论文链接:https://arxiv.org/abs/2405.17414
项目链接:https://collaborativevideodiffusion.github.io/
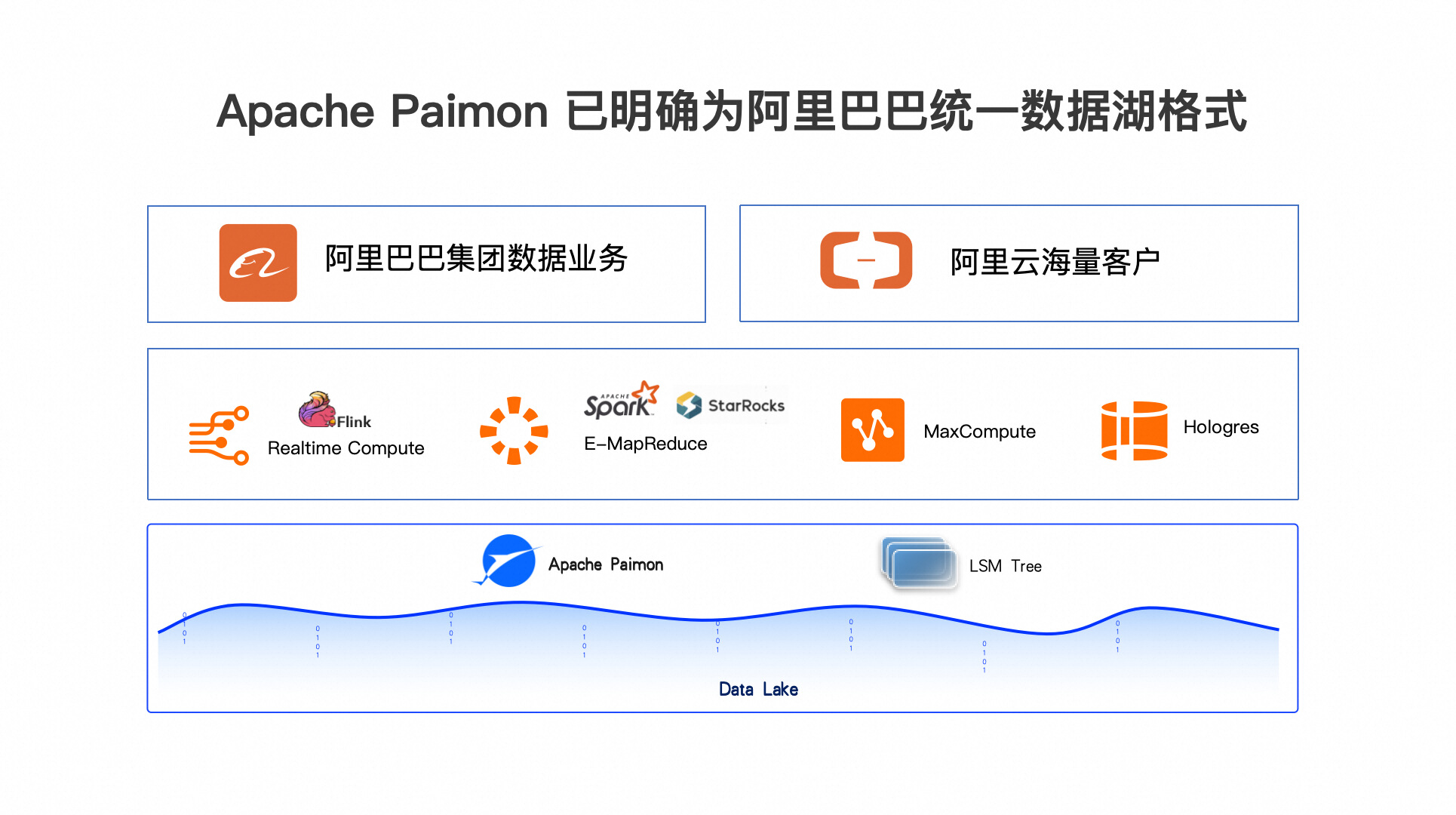
最近对视频生成的研究取得了巨大进展,使得可以从文本提示或图像生成高质量的视频。在视频生成过程中添加控制是未来的重要目标,而最近一些将视频生成模型与摄像机轨迹联系起来的方法正在朝着这个目标迈进。然而,从多个不同的摄像机轨迹生成同一场景的视频仍然具有挑战性。解决这个多视频生成问题可以实现大规模的3D场景生成,其中包括可编辑的摄像机轨迹等应用。本文引入了协作视频扩散(CVD)作为实现这一愿景的重要一步。CVD框架包括一个新颖的跨视频同步模块,通过一个极线注意机制促进了从不同摄像机姿态渲染的同一视频的相应帧之间的一致性。在基于最先进的视频生成摄像机控制模块的基础上进行训练,CVD生成了从不同摄像机轨迹渲染的多个视频,其一致性明显优于基线,在广泛的实验中得到了证明。
介绍
随着扩散模型的显著进展,视频生成也取得了显著进步,对数字内容创作工作流程产生了深远影响。最近的模型如SORA展示了生成复杂动态的长视频的能力。然而,这些方法通常利用文本或图像输入来控制生成过程,缺乏对内容和动作的精确控制,而这对于实际应用是至关重要的。先前的努力探索了其他输入模态的使用,如流、关键点和深度,并开发了新的控制模块,以有效地整合这些条件,实现对生成内容的精确引导。尽管取得了这些进步,但这些方法仍然未能为视频生成过程提供摄像机控制。
最近的研究开始专注于使用各种技术进行摄像机控制,例如运动LoRAs或场景流。一些代表性的作品如MotionCtrl和CameraCtrl通过将视频生成模型条件化为一系列摄像机姿态,提供了更灵活的摄像机控制,展示了自由控制视频摄像机移动的可行性。然而,这些方法局限于单一摄像机轨迹,导致从不同摄像机轨迹生成同一场景的多个视频时在内容和动态上存在显著的不一致性。在许多下游应用中,如大规模3D场景生成,具有摄像机控制的一致性多视频生成是可取的。然而,训练视频生成模型以生成具有不同摄像机轨迹的一致性视频非常具有挑战性,部分原因是缺乏大规模的多视角野外动态场景数据。
本文介绍了CVD,这是一个即插即用的模块,能够生成具有不同摄像机轨迹的视频,这些视频共享场景的相同基础内容和动态。CVD基于一种协作扩散过程设计,生成具有可单独控制的摄像机轨迹的一致性视频对。通过引入一个可学习的跨视图同步模块,利用极线注意机制实现了视频中对应帧之间的一致性。为了有效训练这个模块,本文提出了一种新的伪极线采样方案,以丰富极线几何注意力。