前言:
本篇文章仅用于个人学习笔记,仅限于参考,内容如有侵权,请联系删除,谢谢!
一:大数据简介
大数据概念 :
指无法在一定时间范围内用常规软件工具进行捕管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、捉、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
大数据主要解决,海量数据的采集、存储和分析计算问题。
按顺序给出数据存储单位: bit、 Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB.
1Byte = 8bit 1K = 1024Byte 1MB = 1024K 1G = 1024M 1T = 1024G1P = 1024T
大数据特点:
1、Volume ( 大量)
截至目前,人类生产的所有印刷材料的数据量是200PB,而历史上全人类总共说过的话的数据量大约是5EB。当前,典型个人计算机硬盘的容量为TB量级,而些大企业的数据量已经接近EB量级。
2、Velocity (高速 )
这是大数据区分于传统数据挖掘的最显著特征。根据IDC的“数字宇宙”的报告,预计到2025年,全球数据使用量将达到163ZB。在如此海量的数据面前,处理数据的效率就是企业的生命。
3、Variety (多样)
这种类型的多样性也让数据被分为结构化数据和非结构化数据。相对于以往便于存储的以数据库/文本为主的结构化数据,非结构化数据越来越多,包括网络日志、音频、视频、图片、地理位置信息等,这些多类型的数据对数据的处理能力提出了更高要求
4、Value ( 低价值密度 )
价值密度的高低与数据总量的大小成反比比如,在一天监控视频中,我们只关心宋宋老师晚上在床上健身那一分钟,如何快速对有价值数据“提纯”成为目前大数据背景下待解决的难题
大数据应用场景:
1、抖音:推荐的都是你喜欢的视频
2、电商站内广告推荐:给用户推荐可能喜欢的商品
3、零售:分析用户消费习惯,为用户购买商品提供方便,从而提升商品销量
4、物流仓储: 京东物流,上午下单下午送达、下午下单次日上午送达
5、保险: 海量数据挖掘及风险预测,助力保险行业精准营销,提升精细化定价能力。
6、金融: 多维度体现用户特征,帮助金融机构推荐优质客户,防范欺诈风险
7、房产:大数据全面助力房地产行业,打造精准投策与营销,选出更合适的地,建造更合适的楼卖给更合适的人。
8、人工智能 + 5G + 物联网 + 虚拟与现实
二:hadoop入门:
hadoop概述:
1) Hadoop是一个由Apache基金会所开发的分布式系统基础架构
2)主要解决,海量数据的存储和海量数据的分析计算问题
3)广义上来说,Hadoop通常是指一个更广泛的概念-Hadoop生态圈
hadoop的优势:
1)高可靠性: Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
2)高扩展性:在集群间分配任务数据,可方便的扩展数以干计的节点
3)高效性: 在MapReduce的思想下,Hadoop是并行工作的,以加快任务处
理速度。
4)高容错性: 能够自动将失败的任务重新分配
hadoop三大版本区别:
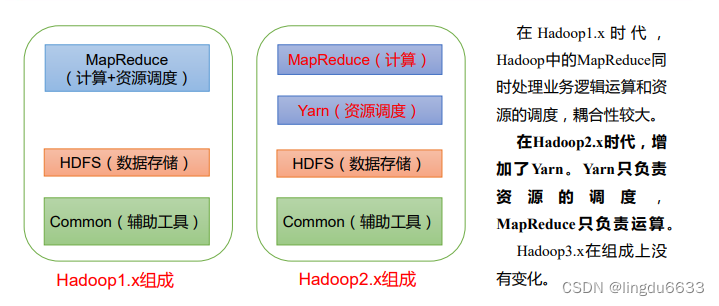
HDFS概述:
Hadoop Distributed File System,简称 HDFS,是一个分布式文件系统。
1)NameNode ( mn ):存储文件的元数据,如文件名,文件目录结构,文件属性( 生成时间、副本数文件权限),以及每个文件的块列表和块所在的DataNode等。
