Solr 源码启动教程
本教程记录了如何通过 IDEA 启动并调试 Solr 源码,从 Solr9 开始 Solr 项目已由 ant 方式改成了 gradle 构建方式,本教程将以 Solr 9 为例进行演示,IDE 选择使用 IntelliJ IDEA。
Solr github 地址:https://github.com/apache/solr
JDK 版本:jdk17
关于系统版本可以参考:https://solr.apache.org/guide/solr/latest/deployment-guide/system-requirements.html
下载 Solr 源码并导入到 IDEA 中
可以从 github 上 clone 下载 java 源码:
git clone git@github.com:apache/solr.git
# git clone https://github.com/apache/solr.git
亦或者下载相应版本的 java 源码包,如下图所示:
下载或 clone 好后,用 IDEA 打开 solr 源码,由于现在 Solr 使用 gradle 构建,IDEA 会自动识别 gradle 项目并进行加载,加载好后如下:
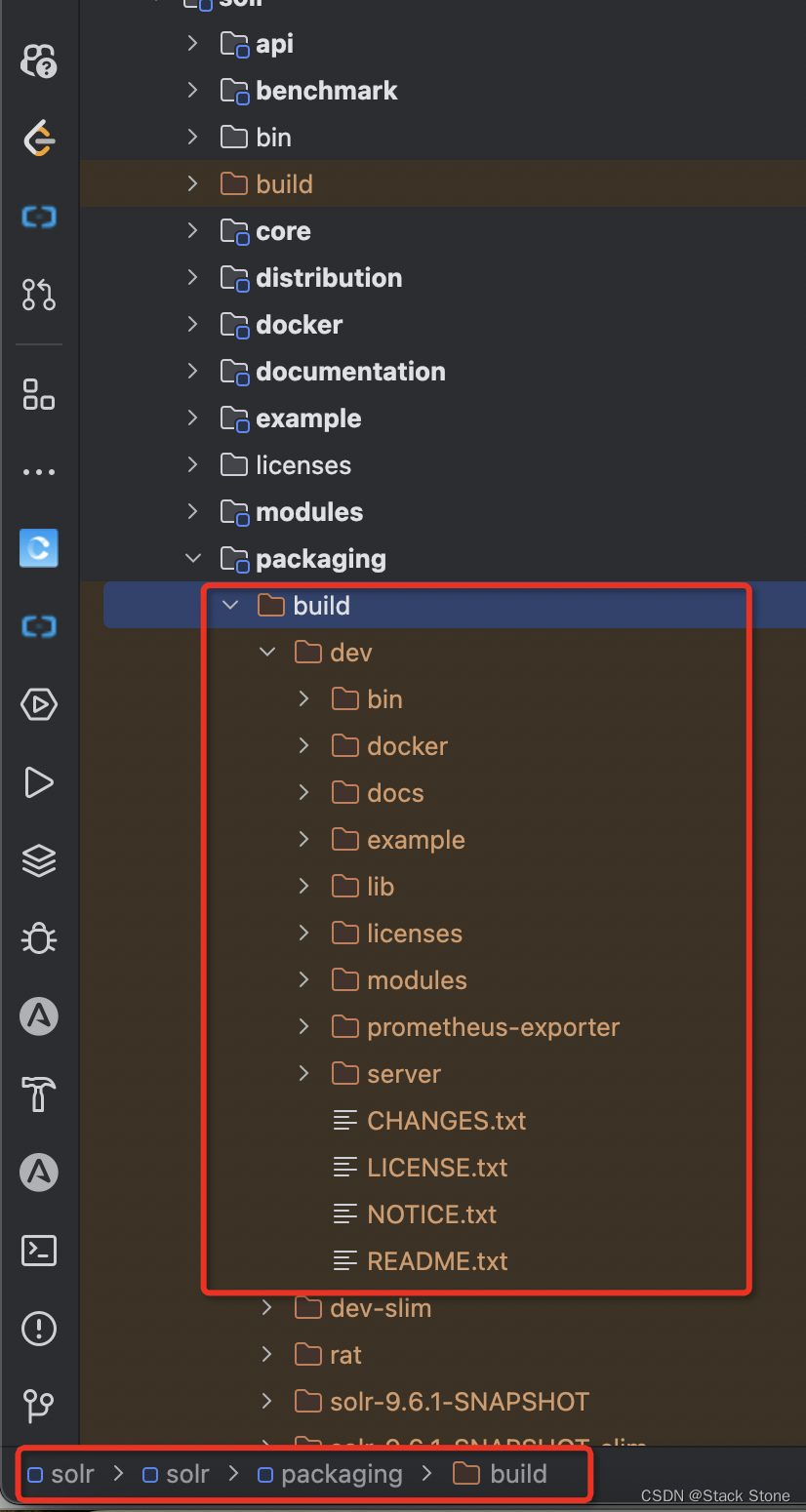
可以在项目的根目录下运行 ./gradlew dev 会构建 Solr 的开发发行版,其会在项目的 solr/packaging 目录下生成 build 目录,如下所示:
我们可以在 help 目录下查看一些关于项目的帮助说明,比如在 formatting.txt 中,如下所示:
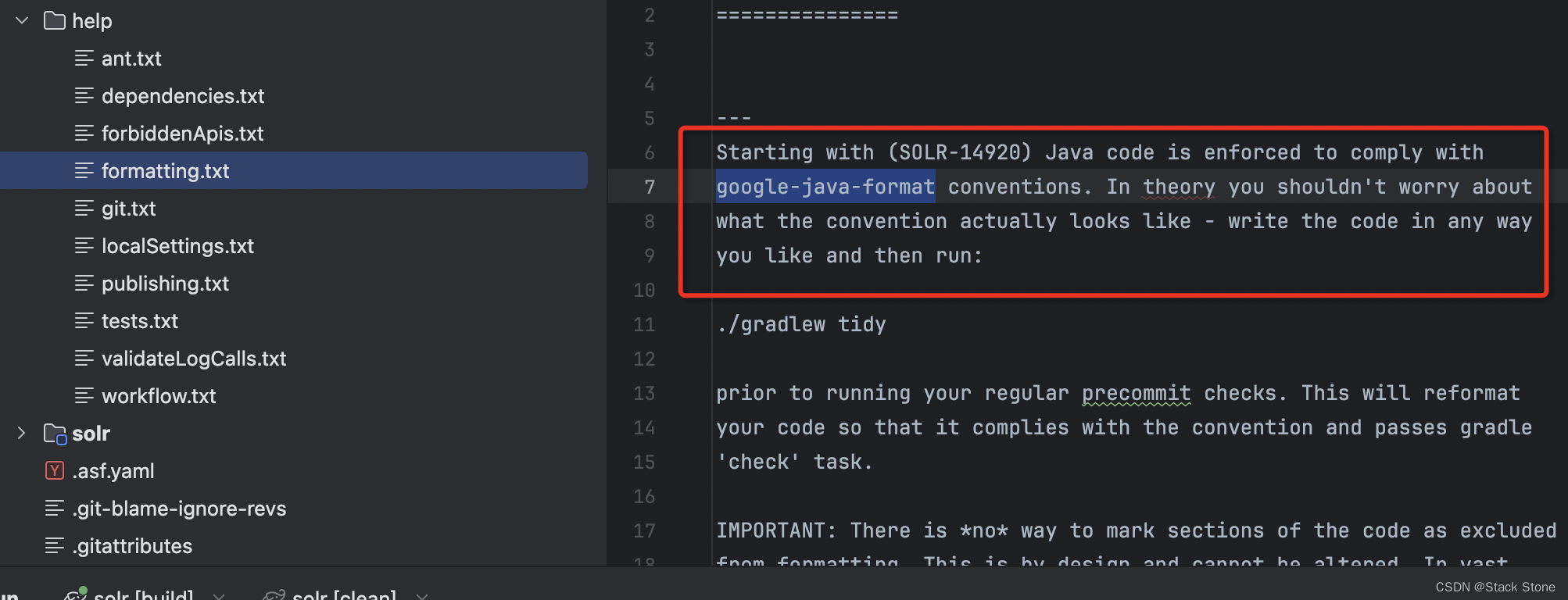
提到了项目使用了 goole-java-format 来风格化代码,所以如果更改 Solr 源码后,我们可以使用 ./gradlew tidy 来风格化代码,亦或者 IDEA 安装 goole-java-format 插件并应用于 Solr 项目。
运行 StartSolrJetty 启动 Solr 服务(非 SolrCloud 方式运行)
如果我们不以 SolrCloud 的方式启动 Solr 服务,我们可以修改 StartSolrJetty 来启动项目,具体做法如下:
- 定义 SolrHome 目录
