Opus从入门到精通(五)OggOpus封装器全解析
为什么要封装
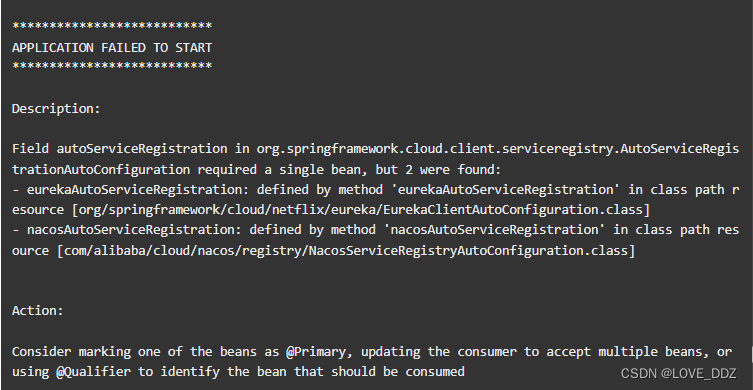
前面Opus从入门到精通(四)Opus解码程序实现提到如果不封装会有两个问题:
- 无法从文件本身获取音频的元数据(采样率,声道数,码率等)
- 缺少帧分隔标识,无法从连续的文件流中分隔帧(尤其是vbr情况)
针对上面的问题我们可以自定义一种封装格式,增加类似于WAV的Header,Header中存储元数据,每一帧音频数据前面增加可以标识帧边界的头,但是又会引出其他问题:
- 播放器播放时Seek操作不方便,无法快速定位特定位置
- 如果有多路,涉及到同步问题
- 文件切割,合并问题
我们引入Opus编码的标准封装格式Ogg.
OGG封装格式介绍
前面文章:
- [译]Ogg bitstream overview
- [译]ogg logical bitstream framing
- [译]Page Multiplexing and Ordering in a Physical Ogg Stream
- [译]The Ogg Skeleton Metadata Bitstream
我们翻译了Ogg的官方文档,下面我们在对Ogg做一个简练的总结
OGG简介
Ogg是一个自由且开放标准的多媒体文件格式,由Xiph.Org基金会所维护。Ogg格式并不受到软件专利的限制,并设计用于有效率地流媒体和处理高质量的数字多媒体。“Ogg”意指一种文件格式,可以纳入各式各样自由和开放源代码的编解码器,包含音效、视频、文字(像字幕)与元数据的处理。在Ogg的多媒体框架下,Theora提供有损的影像层面,而通常用音乐导向的Vorbis编解码器作为音效层面。针对语音设计的压缩编解码器Speex和无损的音效压缩编解码器FLAC与OggPCM也可能作为音效层面使用。“Ogg”这个词汇通常意指Ogg Vorbis这一音频文件格式,也就是将Vorbis编码的音效包含在Ogg的容器中所成的格式。在以往,.ogg这一扩展名曾经被用在任何Ogg支持格式下的内容;但在2007年,Xiph.Org基金会为了向后兼容的考量,提出请求,将.ogg只留给Vorbis格式来使用。Xiph.Org基金会决定创造一些新的扩展名和媒体格式来描述不同类型的内容, 像是只包含音效所用的.oga、 包含或不含声音的影片(涵盖Theora)所用的.ogv, 和可以包含任何比特流的.ogx。Xiph.Org基金会对Ogg的参考实现,当前最新的版本是2010年3月26日发布的libogg 1.2.0。这两个库都是在新BSD许可证下发布的自由软件。因为其格式自由,和其参考实现并非Copyleft形式,无论自由或专有、商业或非商业的媒体播放器,甚至部分制造商的便携式媒体播放器和全球定位系统接收器都采用了Ogg下的各种编解码器。当前Android系统所有的内置铃声也都使用Ogg文件。
Ogg只是容器格式。由编解码器编码的实际音频或视频存储在Ogg容器内。Ogg容器可以包含用多个编解码器编码的流,例如,具有声音的视频文件包含由音频编解码器和视频编解码器编码的数据。 作为容器格式,Ogg可以以各种格式(如Dirac,MNG,CELT,MPEG-4,MP3等)嵌入音频和视频,但是Ogg旨在和通常用于以下Xiph.org免费编解码器:
音频
| 压缩类型 | 格式 | 说明 |
|---|---|---|
| 有损 | Speek | 以低比特率处理语音数据(〜2.1-32 kbit / s /通道) |
| Vorbis | 处理中高级可变比特率(每通道≈16-500kbit / s)的一般音频数据 | |
| Opus: | 以低和高可变比特率处理语音,音乐和通用音频(每通道≈6-510kbit / s) | |
| 无损 | FLAC | 处理文件和高保真音频数据 |
| 未压缩 | OggPCM | 处理未压缩的PCM音频,与WAV类似 |
视频
| 压缩类型 | 格式 | 说明 |
|---|---|---|
| 有损 | Theora | 基于On2的VP3,它的目标是与MPEG-4视频(例如,使用DivX或Xvid编码),RealVideo或Windows Media Video进行竞争。 |
| Daala | 正在开发的视频编码格式。 | |
| Dirac | 由BBC开发的免费开放视频格式。使用小波编码 | |
| Tarkin | 实验项目,现在过时的视频编解码器在2000年,2001年和2002年开发利用离散小波变换的三个维度的宽度,高度和时间。在Theora成为视频编码的主要焦点之后,已被搁置(2002年8月)。 | |
| 无损 | Dirac | Dirac规范的一部分涵盖无损压缩。 |
| Daala | 正在开发的视频编码格式 |
文本
| 格式 | 说明 |
|---|---|