由于缺乏用于3D动态场景的大规模训练数据,本文提出了一种混合训练方案,其中利用来自RealEstate10k的多视图静态数据和来自WebVid10M的单眼动态数据分别学习摄像机控制和动态。据本文所知,CVD是第一个能够生成具有一致内容和动态的多个视频,并提供摄像机控制的方法。通过大量实验证明,CVD确保了强大的几何和语义一致性,在性能上明显优于相关基线。总结本文的贡献如下: • 据本文所知,CVD是第一个生成具有摄像机控制的多视图一致视频的视频扩散模型; • 本文引入了一个新颖的模块,称为跨视频同步模块,旨在对齐不同输入视频的特征,以增强一致性; • 本文提出了一种新的协作推理算法,可以将在视频对上训练的视频模型扩展到任意数量的视频生成; • 本文的模型在生成具有一致内容和动态的多视图视频方面表现出优异性能,明显优于所有基线方法。
相关工作
视频扩散模型。 最近在训练大规模视频扩散模型方面的努力已经实现了高质量的视频生成。视频扩散模型利用3D UNet从图像和视频中联合学习。借助文本到图像(T2I)生成模型,如Stable Diffusion等,获得的优质图像质量,许多最新的工作集中在通过学习时间模块扩展预训练的T2I模型。Align-your-latents提出利用3D卷积和分解的时空块来学习视频动态。类似地,AnimateDiff在Stable Diffusion的基础上构建了一个时态模块,在每个固定的空间层之后添加一个时态模块,实现了即插即用的功能,允许用户进行个性化的动画制作而无需进行任何微调。Pyoco提出了一种时间上连贯的噪声策略,以有效地建模时间动态。最近,SORA利用transformer架构和时空扩散,向逼真的长视频生成迈出了重要的一步。
可控视频生成。 文本条件的模糊性通常导致文本到视频模型(T2V)的控制不足。为了提供精确的引导,一些方法利用额外的条件信号,如深度、骨架和流来控制生成的视频。最近的工作,如SparseCtrl和SVD,将图像作为视频生成的控制信号。为了进一步控制输出视频中的运动和摄像机视图,DragNUWA和MotionCtrl将运动和摄像机轨迹注入到条件分支中,前者使用放松的光流版本作为类似笔画的交互式指令,后者直接将摄像机参数连接为附加特征。CameraCtrl提出使用Plückere mbedding 对摄像机参数进行超参数化,并实现更精确的摄像机调节。另外,AnimateDiff训练摄像机轨迹LoRAs以实现视点移动调节,而MotionDirector也利用LoRAs但过拟合于特定的外观和动作以获得它们的解耦。