可以在本地电脑选择一个目录作为 SolrHome,SolrHome 是指 Apache Solr 的主目录,它是 Solr 实例运行的基础环境和配置的中心位置。这个目录包含了所有关键的配置文件、库文件、日志以及包含各个 Solr Core 数据的目录。
比如我创建了本地目录/Workspace/SolrHome/Solr9/standalone,之后把项目的solr/server/solr/solr.xml文件拷贝至该目录下,如下所示:
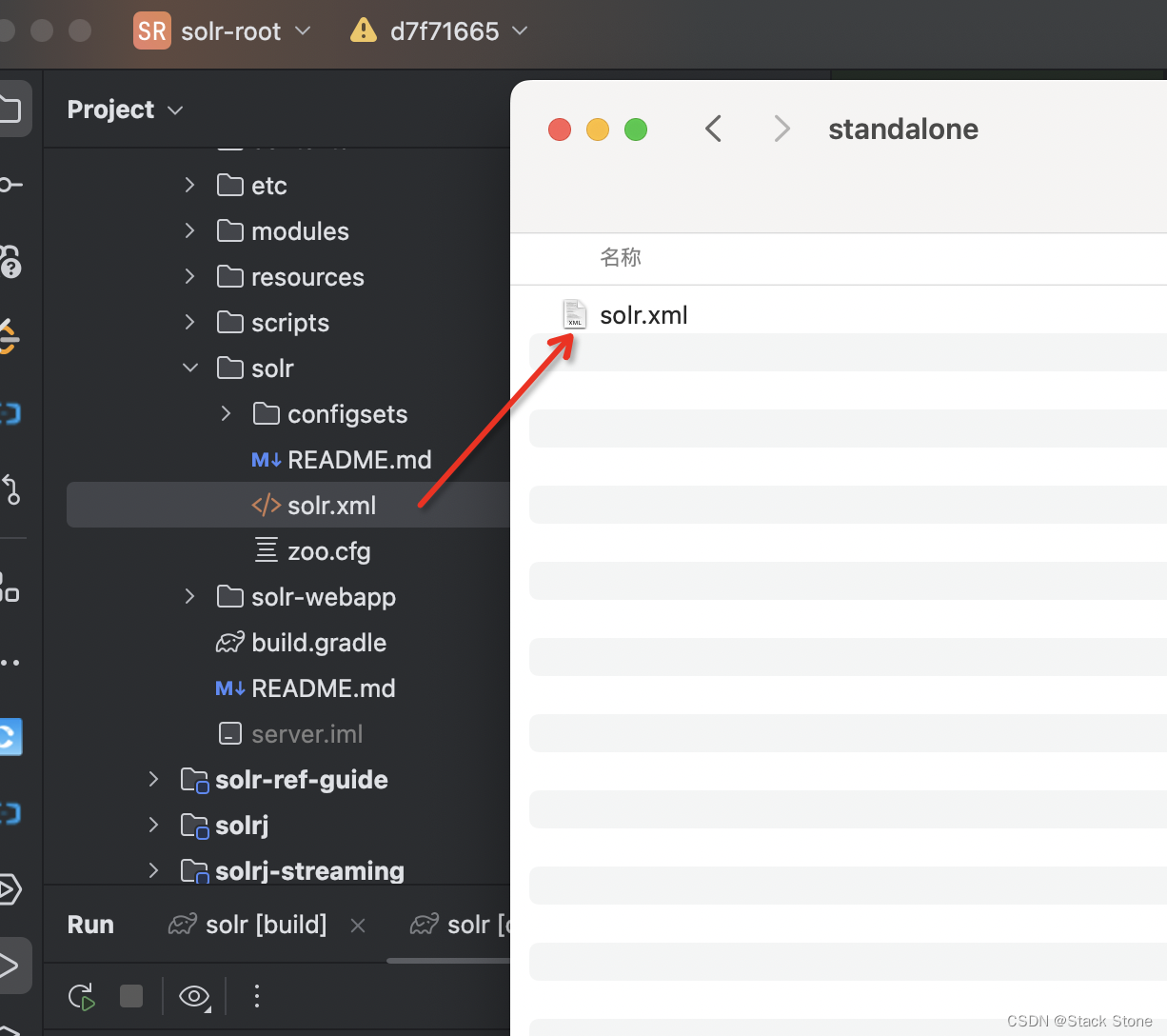
- 定义 SolrCore 目录
之后我们在/Workspace/SolrHome/Solr9/standalone中创建一个 core 目录,把solr/server/solr/configsets/_default/conf的内容拷贝至该目录下,如下所示:
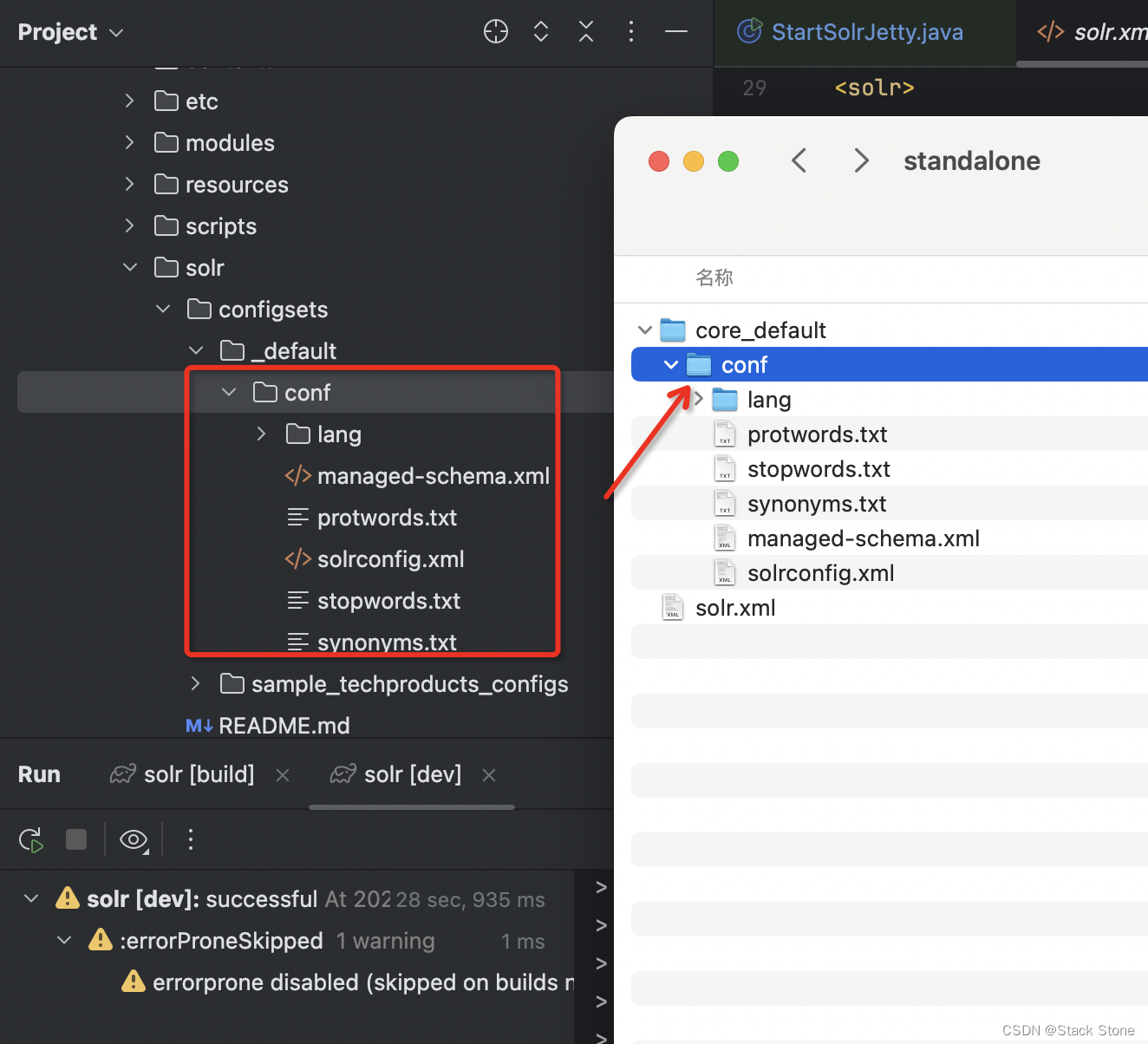
这里我创建了一个core_default目录,并把源码提供的_default的配置拷贝了到了这个目录下,这个目录作为演示的 Solr Core 目录。
什么是 Solr Core?