| Writ | 用于嵌入字幕或字幕的文本编解码器的草稿不完整,于2007年停止 |
| CMML | 用于定时元数据,字幕和格式的文本/应用编解码器 |
| Annodex | CSIRO开发的免费开源标准,用于注释和索引网络媒体。 |
| oggKate | 最初设计用于卡拉OK和文本的重叠编解码器,可以在Ogg中复用。 |
Ogg格式封装结构
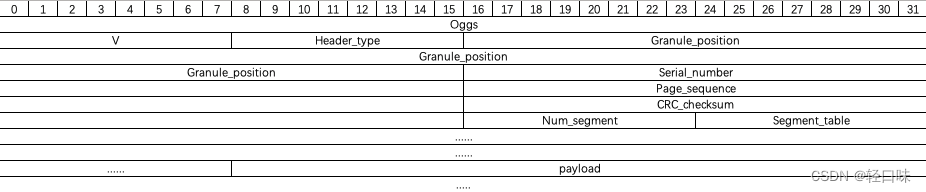
ogg是以页(page)为单位将逻辑流组织链接起来,每个页都有pageheader和pagedata。页头中有如下的定义:
-
capture_pattern页标识:ASCII字符,0x4f ‘O’ 0x67 ‘g’ 0x67 ‘g’ 0x53 ‘S’,4个字节大小,它标识着一个页的开始。
-
stream_structure_version版本id:一般当前版本默认为0,1个字节。
-
header_type_flag类型标识:标识当前的页的类型,1个字节,
- 0x01:本页媒体编码数据与前一页属于同一个逻辑流的同一个packet,若此位没有设,表示本页是以一个新的packet开始的;- 0x02:表示该页为逻辑流的第一页,bos标识,如果此位未设置,那表示不是第一页;- 0x04:表示该页位逻辑流的最后一页,eos标识,如果此位未设置,那表示本页不是最后一页。 -
granule_position:媒体编码相关的参数信息,8个字节,对于音频流来说,它存储着到本页为止逻辑流在PCM输出中采样码的数目,可以由它来算得时间戳。对于视频流来说,它存储着到本页为止视频帧编码的数目。若此值为-1,那表示截止到本页,逻辑流的packet未结束。(小端)
-
serial_number:当前页中的流的id,4个字节,它是区分本页所属逻辑流与其他逻辑流的序号,我们可以通过这个值来划分流。(小端)
-
page_seguence_number:本页在逻辑流的序号,4个字节。
-
CRC_cbecksum:循环冗余效验码效验,4个字节,用来效验每页的有效性。
-
number_page_segments:给定本页在segment_table域中出现的segement个数,1个字节。
-
segment_table:从字面看它就是一个表,表示着每个segment的长度,取值范围是0~255。由segment(1个segment就是1个字节)可以得到packet的值,每个packet的大小是以最后一个不等于255的segment结束的,从页头中的segment_table可以得到每个packet长度,举例:如果一组segment依次顺序为FF 45 FF FF FF 40FF 05FF FF FF 66(共4个packet,含12个segment,每个packet的长度是:FF 45【324】;FF FF FF 40【829】;FF 05【260】;FF FF FF 66【847】),那么第一个packet的长度为255+69 = 324,第二个packet大小829,同理。
页头基本上就是由上述的参数组成,由此我们可以得到页头的长度和整个页的长度:
header_size = 27+number_page_segments ;(byte) page_size = header_size +segment_table中每个segment的大小;页头部格式:
OGG封装处理过程
- 音视频编码在提供给Ogg封装之前是以具有包边界的“Packets”形式呈现的,包边界依赖于具体的编码格式,如Ogg封装示意图。
- 将逻辑流的各个包进行分片segmentation,每片大小固定为255Byte,但包的最后一个segment通常小于255字节。因为packet的大小可以是任意长度,由具体的媒体编码器来决定。
- 进行页封装,每页都被加上页头,每页的长度可不等,由具体情况而确定。页头部segment_table域告知了“lacing_value”值的大小,即页中最后一个segment的长度(可以为0,或小于255)。一次处理一个packet,此packet被封装成一个或多个page页(page的长度设定了上限,一般为4kB);下一个packet必须用新的page开始封装,由首部字段域header_type_flag的设置规定来表示。
- 多个已被页格式封装好的逻辑流(如语音、文本、图片、音频、视频等)按应用要求的时序关系合成物理流。
多个已被页格式封装好的逻辑流(如语音、文本、图片、音频、视频等)按应用要求的时序关系合成物理流。
