1.JVM 简介
JVM 是 Java Virtual Machine 的简称,意为 Java虚拟机。
虚拟机是指通过软件模拟的具有完整硬件功能的、运⾏在⼀个完全隔离的环境中的完整计算机系统。
常⻅的虚拟机:JVM、VMwave、Virtual Box。
JVM 和其他两个虚拟机的区别:
- VMwave与VirtualBox是通过软件模拟物理CPU的指令集,物理系统中会有很多的寄存器;
- JVM则是通过软件模拟Java字节码的指令集,JVM中只是主要保留了PC寄存器,其他的寄存器都进 ⾏了裁剪。 JVM 是⼀台被定制过的现实当中不存在的计算机。
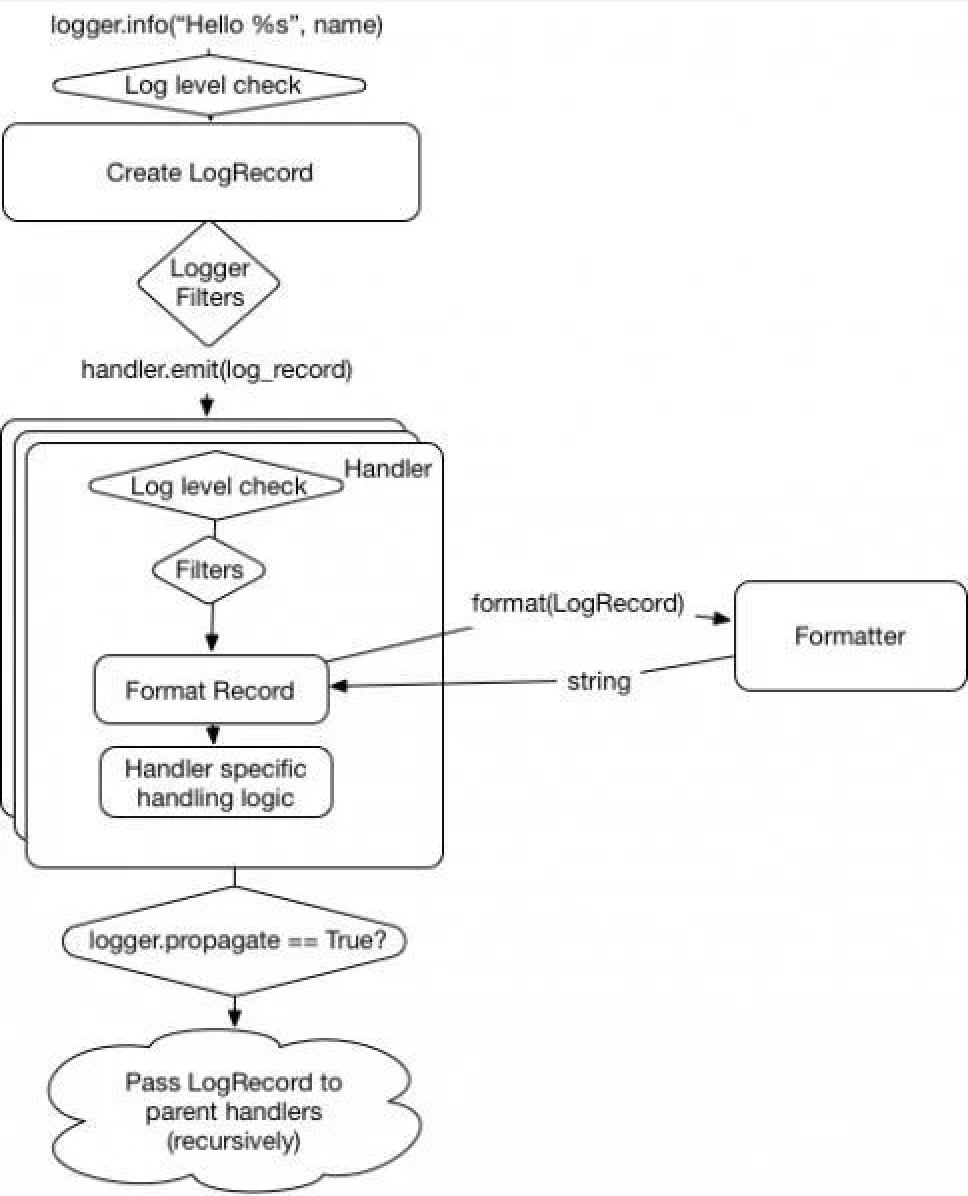
2. JVM 运行流程
JVM 是 Java运行的基础,也是实现⼀次编译到处执⾏的关键,那么 JVM 是如何执⾏的呢?
