一 有状态计算
1.1 概念
1.状态;上一次计算的结果
2.需要基于上一个结果来进行计算,被称为有状态计算
1.2 未使用有状态计算
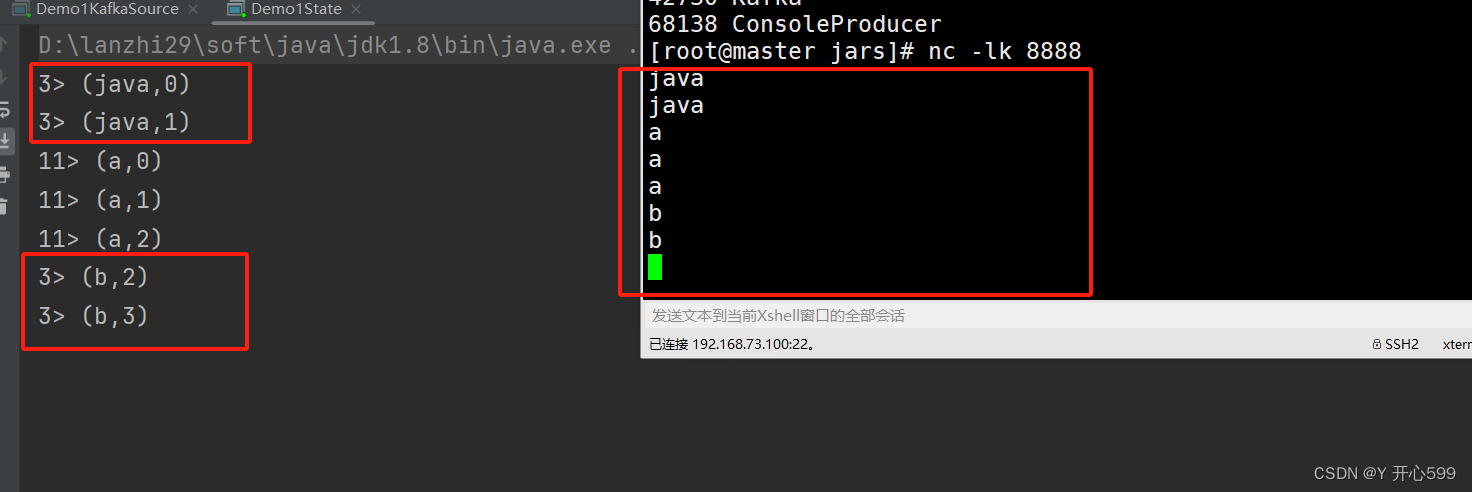
1.下面这个代码将相同的key发送到同一个task任务里面计算。就是因为这个导致了,明明之前没有输入b,但是输入b之后,立马变成了2个。说明他是将上一条计算结果直接拿来用了,没有考虑key是不是一样
2.process算子可以在kvDS上面直接进行操作,里面需要传入重写了KeyedProcessFunction里面的processElement方法的对象。
package com.shujia.flink.state;import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;public class Demo1State {public static void main(String[] args)throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> linesDS = env.socketTextStream("master", 8888);KeyedStream<String, String> keyByDS = linesDS.keyBy(word -> word);//KeyedProcessFunction<KEY, T, R> keyedProcessFunctionSingleOutputStreamOperator<Tuple2<String, Integer>> process = keyByDS.process(new KeyedProcessFunction<String, String, Tuple2<String, Integer>>() {int count = 0;/**** @param word 一行数据* @param ctx 上下文对象* @param out 用于将结果发送到下游**/@Overridepublic void processElement(String word,KeyedProcessFunction<String, String, Tuple2<String, Integer>>.Context ctx,Collector<Tuple2<String, Integer>> out) throws Exception {out.collect(Tuple2.of(word, count));count++;}});process.print();env.execute();}
}
1.3 使用有状态计算
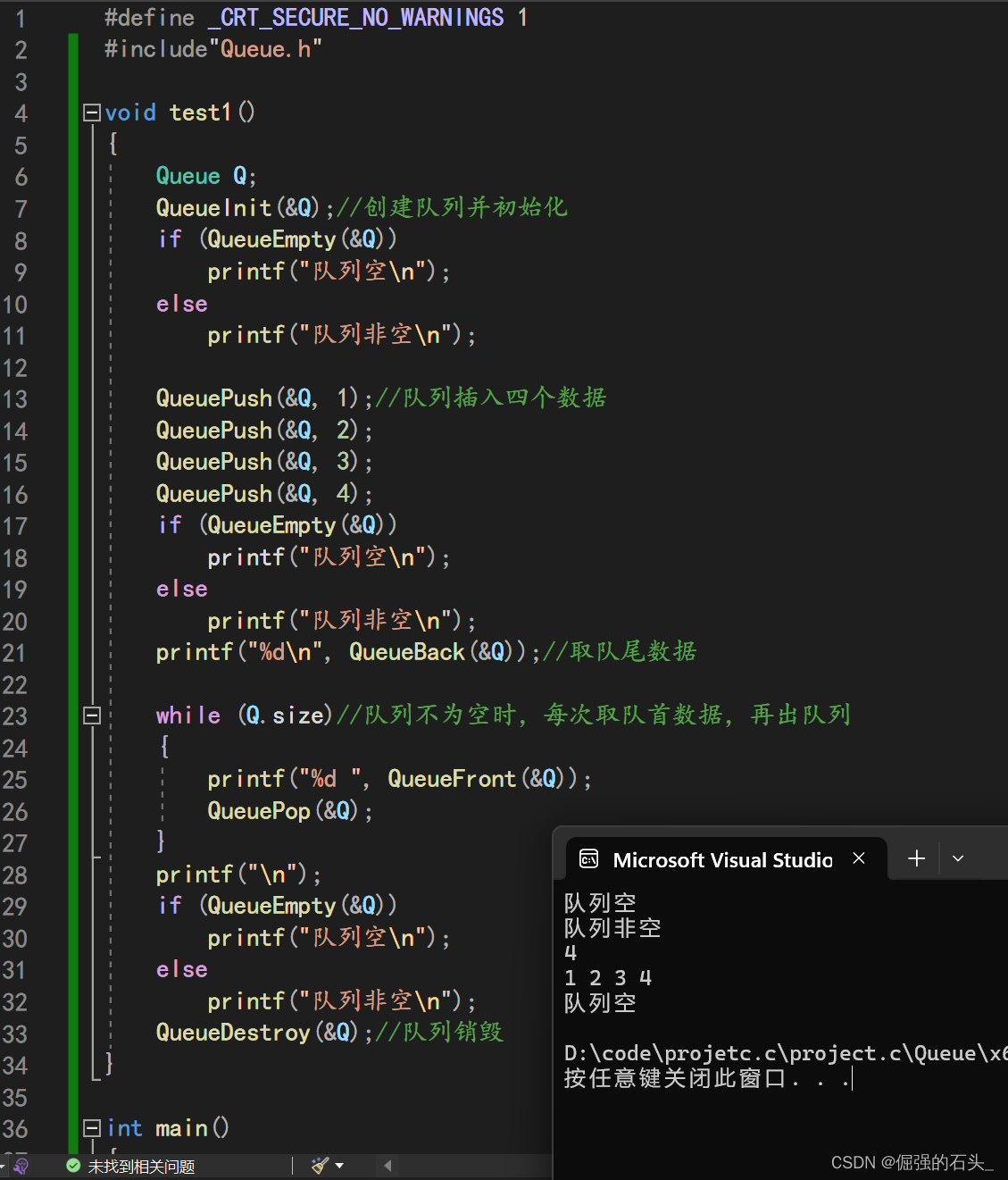
1.使用HashMap保存结果。
package com.shujia.flink.state;import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;import java.util.HashMap;public class Demo2State {public static void main(String[] args)throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> wordsDS = env.socketTextStream("master", 8888);//分组KeyedStream<String, String> keyByDS = wordsDS.keyBy(word -> word);/** process算子时flink提供的一个底层算子,可以获取到flink底层的状态,时间和数据*/DataStream<Tuple2<String, Integer>> countDS = keyByDS.process(new KeyedProcessFunction<String, String, Tuple2<String, Integer>>() {//保存之前统计的结果(状态)//问题:同一个task中的数据共享同一个count变量//int count = 0;//需要为每一个key保存一个结果//使用单词作为key,数量作为value//问题:使用hashmap保存计算的中间结果,flink的checkpoint不会将hashmap中的数据持久化到hdfs总//所以任务失败重启会丢失之前的结果final HashMap<String, Integer> map = new HashMap<>();/*** processElement方法每一条数据执行一次* @param word 一行数据* @param ctx 上下文对象,可以获取到flink的key和时间属性* @param out 用于将处理结果发送到下游*/@Overridepublic void processElement(String word,KeyedProcessFunction<String, String, Tuple2<String, Integer>>.Context ctx,Collector<Tuple2<String, Integer>> out) throws Exception {System.out.println(map);//1、通过key获取value//获取之前的结果(状态)Integer count = map.getOrDefault(word, 0);//基于之前的结果进行计算count++;//将计算结果发送到下游out.collect(Tuple2.of(word, count));//更新之前的结果map.put(word, count);}});countDS.print();env.execute();}
}
运行过后输入f,会提示之前没有数据,输入h,会提示有个f,因为是在同一个task里面,再输入一个f,会显示2个h一个f
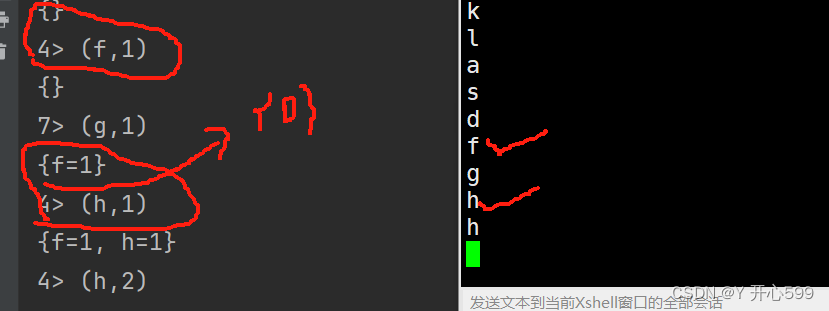
2.但是这些结果都不能持久化保存,想要持久化保存请看2.4节
二 checkpointing
2.1 概念
1.可以定时将flink计算的状态持久化到hdfs中,如果任务执行失败,可以基于hdfs中保存到的状态恢复任务,保证之前的结果不丢失。
2.2 设置
2.2.1 代码中设置
1.代码
flink计算的状态会先保存在taskmanager中,当触发checkpoint时会将状态持久化到hdfs中
// 每 1000ms 开始一次 checkpoint
env.enableCheckpointing(5000);
// 高级选项:
// 当手动取消任务时,是否保留HDFS中保留hdfs中的快照
env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//flink计算的状态会先保存在taskmanager中,当触发checkpoint时会将状态持久化到hdfs中
//指定状态在算子中保存的位置(状态后端)
//HashMapStateBackend:将状态保存在taskmanager的内存中
env.setStateBackend(new HashMapStateBackend());
//指定checkpoint保存快照的位置
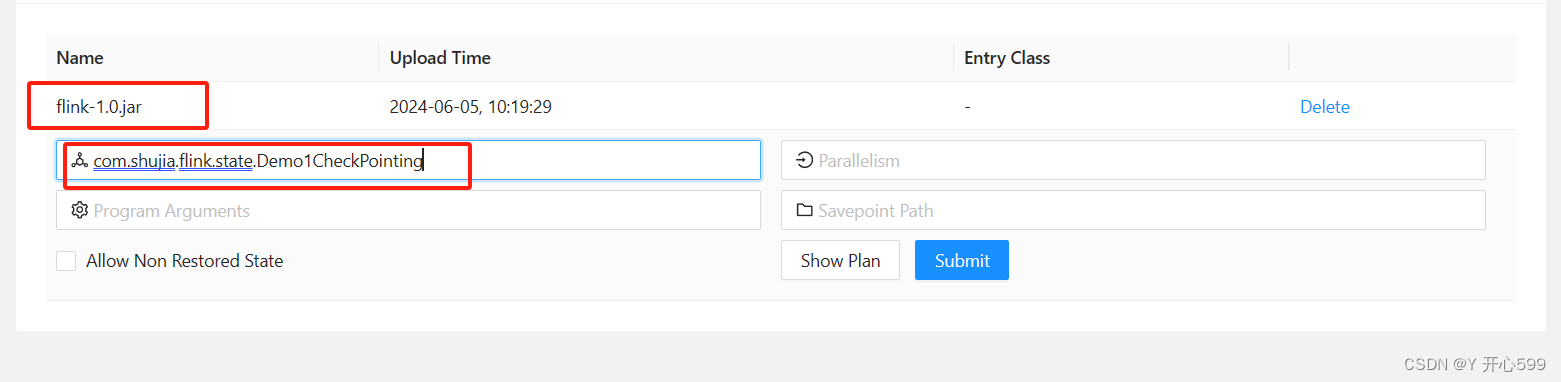
env.getCheckpointConfig().setCheckpointStorage("hdfs://master:9000/flink/checkpoint");1.ui界面第一次提交
