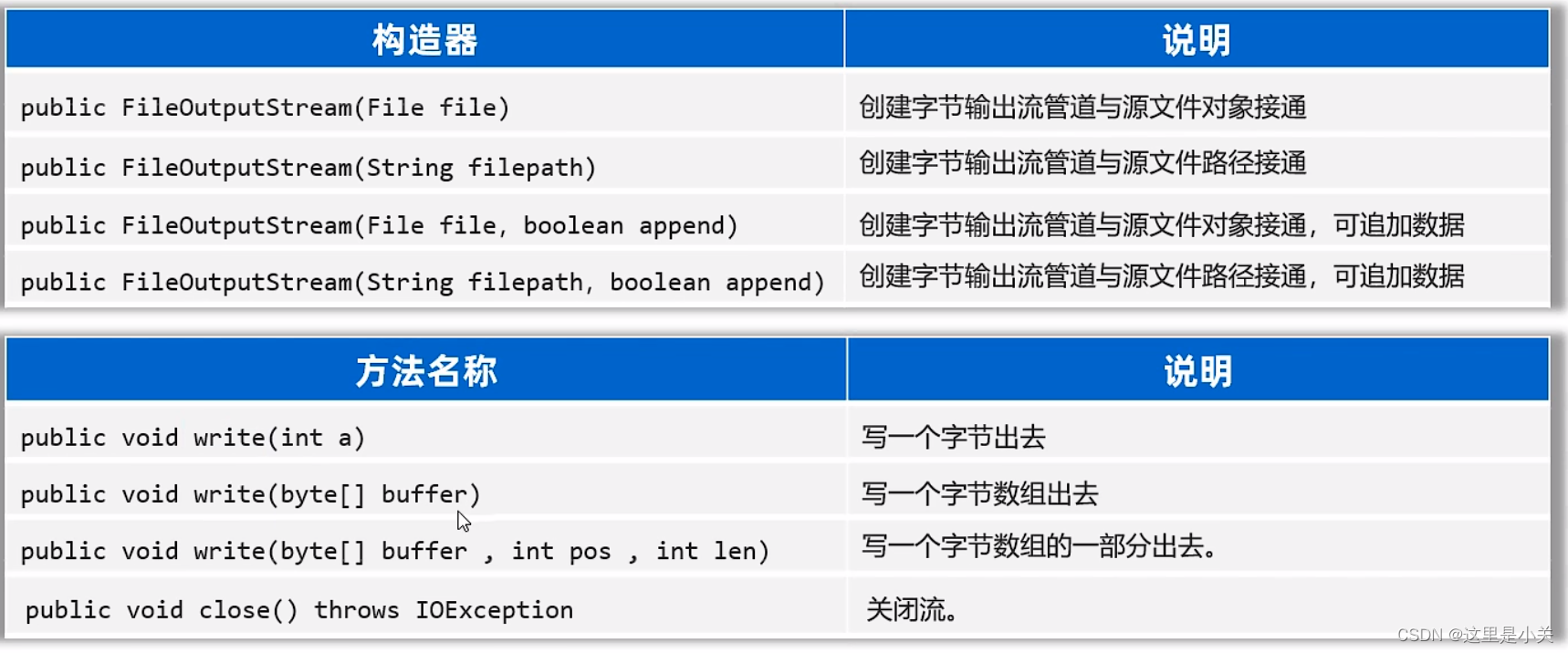
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;public class FileOutputStream01 {public static void main(String[] args) throws IOException {// 1. 创建一个字节输出流管道与目标文件接通OutputStream os = new FileOutputStream("src/text1.txt");// 2. 开始写字节数据出去了os.write(97); //97就是一个字节,代表aos.close();}
}要注意,如果直接在write方法中放一个中文是会输出乱码的,如果想要输出中文,需要这么写:
将中文内容通过getBytes()方法封装成字节数组,然后再输出这个数组即可。
还可以控制输出其中的部分内容:
os.write(bytes,0,15);例如,我们如果只要输出“我爱你中国”五个字,每个字是3个字节,5*3=15.
需要注意的是,默认的输出管道只是覆盖原文件中的内容,如果想要追加内容只需要在创建输出流的时候这么写:
OutputStream os = new FileOutputStream("src/text1.txt",true);在路径后面加上true即可。
如何换行输出?
os.write("\r\n".getBytes());5. 释放资源的方式
加入在创建流和关闭流之间出现了异常,这个时候就不会关闭流,从而造成无法释放资源。这个时候,我们可以通过以下两种方式来解决这个问题:
(1)try-catch-finally
try {......
