摘要
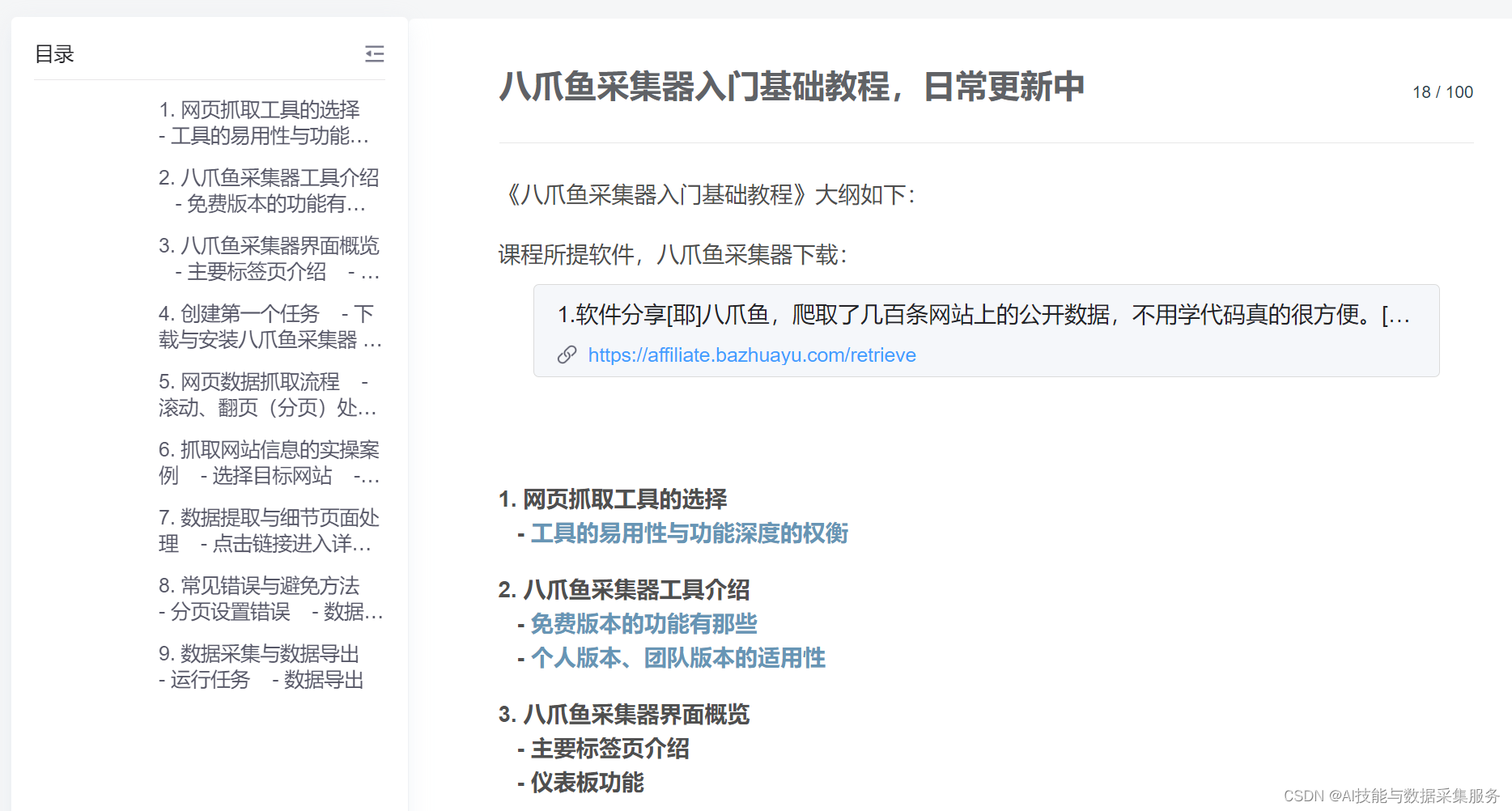
该论文提出了一种名为NoiseBoost的方法,通过噪声扰动来缓解多模态大语言模型(MLLM)中的幻觉问题。论文分析指出,幻觉主要源于大语言模型固有的总结机制,导致对语言符号的过度依赖,而忽视了视觉信息。NoiseBoost通过在视觉特征中加入噪声扰动,作为一种正则化手段,促进视觉和语言符号之间的注意力权重平衡。实验结果显示,NoiseBoost不仅在监督微调和强化学习中提升了模型性能,还首次实现了MLLM的半监督学习,充分利用了未标记数据。
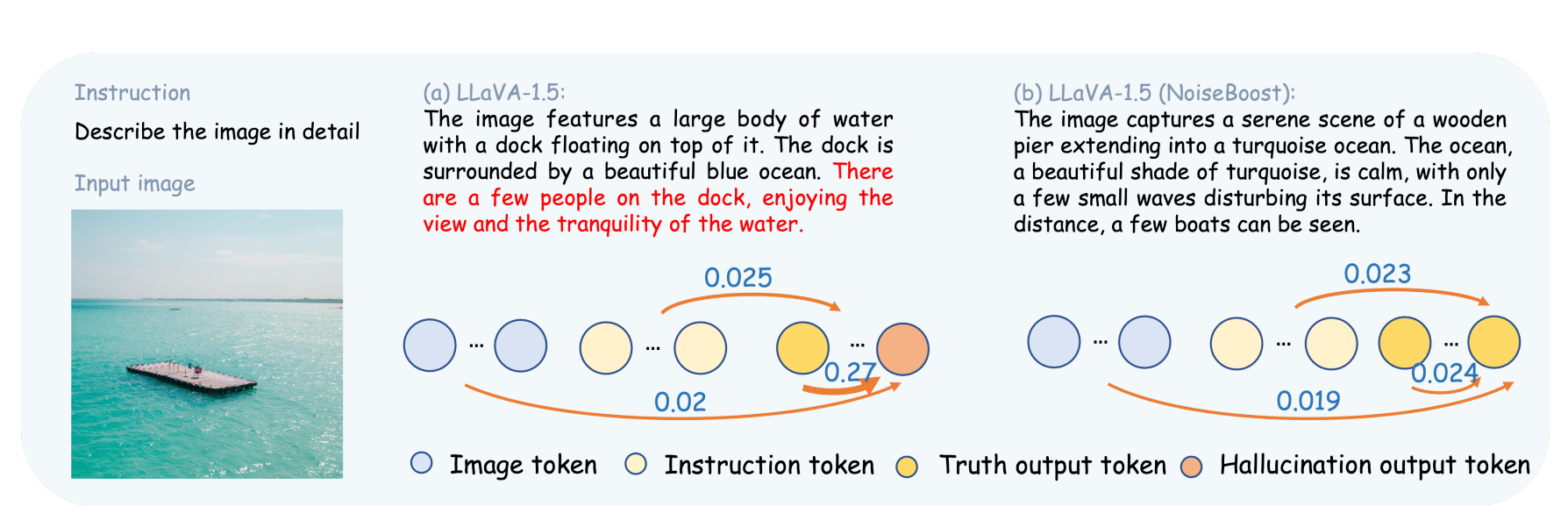
图1:多模态大模型(MLLMs)由于过度依赖语言先验而遭受幻觉问题。在(a)中,幻觉词元过度依赖(0.27)之前的语言词元,后续的词元都是幻觉。同时,在(b)中,NoiseBoost通过噪声扰动帮助MLLMs将注意力权重均匀分配在视觉和语言词元之间,从而产生真实的结果。
主要方法
- 问题分析:
- 幻觉现象:MLLM在生成长描述时容易出现幻觉,因为模型过于依赖语言符号而忽略视觉信息。
