文章目录
- 一、背景
- 二、方法
- 2.1 ShareGPT4V 数据集构建
- 2.2 ShareGPT4V-PT 数据生成
- 2.3 ShareGPT4V-7B Model
- 三、效果
- 3.1 benchmark
- 3.2 定量分析
- 3.3 多模态对话
- 四、一些例子
论文:ShareGPT4V: Improving Large Multi-Modal Models with Better Captions
代码:https://sharegpt4v.github.io/
出处:中国科学技术大学 | 上海 AI Lab
时间:2023.11
贡献:
- 指出了目前 LMM 模型没有发挥最大能力的问题:没有高质量的 image-text pairs 数据集,低质量的数据集不利于 vision 和 language 模型的对齐
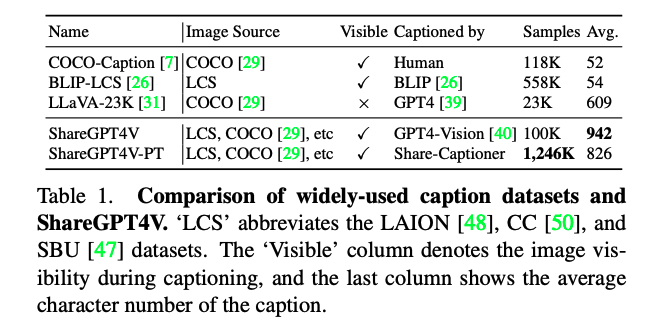
- 构建了 ShareGPT4V 数据集,包含了 100k 高质量描述 caption(GPT-4V生成),1.2M 高质量描述(caption model 生成)
- 提出了 ShareGPT4V-7B 模型,超越其他同量级 7B 模型的效果
一、背景
虽然近来 LMM 模型取得了很大的突破,但作者认为目前 LMM 模型并没有被激发出最优的能力,主要原因在于缺少高质量的 image-text pairs
图像一般包括非常丰富的信息和细粒度的语义,但这些细节信息和细粒度的语音通常并没有在主流的 image-text dataset 中体现出来,这些主流数据的 caption 一般都是对图像中主要目标的简短描述,这样会丢失掉很多内容,没法很好的进行不同模态的信息对齐
为了证明这个观点,作者替换了几个模型在 SFT 阶段中使用的图像的 caption,使用 GPT-4V 进行了优化和丰富,如图 2 所示。在LLaVA-1.5中,只替换了SFT(Supervised Fine-Tuning)阶段使用的图像-文本对数据中的 3.5%,而没有全部替换,即使这样,模型都得到了性能提升。
所以,作者进一步扩大了生成 caption 的范围:
- 第一阶段:作者收集了约 10 万图像,然后使用 GPT-4V 生成高质量的描述文字,这些文字平均长度为 942 个字符,涵盖了丰富的图像信息,例如世界知识、物体属性、空间关系、美学评价等
- 第二阶段:利用这些描述构建了一个描述模型,使用第一阶段的数据来训练该模型,能够给图像生成全面的描述
经过上面两个步骤,就得到了 ShareGPT4V 数据集,包括两部分:
- 100k GPT4V 生成的 caption
- 1.2M 使用 caption model 得到的 caption
作者使用 ShareGPT4V 构建了一个大型 LMM 模型:ShareGPT4V-7B,图 1 b 展示了 ShareGPT4V-7B 在 11 个 benchmark 上超越了其他 7B 量级的 LMM

二、方法
2.1 ShareGPT4V 数据集构建
数据源:为了丰富数据,作者从检测、分割、text-containing、web、landmark、celebrities 等数据集中抽取了 100k 数据
- COCO [29] 的 50K 张图像
- ‘LCS’(即 LAION [48]、CC-3M [50] 和 SBU [41] 的缩写)的 30K 张图像
- SAM [21] 的 20K 张图像
- TextCaps [51] 的 500 张图像
- WikiArt [47] 的 500 张图像
- 从网络爬取的数据中获取的 1K 张图像
prompt:
- 为了确保描述质量和稳定性,作者设计了一个 base prompt,base prompt 的作用是让 GPT-4V 描述图像的基本信息,如图 3 所示

prompt:

quality verification:
- 作者还判断了生成的 caption 的质量
- 证明了使用高质量、详细的字幕可以显著提升多模态模型在监督微调阶段的表现,从而强调了获取更多高质量数据的重要性。

