离开模型能力谈API价格都是耍流氓,豆包大模型作为API最便宜的模型之一,最近向个人开发者开放了,花了300元和一些时间对模型的API吞吐、函数调用能力、长上下文能力等进行了深度测试,看看它的能力究竟适合做 AI 应用开发吗?
本文首发自个人博客 豆包系列大模型能力深度体验,除了便宜,还有哪些亮点?
我的新书《LangChain编程从入门到实践》 已经开售!推荐正在学习AI应用开发的朋友购买阅读,此书围绕LangChain梳理了AI应用开发的范式转变,除了LangChain,还涉及其他诸如 LIamaIndex、AutoGen、AutoGPT、Semantic Kernel等热门开发框架。

本文首发自个人博客 豆包系列大模型能力深度体验,除了便宜,还有哪些亮点?
测试指标
测试指标选哪些,这里以我自己实际接触到的一次企业客户技术咨询为例,抛开大模型厂商自己作为宣传的跑分榜单,看看企业选型究竟关注什么,下面是对方当时抛出的问题:
我们想跟大模型公司合作,通过 api 调用他们的大模型,在找这样的公司时主要考虑什么哪些因素呢,我列了下面几点:
1、模型性能和能力:参数规模、训练数据集的来源和大小、上下文长度
2、模型类型(模型能力):有哪些模型类型,文本模型、语音模型,是否有向量化模型
3、易用性和接入方式:API 的接入方式、文档的完整性、SDK 的支持情况等。
4、成本:定价策略,包括计算资源的计费方式,token 如何收付
5、安全性和合规性:数据隐私保护、是否符合相关法律法规和标准
6、性能稳定性和故障率:模型运行的稳定性,系统故障和崩溃的频率
7、并发处理能力:模型能够处理的并发请求量
8、调用 API 的响应时间
9、可扩展性:是否具有良好的可扩展性,能够随着企业业务的发展而不断升级和优化。
我本篇内容会围绕这些点展开。
模型类型
进入模型广场,火山方舟当前支持接入 14 个大语言模型,模型提供商除了字节,还有 Moonshot、智谱 AI、Mistral AI(开源)、Meta(开源),除此之外还提供了面向向量检索场景的向量模型 doubao-embedding,用于声音克隆的语音模型 ve-voiceclone,不过这里我们主要关注豆包系列 6 个语言模型,即 Doubao-lite-4k 、Doubao-lite-32k 、Doubao-lite-128k 、Doubao-pro-4k 、Doubao-pro-32k 、Doubao-pro-128k 。
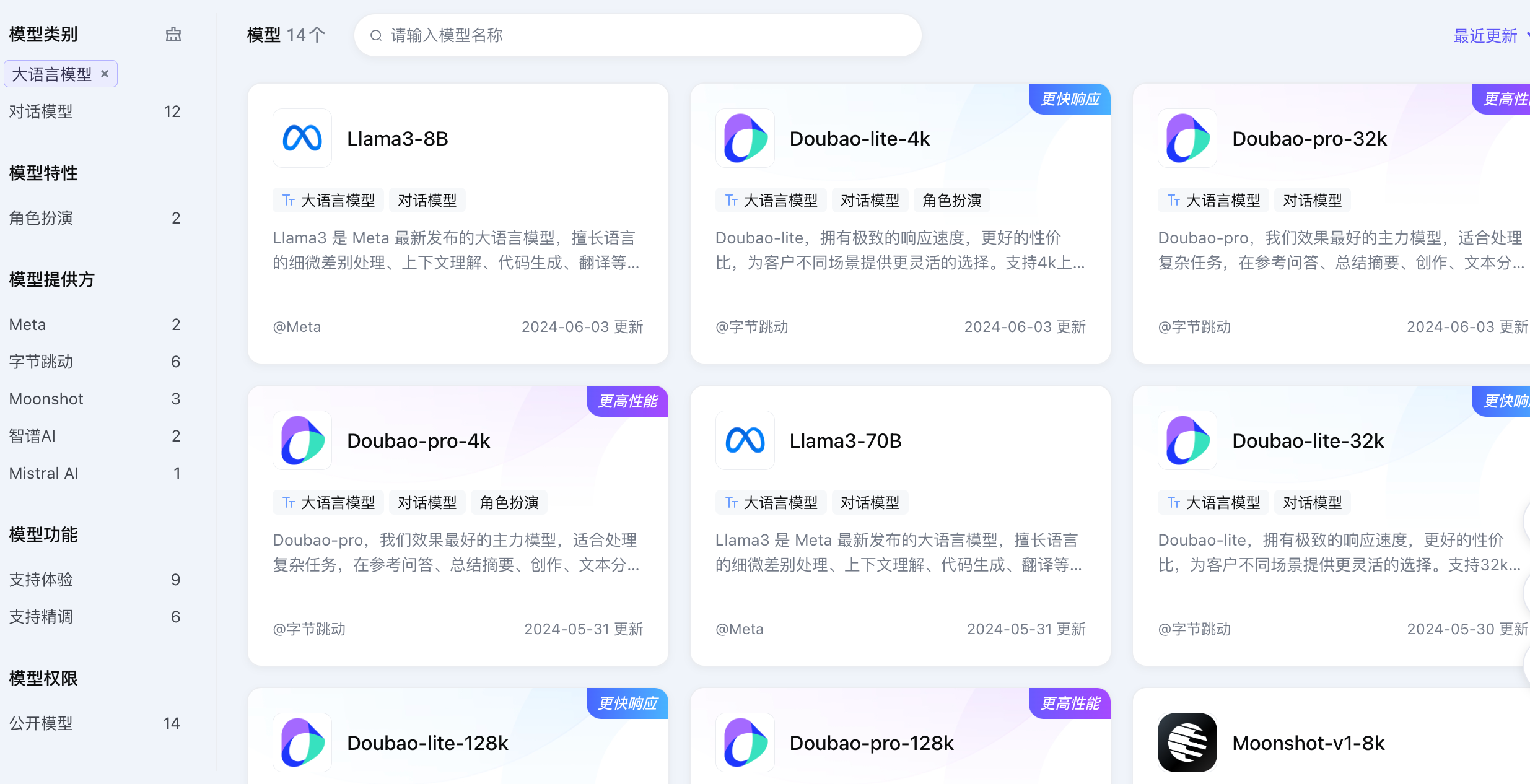
下面是它们的区别,来自官网介绍:
- Doubao-pro-4k 我们效果最好的主力模型,适合处理复杂任务,在参考问答、总结摘要、创作、文本分类、角色扮演等场景都有很好的效果。支持 4k 上下文窗口的推理和精调。
- Doubao-pro-32k 我们效果最好的主力模型,适合处理复杂任务,在参考问答、总结摘要、创作、文本分类、角色扮演等场景都有很好的效果。支持 32k 上下文窗口的推理和精调。