- 原因分析:语言模型在生成过程中会自动选择某些语言符号作为锚点,导致后续生成更加依赖这些锚点信息,而非上下文中的全部视觉和语言符号。
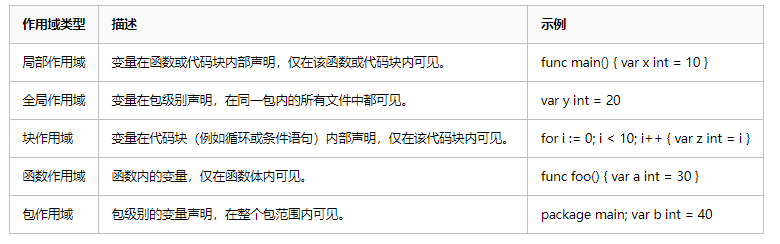
- NoiseBoost方法:
- 噪声扰动:在视觉符号中注入高斯噪声,增加学习过程的难度,迫使模型在理解视觉信息时分配更多的注意力权重。
- 监督微调(SFT):在视觉特征中直接注入噪声扰动,通过交叉熵损失进行训练。
- 强化学习(RL):结合噪声扰动和SFT,使用偏好模型(Preferred output)和非偏好模型(Less preferred output)来优化模型的生成。
- 半监督学习(SSL):利用NoiseBoost生成伪标签,采用教师-学生网络架构,教师模型生成伪标签,学生模型在有噪声的视觉特征上进行一致性正则化学习。
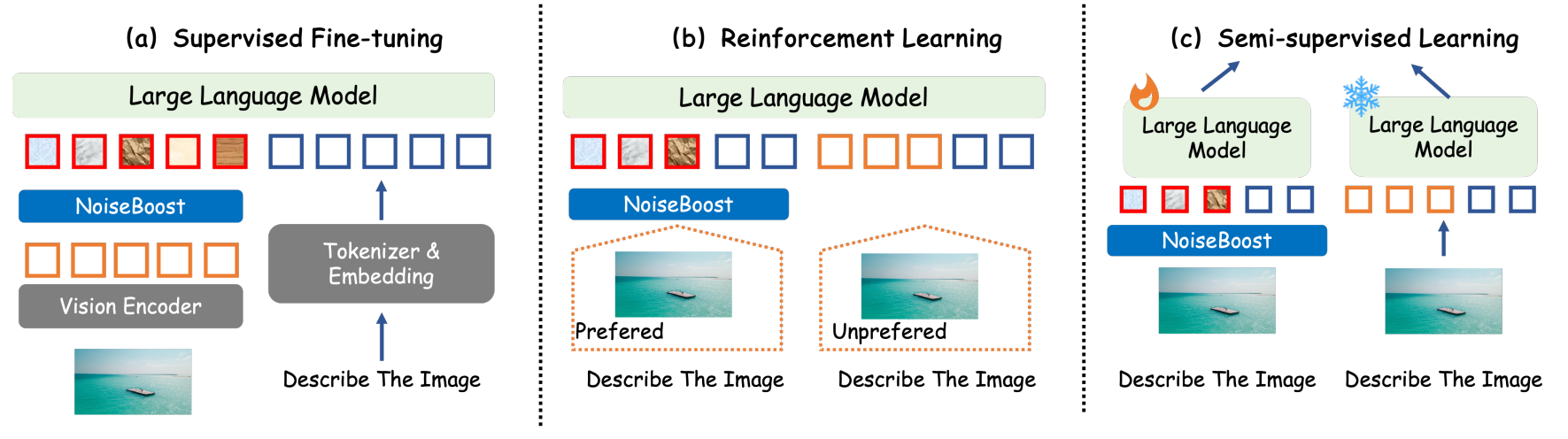
图2:NoiseBoost框架。我们通过向视觉词元添加噪声扰动来减轻对语言词元的过度依赖,从而减少幻觉。在微调(SFT)过程中,我们直接将噪声注入到视觉特征中。我们仅对优选响应注入扰动,因为这样可以使多模态大模型(MLLMs)更难以学习,从而达到更好的效果。对于半监督学习,我们使用冻结的MLLM作为教师生成伪标签,并使用NoiseBoost作为学生进行一致性正则化。