2.2 ShareGPT4V-PT 数据生成
为了构建 pretrain 阶段的数据集,作者使用这生成的 100k 个高质量的 caption 微调了一个 caption model,叫做 Share-Captioner,能够生成高质量的内容丰富的描述
数据来源:
- 预训练的 Share-Captioner 来生成预训练数据集。
- 该数据集由从现有公开数据集中选择的 1.2M 张图像子集组成
- 这些图像包括来自 COCO [29] 的 118K 张图像
- SAM [21] 的 570K 张图像
- LLaVA-1.5 预训练数据 [30] 的 558K 张图像。
为了收集大量高质量的图像-文本对,我们从现有的公共数据集中选择了120万张图像(更多细节见补充材料),并使用预训练的 Share-Captioner 进行 caption 生成。整个 caption 生成过程大约需要 44 个 A100 GPU天,这部分数据命名为ShareGPT4V-PT。
定性分析:
图 4 对比了不同来源的 caption

定量分析:作者使用 gpt-4v 和 share-captioner 生成了 100 个 caption,10 个人选择了其各自认为最好的描述
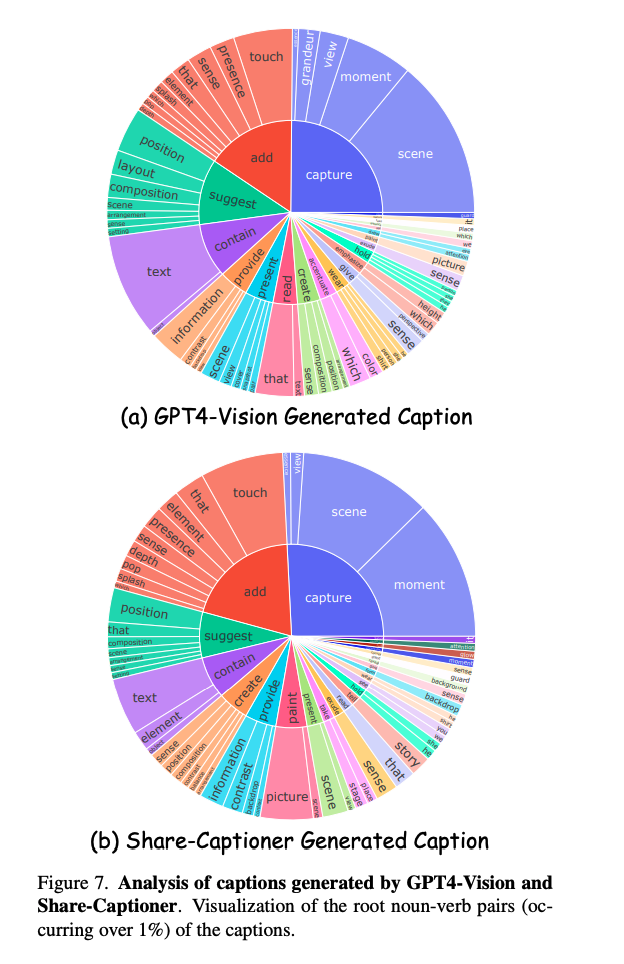
图7展示了由GPT4-Vision和Share-Captioner生成的字幕中根名词-动词对的可视化。从中可以清楚地看到,Share-Captioner生成的字幕在多样性和语言表达上与GPT4-Vision相当。
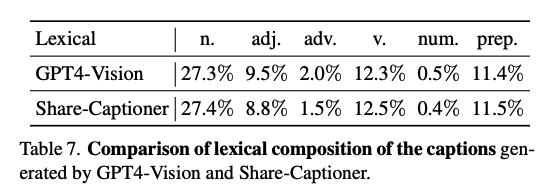
分析了由GPT4-Vision和Share-Captioner生成的字幕的词汇组成,结果如表7所示。分析显示,我们的Share-Captioner生成的字幕包含的信息量与GPT4-Vision生成的字幕相当。
2.3 ShareGPT4V-7B Model
模型结构借鉴 LLava-1.5,包括三个模块:
- vision encoder:clip-large model,分辨率为 336x336,patch size=14,输入图像被转换为 576 个 token
- projector:两层 MLP
- LLM:vicuna-v1.5
预训练:
- 数据集:ShareGPT4V 中的 pretrain 数据集,也就是 ShareGPT4V-PT
- 因为使用了高质量的 caption,只微调 MLP 已经不能很好的开发模型的潜力了(之前的 LMM 模型只微调这部分),所以,作者会同时微调编码器、投影器和大型语言模型,用于让大语言模型理解细致的视觉embedding,嵌入更细节的信息。
- 此外,作者还发现仅仅微调 vision encoder 的后半部分层也可以达到很好的效果,且训练效率会更高
- 学习率:2e-5
- batch size:256
- steps:4700
微调:
- 本文的目标不是为了实现 sota 模型,而是为了研究高质量 caption 在实现多模态模型中更好的模态对齐上是不是有效
- 因此,作者使用 LLava-1.5 中的 665k 微调数据,然后使用 ShareGPT4V 替换了其中一部分。具体的替换是 23k详细描述数据
- 冻结了视觉编码器,专注于微调投影器和大型语言模型。学习率设定为2e-5,批量大小为128,总优化过程大约持续了5200步。
三、效果
3.1 benchmark
使用了 11 个常见的 benchmark
3.2 定量分析
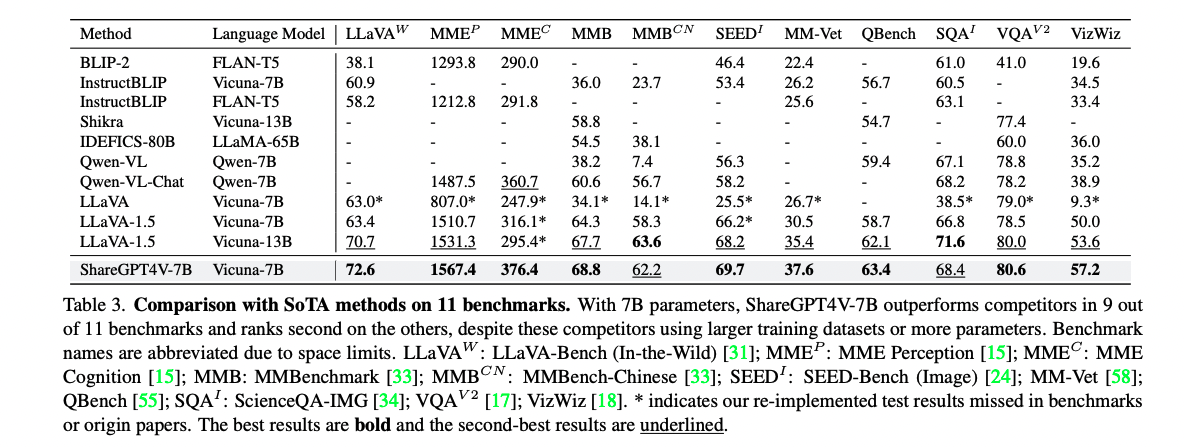
ShareGPT4V-7B 在 9/11 个数据集中取得了很好的效果
3.3 多模态对话