提交jar包跟主类名即可
2.任务取消后,基于hdfs的快照重启任务
需要找到快照的位置,先在任务取消之前,查看任务id

再去hdfs上找到这个id相关的路径
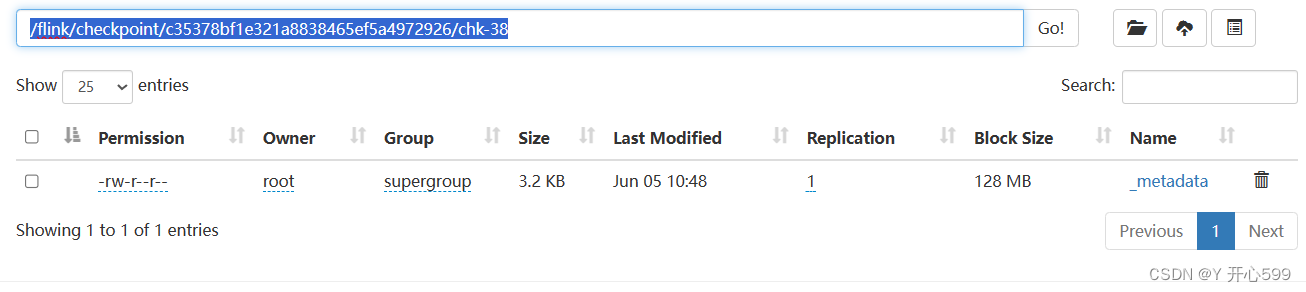
提交的时候加上hdfs://master:9000//然后后面跟上路径

3.命令行第一次提交
flink run -t yarn-session -p 3 -Dyarn.application.id=application_1717552958247_0001 -c com.shujia.flink.state.Demo1CheckPointing flink-1.0.jar
4.任务取消或者失败后重新提交
1.先在hdfs上找到相对应的任务编号,然后点到chk那边

2.输入命令
flink run -t yarn-session -p 3 -Dyarn.application.id=application_1717552958247_0001 -c com.shujia.flink.state.Demo1CheckPointing -s
hdfs://master:9000/flink/checkpoint/9f54421b62240b04fbde1bc413c98934/chk-2105 flink-1.0.jar
2.2.2 配置文件中设置
1.修改flink-conf.yaml,然后重启Hadoop
execution.checkpointing.interval: 5000
execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION
execution.checkpointing.max-concurrent-checkpoints: 1
execution.checkpointing.min-pause: 0
execution.checkpointing.mode: EXACTLY_ONCE
execution.checkpointing.timeout: 10min
execution.checkpointing.tolerable-failed-checkpoints: 0
execution.checkpointing.unaligned: false
state.backend: hashmap
state.checkpoints.dir: hdfs://master:9000/flink/checkpoint2.提交的方法跟上面一样
2.3 原理
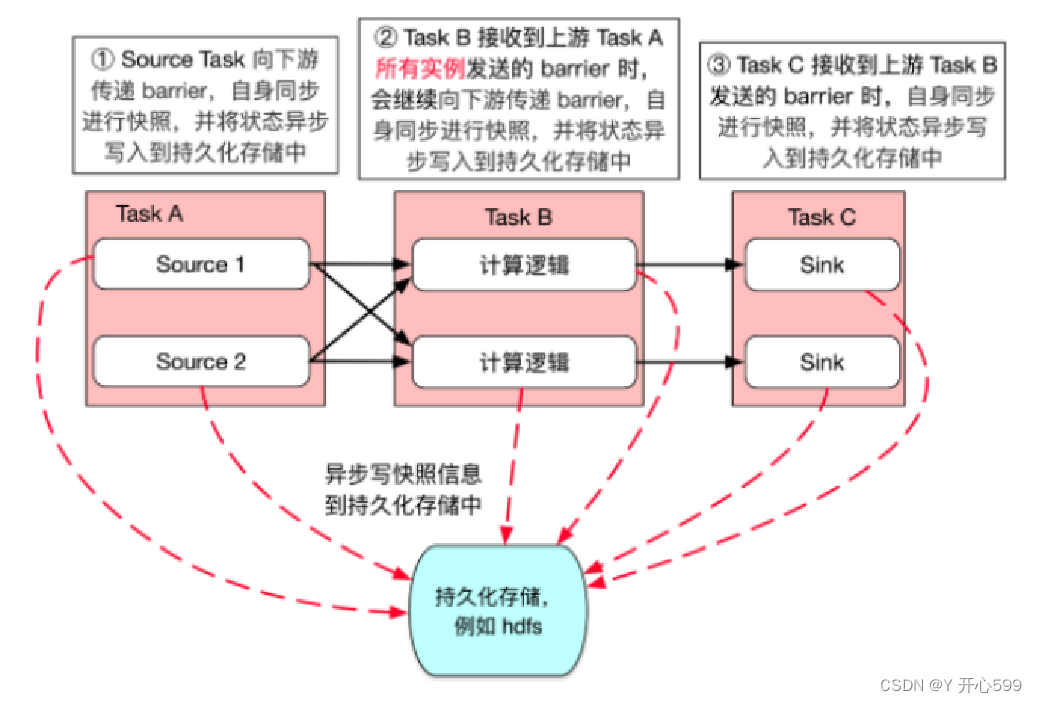
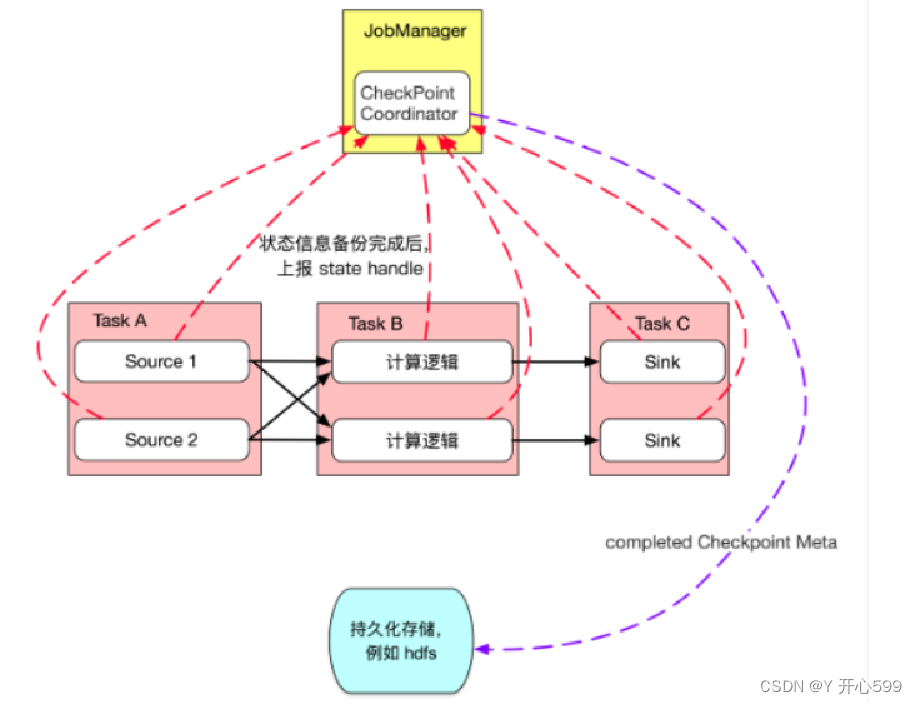
1.JobManager的checkpoint Coordonator(协调器)定期向SourceTask发送Checkpoint Trigger(触发器)。
2.SourceTask在数据流中安排Checkpoint barrier(障碍)
3.SourceTask向下游传递barrier,并自身同步进行快照并将状态写入持久化存储中。
4.整个Task完成后,会汇总最终的快照结果,并将之前的快照删除

2.4 checkpoint所识别的ValueState
1.因为1.3节使用Java自动HashMap不能被Flink识别,中间状态不能被持久化保留,所以我们要用flink自带的接口去接收中间状态
2.中间状态可以接收的接口
-
ValueState<T>: 保存一个可以更新和检索的值(如上所述,每个值都对应到当前的输入数据的 key,因此算子接收到的每个 key 都可能对应一个值)。 这个值可以通过update(T)进行更新,通过T value()进行检索。 -