Solr Core 是 Apache Solr 中的一个基本构建块,它代表一个单独的可搜索的文档集合。每个 Solr Core 都包含其自己的索引文件、配置文件和与之相关的处理逻辑。这使得 Solr 能够在同一个 Solr 实例中同时运行多个搜索应用,每个应用拥有不同的数据和配置,但共享相同的资源。
Solr Core 的目录结构
Solr Core 的目录结构是 Solr 应用中管理索引和配置的关键部分。每个 Core 目录通常包含若干关键文件和子目录,这些组成部分确保了 Solr 能够高效地处理搜索请求和索引操作。Solr Core 目录结构的关键组成部分:
- conf/:
- solrconfig.xml:控制 Solr Core 的操作和行为,包括搜索组件、请求处理器等。
- schema.xml 或 managed-schema:定义索引中的字段和类型,是索引创建和查询的基础。
- stopwords.txt:列出在索引过程中将被忽略的词汇,有助于优化搜索效率和准确性。
- synonyms.txt:定义搜索中使用的同义词,增强搜索的灵活性和深度。
- data/:
- 存放实际的索引数据,由 Lucene 管理,包括但不限于文档数据、索引文件等。
- 这个目录的内容通常是动态变化的,随着文档的增加、更新和删除而更新。
- lib/:
- 可选的目录,包含 Core 特定的 Java 类库文件。如果某个 Core 需要特殊的库而不是共享 Solr 实例中的库,则会使用这个目录。