JVM 执⾏流程
程序在执⾏之前先要把java代码转换成字节码(class⽂件),JVM ⾸先需要把字节码通过⼀定的⽅式 类加载器(ClassLoader)
把⽂件加载到内存中 运⾏时数据区(Runtime Data Area) ,⽽字节码⽂ 件是 JVM的⼀套指令集规范,并不能直接交个底层操作系统去执⾏,因此需要特定的命令解析器 **执 ⾏引擎(Execution Engine)**将字节码翻译成底层系统指令再交由CPU去执⾏,⽽这个过程中需要 调⽤其他语⾔的接⼝ 本地库接⼝(Native Interface) 来实现整个程序的功能,这就是这4个主要组成 部分的职责与功能。
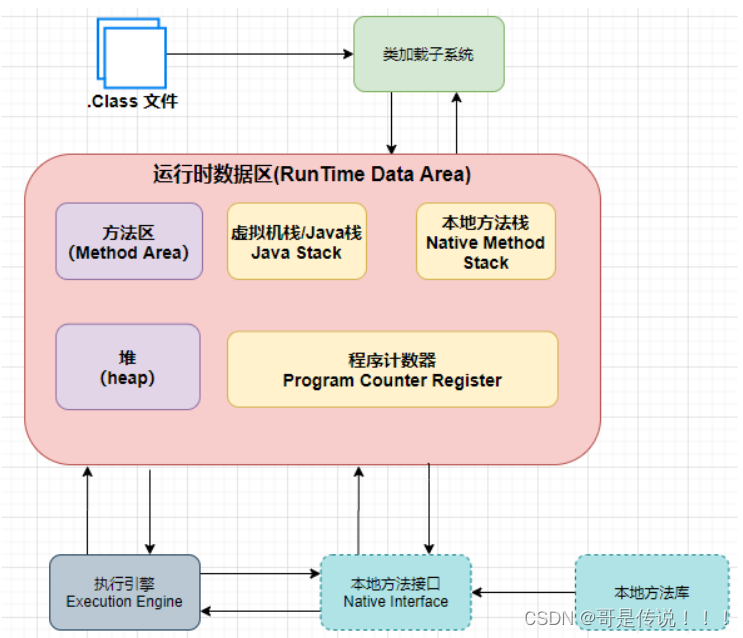
总结来看, JVM 主要通过分为以下 4 个部分,来执⾏ Java 程序的,它们分别是:
- 类加载器(ClassLoader)
- 运⾏时数据区(Runtime Data Area)
- 执⾏引擎(Execution Engine)
- 本地库接⼝(Native Interface)
3. JVM 运⾏时数据区
JVM 运⾏时数据区域也叫内存布局,但需要注意的是它和 Java 内存模型((Java Memory Model,简
