Omnisketch:高效的多维任意谓词高速流分析
- 摘要
- 1 引言
- 2 预备知识及相关工作
- 3 OMNISKETCH:使用任意谓词估计频率
- 3.1 Sketch S0:Count-Min with rid-sets 用于估计带有谓词的查询
- 3.2 Sketch S1 (OmniSketch):通过采样实现亚线性空间
- 3.3 扩展
- 4 实验评价
- 4.1 S0 和 S1 的比较
- 4.2 与最先进的比较
- 4.3 不同流的 S1 评估
- 4.4 范围查询
- 5 总结
- 参考文献

摘要
不同学科的一个关键需求是对快节奏的数据流执行分析,其性质类似于关系数据库中的传统 OLAP 分析,即使用过滤器和聚合。然而,由于存储要求高,以及存储海量数据时引入的延迟,存储无界流不是一种现实或理想的方法。因此,已经提出了许多概要/草图,它们可以在小内存(通常足够小以存储在RAM中)中总结流,这样就可以有效地近似聚合查询,而无需存储整个流。然而,过去的概要主要关注对单一属性流的总结,无法有效地处理对多个属性的任意子集进行过滤和约束。在这项工作中,我们提出了OmniSketch,这是第一个能够适应快节奏和复杂数据流(具有许多属性)的草图,并支持在查询时动态选择多个属性的过滤器的计数聚合。该草图提供概率保证、有利的空间精度权衡以及更新和查询执行的最坏情况下的对数复杂度。我们通过对真实和合成数据的实验证明,该草图优于最先进的技术,并且可以在配置好的精度保证下,以较小的内存需求近似复杂的临时查询。
PVLDB 参考格式:Wieger R. Punter, Odysseas Papapetrou, and Minos Garofalakis. OmniSketch: Efficient Multi-Dimensional High-Velocity Stream Analytics with Arbitrary Predicates. PVLDB, 17(3): 319 - 331, 2023. doi:10.14778/3632093.3632098
PVLDB 工件可用性:源代码、数据和/或其他工件已在 https://github.com/wiegerpunter/omnisketch 上提供。
1 引言
筛选器和聚合器构成了数据分析的主力,并在所有数据库中实现。因此,已经实施了索引和存储技术,以有效地回答此类查询,即使在大数据上也是如此。当涉及到无法完整存储或实时查询的流数据时,首选技术基于草图 [5]:小内存数据结构,用于汇总流,随后可用于执行聚合查询。文献中的示例草图支持计数、范数和连接聚合的估计 [2, 6, 23])、集合大小的估计 [9] 以及频繁项目和重击者的识别 [4]。
尽管被大量使用,但迄今为止,大多数草图都侧重于根据单个属性或预先选择的属性组合来总结频率分布。例如,考虑网络监控领域,其中 Count-min 草图经常用于统计维护 [6]。标准 IPv4 数据包报头定义至少 13 个字段/属性,包括版本、报头长度、总长度、DSCP 代码点、源地址和目标地址、协议,以及 30 个附加选项中的一个或多个。为了能够估计满足属性值组合(在查询时定义)的数据包数,我们需要构造一个草图,该草图使用这些属性的组合值(例如,它们的串联)作为键。作为运行示例,考虑图 1 中简化的 IPv4 标头流,它包含 13 个属性中的 4 个。为了总结每个 IP 地址发送的数据包数的分布,我们需要一个使用 ipSrc 作为密钥构建的草图。需要在 ipDest 上再绘制一个草图,以汇总每个 IP 地址接收的数据包数。如果我们还想汇总任意两个 IP 地址之间交换的数据包数,我们需要维护一个草图,该草图使用源-目标 IP 地址的串联作为键。为支持任意谓词(在此示例中,标题中包含的 13 个字段的任意子组合)而需要维护的草图数总计为 O (213) – 幂组的大小。将其推广到任意用例,估计 p 谓词的所有子组合的频率分布需要维护 2p − 1 草图。这显然是不可行的,因为空间要求和数据流上下文中出现的严格的效率限制。1
我们的贡献。在这项工作中,我们提出、分析和评估了一种名为 OmniSketch 的新型草图工具,它通过将草图与采样相结合,有效地解决了空间和时间效率问题。OmniSketch 结合了草图的紧凑性(这是减少内存约束所必需的)和采样的通用性(这是支持常规查询的关键),适用于在查询时动态决定的谓词。简而言之,用于汇总 p 属性数据流的 OmniSketch 由 p 个单独的小内存子草图组成,每个子草图都类似于 Count-Min 草图。但是,与 Count-Min 草图不同的是,OmniSketch 子草图中的单元格包含哈希到其中的所有记录的固定大小的摘要。在查询时,将定位并查询与查询相关的子草图以及每个子草图中的相关单元格,以估计答案。与以前的工作不同,OmniSketch 提供了计算复杂性(用于更新和查询),该复杂性随属性数量线性扩展(而不是指数级),使其成为迄今为止唯一可行的通用解决方案,用于在狭小空间内汇总具有许多属性的快节奏流。我们的草图以提供形式错误保证的理论分析为后盾,以及基于理论分析的自动初始化算法,以充分利用可用的草图存储器。
我们在真实和合成生成的流上对 OmniSketch 进行了实验性评估,并将其与最先进的竞争对手 Hydra 进行了比较。我们的实验证实,OmniSketch 是汇总复杂流的唯一可行选择,并且具有有利的复杂性和准确性权衡。相比之下,Hydra 在汇总具有五个或更多属性的流时变得非常慢,因此无法有效地汇总快节奏的流。
路线图。本文的其余部分结构如下。在第 2 节中,我们介绍了初步情况并讨论了相关工作。在第 3 节中,我们介绍了 OmniSketch 并分析了其理论特性,而第 4 节总结了我们的实验结果。我们总结了这项工作,并在第 5 节中总结了未来的计划。
2 预备知识及相关工作
预备知识。OmniSketch 继承了 CountMin 草图 [6] 的基本结构,并建立在 k-minwise 哈希理论 [22] 的基础上。现在,我们将简要介绍这两部作品,以深入理解我们的工作。
计数-最小素描(Count-Min Sketch)。由Cormode和Muthukrishnan于2005年提出[6],计数-最小素描已成为数据流分布汇总的事实标准方法。一个计数-最小素描CM是一个二维数组,宽度为w,深度为d,并伴随有d个两两独立的哈希函数,将输入映射到范围 { 1 , . . . , w } \{1, ..., w\} {1,...,w}内。设 C M [ j , h j ( ⋅ ) ] CM[j, h_j(\cdot)] CM[j,hj(⋅)]表示二维数组中第j行,第 h j ( ⋅ ) h_j(\cdot) hj(⋅)列的计数器。一条记录r(例如,一个IP地址)通过增加 C M [ j , h j ( r ) ] CM[j, h_j(r)] CM[j,hj(r)]处的计数被添加到素描中一次,其中j属于 { 1 , . . . , d } \{1, ..., d\} {1,...,d}。流中任何查询q的到达次数估计是通过查找每行j对应的单元格 C M [ j , h j ( q ) ] CM[j, h_j(q)] CM[j,hj(q)],并返回最小计数值,即 f ^ ( q ) = m i n j ∈ { 1 , . . . , d } ( C M [ j , h j ( q ) ] ) \hat{f}(q) = min_{j\in\{1,...,d\}}(CM[j,h_j(q)]) f^(q)=minj∈{1,...,d}(CM[j,hj(q)])。由于哈希冲突(除了q之外落在相同计数器上的其他项)f̂(q)可能是真实频率f(q)的过高估计。通过设置w = ⌈e/ε⌉和d = ⌈ln(1/δ)⌉,我们有f̂(q) - f(q) ≤ εN的概率≥1-δ,其中N是流的长度。
计数-最小草图(Count-Min sketches)也支持范围查询,通过将范围分解为规范覆盖(canonical covers)[6]来实现。为属性 a a a 添加范围查询的支持会使得空间和时间复杂度大约增加一个 O ( log ( ∣ D ( a ) ∣ ) ) O(\log(|D(a)|)) O(log(∣D(a)∣))的因子,其中(D(a))表示该属性的域。
由于计数-最小草图(Count-Min sketches)具有吸引人的成本-精度权衡,因此在快速数据流上维护多个草图也是可能的,每个草图总结一个属性。例如,我们的运行示例(图1)的数据流可以被4个单独的计数-最小草图所概括,这使得能够对以下四种过滤条件中的任何一种进行频率估计:WHERE ipSrc=?, WHERE ipDest=?, WHERE totalLen=?, WHERE dscp=?(其中?表示谓词值)。然而,计数-最小草图不支持在同一查询中使用多个谓词,例如,WHERE ipSrc=? AND ipDest=?。如果这些谓词组合在观察数据流之前已知,那么可以为每种组合构建一个单一的草图,索引属性的串联。例如,为了支持查询WHERE ipSrc=? AND ipDest=?, 我们可以为每条记录构造一个复合键<ipSrc,ipDest>,并将其汇总到一个草图中。然后,具有两个属性作为谓词集的查询可以通过以类似方式构建查询的复合键,并对其进行查询来回答。但是,如果这些谓词组合不是事先知道的,或者如果我们想让用户能够使用任意的属性组合进行查询,那么总结具有n个属性的流需要构建 2 n − 1 2^n - 1 2n−1个草图,以覆盖所有可能的谓词组合。因此,从时间和空间复杂度的角度来看,这种做法不是一个可行的解决方案。

K-minwise 哈希。在这项工作中,我们依靠最小散列来估计多个集合的交集的基数。所有最小哈希方案背后的关键思想是使用一个或多个哈希函数对每个集合中的所有项目进行哈希处理,并且仅保留每个哈希函数具有最小哈希值的 B 项作为每个集合的样本。然后,可以缩放不同集合的这些样本的交集大小,以估计集合交集的基数。
我们在这项工作中将要使用的K-minwise哈希算法估计集合交集的基数如下[22]:设 R 1 , R 2 , … , R p R_1, R_2, \ldots, R_p R1,R2,…,Rp表示我们想要估计其交集基数的 p p p 个集合。首先,我们通过使用全局哈希函数 g ( ⋅ ) → { 0 , 1 } b g(\cdot) \rightarrow \{0, 1\}^b g(⋅)→{0,1}b对每个集合 R i R_i Ri中的每一项进行哈希,并保留 B B B 个最小的哈希值来构造每个集合的摘要 S i S_i Si,其中 b b b 至少设置为 ⌈ log ( 4 B 2.5 / δ ) ⌉ \lceil\log(4B^{2.5}/\delta)\rceil ⌈log(4B2.5/δ)⌉。然后,我们可以从这些摘要中估计 p p p 个集合的交集的基数 ∣ R ∩ ∣ = ∣ R 1 ∩ . . . ∩ R p ∣ |R_{\cap}| = |R_1 \cap ... \cap R_p| ∣R∩∣=∣R1∩...∩Rp∣ 为 R ^ ∩ = ∣ ⋂ i = 1 p S i ∣ ∗ n m a x / B \hat{R}_{\cap} = |\bigcap_{i=1}^{p} S_i| * n_{max}/B R^∩=∣⋂i=1pSi∣∗nmax/B,其中 n m a x = max 1 ≤ i ≤ p ∣ R i ∣ n_{max} = \max_{1 \leq i \leq p} |R_i| nmax=max1≤i≤p∣Ri∣ 。当 R ^ ∩ ≥ 3 n m a x log ( 2 p / δ ) / ( B ϵ 2 ) \hat{R}_{\cap} \geq 3n_{max} \log(2p/\delta)/(B\epsilon^2) R^∩≥3nmaxlog(2p/δ)/(Bϵ2)时,此估计具有((\epsilon, \delta))保证。当上述条件不满足时,可以证明一个较弱的界:以概率 1 − δ / B 1 - \delta/\sqrt{B} 1−δ/B,有 0 ≤ ∣ R ∩ ∣ ≤ 4 n m a x log ( 2 p / δ ) / ( B ϵ 2 ) 0 \leq |R_{\cap}| \leq 4n_{max} \log(2p/\delta)/(B\epsilon^2) 0≤∣R∩∣≤4nmaxlog(2p/δ)/(Bϵ2) 。