} catch (IOException e) {e.printStackTrace();
} finally {}finally代码区的特点:无论try中的程序是正常执行了,还是出现了异常,最后都一定会执行finally区,除非JVM终止(System.exit(0);)
作用:一般用于在程序执行完成后进行资源的释放操作(专业级做法)
import java.io.*;public class FileStreamTest1 {public static void main(String[] args) throws IOException {InputStream is = null;OutputStream os = null;try {// 1. 创建一个字节输入流管道is = new FileInputStream("D:\\test1.txt");// 2. 创建一个字节输出流管道os = new FileOutputStream("D:\\test2.txt");// 3. 创建一个字节数组,负责转移字节数据byte[] buffer = new byte[1024]; //1KB// 4. 从字节输入流中读取字节数据,写出去到字节输入流中,读出去多少写出去多少int len; //记住每次读取了多少字节while ((len = is.read(buffer)) != -1) {os.write(buffer, 0, len);}} catch (IOException e) {e.printStackTrace();} finally {// 释放资源的操作try {if(is != null) is.close();} catch (IOException e) {e.printStackTrace();}try {if(os != null) os.close();} catch (IOException e) {e.printStackTrace();}}}
}
为什么我们在finally处还要给close做try catch呢?因为异常有可能出现在创建IO流之前,这个时候如果出现了异常那么is和os的值仍然是null,这肯定就无法执行close了,所以需要在这里判断一下IO流是否为null
(2)try-with-resource
虽然我们前面那个方法很正确,但是代码很臃肿,不优雅。因此从JDK7开始提供了一种更简单的方案。
try (定义资源1;定义资源2;...) {可能出现异常的代码;
} catch (异常类名, 变量名) {异常处理的代码
}改资源使用完毕后,会自动调用其close()方法,完成对资源的释放!
import java.io.*;public class FileStreamTest1 {public static void main(String[] args) throws IOException {try (InputStream is = new FileInputStream("D:\\test1.txt");OutputStream os = new FileOutputStream("D:\\test2.txt");){// 3. 创建一个字节数组,负责转移字节数据byte[] buffer = new byte[1024]; //1KB// 4. 从字节输入流中读取字节数据,写出去到字节输入流中,读出去多少写出去多少int len; //记住每次读取了多少字节while ((len = is.read(buffer)) != -1) {os.write(buffer, 0, len);}} catch (IOException e) {e.printStackTrace();} }