称 JMM)完全不同,属于完全不同的两个概念,它由以下 5 ⼤部分组成(JVM就是Java进程,这个进程一旦跑起来,就会从操作系统这里,申请一大块内存空间,如下):
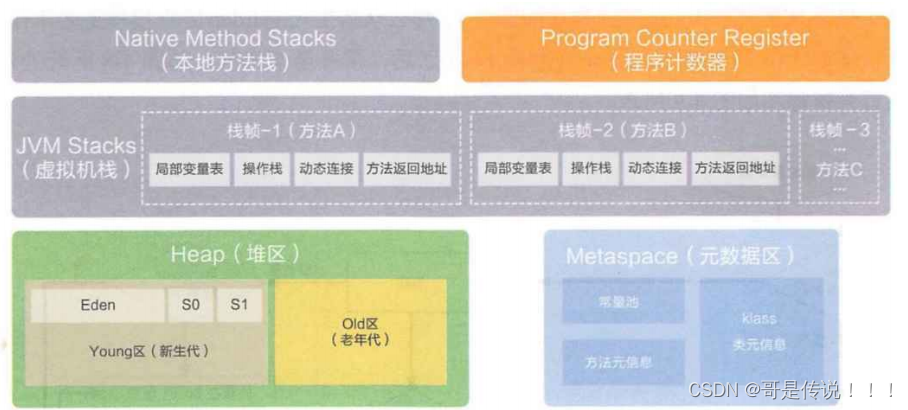
3.1 堆(线程共享)(成员变量)
堆的作用:程序中创建的所有对象都在保存在堆中。(new出来的对象,如成员变量)
3.2 Java虚拟机栈(线程私有)(局部变量)
Java 虚拟机栈的作用:Java 虚拟机栈的⽣命周期和线程相同,Java 虚拟机栈描述的是 Java ⽅法执⾏的内存模型:每个⽅法在执⾏的同时都会创建⼀个栈帧(StackFrame)⽤于存储局部变量表、操作数栈、动态链接、⽅法出⼝等信息。咱们常说的堆内存、栈内存中,栈内存指的就是虚拟机栈
Java 虚拟机栈中包含了以下 4 部分:
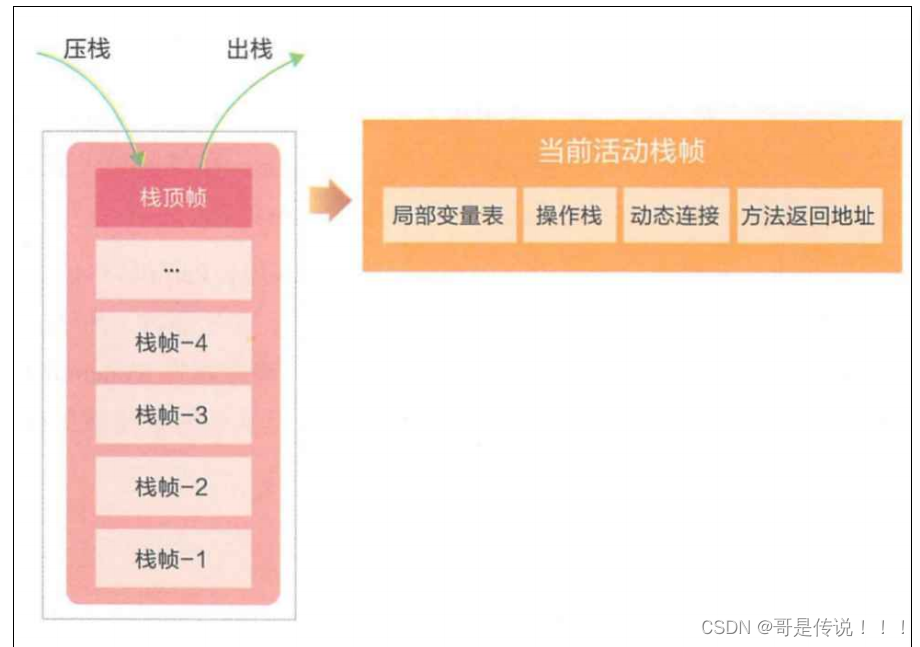
- 局部变量表: 存放了编译器可知的各种基本数据类型(8⼤基本数据类型)、对象引⽤。局部变量表 所需的内存空间在编译期间完成分配,当进⼊⼀个⽅法时,这个⽅法需要在帧中分配多⼤的局部变 量空间是完全确定的,在执⾏期间不会改变局部变量表⼤⼩。简单来说就是存放⽅法参数和局部变量。
- 操作栈:每个⽅法会⽣成⼀个先进后出的操作栈。
- 动态链接:指向运⾏时常量池的⽅法引⽤。
- ⽅法返回地址:PC 寄存器的地址。
什么是线程私有?
