✨✨ 欢迎大家来到贝蒂大讲堂✨✨
🎈🎈养成好习惯,先赞后看哦~🎈🎈
所属专栏:数据结构与算法
贝蒂的主页:Betty’s blog

1. 快速排序
1.1. 算法思想
**快速排序(Quick Sort)**是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
1.2. 算法实现
快速排序的实现方式有很多,下面我们主要介绍三种方法。
1.2.1. Hoare法
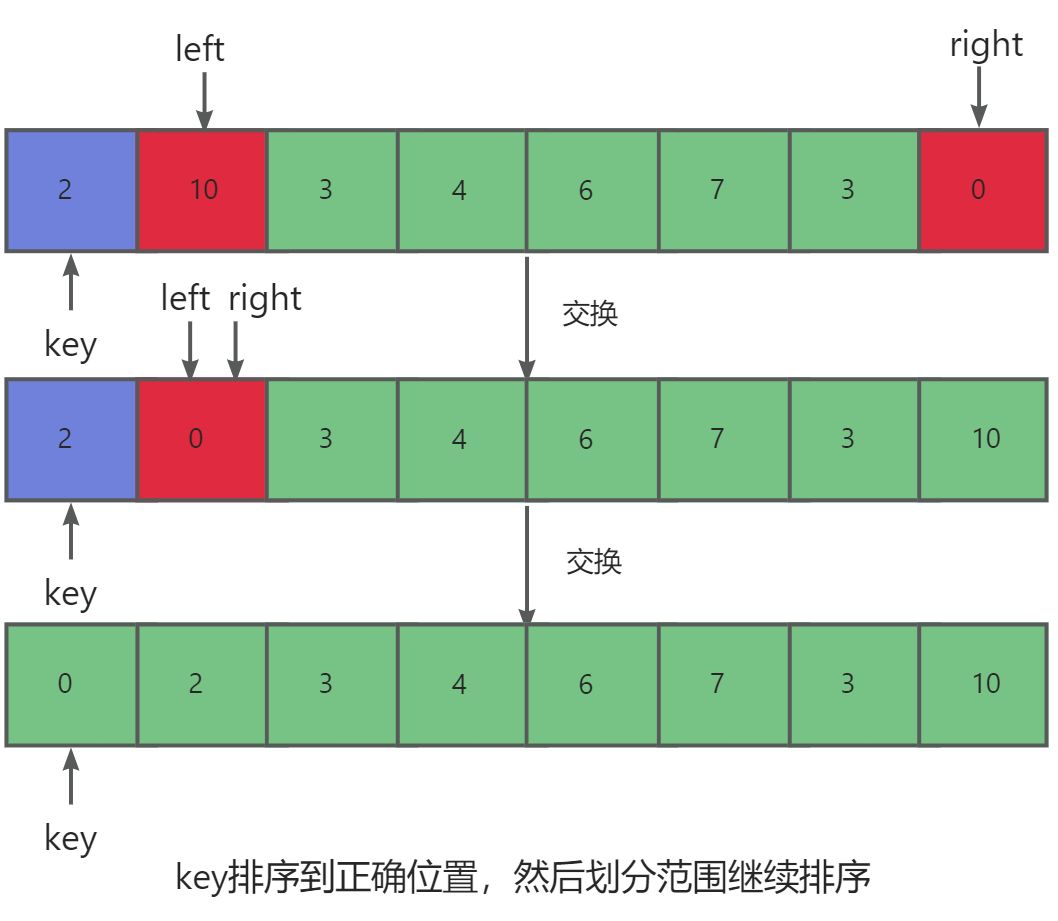
- 利用两个变量
left,right分别指向数组的起始位置与末尾位置。并且以数组第一个元素作为key值。right先从右往左依次遍历找到比key小的数,left从左往右依次遍历找到比key大的数。然后交换left与right下标对应的值。重复步骤2直至right>=left。- 之后交换
key与left或者right对应的值,并且把该位置记为mid。- 最后划分区间
[left,mid-1]与[mid+1,right]继续重复1,2步骤。直至不能划分。

思考:为什么最后相遇位置一定小于或等于**key**值?
