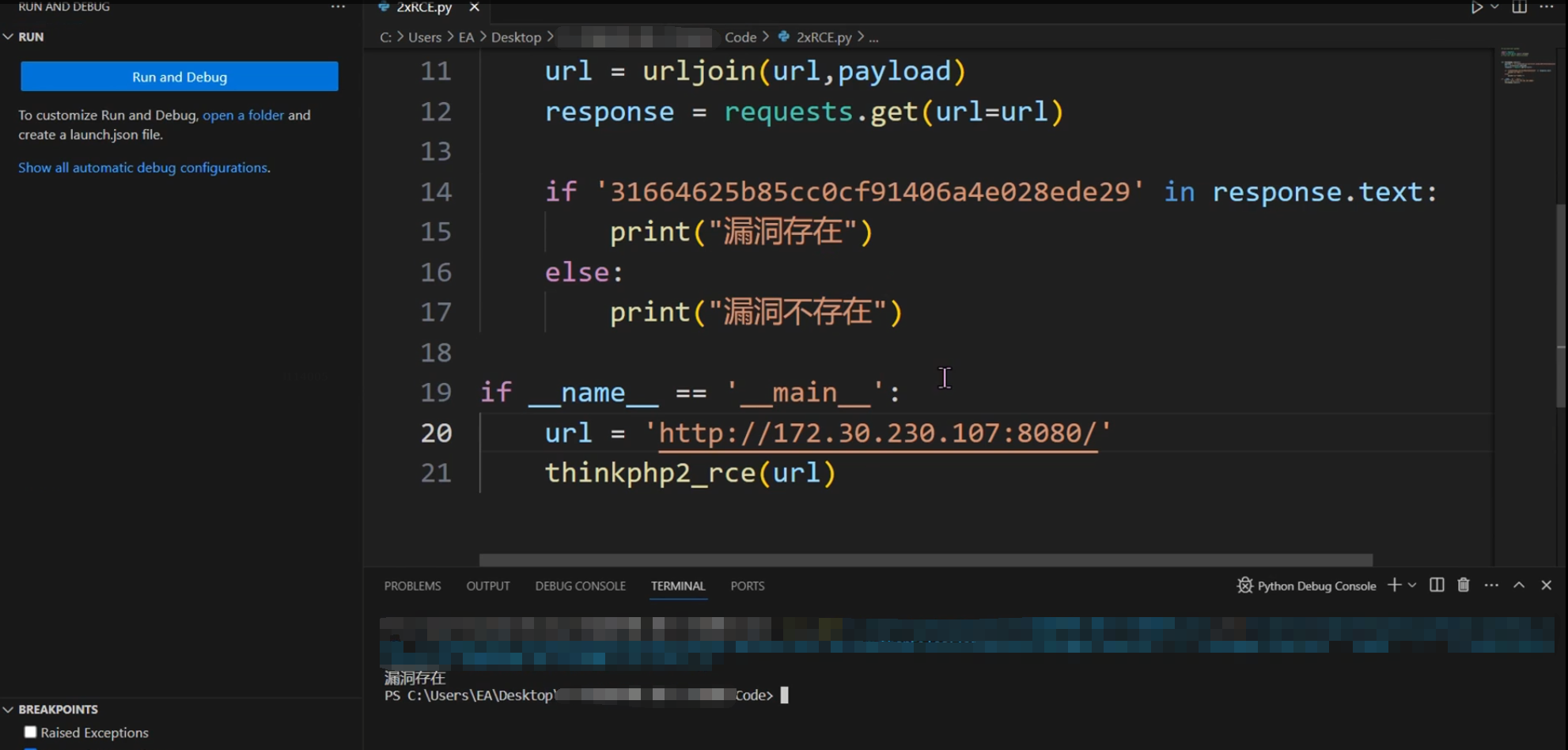
车辆轨迹预测系列 (三):nuScenes数据集详细介绍-1
文章目录
- 车辆轨迹预测系列 (三):nuScenes数据集详细介绍-1
- 一、数据集准备
- 1、解压
- 2、安装nuscenes-devkit
- 3、介绍
- 二、架构内容解释
- 1、category 类别
- 2、attribute 属性
- 3、visibility 可见性
- 4、instance 实例
- 5、sensor 传感器
- 6、calibrated_sensor 校准传感器
- 7、ego_pose 自车位姿
- 8、log 日志
- 9、scene 场景
- 10、 sample 样本
- 11、sample_data 样本数据
- 12、sample_annotation 样本注释
- 三、具体流程
- 1、逻辑关系
- 2、比较探讨
一、数据集准备
-
tutorials/nuscenes_tutorial官方教程文档
-
nuScenes架构页面_官方文档
-
由于官方的文档缺少运行结果,若想查看结果,可访问https://github.com/daetz-coder/TrajectoryPrediction
-
参考:深入nuScenes数据集(1/6)
官方教程:
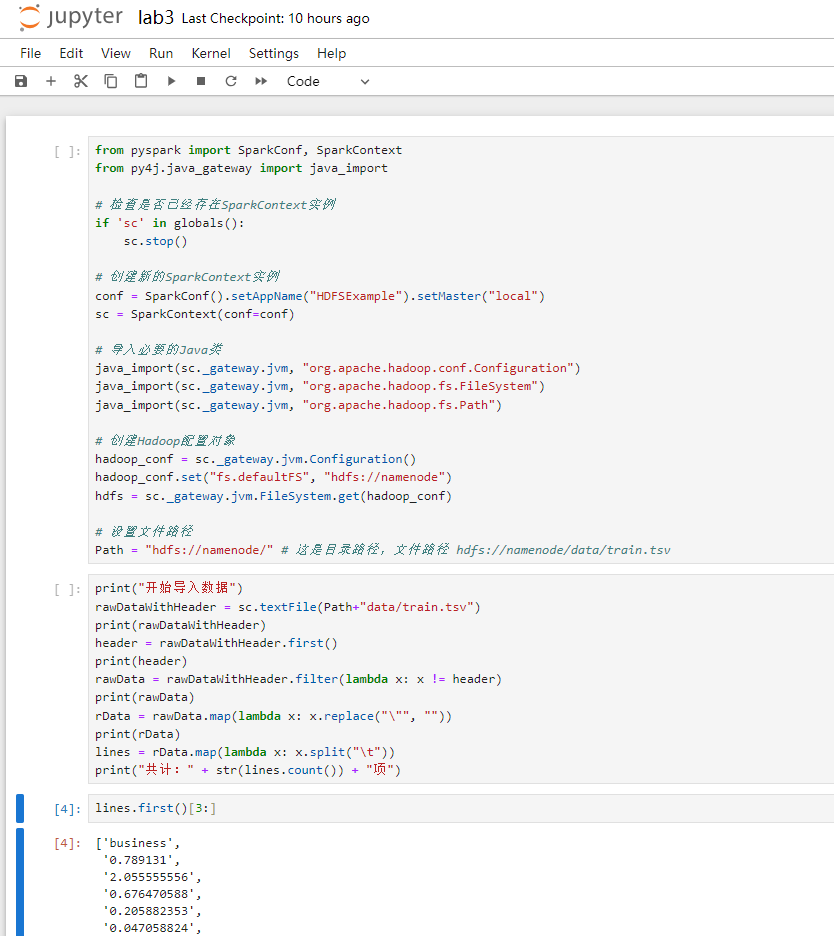
# !mkdir -p /data/sets/nuscenes # Make the directory to store the nuScenes dataset in.# !wget https://www.nuscenes.org/data/v1.0-mini.tgz # Download the nuScenes mini split.# !tar -xf v1.0-mini.tgz -C /data/sets/nuscenes # Uncompress the nuScenes mini split.# !pip install nuscenes-devkit &> /dev/null # Install nuScenes.