由于JVM的多线程是通过线程轮流切换并分配处理器执⾏时间的⽅式来实现,因此在任何⼀个确定的 时刻,⼀个处理器(多核处理器则指的是⼀个内核)都只会执⾏⼀条线程中的指令。因此为了切换线程后能恢复到正确的执⾏位置,每条线程都需要独⽴的程序计数器,各条线程之间计数器互不影响,独⽴ 存储。我们就把类似这类区域称之为"线程私有"的内存
3.3 本地方法栈(线程私有)
本地⽅法栈和虚拟机栈类似,只不过 Java 虚拟机栈是给 JVM 使⽤的,⽽本地⽅法栈是给本地⽅法使⽤的。
3.4 程序计数器(线程私有)
程序计数器的作⽤:⽤来记录当前线程执⾏的⾏号的。
程序计数器是⼀块⽐较⼩的内存空间,可以看做是当前线程所执⾏的字节码的⾏号指⽰器。如果当前线程正在执⾏的是⼀个Java⽅法,这个计数器记录的是正在执⾏的虚拟机字节码指令的地址;如果正在执⾏的是⼀个Native⽅法,这个计数器值为空。程序计数器内存区域是唯⼀⼀个在JVM规范中没有规定任何OOM情况的区域!
3.5 方法区/元数据区(线程共享)(类对象)静态变量
⽅法区的作⽤:⽤来存储被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据的
4.JVM 类加载
1.加载(在硬盘上找到.class文件,读取文件内容)
2.验证(检查.class文件的内容是否符合要求)
3.准备(给类对象分配内存空间)
4.解析(针对字符串常量来进行初始化,把.class文件中的常量内容取出来,放到“元数据区”)
5.初始化(针对类对象进行初始化)
5.双亲委派模型
如果⼀个类加载器收到了类加载的请求,它⾸先不会⾃⼰去尝试加载这个类,⽽是把这个请求委派给⽗类加载器去完成,每⼀个层次的类加载器都是如此,因此所有的加载请求最 终都应该传送到最顶层 的启动类加载器中,只有当⽗加载器反馈⾃⼰⽆ 法完成这个加载请求(它的搜索范围中没有找到所需 的类)时,⼦加载器才会尝试⾃⼰去完成加载。

这与工作时的一段经历非常相似:
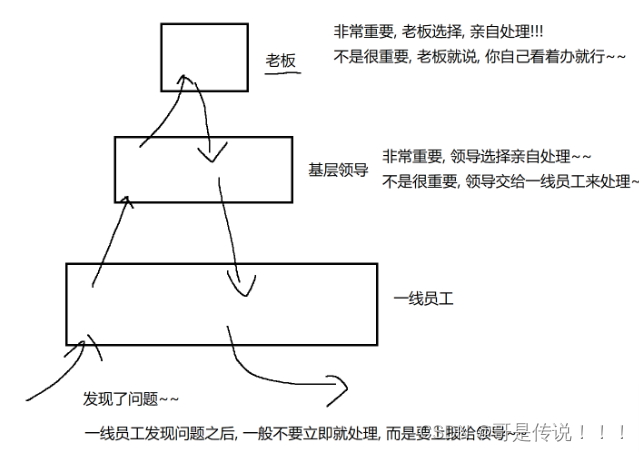
先交给上一级去执行,没有上一级了就自己解决,自己没有找到这个类就让下一级去找,如此执行每一级都会查询到
双亲委派模型的优点
- 避免重复加载类:⽐如 A 类和 B 类都有⼀个⽗类 C 类,那么当 A 启动时就会将 C 类加载起来,那 么在 B 类进⾏加载时就不需要在重复加载 C 类了。