2)DataNode(dn): 在本地文件系统存储文件块数据,以及块数据的校验和。
3)Secondary NameNode(2nn): 每隔一段时间对NameNode元数据备份。
YARN概述:
YetAnother Resource Negotiator 简称 YARN,另一种资源协调者,是 Hadoop 的资源管理器。
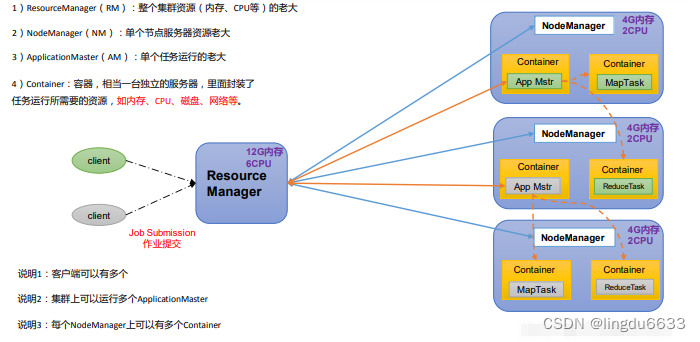
MapReduce概述:
MapReduce 将计算过程分为两个阶段: Map 和 Reduce
1) Map 阶段并行处理输入数据
2) Reduce 阶段对 Map 结果进行汇总
hadoop安装,环境搭建:
请参考另一篇博客:写文章-CSDN创作中心![]() https://mp.csdn.net/mp_blog/creation/editor/131597332,该文章记录了hadoop安装所需的环境,工具准备,网络配置等。(首先需要安装VMware,之后安装LInux系统,复制虚拟机三台形成一个集群,之后配置静态IP,保证三台机器可以正常通信。)
https://mp.csdn.net/mp_blog/creation/editor/131597332,该文章记录了hadoop安装所需的环境,工具准备,网络配置等。(首先需要安装VMware,之后安装LInux系统,复制虚拟机三台形成一个集群,之后配置静态IP,保证三台机器可以正常通信。)
CSDN
hadoop_hdfs详细介绍:
hdfs产生背景:
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS 只是分布式文件管理系统中的一种。
HDFS定义:
HDFS (Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件:其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS 的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭 之后就不需要改变。
HDFS优缺点:
优点:

缺点:

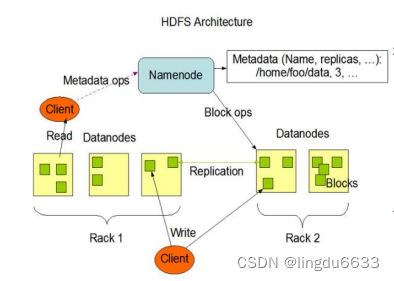
HDFS组成架构:
NameNode(nn):
就是Master,它 是一个主管、管理者。
(1)管理HDFS的名称空间;
(2)配置副本策略;
(3)管理数据块(Block)映射信息;
(4)处理客户端读写请求。
DataNode:
就是Slave。NameNode 下达命令,DataNode执行实际的操作。
(1)存储实际的数据块; (2)执行数据块的读/写操作。
Client:就是客户端
(1)文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传;
(2)与NameNode交互,获取文件的位置信息;
(3)与DataNode交互,读取或者写入数据;
(4)Client提供一些命令来管理HDFS,比如NameNode格式化;
(5)Client可以通过一些命令来访问HDFS,比如对HDFS增删查改操作;
Secondary NameNode:
并非NameNode的热备。当NameNode挂掉的时候,它并不 能马上替换NameNode并提供服务。 (1)辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode ; (2)在紧急情况下,可辅助恢复NameNode。
关系内容如下:
HDFS文件块大小:
HDFS中的文件在物理上是分块存储(Block),块的大小可以通过配置参数 ( dfs.blocksize)来规定,默认大小在Hadoop2.x/3.x版本中是128M,1.x版本中是64M。
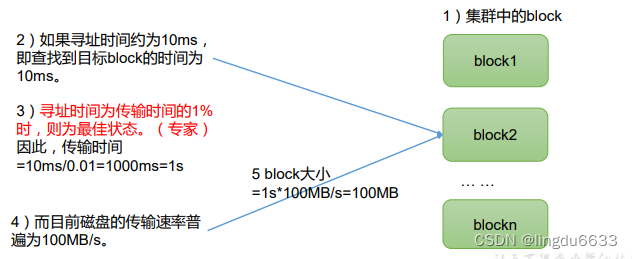
思考:为什么块的大小不能设置太小,也不能设置太大
(1)HDFS的块设置太小,会增加寻址时间,程序一直在找块的开始位置;
(2)如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开 始位置所需的时间。导致程序在处理这块数据时,会非常慢。
总结:HDFS块的大小设置主要取决于磁盘传输速率。
HDFS_shell操作(文件上传,下载):
准备工作先把hadoop集群起来:(集群搭建请参考上面链接)
在hadoop2上:
sbin/start-dfs.sh
sbin/stop-dfs.sh
hadoop fs -mkdir /wcinput hdfs上根目录下创建文件夹
上传文件到hdfs上:
hadoop fs -put wcinput/word.txt /wcinput 上传本地文件到hdfs上面
hadoop fs -moveFromLocal ./suguo.txt /sanguo 从本地剪切粘贴到 HDFS,本地会消失
hadoop fs -copyFromLocal b.txt /shanguo 从本地文件系统中拷贝文件到 HDFS 路径去,本地还在
hadoop fs -put c.txt /shanguo 等同于 copyFromLocal,生产环境更习惯用 put,本地还在
hadoop fs -appendToFile a1.txt /shanguo/a.txt 追加一个文件到已经存在的文件末尾
HDFS下载文件到本地:
-copyToLocal:从 HDFS 拷贝到本地
Hadoop fs -copyToLocal /shanguo/a.txt ./
-get:等同于 copyToLocal,生产环境更习惯用 get
Hadoop fs -get /shanguo/a.txt ./a2.txt 这里可以改名字
HDFS的直接命令:
1)-ls 显示目录信息
hadoop fs -ls /sanguo
2)-cat 显示文件内容
hadoop fs -cat /sanguo/a.txt
3)-chgrp、-chmod、-chown:Linux 文件系统中的用法一样,修改文件所属权限
hadoop fs -chmod 666 /sanguo/shuguo.txt
hadoop fs -chown atguigu:atguigu /sanguo/shuguo.txt
4)-mkdir:创建路径
hadoop fs -mkdir /jinguo
5)-cp:从 HDFS 的一个路径拷贝到 HDFS 的另一个路径
hadoop fs -cp /sanguo/shuguo.txt /jinguo
6)-mv:在 HDFS 目录中移动文件
hadoop fs -mv /sanguo/wuguo.txt /jinguo
7)-tail:显示一个文件的末尾 1kb 的数据
hadoop fs -tail /jinguo/shuguo.txt
8)-rm:删除文件或文件夹
hadoop fs -rm /sanguo/shuguo.txt
9)-rm -r:递归删除目录及目录里面内容
hadoop fs -rm -r /sanguo
10)-du 统计文件夹的大小信息
hadoop fs -du -s -h /jinguo
hadoop fs -du -h /jinguo
11)-setrep:设置 HDFS 中文件的副本数量