- lang/:
- 可选的目录,包含支持多语言处理的配置文件,如语言分析器等。
- logs/:
- 可选的目录,某些配置下 Solr Core 可能会在这里生成特定的日志文件。
功能和用途:
- conf/ 目录是 Core 配置的核心,影响索引结构和搜索行为的所有方面。
- data/ 目录是索引和搜索操作的物理基础,直接关联到性能和存储。
- lib/ 和 lang/ 目录提供了扩展性和灵活性,使得每个 Core 能够根据特定需求定制功能。
- 修改 StartSolrJetty 类,并启动
在项目中找到StartSolrJetty.java这个类,如下图所示:
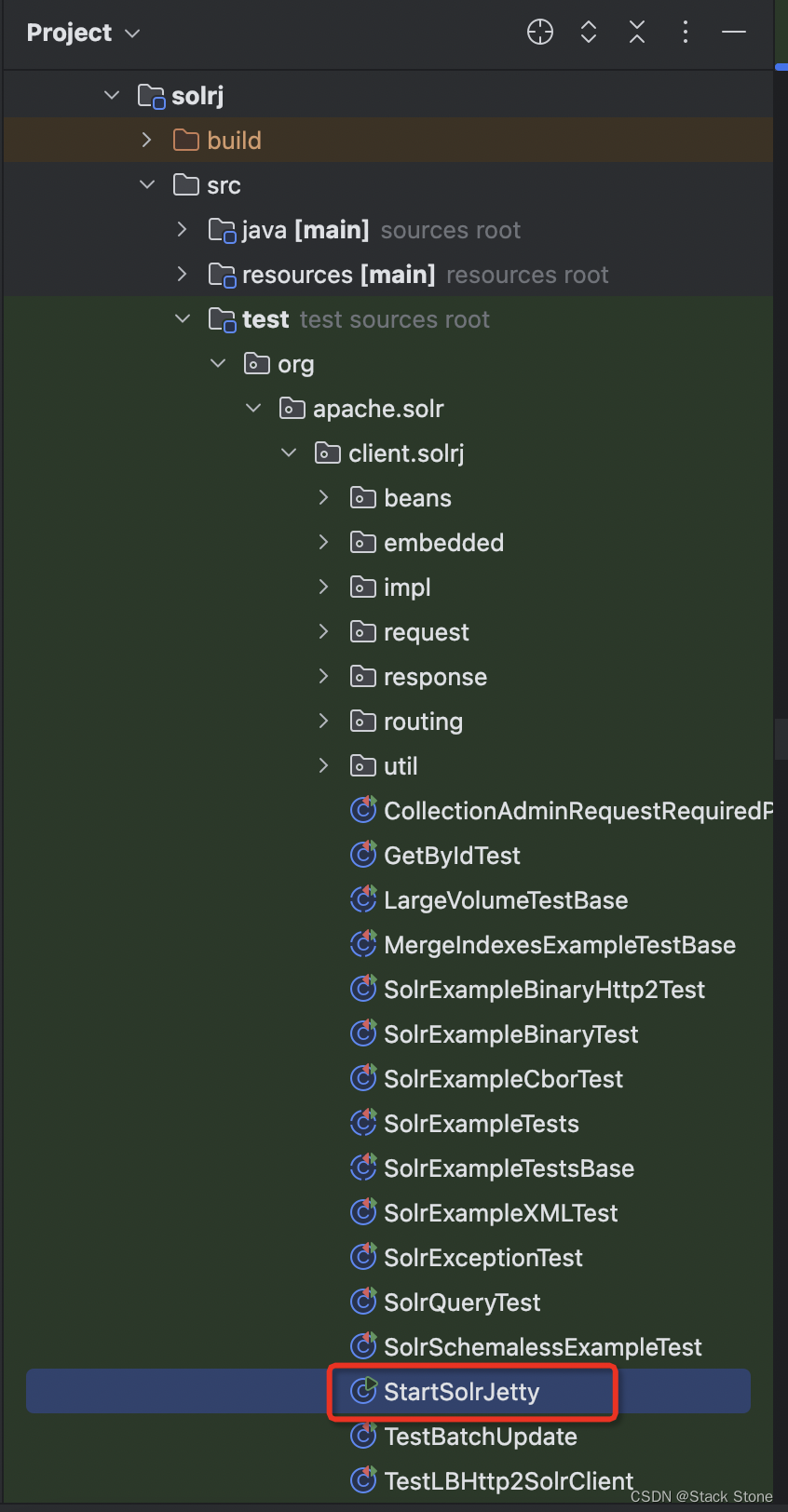
我们需要对这个类的main方法做简单的修改,具体代码如下:
在代码中,我们需要指定 SolrHome 的绝对路径以及 Solr 的public static void main(String[] args) {// System.setProperty("solr.solr.home", "../../../example/solr");// 这里需要填写之前创建的 SolrHome 的绝对路径System.setProperty("solr.solr.home", "/Workspace/SolrHome/Solr9/standalone");Server