我们知道right与left相遇无非两种情况:
- 情况一:
right停住,left移动与right相遇·。因为right一直再找比key小的值,所以right停下位置一定比key小,相遇位置也一定比key小。- 情况二:
left停住,right移动与left相遇·。此时又分为两种情况:
left从未移动,右侧数据都比可以大,相遇位置就是key,交换不变。left移动过至少一次,也就是至少交换过一次,此时left停留位置的值是上一轮right所对应的值,又因为right一直再找比key小的值,所以相遇位置也一定比key小。
代码实现:
void swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}
int PartSort1(int* arr, int begin, int end)
{int left = begin, right = end;int keyi = begin;while (left < right){//left<right防止越界//使用>=而不是>防止数据出现死循环while (left<right && arr[right]>=arr[keyi])//寻找比key小的值{right--;}while (left < right && arr[left] <= arr[keyi])//寻找比key大的值{left++;}swap(&arr[left], &arr[right]);}int mid = left;swap(&arr[keyi], &arr[mid]);return mid;
}
void QuickSort(int* arr, int left, int right)
{if (left >= right)//不能划分{return;}int mid = PartSort1(arr, left, right);//单趟排序QuickSort(arr, left, mid - 1);//左区间QuickSort(arr, mid+1, right);//右区间
}
1.2.2. 挖坑法
- 先将起始位置
key值 设为坑,之后right从右往左找比key值小的值,找到之后放入坑位,此时right就形成新的坑。然后left从左往右找比key大的值, 找到之后放入坑位,此时left就又形成新的坑。- 最后
left与right相遇,将key放入最后一个坑,并将该位置记为mid,。·- 最后划分区间
[left,mid-1]与[mid+1,right]继续重复1,2步骤。直至不能划分。


代码实现:
int PartSort2(int* arr, int begin, int end)
{int left = begin, right = end;int hole = begin;//记录坑位int key = arr[left];while (left < right){//left<right防止越界//使用>=而不是>防止数据出现死循环while (left < right && arr[right] >= key)//寻找比key小的值{right--;}arr[hole] = arr[right];hole = right;while (left < right && arr[left] <= key)//寻找比key大的值{left++;}arr[hole] = arr[left];hole = left;}arr[hole] = key;return hole;
}
void QuickSort(int* arr, int left, int right)
{if (left >= right)//不能划分{return;}int mid = PartSort2(arr, left, right);//单趟排序QuickSort(arr, left, mid - 1);//左区间QuickSort(arr, mid+1, right);//右区间
}
1.2.3. 前后指针法
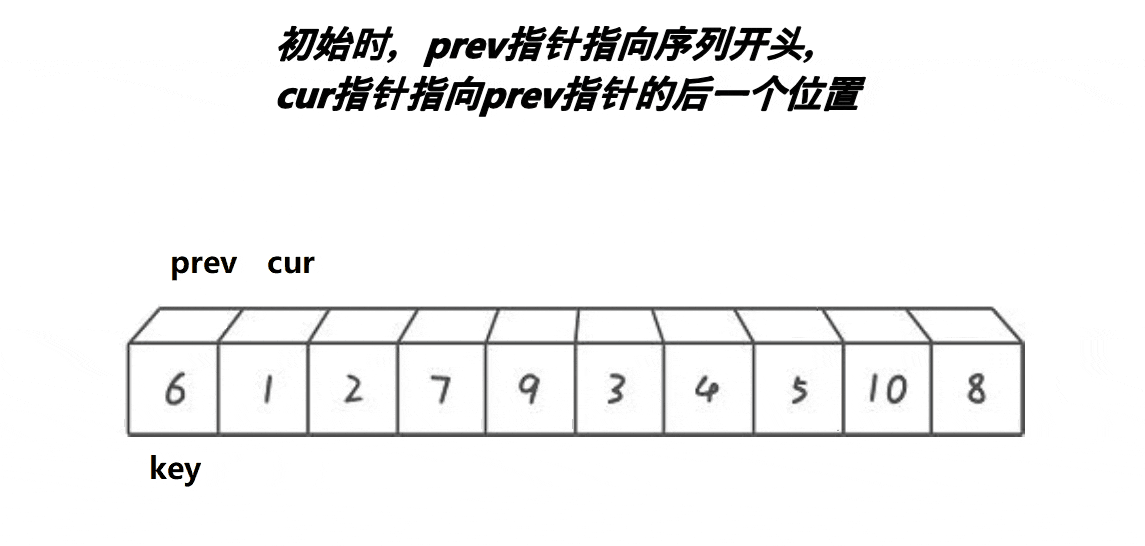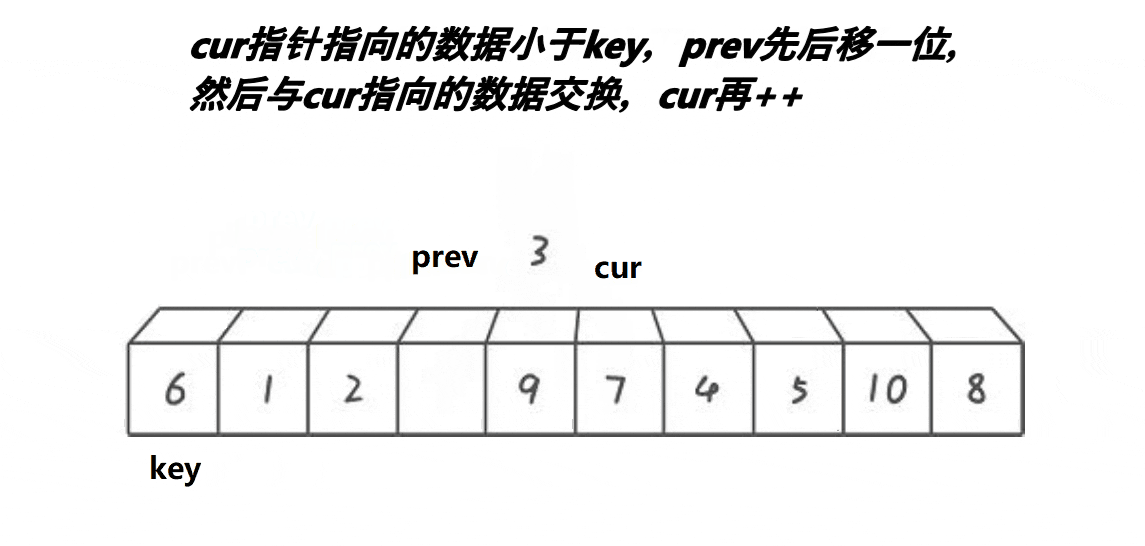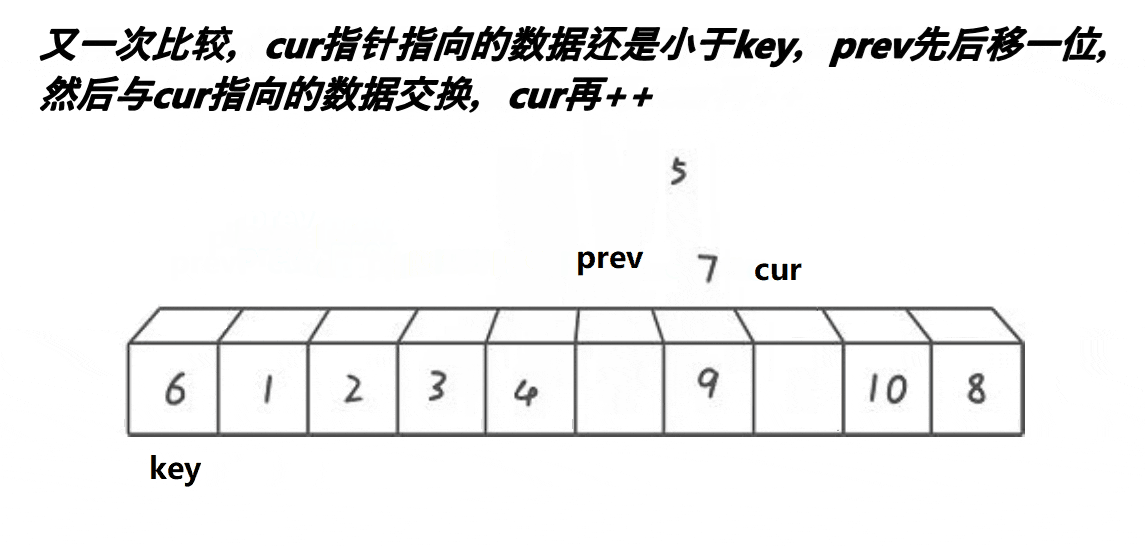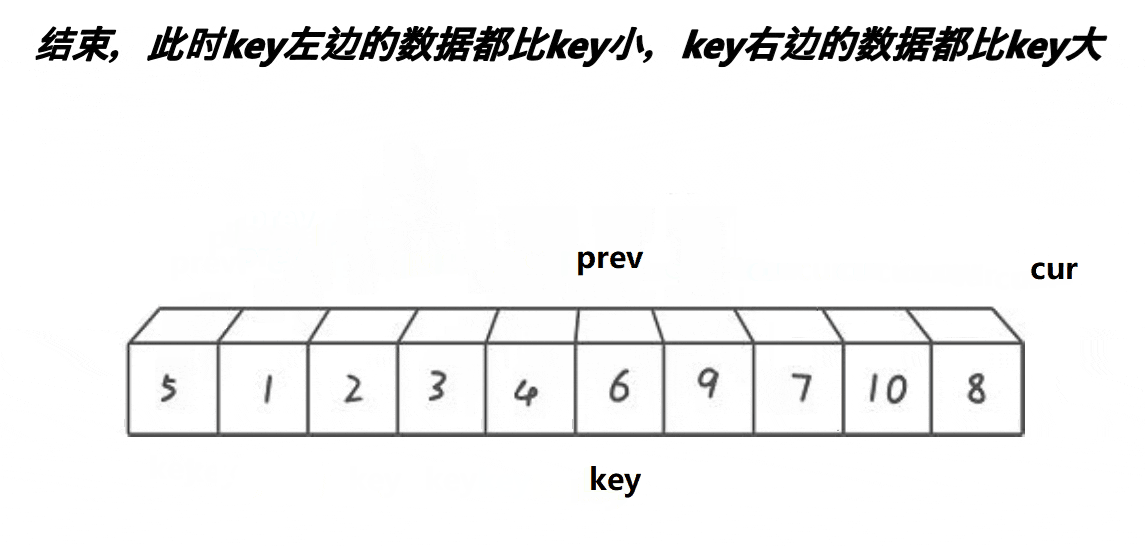