hadoop fs -setrep 10 /jinguo/shuguo.txt
这里设置的副本数只是记录在 NameNode 的元数据中,是否真的会有这么多副本,还得 看 DataNode 的数量。因为目前只有 3 台设备,最多也就 3 个副本,只有节点数的增加到 10 台时,副本数才能达到 10。
hdfs_api操作:这里不再记录需要的话回顾视频。p46
HDFS的读写流程:
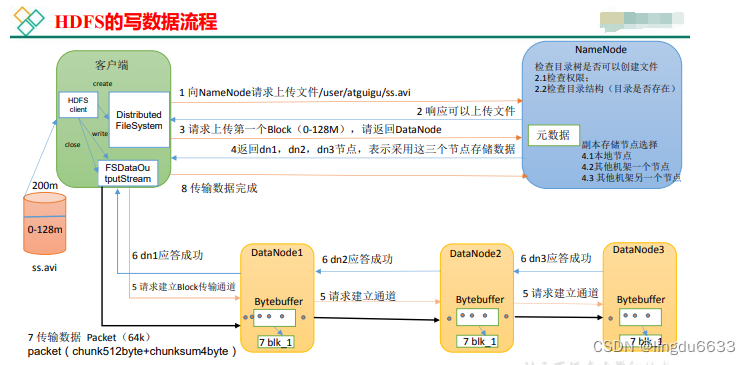
1)客户端通过DistributedFileSystem模块向Name Node请求上传文件,Name Node检查目录文件是否已经存在,父目录是否存在。
2)Name Node返回是否可以上传。
3)客户端请求第一个Block上传到哪几个DATANode服务器上
4)Namenode返回3个DATa Node节点,分别为dn1,dn2,dn3。
5)客户端通过FSDataOutputStream模块请求往dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
6)dn1,dn2,dn3逐级应答客户端。
7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
8)当一个Block传输完成之后,客户端再次请求Name Node上传第二个Block的服务器。(重复执行3-7步)。
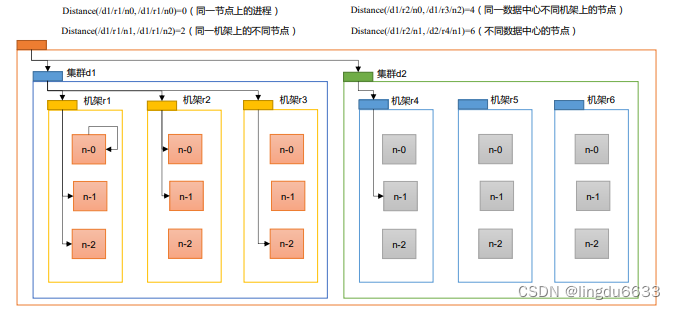
网络拓扑-节点距离计算
在 HDFS 写数据的过程中,NameNode 会选择距离待上传数据最近距离的 DataNode 接 收数据。那么这个最近距离怎么计算呢?
节点距离:两个节点到达最近的共同祖先的距离总和。
HDFS读数据流程:
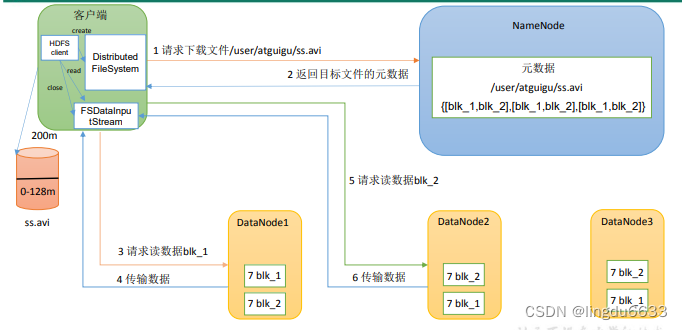
1)客户端通过Distributed File System向Name Node请求下载文件,Name Node通过查询元数据,找到文件块所在的DATa Node地址。
2)挑选一台DATa Node(就近原则,然后随机)服务器,请求读取数据。
3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
4)客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
NameNode 和 SecondaryNameNode
NN 和 2NN 工作机制:
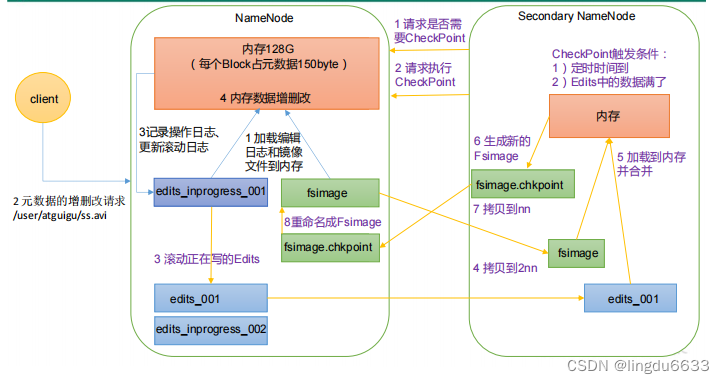
1)第一阶段:NameNode 启动
Fsimage 和 Edits 解析
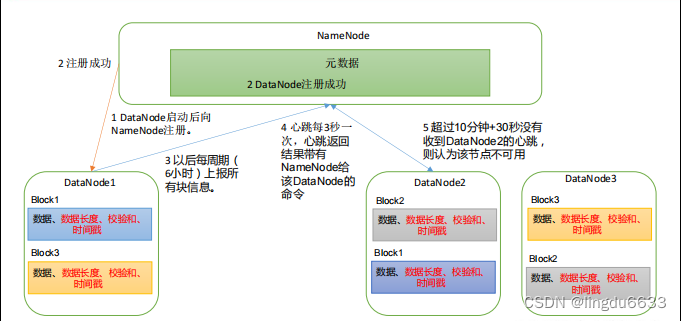
数据完整性:
hadoop_MapReduce:
MR的优缺点:
优点:
缺点:
MapReduce 核心思想:
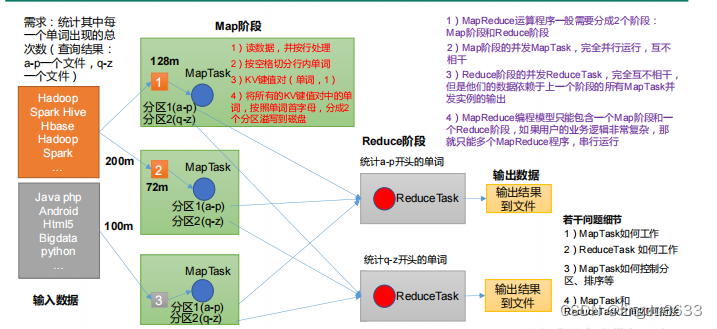
MapReduce 进程:
一个完整的 MapReduce 程序在分布式运行时有三类实例进程:
Mapper阶段:
Reducer阶段 :
Driver阶段

Hadoop 序列化


MapReduce 框架原理

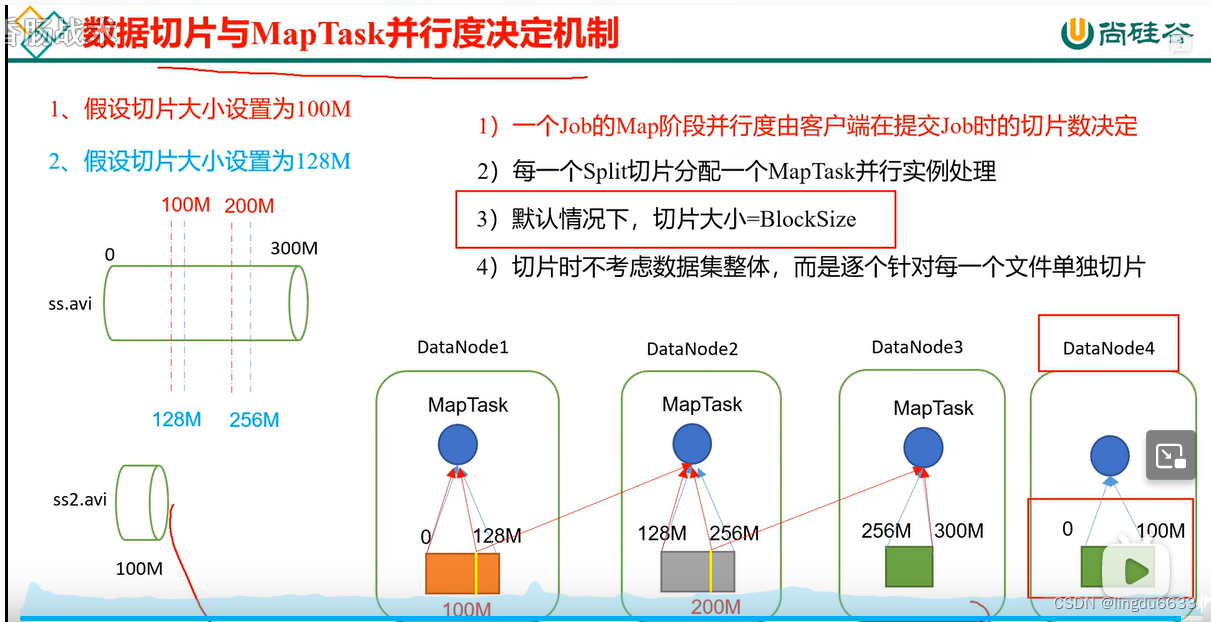


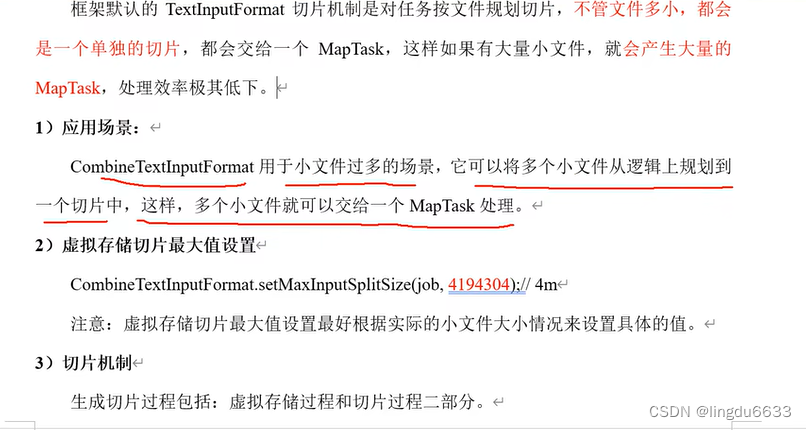
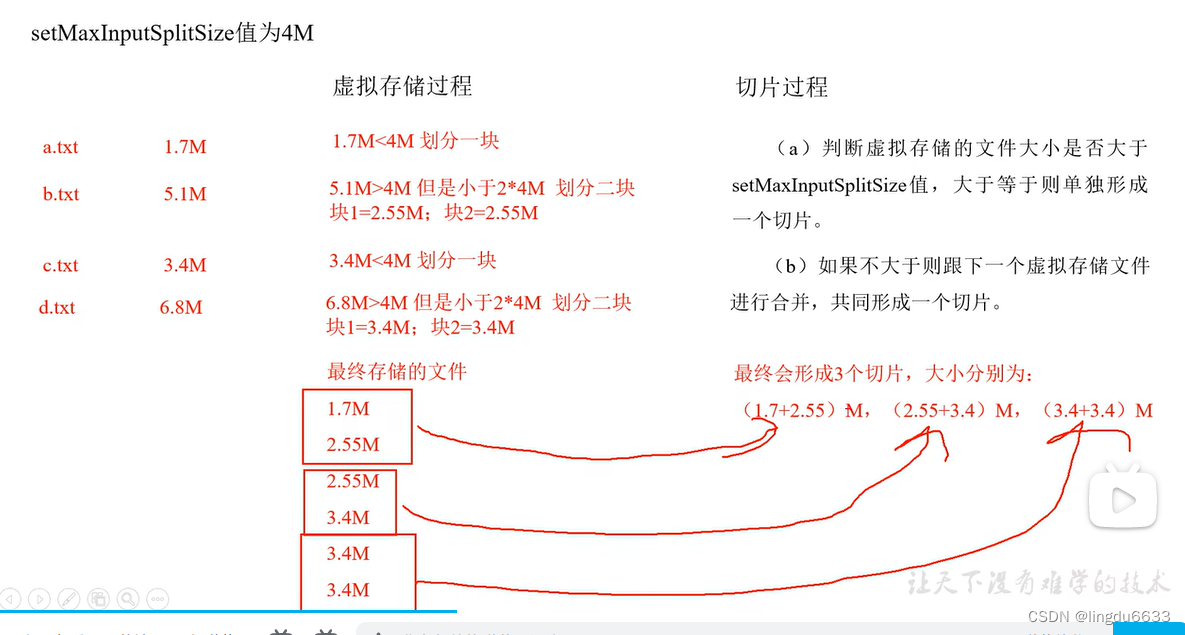

多文件合并切片见P93.