多视图图像生成。 由于缺乏高质量的场景级3D数据集,一系列研究重点关注生成连贯的多视图图像。Zero123学习从姿势条件生成新视图图像,并随后的工作将其扩展为用于更好的视图一致性的多视图扩散。然而,这些方法仅限于对象,并一直难以生成高质量的大规模3D场景。MultiDiffusion和DiffCollage促进了360度场景图像的生成,而SceneScape通过扭曲和修补使用扩散模型生成了放大视图。类似地,Text2Room生成了房间的多视图图像,其中图像可以通过深度投影以获得一致的房间网格。DiffDreamer遵循Infinite-Nature的设置,并使用条件扩散模型进行投影和细化的迭代过程。最近的一项工作,PoseGuided-Diffusion,通过在提供摄像机姿势的多视图数据集上训练并添加极线偏差到其关注mask,从单张图像进行新视图合成。然而,由于该方法的先验仅从定义良好的静态室内数据学习,因此构造的方法无法推广到野外或动态场景。
Po等人提供了最近在视觉计算中扩散模型方面的进展的全面调查。
协作视频生成
传统上,视频扩散模型(VDMs)旨在通过多个去噪步骤,从随机采样的高斯噪声中生成视频,并根据文本提示、帧或相机姿态等条件进行生成。具体来说,设 为从数据分布中采样的数据点;前向扩散过程不断向 添加噪声,得到一系列的 , ,直到它变成高斯噪声。使用 Ho 等人提出的重新参数化技巧, 的分布可以表示为 ,其中 是噪声调度参数,单调递增且 。视频扩散模型,通常表示为 ,是一个由参数 参数化的模型,训练目标是估计后向分布 。根据 Ho 等人的研究,优化 的结果是最小化以下损失函数:
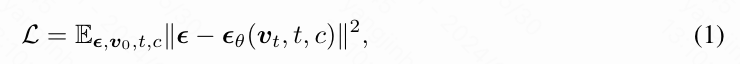
其中, 是从 和随机采样的高斯噪声 生成的噪声视频特征, 是视频扩散模型(VDM)的噪声预测, 是视频生成的条件。在推理时,可以从标准化的高斯噪声 开始,应用噪声预测模型 多次进行去噪,直到得到 。
借助现成的大规模视频数据集,许多最先进的视频扩散模型(VDMs)已经成功展示了生成时间一致且逼真视频的能力。然而,这些现有方法的一个关键缺点是无法生成一致连贯的多视角视频。如下图1所示,在相同文本条件下,由VDM生成的视频在内容和空间布局上存在差异。虽然可以使用推理阶段的技巧,如扩展注意力机制,以增加视频之间的语义相似性,但这并不能解决结构一致性的问题。为了解决这一问题,本文引入了一种新的目标,即在给定特定语义条件下,VDM能够同时生成多个结构一致的视频,并将其命名为协作视频扩散(Collaborative Video Diffusion, CVD)。
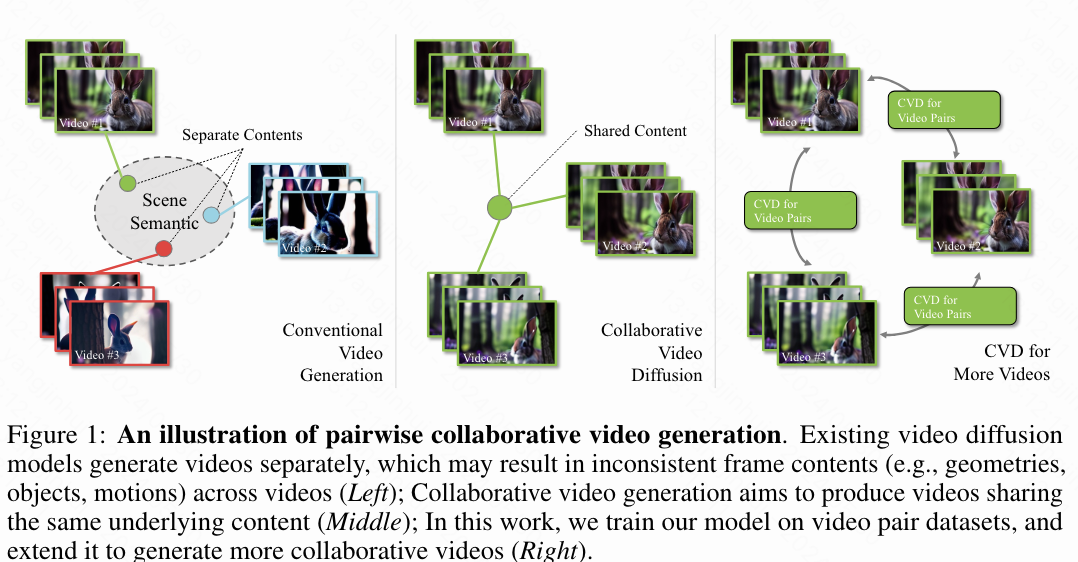