logical bitstream with packet boundaries-----------------------------------------------------------------> | packet_1 | packet_2 | packet_3 | <-----------------------------------------------------------------|segmentation (logically only)vpacket_1 (5 segments) packet_2 (4 segs) p_3 (2 segs)------------------------------ -------------------- ------------.. |seg_1|seg_2|seg_3|seg_4|s_5 | |seg_1|seg_2|seg_3|| |seg_1|s_2 | ..------------------------------ -------------------- ------------| page encapsulationvpage_1 (packet_1 data) page_2 (pket_1 data) page_3 (packet_2 data)
------------------------ ---------------- ------------------------
|H|------------------- | |H|----------- | |H|------------------- |
|D||seg_1|seg_2|seg_3| | |D|seg_4|s_5 | | |D||seg_1|seg_2|seg_3| | ...
|R|------------------- | |R|----------- | |R|------------------- |
------------------------ ---------------- ------------------------|
pages of |
other --------| |
logical -------
bitstreams | MUX |-------|vpage_1 page_2 page_3------ ------ ------- ----- -------... || | || | || | || | || | ...------ ------ ------- ----- -------physical Ogg bitstream
<<The Ogg Encapsulation Format Version 0>>官方文档的图,我做了一个图片形式:

OGG封装流程示意图
Ogg文件的映射与逆映射
用Ogg文件格式封装好压缩编码媒体流可用于存储(磁盘文件)或直接传输(TCP或管道),这是因为Ogg比特流格式提供了封装/同步、差错同步捕获、寻找标记以及其它足够的信息使得这种分散开的数据能够完全地还原为封装之前的具有包边界“packet”形式的压缩编码媒体流,恢复到这种原来媒体流就具有的包边界形式不需要依赖于针对压缩编码的解码器。也就是说Ogg映射与逆映射和媒体流的压缩编码、解码具有相对独立性。
Ogg文件需要解封装的情况有两种:
- 播放器要对媒体流解码之前;
- 对媒体流进行RTP/UDP传输之前。解封装的过程就是ogg逆映射过程,即还原为具有包边界“packet”形式的媒体流,同时以预先填充好了的RTP首部字段与相应一段媒体数据捆绑,形成RTP封包。此过程便是媒体流从Ogg格式到RTP格式的转换过程。
将以packet为单元的媒体流映射为以page为单元的Ogg格式比特流,其中间经过了segment的划分和重组环节,但方便了对媒体流的存储与传输(TCP)。对源缓冲区媒体数据(packet)的操作,需建立几个中间环节的数据结构,只需将切割的媒体数据在内存移动一次,操作指向媒体数据的指针便能达到媒体数据迁移到目的缓冲区(page)的意图,其过程可用两个函数转换来表述:
OGG 实践之Vorbis比特流结构
Vorbis比特流是以三个数据包头开始的。这些头数据包按顺序依次是:The identification header、The comment header和设置数据包。这些都与解码Vorbis音频文件密切相关的。
数据包头结构
每个数据包都是以同样的头结构开始的:
[packet_type] : 8 bit value
0x76, 0x6f, 0x72, 0x62, 0x69, 0x73: the characters’v’,‘o’,‘r’,‘b’,‘i’,‘s’ as six octets
The identification header
The identificationheader identifies the bitstream as Vorbis, Vorbis version, and the simpleaudio characteristics of the stream such as sample rate and number of channels.