- 先定义一个
prev指向数组首元素,然后定义一个cur指向第二个位置。cur从左往右依次遍历找key小的值,找到之后++prev,然后交换prev与cur指向的值。之后cur++继续遍历。(key为起始位置的值)- 当cur遍历完之后,此时交换
prev指向的值与key。将此时位置记为mid。- 最后划分区间
[left,mid-1]与[mid+1,right]继续重复1,2,3步骤。直至不能划分。

代码实现:
int PartSort3(int* arr, int begin, int end)
{int prev = begin;int cur = begin + 1;int keyi = begin;while (cur <= end){if (arr[cur] < arr[keyi])//小于则交换{swap(&arr[++prev], &arr[cur]);}cur++; }swap(&arr[prev], &arr[keyi]);return prev;
}
void QuickSort(int* arr, int left, int right)
{if (left >= right)//不能划分{return;}int mid = PartSort3(arr, left, right);//单趟排序QuickSort(arr, left, mid - 1);//左区间QuickSort(arr, mid+1, right);//右区间
}
1.3. 复杂度分析
- 时间复杂度:通常情况下,需要递归logN层,每层都需要遍历,所以时间复杂度为O(NlogN)。
- 空间复杂度:通常情况下,需要递归logN层,所以空间复杂度为O(logN)。
1.4. 算法优化
1.4.1. 改变基准元素
当数组有序时,我们再对其进行快速排序,其时间复杂度讲话劣化为O(N2)。

这时候我们为了防止这种现象,可以选择提前改变基准元素key。
- 三数取中:即取出数组首尾以及中间元素,选取数值位于中间的元素作为准元素
key。
int GetMidNum(int*arr, int left, int right)
{int mid = (left + right) >> 1;if (arr[mid] > arr[left]){if (arr[mid] < arr[right]){ //left mid rightreturn mid;}else if (arr[left] > arr[right]){ //right left midreturn left;}else{ //left right midreturn right;}}
}
int PartSort3(int* arr, int begin, int end)
{int prev = begin;int cur = begin + 1;int keyi = begin;int mid=GetMidNum(arr, begin, end);swap(&arr[begin], &arr[mid]);while (cur <= end){if (arr[cur] < arr[keyi])//小于则交换{swap(&arr[++prev], &arr[cur]);}cur++; }swap(&arr[prev], &arr[keyi]);return prev;
}
- 随机数取中:三数取中有时候也并不能保证基准元素的准确性,这时候我们最好使用随机数获取基准值。
int GetRanNum(int*arr, int left, int right)
{srand(time(0));//生成随机种子int mid = rand() % (right - left) + left;//随机数return mid;
}
1.4.2. 聚集元素
除了数组有序的情况外,还有一种情况也会导致快速排序的时间复杂度劣化为O(N2 ),那就是当数组元素全部相同时。
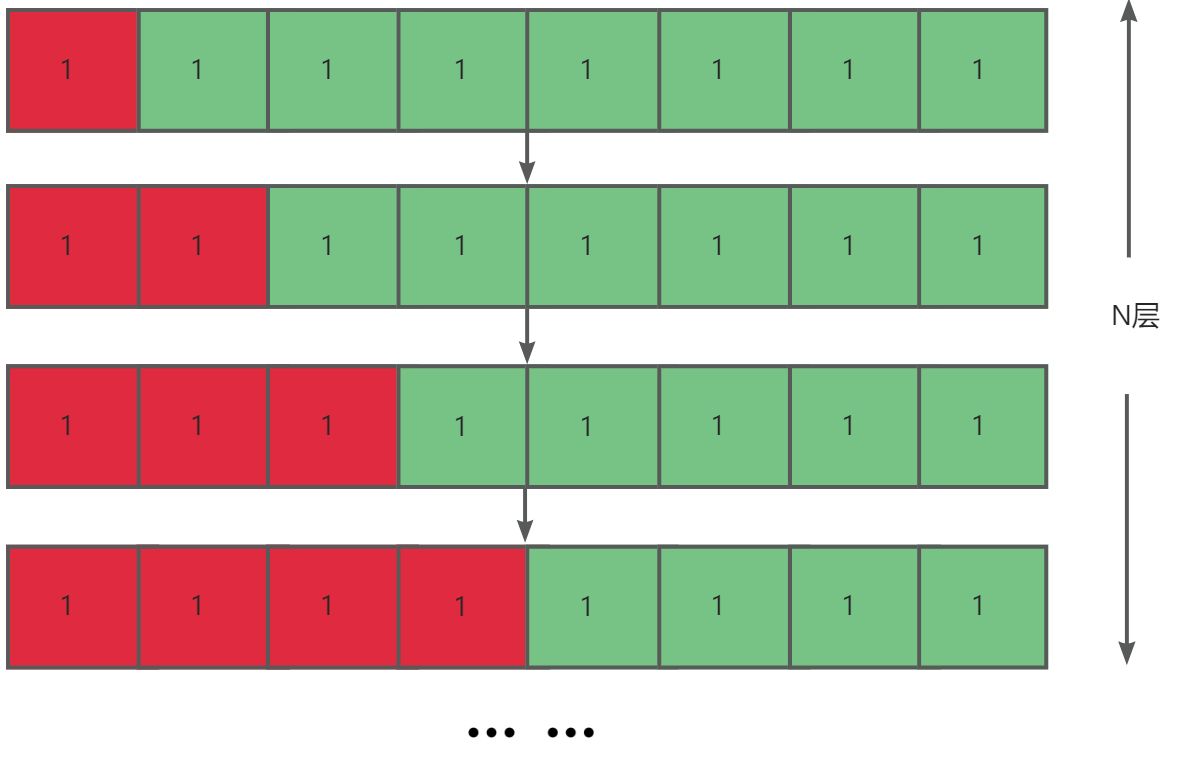
为了解决这个问题,我们采用一种三指针分化区间的方式。其步骤如下:
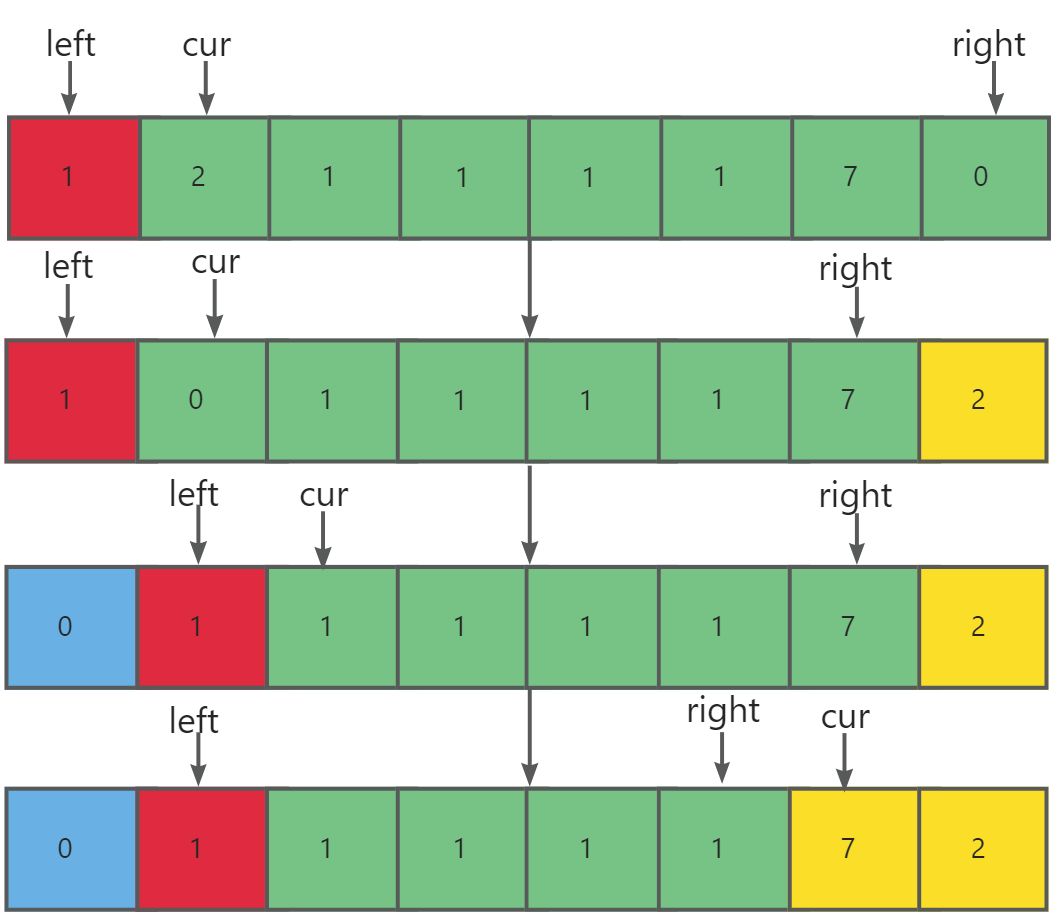