我们选择了 K-minwise 哈希而不是其他采样方法,因为该算法已被证明性能同样好或优于其他采样方法(包括 [3, 16, 18]),并且空间复杂度几乎与问题的理论下限相匹配 [22]。此外,所选算法也适用于流数据,因为样本可以增量维护。
数据流模型和支持的查询。输入数据是一个记录流,例如,类似于图1中我们持续示例的记录。设A = {𝑎1, 𝑎2, …, 𝑎|A|}表示数据流的属性(在持续示例中,ipSrc、ipDest、totalLen、dscp)。每条记录还带有唯一的记录标识符(rid),标记为𝑎0——如果没有记录键存在,可以在摄入时轻松构建此类唯一的rids(例如,使用到达计数器)。我们假设了一个地标式流查询模型[21],其中在数据流摄入的任何时间点都可以提出查询,并且该查询针对直到那时的所有数据流到达。形式上,设 R = { r e c 1 , r e c 2 , . . . , r e c N } R = \{rec_1, rec_2, ..., rec_N\} R={rec1,rec2,...,recN}表示直到查询时间的所有数据流到达。查询𝑞是一个计数查询,包含对A的任何子集 { a 2 , a j , a k , . . . } \{a_2, a_j, a_k, ...\} {a2,aj,ak,...}的选择谓词的合取:
Count (︁ 𝑟𝑒𝑐 ∈ R | 𝑟𝑒𝑐满足𝑞 = q i q_i qi ∧ q j q_j qj ∧ q k q_k qk … )︁
其中每个谓词 q i q_i qi 可以是单个属性 a i a_i ai 上的范围和等值谓词的析取。
其他相关工作。用于多维数据流的最新子种群草图是Hydra[20]。在外层,Hydra 由宽度为 w 和深度为 d 的 Count-Min 草图组成,并伴随着 d 成对独立哈希函数,这些哈希函数将输入域映射到 [1 . . . w]. 此草图中的每个单元格都包含一个嵌套的通用草图 [19],用于保存详细的统计数据。当读取 p 属性的记录时,它会在 Hydra 草图中按如下方式进行哈希处理。首先,计算记录属性的所有 2 p − 1 2^p − 1 2p−1 种可能组合。这些组合中的每一个都定义了此记录所属的子群体。然后使用 d 哈希函数对每个组合进行哈希处理,以在外部草图(每行一个单元格)中找到相应的单元格,并最终将组合添加到包含的通用草图中。对于查询执行,查询谓词被组合起来创建一个键,然后使用相同的 d 哈希函数对其进行哈希处理,以便在外部草图中查找相应的单元格。然后,我们使用相同的键查询嵌套的通用草图,以估计频率。
在全面的实验评估中,Hydra 的表现优于其他方法,并提供交互式查询延迟。
然而,这种草图有两个关键的缺点,使其对于具有许多属性的流来说不是一个可行的选择。首先,回想一下,每条记录会以不同的键被添加到草图中 2 p − 1 2^p − 1 2p−1次——对应于每一种可能的组合一次。如我们稍后将展示的,这种指数级的复杂度即使对于数量适中的索引属性(即,𝑝 = 4)而言,在时间复杂度方面也会成为一个挑战,从而在汇总快节奏的数据流时造成问题。其次,由于草图中添加次数的急剧增加(随𝑝呈指数增长),近似误差也随之迅速增加。我们的实验结果表明,虽然Hydra在小的𝑝值下表现出色,但其误差(以及更新时间)随着𝑝的增加而呈指数级增长。
集合基数估计技术。有人提出采用不同采样法,根据流的少量记忆样本来估计流中不同项目的数量[11]。关键思想是将样本保持在不同的级别,总内存预算为 B。每个采样水平 l 中都包含一条记录,概率为 2 − l 2^{−l} 2−l 。当样本总数(跨所有级别)超过 B 时,将丢弃最低级别,从而释放大约一半的内存,并为更高级别的更多样本腾出空间。流中不同项目数量的 (ε, δ) 估计值可以通过将最小存活采样水平 l m i n l_{min} lmin 中的项目数乘以比例因子 2 l m i n 2^{l_{min}} 2lmin 来计算。通过利用协调抽样,还可以使用不同抽样来估计集合交集的大小。在我们的上下文中,不同采样可以用作 K-minwise 散列的替代方案,以固定内存预算逐步维护流样本。在实践中,K-minwise 哈希在我们的实验中被证明可以更好地利用可用内存。因此,我们不报告具有不同采样的实验。
两层哈希草图(2LHS)[10]被提议用于任意集合表达式的基数估计,适用于包含一般更新(记录插入和删除)的数据流。一个2LHS X A X_A XA 包含两层桶,并实现为一个三维数组,大小为 k log ( M ) × s × 2 k \log(M) \times s \times 2 klog(M)×s×2,其中 k k k 和 s s s 是用户可调参数,用于控制估计精度,而 M M M 是输入域的大小。从概念上讲,2LHS可以被视为区别采样的泛化,可以用来给出集合并集、交集和差集在一般更新(即,翻转[21])数据流上的 ( ϵ , δ ) (\epsilon, \delta) (ϵ,δ) 基数估计。尽管2LHS可以用作K-minwise哈希的替代方案,但在2LHS结构中存在额外的空间/时间复杂度,这是处理数据流中记录删除实际所需的。因此,我们将OmniSketch设计的重点放在K-minwise哈希上,它为仅插入的流提供了一个更简单且空间效率更高的解决方案,并在论文后面讨论了面向一般更新的可能扩展。
文献中还提出了许多其他基于采样的技术,用于估计(仅插入)记录流上的集合并集、集合交集和任意集合表达式的基数 [7, 8, 14, 15, 17]。从本质上讲,这些方法类似于 K-minwise 哈希,具有相似的复杂性和理论保证。原则上,这些都可以与 OmniSketch 一起使用,以构建嵌套草图。但是,需要注意的是,这些方法(包括 K-minwise 哈希)都不支持基于谓词的过滤。因此,它们不能直接用于估计带有谓词的聚合查询的答案,这是我们工作的主要重点。
3 OMNISKETCH:使用任意谓词估计频率
我们现在介绍OmniSketch,这是一种允许对快速数据流上的带有谓词的查询进行高效频率估计的草图。我们将逐步构建最终的草图,分为三个连续的步骤。最初,我们描述了标准计数-最小草图的一种扩展,称为S0,它在单元格中保持额外的数据。利用这些附加信息,可以通过对计数最小估计器的直接推广来估计涉及谓词的基数。然后,在保持S0草图结构不变的情况下,我们提出了一种改进的估计算法及其相应的理论分析,以在不增加额外复杂度的情况下收紧误差界限。我们将新的草图估计器称为 S 0 ∩ S0_∩ S0∩,以区别于早期的估计器(称为 S 0 m i n S0_{min} S0min)。最后,我们介绍了最终的OmniSketch(S1),它将 S 0 ∩ S0_∩ S0∩与一种采样技术相结合,以确保亚线性的空间复杂度。与以往的工作不同,所有三种草图都允许非常高效的更新(具有对数复杂度),因此可以轻松处理快节奏的数据流。
所有三种草图都基于一个共同的架构:每种草图都由一系列子草图组成,每个可搜索属性(即希望支持谓词的属性)分配有一个草图。我们将这些子草图称为属性草图,并用 C M 1 , C M 2 , . . . , C M ∣ A ∣ CM_1, CM_2, ..., CM_{|A|} CM1,CM2,...,CM∣A∣表示它们,其中A对应于可搜索属性的集合。每个𝐶𝑀𝑖是一个大小为𝑤×𝑑的数组,附带了𝑑个成对独立的哈希函数 h i 1 ( ⋅ ) , h i 2 ( ⋅ ) , . . . h i d ( ⋅ ) h^1_i(\cdot),h^2_i(\cdot),...h^d_i(\cdot) hi1(⋅),hi2(⋅),...hid(⋅)(类似于计数-最小草图)。然而,与传统的CM草图不同,𝐶𝑀𝑖中的每个单元格包含记录标识符列表(rids),或是它们的指纹。根据记录在相应属性上的值,rids被放置或哈希到每个草图中。在执行查询时,会查询与查询谓词对应的属性草图,并对这些草图检索到的记录标识符进行交集运算,以计算答案的估计值。图2说明了一个样本数据集的通用草图架构,该数据集具有可搜索属性:<ipSrc, ipDest, totalLen, dscp>。三种草图之间的差异在于:(a) 记录标识符如何在属性草图中被抽样和存储,以及 (b) 支持估计算法的理论,这影响了界限的紧密性。
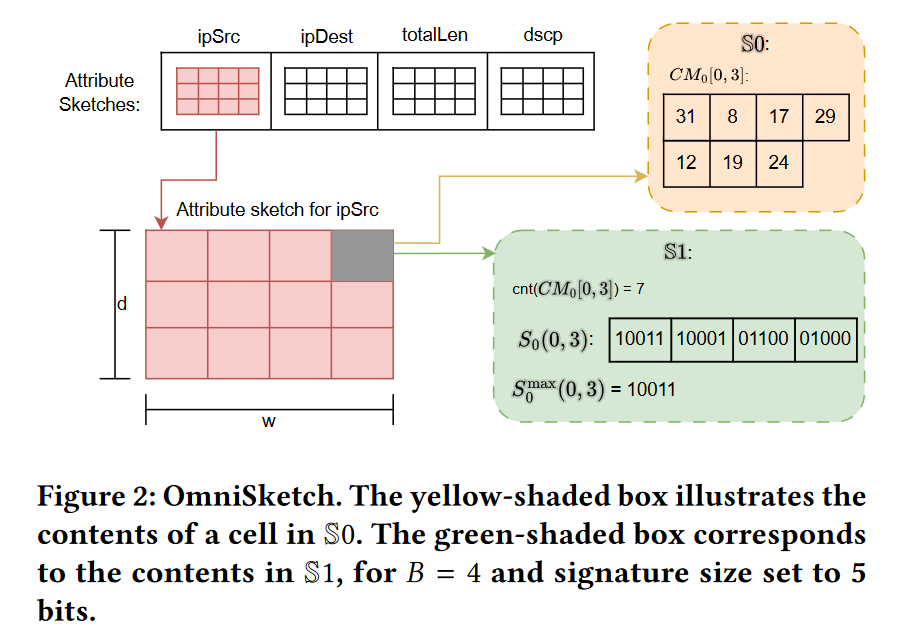
在接下来的讨论中,我们使用A = {𝑎1, 𝑎2, …, 𝑎|A|}表示可搜索属性的集合,𝑞表示含有𝑝个谓词的查询,而𝑞𝑖表示属性𝑎𝑖 ∈ A的谓词。为了简化表述,除非特别说明,我们假定每个谓词𝑞𝑖是在属性𝑎𝑖上对常数值𝑣𝑞𝑖的等值谓词;也就是说,𝑞𝑖 := (𝑎𝑖 = v q i v_{qi} vqi)。每个属性𝑎𝑖的域用D(𝑎𝑖)表示。
不失一般性,我们假设𝑞包含了A的所有属性,即𝑝 = |A|(如果某些属性没有包含在查询中,我们在执行查询时简单地忽略相应的草图);通常情况下,𝑝 ≤ |A|。我们用表1总结了常用的符号。
3.1 Sketch S0:Count-Min with rid-sets 用于估计带有谓词的查询
初始化。在初始化阶段,我们随机均匀地选择|A|×𝑑个成对独立的哈希函数 ℎ11(·), ℎ12(·), …, ℎ𝑑|A|(·),其中每个函数满足 ℎ𝑗𝑖(): D(𝑎𝑖) → {1, …, 𝑤} 的映射规则。此外,我们构建了|A|个大小为𝑤×𝑑的数组𝐶𝑀1, 𝐶𝑀2, …, 𝐶𝑀|A|,并将它们的每一个单元格初始化为包含一个空链表。为了获得估计值的(𝜖, 𝛿)保证,我们将𝑤设定为1 + ⌈𝑒/𝜖⌉ = Θ(1/𝜖),并将𝑑设定为⌈ln(1/𝛿)⌉。
插入。一条新记录 r r r 需要被添加到所有的 ∣ A ∣ |A| ∣A∣ 个草图中。我们使用 r i r_i ri 表示记录 r r r 在属性 a i a_i ai 上的值,而 r 0 r_0 r0 则表示其唯一的记录标识符(rid)。对于每个可搜索属性 a i a_i ai 和每一行 j = { 1 , . . . , d } j = \{1, ..., d\} j={1,...,d} ,我们将 r 0 r_0 r0 添加到位置 C M i [ j , h i j ( r i ) ] CM_i[j, h^j_i(r_i)] CMi[j,hij(ri)] 处的所有链表中。
请注意,根据定义,S0 结构并不是严格意义上的“草图”,因为通过存储完整的 rid-set,它需要在流长度 N 中呈线性的空间。S0 执行的唯一汇总是通过哈希到 CountMin 存储桶中“模糊”单个属性值。尽管如此,它还是为我们最终的 OmniSketch 解决方案提供了概念上有用的第一步。