笔者使用的是AutoDL平台,由于 autodl-pub中携带了相关数据.因此无需额外下载,直接使用即可
# 在autodl-pub/nuScenes/Fulldatasetv1.0/Mini/v1.0-mini.tgz
1、解压
import tarfile
import os# Define the paths
current_directory = os.getcwd() # Get the current working directory
tar_file_path = os.path.join(current_directory, 'v1.0-mini.tgz') # Ensure the tar file path is absolute
extract_path = os.path.join(current_directory, 'data/sets/nuscenes') # Ensure the extract path is absolute# Function to extract tar file
def extract_tar_file(tar_path, extract_to):try:with tarfile.open(tar_path, 'r:gz') as tar:tar.extractall(path=extract_to)print(f"Extracted '{tar_path}' to '{extract_to}' successfully.")except FileNotFoundError:print(f"The file '{tar_path}' was not found.")except PermissionError:print(f"Permission denied: Cannot extract '{tar_path}' to '{extract_to}'.")except Exception as e:print(f"An error occurred: {e}")# Extract the tar file
extract_tar_file(tar_file_path, extract_path)# Verify extraction by listing the top-level contents of the target directory
if os.path.exists(extract_path):print("Extraction completed. Listing top-level contents:")top_level_contents = os.listdir(extract_path)for item in top_level_contents:print(item)
else:print("Failed to extract the tar file.")Extracted '/root/autodl-tmp/TrajectoryPrediction/1_Nuscenes/v1.0-mini.tgz' to '/root/autodl-tmp/TrajectoryPrediction/1_Nuscenes/data/sets/nuscenes' successfully.
Extraction completed. Listing top-level contents:
maps
v1.0-mini
samples
sweeps
.v1.0-mini.txt
LICENSE
2、安装nuscenes-devkit
!pip install nuscenes-devkit
3、介绍
在本教程的这一部分中,让我们自上而下地介绍数据库。我们的数据集由以下基本构建块组成:
log- Log information from which the data was extracted.log-从中提取数据的日志信息。scene- 20 second snippet of a car’s journey.scene-汽车行驶的20秒片段。sample- An annotated snapshot of a scene at a particular timestamp.sample-在特定时间戳的场景的带注释的快照。sample_data- Data collected from a particular sensor.sample_data-从特定传感器收集的数据。ego_pose- Ego vehicle poses at a particular timestamp.ego_pose- Ego车辆在特定时间戳处姿势。sensor- A specific sensor type.sensor—特定的传感器类型。calibrated sensor- Definition of a particular sensor as calibrated on a particular vehicle.calibrated sensor-在特定车辆上校准的特定传感器的定义。instance- Enumeration of all object instance we observed.instance-枚举我们观察到的所有对象实例。category- Taxonomy of object categories (e.g. vehicle, human).category-对象类别的分类(例如车辆、人)。attribute- Property of an instance that can change while the category remains the same.attribute-可以在类别保持不变的情况下更改实例的属性。visibility- Fraction of pixels visible in all the images collected from 6 different cameras.visibility-从6个不同的相机收集的所有图像中可见的像素的百分比。sample_annotation- An annotated instance of an object within our interest.sample_annotation-我们感兴趣的对象的带注释的实例。map- Map data that is stored as binary semantic masks from a top-down view.map-映射自顶向下视图中存储为二进制语义掩码的数据。
%matplotlib inline
from nuscenes.nuscenes import NuScenesnusc = NuScenes(version='v1.0-mini', dataroot='/data/sets/nuscenes', verbose=True)
======
Loading NuScenes tables for version v1.0-mini...
23 category,
8 attribute,
4 visibility,
911 instance,
12 sensor,
120 calibrated_sensor,
31206 ego_pose,
8 log,
10 scene,
404 sample,
31206 sample_data,
18538 sample_annotation,
4 map,
Done loading in 0.479 seconds.
======
Reverse indexing ...
Done reverse indexing in 0.1 seconds.
======
下面对上述内容解释,以便于更好理解每个部分之间的相互关系,具体内容参考官方介绍:nuScenes架构页面_官方文档
23 category: 表示23种类别。每个类别代表一个物体的类型,例如行人、车辆、交通标志等。
8 attribute: 表示8种属性。这些属性用于描述物体的状态或特征,例如是否在运动,是否停放等。
4 visibility: 表示4种可见性状态。描述物体的可见程度,例如完全可见、部分遮挡等。
911 instance: 表示911个实例。每个实例代表一个具体的物体,可能在不同的时间点被多次检测到。
12 sensor: 表示12种传感器。包括摄像头、激光雷达(LiDAR)、雷达等不同类型的传感器。
120 calibrated_sensor: 表示120个校准后的传感器。校准传感器包含了每个传感器的具体校准信息,以确保数据的准确性。
31206 ego_pose: 表示31206个自车位姿。自车位姿记录了自车在不同时间点的位置信息和姿态信息。
8 log: 表示8个日志。每个日志包含了一个或多个场景的数据。
10 scene: 表示10个场景。每个场景代表一个完整的驾驶情境,从开始到结束包含多个时间点的传感器数据。
404 sample: 表示404个样本。每个样本对应一个时间点的所有传感器数据集合。
31206 sample_data: 表示31206个样本数据。每个样本数据是一个具体的传感器读取,例如一帧图像或一组激光雷达点云。
18538 sample_annotation: 表示18538个样本注释。每个注释描述了样本中检测到的物体及其属性。
4 map: 表示4个地图。地图数据包括了道路、车道线等地理信息。
二、架构内容解释
1、category 类别
对象类别的分类(例如车辆、人)。 子类别用一个句号来表示(例如 human.pedestrian.adult )。
category {"token": <str> -- Unique record identifier."name": <str> -- Category name. Subcategories indicated by period."description": <str> -- Category description."index": <int> -- The index of the label used for efficiency reasons in the .bin label files of nuScenes-lidarseg. This field did not exist previously.