-
[vorbis_version] = read 32 bits as unsigned integer
-
[audio_channels] = read 8 bit integer as unsigned必须大于0
-
[audio_sample_rate] = read 32 bits as unsigned integer必须大于0
-
[bitrate_maximum] = read 32 bits as signed integer
-
[bitrate_nominal] = read 32 bits as signed integer
-
[bitrate_minimum] = read 32 bits as signed integer
-
[blocksize_0] = 2 exponent (read 4 bits as unsigned integer)必须小于等于[blocksize_1]
-
[blocksize_1] = 2 exponent (read 4 bits as unsigned integer)
-
[framing_flag] = read one bit不能为0
Thebitrate fields above are used only as hints. The nominal bitrate fieldespecially may be considerably of in purely VBR streams. The fields aremeaningful only when greater than zero.
- All three fields set to thesame value implies a fixed rate, or tightly bounded, nearly fixed-ratebitstream
- Only nominal set implies a VBRor ABR stream that averages the nominal bitrate
- Maximum and or minimum setimplies a VBR bitstream that obeys the bitrate limits
- None set indicates the encoderdoes not care to speculate.
The comment header
The comment header includes user text comments (\tags") and a vendor stringfor the application/library that produced the bitstream.
The comment header is logically a list of eight-bit-clean vectors; the number ofvectors is bounded to 232 … 1 and the length of each vector is limited to 232… 1 bytes. The vector length is encoded; the vector contents themselves arenot null terminated. In addition to the vector list, there is a single vectorfor vendor name (also 8 bit clean, length encoded in 32 bits). For example, the1.0 release of libvorbis set the vendor string to \Xiph.Org libVorbis I20020717".
The vector lengths and number of vectors are stored lsbfirst, according to the bit packing conventions of the vorbis codec. However,since data in the comment header is octetaligned,they can simply be read asunaligned 32 bit little endian unsigned integers
The comment vectors are structured similarlyto a UNIX environment variable. That is,comment fields consist of a field nameand a corresponding value and look like:
- 1 comment[0]=“ARTIST=me”;
- 2 comment[1]=“TITLE=the sound of Vorbis”;
The field name is case-insensitive and may consist of ASCII 0x20 through 0x7D, 0x3D (‘=’)excluded. ASCII 0x41 through 0x5A inclusive (characters A-Z) is to beconsidered equivalent to ASCII 0x61 through 0x7A inclusive (characters a-z).Thefield name is immediately followed by ASCII 0x3D (‘=’);
this equals sign is used to terminate the field name.0x3D is followed by 8 bit cleanUTF-8 encoded value of the field contents to the end of the field.Field namesBelow is a proposed, minimal list of standard field names with a description ofintended use. No single or group of field names is mandatory; a comment headermay contain one, all or none of the names in this list.
- TITLE Track/Work name
- VERSION The version field may be used to differentiate multipleversions of the same track title in a single collection. (e.g. remix info)
- ALBUM The collection name to which this track belongs
- TRACKNUMBER The track number of this piece if part of a specific largercollection or album
- ARTIST The artist generally considered responsible for the work. Inpopular music this is usually the performing band or singer. For classicalmusic it would be the composer.For an audio book it would be the author of theoriginal text.
- PERFORMER The artist(s) who performed the work. In classical musicthis would be the conductor, orchestra, soloists. In an audio book it would bethe actor who did the reading. In popular music this is typically the same asthe ARTIST and is omitted.
- COPYRIGHT Copyright attribution.
- LICENSE License information, eg, ‘All Rights Reserved’, ‘Any UsePermitted’.
- ORGANIZATION Name of the organization producing the track (i.e. the’record label’)
- DESCRIPTION A short text description of the contents
- GENRE A short text indication of music genre
- DATE Date the track was recorded
- LOCATION Location where track was recorded
- CONTACT Contact information for the creators or distributors of thetrack. This could be a URL, an email address, the physical address of the producinglabel.
