开源数据库DuckDB1.0 经过内部6年的打磨,积累了30万行代码,1.8万star,2024.06.03号正式发布了1.0版本(代号 Snow Duck)。
我们新一代程序员,没能见证MySQL 1.0、PostgreSQL 1.0、Windows 1.0、Linux 1.0、Java 1.0。但是今天有幸见证 DuckDB 这样一个伟大的产品发布了1.0,我不知道她会不会发展为AI时代最耀眼的数据库,但她已经可以轻松访问AI大模型与数据聚居地Hugging Face的数据,她还可以使用GPU加速运算。
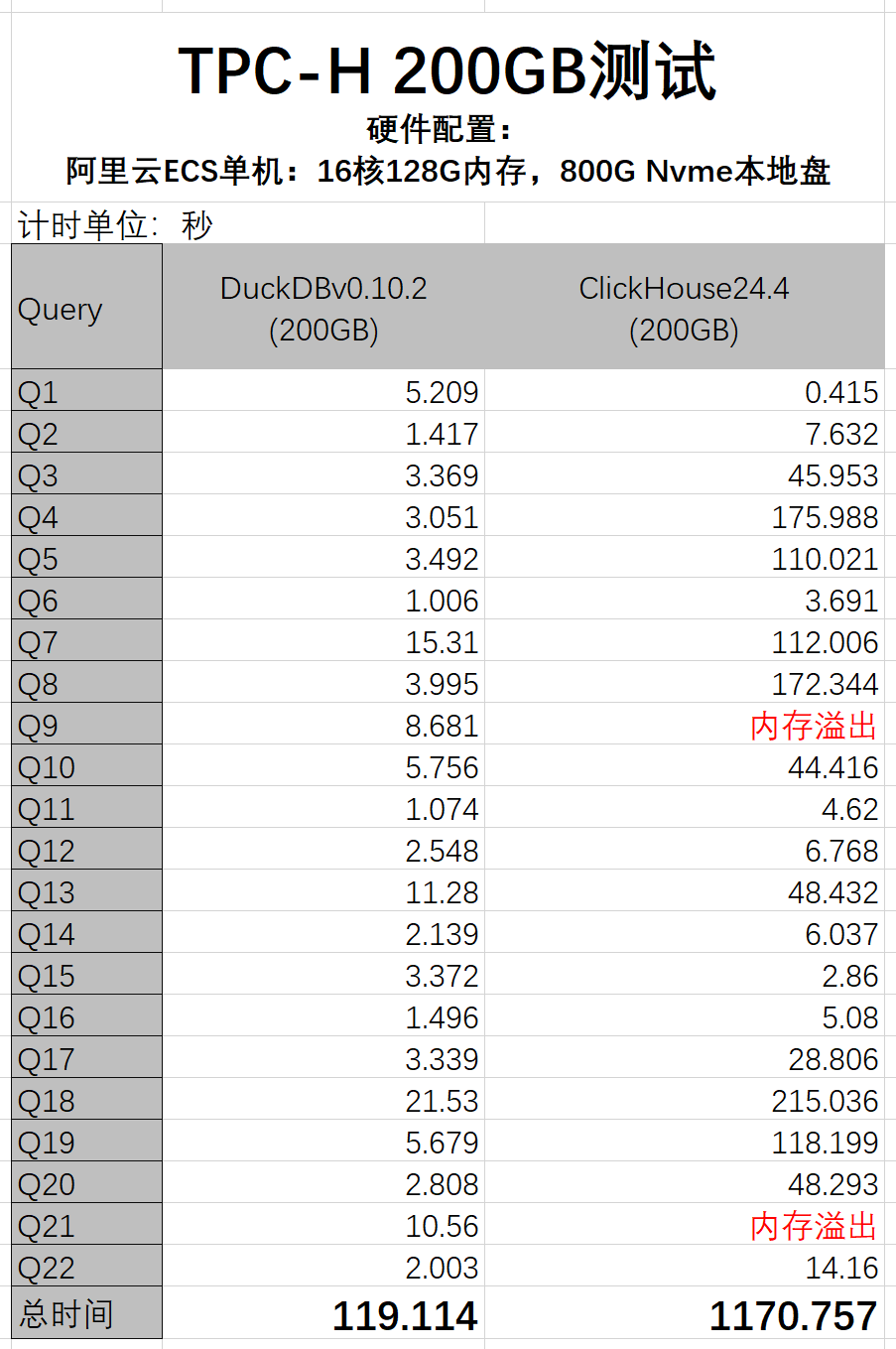
DuckDB非常擅长大数据量的分析,基于列式数据存储与向量计算与当红的ClickHouse理念类似,但相比ClickHouse,他有非常优秀的优化器和复杂查询计算能力,本人2周前在TPC-H 200GB的数据测试中,DuckDB仅用了ClickHouse 1/10的时间,轻松完成测试。
2019年数据库最顶级的会议ACM SIGMOD有一篇DuckDB论文,介绍了DuckDB的理念,定位是嵌入式分析型数据库,理念对标OLTP领域的SQLite。SQLite现在是全球装机量最大的数据库,据说超过80亿个,手机里的主流APP 微信、淘宝、Twitter和浏览器、汽车里都内置了至少一个SQLite。

论文地址:https://duckdb.org/pdf/SIGMOD2019-demo-duckdb.pdf
DuckDB使用
DuckDB与PostgreSQL、SQLite、MonetDBLite都有渊源,她继承了MonetDBLite的发展,参考和使用了PostgrSQL的解析器代码,同时还兼容了很多SQLite的接口。
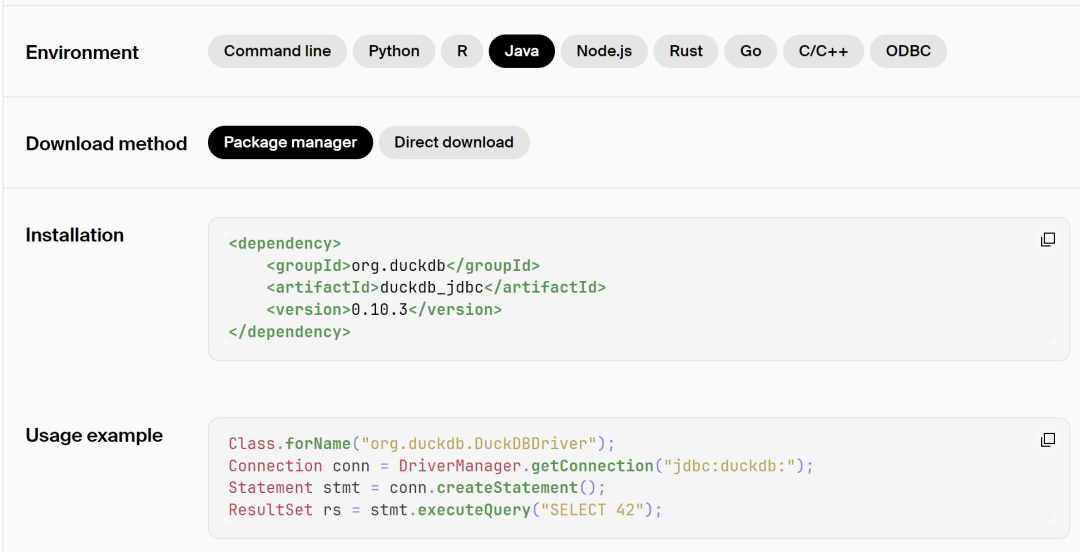