server = new Server();ServerConnector connector = new ServerConnector(server, new HttpConnectionFactory());// Set some timeout options to make debugging easier.connector.setIdleTimeout(1000 * 60 * 60);connector.setPort(8983);server.setConnectors(new Connector[] {connector});WebAppContext bb = new WebAppContext();bb.setServer(server);bb.setContextPath("/solr");// bb.setWar("webapp/web");// 这里需要填写 Solr 源码的 `solr/webapp/web` 的绝对路径bb.setWar("/Workspace/source-code/solr/solr/webapp/web");// // START JMX SERVER// if( true ) {// MBeanServer mBeanServer = ManagementFactory.getPlatformMBeanServer();// MBeanContainer mBeanContainer = new MBeanContainer(mBeanServer);// server.getContainer().addEventListener(mBeanContainer);// mBeanContainer.start();// }server.setHandler(bb);try {System.out.println(">>> STARTING EMBEDDED JETTY SERVER, PRESS ANY KEY TO STOP");server.start();while (System.in.available() == 0) {Thread.sleep(5000);}server.stop();server.join();} catch (Exception e) {log.error("failed to start", e);System.exit(100);}}webapp/web的绝对路径,webapp/web目录对应项目目录如下:
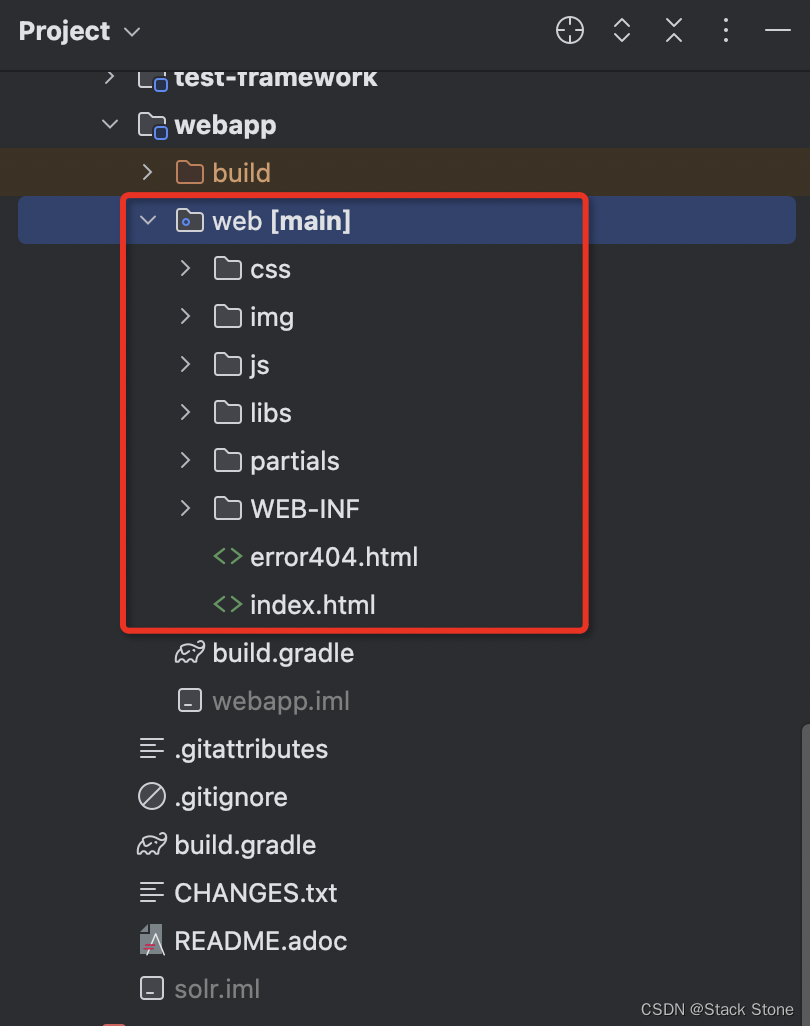
之后运行启动这个类:
浏览器访问:http://localhost:8983/solr,页面如下:

- 创建 Core
如下所示:
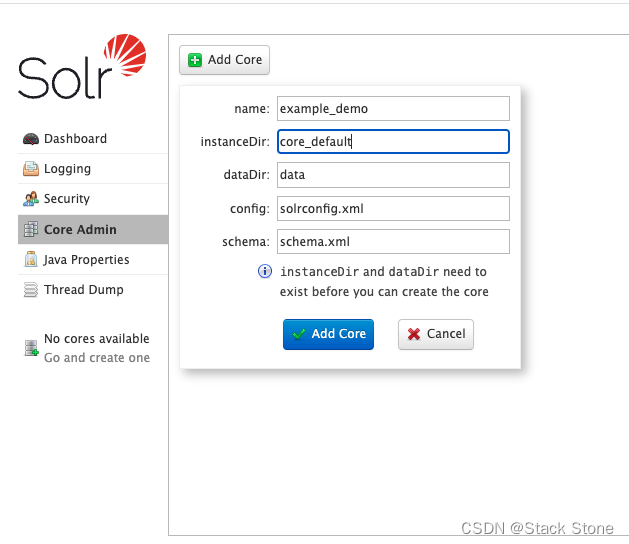
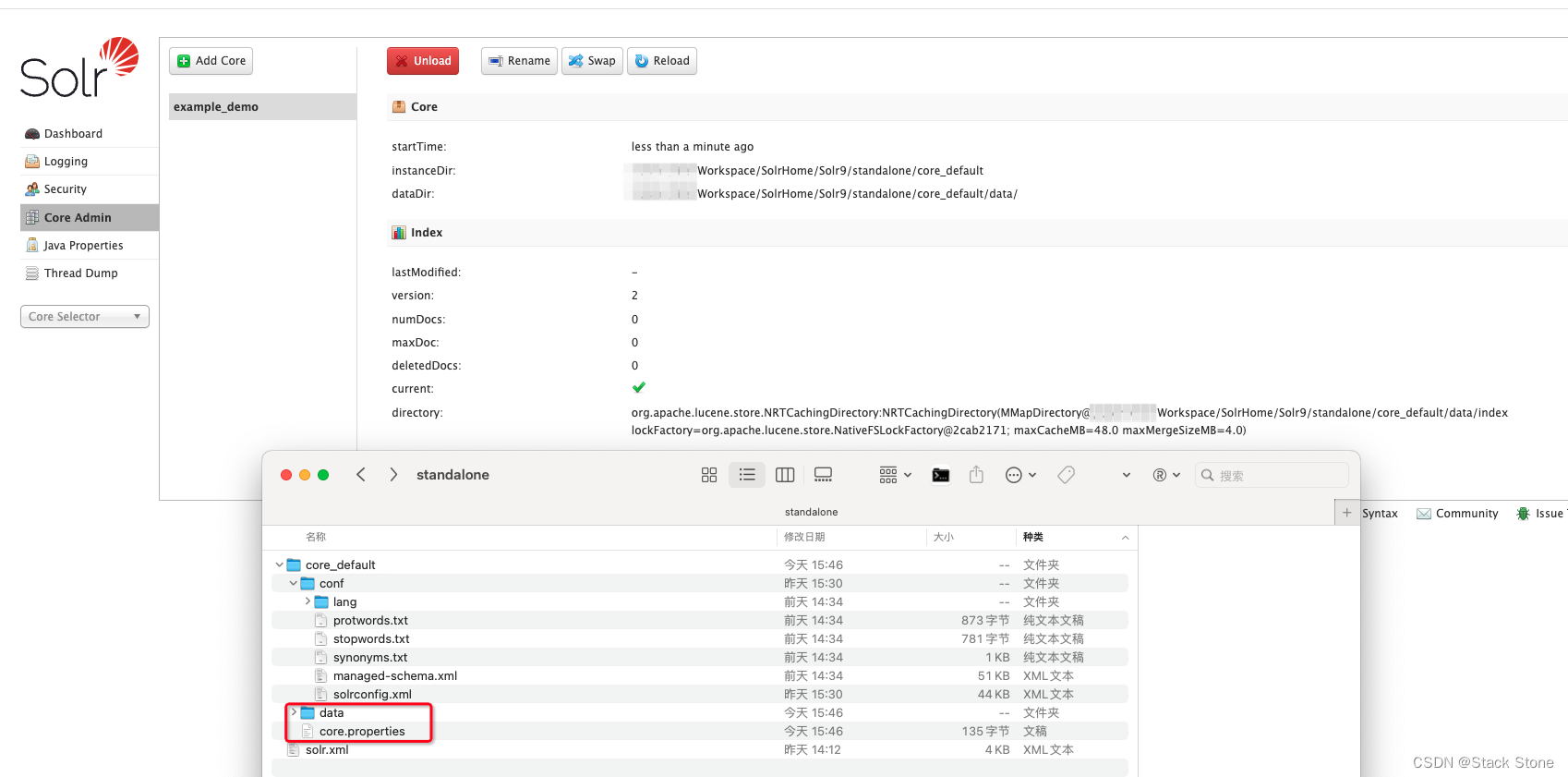