S0min估计器。设 f ( q ) f(q) f(q)表示满足查询 q q q 中所有谓词的记录数目。遵循传统的计数-最小(Count-Min)估计程序[6],我们可以按如下方式计算一个估计值 f ^ ( q ) \hat{f}(q) f^(q) :对于每一行 j = { 1 , . . . , d } j = \{1, ..., d\} j={1,...,d} ,我们计算存储在单元格 C M 1 [ j , h 1 j ( v q 1 ) ] , C M 2 [ j , h 2 j ( v q 2 ) ] , . . . , C M p [ j , h p j ( v q p ) ] CM_1[j, h^j_1(vq_1)], CM_2[j, h^j_2(vq_2)], ..., CM_p[j, h^j_p(vq_p)] CM1[j,h1j(vq1)],CM2[j,h2j(vq2)],...,CMp[j,hpj(vqp)] 中所有记录的交集大小。我们对(d)行重复这一过程,并将最小值返回作为一个估计值。形式上表示如下:
f ^ ( q ) = min j = { 1 , . . . , d } ∣ ⋂ q i ∈ q C M i [ j , h j ( v q i ) ] ∣ ( 1 ) \hat{f}(q) = \min_{j=\{1,...,d\}} \left| \bigcap_{q_i \in q} CM_i [ j, h^j(v_{qi}) ] \right| \qquad (1) f^(q)=j={1,...,d}min qi∈q⋂CMi[j,hj(vqi)] (1)
直观地说,交集将包含满足查询的所有记录 r 的 rid,因为对于所有谓词,这些记录将始终在与查询谓词相同的单元格上进行哈希处理,但是,交集也可能包含一些误报,即由于一个或多个随机冲突而在 C M i [ j , h i j ( v q i ) ] CM_i [ j, h^j_i (v_{qi} )] CMi[j,hij(vqi)] 中散列的记录。通过取所有 d 行的最小交集大小,我们尝试将此类误报的影响降至最低。
误差边界。以下引理为方程 1 的估计量提供了概率保证。
引理3.1. 设 f ^ ( q ) \hat{f}(q) f^(q) 是根据公式1在使用 d = ⌈ ln ( 1 δ ) ⌉ d = \lceil\ln(\frac{1}{\delta})\rceil d=⌈ln(δ1)⌉, w = 1 + ⌈ e ϵ ⌉ w = 1 + \lceil\frac{e}{\epsilon}\rceil w=1+⌈ϵe⌉ 构造的草图上提供的估计值。对于含有 p p p 个谓词的查询 q q q :
P r ( ∣ f ^ ( q ) − f ( q ) ∣ ≤ ϵ N ) ≥ 1 − δ ( 2 ) Pr\left(\left|\hat{f}(q) - f(q)\right| \leq \epsilon N\right) \geq 1 - \delta \qquad(2) Pr( f^(q)−f(q) ≤ϵN)≥1−δ(2)
证明。考虑行 j ∈ { 1 , . . . , d } j \in \{1, ..., d\} j∈{1,...,d}。我们定义指示变量 I y , j I_{y,j} Iy,j,当所有满足以下条件的记录(y)时,其值为1:
∀ q i ∈ q [ h i j ( v q i ) = h i j ( y i ) ] ∧ ∃ q i ∈ q [ v q i ≠ y i ] {\forall q_i \in q }[h^j_i(vq_i) = h^j_i(y_i) \;] \land \exists q_i \in q [v_{qi} \neq y_i] ∀qi∈q[hij(vqi)=hij(yi)]∧∃qi∈q[vqi=yi]
非正式地说,上述条件对于所有误报记录成立,即,那些包含在交集中但并不完全满足查询的记录。另外,变量 X j = ∑ y = 1 N − f ( q ) I y , j X_j = \sum_{y=1}^{N-f(q)} I_{y,j} Xj=∑y=1N−f(q)Iy,j 是对行 j j j 的这些误报的计数器。
回想一下,第 j 行的估计量如下: f ^ j ( q ) = ∣ R ∩ j ∣ \hat{f}^j(q) = |R^j_∩| f^j(q)=∣R∩j∣,其中 R ∩ j R^j_∩ R∩j 表示位置 h i j ( v q i ) h^j_i(v_{qi}) hij(vqi) 处的单元格的交集,因为 i = {1, . . . , p}。我们需要证明:(a)所有满足所有谓词的记录都将包含在 R ∩ j R^j_∩ R∩j中,即不会有假阴性,并且(b)假阳性的总数 X X X 是w.h.p.的上限。
对于(a),注意到对于满足 y i = v q i y_i = v_{q_i} yi=vqi的任意记录 y y y ,其中 i = { 1 , … , p } i = \{1, \ldots, p\} i={1,…,p},我们将有 y i = v q i ⇒ h i j ( y i ) = h i j ( v q i ) y_i = v_{q_i} \Rightarrow h^j_{i}(y_i) = h^j_{i}(v_{q_i}) yi=vqi⇒hij(yi)=hij(vqi)。因此,满足所有谓词的所有记录都将被包含在 R ∩ j R^j_ \cap R∩j中。
对于(b),如果对于所有属性 y i y_i yi,当 y i ≠ v q i y_i \neq v_{q_i} yi=vqi时,我们有 h i j ( y i ) = h i j ( v q i ) h^j_{i}(y_i) = h^j_{i}(v_{q_i}) hij(yi)=hij(vqi),则记录将是错误的正例并使 X j X_j Xj的值增加1。令 X k j X^j_{k} Xkj表示在 R ∩ j R^j_\cap R∩j中满足恰好 p − k p-k p−k个谓词的记录数量,即,它们不满足 p p p个谓词中的 k k k个,但由于哈希冲突,它们仍被算法检索。那么, X j = ∑ k = 1 p X k j X_j = \sum^{p}_{k=1} X^j_{k} Xj=∑k=1pXkj。
根据散列函数的构造,具有 y i ≠ v q i y_i \neq v_{qi} yi=vqi的记录 y y y将以概率1/w使得 h j i ( y i ) = h j i ( v q i ) h_{ji}(y_i) = h_{ji}(v_{qi}) hji(yi)=hji(vqi)。由于散列函数是两两独立的,一个与查询 q q q在 k k k个属性上不同的记录散列到相同单元格的概率是 1 / w k 1/w^k 1/wk。因此, E [ X k j ] ≤ ( N − f ( q ) ) / w k \mathbb{E}[X^j_{k}] \leq (N - f(q))/w^k E[Xkj]≤(N−f(q))/wk,并且 E [ X j ] = ∑ k = 1 p E [ X k j ] ≤ ( N − f ( q ) ) ∗ ( 1 / w + 1 / w 2 + . . . + 1 / w p ) = ( N − f ( q ) ) ∗ ( 1 − ( 1 / w ) p ) / ( w − 1 ) \mathbb{E}[X^j] = \sum^{p}_{k=1} \mathbb{E}[X^j_{k}] \leq (N - f(q))*(1/w + 1/w^2 + ... + 1/w^p) = (N - f(q))*(1 - (1/w)^p)/(w - 1) E[Xj]=∑k=1pE[Xkj]≤(N−f(q))∗(1/w+1/w2+...+1/wp)=(N−f(q))∗(1−(1/w)p)/(w−1)。通过设置 w = 1 + ⌈ e / ϵ ⌉ w = 1 + \lceil e/\epsilon\rceil w=1+⌈e/ϵ⌉,我们得到 E [ X ] = ( N − f ( q ) ) / e ∗ ( 1 − ϵ p ) / ϵ ≤ ϵ ( N − f ( q ) ) / e ≤ ϵ N / e \mathbb{E}[X] = (N - f(q))/e * (1 - \epsilon^p)/\epsilon \leq \epsilon(N - f(q))/e \leq \epsilon N/e E[X]=(N−f(q))/e∗(1−ϵp)/ϵ≤ϵ(N−f(q))/e≤ϵN/e。
注意到我们有d行,每行使用不同的散列函数。根据马尔可夫不等式,我们有 [ P r [ X ≥ ϵ ( N − f ( q ) ) ] = P r [ ∀ j ∈ [ 1... d ] . f ^ j ( q ) > f ( q ) + ϵ N ] = P r [ ∀ j ∈ [ 1... d ] . X j > e E [ X ] ] < e − d ] [Pr[X \geq \epsilon(N - f(q))] = Pr[\forall_{j \in [1...d]}. \hat{f}_j(q) > f(q) + \epsilon N] = Pr[\forall_{j \in [1...d]}. X_j > eE[X]] < e^{-d}] [Pr[X≥ϵ(N−f(q))]=Pr[∀j∈[1...d].f^j(q)>f(q)+ϵN]=Pr[∀j∈[1...d].Xj>eE[X]]<e−d],其中 f ( q ) f(q) f(q)表示真实的答案,而 X j X_j Xj表示在第j行的误报数量,即 X j = f ^ j ( q ) − f ( q ) X_j = \hat{f}^j (q) - f(q) Xj=f^j(q)−f(q)。最后的界限可以通过设置 d = ⌈ ln ( 1 / δ ) ⌉ d = \lceil \ln(1/\delta) \rceil d=⌈ln(1/δ)⌉来得到。
S0∩:一个改进的估计器。S0min估计器基于标准Count-Min草图[6]中的传统估算逻辑;也就是说,它按行产生估计,并取所有d行估计的最小值。与标准的Count-Min估算相似,很容易看出S0min只能由于哈希桶碰撞(误报)而高估真实的计数值。然而,与标准的Count-Min相比,S0中的每个桶包含更多可以利用的详细信息,以提供更紧密的估计(即,具有较少的误报)。关键的观察点在于,通过构建S0的方式,满足完整查询的每条记录最终会出现在该查询的所有d行以及所有p个谓词的单元格中,而误报则只可能出现在少数几行中。因此,在不修改草图构造或空间/时间复杂度的情况下,我们可以通过去掉跨行的最小值操作,仅仅对所有d行返回的rid集进行交集运算,就能获得一个更紧密的估计器。我们将这个更紧密的S0估计器称为S0∩,并正式定义如下:
f ^ ( q ) = ∣ ⋂ i = { 1... p } , j = { 1... d } C M i [ j , h j i ( v q i ) ] ∣ ( 3 ) \hat{f}(q) = \left| \bigcap_{i=\{1...p\},j=\{1...d\}} CM_i[j, h_j^i(v_{q_i})] \right| \qquad (3) f^(q)= i={1...p},j={1...d}⋂CMi[j,hji(vqi)] (3)