与传统的视频扩散模型相比,CVD 试图在给定独立条件 的情况下,找到任意数量的视频 ,其中 ,这些视频符合未知的数据分布 。同样,CVD 模型可以表示为 。一个例子是从同一个动态 3D 场景同步捕获的多视角视频。同样,协作视频扩散模型的损失函数定义为:
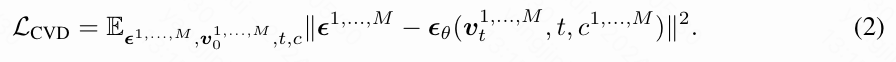
然而,在实际操作中,大规模多视角视频数据的稀缺性使得本文无法直接训练一个针对任意数量视频的模型。因此,本文从现有的单目视频数据集中构建了一致的视频对(即 )的训练数据集,并训练扩散模型生成共享相同基础内容和运动的视频对。本文的模型设计可以适应任意数量的输入视频特征,本文还开发了一种推理算法,从本文预训练的成对 CVD 模型中生成任意数量的视频。
具有摄像机控制的协作视频扩散
本文寻求构建一个扩散模型,该模型接收文本提示 和一组相机轨迹 ,并生成相同数量的协作视频 。为了简化一致视频的生成,在本工作中本文使用视频对( )训练模型,并假设视频是同步的(即对应的帧是同时捕获的),并将每条轨迹的第一个姿态设置为相同,强制所有视频的第一帧一致。
受 [18, 17] 启发,本文的模型设计为相机控制视频模型 CameraCtrl的扩展。如下图 2 所示,本文的模型接收两个(或更多)带噪视频特征输入,并在一次传递中生成噪声预测。这些视频特征通过 CameraCtrl 的预训练权重,并在本文提出的跨视角同步模块中同步。该模型使用两个不同的数据集进行训练:RealEstate10K,该数据集包含主要静态场景的相机校准视频;以及 WebVid10M,该数据集包含不带姿态的通用视频。这导致了本文在下文中介绍的两阶段训练策略。通过本文提出的推理算法,学习到的模型可以推断任意数量的视频。
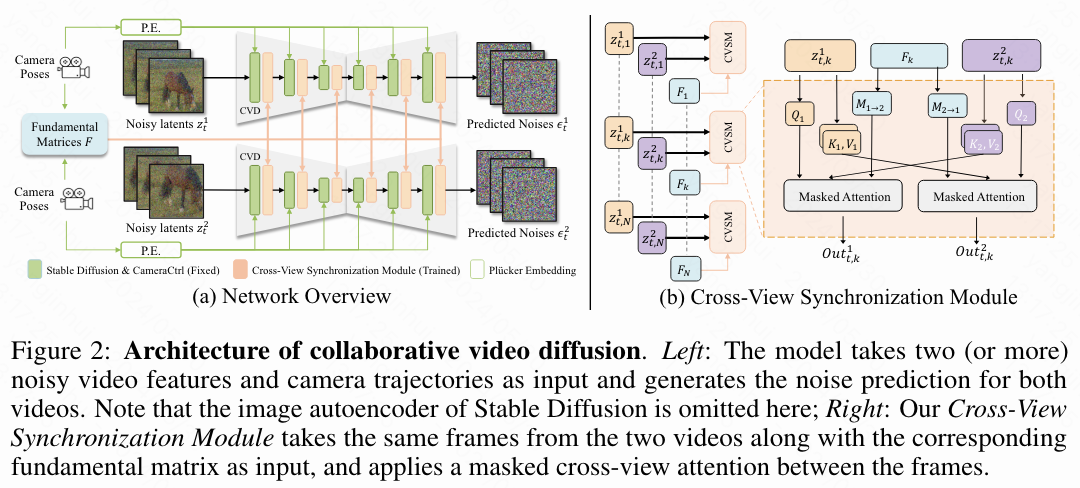
跨视图同步模块
最新的 VDM(视频扩散模型)通常在空间和时间维度上结合了各种类型的注意力机制:例如 AnimateDiff、SVD、LVDM将空间和时间解耦并应用独立的注意力层;而最新的突破性工作 SORA在其 3D 空间-时间注意模块上同时处理这两个维度。尽管在空间和时间维度上定义的操作在不同帧的不同像素之间带来了强相关性,但捕捉不同视频之间的上下文关系需要一种新的操作:跨视频注意力。
幸好,先前的研究已经表明,扩展注意力技术,即将不同视角的键和值拼接在一起,对于在视频之间保留相同的语义信息是显然有效的。然而,这种方法无法保持它们之间的结构一致性,导致在几何上完全不同的场景。因此,受到 [53] 的启发,本文引入了基于极几何的跨视角同步模块,以在生成过程中揭示跨视频帧之间的结构关系,使视频在几何上对齐。