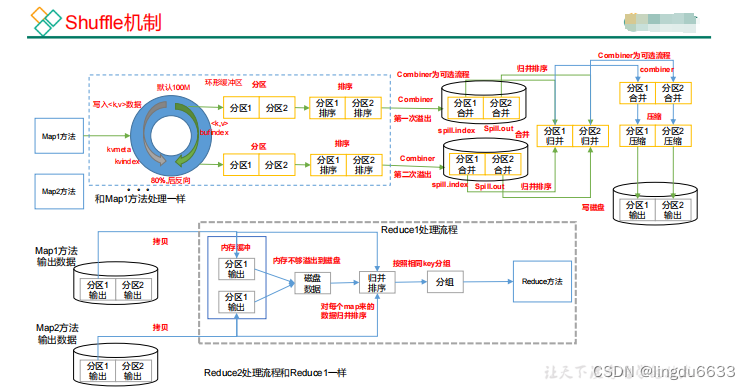
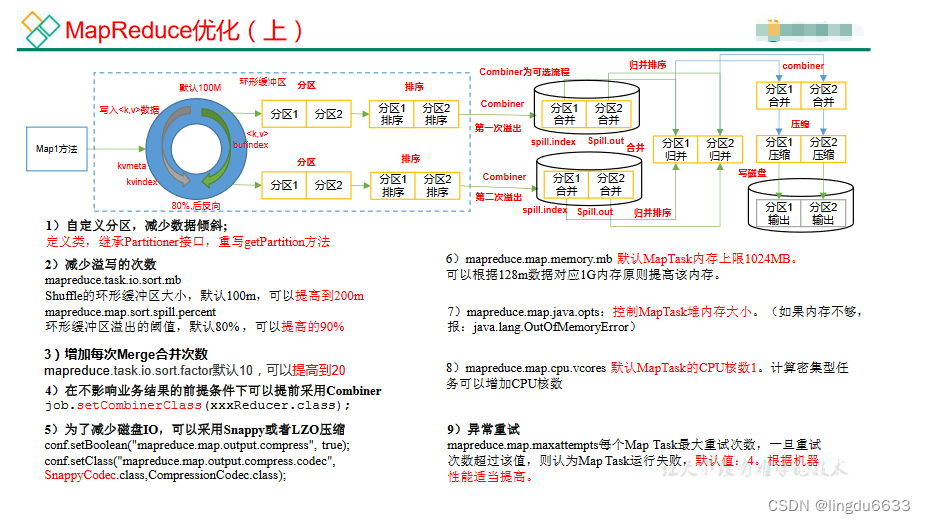
排序:
排序是MapReduce框架中最重要的操作之一。
MapTask和ReduceTask均会对数据按照key进行排序。该操作属于Hadoop的默认行为。个任何应用程序中的数据均会被排序,而不管逻辑上是否需要。
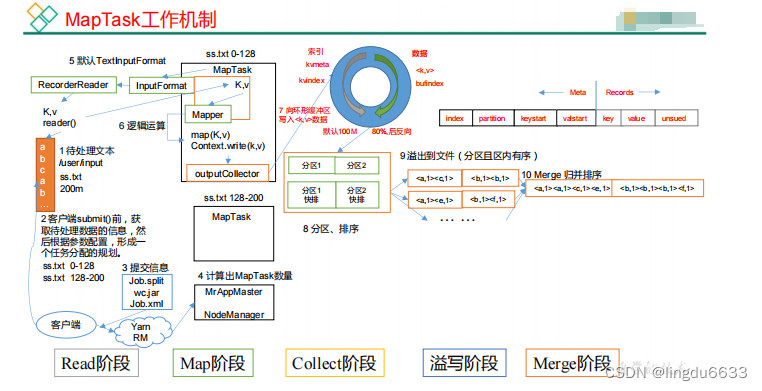
默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
对于MapTask,它会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次快速排序,并将这些有序数据溢写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行归并排序。
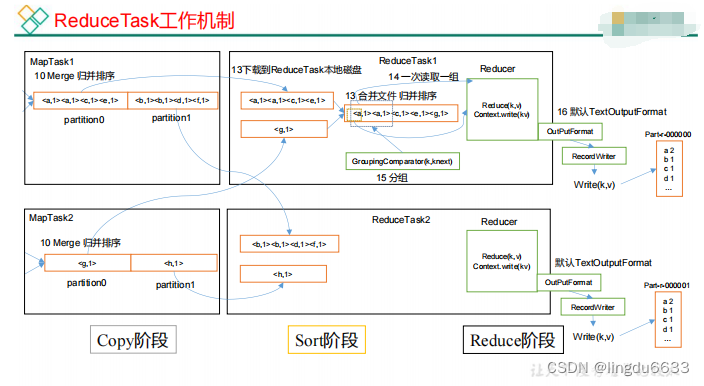
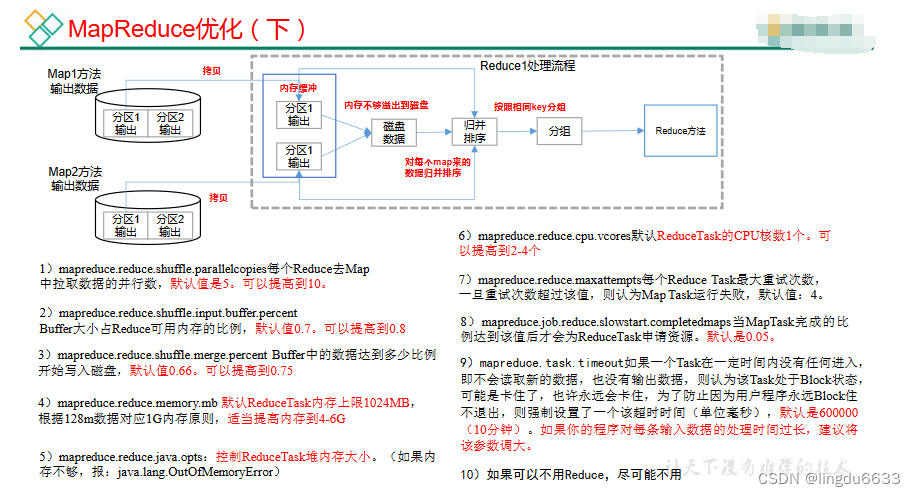
对于ReduceTask,它从每个MapTask上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则溢写磁盘上,否则存储在内存中。如果磁盘上文件数目达到一定阈值,则进行一次归并排序以生成一个更大文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据溢写到磁盘上。当所有数据拷贝完毕后,ReduceTask统一对内存和磁盘上的所有数据进行一次归并排序,


MapReduce 工作流程:
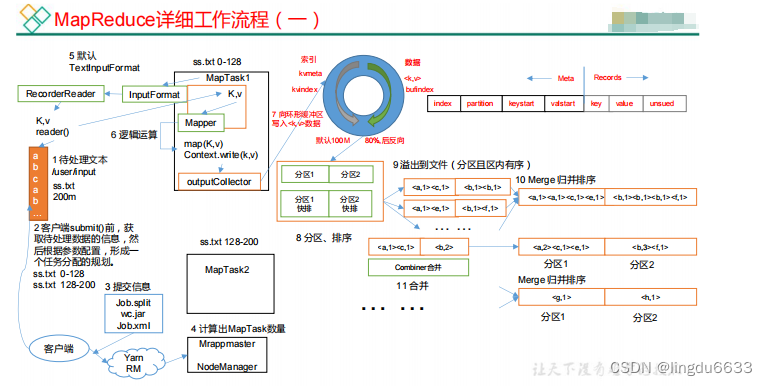
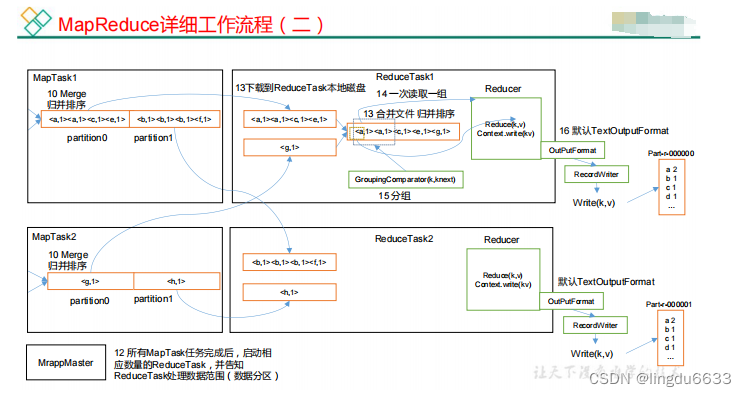
Shuffle 机制
MapTask 工作机制:
输出类:

ReduceTask 工作机制:
debug调试P77。
分区案例请查看P96。
ReduceTask 并行度决定机制:
Join 应用:
节点的运算负载则很低,资源利用率不高,且在 Reduce 阶段极易产生数据倾斜。
解决方案:Map 端实现数据合并。
Map Join:
(1)在 Mapper 的 setup 阶段,将文件读取到缓存集合中。
(2)在 Driver 驱动类中加载缓存。
//缓存普通文件到 Task 运行节点。
job.addCacheFile(new URI("file:///e:/cache/pd.txt"));
//如果是集群运行,需要设置 HDFS 路径
job.addCacheFile(new URI("hdfs://hadoop102:8020/cache/pd.txt"));

数据清洗:
(Extract)、转换(Transform)、加载(Load)至目的端的过程。ETL 一词较常用在数据仓
库,但其对象并不限于数据仓库
在运行核心业务 MapReduce 程序之前,往往要先对数据进行清洗,清理掉不符合用户
要求的数据。 清理的过程往往只需要运行 Mapper 程序,不需要运行 Reduce 程序。
正则表达式P121章节有记录。
MapReduce 开发总结:
1)输入数据接口:InputFormat
(1)默认使用的实现类是:TextInputFormat
(2)TextInputFormat 的功能逻辑是:一次读一行文本,然后将该行的起始偏移量作为
key,行内容作为 value 返回。
(3)CombineTextInputFormat 可以把多个小文件合并成一个切片处理,提高处理效率。
2)逻辑处理接口:Mapper
用户根据业务需求实现其中三个方法:map() setup() cleanup ()
3)Partitioner 分区
(1)有默认实现 HashPartitioner,逻辑是根据 key 的哈希值和 numReduces 来返回一个
分区号;key.hashCode()&Integer.MAXVALUE % numReduces
(2)如果业务上有特别的需求,可以自定义分区。
4)Comparable 排序
(1)当我们用自定义的对象作为 key 来输出时,就必须要实现 WritableComparable 接