- 分别定义三个指针
left,cur,right分别指向数组首元素,第二个元素,最后一个元素。- 从左往右用
cur依次遍历数组:(key为数组第一个元素)
- 如果
arr[cur]<key,交换arr[cur]与arr[left],再让cur++``left++。- 如果
arr[cur]>key,交换arr[cur]与arr[right],再让right--。- 如果
arr[cur]==key,直接让cur++。
- 重复步骤2直至
cur>right,成功划分区间。小于key:[begin,left-1],等于key:[left, right]大于key:[right + 1, end]。
问题:为什么当arr[cur]>key,交换arr[cur]与arr[right]时不让cur++?
因为交换过来的值可能比key大,也可能比key小。如果直接cur++,并不能对这个元素进行正确的划分。
void ThreeDivision(int*arr, int*left, int*right)
{int cur = *left + 1;int key = arr[*left];while (cur <= *right){if (arr[cur] < key)//大于key{swap(&arr[(*left)++], &arr[cur++]);}else if (arr[cur] > key)//小于key{swap(&arr[cur], &arr[(*right)--]);}else//等于key{cur++;}}
}
void QuickSort(int* arr, int begin, int end)
{if (begin >= end)//不能划分{return;}if ((end - begin + 1) < 10)//小区间优化{InsertSort(arr, end - begin + 1);return;}int mid = GetRanNum(arr, begin, end);swap(&arr[begin], &arr[mid]);int left = begin;int right = end;ThreeDivision(arr, &left, &right);//三指针划分区间//[begin, left - 1][left, right][right + 1, end]QuickSort(arr, begin, left - 1);//左区间QuickSort(arr, left+1, end);//右区间
}
1.4.3. 区间优化
在我们进行递归调用时,递归越深递归调用的次数就会越多,为了优化这个问题,我们可以当区间较小时采用其他排序。
其中我们将递归调用抽象成树的形式:
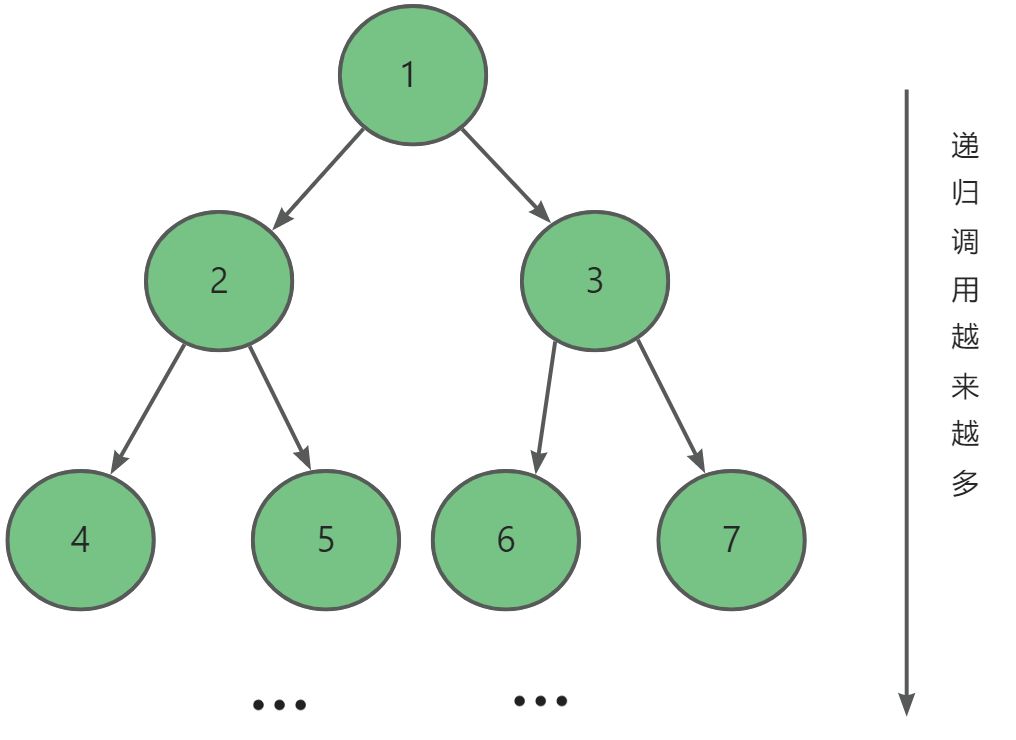
其中根据我们在树那节学习的知识,我们知道第i层的节点数为2i-1 个,节点总数为2h -1个,**最后三次调用次数就约占据总次数的87.5%。**所以我们可以在倒数三层之后采用其他排序,如插入排序。
void QuickSort(int* arr, int left, int right)
{if (left >= right)//不能划分{return;}if ((right - left + 1) < 10)//小区间优化{InsertSort(arr+left, right - left + 1);return ;}int mid = PartSort3(arr, left, right);//单趟排序QuickSort(arr, left, mid - 1);//左区间QuickSort(arr, mid+1, right);//右区间
}
1.4.4. 尾递归优化
我们知道快速排序的空间复杂度最坏情况下会劣化为O(N),为了防止栈帧空间的积累,我们可以采用尾递归形式进行递归,并且仅对较短的子数组进行递归。由于较短子数组的长度不会超过n/2,因此这种方法能确保递归深度不超过logN ,从而将最差空间复杂度优化至O(logN) 。
void QuickSort(int* arr, int begin, int end)