DuckDB是嵌入式架构,使用很简单,不需要安装,他支持Java、C/C++、Python、Go等主流语言接口和CLI操作。在Java里面只需要maven引入一个jar包即可在本机上管理数据库,支持标准的jdbc接口,如下:
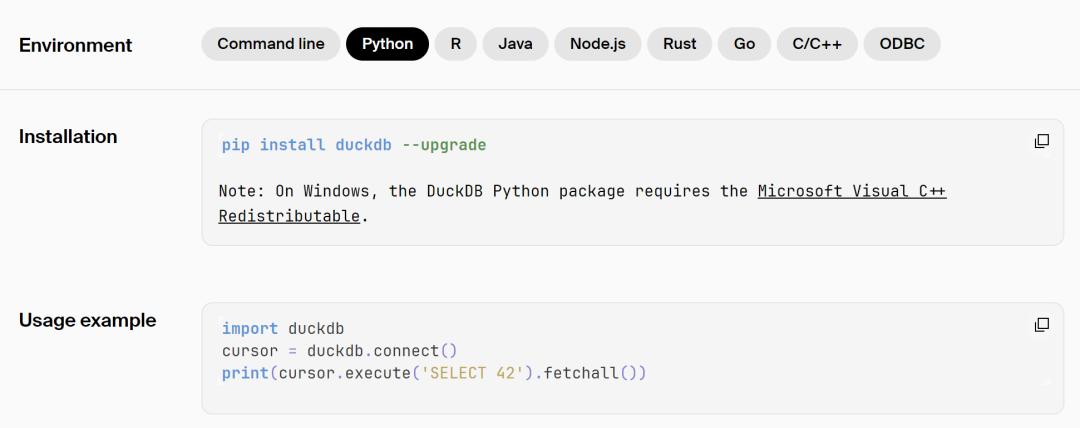
下面是Python的用法,是不是更简单易用。
如果你是AI数据程序员,你应该要想想如何使用DuckDB来处理数据,而不是Python语言那蜗牛性能,使用DuckDB有可能数据处理效率会提升100倍,如果再结合GPU加速的DuckDB,要上天了。
DuckDB可以直接用SQL读取本地或者远程(HTTP、S3)的csv和parquet文件,类似下面的SQL方法:
# SQL读取本地csvSELECT * FROM 'myfile.csv';# SQL读取本地parquetSELECT * FROM 'myfile.parquet';# SQL读取http远程文件SELECT * FROM 'https://domain.tld/file.parquet';# SQL读取AWS 对象存储S3上的文件SELECT * FROM 's3://my-bucket/file.parquet';# DuckDB最近还新增了用SQL读取Hugging Face上的数据文件,这是搞AI同学一定要学习的利器啊SELECT * FROM 'hf://datasets/datasets-examples/doc-formats-csv-1/data.csv';
DuckDB另一个特性是可以非常轻松的扩展插件,通过插件,他可以很简单的访问MySQL、PostgreSQL数据库,还可以快速完成TPC-H、TPC-DS测试,DuckDB的插件思想应该是学习了PostgreSQL理念。
DuckDB团队
DuckDB早期是由荷兰阿姆斯特丹CWI(国家数学和计算机科学研究学会)的Hannes和Mark两位大神开发的,CWI也是Python诞生的地方,他们还成立了DuckDB基金会和DuckDB Labs公司,以保障产品的顺利发展,现在核心开发人员10人左右。