}token: <字符串> -- 唯一记录标识符。用于唯一标识这个类别记录。
name: <字符串> -- 类别名称。子类别用点号分隔。例如,"vehicle.car" 表示车辆类别下的汽车子类别。
description: <字符串> -- 类别描述。提供关于这个类别的详细描述信息。
index: <整数> -- 在nuScenes-lidarseg的.bin标签文件中用于效率原因的标签索引。这个字段在以前版本中不存在。
human.pedestrian.adult: 成年行人
human.pedestrian.child: 儿童行人
human.pedestrian.construction_worker: 建筑工人
human.pedestrian.personal_mobility: 个人移动设备使用者
human.pedestrian.police_officer: 警察
movable_object.barrier: 可移动障碍物
movable_object.debris: 碎片
movable_object.pushable_pullable: 可推拉的物体
movable_object.trafficcone: 交通锥
static_object.bicycle_rack: 自行车架
vehicle.bicycle: 自行车
vehicle.bus.bendy: 铰接式公交车
vehicle.bus.rigid: 刚性公交车
vehicle.car: 汽车
vehicle.construction: 建筑车辆
vehicle.motorcycle: 摩托车
vehicle.trailer:拖车
vehicle.truck:卡车
#展示类型
nusc.list_categories()
Category stats for split v1.0-mini:
human.pedestrian.adult n= 4765, width= 0.68±0.11, len= 0.73±0.17, height= 1.76±0.12, lw_aspect= 1.08±0.23
human.pedestrian.child n= 46, width= 0.46±0.08, len= 0.45±0.09, height= 1.37±0.06, lw_aspect= 0.97±0.05
human.pedestrian.constructi n= 193, width= 0.69±0.07, len= 0.74±0.12, height= 1.78±0.05, lw_aspect= 1.07±0.16
human.pedestrian.personal_m n= 25, width= 0.83±0.00, len= 1.28±0.00, height= 1.87±0.00, lw_aspect= 1.55±0.00
human.pedestrian.police_off n= 11, width= 0.59±0.00, len= 0.47±0.00, height= 1.81±0.00, lw_aspect= 0.80±0.00
movable_object.barrier n= 2323, width= 2.32±0.49, len= 0.61±0.11, height= 1.06±0.10, lw_aspect= 0.28±0.09
movable_object.debris n= 13, width= 0.43±0.00, len= 1.43±0.00, height= 0.46±0.00, lw_aspect= 3.35±0.00
movable_object.pushable_pul n= 82, width= 0.51±0.06, len= 0.79±0.10, height= 1.04±0.20, lw_aspect= 1.55±0.18
movable_object.trafficcone n= 1378, width= 0.47±0.14, len= 0.45±0.07, height= 0.78±0.13, lw_aspect= 0.99±0.12
static_object.bicycle_rack n= 54, width= 2.67±1.46, len=10.09±6.19, height= 1.40±0.00, lw_aspect= 5.97±4.02
vehicle.bicycle n= 243, width= 0.64±0.12, len= 1.82±0.14, height= 1.39±0.34, lw_aspect= 2.94±0.41
vehicle.bus.bendy n= 57, width= 2.83±0.09, len= 9.23±0.33, height= 3.32±0.07, lw_aspect= 3.27±0.22
vehicle.bus.rigid n= 353, width= 2.95±0.26, len=11.46±1.79, height= 3.80±0.62, lw_aspect= 3.88±0.57
vehicle.car n= 7619, width= 1.92±0.16, len= 4.62±0.36, height= 1.69±0.21, lw_aspect= 2.41±0.18
vehicle.construction n= 196, width= 2.58±0.35, len= 5.57±1.57, height= 2.38±0.33, lw_aspect= 2.18±0.62
vehicle.motorcycle n= 471, width= 0.68±0.21, len= 1.95±0.38, height= 1.47±0.20, lw_aspect= 3.00±0.62
vehicle.trailer n= 60, width= 2.28±0.08, len=10.14±5.69, height= 3.71±0.27, lw_aspect= 4.37±2.41
vehicle.truck n= 649, width= 2.35±0.34, len= 6.50±1.56, height= 2.62±0.68, lw_aspect= 2.75±0.37
2、attribute 属性
attribute 是一个实例的属性,它可以在场景的不同部分发生变化,而类别保持不变。这里我们列出了所提供的属性以及与特定属性相关联的注释的数量。
属性是实例的属性,它可以在类别保持不变的情况下发生变化。 例如:一辆正在停放/停止/移动的车辆,以及一辆自行车是否有人骑。
category {"token": <str> -- Unique record identifier."name": <str> -- Category name. Subcategories indicated by period."description": <str> -- Category description."index": <int> -- The index of the label used for efficiency reasons in the .bin label files of nuScenes-lidarseg. This field did not exist previously.
}
nusc.list_attributes()
cycle.with_rider: 305
cycle.without_rider: 434
pedestrian.moving: 3875
pedestrian.sitting_lying_down: 111
pedestrian.standing: 1029
vehicle.moving: 2715
vehicle.parked: 4674
vehicle.stopped: 1545
cycle.with_rider: 有骑行者的自行车:305
cycle.without_rider: 无骑行者的自行车:434
pedestrian.moving: 移动中的行人:3875
pedestrian.sitting_lying_down: 坐着或躺着的行人:111
pedestrian.standing: 站立的行人:1029
vehicle.moving: 移动中的车辆:2715
vehicle.parked: 停放的车辆:4674
vehicle.stopped: 停止的车辆:1545
在nuScenes数据集中,vehicle.parked 和 vehicle.stopped 两者的区别如下:
vehicle.parked(停放的车辆):
- 这类车辆是指完全停放在一个固定的位置,并且通常处于停车状态。这意味着车辆可能是在停车场、路边停车位等地方停放的,驾驶员可能已经离开车辆,车辆也可能已经熄火。
vehicle.stopped(停止的车辆):
- 这类车辆是指虽然当前处于静止状态,但并不是停放的车辆。这可能包括在交通信号灯前等待、因为交通堵塞而暂时停止、或在其他情况下暂时停止的车辆。这些车辆一般仍在道路上,并且驾驶员仍在车内,准备继续行驶。
3、visibility 可见性
visibility 被定义为在6个摄像头输入中可见的特定注释的像素比例,分为4个组别。
实例的可见性是在所有6个图像中可见的注释的分数。分为0-40%,40-60%,60-80%和80-100% 4个组别。
visibility {"token": <str> -- Unique record identifier."level": <str> -- Visibility level."description": <str> -- Description of visibility level.
}
token: <字符串> -- 唯一记录标识符。用于唯一标识这个可见性等级记录。
level: <字符串> -- 可见性等级。描述物体的可见程度。
description: <字符串> -- 可见性等级的描述。提供关于这个等级的详细说明。
nusc.visibility
[{'description': 'visibility of whole object is between 0 and 40%','token': '1','level': 'v0-40'},{'description': 'visibility of whole object is between 40 and 60%','token': '2','level': 'v40-60'},{'description': 'visibility of whole object is between 60 and 80%','token': '3','level': 'v60-80'},{'description': 'visibility of whole object is between 80 and 100%','token': '4','level': 'v80-100'}]
用于描述物体整体的可见性
anntoken = 'a7d0722bce164f88adf03ada491ea0ba'
visibility_token = nusc.get('sample_annotation', anntoken)['visibility_token']print("Visibility: {}".format(nusc.get('visibility', visibility_token)))
nusc.render_annotation(anntoken)

4、instance 实例
一个对象实例,例如,特定的车辆。 该表是我们观察到的所有对象实例的枚举。 注意,实例不会跨场景跟踪。
instance {"token": <str> -- Unique record identifier."category_token": <str> -- Foreign key pointing to the object category."nbr_annotations": <int> -- Number of annotations of this instance."first_annotation_token": <str> -- Foreign key. Points to the first annotation of this instance."last_annotation_token": <str> -- Foreign key. Points to the last annotation of this instance.