- SRC International Standard Recording Code for the track; see theISRC intro page for more information on ISRC numbers.
Hint: Field names are not required to beunique (occur once) within a comment header. As
an example, assume a track was recorded bythree well know artists; the following is permissible, and encouraged:
- 1 ARTIST=Dizzy Gillespie
- 2 ARTIST=Sonny Rollins
- 3 ARTIST=Sonny Stitt
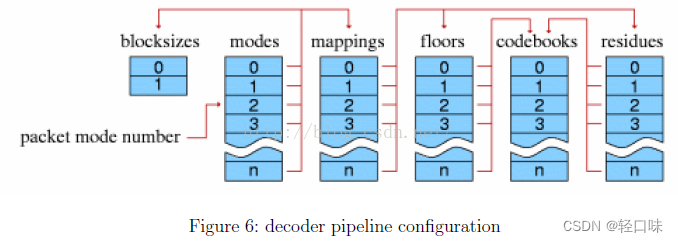
- 4 Setup Header
The setupheader includes extensive CODEC setup information as well as the complete VQand Hu man codebooks needed for decode.
Thesetup header contains, in order, the lists of codebook configurations,time-domain transform configurations (placeholders in Vorbis I), floorconfigurations, residue configurations,channel mapping configurations and modeconfigurations. It finishes with a framing bit of ‘1’. 如下图:
OggOpus封装格式介绍
终于介绍完Ogg的结构了,可以开始Opus的Ogg封装了,先以一个示例文件分析了解一下Opus封装的Ogg结构
一个Opus文件按Ogg 页结构拆分
我们以我生成的这个链接: https://pan.baidu.com/s/1xRdehcOJSJILZ58b8KOt-A 提取码: nzq7 文件为例分析:
第一页
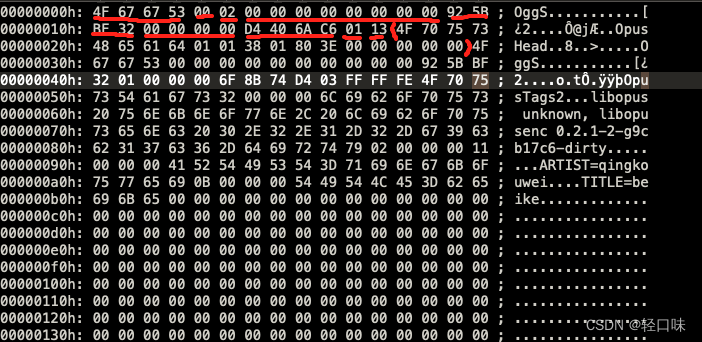
- 0x4F 0x67 0x67 0x53 : capture_pattern页标识,OggS ASCII字符
- 00 : stream_structure_version,版本id
- 02 : header_type_flag,类型标识,表示该页为逻辑流的第一页
- 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 : granule_position:媒体编码相关的参数信息,表示到本页为止逻辑流有0个采样
- 0x92 0x5B 0xBF 0x32 serial_number:当前页中的流的id
- 0x00 0x00 0x00 0x00 : page_seguence_number:本页在逻辑流的序号
- 0xD4 0x40 0x6A 0xC6 : CRC_cbecksum:循环冗余效验码效验
- 0x01 : number_page_segments:给定本页在segment_table域中出现的segement个数,本页只有一个
- 0x13 : segment_table,本页只有一个长度为19的segment
- 0x4F-0x00 : page data,后面分析
第二页
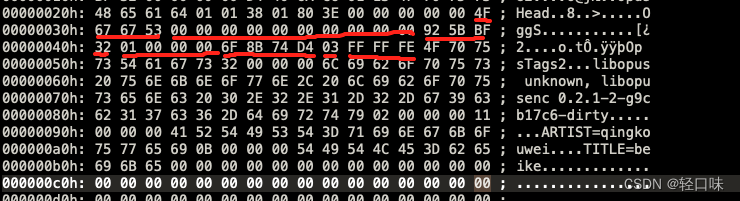
…

- 0x4F 0x67 0x67 0x53 : capture_pattern页标识,OggS ASCII字符
- 00 : stream_structure_version,版本id 0
- 0x00 : header_type_flag,类型标识,表示该页不是逻辑流的第一页,不是最后一页,也不是延续之前packet
- 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 : granule_position:媒体编码相关的参数信息,表示到本页为止逻辑流有0个采样
- 0x92 0x5B 0xBF 0x32 : serial_number,当前页中的流的id
- 0x01 0x00 0x00 0x00 : page_seguence_number:本页在逻辑流的序号