- Doubao-pro-128k 我们效果最好的主力模型,适合处理复杂任务,在参考问答、总结摘要、创作、文本分类、角色扮演等场景都有很好的效果。支持 128k 上下文窗口的推理和精调。
- Doubao-lite-4k 拥有极致的响应速度,更好的性价比,为客户不同场景提供更灵活的选择。支持 4k 上下文窗口的推理和精调。
- Doubao-lite-32k 拥有极致的响应速度,更好的性价比,为客户不同场景提供更灵活的选择。支持 32k 上下文窗口的推理和精调。
- Doubao-lite-128k 拥有极致的响应速度,更好的性价比,为客户不同场景提供更灵活的选择。支持 128k 上下文窗口的推理和精调。
挺废话的,开发者关注的模型性能和能力说明基本没有,只提到了上下文长度,不过这部分后面我会有具体的测试。
模型初体验
这里以最强的 Doubao-pro-128k 作为测试,使用 API 调用使用前,需要先创建推理接入点,需要注意的是,当前只有华北 2(北京)这一个 region 可选,对 TTFT(首 token 输出耗时)敏感的应用接入时需要特别注意
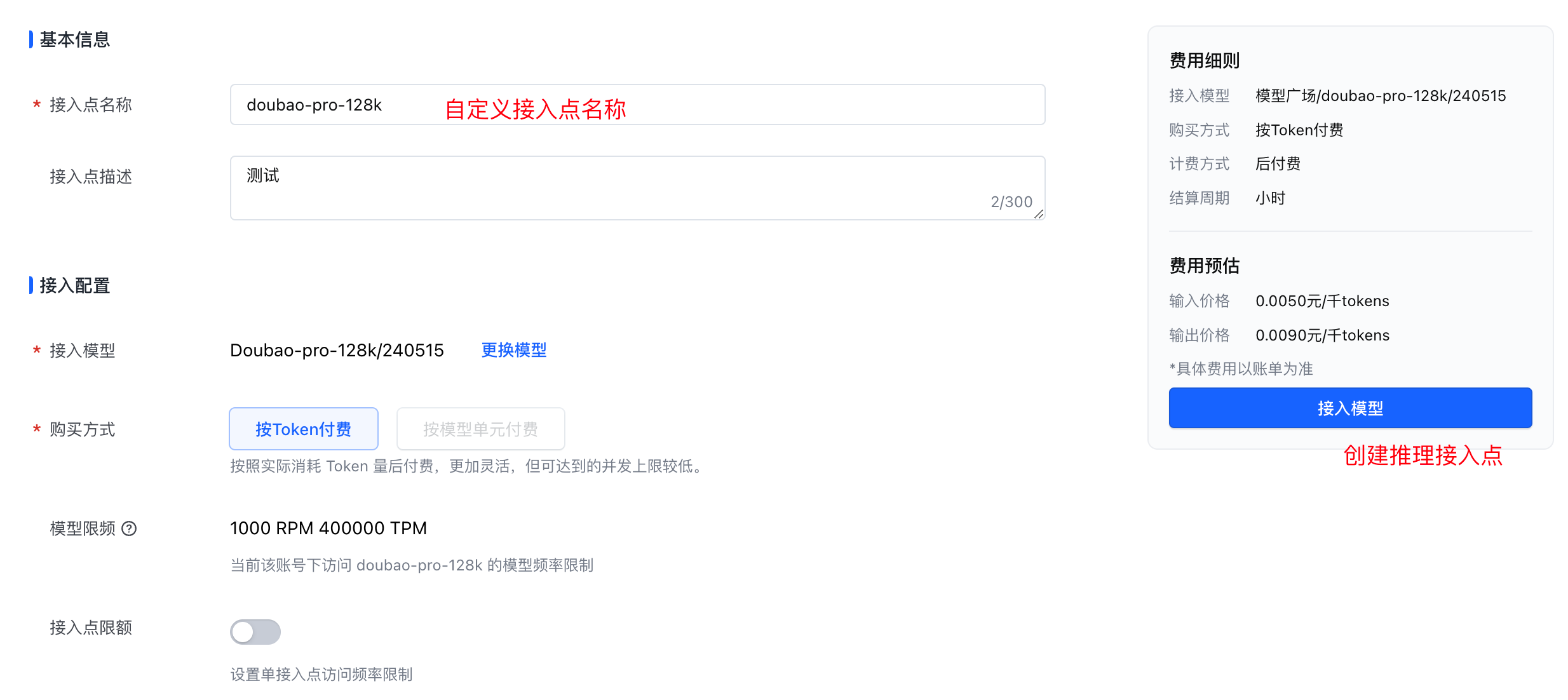
然后在模型推理的入口就可以看到我们的刚刚创建的推理点,大概 1 ~ 3s 等待状态从调度中切换为健康就可以通过 API 方式调用了。

API 调用时支持两种授权方式,一种是采用直接生成的 API Key 授权(推荐个人开发者采用),一种是火山引擎 IAM 授权(推荐企业开发者采用),我这里选用 API Key 授权方式调用:
import os
import requests
import json# 从环境变量中获取API密钥和模型ID
api_key = os.getenv("API_KEY")
model = os.getenv("MODEL")url = "https://ark.cn-beijing.volces.com/api/v3/chat/completions"headers = {"Content-Type": "application/json","Authorization": f"Bearer {api_key}"
}data = {"model": model,"messages": [{"role": "system","content": "You are a helpful assistant."},{"role": "user","content": "你好!"}],"stream": False
}response = requests.post(url, headers=headers, json=data)
result = json.loads(response.content)
print(result["choices"][0]["message"]["content"])
当然也可以选择 OpenAI 兼容的方式访问:
import os
from openai import OpenAI# 从环境变量中获取API密钥和模型ID