显然,这个新的S0∩估计器也仅能由于哈希碰撞而高估真实的计数值——同时,它保证了更少的误报,因为它总是小于或等于公式1中的S0min估计。我们现在展示S0∩更强的误差保证,证明它允许我们在不改变草图的空间复杂度的情况下,将误差限定在(\epsilon d (N - f(q)))而不是(\epsilon (N - f(q)))。
引理3.2. 设 f ^ ( q ) \hat{f}(q) f^(q)是使用公式3在由 d = ⌈ ln ( 1 δ ) ⌉ d = \lceil \ln(\frac{1}{\delta}) \rceil d=⌈ln(δ1)⌉, w = 1 + ⌈ e ϵ ⌉ w = 1 + \lceil e^{\epsilon} \rceil w=1+⌈eϵ⌉构建的草图上提供的估计值。对于有p个谓词的查询q:
P ( ∣ f ^ ( q ) − f ( q ) ∣ ≤ ϵ d ( N − f ( q ) ) ≤ ϵ d N ) ≥ 1 − δ P\left( \left| \hat{f}(q) - f(q) \right| \leq \epsilon^d (N - f(q)) \leq \epsilon^d N \right) \geq 1-\delta P( f^(q)−f(q) ≤ϵd(N−f(q))≤ϵdN)≥1−δ
证明。证明类似于引理3.1的证明。我们定义指示变量 I y I_y Iy,当所有记录y满足以下条件时,它的值为1:
∀ q i ∈ q [ ∀ 1 ≤ j ≤ d [ h j i ( v q i ) = h j i ( y i ) ] ∧ ∃ q i ∈ q [ v q i ≠ y i ] ] \forall_{q_i \in q} [\forall _{1 \leq j \leq d} [h_j^i(v_{q_i}) = h_j^i(y_i)] \land \exists_{q_i \in q} [v_{q_i} \neq y_i]] ∀qi∈q[∀1≤j≤d[hji(vqi)=hji(yi)]∧∃qi∈q[vqi=yi]]
非正式地说, I y I_y Iy对于所有假正例记录变为1,即那些在所有d行和所有p个谓词下,哈希到与查询谓词值相同的单元格的记录。此外, X = ∑ y = 1 N − f ( q ) I y X = \sum_{y=1}^{N-f(q)} I_y X=∑y=1N−f(q)Iy是对假正例记录总数的计数器。
我们将证明以下两点:(a) 所有满足所有谓词的记录都将包含在 ⋂ j = 1 d R ∩ j \bigcap_{j=1}^{d} R^j_∩ ⋂j=1dR∩j 中,即不会有假阴性;以及,(b) 假阳性记录的数量 X X X 高概率下有界。
对于(a),注意到对于任何记录 y y y 满足 y i = v q i y_i = v_{q_i} yi=vqi 对于 i = { 1... p } i = \{1 ... p\} i={1...p},我们会有 y i = v q i ⇒ ∀ 1 ≤ j ≤ d [ h i j ( y i ) = h i j ( v q i ) ] y_i = v_{q_i} \Rightarrow \forall _{1 \leq j \leq d} [h^j_i(y_i) = h^j_i(v_{q_i})] yi=vqi⇒∀1≤j≤d[hij(yi)=hij(vqi)]。因此,所有满足所有谓词的记录都将包含在所有 R ∩ j R^j_∩ R∩j 的交集中,记作 R ∩ R_∩ R∩。
对于(b),一个记录 y y y 如果对于所有属性 y i y_i yi (其中 y i ≠ v q i y_i \neq v_{q_i} yi=vqi)和所有行 j ∈ { 1... d } j \in \{1 ... d\} j∈{1...d},它与 h i j ( v q i ) h_i^j(v_{q_i}) hij(vqi) 发生冲突,即 h i j ( y i ) = h i j ( v q i ) h_i^j(y_i) = h_i^j(v_{q_i}) hij(yi)=hij(vqi),则会增加 X X X 的值。在单一行 j j j 上发生这种冲突的概率是 P r [ h i j ( y i ) = h i j ( v q i ) ] = 1 / w Pr[h_i^j(y_i) = h_i^j(v_{q_i})] = 1/w Pr[hij(yi)=hij(vqi)]=1/w。此外,由于哈希函数在草图行之间是独立的,一个记录在所有 d d d 行 j j j 上与查询发生碰撞的概率将是 1 / w d 1/w^d 1/wd。
令 X k X_k Xk 表示来自 R R R 的记录数量,这些记录恰好满足 p − k p-k p−k 个谓词。那么, E [ X k ] ≤ ( N − f ( q ) ) / w k d E[X_k] \leq (N - f(q))/w^{kd} E[Xk]≤(N−f(q))/wkd,并且 E [ X ] = ∑ k = 1 p E [ X k ] ≤ ( N − f ( q ) ) ∑ k = 1 p 1 / w k d = ( N − f ( q ) ) 1 − w − d ( p + 1 ) w d − 1 < ( N − f ( q ) ) / ( w d − 1 ) E[X] = \sum_{k=1}^{p} E[X_k] \leq (N - f(q)) \sum_{k=1}^{p} 1/w^{kd} = (N - f(q)) \frac{1-w^{-d(p+1)}}{w^d-1} < (N - f(q))/(w^d - 1) E[X]=∑k=1pE[Xk]≤(N−f(q))∑k=1p1/wkd=(N−f(q))wd−11−w−d(p+1)<(N−f(q))/(wd−1)。通过设置 w = 1 + ⌈ e / ϵ ⌉ w = 1 + \lceil e/\epsilon \rceil w=1+⌈e/ϵ⌉,我们得到 E [ X ] ≤ ( N − f ( q ) ) / ( ( 1 + e / ϵ ) d − 1 ) ≤ ϵ d ( N − f ( q ) ) / e d E[X] \leq (N - f(q))/((1 + e/\epsilon)^d - 1) \leq \epsilon^d (N - f(q))/e^d E[X]≤(N−f(q))/((1+e/ϵ)d−1)≤ϵd(N−f(q))/ed。
下面的界限直接来自于马尔科夫不等式: P r [ X ≥ ϵ d ( N − f ( q ) ) ] = P r [ X ≥ e d E [ X ] ] ≤ e − d Pr[X \geq \epsilon^d (N - f(q))] = Pr[X \geq e^d E[X]] \leq e^{-d} Pr[X≥ϵd(N−f(q))]=Pr[X≥edE[X]]≤e−d
然后,通过设置 d = ⌈ ln ( 1 / δ ) ⌉ d = \lceil \ln(1/\delta) \rceil d=⌈ln(1/δ)⌉ 我们得到最终的界限, P r [ X ≥ ϵ d ( N − f ( q ) ) ] ≤ δ ⇒ P r [ X ≥ ϵ d N ] ≤ δ Pr[X \geq \epsilon^d (N - f(q))] \leq \delta \Rightarrow Pr[X \geq \epsilon^d N] \leq \delta Pr[X≥ϵd(N−f(q))]≤δ⇒Pr[X≥ϵdN]≤δ。
3.2 Sketch S1 (OmniSketch):通过采样实现亚线性空间
草图S0存储所有记录的ID,导致空间复杂度为 O ( d × ∣ A ∣ × N ) O(d \times |A| \times N) O(d×∣A∣×N),这对于大规模数据流来说是不可行的。我们的全功能OmniSketch(在下文中也标记为S1),通过对属性草图单元格中的rids取样并维护这些样本,采用K-minwise散列算法[22],实现了严格亚线性的空间复杂度于N。我们现在描述我们的OmniSketch解决方案,假设两个关键参数(每个单元的最大样本大小B和采样哈希函数的范围[0, 2^b-1])已经设定。本节稍后将解释如何确定这些值。
与S0类似,S1由|A|个属性草图组成。此外,S1集成了一个哈希函数 g : D ( r 0 ) → { 0 , 1 } b g: D(r_0) \rightarrow \{0, 1\}^b g:D(r0)→{0,1}b,将每个记录ID映射到长度为b的位串上,其中b至少设为 ⌈ log ( 4 B 2.5 / δ ) ⌉ ⌈\log(4B^{2.5}/\delta)⌉ ⌈log(4B2.5/δ)⌉。函数g对K-minwise散列(第2节)是必要的。|A|个属性草图 C M 1 , C M 2 , . . . , C M ∣ A ∣ CM_1, CM_2, ..., CM_{|A|} CM1,CM2,...,CM∣A∣ 都具有相同的大小 w × d w \times d w×d。每个草图单元 C M i [ j , k ] CM_i[j, k] CMi[j,k] 包含:(a) 在该单元中被哈希的所有项目的计数,记作 c n t ( C M i [ j , k ] ) cnt(CM_i[j, k]) cnt(CMi[j,k]);(b) 最大尺寸为B的minwise样本 S i ( j , k ) S_i(j, k) Si(j,k),包含了所有在该单元中被哈希的记录 r r r 的rid哈希值 g ( r 0 ) g(r_0) g(r0);以及,(c ) 所有包含在 S i ( j , k ) S_i(j, k) Si(j,k) 中项的最大哈希值,记作 S i m a x ( j , k ) S^{max}_i(j, k) Simax(j,k)。值得注意的是, c n t ( C M i [ j , k ] ) cnt(CM_i[j, k]) cnt(CMi[j,k]) 还包括那些在 C M i [ j , k ] CM_i[j, k] CMi[j,k] 中被哈希但未进入样本的项目,而且在一个人口密集的草图中,它的值预期会远大于B。图2(绿色阴影框)展示了一个已填充单元的内容示例,其中B=4,b=5。
初始化。用户选择期望的误差保证( ϵ \epsilon ϵ, δ \delta δ),其中 ϵ < 0.25 \epsilon < 0.25 ϵ<0.25。令( ϵ 1 \epsilon_1 ϵ1, δ 1 \delta_1 δ1)和( ϵ 2 \epsilon_2 ϵ2, δ 2 \delta_2 δ2)分别对应minwise采样算法和属性草图的( ϵ \epsilon ϵ, δ \delta δ)配置,且 ϵ 1 = ϵ \epsilon_1 = \epsilon ϵ1=ϵ, ϵ 2 = ( ϵ / ( 1 + ϵ ) ) 1 / d \epsilon_2 = (\epsilon/(1 + \epsilon))^{1/d} ϵ2=(ϵ/(1+ϵ))1/d,以及 δ 1 = δ 2 = δ / 2 \delta_1 = \delta_2 = \delta/2 δ1=δ2=δ/2。我们通过选择与S0相似的 w w w和 d d d来初始化所有属性草图。这些草图中的每个单元格初始化为空样本 S i ( j , k ) S_i(j, k) Si(j,k),并且 c n t ( C M i [ j , k ] ) = 0 cnt(CM_i[j, k]) = 0 cnt(CMi[j,k])=0和 S i m a x ( j , k ) = ∞ S_i^{max}(j, k) = ∞ Simax(j,k)=∞。