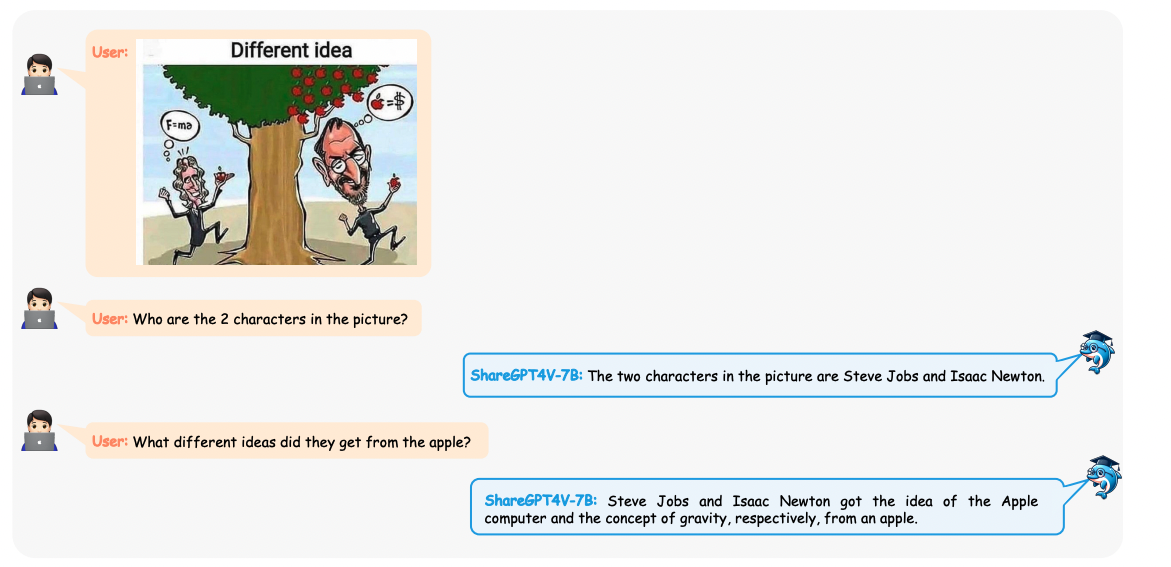
四、一些例子