口,重写其中的 compareTo()方法。
(2)部分排序:对最终输出的每一个文件进行内部排序。
(3)全排序:对所有数据进行排序,通常只有一个 Reduce。
(4)二次排序:排序的条件有两个。
5)Combiner 合并
Combiner 合并可以提高程序执行效率,减少 IO 传输。但是使用时必须不能影响原有的
业务处理结果。
6)逻辑处理接口:Reducer
用户根据业务需求实现其中三个方法:reduce() setup() cleanup ()
7)输出数据接口:OutputFormat
(1)默认实现类是 TextOutputFormat,功能逻辑是:将每一个 KV 对,向目标文本文件
输出一行。
(2)用户还可以自定义 OutputFormat。
Yarn 资源调度器:
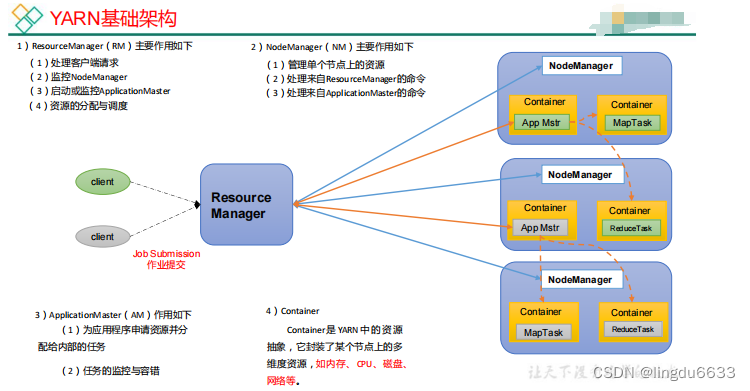
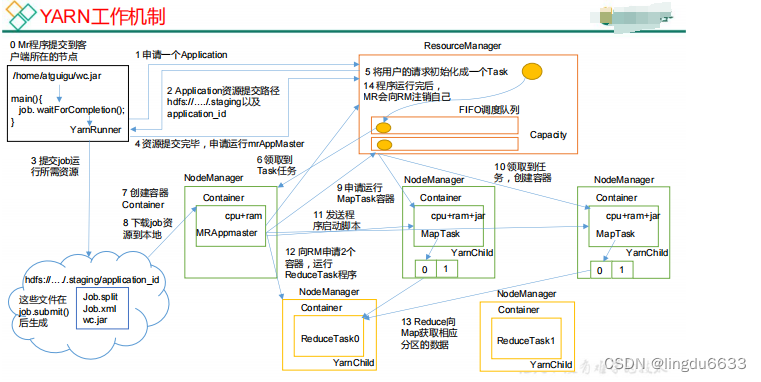
yarn 工作机制:
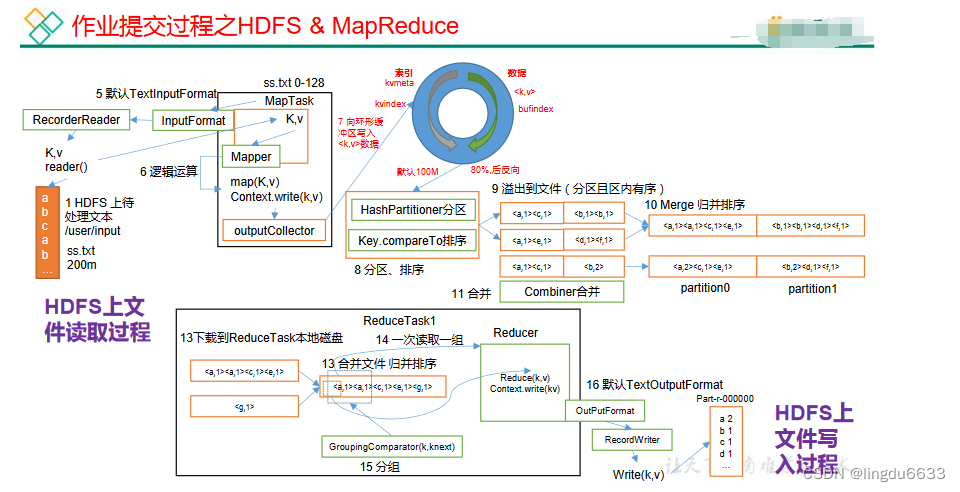
作业提交全过程详解
第 1 步:Client 调用 job.waitForCompletion 方法,向整个集群提交 MapReduce 作业。
第 2 步:Client 向 RM 申请一个作业 id。
第 3 步:RM 给 Client 返回该 job 资源的提交路径和作业 id。
第 4 步:Client 提交 jar 包、切片信息和配置文件到指定的资源提交路径。
第 5 步:Client 提交完资源后,向 RM 申请运行 MrAppMaster。
(2)作业初始化
第 6 步:当 RM 收到 Client 的请求后,将该 job 添加到容量调度器中。
第 8 步:该 NM 创建 Container,并产生 MRAppmaster。
第 9 步:下载 Client 提交的资源到本地。
(3)任务分配
第 10 步:MrAppMaster 向 RM 申请运行多个 MapTask 任务资源。