另外业界有一家创业公司MotherDuck,基于DuckDB提供云服务,已经获得超过1亿美金的融资,他们也是DuckDB的重要赞助企业。
DuckDB Labs现在有18人,包括2个创始人( CEO Hannes,CTO Mark)CTO是最主力的程序员,50%的代码是他1人完成,另外还有13个程序员,1个测试实习生,1个人负责开发者生态,1个人负责培训与文档,里面应该不少都是Hannes教授的弟子。

DuckDB1.0.0发布官方公告
以下内容翻译自DuckDB发布的官方博客:
https://duckdb.org/2024/06/03/announcing-duckdb-100
DuckDB 1.0.0 发布
马克·拉斯维尔特(Mark Raasveldt)和汉内斯·穆莱森(Hannes Mühleisen)2024-06-03
TL;DR:DuckDB 团队非常高兴地宣布,今天我们发布了 DuckDB 1.0.0 版本,代号为“Snow Duck”(anas nivis)。
要安装新版本,请访问安装指南。有关发行说明,请参阅发行页面。
自 2018 年为该项目编写第一个源代码以来,已经过去了将近六年,此后发生了很多事情:现在有超过 300,000 行 C++ 引擎代码,超过 42,000 次提交,近 4,000 个问题被打开和关闭。DuckDB 也获得了极大的人气:该项目在 GitHub 和社交媒体平台上吸引了数以万计的明星和追随者。每个月的下载量以百万计,仅扩展程序的下载流量每天就超过 4 TB。甚至有关于DuckDB的书在写,最重要的是,现在甚至维基百科也认为DuckDB是值得注意的,尽管几乎没有。
为什么现在发布?
当然,版本号有些武断和“费力”,尽管试图使它们更加机械。我们本可以在 2018 年发布 DuckDB 1.0.0,或者我们可以再等十年。从来没有一个伟大的时刻,因为软件(TeX除外)永远不会“完成”。为什么选择今天?