api_key = os.getenv("API_KEY")
model = os.getenv("MODEL")url = "https://ark.cn-beijing.volces.com/api/v3"client = OpenAI(base_url=url, api_key=api_key)response = client.chat.completions.create(model=model,messages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "你好!"}]
)
print(response.choices[0].message.content)
官网也提供了官方 SDK 调用方式,默认走火山引擎 IAM 授权,且每次调用都包括一次 token 获取刷新操作,可以自行可以在这里直接生成 token(https://api.volcengine.com/api-explorer),token最长有效时间可以设置为30天,SDK版本分为 V3 和 V2 两个版本。
V3 版本目前暂且只支持 cURL(原生 HTTP 请求)和 Python SDK 方式,暂不支持 Go SDK、Java SDK 及 JS SDK 方式调用,并且 Python SDK 方式也暂不支持 Function Call 能力(文档未说明,但测试下来未生效)。
V2 版本虽然支持 Go SDK 及 Java SDK,也支持 Function Call 能力,但是接口设计极其丑陋,下面是官网 API 调用示例,大家可以自行评价。
import os
from volcengine.maas.v2 import MaasService
from volcengine.maas import MaasException, ChatRoledef test_chat(maas, endpoint_id, req):try:resp = maas.chat(endpoint_id, req)print(resp)except MaasException as e:print(e)if __name__ == '__main__':maas = MaasService('maas-api.ml-platform-cn-beijing.volces.com', 'cn-beijing')maas.set_ak(os.getenv("VOLC_ACCESSKEY"))maas.set_sk(os.getenv("VOLC_SECRETKEY"))req = {"messages": [{"role": ChatRole.USER,"content": "你好"}]}endpoint_id = "{YOUR_ENDPOINT_ID}"test_chat(maas, endpoint_id, req)test_stream_chat(maas, endpoint_id, req)