- 安全性:使⽤双亲委派模型也可以保证了 Java 的核⼼ API 不被篡改,如果没有使⽤双亲委派模 型,⽽是每个类加载器加载⾃⼰的话就会出现⼀些问题,⽐如我们编写⼀个称为 java.lang.Object 类的话,那么程序运⾏的时候,系统就会出现多个不同的 Object 类,⽽有些 Object 类⼜是⽤⼾⾃ ⼰提供的因此安全性就不能得到保证了
5.垃圾回收相关
上⾯讲了Java运⾏时内存的各个区域。对于程序计数器、虚拟机栈、本地⽅法栈这三部分区域⽽⾔,其⽣命周期与相关线程有关,随线程⽽⽣,随线程⽽灭。并且这三个区域的内存分配与回收具有确定性,因为当⽅法结束或者线程结束时,内存就⾃然跟着线程回收了。因此我们本节课所讲的有关内存分配和回收关注的为Java堆与⽅法区这两个区域。Java堆中存放着⼏乎所有的对象实例,垃圾回收器在对堆进⾏垃圾回收前,⾸先要判断这些对象哪些还存活,哪些已经"死去"。判断对象是否已"死"有如下⼏种算法
gc回收机制回收的是内存,更准确的说回收的是对象,回收的是堆上的内存。程序计数器,元数据区,栈一般不需要额外回收,线程销毁了自然就销毁了
gc机制的两个流程:1.找到谁是垃圾2.清除这个垃圾,释放对应的内存
1.引⽤计数描述的算法:
给对象增加⼀个引⽤计数器,每当有⼀个地⽅引⽤它时,计数器就+1;当引⽤失效时,计数器就-1;任何时刻计数器为0的对象就是不能再被使⽤的,即对象已"死"。
引⽤计数法实现简单,判定效率也⽐较⾼,在⼤部分情况下都是⼀个不错的算法。⽐如Python语⾔就采⽤引⽤计数法进⾏内存管理。
但是,在主流的JVM中没有选⽤引⽤计数法来管理内存,最主要的原因就是引⽤计数法⽆法解决对象的循环引⽤问题
public class Test {public Object instance = null;private static int _1MB = 1024 * 1024;private byte[] bigSize = new byte[2 * _1MB];public static void testGC() {Test test1 = new Test();Test test2 = new Test();test1.instance = test2;test2.instance = test1;test1 = null;test2 = null;// 强制jvm进⾏垃圾回收System.gc();}public static void main(String[] args) {testGC();}}