}注意,try后面的括号中只能放置资源对象。(此处只能放流对象)
什么是资源呢?资源都是会实现AutoCloseable接口
(二)字符流
1. 文件字符输入流-读字符数据进来
前面我们学习的字节流更适合做文件复制,不适合读写文本文件,而字符流则改善了这一缺点。
FileReader(文件字符输入流):以内存为基准,可以把文件中的数据以字符的形式读入到内存中去。

import java.io.FileReader;
import java.io.Reader;public class FileReaderTest1 {public static void main(String[] args) {try (// 1.创建一个文件字符输入流管道与源文件想通Reader fr = new FileReader("src/text.txt");){// 2. 读取文本文件内容int c; //用于记住每次读取的字符编号while ((c = fr.read()) != -1) {System.out.print((char) c); //不要换行,不然输出一个文字就换一行。}} catch (Exception e) {e.printStackTrace();}}
}像上面这样写,每次读取一个字符的效率肯定是很差的,那么我们同样也可以做一个buffer,每次读取多个字符。
import java.io.FileReader;
import java.io.Reader;public class FileReaderTest1 {public static void main(String[] args) {try (// 1.创建一个文件字符输入流管道与源文件想通Reader fr = new FileReader("src/text.txt");){// 2. 读取文本文件内容// 3. 每次读取多个字符char[] buffer = new char[3];int len; //记住每次读取了多少字符while ((len = fr.read(buffer)) != -1) {System.out.print(new String(buffer, 0, len));}} catch (Exception e) {e.printStackTrace();}}
}2. 文件字符输出流-写字符数据出去
FileWriter(文件字符输出流)
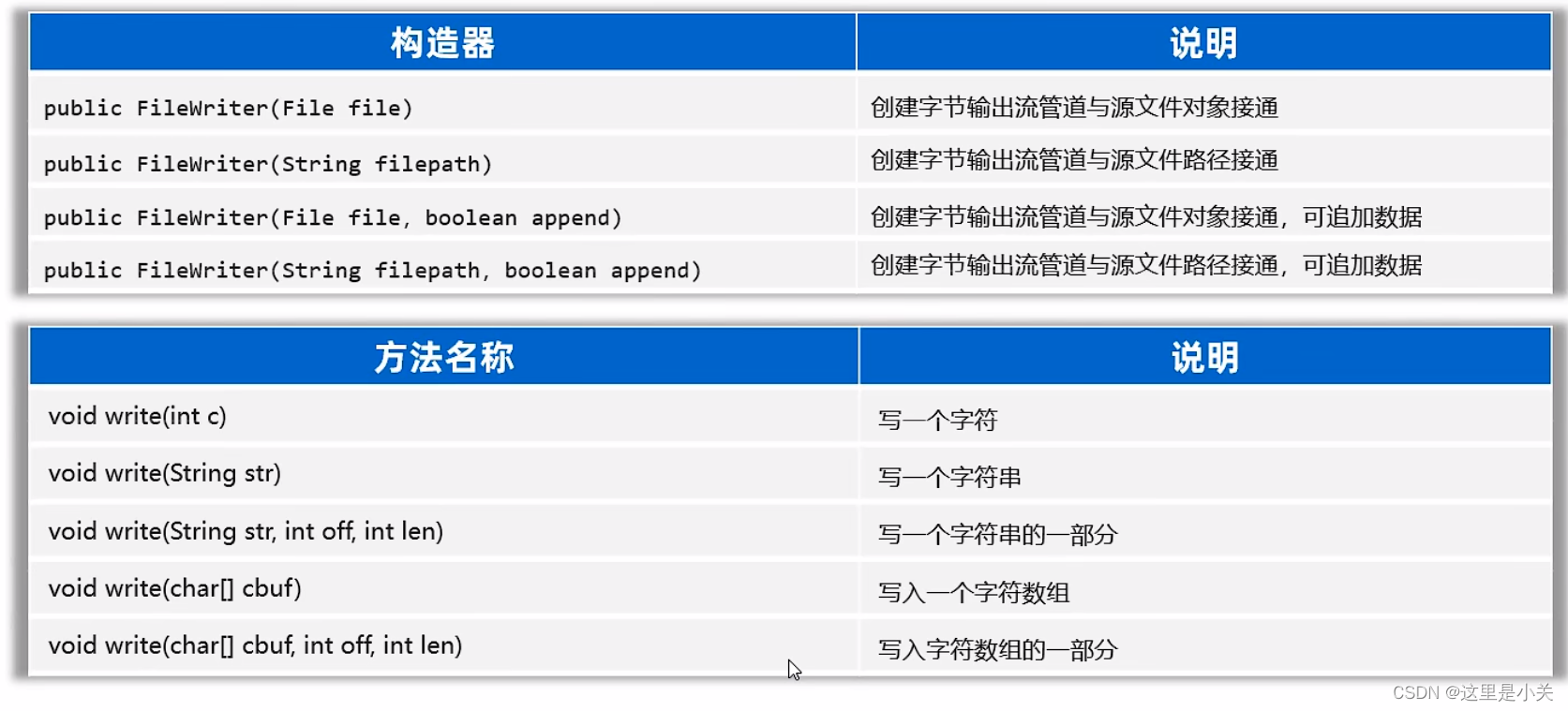
import java.io.FileWriter;
import java.io.Writer;public class FileWriterTest2 {public static void main(String[] args) {try (// 1. 创建一个文件字符输出流管道与目标文件接通Writer fw = new FileWriter("src/test.txt");){// 2. public void write(int c); 写一个字符出去fw.write("a");fw.write(97);fw.write('中'); //写一个字符出去fw.write("\r\n");// 3. public void write(String c); 写一个字符串出去fw.write("我爱你中国");fw.write("\r\n");// 4. public void write(String c, int pos, int