{while (begin < end){int mid = PartSort3(arr, begin, end);if (mid - begin<end - mid)//左区间{QuickSort(arr, begin, mid-1);begin = mid + 1;//更新区间}else{QuickSort(arr, mid + 1, end);//右区间end = mid - 1;//更新区间}}
}
1.5. 非递归实现
我们知道当递归太深时会存在栈溢出的风险,为了避免这种风险我们除了采用尾递归优化空间外,我们还可以采用非递归的形式实现。
非递归实现的方法需要借助栈这个数据结构,利用其后进先出的形式模拟实现递归,具体步骤如下:
- 首先将左右端点
begin,end入栈。- 如果栈不为空,则先出栈右端点
right,在出栈左端点left,然后将[left,right]进行单趟排序得到基准点keyi。- 然后判断
[left,keyi-1],[keyi+1,right]区间是否合法,合法就继续入栈。- 最后重复步骤2,3,直至栈为空。
void QuickSortNonR(int* a, int begin, int end)
{Stack st;InitStack(&st);PushStack(&st, begin);PushStack(&st, end);//入栈while (!StackEmpty(&st)){//先出为右端点int right = StackTop(&st);PopStack(&st);//后出为左端点int left = StackTop(&st);PopStack(&st);//单趟排序int keyi = PartSort3(a, left, right);//先入右if (keyi + 1 < right)//判断区间是否存在{PushStack(&st, keyi + 1);PushStack(&st, right);}//后入左if (left< keyi-1){ PushStack(&st, left);PushStack(&st, keyi - 1);}}DestroyStack(&st);
}
2. 归并排序
2.1. 算法思想
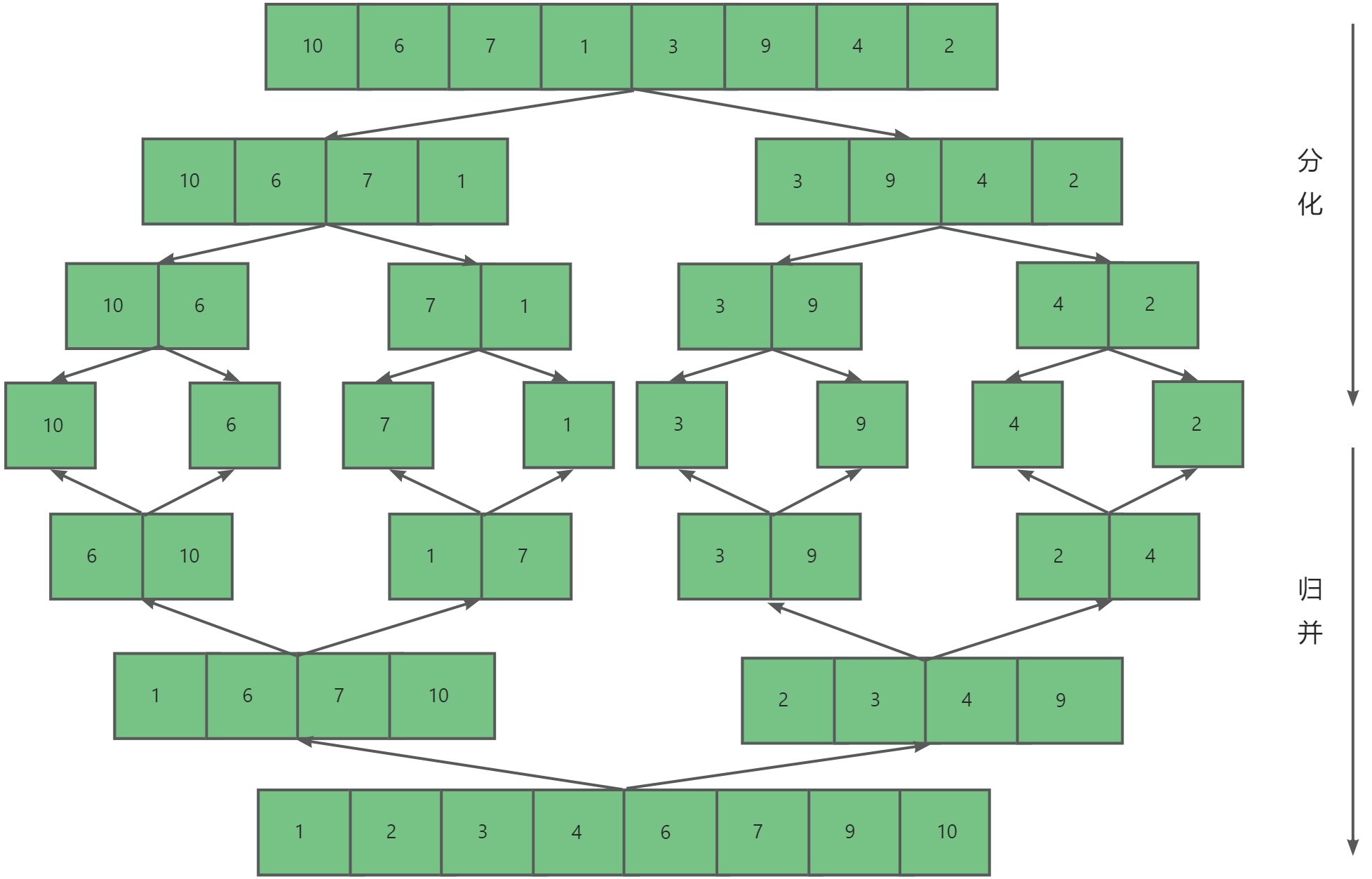
**归并排序(Merge Sort)**是建立在归并操作上的一种有效的排序算法, 该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
2.2. 算法步骤
- 创建一个与待排序数组同等大小的
tmp数组。- 然后将待排序数组分为两个子数组,让两个子数组有序。为了让这两个子数组有序,我们又要将每个子数组分为两个子数组,让其有序。
- 当子数组没有元素或者只有一个元素时,我们可以认为其有序,然后将两个子数组开始归并。
- 归并时因为两个子数组有序,我们可以定义两个指针
begin1,begin2分别指向两个数组起始位置。然后遍历比较arr[begin1]与arr[begin2],取较小的元素尾插进tmp数组。- 最后
tmp数组数据拷贝回原数组。
2.3. 动图演示
2.4. 代码实现
void _MergeSort(int* arr, int begin, int end, int* tmp)
{if (begin >= end){return;}int mid = (begin + end) >> 1;//以中间为分割点_MergeSort(arr, begin, mid, tmp);//归并左区间_MergeSort(arr, mid+1, end, tmp);//归并右区间int i = begin; int begin1 = begin, end1 = mid;int begin2 = mid + 1, end2 = end;while (begin1 <= end1 && begin2 <= end2){if (arr[begin1] < arr[begin2]){tmp[i++] = arr[begin1++];}else{tmp[i++] = arr[begin2++];}}//若是还有区间存在数据while (begin1 <= end1){tmp[i++] = arr[begin1++];}while (begin2 <= end2){tmp[i++] = arr[begin2++];}//最后将归并完后后的数据拷贝回原数组memcpy(arr + begin, tmp + begin, sizeof(int) * (end - begin + 1));