从结果可以看出,GC⽇志包含" 6092K->856K(125952K)",意味着虚拟机并没有因为这两个对象互相引⽤就不回收他们。即JVM并不使⽤引⽤计数法来判断对象是否存活。
b) 可达性分析算法
在上⾯我们讲了,Java并不采⽤引⽤计数法来判断对象是否已"死",⽽采⽤"可达性分析"来判断对象是否存活(同样采⽤此法的还有C#、Lisp-最早的⼀⻔采⽤动态内存分配的语⾔)。此算法的核⼼思想为 : 通过⼀系列称为"GC Roots"的对象作为起始点,从这些节点开始向下搜索,搜索⾛过的路径称之为"引⽤链",当⼀个对象到GC Roots没有任何的引⽤链相连时(从GC Roots到这个对象不可达)时,证明此对象是不可⽤的。以下图为例:
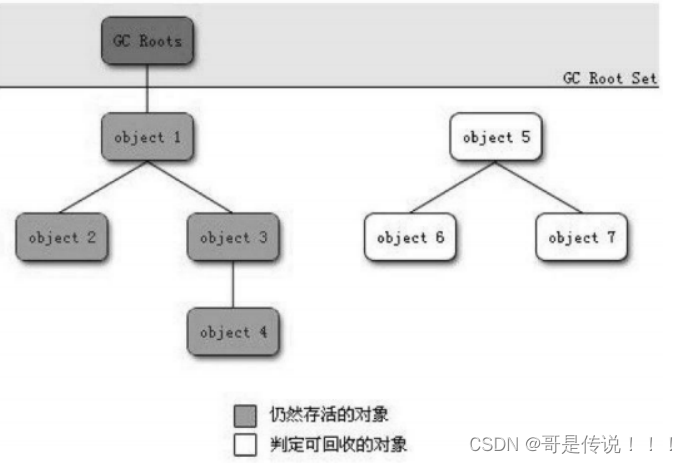
对象Object5-Object7之间虽然彼此还有关联,但是它们到GC Roots是不可达的,因此他们会被判定为可回收对象。
总结:引用计数描述算法和可达性分析就是对于垃圾进行标记
② 垃圾回收算法
通过上⾯的学习我们可以将死亡对象标记出来了,标记出来之后我们就可以进⾏垃圾回收操作了,在正式学习垃圾收集器之前,我们先看下垃圾回收机器使⽤的⼏种算法(这些算法是垃圾收集器的指导思想)。
a) 标记-清除算法
"标记-清除"算法是最基础的收集算法。算法分为"标记"和"清除"两个阶段 : ⾸先标记出所有需要回收的对象,在标记完成后统⼀回收所有被标记的对象(标记过程⻅3.1.2章节)。后续的收集算法都是基于这种思路并对其不⾜加以改进⽽已。
"标记-清除"算法的不⾜主要有两个 :
- 效率问题 : 标记和清除这两个过程的效率都不⾼
- 空间问题 : 标记清除后会产⽣⼤量不连续的内存碎⽚,空间碎⽚太多可能会导致以后在程序运⾏中 需要分配较⼤对象时,⽆法找到⾜够连续内存⽽不得不提前触发另⼀次垃圾收集。

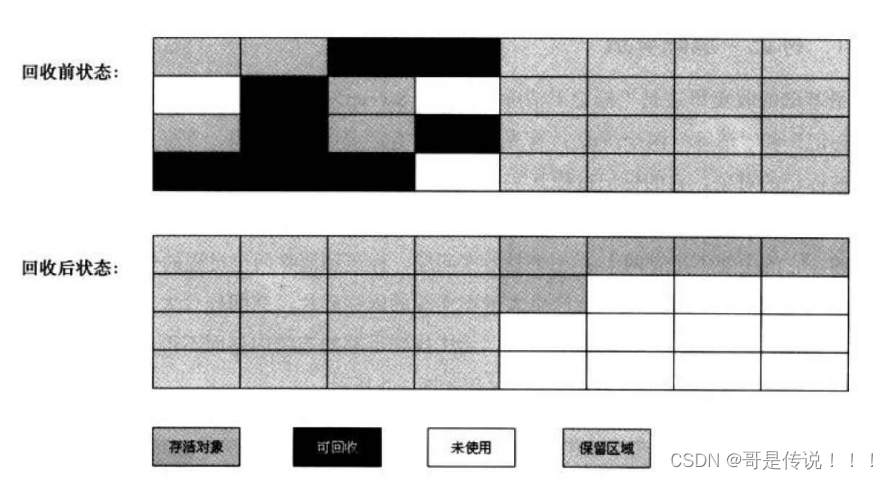
b) 复制算法