插入操作。为了将新记录 r r r添加到草图中,我们首先定位在|A|个草图中与 r r r的值对应的单元格(算法1,第2-4行)。这些单元格是 C ( r ) = { C M i [ j , h i j ( r i ) ] : i = { 1 , . . . , ∣ A ∣ } , j = { 1 , . . . , d } } C(r) = \{CM_i[j, h_i^j(r_i)] : i = \{1, ..., |A|\}, j = \{1, ..., d\}\} C(r)={CMi[j,hij(ri)]:i={1,...,∣A∣},j={1,...,d}}。对于这些单元格 C M i [ j , k ] ∈ C ( r ) CM_i[j, k] \in C(r) CMi[j,k]∈C(r)中的每一个,我们将 c n t ( C M i [ j , k ] ) cnt(CM_i[j, k]) cnt(CMi[j,k])增加一(第5行)。然后,我们检查 g ( r 0 ) g(r_0) g(r0)是否应该被添加到该单元格的样本中(第6-10行),具体如下。如果样本包含少于 B B B个项目,则将 g ( r 0 ) g(r_0) g(r0)添加到其中。另一方面,如果 ∣ S i ( j , k ) ∣ = B |S_i(j, k)| = B ∣Si(j,k)∣=B且 g ( r 0 ) < S i m a x ( j , k ) g(r_0) < S_i^{max}(j, k) g(r0)<Simax(j,k)(即样本已满,但新记录的ID具有比样本中另一个记录更小的哈希值 g g g),我们从样本中移除 S i m a x ( j , k ) S_i^{max}(j, k) Simax(j,k)以为 g ( r 0 ) g(r_0) g(r0)腾出空间。最后,我们将 g ( r 0 ) g(r_0) g(r0)添加到 S i ( j , k ) S_i(j, k) Si(j,k)中,并重新计算 S i m a x ( j , k ) S_i^{max}(j, k) Simax(j,k)。插入元素的复杂度为 O ( ∣ A ∣ × d × log ( B ) ) O(|A| \times d \times \log(B)) O(∣A∣×d×log(B))。

OmniSketch 查询估计。设 q q q表示输入查询。如同S0一样,我们假设 q q q包含所有A属性,即 p = ∣ A ∣ p = |A| p=∣A∣;如果一个属性未包含在 q q q中,估计器会简单地忽略相应的属性草图。每个查询属性值 v q i v_{q_i} vqi使用对应草图 C M i CM_i CMi的 d d d个哈希函数进行哈希处理,这导致每个草图有 d d d个单元格。设 C ( q ) C(q) C(q)表示跨所有草图的单元格集合,这些单元格用于回答查询,即 C ( q ) = { C M i [ j , h j ( v q i ) ] : i = { 1... p } , j = { 1... d } } C(q) = \{CM_i[j, h^j(v_{q_i})] : i = \{1 ... p\}, j = \{1 ... d\}\} C(q)={CMi[j,hj(vqi)]:i={1...p},j={1...d}},而 n m a x = m a x C M i [ j , k ] ∈ C ( q ) c n t ( C M i [ j , k ] ) n_{max} = max_{CM_i[j,k] \in C(q)} cnt(CM_i[j, k]) nmax=maxCMi[j,k]∈C(q)cnt(CMi[j,k])是这些单元格的最大计数值。
遵循我们改进的S0∩估计器的推理,设 S ∩ = ⋂ i = { 1... p } , j = { 1... d } S i ( j , h j ( v q i ) ) S_{\cap} = \bigcap_{i=\{1...p\},j=\{1...d\}} S_i(j, h^j(v_{q_i})) S∩=i={1...p},j={1...d}⋂Si(j,hj(vqi))表示存储在 C ( q ) C(q) C(q)中所有单元格内的所有样本的交集。我们的OmniSketch估计器 f ^ ( q ) \hat{f}(q) f^(q)按以下方式计算:
f ^ ( q ) = n m a x B × ∣ S ∩ ∣ ( 4 ) \hat{f}(q) = \frac{n_{max}}{ B} \times |S_{\cap}| \qquad (4) f^(q)=Bnmax×∣S∩∣(4)
直观上讲,这个估计器计算在 C ( q ) C(q) C(q)中所有样本的交集的基数,并将其乘以 n m a x B \frac{n_{max}}{ B} Bnmax的倍数,以考虑到采样的影响。根据K-minwise哈希分析[22],我们的估计器具有一个合理范围的边界,即 3 n m a x log ( 4 p d B / δ ) B ϵ 2 \frac{3n_{max} \log(4pd\sqrt{B}/\delta)}{ B\epsilon^2} Bϵ23nmaxlog(4pdB/δ),以覆盖交集中样本不足的情况。这一边界确保了即使在样本数量有限的情况下,估计值也能保持在合理的范围内,避免了显著的偏差。
高效计算交集。计算 ∣ S ∩ ∣ |S_{\cap}| ∣S∩∣需要在参与查询的所有样本之间进行多路连接。对于较大的 B B B值,朴素的基于哈希的交集计算可能需要数百毫秒。为了加速查询执行,我们利用了一个事实,即每个单元格中的样本已经存储在一个红黑树中,这允许以对数复杂度进行排序迭代和搜索。我们的代码是对多路连接的sort-merge join算法的扩展。从第一个单元格开始,我们获取第一个样本(具有最小哈希值的那个),并在所有其他单元格上执行查找,检查这个哈希值是否包含在它们的样本中。一旦我们找到一个不包含这个样本的单元格,我们就从该单元格中获取具有比失败值更大的哈希值的最小样本,并从这个值恢复搜索(在失败值和这个值之间的其他值不可能是连接的一部分)。一个有趣的观察结果,这在我们的实验结果中也变得显而易见(见第4节),是在回答具有更多谓词的查询时,这个算法通常变得更有效率,因为它允许更大的步长。例如,如果其中一个单元格包含非常少的样本,这个单元格将导致跳过所有其他单元格上的许多候选记录。这可以将查询执行的复杂度从 O ( p ∗ d ∗ B ∗ log ( B ) ) O(p * d * B * \log(B)) O(p∗d∗B∗log(B))有效地降低到实际上的 O ( B log ( B ) ) O(B \log(B)) O(Blog(B))。
误差界限的推导。 f ^ ( q ) \hat{f}(q) f^(q)有两个错误来源:(a)由于K-minwise哈希采样导致的低估或高估,以及(b)由于外部Count-Min结构中的哈希冲突导致的(单侧)高估。我们首先提供一个仅与哈希冲突无关的采样误差边界,然后将由哈希冲突引起的误差整合进来。回想一下, ( ϵ 1 , δ 1 ) (\epsilon_1, \delta_1) (ϵ1,δ1)和 ( ϵ 2 , δ 2 ) (\epsilon_2, \delta_2) (ϵ2,δ2)分别对应K-minwise采样算法和属性草图的 ( ϵ , δ ) (\epsilon, \delta) (ϵ,δ)配置。
我们使用 R ( C M i [ j , k ] ) R(CM_i[j, k]) R(CMi[j,k])来表示所有被哈希到 C M i [ j , k ] CM_i[j, k] CMi[j,k]的记录,即使它们最终没有进入样本,而 R ∩ = ⋂ C M i [ j , k ] ∈ C ( q ) R ( C M i [ j , k ] ) R_{\cap} = \bigcap_{CM_i[j,k] \in C(q)} R(CM_i[j, k]) R∩=⋂CMi[j,k]∈C(q)R(CMi[j,k])表示在 C ( q ) C(q) C(q)中的所有单元格中被哈希的所有记录的交集。最后, S i ( j , k ) S_i(j, k) Si(j,k)表示在单元格 C M i [ j , k ] CM_i[j, k] CMi[j,k]收集的样本,而 S ∩ S_{\cap} S∩表示在 C ( q ) C(q) C(q)中所有单元格的样本的交集。
下面的定理和推论提供了我们OmniSketch估计器的误差保证。(需要注意的是,在任何现实场景中, n m a x ≪ N n_{max} \ll N nmax≪N。)
定理3.3。考虑一个带有 ϵ 1 = ϵ \epsilon_1 = \epsilon ϵ1=ϵ, ϵ 2 = ( ϵ 1 + ϵ ) 1 / d \epsilon_2 = (\frac{\epsilon}{1+\epsilon})^{1/d} ϵ2=(1+ϵϵ)1/d,和 δ 1 = δ 2 = δ / 2 \delta_1 = \delta_2 = \delta/2 δ1=δ2=δ/2的OmniSketch。如果 ∣ S ∩ ∣ |S_{\cap}| ∣S∩∣小于 3 log ( 4 p d B / δ ) ϵ 2 \frac{3\log(4pd\sqrt{B}/\delta)}{\epsilon^2} ϵ23log(4pdB/δ),设置 f ^ ( q ) = 2 n m a x log ( 4 p d B / δ ) B ϵ 2 \hat{f}(q) = \frac{2n_{max}\log(4pd\sqrt{B}/\delta)}{B\epsilon^2} f^(q)=Bϵ22nmaxlog(4pdB/δ)满足 ∣ f ( q ) − f ^ ( q ) ∣ < 2 n m a x log ( 4 p d B / δ ) B ϵ 2 |f(q) - \hat{f}(q)| < \frac{2n_{max}\log(4pd\sqrt{B}/\delta)}{B\epsilon^2} ∣f(q)−f^(q)∣<Bϵ22nmaxlog(4pdB/δ)的概率至少为 1 − δ / 2 1 - \delta/2 1−δ/2。否则,设置 f ^ ( q ) = n m a x B × ∣ S ∩ ∣ \hat{f}(q) = n_{max}B \times |S_{\cap}| f^(q)=nmaxB×∣S∩∣满足 ∣ f ( q ) − f ^ ( q ) ∣ ≤ ϵ N |f(q) - \hat{f}(q)| \leq \epsilon N ∣f(q)−f^(q)∣≤ϵN的概率至少为 1 − δ 1 - \delta 1−δ。
证明。我们将证明分为两种情况,依据 ∣ S ∩ ∣ |S_{\cap}| ∣S∩∣的值来进行讨论:
情况1:首先,我们考察 ∣ S ∩ ∣ |S_{\cap}| ∣S∩∣不超过特定阈值的情况,即 ∣ S ∩ ∣ |S_{\cap}| ∣S∩∣ ≤ 3 log ( 2 p d B / δ 1 ) ϵ 1 2 \frac{3\log(2pd\sqrt{B}/\delta_1)}{\epsilon_1^2} ϵ123log(2pdB/δ1)。根据文献[22]中的定理4,并且将该定理中的 δ \delta δ设置为 δ 1 / B \delta_1/\sqrt{B} δ1/B,我们可以得出结论, ∣ R ∩ ∣ |R_{\cap}| ∣R∩∣的范围为 0 ≤ ∣ R ∩ ∣ ≤ 4 n m a x log ( 2 p d B / δ 1 ) B ϵ 1 2 0 \leq |R_{\cap}| \leq \frac{4n_{max}\log(2pd\sqrt{B}/\delta_1)}{B\epsilon_1^2} 0≤∣R∩∣≤Bϵ124nmaxlog(2pdB/δ1)。