len); 写字符串的一部分出去fw.write("我爱你中国abc", 0, 5);fw.write("\r\n");// 5. public void write(char[] buffer); 写一个字符数组出去char[] buffer = {'我', '爱', '你', '中', '国'};fw.write(buffer);fw.write("\r\n");// 6. public void write(char[] buffer, int pos, int len); 写字符数组的一部分出去fw.write(buffer,0,3);} catch (Exception e) {e.printStackTrace();}}
}
默认的管道是覆盖管道,如果要改为追加管道就在创建的后面写一个true
Writer fw = new FileWriter("src/test.txt", true);字符输出流使用时的注意事项:
字符输出流写出数据后,必须刷新流,或者关闭流,写出去的数据才能生效
因为字符输出流是会创建一个缓冲区,先把数据都存缓冲区里面去,再存入文件中去。
fw.close();直接关闭流,不需要使用flush()来刷新流,因为close包含flush操作的。要注意,一旦关闭,这个流就用不了了,所以如果还要再次使用这个流,就要用flush来刷新缓冲区。
(三)缓冲流
对原始流进行包装,以提高原始流的读写性能
1.字节缓冲流
(1)字节缓冲输入流
BufferdInputStream
(2)字节缓冲输出流
BufferdOutputStream
(3)应用
import java.io.*;public class BufferedInputStreamTest1 {public static void main(String[] args) throws IOException {try (InputStream is = new FileInputStream("D:\\test1.txt");// 1. 定义一个字节缓冲输入流包装原始的字节输入流InputStream bis = new BufferedInputStream(is);OutputStream os = new FileOutputStream("D:\\test2.txt");// 2. 定义一个字节缓冲输出流包装原始的字节输入流OutputStream bos = new BufferedOutputStream(os);){// 3. 创建一个字节数组,负责转移字节数据byte[] buffer = new byte[1024]; //1KB// 4. 从字节输入流中读取字节数据,写出去到字节输入流中,读出去多少写出去多少int len; //记住每次读取了多少字节while ((len = bis.read(buffer)) != -1) {os.write(buffer, 0, len);}System.out.println("复制完成!!");} catch (IOException e) {e.printStackTrace();}}
}默认的缓冲大小为8K(8192),如果我们想扩大这个空间的话可以再创建流对象的时候这么写:
InputStream bis = new BufferedInputStream(is, 8192*2);这样就扩大到原来的两倍了
2.字符缓冲流
(1)字符缓冲输入流
BufferedReader
自带8k(8192)的字符缓冲池,可以提高字符输入流读取字符数据的性能
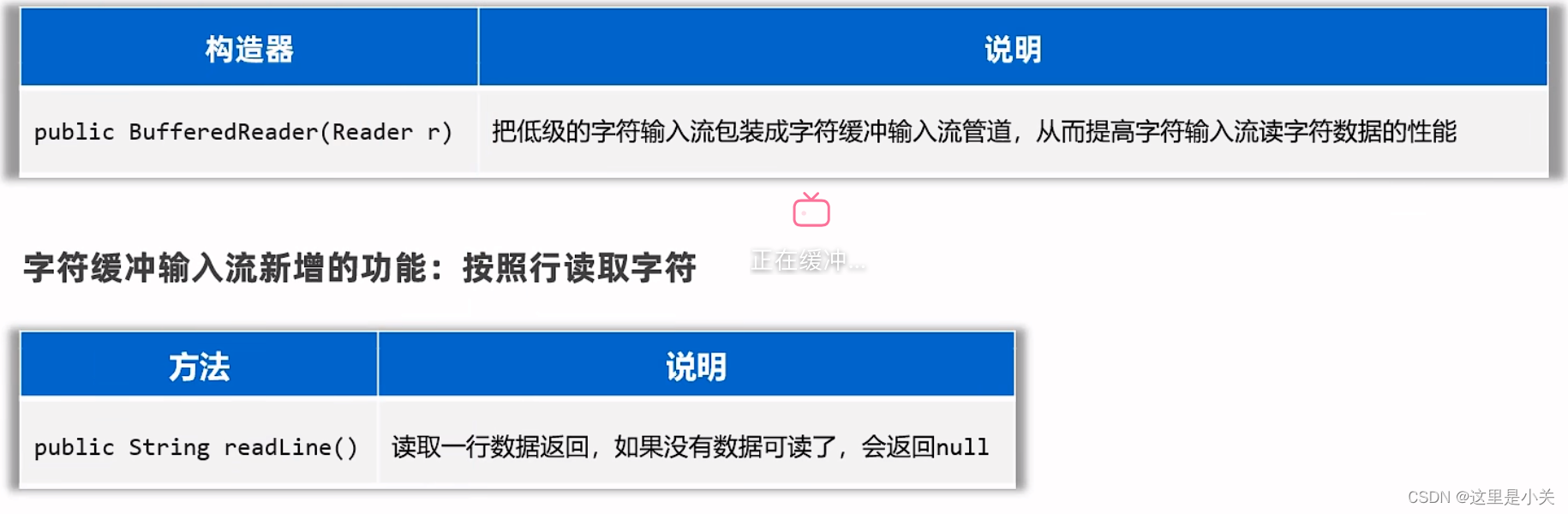