ListState<T>: 保存一个元素的列表。可以往这个列表中追加数据,并在当前的列表上进行检索。可以通过add(T)或者addAll(List<T>)进行添加元素,通过Iterable<T> get()获得整个列表。还可以通过update(List<T>)覆盖当前的列表。 -
ReducingState<T>: 保存一个单值,表示添加到状态的所有值的聚合。接口与ListState类似,但使用add(T)增加元素,会使用提供的ReduceFunction进行聚合。 -
AggregatingState<IN, OUT>: 保留一个单值,表示添加到状态的所有值的聚合。和ReducingState相反的是, 聚合类型可能与 添加到状态的元素的类型不同。 接口与ListState类似,但使用add(IN)添加的元素会用指定的AggregateFunction进行聚合。 -
MapState<UK, UV>: 维护了一个映射列表。 你可以添加键值对到状态中,也可以获得反映当前所有映射的迭代器。使用put(UK,UV)或者putAll(Map<UK,UV>)添加映射。 使用get(UK)检索特定 key。 使用entries(),keys()和values()分别检索映射、键和值的可迭代视图。你还可以通过isEmpty()来判断是否包含任何键值对
3.我们使用ValueState,需要在底层算子process中,先重写open方法,用来创建状态接收对象。
ValueState<Integer> valueState;//open方法每一个task启动的时候执行一次,一般用于初始化@Overridepublic void open(Configuration parameters) throws Exception {//获取flink环境对象RuntimeContext runtimeContext = getRuntimeContext();//创建状态的描述对象。指定状态的类型和名称ValueStateDescriptor<Integer> valueStateDescriptor = new ValueStateDescriptor<>("count", Types.INT);//初始化状态//ValueState: 单值状态,为每一个key在状态中保存一个值valueState=runtimeContext.getState(valueStateDescriptor);}ValueState中的value方法是获取上一阶段的状态值,update是更新数据的。完整代码如下
package com.shujia.flink.state;import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;import java.util.HashMap;public class Demo4ValueState {public static void main(String[] args)throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> wordsDS = env.socketTextStream("master", 8888);//分组KeyedStream<String, String> keyByDS = wordsDS.keyBy(word -> word);/** process算子时flink提供的一个底层算子,可以获取到flink底层的状态,时间和数据*/DataStream<Tuple2<String, Integer>> countDS = keyByDS.process(new