我们知道 f ( q ) f(q) f(q)不会超过 ∣ R ∩ ∣ |R_{\cap}| ∣R∩∣,因为后者可能包含那些不完全满足查询谓词的虚假记录(由于哈希碰撞,这些记录仍可能出现在 C ( q ) C(q) C(q)的所有单元格中)。因此,我们有 f ( q ) ≤ ∣ R ∩ ∣ f(q) \leq |R_{\cap}| f(q)≤∣R∩∣,进而得到 f ( q ) ≤ 4 n m a x log ( 2 p d B / δ 1 ) B ϵ 1 2 f(q) \leq \frac{4n_{max}\log(2pd\sqrt{B}/\delta_1)}{B\epsilon_1^2} f(q)≤Bϵ124nmaxlog(2pdB/δ1)。通过返回 f ^ ( q ) = 2 n m a x log ( 2 p d B / δ 1 ) B ϵ 1 2 \hat{f}(q) = \frac{2n_{max}\log(2pd\sqrt{B}/\delta_1)}{B\epsilon_1^2} f^(q)=Bϵ122nmaxlog(2pdB/δ1),我们确保了 ∣ f ^ ( q ) − f ( q ) ∣ ≤ f ^ ( q ) |\hat{f}(q) - f(q)| \leq \hat{f}(q) ∣f^(q)−f(q)∣≤f^(q)的概率为 1 − δ 1 1 - \delta_1 1−δ1。进一步,通过设定 δ 1 = δ / 2 \delta_1 = \delta/2 δ1=δ/2以及 ϵ 1 = ϵ \epsilon_1 = \epsilon ϵ1=ϵ,我们得到了此情况下的最终估计量 f ^ ( q ) = 2 n m a x log ( 4 p d B / δ ) B ϵ 2 \hat{f}(q) = \frac{2n_{max}\log(4pd\sqrt{B}/\delta)}{B\epsilon^2} f^(q)=Bϵ22nmaxlog(4pdB/δ),并确保了 ∣ f ^ ( q ) − f ( q ) ∣ ≤ 2 n m a x log ( 4 p d B / δ ) B ϵ 2 |\hat{f}(q) - f(q)| \leq \frac{2n_{max}\log(4pd\sqrt{B}/\delta)}{B\epsilon^2} ∣f^(q)−f(q)∣≤Bϵ22nmaxlog(4pdB/δ)的概率大于等于 1 − δ 1 = 1 − δ / 2 1 - \delta_1 = 1 - \delta/2 1−δ1=1−δ/2。
情况2:接下来,考虑 ∣ S ∩ ∣ |S_{\cap}| ∣S∩∣超过特定阈值的情况,即 ∣ S ∩ ∣ |S_{\cap}| ∣S∩∣ > 3 log ( 2 p d B / δ 1 ) ϵ 1 2 \frac{3\log(2pd\sqrt{B}/\delta_1)}{\epsilon_1^2} ϵ123log(2pdB/δ1)。同样根据文献[22]中的定理4,我们有 n m a x B ∣ S ∩ ∣ = ( 1 ± ϵ 1 ) ∣ R ∩ ∣ ( 5 ) \frac{n_{max}}{B} |S_{\cap}| = (1 \pm \epsilon_1)|R_{\cap}| \qquad (5) Bnmax∣S∩∣=(1±ϵ1)∣R∩∣(5),其发生的概率至少为 1 − δ 1 1 - \delta_1 1−δ1。然而,需要注意的是,由于哈希碰撞,不是所有的 R ∩ R_{\cap} R∩中的记录(因此也是 S ∩ S_{\cap} S∩中的记录)都会完全满足查询条件。我们可以使用引理3.2来估计 R ∩ R_{\cap} R∩中的虚假正例数量: ∣ F P ∣ = ∣ ∣ R ∩ ∣ − f ( q ) ∣ ≤ ϵ 2 d N − f ( q ) 2 |FP| = ||R_{\cap}| - f(q)| \leq \epsilon^d_2 \frac{N-f(q)}{2} ∣FP∣=∣∣R∩∣−f(q)∣≤ϵ2d2N−f(q),其发生的概率为 1 − δ 2 1 - \delta_2 1−δ2
由式(5)及三角不等式,我们有 ∣ n m a x B ∣ S ∩ ∣ − f ( q ) ∣ ≤ ∣ n m a x B ∣ S ∩ ∣ − ∣ R ∩ ∣ ∣ + ( ∣ R ∩ ∣ − f ( q ) ) | \frac{n_{max}}{B}|S_{\cap}| - f(q)| \leq | \frac{n_{max}}{B}|S_{\cap}| - |R_{\cap}|| + (|R_{\cap}| - f(q)) ∣Bnmax∣S∩∣−f(q)∣≤∣Bnmax∣S∩∣−∣R∩∣∣+(∣R∩∣−f(q)) ≤ ϵ 1 ∣ R ∩ ∣ + ϵ 2 d ( N − f ( q ) ) \leq \epsilon_1|R_{\cap}| + \epsilon^d_{2}(N - f(q)) ≤ϵ1∣R∩∣+ϵ2d(N−f(q)) ≤ ϵ 1 ( f ( q ) + ϵ 2 d ( N − f ( q ) ) ) + ϵ 2 d ( N − f ( q ) ) \leq \epsilon_1(f(q) + \epsilon^d_{2}(N - f(q))) + \epsilon^d_{2}(N - f(q)) ≤ϵ1(f(q)+ϵ2d(N−f(q)))+ϵ2d(N−f(q)),其发生的概率至少为 1 − δ 1 − δ 2 1 - \delta_1 - \delta_2 1−δ1−δ2。
为了简化表达,设 c = f ( q ) N c = \frac{f(q)}{N} c=Nf(q)。则: ∣ n m a x B ∣ S ∩ ∣ − f ( q ) ∣ ≤ ϵ 1 ( c N + ϵ 2 d ( N − c N ) ) + ϵ 2 d ( N − c N ) |\frac{n_{max}}{B}|S_{\cap}| - f(q)| \leq \epsilon_1(cN + \epsilon^d_{2}(N - cN)) + \epsilon^d_{2}(N - cN) ∣Bnmax∣S∩∣−f(q)∣≤ϵ1(cN+ϵ2d(N−cN))+ϵ2d(N−cN) ≤ N [ ϵ 1 c + ϵ 1 ϵ 2 d ( 1 − c ) + ϵ 2 d ( 1 − c ) ] \leq N[\epsilon_1c + \epsilon_1\epsilon^d_{2}(1 - c) + \epsilon^d_{2}(1 - c)] ≤N[ϵ1c+ϵ1ϵ2d(1−c)+ϵ2d(1−c)] = N [ ϵ 2 d ( ϵ 1 + 1 ) − c ( ϵ 1 ϵ 2 d + ϵ 2 d − ϵ 1 ) ] = N[\epsilon^d_{2}(\epsilon_1 + 1) - c (\epsilon_1\epsilon^d_{2} + \epsilon^d_{2} - \epsilon_1)] =N[ϵ2d(ϵ1+1)−c(ϵ1ϵ2d+ϵ2d−ϵ1)]
通过设置 ϵ 1 = ϵ < 1 / 4 \epsilon_1 = \epsilon < 1/4 ϵ1=ϵ<1/4, ϵ 2 = ( ϵ 1 + ϵ ) 1 / d \epsilon_2 = (\frac{\epsilon}{1 + \epsilon})^{1/d} ϵ2=(1+ϵϵ)1/d, δ 1 = δ 2 = δ / 2 \delta_1 = \delta_2 = \delta/2 δ1=δ2=δ/2,我们得到 ∣ n m a x B ∣ S ∩ ∣ − f ( q ) ∣ ≤ ϵ N |\frac{n_{max}}{B}|S_{\cap}| - f(q)| \leq \epsilon N ∣Bnmax∣S∩∣−f(q)∣≤ϵN,其发生的概率为 1 − δ 1 − δ 2 1 - \delta_1 - \delta_2 1−δ1−δ2。
以下推论简化了估计过程,始终使用针对情况2提出的估计量。
推论3.4:设 f ^ ( q ) = n m a x B × ∣ S ∩ ∣ \hat{f}(q) = \frac{n_{max}}{B} \times |S_{\cap}| f^(q)=Bnmax×∣S∩∣。如果 ∣ S ∩ ∣ < 3 n m a x log ( 4 p d B / δ ) B ϵ 2 |S_{\cap}| < \frac{3n_{max}\log(4pd\sqrt{B}/\delta)}{B\epsilon^2} ∣S∩∣<Bϵ23nmaxlog(4pdB/δ),那么 ∣ f ( q ) − f ^ ( q ) ∣ ≤ 4 n m a x log ( 4 p d B / δ ) B ϵ 2 |f(q) - \hat{f}(q)| \leq \frac{4n_{max}\log(4pd\sqrt{B}/\delta)}{B\epsilon^2} ∣f(q)−f^(q)∣≤Bϵ24nmaxlog(4pdB/δ)的概率至少为 1 − δ / 2 1 - \delta/2 1−δ/2。否则,同样的估计量满足 ∣ f ( q ) − f ^ ( q ) ∣ ≤ ϵ N |f(q) - \hat{f}(q)| \leq \epsilon N ∣f(q)−f^(q)∣≤ϵN的概率至少为 1 − δ 1 - \delta 1−δ。
推论直接源自上述定理,观察到当 ∣ S ∩ ∣ |S_{\cap}| ∣S∩∣小于 3 n m a x log ( 4 p d B / δ ) B ϵ 2 \frac{3n_{max}\log(4pd\sqrt{B/\delta})}{B\epsilon^2} Bϵ23nmaxlog(4pdB/δ)时, f ( q ) f(q) f(q)有很大概率落在 { 0 , 4 n m a x log ( 4 p d B / δ ) B ϵ 2 } \{0, \frac{4n_{max}\log(4pd\sqrt{B/\delta})}{B\epsilon^2}\} {0,Bϵ24nmaxlog(4pdB/δ)}集合内,并且估计量 f ^ ( q ) \hat{f}(q) f^(q)同样位于该范围内。因此,在高概率下,估计量 f ^ ( q ) \hat{f}(q) f^(q)与真实值 f ( q ) f(q) f(q)之间的差距不会超过 4 n m a x log ( 4 p d B / δ ) B ϵ 2 \frac{4n_{max}\log(4pd\sqrt{B/\delta})}{B\epsilon^2} Bϵ24nmaxlog(4pdB/δ)。
复杂度分析:
- 空间复杂度:结构 S 1 S1 S1的空间复杂度为 O ( w × d × B × b × ∣ A ∣ ) \mathcal{O}(w \times d \times B \times b \times |A|) O(w×d×B×b×∣A∣)。
- 查询执行的计算复杂度:为 O ( p × d × B × log ( B ) ) \mathcal{O}(p \times d \times B \times \log(B)) O(p×d×B×log(B))。