}token: <字符串> -- 唯一记录标识符。用于唯一标识这个实例记录。
category_token: <字符串> -- 外键,指向对象类别。表示这个实例属于哪个类别。
nbr_annotations: <整数> -- 这个实例的注释数量。表示这个实例在数据集中被标注的次数。
first_annotation_token: <字符串> -- 外键,指向这个实例的第一个注释。用于获取这个实例的第一个标注记录。
last_annotation_token: <字符串> -- 外键,指向这个实例的最后一个注释。用于获取这个实例的最后一个标注记录。
my_instance = nusc.instance[599]
my_instance
{'token': '9cba9cd8af85487fb010652c90d845b5','category_token': 'fedb11688db84088883945752e480c2c','nbr_annotations': 16,'first_annotation_token': '77afa772cb4a4e5c8a5a53f2019bdba0','last_annotation_token': '6fed6d902e5e487abb7444f62e1a2341'}
我们通常在一个特定场景的不同帧中跟踪一个实例。但是,我们不会在不同的场景中跟踪它们。在这个例子中,我们在一个特定的场景中有16个带注释的样本。
instance_token = my_instance['token']
nusc.render_instance(instance_token)

实例记录记录它的第一个和最后一个注释标记。我们来渲染一下
print("First annotated sample of this instance:")
nusc.render_annotation(my_instance['first_annotation_token'])

print("Last annotated sample of this instance")
nusc.render_annotation(my_instance['last_annotation_token'])

需要注意的是虽然仅仅给定了first_annotation_token和
last_annotation_token但是,在sample_annotation可以通过next和prev来找到全部的内容
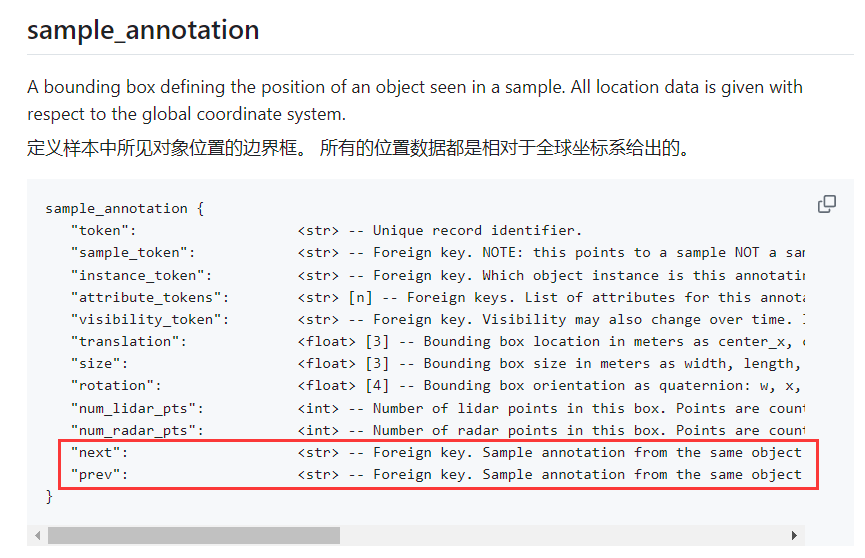
# 获取实例的第一个注释
current_annotation_token = my_instance['first_annotation_token']
last_annotation_token = my_instance['last_annotation_token']# 初始化一个列表来存储所有注释的详细信息
annotations = []# 遍历所有注释,直到最后一个注释
while current_annotation_token:# 获取当前注释记录annotation = nusc.get('sample_annotation', current_annotation_token)annotations.append(annotation)# 打印当前注释的详细信息print(f"Annotation token: {annotation['token']}")print(f"Sample token: {annotation['sample_token']}")print(f"Instance token: {annotation['instance_token']}")print(f"Attribute tokens: {annotation['attribute_tokens']}")print(f"Visibility token: {annotation['visibility_token']}")print(f"Translation: {annotation['translation']}")print(f"Size: {annotation['size']}")print(f"Rotation: {annotation['rotation']}")print(f"Num lidar points: {annotation['num_lidar_pts']}")print(f"Num radar points: {annotation['num_radar_pts']}")print(f"Next token: {annotation['next']}")print(f"Prev token: {annotation['prev']}")print("\n" + "="*50 + "\n")# 获取下一个注释的标识符current_annotation_token = annotation['next']# 如果当前注释是最后一个注释,则终止循环if current_annotation_token == last_annotation_token:break# 打印最后一个注释的详细信息
last_annotation = nusc.get('sample_annotation', last_annotation_token)
annotations.append(last_annotation)print(f"Annotation token: {last_annotation['token']}")
print(f"Sample token: {last_annotation['sample_token']}")
print(f"Instance token: {last_annotation['instance_token']}")
print(f"Attribute tokens: {last_annotation['attribute_tokens']}")
print(f"Visibility token: {last_annotation['visibility_token']}")
print(f"Translation: {last_annotation['translation']}")
print(f"Size: {last_annotation['size']}")
print(f"Rotation: {last_annotation['rotation']}")
print(f"Num lidar points: {last_annotation['num_lidar_pts']}")
print(f"Num radar points: {last_annotation['num_radar_pts']}")
print(f"Next token: {last_annotation['next']}")
print(f"Prev token: {last_annotation['prev']}")
print("\n" + "="*50 + "\n")5、sensor 传感器
数据集包括从我们的完整传感器套件收集的数据,其中包括:
- 1 x LIDAR, 1个激光雷达;
- 5 x RADAR, 5 x雷达;
- 6 x cameras, 6个摄像头;
sensor {"token": <str> -- Unique record identifier."channel": <str> -- Sensor channel name."modality": <str> {camera, lidar, radar} -- Sensor modality. Supports category(ies) in brackets.
}
token: 唯一记录标识符
channel: 传感器通道名称 不同方向上
modality: 传感器模式(例如,camera、lidar、radar)
nusc.sensor
[{'token': '725903f5b62f56118f4094b46a4470d8','channel': 'CAM_FRONT','modality': 'camera'},{'token': 'ce89d4f3050b5892b33b3d328c5e82a3','channel': 'CAM_BACK','modality': 'camera'},{'token': 'a89643a5de885c6486df2232dc954da2','channel': 'CAM_BACK_LEFT','modality': 'camera'},{'token': 'ec4b5d41840a509984f7ec36419d4c09','channel': 'CAM_FRONT_LEFT','modality': 'camera'},{'token': '2f7ad058f1ac5557bf321c7543758f43','channel': 'CAM_FRONT_RIGHT','modality': 'camera'},{'token': 'ca7dba2ec9f95951bbe67246f7f2c3f7','channel': 'CAM_BACK_RIGHT','modality': 'camera'},{'token': 'dc8b396651c05aedbb9cdaae573bb567','channel': 'LIDAR_TOP','modality': 'lidar'},{'token': '47fcd48f71d75e0da5c8c1704a9bfe0a','channel': 'RADAR_FRONT','modality': 'radar'},{'token': '232a6c4dc628532e81de1c57120876e9','channel': 'RADAR_FRONT_RIGHT','modality': 'radar'},{'token': '1f69f87a4e175e5ba1d03e2e6d9bcd27','channel': 'RADAR_FRONT_LEFT','modality': 'radar'},{'token': 'df2d5b8be7be55cca33c8c92384f2266','channel': 'RADAR_BACK_LEFT','modality': 'radar'},{'token': '5c29dee2f70b528a817110173c2e71b9','channel': 'RADAR_BACK_RIGHT','modality': 'radar'}]
每个 sample_data 都有一个记录, sensor 数据是从该记录收集的(注意“channel”键)
nusc.sample_data[10]
{'token': '2ecfec536d984fb491098c9db1404117','sample_token': '356d81f38dd9473ba590f39e266f54e5','ego_pose_token': '2ecfec536d984fb491098c9db1404117','calibrated_sensor_token': 'f4d2a6c281f34a7eb8bb033d82321f79','timestamp': 1532402928269133,'fileformat': 'pcd','is_key_frame': False,'height': 0,'width': 0,'filename': 'sweeps/RADAR_FRONT/n015-2018-07-24-11-22-45+0800__RADAR_FRONT__1532402928269133.pcd','prev': 'b933bbcb4ee84a7eae16e567301e1df2','next': '79ef24d1eba84f5abaeaf76655ef1036','sensor_modality': 'radar','channel': 'RADAR_FRONT'}
每个sensor在一个特定时间点上的数据记录称为sample_data,每条sample_data记录如下:
token: 唯一记录标识符sample_token: 外键,指向所属的样本ego_pose_token: 外键,指向自车位姿calibrated_sensor_token: 外键,指向校准后的传感器timestamp: 时间戳fileformat: 文件格式(如图像、点云等)is_key_frame: 是否为关键帧height: 图像高度(对于非图像数据为0)width: 图像宽度(对于非图像数据为0)filename: 文件名和路径prev: 前一条sample_data记录的标识符next: 后一条sample_data记录的标识符sensor_modality: 传感器模式(例如,camera、lidar、radar)channel: 传感器通道名称
虽然sensor记录本身不直接用于检测任务,但它们提供了上下文信息,使得数据处理和分析更加准确。例如,知道某个数据是来自前置摄像头还是后置摄像头,有助于理解该数据的视角和相关性。此外,不同传感器的数据融合(例如,摄像头和激光雷达数据)可以提高检测任务的准确性。
6、calibrated_sensor 校准传感器
calibrated_sensor 包含在特定车辆上校准的特定传感器(激光雷达/雷达/相机)的定义。让我们来看一个例子。
nusc.calibrated_sensor[0]
{'token': 'f4d2a6c281f34a7eb8bb033d82321f79','sensor_token': '47fcd48f71d75e0da5c8c1704a9bfe0a','translation': [3.412, 0.0, 0.5],'rotation': [0.9999984769132877, 0.0, 0.0, 0.0017453283658983088],'camera_intrinsic': []}
Note that the translation and the rotation parameters are given with respect to the ego vehicle body frame.