- 0x6F 0x8B 0x74 0xD4 : CRC_cbecksum:循环冗余效验码效验
- 0x03 : number_page_segments:给定本页在segment_table域中出现的segement个数,本页有3个
- 0xFF 0xFF 0xFF : segment_table,本页有三个segment,三个segment组成一个packet,大小为255+255+254 = 764(0x2fc),计算下来最后一个字节的位置应该是0000004Dh + 2fch = 349h
- 0x0000004D-0x00000349 : page data,后面分析
第三页
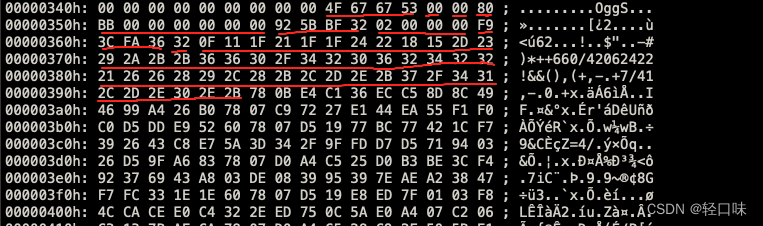
- 0x4F 0x67 0x67 0x53 : capture_pattern页标识,OggS ASCII字符
- 00 : stream_structure_version,版本id 0
- 0x00 : header_type_flag,类型标识,表示该页不是逻辑流的第一页,不是最后一页,也不是延续之前packet
- 0x80 0xBB 0x00 0x00 0x00 0x00 0x00 0x00 : granule_position:媒体编码相关的参数信息,表示到本页为止逻辑流有48000个采样(小端,0xBB80 = 48000
- 0x92 0x5B 0xBF 0x32 : serial_number,当前页中的流的id
- 0x02 0x00 0x00 0x00 : page_seguence_number:本页在逻辑流的序号
- 0xF9 0x3C 0xFA 0x36 : CRC_cbecksum:循环冗余效验码效验
- 0x32 : number_page_segments:给定本页在segment_table域中出现的segement个数,本页有50个
- 0x0F 0x11 … 0x2B : segment_table,本页有50个segment,50个segment组成50个packet
- 0x00000364-0x00000bca : page data,后面分析 0x866=2150个字节 本文件码率为16kbits/s,帧大小为20ms,一帧16000/8/1000*20=40字节,
第四页

- 0x4F 0x67 0x67 0x53 : capture_pattern页标识,OggS ASCII字符
- 00 : stream_structure_version,版本id 0
- 0x00 : header_type_flag,类型标识,表示该页不是逻辑流的第一页,不是最后一页,也不是延续之前packet
- 0x00 0x77 0x01 0x00 0x00 0x00 0x00 0x00 : granule_position:媒体编码相关的参数信息,表示到本页为止逻辑流有48000个采样(小端,0x017700 = 96000
- 0x92 0x5B 0xBF 0x32 : serial_number,当前页中的流的id
- 0x03 0x00 0x00 0x00 : page_seguence_number:本页在逻辑流的序号
- 0x89 0xB5 0x54 0x5E : CRC_cbecksum:循环冗余效验码效验
- 0x32 : number_page_segments:给定本页在segment_table域中出现的segement个数,本页有50个
- 0x32 0x30 … 0x35: segment_table,本页有50个segment,50个segment组成50个packet
- 0x00000c18-0x0000146a : page data,后面分析 0x852=2130个字节
第三页第四页已经开始很类似,是时候真正的解析Page中的Opus,首先还是从官方文档看看Opus是怎么封装进Ogg容器的
Opus音频编解码器的Ogg封装
参考Ogg Encapsulation for the opus Audio Codec,先来个简单介绍:
简介
IETF Opus编解码器是针对两者均进行了优化的低延迟音频编解码器语音和通用音频。有关技术,请参见[RFC6716]细节。本文档定义了Opus封装在连续的逻辑Ogg位流[RFC3533]。 Ogg封装为Opus提供长期存储格式,支持所有基本功能,包括元数据,快速准确的搜索,损坏检测,错误后重新捕获,低开销以及能够将Opus与其他编解码器(包括视频)复用最小缓冲。它还提供了实时流式格式通过可靠的面向流的运输进行交付,而无需需要所有数据(甚至是数据的总长度)以与磁盘存储格式相同的形式预先存储。这样解决了咱们最开始提到为什么要封装提出的问题.