- 插入操作的计算复杂度:为 O ( ∣ A ∣ × d × log ( B ) ) \mathcal{O}(|A| \times d \times \log(B)) O(∣A∣×d×log(B)),其中最后一个对数项用于维护样本有序集合,加速插入过程。
配置概要图:用户首先设定可用内存 M M M(单位:比特),以及误差界限 ϵ \epsilon ϵ和置信水平 δ \delta δ的值。随后,计算 w w w和 d d d的值,其中 w = 1 + ⌈ e ∗ ( ( ϵ + 1 ) / ϵ ) 1 / d ⌉ = Θ ( ( 1 / ϵ ) 1 / d ) w = 1+\lceil e*((\epsilon+1)/\epsilon)^{1/d} \rceil = \Theta((1/\epsilon)^{1/d}) w=1+⌈e∗((ϵ+1)/ϵ)1/d⌉=Θ((1/ϵ)1/d), d = ⌈ ln ( 2 / δ ) ⌉ d = \lceil\ln(2/\delta)\rceil d=⌈ln(2/δ)⌉。为了不超出内存配额 M M M,用户需要选择满足 M ≥ w ∗ d ∗ ∣ A ∣ ∗ ( 32 + B ∗ ( ⌈ log ( 4 B 2.5 / δ ) ⌉ + 3 ∗ 32 + 1 ) ) M \geq w * d * |A| * (32 + B * (\lceil\log(4B^{2.5}/\delta)\rceil + 3 * 32 + 1)) M≥w∗d∗∣A∣∗(32+B∗(⌈log(4B2.5/δ)⌉+3∗32+1))条件的最大 B B B值。
3.3 扩展
支持范围查询的扩展。所有提出的概要图都支持数值属性上的范围查询,以及范围和点谓词的组合,例如,计算具有 112.1.4.1 112.1.4.1 112.1.4.1到 112.1.255.255 112.1.255.255 112.1.255.255之间源IP地址,以及 202.21.1.1 202.21.1.1 202.21.1.1到 202.22.255.255 202.22.255.255 202.22.255.255之间目的IP地址,且差分服务代码点(DSCP)在0到16之间的记录数量。这是通过索引和查询二进制范围来实现的,类似于Count-min Sketches中使用的技术。特别地,为了支持范围查询,OmniSketch为每个属性 a i a_i ai包含 log ( ∣ D ( a i ) ∣ ) \log(|D(a_i)|) log(∣D(ai)∣)个内部属性概要图,分别标记为 C M ( i , 0 ) , C M ( i , 1 ) , . . . , C M ( i , log ( ∣ D ( a i ) ∣ ) − 1 ) CM_{(i,0)}, CM_{(i,1)}, ..., CM_{(i,\log(|D(a_i)|)-1)} CM(i,0),CM(i,1),...,CM(i,log(∣D(ai)∣)−1)。每个内部概要图 C M ( i , k ) CM_{(i,k)} CM(i,k)保存长度为 2 k 2^k 2k的二进制范围的频率统计。因此, C M ( i , 0 ) CM_{(i,0)} CM(i,0)存储点统计, C M ( i , 1 ) CM_{(i,1)} CM(i,1)存储大小为2的范围统计,以此类推。
记录 r r r被如下方式索引至概要图中:对于每个数值属性 r i r_i ri,从 k = 0 k=0 k=0到 log ( ∣ D ( a i ) ∣ ) − 1 \log(|D(a_i)|)-1 log(∣D(ai)∣)−1,我们找出所有形式为 [ x × 2 k + 1 , ( x + 1 ) 2 k ] [x \times 2^k + 1, (x + 1)2^k] [x×2k+1,(x+1)2k]的范围,其中 x ∈ Z ∗ x \in Z^* x∈Z∗,这些范围包含 r i r_i ri。对于每个大小为 2 k 2^k 2k的范围,我们将 x x x添加到 C M ( i , k ) CM_{(i,k)} CM(i,k)中。查询执行遵循类似的过程。在查询时,任何范围谓词都被分解为其规范覆盖——所有遵循上述形式的子范围。然后,对于概要图的每一行,我们查询所有子范围并合并检索到的样本,有效地构建一个覆盖完整查询范围的单一样本。剩下的查询过程与点查询相同。
内部范围概要图的维护将概要图的空间和时间复杂度增加了 log ( ∣ D ( a i ) ∣ ) \log(|D(a_i)|) log(∣D(ai)∣)倍。近似误差取决于查询规范覆盖中所含二进制范围的数量,最多为 2 log ( ∣ D ( a i ) ∣ ) 2\log(|D(a_i)|) 2log(∣D(ai)∣),正如在文献[12]中所示。因此,总误差最多为 2 ϵ log ( ∣ D ( a i ) ∣ ) N 2\epsilon\log(|D(a_i)|)N 2ϵlog(∣D(ai)∣)N。
通用更新的支持。如前所述,OmniSketch支持典型的仅插入(即cash寄存器模型)数据流模型。OmniSketch可以进一步扩展以处理更通用的旋转模型,即,包括现有数据的更新和删除操作。在这种情况下,持续维护桶内的样本成为主要挑战。如果我们在删除时已完全指定了删除项(即,在删除时知道包括rid在内的所有属性值),那么可以采用更为复杂的流采样方法,比如2LHS(第二节所述),替代K-最小哈希算法来支持删除操作。2LHS算法能够处理更复杂的流数据,包括数据的增删改查,使得OmniSketch在面对动态数据流时仍然能够保持其功能性和效率。然而,当删除操作不是完全指定的情况(例如,只知道部分属性值)时,在常数/对数时间内解决这个问题变得更加具有挑战性,这构成了我们正在进行的研究的一部分。
4 实验评价
我们实验的目的是:(a) 将三个提议的草图的空间复杂性、效率和准确性相互比较,并与最先进的草图进行比较,以及 (b) 检查我们表现最好的草图 S1 在总结不同特征和不同配置的流时的表现。
数据。在我们的实验中,我们使用了两个真实世界的数据集(SNMP [13] 和 CAIDA [1]),以及几个合成数据集,使我们能够彻底评估算法的特定属性。SNMP 包含 820 万条记录和 11 个属性,而 CAIDA 包含 1.09 亿条记录,每条记录有 6 个属性。SNMP 数据集包含 2003 年秋季从达特茅斯学院的无线网络收集的记录,而 CAIDA 是由美国互联网服务提供商收集的网络流量监控数据集。我们还生成了具有不同属性/分布的合成数据集,以检查输入流的属性如何影响我们的算法。除非另有说明,否则报告的结果与SNMP数据集相对应。数据集加载/生成/预处理的代码,以及实验中使用的所有文件和属性的列表,都包含在我们的 github 存储库中。
查询构建。我们系统地构建查询,目的是全面覆盖广泛的查询特征(不同的结果数量、不同的谓词数量、不同的谓词值)。在预处理步骤中,我们检查了数据集的一小部分样本(大约占所有记录的0.05%)。对于每个采样记录,以及对于每种可能的谓词数量p∈[2,|A|],我们通过从属性集合A中随机选择p个属性,并使用采样记录中的这些属性值作为谓词,构造了10个查询。所有查询被保存在一个集合中,有效地过滤掉了重复项。这导致SNMP数据集上总共有39,319个查询,涉及11个不同属性;CAIDA数据集上有3,304个查询,涉及6个不同属性。更多细节可以在GitHub仓库中找到。
硬件与实现。所有实验均在一台Linux机器上执行,该机器配备了512GB RAM和一个Intel Xeon® CPU E5-2697 v2处理器,主频为2.7GHz。实验是单线程的,即只使用了48个核心中的一个,且机器在其他时间处于空闲状态。所有草图都在Java(OpenJDK版本19.0.2)中实现并运行。对于Hydra基线,我们使用了作者提供的原始代码[20]。由于Hydra最初是作为Spark插件构建的,为了避免Spark带来的不必要的额外延迟,我们提取并仅使用了适用于集中式执行的必要代码。此外,为了确保公平比较,我们从Hydra的实现中排除了与基数估计之外的统计相关的任何代码和数据结构,如子群体的L2范数和熵。我们的改动提高了Hydra的性能并降低了其空间复杂度。在开始测量摄入时间之前,所有算法都被给予了几秒钟的预热时间(30万个更新)。我们的方法的代码以及处理数据集和复现实验结果的详细说明已经公开发布。
4.1 S0 和 S1 的比较
我们的第一系列实验旨在比较两种S0估计器(S0min和S0∩)与S1在以下方面:(a) 流摄入时间,(b) 内存需求,© 估计精度,以及 (d) 查询执行时间。我们通过计算平均绝对误差来量化准确性,该误差经由流大小进行归一化,即 ∑ ︁ q ∈ Q ∣ f ^ ( q ) − f ( q ) ∣ / ( N ∗ ∣ Q ∣ ) ∑︁_{q∈Q} |f̂(q) - f(q)|/(N * |Q|) ∑︁q∈Q∣f^(q)−f(q)∣/(N∗∣Q∣),其中N代表流大小,Q表示执行的查询集。在这组实验中,所有草图均配置为(ε=0.1, δ=0.1)。我们测试了四种不同内存配置的S1,分别为10MB、50MB、100MB和200MB。
图3展示了使用对比草图总结SNMP流(所有11个属性)子集所需的时间和内存。请记住,S0min和S0∩使用相同的草图,因此在图中共同以S0呈现。S1的内存需求没有作为单独的序列包含在图中,因为这些需求对于每种配置都是固定的。如预期所示,我们观察到构建所有草图所需的时间(左轴)随着流大小线性增长。然而,草图S1的效率显著更高,相比S0需要4到5倍少的时间。同时,当允许S1使用更多内存时,其吞吐量会下降。这也是可以预料的,因为对S1分配更高的内存配额意味着B的值更高(每个单元格的样本更多),这会导致红黑树维护速度变慢。即便如此,即使对于使用200MB内存和11个属性的S1,吞吐量仍超过每秒89,000次更新。还需注意的是,S1的摄入时间形成了一个微妙但明显的拐点(例如,对于使用200MB的S1,这一现象发生在大约270万次更新时)。这个拐点表明草图中大多数单元格的K最小样本已达到几乎稳定的状态,任何新更新需要添加到样本中的概率很小。此时,大多数更新只需O(|A|×d)时间,而非O(log(B)×|A|×d)。最后,我们观察到S0的内存需求(图3,右轴)随着流大小线性增长,因为所有记录都保留在草图中。
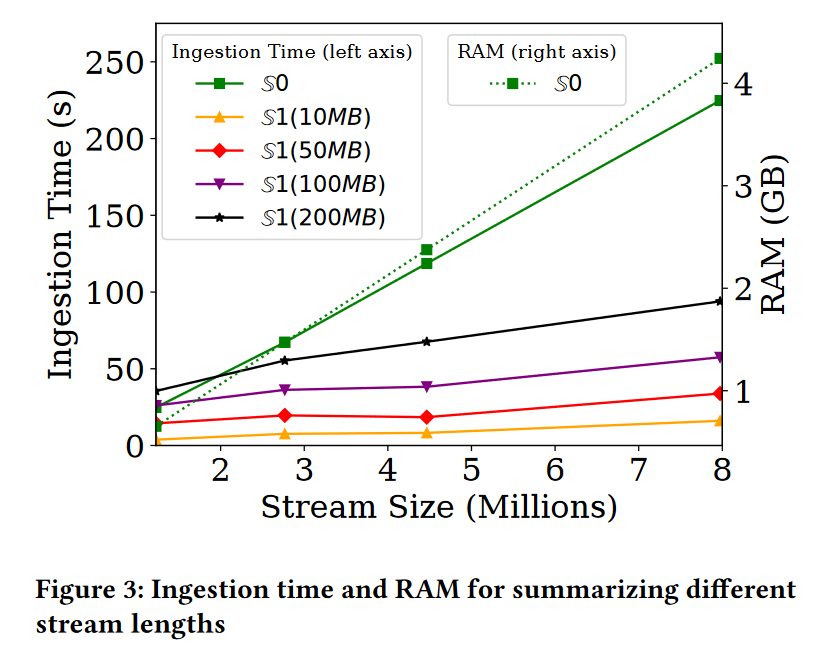
表2汇总了所有考虑配置下的平均误差和查询执行时间。我们观察到,与S1变体相比,两种S0变体在查询执行上耗费了显著更多的时间。性能差异在1到2个数量级之间,具体取决于S1的内存配额。这种明显差异的原因在于,S0变体需要遍历非常大的集合来计算交集,而S1仅需遍历大小为B的样本集,B通常在几千的数量级。我们还注意到,尽管S0∩和S0min都在同一草图结构上运行,但S0∩的查询执行速度明显快于S0min。这归因于两个估计器中查询执行的实现方式不同。在S0∩中,类似于S1,我们从第一个单元格开始,持续减少候选记录,直到遍历完所有p×d个单元格(参见S1实现部分的相关讨论,第3.2节)。这迅速减少了候选记录的数量。另一方面,S0min估计器的实现则逐行执行相同的过程,并取所有行的最小值。因此,S0min对每个满足查询条件的记录重复进行每次检查。
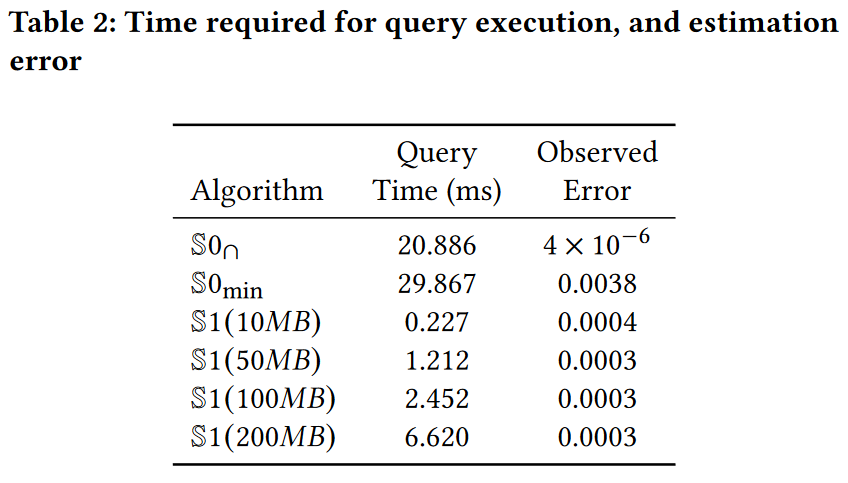