}
void MergeSort(int* arr, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail:");return;}_MergeSort(arr, 0, n - 1, tmp);free(tmp);tmp = NULL;
}
2.5. 复杂度分析
- 时间复杂度:通常情况下,需要递归logN层,每层都需要遍历,所以时间复杂度为O(NlogN)。
- 空间复杂度:通常情况下,需要创建tmp临时数组,所以空间复杂度为O(N)。
2.6. 算法优化
2.6.1. 区间优化
与快速排序类似,当递归调用层数越多时,最后三层的递归调用会浪费大量时间。为了避免这种情况,这时我们就可以采用小区间使用插入排序的方法。
void _MergeSort(int* arr, int begin, int end, int* tmp)
{if (begin >= end){return;}if (end-begin+1<10)//小区间优化{InsertSort(arr+begin, end-begin+1);return;}int mid = (begin + end) >> 1;//以中间为分割点_MergeSort(arr, begin, mid, tmp);//归并左区间_MergeSort(arr, mid+1, end, tmp);//归并右区间int i = begin; int begin1 = begin, end1 = mid;int begin2 = mid + 1, end2 = end;while (begin1 <= end1 && begin2 <= end2){if (arr[begin1] < arr[begin2]){tmp[i++] = arr[begin1++];}else{tmp[i++] = arr[begin2++];}}//若是还有区间存在数据while (begin1 <= end1){tmp[i++] = arr[begin1++];}while (begin2 <= end2){tmp[i++] = arr[begin2++];}//最后将归并完后后的数据拷贝回原数组memcpy(arr + begin, tmp + begin, sizeof(int) * (end - begin + 1));
}
2.6.2. 判断区间有序
在归并排序合并时,如果两个区间是有序,即arr[end1]<=arr[begin2]时就不需要对其进行归并。
void _MergeSort(int* arr, int begin, int end, int* tmp)
{if (begin >= end){return;}int mid = (begin + end) >> 1;//以中间为分割点_MergeSort(arr, begin, mid, tmp);//归并左区间_MergeSort(arr, mid+1, end, tmp);//归并右区间int i = begin; int begin1 = begin, end1 = mid;int begin2 = mid + 1, end2 = end;if (arr[begin2] < arr[end1])//区间有序则不合并{while (begin1 <= end1 && begin2 <= end2){if (arr[begin1] < arr[begin2]){tmp[i++] = arr[begin1++];}else{tmp[i++] = arr[begin2++];}}//若是还有区间存在数据while (begin1 <= end1){tmp[i++] = arr[begin1++];}while (begin2 <= end2){tmp[i++] = arr[begin2++];}//最后将归并完后后的数据拷贝回原数组memcpy(arr + begin, tmp + begin, sizeof(int) * (end - begin + 1));}
}