数据管理系统(即使是纯粹的分析系统)是任何应用程序的核心组件,其开发人员和用户之间始终存在隐含的信任契约。用户依靠数据库来提供正确的查询结果,并且不会丢失其数据。同时,系统开发人员需要意识到他们的责任,即不随意破坏人们的应用程序。直观地说,版本 1.0.0 对数据管理系统的意义大于对煮蛋计时器应用程序的意义(没有冒犯)。从一开始,我们就致力于使 DuckDB 成为人们构建应用程序的可靠基础。这也是为什么 1.0.0 版本以不存在的雪鸭 (anas nivis) 命名的原因,让人想起几年前 Apple 的 Snow Leopard 版本。
对我们来说,发布 1.0.0 的主要障碍之一是存储格式。DuckDB 有自己定制的数据存储格式。这种格式允许用户在单个文件中管理许多(可能非常大)的表,具有完整的事务语义和最先进的压缩。当然,设计一种新的文件格式并非没有挑战,随着时间的推移,我们不得不对格式进行重大更改。这导致了次优的情况,即每当发布新的 DuckDB 版本时,使用旧版本创建的文件无法与新的 DuckDB 版本一起使用,必须手动升级。这个问题在 2 月份的 v0.10.0 中得到了解决——我们为 DuckDB 的存储格式引入了向后兼容性和有限的向前兼容性。这个功能现在已经在野外使用了一段时间,没有出现严重问题——这让我们有信心保证使用 DuckDB 1.0.0 创建的 DuckDB 文件将与未来的 DuckDB 版本兼容。
稳定性
1.0.0 版本的核心主题是稳定性。这与以前的版本形成鲜明对比,在以前的版本中,我们已经有博客文章讨论了一长串新功能。相反,1.0.0 版本的新功能非常有限(一些可能已经 偷偷溜进来了)。相反,我们的重点一直是稳定性。
坦率地说,我们已经观察到 DuckDB 在野外使用的数量和广度的惊人增长,并且没有看到报告的严重问题增加。同时,每天晚上都有数千个测试用例和数百万个测试查询。我们运行了大量的微基准测试和标准化基准测试套件来发现性能回归。DuckDB 不断受到各种模糊器的折磨,这些模糊器构建了各种形式的野生 SQL 查询,以确保我们不会错过奇怪的极端情况。总而言之,这为我们发布 1.0.0 建立了必要的信心。
1.0.0 版本稳定性的另一个核心方面是跨版本的稳定性。虽然永远不可能破坏任何人的工作流程,但我们计划在未来更加谨慎地对待面向用户的更改。特别是,我们计划专注于为 SQL 方言以及 C API 提供稳定性。虽然我们不能保证将来永远不会更改这些层的语义,但我们会在这样做时尝试提供充分的警告,并提供允许以前工作的代码继续工作的解决方法。
展望未来
与许多开源项目不同,DuckDB 也有一个健康的长期融资策略。DuckDB Labs 是雇用 DuckDB 核心贡献者的公司,没有任何外部投资,因此,该公司完全归团队所有。Labs 的商业模式是为 DuckDB 提供咨询和支持服务,我们很高兴地报告进展顺利。凭借合同收入,我们拥有近 20 人的团队,为长期和战略性的 DuckDB 开发提供资金。同时,该项目的知识产权由独立的DuckDB基金会保护。这个非营利性基金会确保 DuckDB 将在 MIT 许可下长期存在。
关于长期计划,当然,路线图上还有很多事情。我们非常兴奋的一件事是能够围绕 DuckDB 扩展扩展环境。扩展是插件,可以添加新的 SQL 级函数、文件格式、优化器等,同时保持 DuckDB 核心的均值和精益。DuckDB 已经有大量第三方扩展,我们正在努力简化构建和分发社区贡献的扩展的过程。我们认为 DuckDB 可以成为下一次数据革命的基础,通过社区扩展通过高性能数据结构连接,可通过统一的 SQL 接口访问。
当然,在今天的版本中会发现一些问题。但请放心,将会有一个 1.0.1 版本。将有一个 1.1.0。在某个时候也可能有 2.0.0。从长远来看,我们所有人都在一起。我们有团队、结构和资源来做到这一点。
致谢
首先,我们非常感谢大家。我们衷心感谢所有贡献代码、提交问题或参与讨论、在他们的环境中推广 DuckDB 的人,当然还有所有 DuckDB 用户。没有你,我们不可能做到这一点!
我们还要感谢 CWI 数据库架构小组为我们提供了构建 DuckDB 的环境和专业知识,感谢早期为我们提供研究资助的组织,感谢 DuckDB Labs 的优秀客户(尤其是早期客户),以及 DuckDB 基金会的慷慨捐赠者。我们特别感谢我们长期的金牌赞助商 MotherDuck、Voltron Data 和 Posit。
最后,我们要感谢 DuckDB Labs 优秀而出色的团队。
因此,现在就加入我们的行列,怀念、泪眼婆娑,对 DuckDB 即将发生的事情感到兴奋,并与我们一起庆祝 DuckDB 1.0.0 的发布。我们当然会。
关于作者
叶正盛,NineData 创始人 &CEO,资深数据库专家,原阿里云数据库产品管理与解决方案部总经理。NineData(www.ninedata.cloud)是云原生数据管理平台,提供数据库 DevOps(SQL IDE、SQL 审核与发布、性能优化、数据安全管控)、数据复制(迁移、同步、ETL)、备份等功能,可以帮助用户更安全、高效使用数据。