就近似误差而言,S0∩的表现优于所有其他方法,平均误差微乎其微。这是意料之中的,因为S0∩不会遭受低估和假阴性问题,其估计中包含假阳性的概率也非常小:εp’d,其中p’表示记录未满足的查询属性数量。我们还看到,依赖于交集的S1,其误差比S0min小约一个数量级,即使它在表示相同数据集时所需的内存仅为S0min的十分之一至百分之一。
总结。S0min、S0∩和S1之间的对比显示,就准确性而言,S0∩显著超越其他两种变体,但其空间需求呈线性增长。因此,S0∩仅作为全索引的一种替代方案,在有足够的内存存储整个数据流的情况下才显得有用。S0min的大小同样随数据量线性增长,且其估计效果相较于S0∩较差。相比之下,S1在准确性和空间复杂度/效率之间提供了有利的折衷,使用户能够调整内存配额,充分利用可用的RAM。因此,对于接下来的实验以及与现有最先进技术的比较,我们将只考虑S1。
4.2 与最先进的比较
我们的第二系列实验侧重于将我们表现最好的草图 S1 与 Hydra 进行比较。允许两个草图具有相同的内存,并比较了它们的:(a) 摄取时间,(b) 查询执行性能,以及 (c) 准确性。
摄取时间。高吞吐量是流处理与总结的关键要求。因此,我们最初的实验旨在评估S1和Hydra总结整个流所需的时间,并检查这个时间如何受到流中属性数量的影响。我们通过获取SNMP的不同垂直分区(即不同的属性子集),生成具有不同数量属性(从2个到11个)的流。
图4展示了Hydra和S1在不同内存配额下的数据摄入时间。为了便于说明,Y轴被分为两个不同比例尺的子范围。我们首先观察到,当存储的属性数量不超过4个时,这两种算法的表现相当。然而,Hydra的计算复杂度会随着数据流属性数量的增加而呈指数级增长。这是因为Hydra中的每条记录都会导致2的|A|次方减1次的草图更新,其中A表示数据流的属性集合。因此,在Hydra中存储SNMP的所有11个属性会导致每个记录大约有O(2^11)个子群体/更新,对于完整数据集来说,这大约需要14000秒(即超过1毫秒/记录)的时间。这里需要强调的是,在Hydra中存储所有子群体不仅是支持包含恰好11个谓词的查询所必需的,而且也是为了支持那些包含这些谓词子集的查询,特别是当确切的查询谓词组合在观察数据流之前未知的情况下。
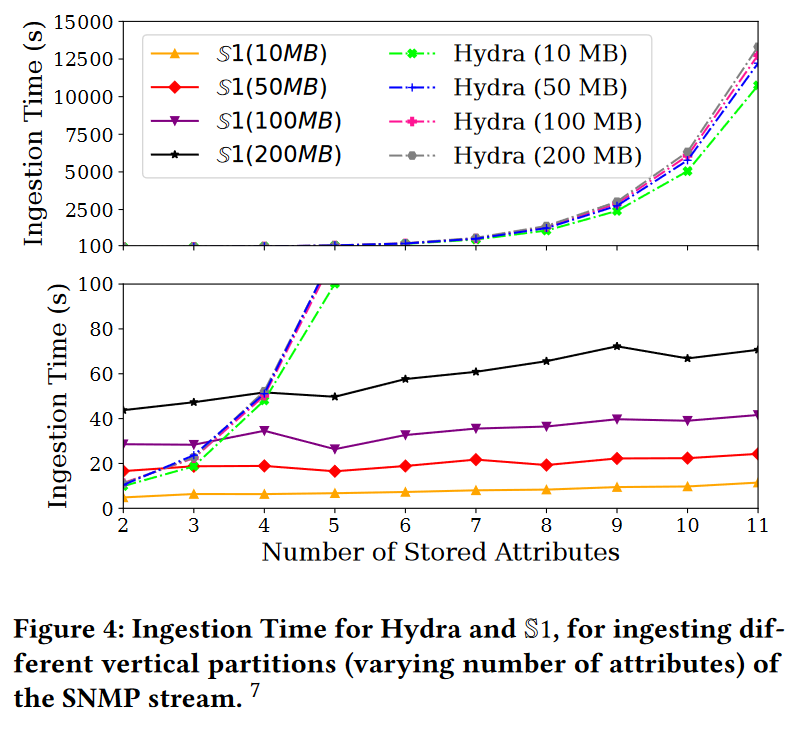
有趣的是,添加更多属性对 S1 的摄取时间的影响可以忽略不计。事实上,在某些情况下,添加属性不会增加,甚至会略微减少摄取时间(例如,为 S1 添加第五个属性时,200 MB)。乍一看,此结果可能看起来有悖常理,因为添加更多属性意味着维护更多属性草图,并在这些草图中存储更多样本。这种行为归因于这样一个事实,即在 S1 添加记录最耗时的步骤是维护 K-minwise 样本,当样本数量减少时,K-minwise 样本会变得更快。通过在不增加其内存配额的情况下在草图中添加更多属性,我们有效地减少了草图所有属性的样本数量 B。这导致:(a) 降低红黑树需要更新的概率,以及 (b) 在需要更新时更快地更新红黑树。
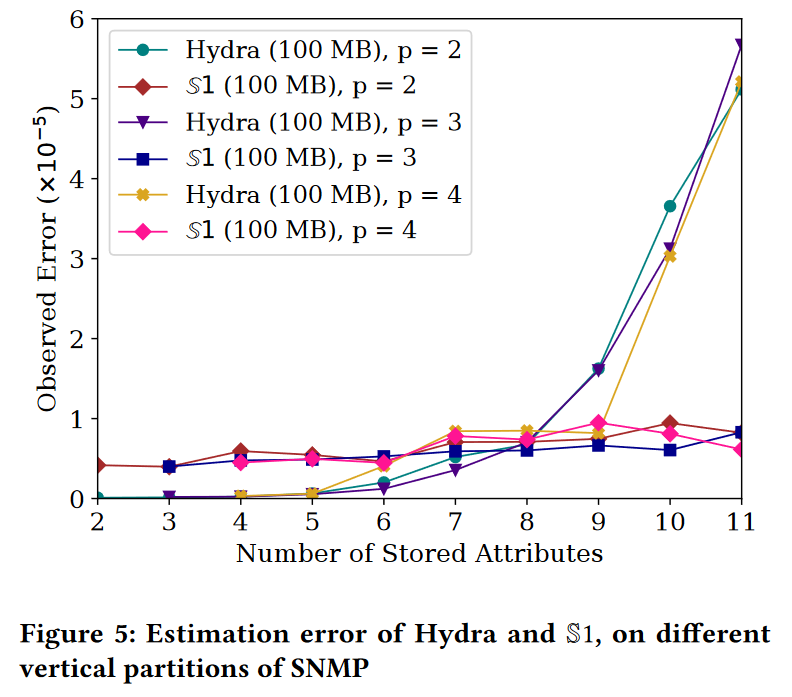
准确性。图5绘制了针对具有𝑝 = 2、3和4个谓词的查询,在两个概要上的观察到的误差。我们发现,尽管查询谓词的数量对两种方法的准确性没有显著影响,但存储的属性数量确实影响了Hydra的准确性。超过8个属性后,Hydra的准确性会降低,而S1的准确性则不受影响。Hydra的这种行为再次归因于Hydra最终对每个记录执行的插入操作数量:Hydra所总结的信息随属性数量呈指数级增长,导致更多的碰撞和观察到的误差急剧增加。
查询执行时间。在最后的比较中,我们使用Hydra和S1来汇总整个SNMP流(830万次更新)的全部11个属性。表3总结了包含最多8个谓词的查询执行时间。两种草图都非常高效,即使在RAM配额为200MB的配置下,执行一个查询所需的时间也少于10毫秒。我们还注意到S1比Hydra慢。这是可以预料的,因为S1需要计算p×d个大小为B的样本的交集,而Hydra只需要计算大约相同数量的计数器的最小值。出于同样的原因,S1的查询时间也会随着可用内存的增加而略有增长,而Hydra的性能则不受影响。另外,我们发现S1的效率随着谓词数量的增加而提高,这与我们之前的观察结果相符(第4.1节)。这种改善归因于算法计算集合交集的方式,随着属性/集合数量的增加,这种方式变得越来越高效(参见第3.2节)。
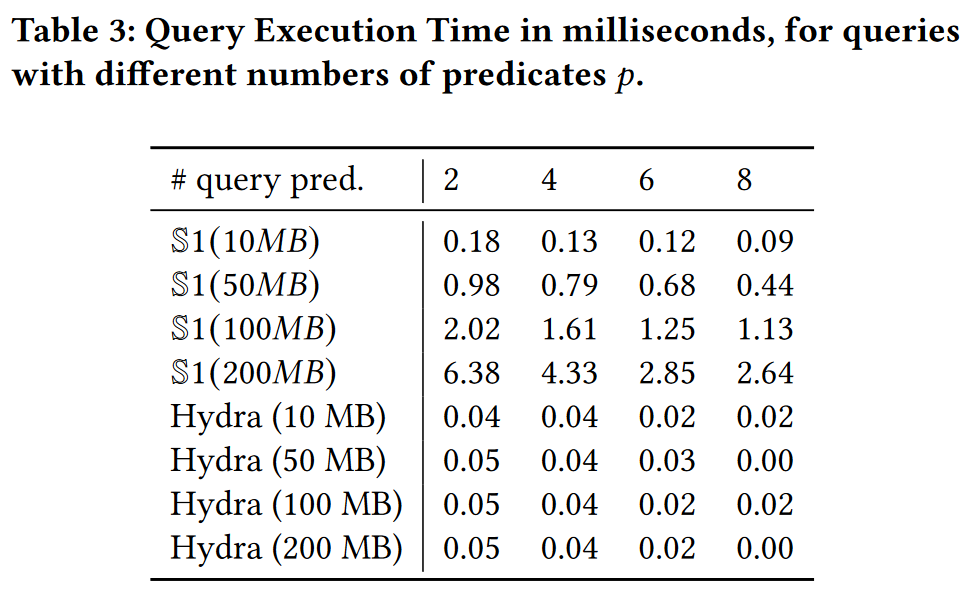
综述。无论是Hydra还是S1,执行包含最多8个谓词的查询所需的时间都少于10毫秒。但是,当汇总具有多个属性的流时,S1在效率上远远超过Hydra,吞吐量差异可能超过两个数量级。重要的是,Hydra的吞吐率随着流属性数量的增加而呈指数级下降。即使对于包含很少属性的查询,Hydra的估计准确性也随着流属性数量的增加而呈指数级下降。因此,Hydra不是汇总包含许多属性的流的有效选择。
4.3 不同流的 S1 评估
我们接下来的一系列实验着重于探究数据流特性(属性值的分布和流中的记录数量)对S1效率和准确度的影响。
图7展示了汇总来自以下数据流的500万条记录所需的时间:
- Zipf, 𝛼 ∈ [1, 1.3, 1.5]:三个不同的流。每个流包含5个属性(整数值)。我们通过从指数为𝛼 ∈ [1, 1.3, 1.5]的Zipf分布中抽取随机数来生成记录。
- Uniform:该流包含5个整数属性。所有属性的值都是由均匀分布抽取的。
- CAIDA和SNMP:CAIDA和SNMP流的垂直分区,包含5个属性。
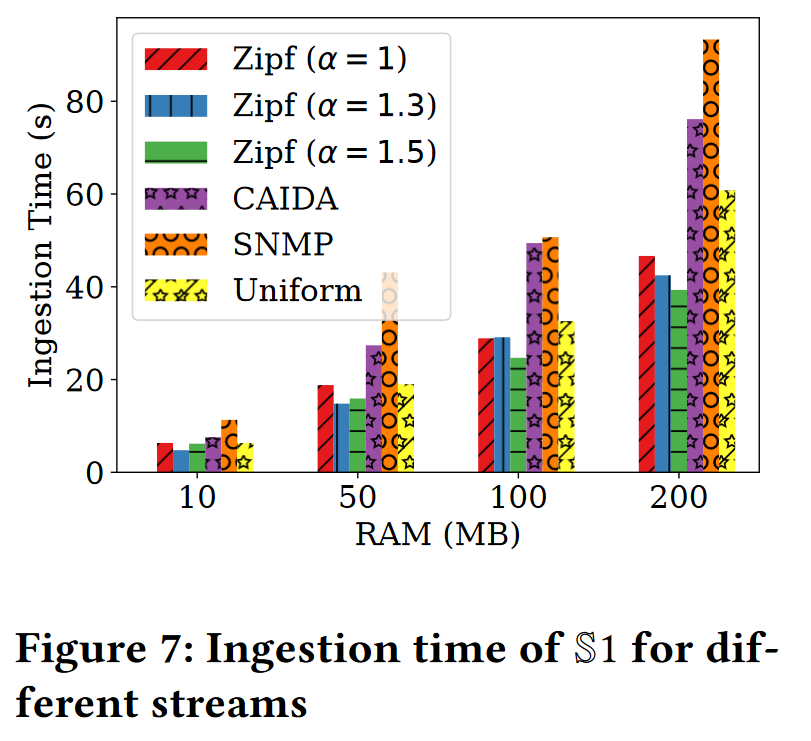
我们可以看到,即使在200MB的配额下,S1也只需要不到100秒就能汇总每个流。此外,Zipf流的摄入时间相比均匀流明显更短,并且随着Zipf的𝛼值增加而进一步减少。这种行为可以追溯到维护K-minwise样本所需的精力,这与我们之前在图3中观察到的微妙拐点一致。在这个实验中,随着Zipf指数值的上升,值的分布变得更加偏斜,导致更多的记录在相应属性草图的相同单元格中散列。因此,这些单元格的K-minwise样本迅速达到几乎稳定的状态。这种模式同样出现在CAIDA和SNMP流中,其中某些属性也遵循Zipf分布,导致与均匀流相比,摄入速度更快。即便在极端情况下,即所有流属性的值都遵循均匀分布,S1的吞吐量仍然超过每秒15万次更新。
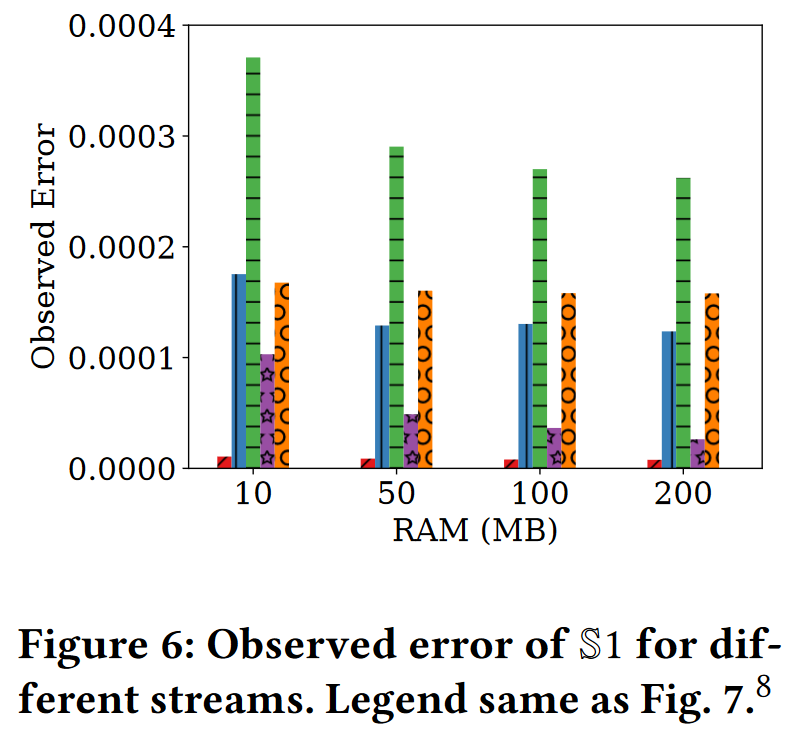
在这些数据集上观察到的估计误差如图 6 所示。显示的结果对应于包含三个谓词的 450 个查询的平均误差。我们看到,在所有情况下,观察到的误差都非常低。对于 Uniform 的情况,平均误差接近 0,而 Zipf 观察到的最大误差为 α = 1.5。这样做的原因是,随着 Zipf 指数的增长,草图中流行单元格的样本(负责存储频率值的单元格位于 Zipf 分布的头部)最终几乎只包含这些流行值的记录。因此,对于恰好落在相同流行单元格中的低频谓词,没有足够的样本剩余,从而导致更高的估计误差。这种限制在所有提供与流大小相关的误差的小内存草图中都很常见,例如,Count-min草图[6]。
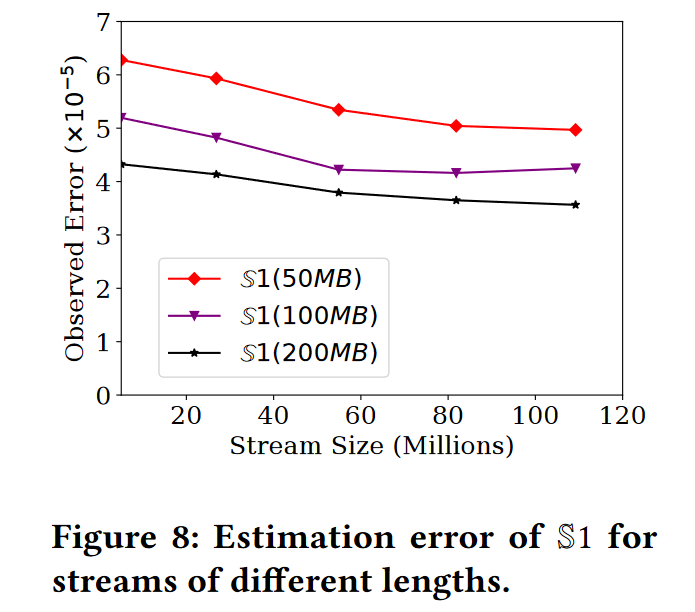
我们最后的点查询实验旨在探索流大小对 S1 性能的影响。由于我们已经证明了 S1 的吞吐量不受流大小的影响(图 3),因此本实验仅关注流大小对准确性的影响。准确地说,我们使用 S1 来总结 CAIDA,这是最大的真实数据集,拥有 1.09 亿条记录。我们定期暂停流引入,对草图执行一组固定的 3304 个查询,并计算每个查询的估计误差。图 8 所示的结果与每个间隔的平均观测误差相对应。正如分析所预测的那样,在 OmniSketch 中观察到的误差与流大小保持稳定。
总结。S1 在所有情况下都非常高效,提供超过每秒 150k 更新的吞吐量。在效率方面,最困难的分布是均匀分布,因为草图单元中的样品需要更长的时间才能达到稳定状态。在精度方面,具有极高值的 Zipf 分布对于 S1 来说更加困难。这是所有小型内存草图共有的限制。此外,增加流大小对观察到的误差没有显著影响。
4.4 范围查询
最后一组实验用于评估 S 1 在范围查询中的性能。对于不同的 p 值,通过选择长度为 225 的随机 p 维范围来生成此实验的查询。在所有情况下,范围的起点和终点都在相应属性的最小值和最大值范围内。在下文中,我们报告 p = {2, 3} 的结果。虽然 S1(及其理论分析)对 p 的值和查询范围长度没有施加任何约束,但较高的 p 值或较小的查询范围总是导致数据集的选择性为零——没有与查询匹配的记录。即使在这些情况下,S1 仍然支持我们对此类查询的理论保证,通常误差非常小。但是,为了能够在这里专注于更具挑战性的配置,我们不提供较高 p 值和较小范围的详细结果。另请注意,并非所有流属性都适合范围查询 - 某些属性是分类的(例如,IP 标头中的属性协议)。
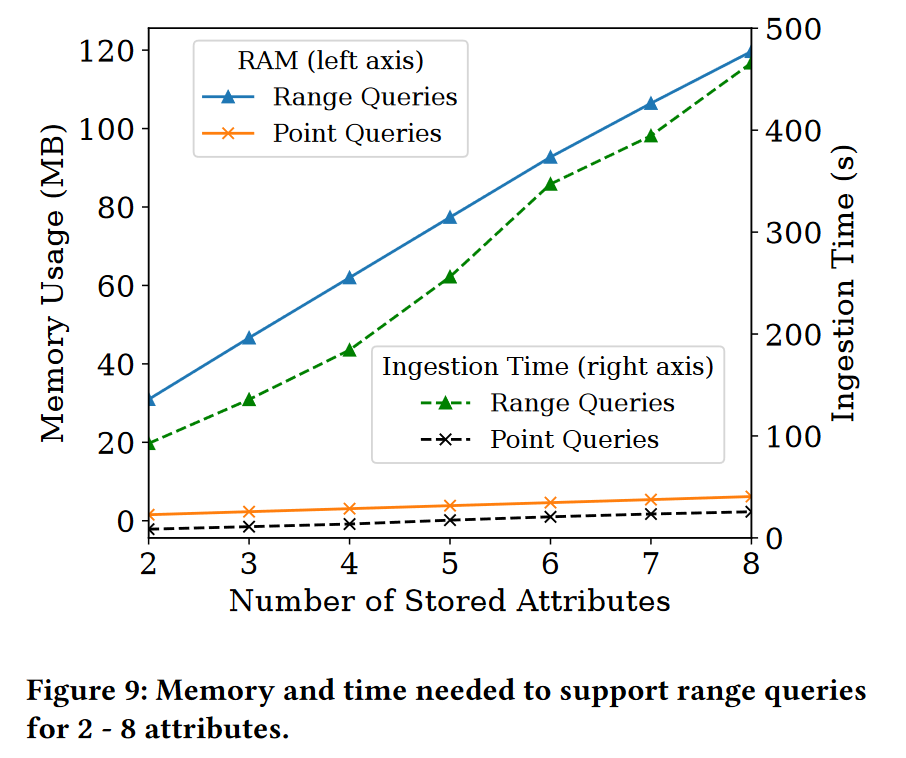
图9展示了使用支持范围查询的增强版S1对SNMP流(属性ifOutOctets, ifOutErrors, ifOutDiscards, ifOutUcastPkts, ifInOctets, ifInUcastPkts, ifInErrors, ifInDiscards)进行汇总所需的时间和内存。实验结果对应于𝐵 = 1000,𝑤 = 20,以及𝑑 = 3。作为参考,图中还包括了使用标准S1草图(未配置支持范围查询)对同一数据流进行汇总所需的时间。与标准S1类似,增强版S1的内存消耗和摄入时间均随属性数量线性增长。这是预料之中的,因为每个新增加的属性都需要一个新的属性草图。同时,支持范围查询的S1在处理相同数量的样本时运行更慢且需要更多内存。性能下降的原因在于,在支持范围查询的草图中,为了存储二进制范围内的统计信息,内部属性草图的数量增加了对数倍。然而,实际观察到的性能下降远小于理论预测值。这种差异源于负责存储大二进制范围的草图;回想一下,大二进制范围的数量远远少于小二进制范围的数量。例如,对于域大小为 2 32 2^{32} 232的属性,仅存在四个大小为 2 32 2^{32} 232的二进制范围。因此,存储大二进制范围的单元格大多为空,只需少量RAM即可,而少数非空单元格(约为4×𝑑每个谓词)仍然限制在𝐵个样本内。这导致了更快的摄入速度(样本更新频率降低)和更小的内存占用。对于𝑝 = 2的范围查询,平均观察误差为0.094(886次查询),而对于𝑝 = 3,平均观察误差为0.072(99次查询)。这些误差均在第3.3节所示的界限之内。
总结。我们的最后一组实验表明,启用范围的 S1 在范围查询方面也能保持高性能和高精度。维护 S1 的存储和计算复杂性随属性数量的增加呈线性增长。
5 总结
我们展示了 OmniSketch,这是一个专注于在小空间内总结复杂流(具有许多属性)分布的草图。该草图结合了小(用户定义的)内存占用、快速更新和查询时间(对数线性复杂度),并为点查询和范围查询提供理论支持的准确性保证。对草图的彻底实验评估表明,即使在汇总具有许多属性的流时,它也可以实现非常快的更新速率。例如,使用 200 MB 的草图可以汇总吞吐量超过每秒 8.9 万次更新的 11 个属性流,而同一流上的 100 MB 草图支持两倍的吞吐量。此外,我们已经证明 OmniSketch 的性能优于最先进的技术(在我们的实验中,吞吐量超过 2 个数量级),同时仍能提供高度准确的估计。
参考文献