注意, translation 和 rotation 参数是针对ego车身框架给出的
在特定车辆上校准的特定传感器(激光雷达/雷达/摄像头)的定义。 给出了车身框架的所有外在参数。 所有的相机图像都是不失真和校正的。
calibrated_sensor {"token": <str> -- Unique record identifier."sensor_token": <str> -- Foreign key pointing to the sensor type."translation": <float> [3] -- Coordinate system origin in meters: x, y, z."rotation": <float> [4] -- Coordinate system orientation as quaternion: w, x, y, z."camera_intrinsic": <float> [3, 3] -- Intrinsic camera calibration. Empty for sensors that are not cameras.
}token: <字符串> -- 唯一记录标识符,用于唯一标识这个校准后的传感器记录。
sensor_token: <字符串> -- 外键,指向传感器类型。这个字段与sensor表中的token字段对应,表示该校准记录属于哪个传感器。
translation: <浮点数>[3] -- 坐标系原点在米为单位的坐标:x, y, z。表示传感器在自车坐标系中的位置。
rotation: <浮点数>[4] -- 坐标系的方向,以四元数表示:w, x, y, z。表示传感器在自车坐标系中的旋转方向。
camera_intrinsic: <浮点数>[3, 3] -- 相机内参校准参数。只有对于相机传感器,这个字段才会有值,其他类型的传感器此字段为空。
7、ego_pose 自车位姿
自我车辆在特定时间戳的姿势。给定相对于全局坐标系统的日志地图。 ego_pose是本文中描述的基于激光雷达地图的定位算法的输出。 定位在x-y平面上是二维的。
ego_pose {"token": <str> -- Unique record identifier."translation": <float> [3] -- Coordinate system origin in meters: x, y, z. Note that z is always 0."rotation": <float> [4] -- Coordinate system orientation as quaternion: w, x, y, z."timestamp": <int> -- Unix time stamp.
}
token: 唯一标识符。
translation: 自车的坐标位置,z 值始终为0,表示自车在地面上的位置。
rotation: 自车的旋转方向,以四元数形式表示。
timestamp: Unix时间戳,表示记录的时间。
ego_pose 包含了ego车辆相对于全局坐标系的位置信息(编码为 translation )和方向信息(编码为 rotation )。
注意,在加载的数据库中 ego_pose 记录的数量与 sample_data 记录的数量相同。这两份记录显示出一一对应。
nusc.ego_pose[0]
{'token': '5ace90b379af485b9dcb1584b01e7212','timestamp': 1532402927814384,'rotation': [0.5731787718287827,-0.0015811634307974854,0.013859363182046986,-0.8193116095230444],'translation': [410.77878632230204, 1179.4673290964536, 0.0]}
8、log 日志
log 表包含从中提取数据的日志信息。 log 记录对应于我们的自我车辆沿着预定义路线的一次旅行。让我们检查日志的数量和日志的元数据。
log {"token": <str> -- Unique record identifier."logfile": <str> -- Log file name."vehicle": <str> -- Vehicle name."date_captured": <str> -- Date (YYYY-MM-DD)."location": <str> -- Area where log was captured, e.g. singapore-onenorth.
}token: <字符串> -- 唯一记录标识符 用于唯一标识这条日志记录。在数据库中,每条日志记录都有一个独特的标识符,确保其唯一性。
logfile: <字符串> -- 日志文件名称 记录日志数据的文件名。例如:"log_001.txt"。这是实际存储传感器数据或其他相关信息的文件。
vehicle: <字符串> -- 车辆名称 记录数据的车辆名称或标识。用于区分不同车辆的数据。例如:"vehicle_a"。
date_captured: <字符串> -- 数据捕获日期 数据捕获的日期,格式为YYYY-MM-DD。例如:"2023-06-22"。表示日志数据是在何时收集的。
location: <字符串> -- 捕获日志的区域 捕获日志的地理位置。例如:"singapore-onenorth"。这个字段有助于了解数据的地理背景信息。
print("Number of `logs` in our loaded database: {}".format(len(nusc.log)))
Number of `logs` in our loaded database: 8
nusc.log[0]
{'token': '7e25a2c8ea1f41c5b0da1e69ecfa71a2','logfile': 'n015-2018-07-24-11-22-45+0800','vehicle': 'n015','date_captured': '2018-07-24','location': 'singapore-onenorth','map_token': '53992ee3023e5494b90c316c183be829'}
注意,它包含各种信息,如收集日志的日期和位置。它还提供了从哪里收集数据的地图信息。注意,一个日志可以包含多个不重叠的场景。
9、scene 场景
nuScenes是一个大型数据库,具有1000个场景的注释样本,每个场景约20秒。让我们看一下加载数据库中的场景。
场景是从日志中提取的20秒长的连续帧序列。 多个场景可以来自同一日志。 注意,对象标识(实例令牌)不会跨场景保留。
scene {"token": <str> -- Unique record identifier."name": <str> -- Short string identifier."description": <str> -- Longer description of the scene."log_token": <str> -- Foreign key. Points to log from where the data was extracted."nbr_samples": <int> -- Number of samples in this scene."first_sample_token": <str> -- Foreign key. Points to the first sample in scene."last_sample_token": <str> -- Foreign key. Points to the last sample in scene.
}
token: <字符串> -- 唯一记录标识符。用于唯一标识该场景记录。
name: <字符串> -- 简短的字符串标识符。场景的简短名称,用于快速标识。
description: <字符串> -- 场景的详细描述。对该场景的更详细的描述信息。
log_token: <字符串> -- 外键。指向提取数据的日志。指向log表中的一个记录,表示该场景数据从哪个日志中提取。
nbr_samples: <整数> -- 场景中的样本数量。该场景包含的样本数量。
first_sample_token: <字符串> -- 外键。指向场景中的第一个样本。 指向该场景中的第一个sample记录。
last_sample_token: <字符串> -- 外键。指向场景中的最后一个样本。指向该场景中的最后一个sample记录。
nusc.list_scenes()
scene-0061, Parked truck, construction, intersectio... [18-07-24 03:28:47] 19s, singapore-onenorth, #anns:4622
scene-0103, Many peds right, wait for turning car, ... [18-08-01 19:26:43] 19s, boston-seaport, #anns:2046
scene-0655, Parking lot, parked cars, jaywalker, be... [18-08-27 15:51:32] 20s, boston-seaport, #anns:2332
scene-0553, Wait at intersection, bicycle, large tr... [18-08-28 20:48:16] 20s, boston-seaport, #anns:1950
scene-0757, Arrive at busy intersection, bus, wait ... [18-08-30 19:25:08] 20s, boston-seaport, #anns:592
scene-0796, Scooter, peds on sidewalk, bus, cars, t... [18-10-02 02:52:24] 20s, singapore-queensto, #anns:708
scene-0916, Parking lot, bicycle rack, parked bicyc... [18-10-08 07:37:13] 20s, singapore-queensto, #anns:2387
scene-1077, Night, big street, bus stop, high speed... [18-11-21 11:39:27] 20s, singapore-hollandv, #anns:890
scene-1094, Night, after rain, many peds, PMD, ped ... [18-11-21 11:47:27] 19s, singapore-hollandv, #anns:1762
scene-1100, Night, peds in sidewalk, peds cross cro... [18-11-21 11:49:47] 19s, singapore-hollandv, #anns:935
让我们看一下场景元数据
my_scene = nusc.scene[0]
my_scene
{'token': 'cc8c0bf57f984915a77078b10eb33198','log_token': '7e25a2c8ea1f41c5b0da1e69ecfa71a2','nbr_samples': 39,'first_sample_token': 'ca9a282c9e77460f8360f564131a8af5','last_sample_token': 'ed5fc18c31904f96a8f0dbb99ff069c0','name': 'scene-0061','description': 'Parked truck, construction, intersection, turn left, following a van'
}
其中的**token**: 场景的唯一标识符。例如:'cc8c0bf57f984915a77078b10eb33198'。这个标识符用于在数据库中唯一标识这个场景。
log_token: 关联的日志的唯一标识符。例如:'7e25a2c8ea1f41c5b0da1e69ecfa71a2'。日志包含了一系列相关的场景数据,例如时间戳和传感器数据。
nbr_samples: 场景中样本的数量。例如:39。表示场景中包含的传感器数据点数。一个样本(sample)通常对应于某一个时间点的所有传感器数据集合。这些传感器数据可能包括来自多个传感器的读数,如摄像头图像、激光雷达点云、雷达数据等。每个样本中可以包含对场景中多个对象(如行人、车辆、建筑物等)的检测和注释。
first_sample_token: 场景中第一个样本的唯一标识符。例如:'ca9a282c9e77460f8360f564131a8af5'。这可以用于获取场景的开始时间点的数据。
last_sample_token: 场景中最后一个样本的唯一标识符。例如:'ed5fc18c31904f96a8f0dbb99ff069c0'。这可以用于获取场景的结束时间点的数据。
name: 场景的名称。例如:'scene-0061'。这个名称通常用于简单标识和查找场景。
description: 场景的描述。例如:'Parked truck, construction, intersection, turn left, following a van'。描述提供了场景的简要信息,帮助理解场景的具体情况。
10、 sample 样本
In scenes, we annotate our data every half a second (2 Hz).