第 11 步:RM 将运行 MapTask 任务分配给另外两个 NodeManager,另两个 NodeManager
分别领取任务并创建容器。
(4)任务运行
第 12 步 : MR 向两个接收到任 务的 NodeManager 发 送 程序启动 脚本 , 这两 个
NodeManager 分别启动 MapTask,MapTask 对数据分区排序。
第 13 步:MrAppMaster 等待所有 MapTask 运行完毕后,向 RM 申请容器,运行 ReduceTask。
第 14 步:ReduceTask 向 MapTask 获取相应分区的数据。
第 15 步:程序运行完毕后,MR 会向 RM 申请注销自己。
(5)进度和状态更新
YARN 中的任务将其进度和状态(包括 counter)返回给应用管理器, 客户端每秒(通过
mapreduce.client.progressmonitor.pollinterval 设置)向应用管理器请求进度更新, 展示给用户。
(6)作业完成
除了向应用管理器请求作业进度外, 客户端每 5 秒都会通过调用 waitForCompletion()来
检查作业是否完成。时间间隔可以通过 mapreduce.client.completion.pollinterval 来设置。作业
完成之后, 应用管理器和 Container 会清理工作状态。作业的信息会被作业历史服务器存储
以备之后用户核查。
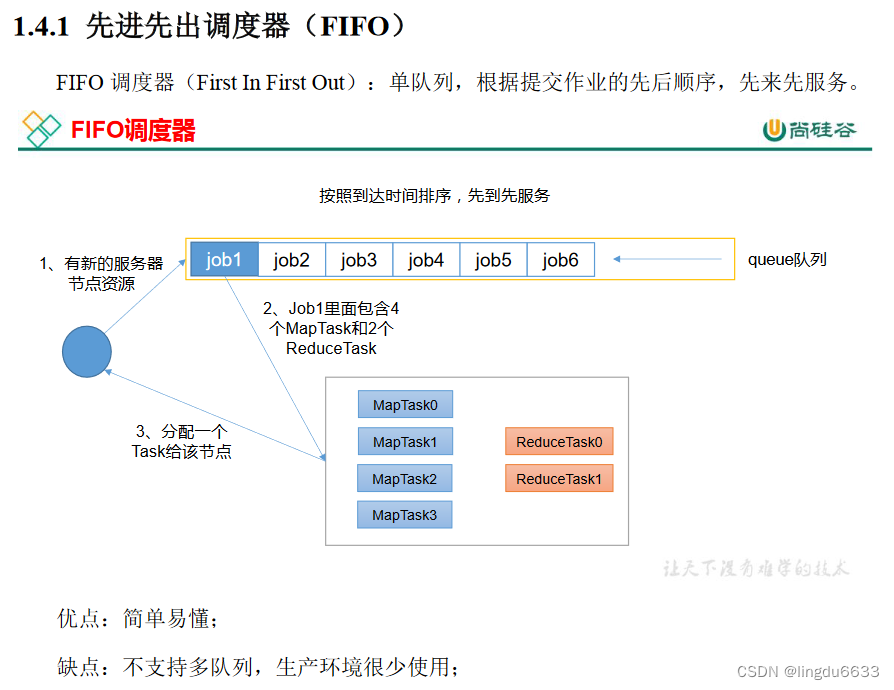
Hadoop调度器:
Scheduler)。Apache Hadoop3.1.3 默认的资源调度器是 Capacity Scheduler。
CDH 框架默认调度器是 Fair Scheduler。

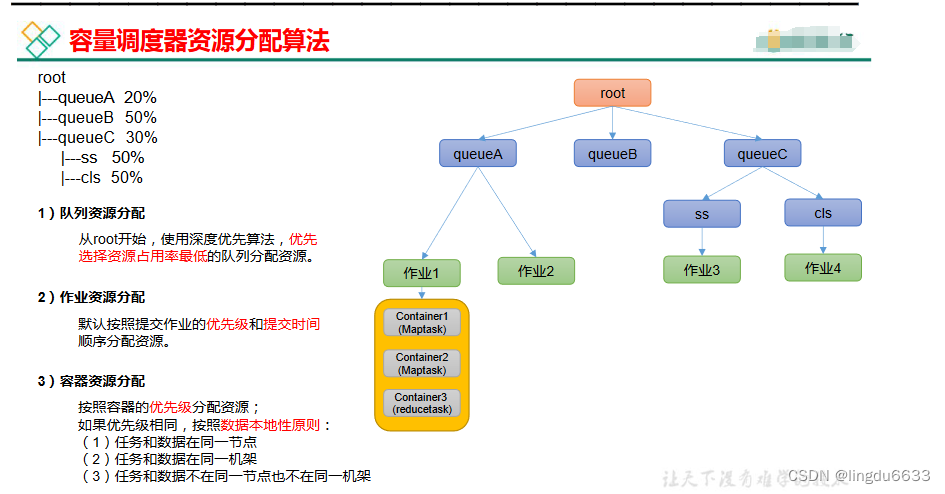
yarn总结:

HDFS存储优化:
纠删码策略
异构存储,冷热分离

HDFS 故障排除:
集群迁移:
mapreduce生产经验:
散。最后再二次聚合。
(2)能在 map 阶段提前处理,最好先在 Map 阶段处理。如:Combiner、MapJoin
(3)设置多个 reduce 个数