"复制"算法是为了解决"标记-清理"的效率问题。它将可⽤内存按容量划分为⼤⼩相等的两块,每次只使⽤其中的⼀块。当这块内存需要进⾏垃圾回收时,会将此区域还存活着的对象复制到另⼀块上⾯,然后再把已经使⽤过的内存区域⼀次清理掉。这样做的好处是每次都是对整个半区进⾏内存回收,内存分配时也就不需要考虑内存碎⽚等复杂情况,只需要移动堆顶指针,按顺序分配即可。此算法实现简单,运⾏⾼效。算法的执⾏流程如下图
c) 标记-整理算法
复制收集算法在对象存活率较⾼时会进⾏⽐较多的复制操作,效率会变低。因此在⽼年代⼀般不能使⽤复制算法。
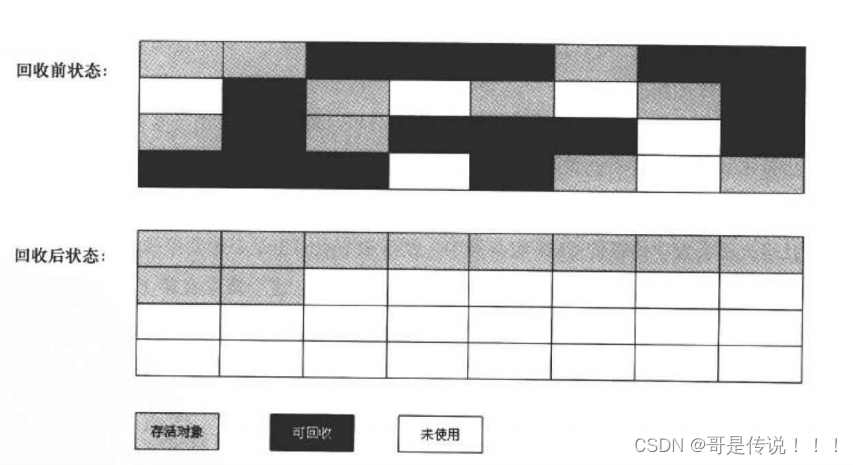
针对⽼年代的特点,提出了⼀种称之为"标记-整理算法"。标记过程仍与"标记-清除"过程⼀致,但后续步骤不是直接对可回收对象进⾏清理,⽽是让所有存活对象都向⼀端移动,然后直接清理掉端边界以外的内存。流程图如下
d) 分代算法
分代算法和上⾯讲的 3 种算法不同,分代算法是通过区域划分,实现不同区域和不同的垃圾回收策略,从⽽实现更好的垃圾回收。这就好⽐中国的⼀国两制⽅针⼀样,对于不同的情况和地域设置更符合当地的规则,从⽽实现更好的管理,这就时分代算法的设计思想。
当前 JVM 垃圾收集都采⽤的是"分代收集(Generational Collection)"算法,这个算法并没有新思想,只是根据对象存活周期的不同将内存划分为⼏块。⼀般是把Java堆分为新⽣代和⽼年代。在新⽣代中,每次垃圾回收都有⼤批对象死去,只有少量存活,因此我们采⽤复制算法;⽽⽼年代中对象存活率⾼、没有额外空间对它进⾏分配担保,就必须采⽤"标记-清理"或者"标记-整理"算法。哪些对象会进⼊新⽣代?哪些对象会进⼊⽼年代?
• 新⽣代:⼀般创建的对象都会进⼊新⽣代;
• ⽼年代:⼤对象和经历了 N 次(⼀般情况默认是 15 次)垃圾回收依然存活下来的对象会从新⽣代
移动到⽼年代。
⾯试题 : 请问了解Minor GC和Full GC么,这两种GC有什么不⼀样吗
- Minor GC⼜称为新⽣代GC : 指的是发⽣在新⽣代的垃圾收集。因为Java对象⼤多都具备朝⽣夕灭 的特性,因此Minor GC(采⽤复制算法)⾮常频繁,⼀般回收速度也⽐较快。
- Full GC ⼜称为 ⽼年代GC或者Major GC : 指发⽣在⽼年代的垃圾收集。出现了Major GC,经常会伴 随⾄少⼀次的Minor GC(并⾮绝对,在Parallel Scavenge收集器中就有直接进⾏Full GC的策略选择 过程)。Major
GC的速度⼀般会⽐Minor GC慢10倍以上。