上图 2 展示了本文跨视角模块对于两个视频的设计。以一对特征序列 和 (包含 N 帧)作为输入,本文的模块在两个视频的相同帧之间应用跨视频注意力。具体来说,本文将本文的模块定义为:
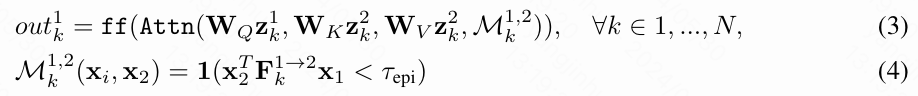
其中 是帧索引, 、 、 分别是查询、键、值的映射矩阵, 是注意力mask, 是从Transformer引入的注意力操作符, 是前馈函数, 是在第 帧时摄像机1和摄像机2之间的基本矩阵。 在本文所有的实验中都设置为3。这些模块的输出被用作残差连接与相应的原始输入结合,以确保不会丢失原本学习到的信号。这个模块的关键见解是,由于假设两个视频是同步的,相同帧应该共享相同的基础几何,因此可以通过给定摄像机姿态定义的极线几何进行关联。对于第一帧,由于基本矩阵在这里未定义,因此摄像机姿态被设置为相同,本文为每个像素生成通过这些像素的随机斜率的伪极线。在多视图数据集可用的情况下,可以通过将跨视图注意力从一对一扩展到一对多来进一步适应更多的视频。本文的研究表明,基于极线的注意力显著提高了生成视频对的几何完整性。
两个数据集的混合训练策略
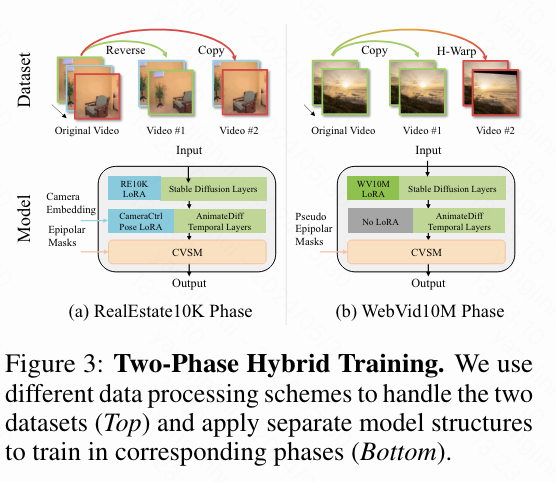
考虑到目前没有可用的大规模真实世界视频对数据集,本文选择利用两个流行的单目数据集,RealEstate10K和 WebVid10M,来开发一种用于视频对生成模型的混合训练策略。
RealEstate10K 与视频折叠。训练的第一阶段涉及 RealEstate10K,这是一个包含主要静态室内场景和相应摄像机姿态的视频剪辑数据集。本文通过简单地从数据集中的视频采样2N-1帧的子序列来采样视频对,然后从中间剪切并反转它们的前半部分,以形成同步的视频对。换句话说,这些子序列被折叠成两个共享相同起始帧的视频剪辑。
WebVid10M 与单应变换增强。 虽然 RealEstate10K 提供了不错的几何先验,但仅在这个数据集上训练本文的模型并不理想,因为它不包含任何关于动态的知识,并且只包含室内场景。另一方面,WebVid10M 是一个大规模视频数据集,包含各种类型的视频,可以作为 RealEstate10K 的良好补充。为了提取视频对,本文克隆数据集中的视频,然后对这些克隆视频应用随机单应变换。然而,WebVid10M 数据集不包含摄像机信息,这使得它不适合用于基于摄像机条件的模型训练。为了解决这个问题,本文提出了一种两阶段训练策略,以适应这两个数据集(无论是否包含摄像机姿态)用于同一个模型。