Ogg Opus推荐的mime-type是audio/ogg,高特性的可以设置为’audio/ogg;codecs=opus’,推荐的文件扩展名为.opus
直接引用一段文档原文,继续我们的解析之旅:
This encapsulation defines the contents of the packet data, including the necessary headers, the organization of those packets into a logical stream, and the interpretation of the codec-specific granule position field. It does not attempt to describe or specify the existing Ogg container format. Readers unfamiliar with the basic concepts mentioned above are encouraged to review the details in [RFC3533].
packet Organization
一个Ogg Opus流被组织成如下结构:
Page 0 Pages 1 ... n Pages (n+1) ...+------------+ +---+ +---+ ... +---+ +-----------+ +---------+ +--| | | | | | | | | | | | ||+----------+| |+-----------------+| |+-------------------+ +-----|||ID Header|| || Comment Header || ||Audio Data Packet 1| | ...|+----------+| |+-----------------+| |+-------------------+ +-----| | | | | | | | | | | | |+------------+ +---+ +---+ ... +---+ +-----------+ +---------+ +--^ ^ ^| | || | Mandatory Page Break| || ID header is contained on a single page|'Beginning Of Stream'
Figure 1: Example Packet Organization for a Logical Ogg Opus Stream
它有两个mandator header packets:
- ID header:在ogg逻辑流中的第一个包必须包含ID header,它唯一的把一个流标识成一个opus音频.它单独的并且完整的放置在ogg逻辑流的第一页.这一页有bos标记
- comment header:逻辑流中第二个包必须包含comment header,它包含用户提供的元信息.它可能是跨多个页,从第二个逻辑页开始.无论comment header跨多少页,它必须结束在它完成的地方.
随后的所有页面都是音频数据页面,它们的Ogg数据包包含音频数据包。对于N个不同的流中的每一个,每个音频数据包都包含一个Opus包,其中对于单声道或立体声,N通常为1,但对于多声道音频,N可能大于1。值N在ID标头中指定,并在逻辑Ogg比特流的整个长度上固定。
Identification Header
0 1 2 30 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| 'O' | 'p' | 'u' | 's' |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| 'H' | 'e' | 'a' | 'd' |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| Version = 1 | Channel Count | Pre-skip |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| Input Sample Rate (Hz) |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| Output Gain (Q7.8 in dB) | Mapping Family| |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ :| |: Optional Channel Mapping Table... :| |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
对应我们文件第一个page data:
4F 70 75 73 48 65 61 64
01
01
38 01
80 3E 00 00
00 00 00
- Magic Signature:OpusHead 8字节
- Version : 1字节 unsigned,对应值 0x01
- Output Channel Count ‘C’:1个字节,unsigned,声道数,它可能和编码声道数不一致,它可能被修改成packet-by-packet,对应值0x01
- Pre-skip:2字节,unsigned,小端,这是要从开始播放时的解码器输出,从页面的颗粒位置减去以计算其PCM样本位置。裁剪现有Ogg的开头时Opus流是至少3840个样本(80毫秒)的预跳过时间是建议确保解码器中完全收敛。对应值0x0138=312字节
- Input Sample Rate:4字节,unsigned, little endian,原始输入采样,对应值0x3e80=16000
- Output Gain:2字节,signed,little endian,这是解码时要应用的增益。是20 * log10缩放解码器输出以实现所需的播放音量,以16位带符号二进制存储,对应值:0x0000
- Channel Mapping Family:1字节,unsigned,该字节指示输出渠道的顺序和语音含义.该八位位组的每个当前指定的值表示一个映射系列,它定义了一组允许的通道数,以及每个允许的通道数的通道名称的有序集合.当前值0x0,表示声道数为1或者2
- Channel Mapping Table:可选,当Channel Mapping Family为0时被省略.