在场景中,我们每半秒(2hz)注释一次数据。
We define sample as an *annotated keyframe of a scene at a given timestamp*. A keyframe is a frame where the time-stamps of data from all the sensors should be very close to the time-stamp of the sample it points to.
我们将 sample 定义为给定时间戳的场景的带注释的关键帧。关键帧是所有传感器的数据的时间戳应该非常接近它所指向的样本的时间戳的帧。
my_sample = nusc.get('sample', first_sample_token)
my_sample
{'token': 'ca9a282c9e77460f8360f564131a8af5','timestamp': 1532402927647951,'prev': '','next': '39586f9d59004284a7114a68825e8eec','scene_token': 'cc8c0bf57f984915a77078b10eb33198','data': {'RADAR_FRONT': '37091c75b9704e0daa829ba56dfa0906','RADAR_FRONT_LEFT': '11946c1461d14016a322916157da3c7d','RADAR_FRONT_RIGHT': '491209956ee3435a9ec173dad3aaf58b','RADAR_BACK_LEFT': '312aa38d0e3e4f01b3124c523e6f9776','RADAR_BACK_RIGHT': '07b30d5eb6104e79be58eadf94382bc1','LIDAR_TOP': '9d9bf11fb0e144c8b446d54a8a00184f','CAM_FRONT': 'e3d495d4ac534d54b321f50006683844','CAM_FRONT_RIGHT': 'aac7867ebf4f446395d29fbd60b63b3b','CAM_BACK_RIGHT': '79dbb4460a6b40f49f9c150cb118247e','CAM_BACK': '03bea5763f0f4722933508d5999c5fd8','CAM_BACK_LEFT': '43893a033f9c46d4a51b5e08a67a1eb7','CAM_FRONT_LEFT': 'fe5422747a7d4268a4b07fc396707b23'},'anns': ['ef63a697930c4b20a6b9791f423351da','6b89da9bf1f84fd6a5fbe1c3b236f809','924ee6ac1fed440a9d9e3720aac635a0','91e3608f55174a319246f361690906ba','cd051723ed9c40f692b9266359f547af','36d52dfedd764b27863375543c965376','70af124fceeb433ea73a79537e4bea9e','63b89fe17f3e41ecbe28337e0e35db8e','e4a3582721c34f528e3367f0bda9485d','fcb2332977ed4203aa4b7e04a538e309','a0cac1c12246451684116067ae2611f6','02248ff567e3497c957c369dc9a1bd5c','9db977e264964c2887db1e37113cddaa','ca9c5dd6cf374aa980fdd81022f016fd','179b8b54ee74425893387ebc09ee133d','5b990ac640bf498ca7fd55eaf85d3e12','16140fbf143d4e26a4a7613cbd3aa0e8','54939f11a73d4398b14aeef500bf0c23','83d881a6b3d94ef3a3bc3b585cc514f8','74986f1604f047b6925d409915265bf7','e86330c5538c4858b8d3ffe874556cc5','a7bd5bb89e27455bbb3dba89a576b6a1','fbd9d8c939b24f0eb6496243a41e8c41','198023a1fb5343a5b6fad033ab8b7057','ffeafb90ecd5429cba23d0be9a5b54ee','cc636a58e27e446cbdd030c14f3718fd','076a7e3ec6244d3b84e7df5ebcbac637','0603fbaef1234c6c86424b163d2e3141','d76bd5dcc62f4c57b9cece1c7bcfabc5','5acb6c71bcd64aa188804411b28c4c8f','49b74a5f193c4759b203123b58ca176d','77519174b48f4853a895f58bb8f98661','c5e9455e98bb42c0af7d1990db1df0c9','fcc5b4b5c4724179ab24962a39ca6d65','791d1ca7e228433fa50b01778c32449a','316d20eb238c43ef9ee195642dd6e3fe','cda0a9085607438c9b1ea87f4360dd64','e865152aaa194f22b97ad0078c012b21','7962506dbc24423aa540a5e4c7083dad','29cca6a580924b72a90b9dd6e7710d3e','a6f7d4bb60374f868144c5ba4431bf4c','f1ae3f713ba946069fa084a6b8626fbf','d7af8ede316546f68d4ab4f3dbf03f88','91cb8f15ed4444e99470d43515e50c1d','bc638d33e89848f58c0b3ccf3900c8bb','26fb370c13f844de9d1830f6176ebab6','7e66fdf908d84237943c833e6c1b317a','67c5dbb3ddcc4aff8ec5140930723c37','eaf2532c820740ae905bb7ed78fb1037','3e2d17fa9aa5484d9cabc1dfca532193','de6bd5ffbed24aa59c8891f8d9c32c44','9d51d699f635478fbbcd82a70396dd62','b7cbc6d0e80e4dfda7164871ece6cb71','563a3f547bd64a2f9969278c5ef447fd','df8917888b81424f8c0670939e61d885','bb3ef5ced8854640910132b11b597348','a522ce1d7f6545d7955779f25d01783b','1fafb2468af5481ca9967407af219c32','05de82bdb8484623906bb9d97ae87542','bfedb0d85e164b7697d1e72dd971fb72','ca0f85b4f0d44beb9b7ff87b1ab37ff5','bca4bbfdef3d4de980842f28be80b3ca','a834fb0389a8453c810c3330e3503e16','6c804cb7d78943b195045082c5c2d7fa','adf1594def9e4722b952fea33b307937','49f76277d07541c5a584aa14c9d28754','15a3b4d60b514db5a3468e2aef72a90c','18cc2837f2b9457c80af0761a0b83ccc','2bfcc693ae9946daba1d9f2724478fd4']}
sample {"token": <str> -- Unique record identifier."timestamp": <int> -- Unix time stamp."scene_token": <str> -- Foreign key pointing to the scene."next": <str> -- Foreign key. Sample that follows this in time. Empty if end of scene."prev": <str> -- Foreign key. Sample that precedes this in time. Empty if start of scene.