而且 MaaS 当前不对个人开发者开放,所以 V2 版本的 SDK 基本是没法用的。
总结起来,使用官方 SDK,目前是无法使用 Function Call 能力的,所以只有曲线救国,按照 OpenAI 兼容的方式去调用了,这个我会在后面测试 Function Call 能力的部分放出来。
模型成本
豆包模型从最便宜的的 0.3 元每百万 tokens 的 lite-4k 到最贵的 9 元每百万 tokens 的 pro-128k,计费方式分为后付费和预付费方式,后付费通常限制 TPM(每分钟 token 数)和 RPM(每分钟请求数)的最高值,豆包大模型相较其他大型厂商,其后付费模式的 TPM 和 RPM 上限也非常高(见下图,当然也可以通过申请工单的方式在此基础上提额度),足以满足大多数公司的业务需求。
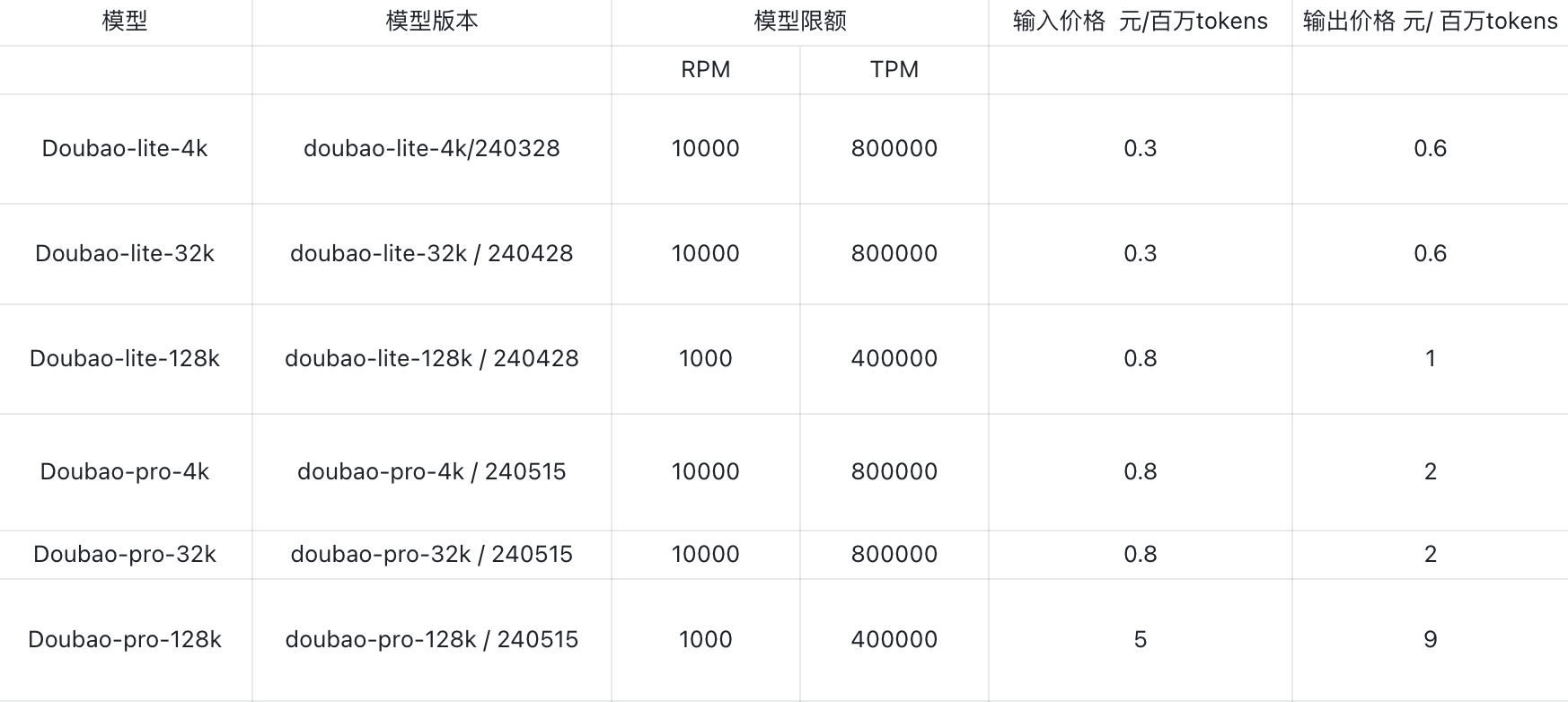
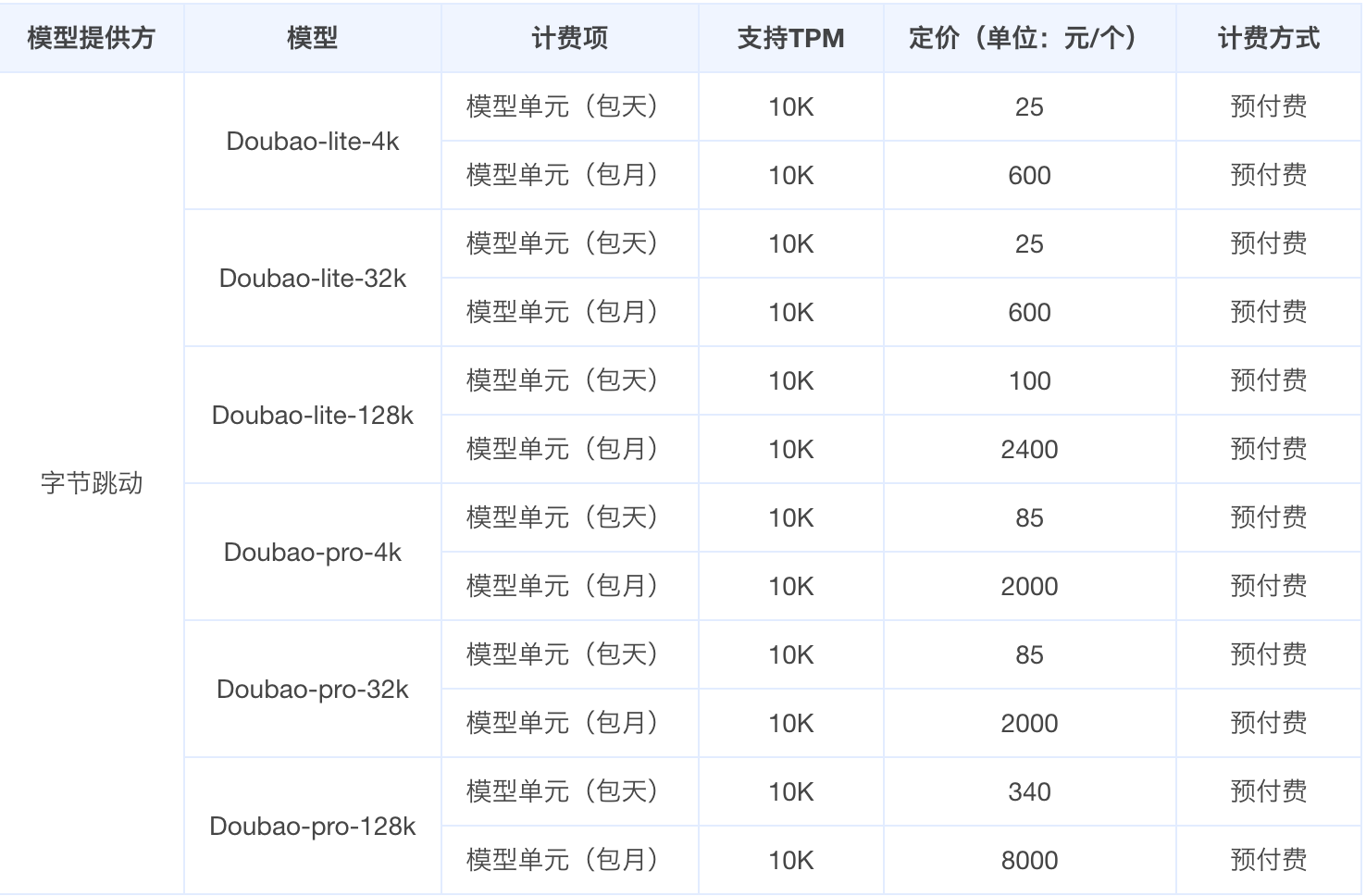
预付费模式提供更多附加服务,价格相对后付费更昂贵,但预付费通常享有大幅折扣,按行业标准打折下来大致为预付费两三倍,这种模式主要适用于少数需要高并发保障的大客户,预付费模式可以选择的有包天、包月,由于后付费方式的 API 吞吐已经能够支撑绝大多数场景,这里不再详细展开。
模型能力
离开模型能力谈成本那就是耍流氓,我在大模型价格战是浑水摸鱼的噱头吗?仔细分析过,否则你再便宜,如果不能用那都是营销噱头。做应用最关注的就是有效的长上下文能力(用于多轮对话记忆保持、各种阅读助手、长文本理解等常见场景)和 Function Call 能力(工具调用,构建智能体应用的基础),这两种底层能力决定 AI 应用的效果,另一个关键点就是 API 吞吐,决定了 AI 应用的体验,下面我将逐个对豆包模型这三方面进行测试。
API 吞吐
首先是 API 吞吐,明确下我的测试环境:
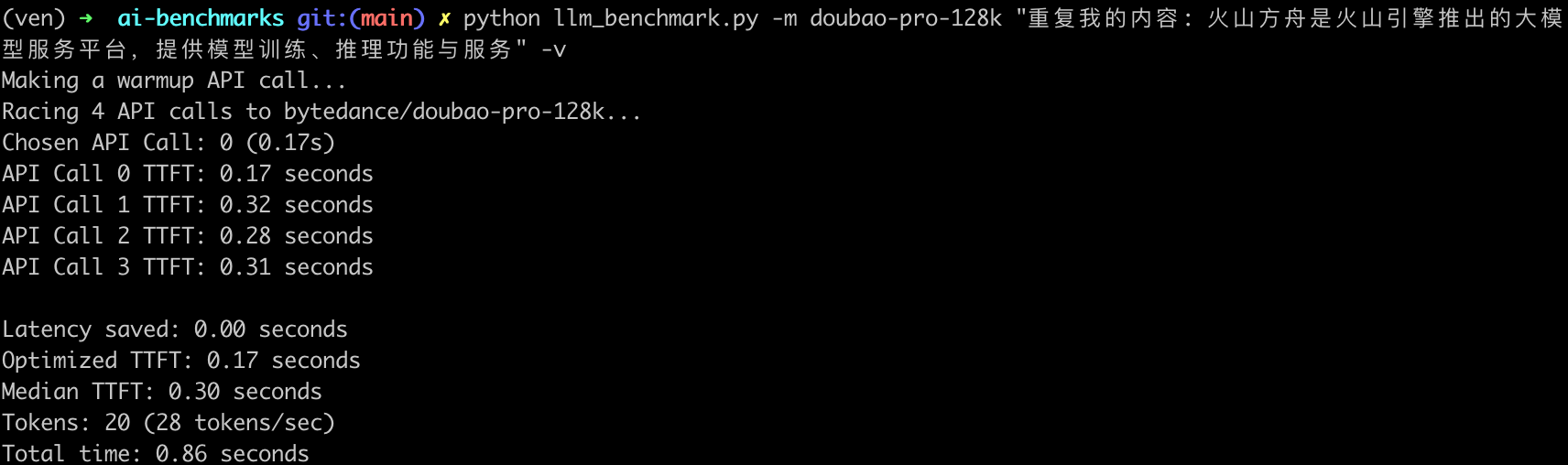
测试环境:请求所在地的 Region 在西南 1(成都),模型推理服务所在的 Region 在 华北 2(北京),测试时间是 2024 年 6 月 11 日 21:00,由于使用 SDK 的方式调用,每次都会刷新 API Key,有额外的耗时,所以这里选择直接生成持久 API Key(https://api.volcengine.com/api-explorer),然后构造原生HTTP请求的方式调用模型API接口,每轮测试前都会请求五次接口,下面是其中一组数据:
指标说明
测试时的输入提示词「重复我的内容: 火山方舟是火山引擎推出的大模型服务平台,提供模型训练、推理功能与服务」,使用豆包模型的分词器,输出 20 个 token,对应大约 34 个中文字符。
- 首次响应时间与最快响应时间差(
Latency saved 0.00s): 表示首次响应时间与最快响应时间之间的差异,这个指标可以反映出大模型 API 服务在处理请求时的波动。 - 首 token 最短耗时(