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.Reader;public class BufferedReaderTest1 {public static void main(String[] args) {try (Reader fr = new FileReader("src/text.txt");// 创建一个字符缓冲输入流包装原始的字符输入流BufferedReader br = new BufferedReader(fr); //不要用多态写){char[] buffer = new char[3];int len; //记住每次读取了多少字符while ((len = br.read(buffer)) != -1) {System.out.print(new String(buffer, 0, len));}} catch (Exception e) {e.printStackTrace();}}
}按行读取数据:
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.Reader;public class BufferedReaderTest1 {public static void main(String[] args) {try (Reader fr = new FileReader("src/text.txt");// 创建一个字符缓冲输入流包装原始的字符输入流BufferedReader br = new BufferedReader(fr); //不要用多态写){String line; //记住每次读取的一行的数据while ((line = br.readLine()) != null) {System.out.println(line);}} catch (Exception e) {e.printStackTrace();}}
}(2)字符缓冲输出流
BufferedWriter
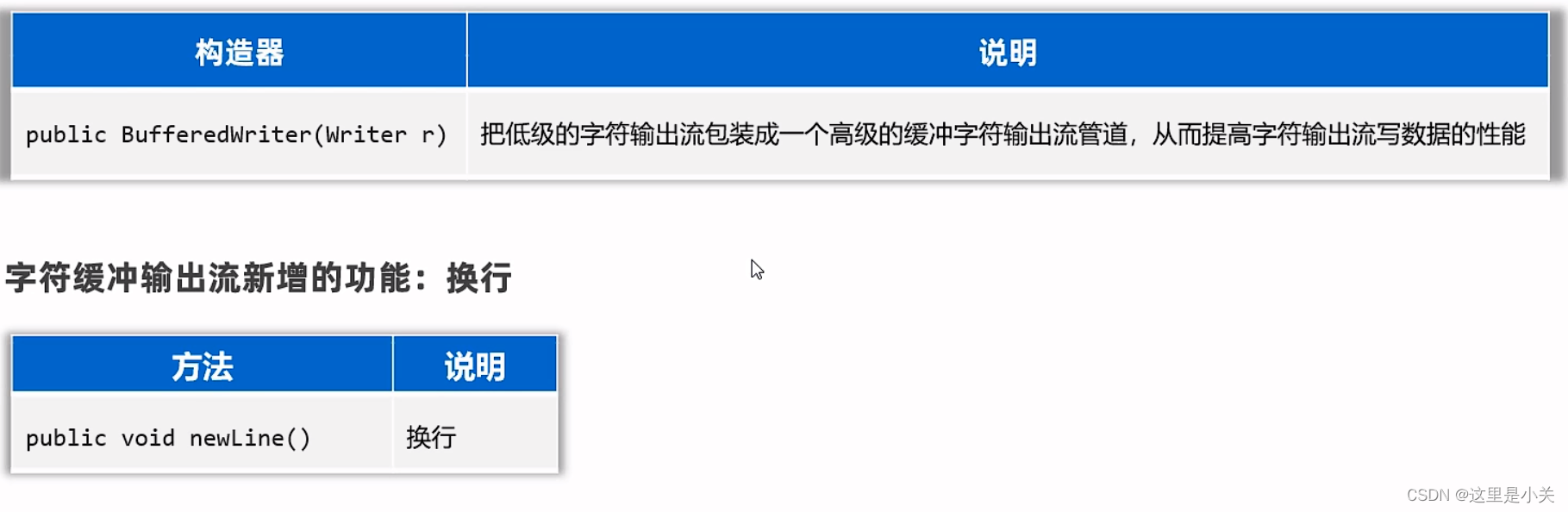
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.Writer;public class BufferedWriterTest2 {public static void main(String[] args) {try (Writer fw = new FileWriter("src/test/txt",true);//创建一个字符缓冲输出流管道包装原始的字符输出流BufferedWriter bw = new BufferedWriter(fw);) {bw.write('a');bw.write(97);bw.write('关');bw.newLine();bw.write("我爱你中国abc");bw.newLine();} catch (Exception e) {e.printStackTrace();}}
}3. 原始流,缓冲流的性能分析【重点】
- 使用低级的字节流按照一个一个字节的形式复制文件
- 使用低级的字节流按照字节数组的形式复制文件
- 使用高级的缓冲字节流按照一个一个字节的形式复制文件
- 使用高级的缓冲字节流按照字节数组的形式复制文件
4. 不同编码读取出现乱码的问题
如果代码编码和被读取的文本文件的编码是一致的,使用字符流读取文本文件时不会出现乱码!
如果代码编码和被读取的文本文件的编码是不一致的,使用字符流读取文本文件时就会出现乱码