}
{"token": <str> -- 唯一的记录标识符。"timestamp": <int> -- Unix 时间戳。"scene_token": <str> -- 指向场景的外键。"next": <str> -- 外键。时间上跟随此记录的样本。如果是场景的结尾,则为空。"prev": <str> -- 外键。时间上在此记录之前的样本。如果是场景的开始,则为空。
}
11、sample_data 样本数据
传感器数据,如图像、点云或雷达返回。 对于is_key_frame=True的sample_data,时间戳应该非常接近它所指向的样本。 对于非关键帧,sample_data指向时间上最接近的样本。
sample_data {"token": <str> -- Unique record identifier."sample_token": <str> -- Foreign key. Sample to which this sample_data is associated."ego_pose_token": <str> -- Foreign key."calibrated_sensor_token": <str> -- Foreign key."filename": <str> -- Relative path to data-blob on disk."fileformat": <str> -- Data file format."width": <int> -- If the sample data is an image, this is the image width in pixels."height": <int> -- If the sample data is an image, this is the image height in pixels."timestamp": <int> -- Unix time stamp."is_key_frame": <bool> -- True if sample_data is part of key_frame, else False."next": <str> -- Foreign key. Sample data from the same sensor that follows this in time. Empty if end of scene."prev": <str> -- Foreign key. Sample data from the same sensor that precedes this in time. Empty if start of scene.
}{"token": <str> -- 唯一的记录标识符。"sample_token": <str> -- 外键。与此 sample_data 关联的样本。"ego_pose_token": <str> -- 外键。自车位姿的标识符。"calibrated_sensor_token": <str> -- 外键。校准传感器的标识符。"filename": <str> -- 数据文件在磁盘上的相对路径。"fileformat": <str> -- 数据文件格式。"width": <int> -- 如果 sample data 是图像,这是图像的宽度(像素)。"height": <int> -- 如果 sample data 是图像,这是图像的高度(像素)。"timestamp": <int> -- Unix 时间戳。"is_key_frame": <bool> -- 如果 sample data 是关键帧的一部分,则为 True,否则为 False。"next": <str> -- 外键。时间上跟随此传感器数据的同一传感器的数据。如果是场景的结尾,则为空。"prev": <str> -- 外键。时间上在此传感器数据之前的同一传感器的数据。如果是场景的开始,则为空。
}nuScenes数据集包含从完整的传感器套件收集的数据。因此,对于场景的每个快照,我们提供了从这些传感器收集的一系列数据的参考。
We provide a data key to access these:我们提供了一个 data 键来访问这些:
my_sample['data']
{'RADAR_FRONT': '37091c75b9704e0daa829ba56dfa0906','RADAR_FRONT_LEFT': '11946c1461d14016a322916157da3c7d','RADAR_FRONT_RIGHT': '491209956ee3435a9ec173dad3aaf58b','RADAR_BACK_LEFT': '312aa38d0e3e4f01b3124c523e6f9776','RADAR_BACK_RIGHT': '07b30d5eb6104e79be58eadf94382bc1','LIDAR_TOP': '9d9bf11fb0e144c8b446d54a8a00184f','CAM_FRONT': 'e3d495d4ac534d54b321f50006683844','CAM_FRONT_RIGHT': 'aac7867ebf4f446395d29fbd60b63b3b','CAM_BACK_RIGHT': '79dbb4460a6b40f49f9c150cb118247e','CAM_BACK': '03bea5763f0f4722933508d5999c5fd8','CAM_BACK_LEFT': '43893a033f9c46d4a51b5e08a67a1eb7','CAM_FRONT_LEFT': 'fe5422747a7d4268a4b07fc396707b23'}
注意,这些键指的是构成传感器套件的不同传感器。让我们看一下从 CAM_FRONT 获取的 sample_data 的元数据。
sensor = 'CAM_FRONT'
cam_front_data = nusc.get('sample_data', my_sample['data'][sensor])
cam_front_data
{'token': 'e3d495d4ac534d54b321f50006683844','sample_token': 'ca9a282c9e77460f8360f564131a8af5','ego_pose_token': 'e3d495d4ac534d54b321f50006683844','calibrated_sensor_token': '1d31c729b073425e8e0202c5c6e66ee1','timestamp': 1532402927612460,'fileformat': 'jpg','is_key_frame': True,'height': 900,'width': 1600,'filename': 'samples/CAM_FRONT/n015-2018-07-24-11-22-45+0800__CAM_FRONT__1532402927612460.jpg','prev': '','next': '68e8e98cf7b0487baa139df808641db7','sensor_modality': 'camera','channel': 'CAM_FRONT'}
我们还可以在特定的传感器上渲染 sample_data 。sample_data 条目的元数据。sample_data 包含多个传感器的对应 token,需要使用这些 token 来展示具体的内容。例如,如果我们想渲染 CAM_FRONT 传感器的数据,可以使用如下代码
nusc.render_sample_data(cam_front_data['token'])
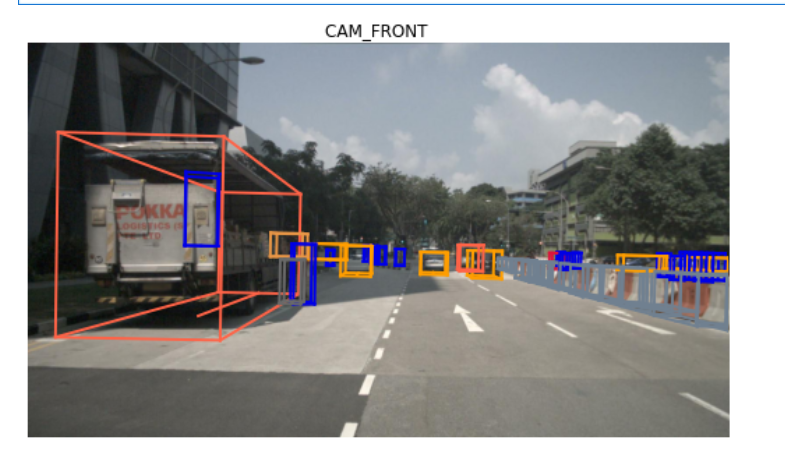
综上所述,一个 sample_data 仅包含多个传感器的对应 token。使用这些 token 可以展示具体传感器的数据内容。
12、sample_annotation 样本注释
sample_annotation 表示定义样本中所见对象位置的任何边界框。所有的位置数据都是相对于全球坐标系给出的。让我们看看上面 sample 中的一个例子。
sample_annotation {"token": <str> -- Unique record identifier."sample_token": <str> -- Foreign key. NOTE: this points to a sample NOT a sample_data since annotations are done on the sample level taking all relevant sample_data into account."instance_token": <str> -- Foreign key. Which object instance is this annotating. An instance can have multiple annotations over time."attribute_tokens": <str> [n] -- Foreign keys. List of attributes for this annotation. Attributes can change over time, so they belong here, not in the instance table."visibility_token": <str> -- Foreign key. Visibility may also change over time. If no visibility is annotated, the token is an empty string."translation": <float> [3] -- Bounding box location in meters as center_x, center_y, center_z."size": <float> [3] -- Bounding box size in meters as width, length, height."rotation": <float> [4] -- Bounding box orientation as quaternion: w, x, y, z."num_lidar_pts": <int> -- Number of lidar points in this box. Points are counted during the lidar sweep identified with this sample."num_radar_pts": <int> -- Number of radar points in this box. Points are counted during the radar sweep identified with this sample. This number is summed across all radar sensors without any invalid point filtering."next": <str> -- Foreign key. Sample annotation from the same object instance that follows this in time. Empty if this is the last annotation for this object."prev": <str> -- Foreign key. Sample annotation from the same object instance that precedes this in time. Empty if this is the first annotation for this object.