Optimized TTFT 0.17s):是指在多次请求中,最快的一次首 token 响应时间。 - 首 token 耗时中位数(
Median TTFT 0.30s):是指在所有请求中,首 token 响应时间的中位数,即一半的请求首 token 响应时间比这个值快,另一半比这个值慢。中位数可以提供一个更稳健的性能指标,因为它不受极端值的影响。 - token 总数(
Tokens: 20):表示在请求过程中生成的 token 总数。(输出 token 数被设置为 20 个,对应 34 个中文字符是日常正式对话常见句子长度) - token 生成速率(
28 tokens/sec): 表示每秒生成的 Token 数量(TPS),这是衡量大模型 API 服务处理能力的一个指标。 - 总耗时(
Total time: 0.86s): 表示从开始发送 HTTP 请求到接收到最后一个 token 的时间,这是整个请求处理过程的总耗时。总耗时 🟰TTFT➕token 总数 ➗TPS
下面是各个模型的数据:
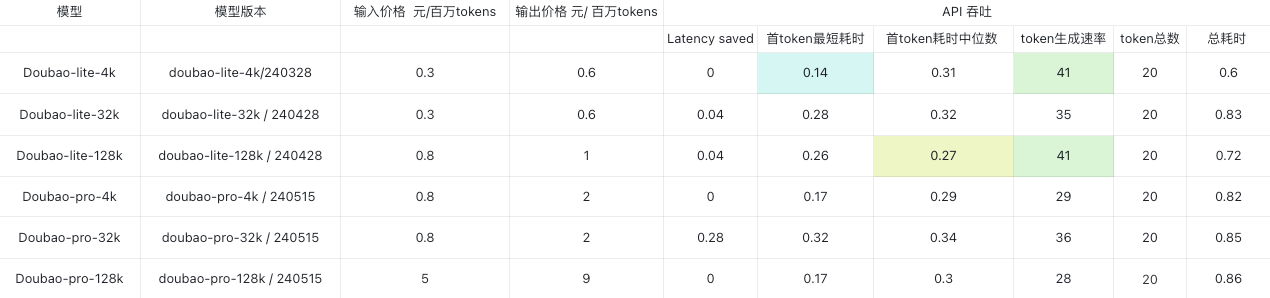
以自然对话中的标准响应间隔大约为 200 毫秒为基准,除了 Doubao-pro-32k,其他模型的首 token 耗时都可以很好的满足要求,当然 Doubao-pro-32k API 本身波动也较高,不排除本次测试结果的偶然性,真正生产使用,是需要在环境中多次持续性拔测的。
Function Call 能力
智能体应用构建的核心,看重的其实是模型的工具调用能力,确切来说就是 Function Call 能力,详细可以看我这篇基于大模型的 Agent 进行任务规划的 10 种方式。由于大模型对 Function Call 的指令跟随差异性很大,经常需要尝试不同模型+Prompt 组合,这里我选用斯坦福大学的 Function Call 数据集对支持 Function Call 能力的模型进行测试(需要说明的是,当前只有 Doubao-pro-4k、Doubao-lite-4k、Doubao-pro-32k 三款模型支持 Function Call 能力,但是 lite 版面对复杂 case 多次测试效果不理想,这里就没有继续测试,所以数据主要关注 Doubao-pro-4k 和 Doubao-pro-32k 模型)。
先简单介绍下 BFCL(Berkeley Function-Calling Leaderboard,伯克利函数调用排行榜),完整数据集由 1.7k 个问题-函数-答案对组成,涉及 python、java、javascript 三种编程语言,覆盖不同应用领域的复杂用例,使用抽象语法树(AST Evaluation ) 和可执行函数(Executing APIs )两种评估方式对结果进行评估,其次还对函数调用幻觉问题进行评估(即传入的所有函数都与问题不相关,理想情况下模型应该不进行任何函数调用),用于测试模型是否会在函数或参数选择上产生幻觉情况, 具体组成如下图所示,更详细的用例设计说明见介绍https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html。