Comment Header
0 1 2 30 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| 'O' | 'p' | 'u' | 's' |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| 'T' | 'a' | 'g' | 's' |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| Vendor String Length |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| |: Vendor String... :| |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| User Comment List Length |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| User Comment #0 String Length |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| |: User Comment #0 String... :| |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+| User Comment #1 String Length |+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+: :
对应文件的第二个page data:
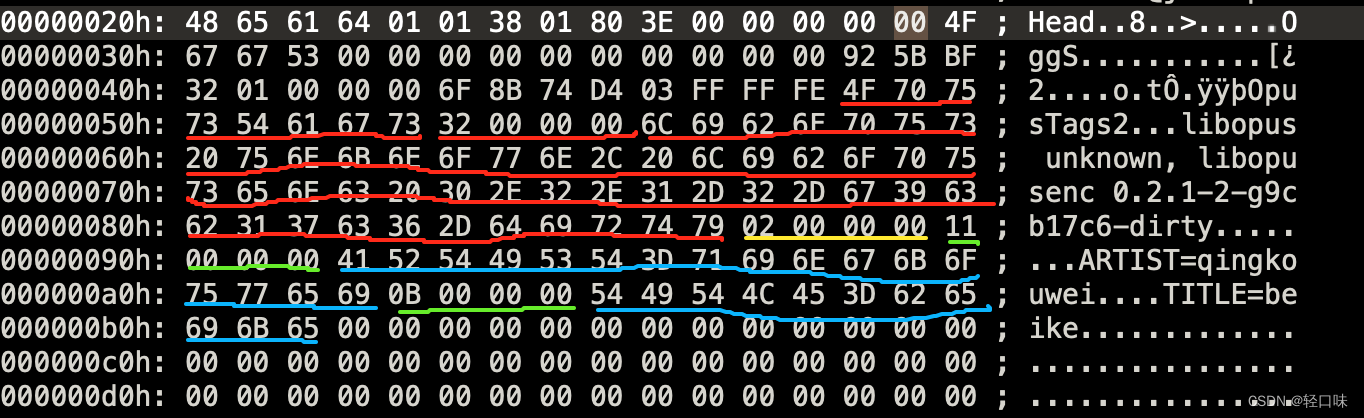
- Magic Signature:8个字节,OpusTags
- Vendor String Length:4个字节,unsigned,little endian:当前值:0x00000032=50字节
- Vendor String:长度由Vendor String Length指定,utf-8编码,当前值0x6C 0x69 …0x74 0x79,内容:“libopus unknown,libopusenc 0.2.1-2-g9cb17c6-dirty”,因为我用的是libopussenc输出的
- User Comment List Length:4字节,unsigned, little endian,该字段指示用户提供的注释数。它可能表示用户提供的评论为零,在这种情况下数据包中没有其他字段。一定不要表示评论太多,以至于评论字符串长度将需要比其余的可用数据更多的数据数据包。当前值0x00 00 00 02 = 2个评论
- User Comment #i String Length:4字节,unsigned, little endian:该字段提供以下用户注释字符串的长度,以八位字节为单位。每个用户评论都有一个,由“用户评论列表长度”字段。它不得表示字符串比数据包的其余部分长。当前值:0x00 00 00 11 = 17
- User Comment #i String:可变长度,UTF-8载体,当前值0x41 0x52 … 0x69 0x0B,内容为"ARTIST=qingkouwei"
我们使用的这个文件有两个User Comment,第二个为:
- User Comment List Length: 0x00 00 00 0B = 11个字节
- User Comment: 0x54 0x49 …0x6B 0x65,内容为"TITLE=beike"
总字节大小: 12 + 50 + 4 + 4 + 17 + 4 + 11 = 102 ,与前面计算的764字节差下的字节都是padding
紧随用户评论列表之后,评论标头可以包含零填充或此处未指定的其他二进制数据。如果此数据的第一个字节的最低有效位是1,然后编辑者应在更新时保留此数据的内容标签,但是如果该位为0,则可以将所有此类数据视为填充,并根据需要截断或丢弃。可以为后面提供扩展预留空间.
注释标题可以任意大,并且可以分布在大量的Ogg页面。实现必须避免尝试出现为过大的标题分配过大的内存。为了做到这一点,实现可以对待如果流的注释头大于125,829,120个八位位组(120 MB),视为无效,并且可以忽略未完全包含在注释的前61,440个八位字节中标头。
用户注释字符串遵循由NAME = value所描述的格式[VORBIS-COMMENT]具有相同的推荐标签名称:ARTIST,TITLE,DATE,ALBUM等。
OggOpus先介绍到这,后面继续分析OggOpus封装库的实现与API等.
参考
- OggOpus Wiki
- (rfc7845)Ogg Encapsulation for the Opus Audio Codec