KeyedProcessFunction<String, String, Tuple2<String, Integer>>() {ValueState<Integer> valueState;//open方法每一个task启动的时候执行一次,一般用于初始化@Overridepublic void open(Configuration parameters) throws Exception {//获取flink环境对象RuntimeContext runtimeContext = getRuntimeContext();//创建状态的描述对象。指定状态的类型和名称ValueStateDescriptor<Integer> valueStateDescriptor = new ValueStateDescriptor<>("count", Types.INT);//初始化状态//ValueState: 单值状态,为每一个key在状态中保存一个值valueState=runtimeContext.getState(valueStateDescriptor);}/*** processElement方法每一条数据执行一次* @param word 一行数据* @param ctx 上下文对象,可以获取到flink的key和时间属性* @param out 用于将处理结果发送到下游*/@Overridepublic void processElement(String word,KeyedProcessFunction<String, String, Tuple2<String, Integer>>.Context ctx,Collector<Tuple2<String, Integer>> out) throws Exception {//获取状态中保存和值Integer count = valueState.value();//判断count是否为nullif (count==null){count=0;}//累加计算count++;//将结果发送到下游out.collect(Tuple2.of(word,count));//更新数据valueState.update(count);}});countDS.print();env.execute();}
}
这个是我第一次执行任务输入的

取消任务,看看能不能保存这个状态,然后提交重新提交任务,
发现还在
三 Exactly Once
3.1 生产端
1.kafka 0.11之后,Producer的send操作现在是幂等的,在任何导致producer重试的情况下,相同的消息,如果被producer发送多次,也只会被写入Kafka一次 ACKS机制+副本,保证数据不丢失

kafka保存数据处理的唯一一次:
幂等性:保持数据不重复
事务:保存数据不重复
ACKS+副本:保证数据不丢失
3.1.1 kafka事务
1.开启事务
package com.shujia.flink.state;import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;public class Demo6KafkaAffairs {public static void main(String[] args)throws Exception {Properties properties = new Properties();//指定broker列表properties.setProperty("bootstrap.servers", "master:9092,node2:9092,node2:9092");//指定key和value的数据格式properties.