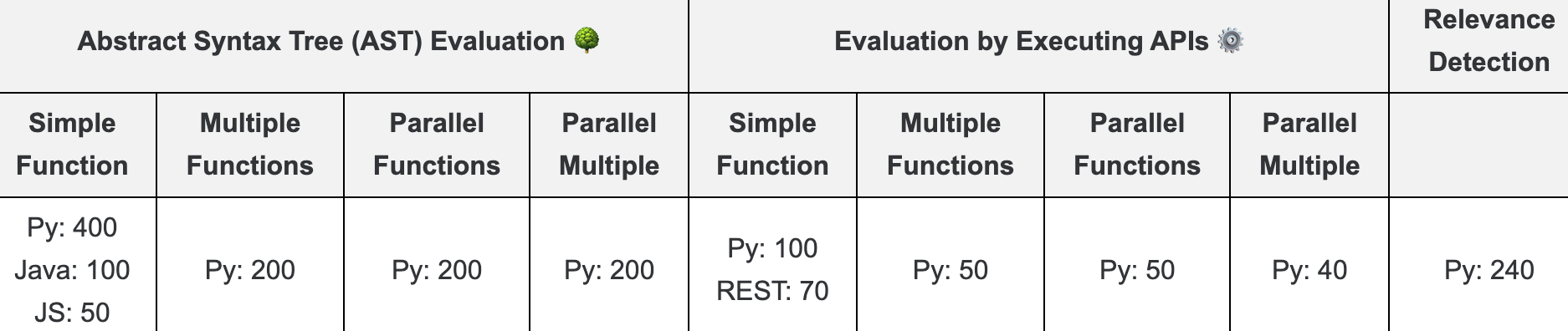
这里我选用 AST Evaluation 方式对结果进行评估,同时 Simple Function 数据只选取了 Python 函数,所以最终我的数据集由 1k 条问题-函数-答案对(Simple Function 400+ Multiple Functions 200+Parallel Functions 200+Parallel Multiple Functions 200)组成,详细的测试结果数据可以后台回复「豆包」获取。
- Simple Function(简单函数):用户提供单一函数,模型仅需调用一次函数。
- Multiple Functions(多个函数):用户问题涉及 2 到 4 个函数,模型需根据上下文选择最合适的一个函数进行调用。
- Parallel Functions(并行函数):模型在一次用户查询中需并行调用多个独立的函数。
- Parallel Multiple Functions(并行多个函数):并行多个函数是并行函数和多个函数方式的结合,模型一次从 2 到 4 个函数中并行调用多个独立的函数。

通过测试发现,在简单函数调用场景下,Doubao-pro-4k 和 Doubao-pro-32k 模型和比较领先的 GPT-4-1106-Preview 和 Gemini-1.5-Pro-Preview-0514 处于同一水平,而且成本优势明显,推荐采用;在多函数场景下,准确率明显降低,但是也在 80%以上,可以结合成本和业务重要性有选择采用;在并行调用多个独立的函数方面能力显著下降,基本属于不可用状态;函数调用幻觉问题方面豆包模型表现优秀,毕竟让大模型能够回答“我不知道”,可以极大的降低业务使用大模型过程中的风险。
长上下文能力
智能体应用构建除了关注 Function Call 能力,最看重的就是长上下文能力,LLMTest_NeedleInAHaystack(中文译作”大海捞针“)实验是对大模型实际长文本能力进行压测的成熟方案,原理简单,并且符合日常使用习惯,测试的过程如下:
- 将一个随机的事实或陈述(“针”)放在一个长上下文窗口(“大海捞针”)的中间
- 要求模型检索此语句
- 遍历各种文档深度(指针放置位置)和上下文长度以衡量性能
这里我从 Doubao-pro-128k 模型 128K 上下文窗口中抽样提取了 50 个不同上下文窗口长度区间,然后针对每个长度区间,分别在文档的 1%、6%、11% …99% 总共 20 个不同的文档深度处放置“针”,总共采集了 1000 (50*20)条数据。