两阶段训练。 如前所述,本文的模型基于现有的摄像机控制VDM CameraCtrl。它是AnimateDiff的扩展版本,添加了一个姿态编码器和几个姿态特征注入器,用于原模型的时间注意力层。AnimateDiff 和 CameraCtrl 都基于 Stable Diffusion。这意味着它们采用相同的潜在空间域,因此可以训练一个通用适应的模块。因此,如下图3所示,本文的训练方案设计如下:
对于 RealEstate10K 数据集,本文使用在 RealEstate10K 上通过 LoRA 微调的 CameraCtrl 作为骨干,并在跨视频模块中应用真实的极线几何。对于 WebVid10M 数据集,本文使用在 WebVid10M 上通过 LoRA 微调的 AnimateDiff 作为骨干,并在跨视频模块中应用伪极线几何(与在 RealEstate10K 数据集的第一帧中使用的策略相同)。实验表明,这种混合训练策略极大地帮助模型生成具有同步运动和良好几何一致性的视频。
观看更多视频
通过在视频对上训练的CVD,本文可以生成多个共享一致内容和运动的视频。在每个去噪步骤 ,本文在所有 视频特征中选择 特征对 。然后,本文使用训练好的网络来预测每个特征对的噪声,并对每个视频特征进行平均。即,第 个视频特征的输出噪声定义为:
其中, 是给定视频对输入 时的噪声预测。对于对的选择,本文提出以下策略:
-
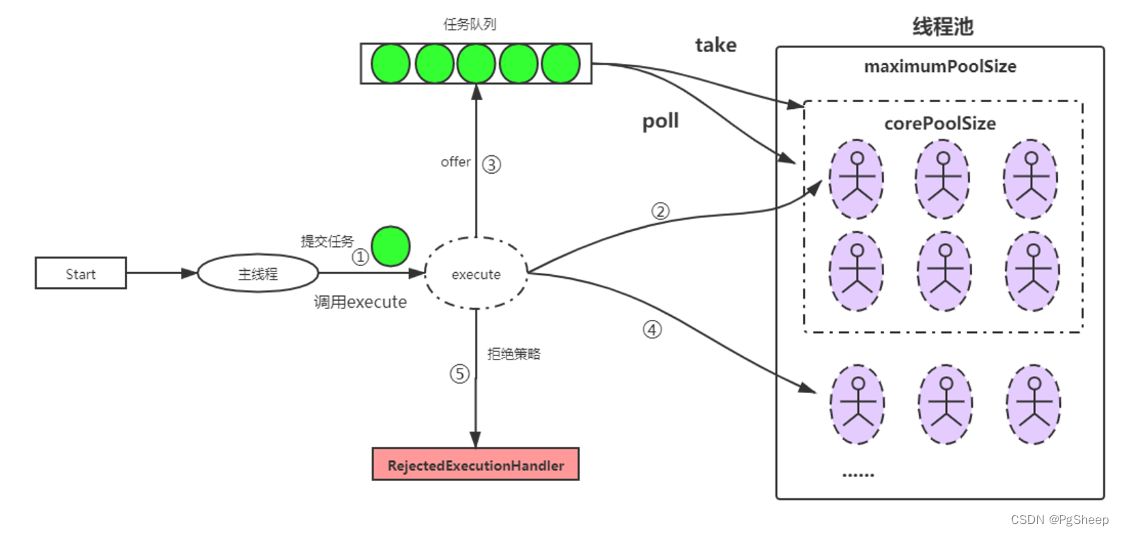
穷尽策略:选择所有 对。 -
分区策略:随机将 个噪声视频输入分成 对。 -
多分区策略:多次重复分区策略并结合所有选定的对。
穷尽策略的计算复杂度为 ,相比之下,分区策略的计算复杂度为 ,但穷尽策略覆盖了 个视频中的每一对,因此可以生成更一致的视频。另一方面,多分区策略在两种策略之间进行了权衡。本文还采用了 Bansal 等人介绍的递归去噪方法,在每个去噪时间步上进行多次递归迭代。
实验
定量结果
本文将本文的模型与两个最先进的相机控制视频扩散模型进行定量评估比较:CameraCtrl 和 MotionCtrl。这两个基线模型都在 RealEstate10K数据集上进行了相机控制视频生成的训练。本文进行了以下实验来测试所有模型的几何一致性、语义一致性和视频保真度:
地产场景中的每视频几何一致性。 按照 CameraCtrl的方法,本文首先使用 RealEstate10K(主要由静态场景组成)中的相机轨迹和文本提示测试本文模型生成的视频帧之间的几何一致性。具体来说,本文首先从随机采样的相机轨迹对(两个具有相同起始变换的相机轨迹)和文本标题中生成 1000 个视频。所有基线模型一次生成一个视频;本文的模型同时生成两个视频。对于每个生成的视频,本文应用最先进的图像匹配算法 SuperGlue来提取其第一帧和后续帧之间的对应关系,并使用 RANSAC算法估计它们的相对相机姿态。为了评估对应关系和估计的相机姿态的质量,本文采用了 SuperGlue的相同协议:
-
通过旋转和平移的角度误差来评估姿态 -
通过对应的极线误差(即到真实极线的距离)来评估匹配的对应关系。
结果如下表 1 所示,本文的模型显著优于所有基线模型。
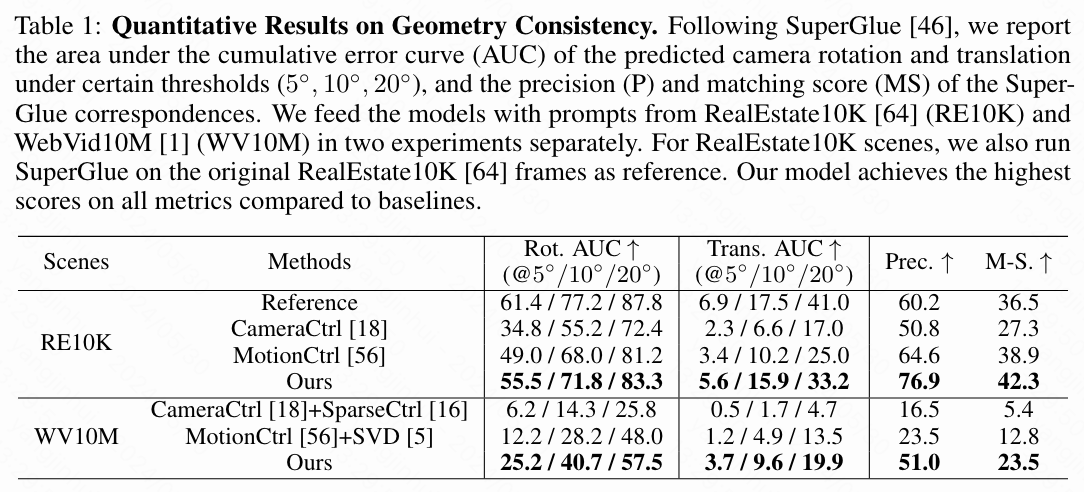
跨视频几何一致性在通用场景中的表现。 除了评估同一视频中帧与帧之间的一致性外,本文还测试了本文的模型在不同视频中保持几何信息的一致性能力。为此,本文随机抽取了500对视频(总计1000个视频),使用了RealEstate10K中的相机轨迹对和WebVid10M字幕中的文本提示。据本文所知,目前没有可用的大型视频扩散模型专门设计用于生成通用场景的多视角一致视频。因此,本文修改了CameraCtrl和MotionCtrl以生成视频对作为基线。在此,本文首先使用每个模型的文本到视频版本生成一个参考视频,然后将其第一帧作为输入,使用其图像到视频版本(即与SparseCtrl和SVD的结合)生成第二个视频。本文使用与第一个实验相同的指标,但评估的是两个视频中对应帧之间的一致性。结果如上表1所示,本文的模型大大优于所有基线模型。
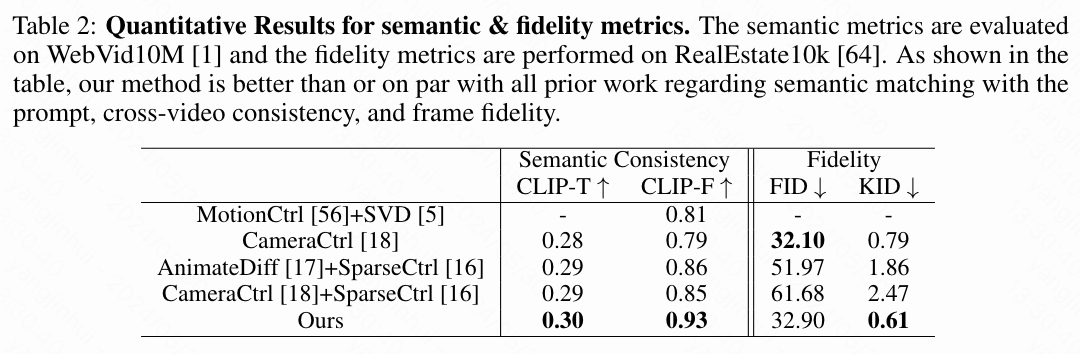
语义和保真度评估。 按照之前工作的标准实践,本文报告了CLIPembedding相似性,包括1)输出视频的每一帧与对应输入提示之间的相似性和2)视频对之间帧的相似性。前者指标记为CLIP-T,用于显示本文的模型不会破坏基础模型的外观/内容先验,而后者指标记为CLIP-F,旨在显示跨视图模块可以提高生成视频对之间的语义和结构一致性。为此,本文随机抽取了1000个视频,使用RealEstate10K中的相机轨迹对和WebVid10M中的文本字幕(总计生成2000个视频)。为了进一步展示本文方法保持高保真度生成内容的能力,本文报告了使用实现的FID和KID ×100。
本文不与不共享相同基础模型的模型进行FID和KID比较,因为这些指标受基础模型能力的强烈影响。按照之前的工作,本文在RealEstate10K上评估这两个指标,因为WebVid10M上存在强烈的不良偏差,例如水印。正如下表2所示,本文的模型在基于CLIP的指标上超越了所有基线模型。这证明了本文的模型能够合成共享场景的协作视频,同时根据提示保持和提高保真度。本文的模型在保真度指标上也优于或与所有之前的工作相当,这表明了对本文基础模型所学习的外观和内容先验的鲁棒性。
定性结果
与基线比较