2.7. 非递归实现
非递归实现归并排序,就需要通过迭代来模拟归并排序归并的过程。这时我们可以通过一个变量gap来代表归并区间的大小,初始化gap=1并且每次归并完成之后gap*=2。

void MergeSortNonR(int* arr, int n)//非递归实现
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail:");return;}int gap = 1;//归并区间大小while (gap < n){for (int i = 0; i < n; i += 2 * gap){int j = i;//记录起始位置int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;while (begin1 <= end1 && begin2 <= end2){if (arr[begin1] < arr[begin2]){tmp[j++] = arr[begin1++];}else{tmp[j++] = arr[begin2++];}}//若是还有区间存在数据while (begin1 <= end1){tmp[j++] = arr[begin1++];}while (begin2 <= end2){tmp[j++] = arr[begin2++];}//归并一组拷贝一组memcpy(arr + i, tmp + i, sizeof(int) * (end2 - i + 1));}gap *= 2;}
}
但是这段代码有一个明显的问题,那就是可能出现越界访问的情况,分别可能是end1越界,begin2越界, end2`越界。
- 情况一:
end1越界,begin2越界,只有一个区间在原数组内,不需要归并拷贝,直接break跳出循环。 - 情况二:
end2越界,有两个区间在原数组内,需要归并拷贝,修正end2=n-1。
void MergeSortNonR(int* arr, int n)//非递归实现
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail:");return;}int gap = 1;//归并区间大小while (gap < n){for (int i = 0; i < n; i += 2 * gap){int j = i;//记录起始位置int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;if (end1 >= n || begin2 >= n){break;}if (end2 >= n){end2 = n - 1;}while (begin1 <= end1 && begin2 <= end2){if (arr[begin1] < arr[begin2]){tmp[j++] = arr[begin1++];}else{tmp[j++] = arr[begin2++];}}//若是还有区间存在数据while (begin1 <= end1){tmp[j++] = arr[begin1++];}while (begin2 <= end2){tmp[j++] = arr[begin2++];}memcpy(arr + i, tmp + i, sizeof(int) * (end2 - i + 1));}gap *= 2;}
}
3. 文件外排序
当数据量很少时,数据都存在内存中,我们可以用的排序多种多样。但是当数据量足够大时,数据就将会放在磁盘文件中,这时文件指针很难完成随机偏移。即使有着fseek的库函数,效率也是极低的,所以这时最好选择归并排序对其进行排序。
步骤如下:
- 首先将一个待排序文件分成若干份,每一份文件存储数据都不大于内存最大的容纳范围。
- 然后将这若干个小文件放入内存中对其进行排序,使每一个文件有序。
- 然后利用归并排序的思想,以每一个小文件为基准进行归并。
- 最后归并完毕,就能使原数据量较大的文件有序。

void _MergeSortFile(const char* file1, const char* file2, const char* mfile)