needlehaystack.run_test --provider bytedance --model_name "doubao-pro-128k" --document_depth_percent_min 1 --document_depth_percent_max 99 --document_depth_percent_intervals 20 --context_lengths_min 1000 --context_lengths_max 128000 --context_lengths_num_intervals 50
下面是 Doubao-pro-128k 的测试结果:
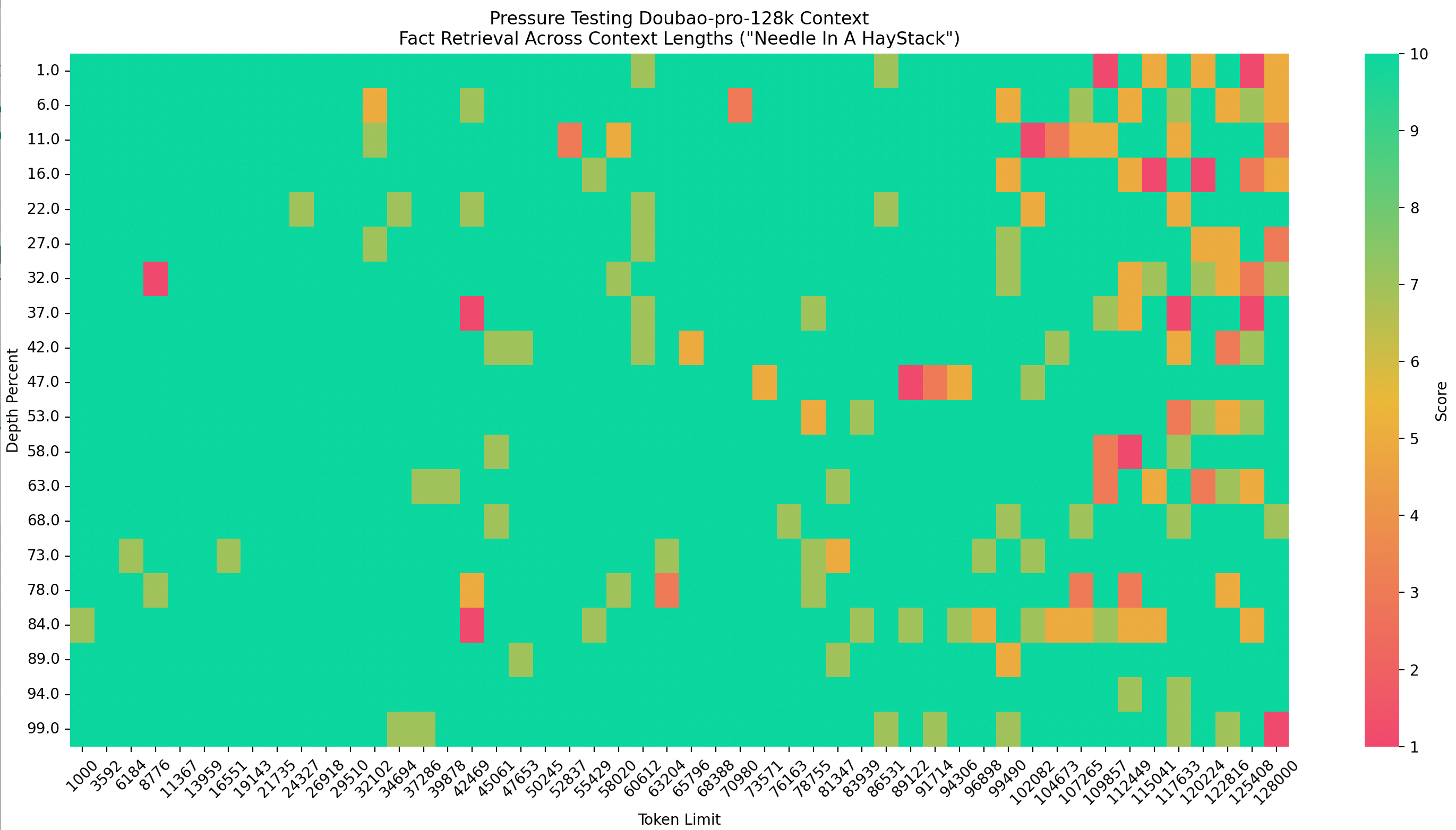
Score 为 1 的一共有 13 条结果(深红色的块),Score 为 3 的一共有 16 条结果,Score 为 5 的一共有 40 条结果,Score 为 7 的一共有 72 条结果(墨绿色的块,根据下面的定义,Score 7 的结果也是可接受的),可以看到从 100K 上下文窗口开始,深红色和橘黄色块开始密集,模型在长上下文的前后中不同部分获取相关信息时,性能明显下降,这也说明 Doubao-pro-128k 实际的上下文窗口在 100K 左右,详细的测试结果数据可以后台回复「豆包」获取。
这里不同的色块代表答案与参考的相关性:
- Score 1: 答案与参考完全无关
- Score 3: 答案有轻微的相关性,但与参考不符
- Score 5: 答案有中等的相关性,但包含不准确之处
- Score 7: 答案与参考相符,但有轻微的遗漏
- Score 10: 答案完全准确并与参考完全一致
这个结果属于什么水平呢,这里使用 GPT-4、Claude 2.1 以及主打长上下文能力的 Kimi 的作为对比:
GPT-4-1106-Preview(128K)的测试结果

Claude 2.1(200K)的测试结果

Kimi 的测试结果
下面是主打长上下文能力的国内大模型 Kimi(128K) 测试结果,但是官方并未同时放出测试结果数据。

不过“大海捞针”实验结果也受到“针”所表述的事实是否无歧义和提问的 Prompt 是否足够明确的影响,而且打分也是用大模型,存在一定的局限性,但对于直观的感知大模型长文本能力足够了。
总结
我在无数个场合被问过哪家大模型能力强、效果好,我个人一直持有的观点就是这是一个小马过河的问题,关键看你个人或所在公司是否根据涉及的业务场景提炼出一套自己独有的测试集,如果在你自己的测试集上跑的满意,那它对你来说就是效果最好的,然后再去综合接入成本、安全合规等因素去选型。
模型服务协议
看完上面的硬指标,最后快速过下豆包的大模型服务协议,我关注的三个点就是内容安全合规、数据隐私保护和 SLA(Service Level Agreement,服务级别协议)。
内容安全合规
关于大模型生成内容安全合规问题,下面是协议原文:
您保证在使用本协议项下服务时须遵守相关法律法规,不违反《中华人民共和国刑法》、《中华人民共和国反不正当竞争法》、《中华人民共和国网络安全法》、《中华人民共和国数据安全法》、《中华人民共和国个人信息保护法》等相关法律法规及政策,维护互联网秩序和网络安全,不得利用服务发布危害国家安全的、破坏民族团结的、扰乱社会秩序的、有歧视性的、不正当的言论,或侵害任何第三方的个人信息保护权、名誉权、人格权、知识产权、财产权等其他任何权益,或从事涉及黄赌毒、违反法律法规或公序良俗的行为。如果您(包括您应用/网站用户)有任何违反服务使用规范行为的,火山引擎有权采取警示、限制功能、暂停提供服务、删除违法违规信息、锁定账号等火山引擎认为合理的处理措施。