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");//给事务取一个名字properties.setProperty("transactional.id", "hhh");Producer<String, String> producer = new KafkaProducer<String, String>(properties);//开启事务producer.initTransactions();producer.beginTransaction();//ProducerRecord<K, V> recordproducer.send(new ProducerRecord<>("train","java"));Thread.sleep(10000);producer.send(new ProducerRecord<>("train","flink"));//提交事务producer.commitTransaction();producer.flush();producer.close();}
}
2.消费的命令记得使用读并提交。发现两条数据是一起过来的,如果中间有一条数据是失败的,那么整个数据都过不来,这样保证了数据不重复。
3.1.2 ACKS+副本
1.topic创建是需要多个副本
2.将acks设置成-1或者all。
acks机制:当acks=1时(默认),当主分区写入成功,就会返回成功。如果这个时候主分区所在的节点挂了,刚刚写入的数据就会丢失。当acks=0时,生产者只负责生产数据,不负责验证数据是否写入成功,会丢失数据,但是写入的性能好。当acks=-1或者all时,生产者生产数据后必须等到所有副本都同步成功才会返回成功,这样不会丢失数据,但是写入的性能差。
3.1.3 幂等性
Producer的send操作现在是幂等的,在任何导致producer重试的情况下,相同的消息,如果被producer发送多次,也只会被写入Kafka一次
3.2 消费端
1.Flink 分布式快照保存数据计算的状态和消费的偏移量,保证程序重启之后不丢失状态和消费偏移量
2.flink的数据源如果来自于socket,那么在发生checkpoint之前,有数据进去了并又取消了任务,那么这个数据没有写进hdfs。所以我们换数据源,换成Kafka的生产者产生的数据。这样checkpoint会定时将flink的计算状态和Kafka消费偏移量同时保存到hdfs中,这样不会丢失数据
package com.shujia.flink.state;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class Demo7ExactlyOnce {public static void main(String[] args) throws Exception{StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//创建kafka sourceKafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("master:9092,node1:9092,node2:9092")//kafka集群列表.setTopics("kafka_flink")//指定消费的topic.setGroupId("my-group")//指定消费者组.setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema())//指定读取数据的格式.build();//使用kafka sourceDataStream<String> wordsDS = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");//3、统计单词的数量DataStream<Tuple2<String, Integer>> kvDS = wordsDS.map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT));//分组统计单词的数量KeyedStream<Tuple2<String, Integer>, String> keyByDS = kvDS.keyBy(kv -> kv.f0);//对下标为1的列求和DataStream<Tuple2<String, Integer>> countDS = keyByDS.sum(1);//打印数据countDS.print();//启动flinkenv.execute();}
}
3.3 sink端
1.flink在聚合计算后将结果写进hdfs或者kafka中,如果在中间某一个时间有数据进去但是任务又取消或者失败了,但是这样结果不会重复。然而,在非聚合计算中,如果在中间某一个时间有数据进去但是任务又取消或者失败了,这样kafka或者hdfs中数据会重复
package com.shujia.flink.state;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.Properties;public class Demo8ExactlyOnceKafkaSink {public static void main(String[] args)throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//创建kafka sourceKafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("master:9092,node1:9092,node2:9092")//kafka集群列表.setTopics("kafka_flink")//指定消费的topic.setGroupId("my-group")//指定消费者组.setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema())//指定读取数据的格式.build();//使用kafka sourceDataStream<String> wordsDS = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");DataStream<String> filterDS = wordsDS.filter(word -> !"".equals(word));// Properties properties = new Properties();//指定事务超时时间,不能大于15分钟
// properties.setProperty("transaction.timeout.ms", 1000 * 60 * 10 + "");//创建kafka sinkKafkaSink<String> sink = KafkaSink.<String>builder().setBootstrapServers("master:9092,node1:9092,node2:9092")//kafka集群列表
// .setKafkaProducerConfig(properties).setRecordSerializer(KafkaRecordSerializationSchema.builder().setTopic("filter")//指定topic.setValueSerializationSchema(new SimpleStringSchema())//指定数据格式.build())//指定数据处理的语义.setDeliverGuarantee(DeliveryGuarantee.AT_LEAST_ONCE).build();//使用kafka sinkfilterDS.sinkTo(sink);//启动flinkenv.execute();}