{FILE* fout1 = fopen(file1, "r");if (fout1==NULL){perror("fopen fail");return;}FILE* fout2 = fopen(file2, "r");if (fout2==NULL){perror("fopen fail");return;}FILE* fin = fopen(mfile, "w");if (fin==NULL){perror("fopen fail");return;}int num1, num2;int ret1 = fscanf(fout1, "%d\n", &num1);//利用返回值判断是否结束int ret2 = fscanf(fout2, "%d\n", &num2);while (ret1 != EOF && ret2 != EOF){//文件指针在读取时会自动往后移动if (num1 < num2){fprintf(fin, "%d\n", num1);ret1 = fscanf(fout1, "%d\n", &num1);}else{fprintf(fin, "%d\n", num2);ret2 = fscanf(fout2, "%d\n", &num2);}}while (ret1 != EOF){fprintf(fin, "%d\n", num1);ret1 = fscanf(fout1, "%d\n", &num1);}while (ret2 != EOF){fprintf(fin, "%d\n", num2);ret2 = fscanf(fout2, "%d\n", &num2);}fclose(fout1);fclose(fout2);fclose(fin);
}/*文件外排序*/
void MergeSortFile(const char* file)
{FILE* fout1 = fopen(file, "w");if (fout1 == NULL){perror("fopen fail");return;}for (int i = 0; i < 100; ++i){int num = rand() % 100;fprintf(fout1, "%d\n", num);}fclose(fout1);FILE* fout = fopen(file, "r");if (fout==NULL){perror("fopen fail");return;}int num = 0;const int n = 10;//每个小文件数据个数int i = 0;int arr[10];char subfile[20];int filei = 1;memset(arr, 0, sizeof(int) * n);//初始化//将大文件分为小文件while (fscanf(fout, "%d\n", &num) != EOF){//首先读9个数据到数组中。//如果是一次读取10个数据,第11次进入else时的num会被忽略if (i < n - 1){arr[i++] = num; }else{arr[i] = num;//放入第10个数据QuickSort(arr, 0, n - 1); //进行排序sprintf(subfile, "%d", filei++);//文件名FILE* fin = fopen(subfile, "w");if (fin==NULL){perror("fopen fail:");return;}//将排序好数据写入每个小文件for (int j = 0; j < n; ++j){fprintf(fin, "%d\n", arr[j]);}fclose(fin);i = 0; //i重新置0,方便下一次的读取memset(arr, 0, sizeof(int) * n);//重置}}//两两归并文件char file1[100] = "1";char file2[100] = "2";char mfile[100] = "12";for (int i = 2; i <= 10; i++){_MergeSortFile(file1, file2, mfile);strcpy(file1, mfile);sprintf(file2, "%d", i + 1);//更新文件名sprintf(mfile, "%s%d", mfile, i + 1);//更新文件名}
}