您接入我们服务向公众提供内容生成式人工智能产品或服务的,需要开展安全评估和算法备案工作,且应同时满足法律法规政策相关的要求,对生成内容的安全性、合法性、合规性进行有效管理和控制,建立包括但不限于内容审核、用户管理、数据安全、监测预警和应急处置等机制。如因用户使用您产品或服务导致数据安全、舆情风险或发生任何产品或服务被滥用、传播、不当利用而产生的风险和责任,应由您自行承担。因此给火山引擎造成损失的,您应向火山引擎承担相应责任。
为履行法定合规要求,火山引擎有权采取技术手段或人工手段对您使用本服务的行为及信息进行审查,包括但不限于对您提交给服务或使用服务输出的内容进行审查,建立和改进风险过滤机制、违法内容特征库等。
您接入我们服务向公众提供内容生成式人工智能产品或服务的,您理解火山引擎提供自动化过滤审核能力,为了保障审核能力的稳定性,您授权火山引擎基于过滤审核内容建立和改进风险过滤机制、违法内容特征库。
强调了用户在使用服务时必须遵守的法律法规,包括但不限于数据保护和网络安全相关的法律,同时明确了用户的责任,要求用户不仅要合法使用服务,还要对生成内容的安全性、合法性、合规性负责,此外火山引擎保留了审查用户行为及信息的权利,并建立了风险过滤机制,豆包模型对安全性和合规性非常关注。
数据隐私保护
关于数据隐私保护,下面是协议原文:
- 服务将不使用您提交给服务或使用服务输出的内容训练、重新训练或改进基础模型。除外情况,您主动:
(1)同意火山引擎的《数据授权使用协议》;或
(2)参与火山引擎协作奖励计划,包括奖励资源包或不定期为您提供的其他奖励或优惠活动等。
除非额外签署数据授权协议或者参与平台活动,已明确其他情况下使用 API 接入传入的数据不会用于模型训练,赞~
SLA
关于模型服务运行的稳定性和故障率保障,下面是协议原文:
火山引擎的产品和服务是按照现有技术和条件所能达到的现状提供的。火山引擎将尽最大努力确保产品和服务的可用性,除本合同或双方书面确认的其他规定外,火山引擎不作任何其他明示或暗示的陈述或保证。例如,火山引擎未声明或保产品和服务 100%完整、准确、可靠、更新及时,也不保证产品/服不间断、系统稳定没有任何故障、内容完全安全或不侵权,您应根据其实际情况独立判断。
协议中对性能稳定性和故障率的说明相对保守,火山引擎没有对服务的稳定性和可靠性做出绝对的保证,承诺将尽最大努力确保服务的可用性,同时,协议也提醒用户需要根据实际情况独立判断服务的适用性,并自行承担因服务使用产生的知识产权纠纷,由于大模型技术固有的不确定性和复杂性,无法完全控制所有可能影响服务的因素(比如保证内容完全安全或不侵权)。
本文涉及的所有测试结果数据,均在可以后台回复「豆包」一次性获取。