实验结果
- 实验设置:
- 基线模型:选择了LLaVA-1.5和QwenVL作为基线模型。
- 数据集:使用COCO captions和ShareGPT4v扩充数据集。
- 训练细节:采用V100 GPU进行训练,使用float16和deepspeed优化训练。
- 性能提升:
- 监督微调:在多项数据集上表现出色,尤其是在MME数据集上提升显著(如LLaVA-1.5在MME上的分数提高了40点)。
- 强化学习:NoiseBoost在各种问答数据集和幻觉数据集上均有约1%的性能提升。
- 半监督学习:在使用50%标记数据的情况下,NoiseBoost可以达到与使用全部标记数据相似的性能。
- 定性评估:
- 人类评估:在1000张图片上进行密集描述评估,NoiseBoost的准确率提高了8.1%,主要改善了对象错误和幻觉错误。
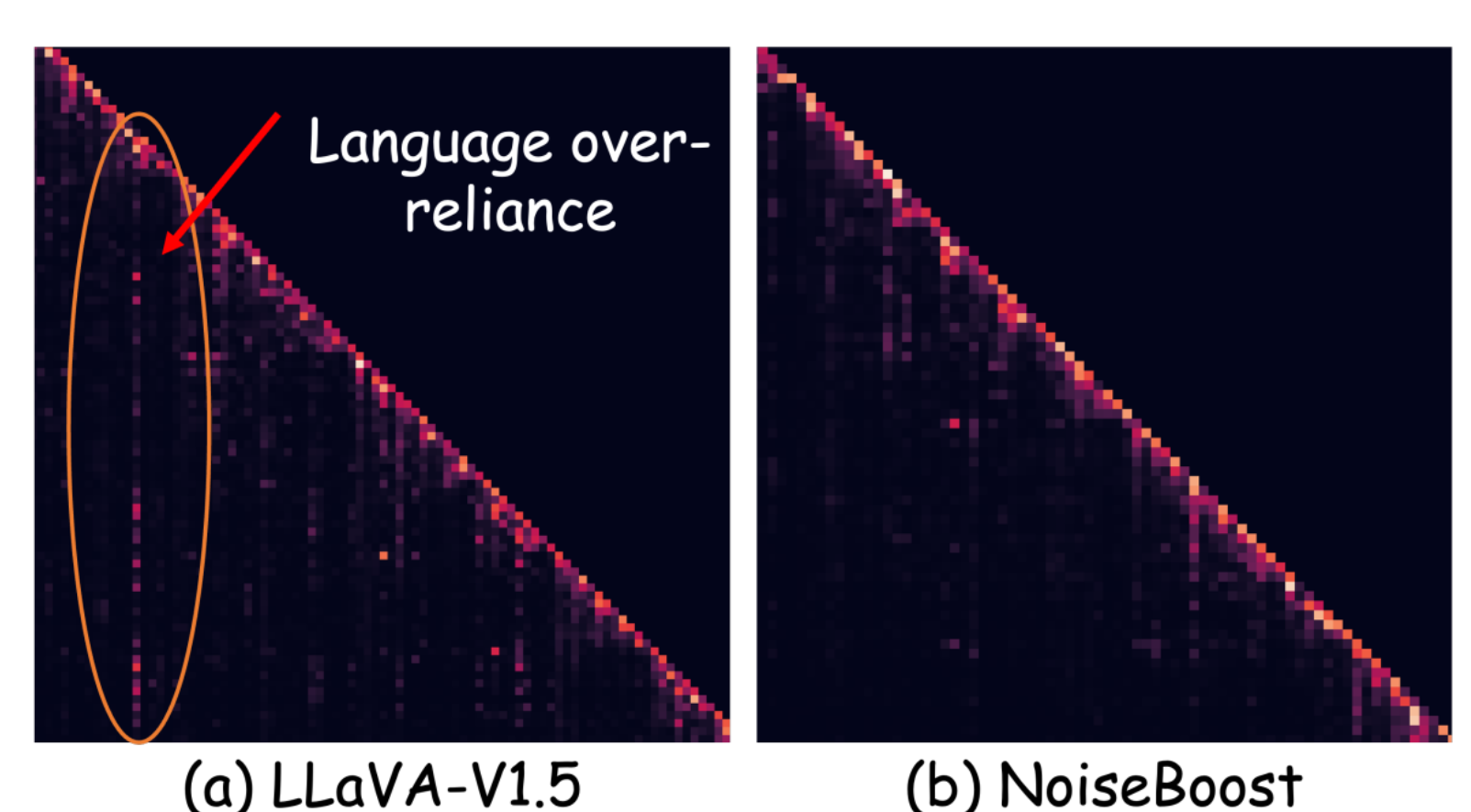
图4:对幻觉原因的分析是过度依赖红色圈出的语言词元,而NoiseBoost没有这种依赖。
创新贡献
- 提出了NoiseBoost,通过简单且通用的噪声扰动方法,有效缓解MLLM中的幻觉现象。
- 首次将半监督学习引入MLLM,通过噪声扰动充分利用未标记数据。
- 实验验证了NoiseBoost在不同训练方法中的一致性能提升。
方法的优缺点
- 优点:
- 方法简单,易于集成到现有的MLLM训练过程中。
- 不需要额外的数据集或显著增加训练成本。
- 在多种训练方法中均表现出色,具有良好的通用性。
- 缺点:
- 噪声扰动的规模和概率需要仔细调优,否则可能影响模型学习过程。
- 虽然方法有效,但依赖现有的大语言模型架构,没有从根本上解决多模态信息融合的问题。
结论
NoiseBoost是一种简单但有效的方法,通过引入噪声扰动,显著缓解了MLLM的幻觉问题,并提升了模型的视觉理解能力和生成准确性。这项工作为未来多模态大语言模型的研究和应用提供了重要的借鉴和思路。
论文下载地址
链接:https://pan.quark.cn/s/c73f2cb7010a













![[Linux] 历史根源](https://img-blog.csdnimg.cn/direct/040a034bd0214b4f9ae4a38ab5dd06df.png)