定性比较如下图4所示。在上文中的定量比较之后,本文对比了CameraCtrl及其与SparseCtrl 的组合、MotionCtrl及其与SVD的组合。结果表明,本文的方法在视频内容对齐方面具有优越性,包括闪电、海浪等动态内容。

任意视图生成的附加结果
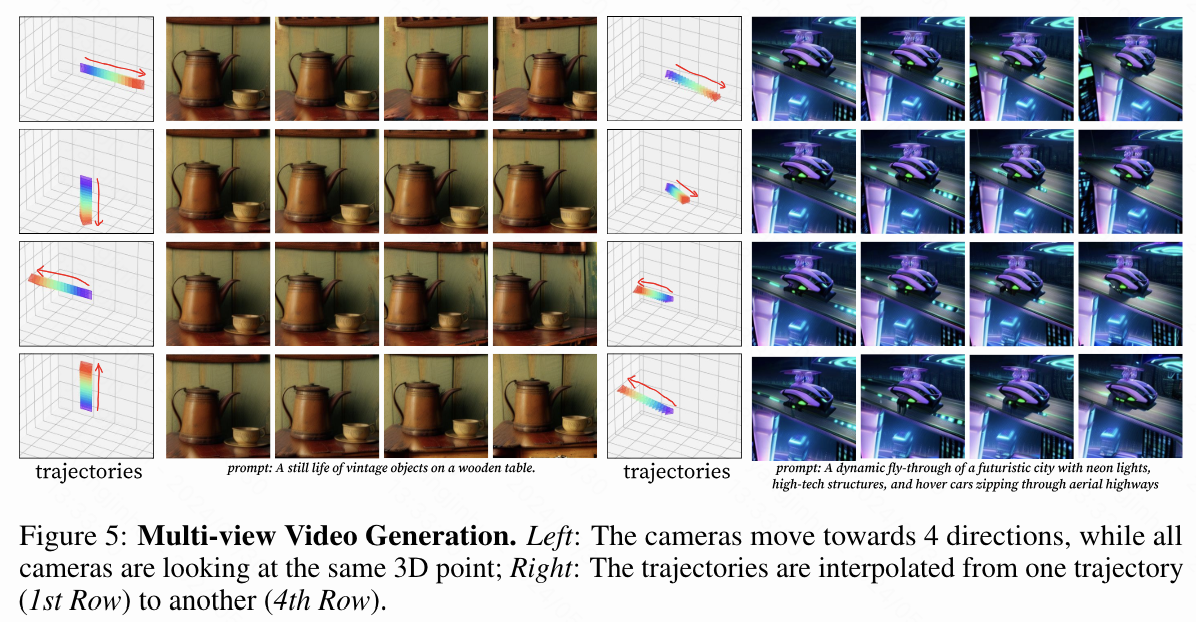
本文还展示了下图5中的任意视角生成结果。使用上文介绍的算法,本文的模型可以生成一组不同相机条件下的视频,这些视频共享相同的内容、结构和运动。
讨论
本文推出了CVD,一种促进协作视频生成的新框架。它确保视频实例之间的信息无缝交换,同步内容和动态。此外,CVD提供相机定制功能,以便使用多个相机全面捕捉场景。CVD的核心创新在于其利用重建管线中推导出的极几何作为约束。这种几何框架微调了预训练的视频扩散模型。通过整合动态的、单视角的野外视频,训练过程得到了增强,从而保持了多样的运动模式。在推理过程中,CVD采用多视角采样策略,促进视频间的信息共享,从而实现统一视频输出的“协作扩散”效果。据本文所知,CVD是首个解决多视角或多轨迹视频合成复杂性的方案。它显著超越了现有的多视角图像生成技术,如Zero123,不仅确保了生成视频的一致动态,还带来了视频合成领域的重要突破,承诺了新的能力和应用。
限制
CVD 面临一些局限性。首先,CVD 的有效性本质上与其基础模型 AnimateDiff 和 CameraCtrl的性能密切相关。尽管 CVD 力求促进视频之间的稳健信息交换,但它并未从根本上解决单个视频内部一致性的问题。因此,基础模型中存在的诡异形变和动态不一致等问题可能会持续存在,影响视频输出的整体一致性。此外,由于扩散模型计算量大,CVD 无法实时合成视频。然而,扩散模型优化领域正在迅速发展,未来的进展可能会显著提高 CVD 的效率。
更广泛的影响
本文的方法在多摄像头视频合成领域代表了一个重要的进步,对电影制作和内容创作等行业具有广泛的影响。然而,本文也意识到潜在的滥用风险,特别是在制作虚假内容如深度伪造(deepfakes)方面。本文坚决反对利用本文的方法进行任何侵犯道德标准或隐私权的行为。为了应对这种滥用风险,本文倡导持续开发和改进深度伪造检测技术。
参考文献
[1] Collaborative Video Diffusion: Consistent Multi-video Generation with Camera Control
本文由 mdnice 多平台发布








![[大模型]Phi-3-mini-4k-instruct langchain 接入](https://img-blog.csdnimg.cn/direct/dc2da995c6774ca7b9aa54bf7e52df2c.png#pic_center)