}
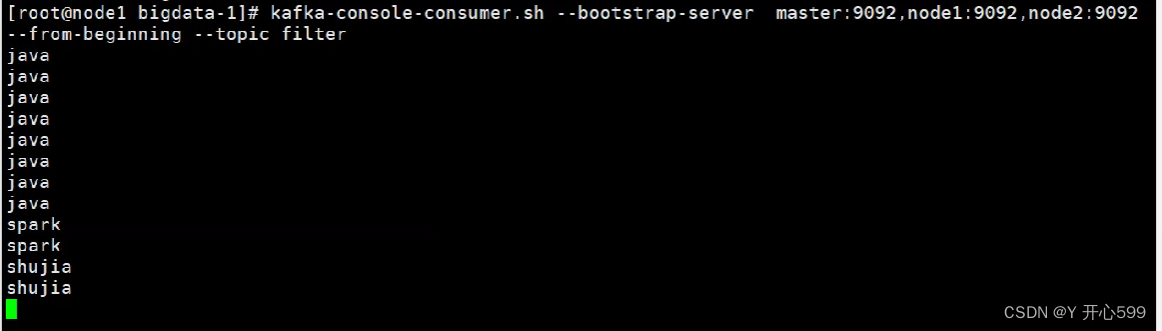
提交这个任务代码,执行一次后,再他执行checkpoint之前再次输入shujiashujia,取消任务,然后再通过上一次的checkpoint重启任务,发现:消费端居然消费了两次shujiashujia
生产端:

消费端:
2.为了避免在非聚合计算中,状态或者消费的偏移量存储到kafka或者hdfs中,数据不重复,我们需要开启 Kafka事务。代码如下
package com.shujia.flink.state;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.Properties;public class Demo8ExactlyOnceKafkaSink {public static void main(String[] args)throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//创建kafka sourceKafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("master:9092,node1:9092,node2:9092")//kafka集群列表.setTopics("kafka_flink")//指定消费的topic.setGroupId("my-group")//指定消费者组.setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema())//指定读取数据的格式.build();//使用kafka sourceDataStream<String> wordsDS = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");DataStream<String> filterDS = wordsDS.filter(word -> !"".equals(word));Properties properties = new Properties();//指定事务超时时间,不能大于15分钟properties.setProperty("transaction.timeout.ms", 1000 * 60 * 10 + "");//创建kafka sinkKafkaSink<String> sink = KafkaSink.<String>builder().setBootstrapServers("master:9092,node1:9092,node2:9092")//kafka集群列表.setKafkaProducerConfig(properties).setRecordSerializer(KafkaRecordSerializationSchema.builder().setTopic("filter")//指定topic.setValueSerializationSchema(new SimpleStringSchema())//指定数据格式.build())//指定数据处理的语义.setDeliverGuarantee(DeliveryGuarantee.EXACTLY_ONCE).build();//使用kafka sinkfilterDS.sinkTo(sink);//启动flinkenv.execute();}
}
这样我们在生产端产生数据,只有产生checkpoint,才会消费数据(消费端使用读并提交的方式)
但是这样会增加数据延迟