}{"token": <str> -- 唯一的记录标识符。"sample_token": <str> -- 外键。注意:这指向一个样本(sample),而不是样本数据(sample_data),因为注释是在样本级别完成的,考虑了所有相关的样本数据。"instance_token": <str> -- 外键。此注释标注的是哪个对象实例。一个实例可以随着时间有多个注释。"attribute_tokens": <str> [n] -- 外键列表。此注释的属性列表。属性可以随时间改变,所以它们属于这里,而不是实例表。"visibility_token": <str> -- 外键。可见性也可以随时间变化。如果没有标注可见性,该字段为空字符串。"translation": <float> [3] -- 边界框位置,以米为单位,格式为中心点的 x, y, z 坐标。"size": <float> [3] -- 边界框大小,以米为单位,格式为宽度、长度、高度。"rotation": <float> [4] -- 边界框方向,四元数表示:w, x, y, z。"num_lidar_pts": <int> -- 此框中的激光雷达点数。点数是在与此样本标识的激光雷达扫描期间计数的。"num_radar_pts": <int> -- 此框中的雷达点数。点数是在与此样本标识的雷达扫描期间计数的。此数字是所有雷达传感器的点数总和,没有进行任何无效点过滤。"next": <str> -- 外键。时间上跟随此对象实例的样本注释。如果这是该对象的最后一个注释,则为空。"prev": <str> -- 外键。时间上在此对象实例之前的样本注释。如果这是该对象的第一个注释,则为空。
}my_annotation_token = my_sample['anns'][18]
my_annotation_metadata = nusc.get('sample_annotation', my_annotation_token)
my_annotation_metadata
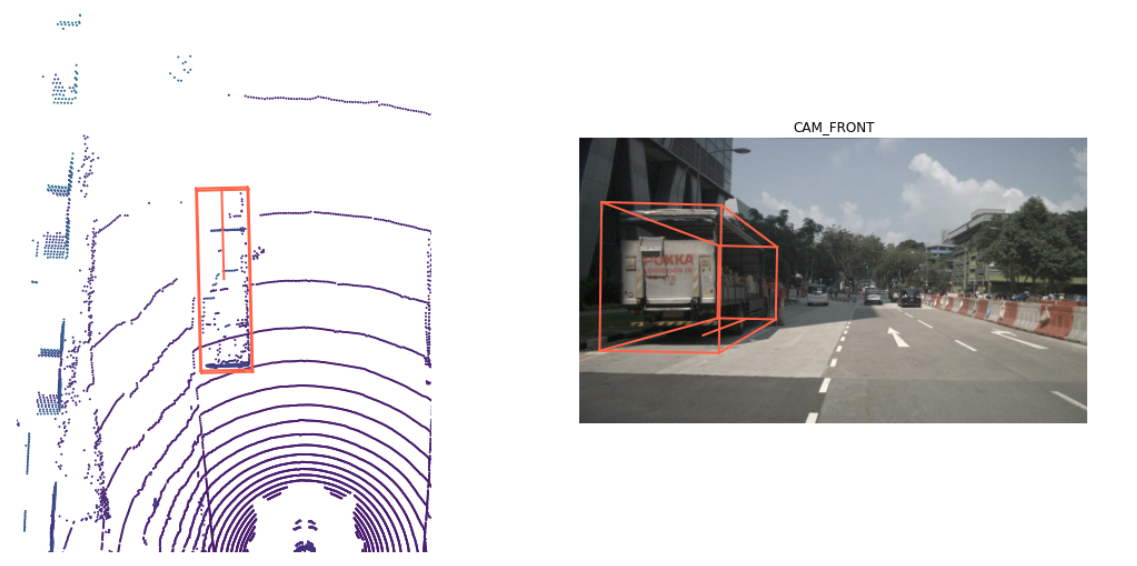
{'token': '83d881a6b3d94ef3a3bc3b585cc514f8','sample_token': 'ca9a282c9e77460f8360f564131a8af5','instance_token': 'e91afa15647c4c4994f19aeb302c7179','visibility_token': '4','attribute_tokens': ['58aa28b1c2a54dc88e169808c07331e3'],'translation': [409.989, 1164.099, 1.623],'size': [2.877, 10.201, 3.595],'rotation': [-0.5828819500503033, 0.0, 0.0, 0.812556848660791],'prev': '','next': 'f3721bdfd7ee4fd2a4f94874286df471','num_lidar_pts': 495,'num_radar_pts': 13,'category_name': 'vehicle.truck'}
边界框的含义和应用
- 描述物体的位置和大小:边界框用于精确描述检测到的物体在三维空间中的位置(中心点),以及物体的尺寸(宽度、长度和高度)。
- 物体的方向:使用四元数表示边界框的旋转方向,可以准确描述物体在三维空间中的朝向。
- 检测结果表示:在物体检测任务中,边界框是表示检测结果的常用方式。例如,在自动驾驶场景中,车辆、行人等目标物体都会被检测并用边界框标出其位置和大小。
- 数据可视化:在数据可视化过程中,边界框可以用来在三维点云或图像上标出物体的位置和尺寸,帮助理解和分析检测结果。
nusc.render_annotation(my_annotation_token)
三、具体流程
在nuScenes数据集中,数据的逻辑关系和结构是层次化的,每个数据表和记录之间有明确的关系。以下是这些关系的解释,以及如何通过这些关系理解数据总量:
1、逻辑关系
- 场景(scene) 主体是位置:
- 每个场景是一个连续的驾驶情境,包括多个时间点的数据。数据集中有10个场景。
- 一个场景中可能包括多种不同的传感器数据,如图像、激光雷达数据等。
- 样本(sample) 主体是某一时间点上的所有传感器数据集合:
- 每个场景由多个样本组成。样本表示某一时间点上的所有传感器数据集合。
- 数据集中总共有404个样本,分布在10个场景中。
- 样本数据(sample_data) 主体是所有传感器:
- 每个样本包含多个样本数据,每个样本数据对应一个具体的传感器读取(例如,一帧图像或一组激光雷达点云)。
- 数据集中有31206个样本数据。
- 样本注释(sample_annotation) 主体是被传感器记录的内容:
- 样本注释是对每个样本中检测到的物体及其属性的描述。
- 数据集中有18538个样本注释。
2、比较探讨
1、场景(scene)和样本(sample)
nuScenes数据集包含10个场景,每个场景约20秒,每秒采集多帧数据,总计有404个样本。每个样本代表一个时间点,包含所有传感器在该时间点的数据。
2、传感器数据(sample_data)
每个样本(sample)都包含多个传感器的数据。这些传感器包括前雷达(RADAR_FRONT)、左前雷达(RADAR_FRONT_LEFT)、右前雷达(RADAR_FRONT_RIGHT)、左后雷达(RADAR_BACK_LEFT)、右后雷达(RADAR_BACK_RIGHT)、顶部激光雷达(LIDAR_TOP)和六个摄像头(CAM_FRONT、CAM_FRONT_RIGHT、CAM_BACK_RIGHT、CAM_BACK、CAM_BACK_LEFT、CAM_FRONT_LEFT)。
3、实例(instance)和 样本注释(sample_annotation)
如果多个传感器都记录了同一个实例(例如一个人),那么 instance 表中只会有一个记录代表这个人,但是在 sample_annotation 表中可能会有多个记录,因为每个传感器的数据都会生成一个单独的注释。
instance 表:这个表记录了数据集中唯一的对象实例,例如一个特定的人或车辆。每个实例有一个唯一的 token 标识。
sample_annotation表:这个表记录了每个样本中所有对象的注释。每条注释详细描述了对象在特定时间点上的位置、尺寸、方向、可见性等属性。
“instance_token”: – 外键。此注释标注的是哪个对象实例。一个实例可以随着时间有多个注释。