我们添加一个 Core,这里的instanceDir就是刚才我们创建的 Core 目录的名称,添加好后,如下所示,可以看到添加的 Core 名称为example_demo同时会在 Core 目录下多出了data索引目录以及core.propertiesCore 属性文件
在如下页面可以运行查询:
- 断点调试 Solr 源码
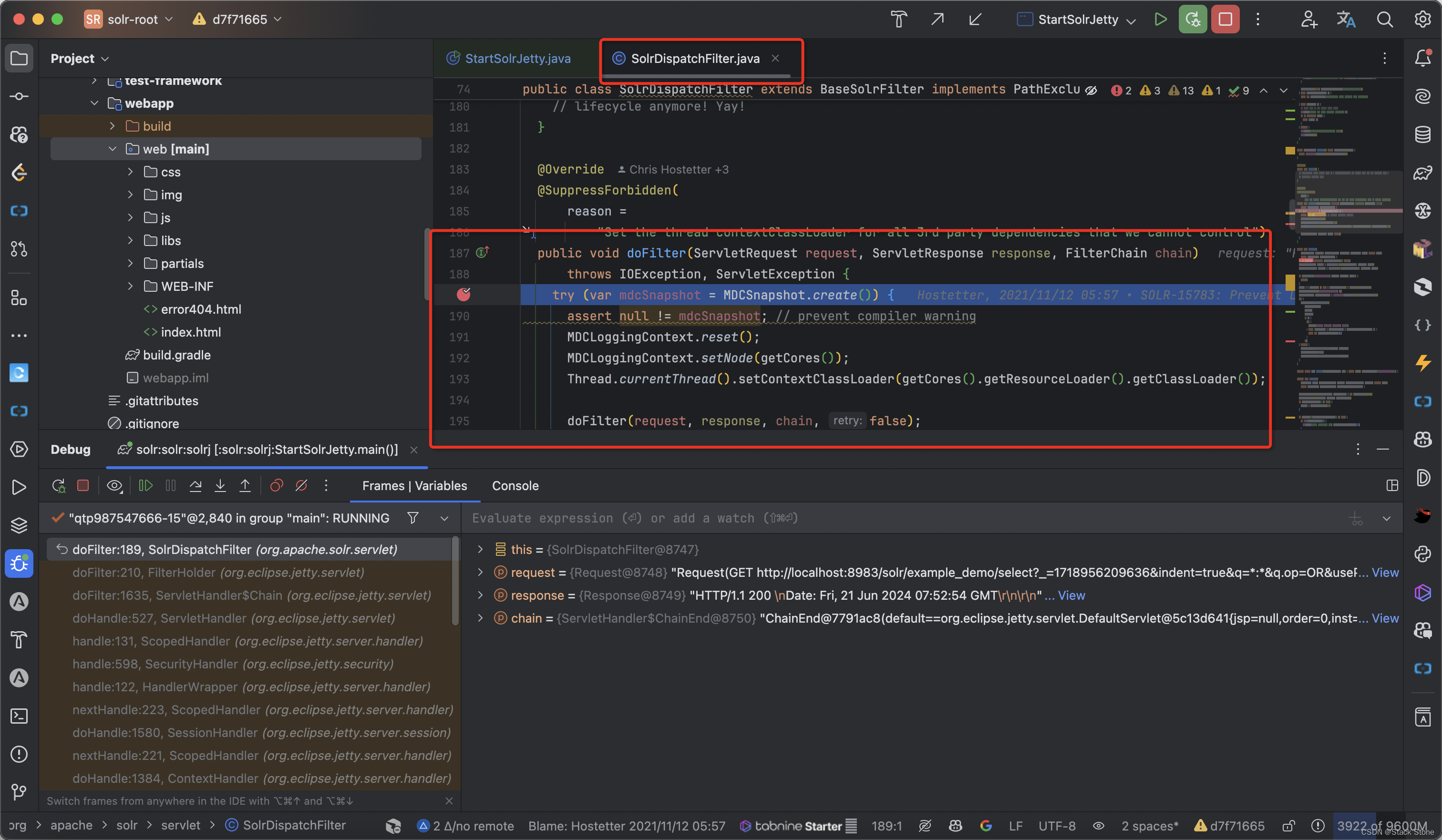
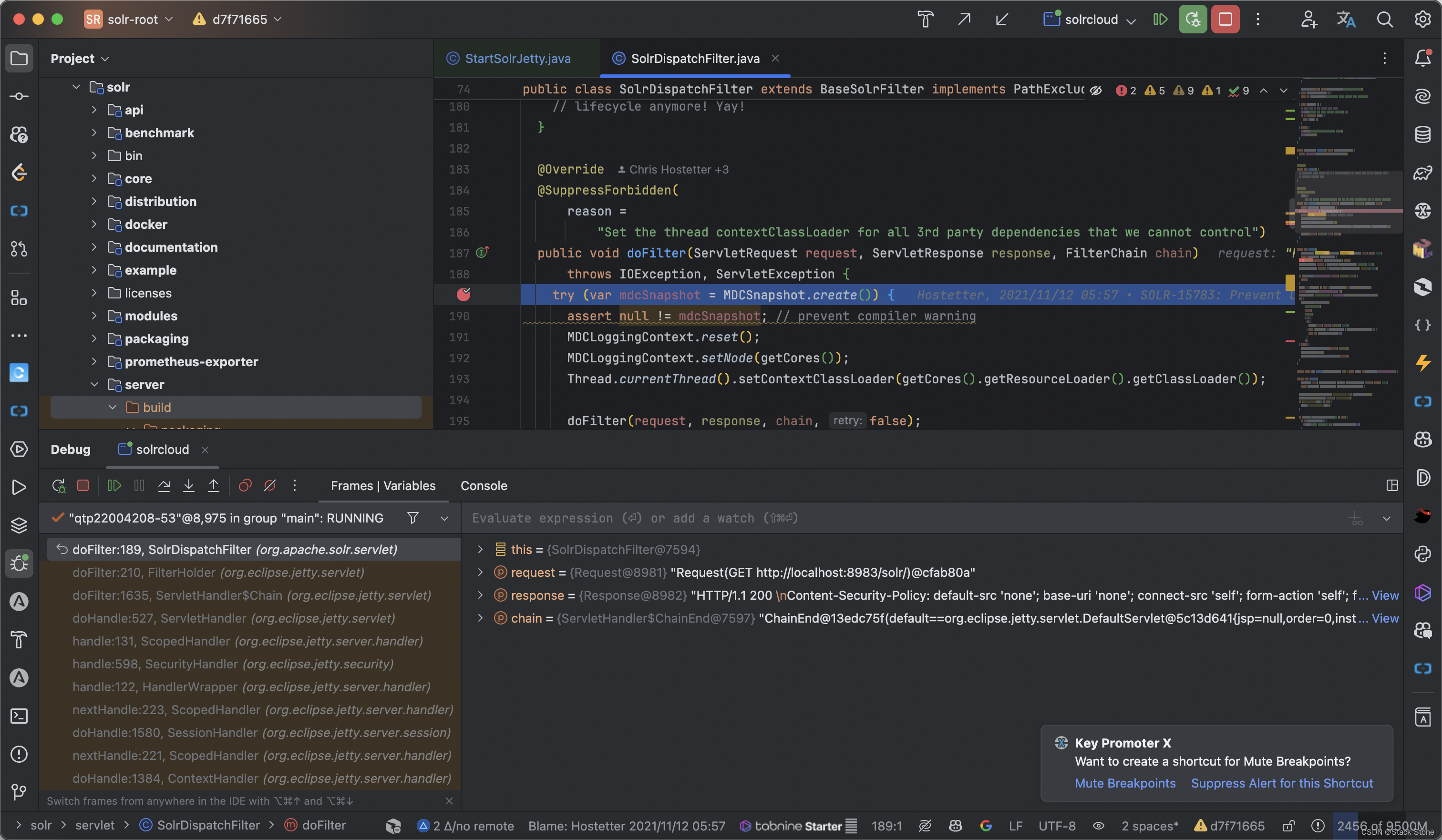
如果StartSolrJetty是以 debug 方式运行的,你可以在项目中打断点调试 Solr 源码,Solr 的请求入口在SolrDispatchFile.doFilter处,如下所示:
以 SolrCloud 方式运行 Solr 源码
如果想通过 SolrCloud 方式运行并调试 Solr 源码,我们需要创建一个运行应用,具体操作如下所示:
-
运行
./gradlew dev构建 Solr 开发发行版
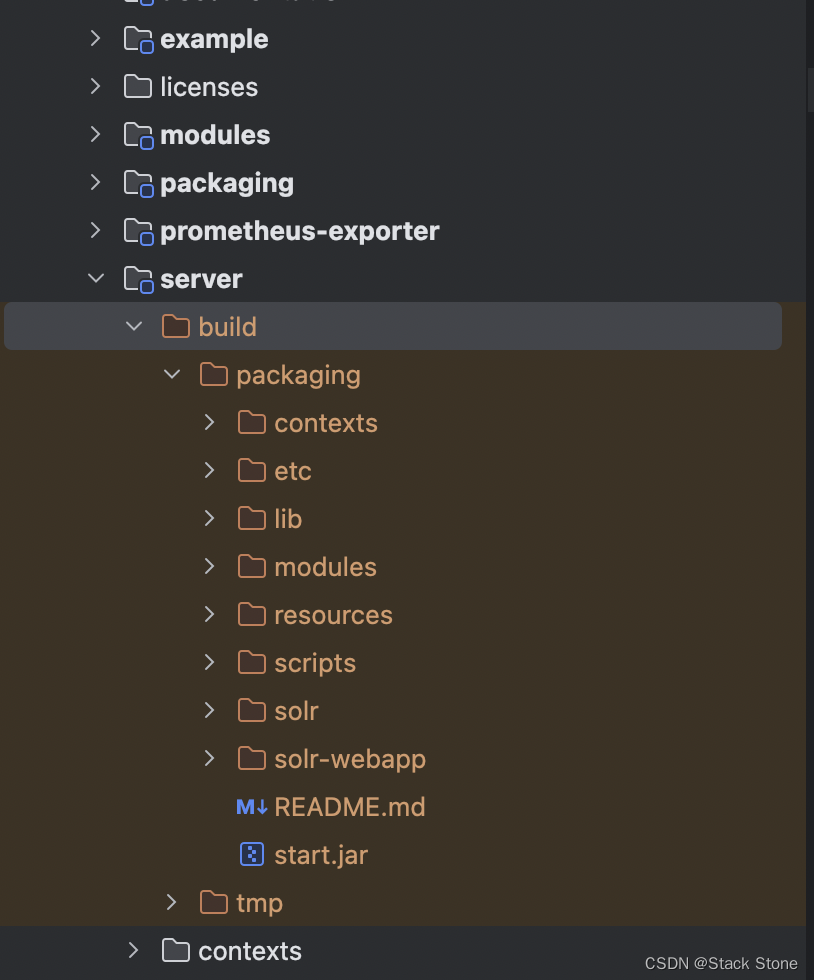
在项目中我们可以运行./gradlew dev构建 Solr 开发发行版,或者在 IDEA 中,在 gradle 面板运行,如下图所示:

运行成功后,会在solr/server/build目录下生成packaging目录,如下所示:
-
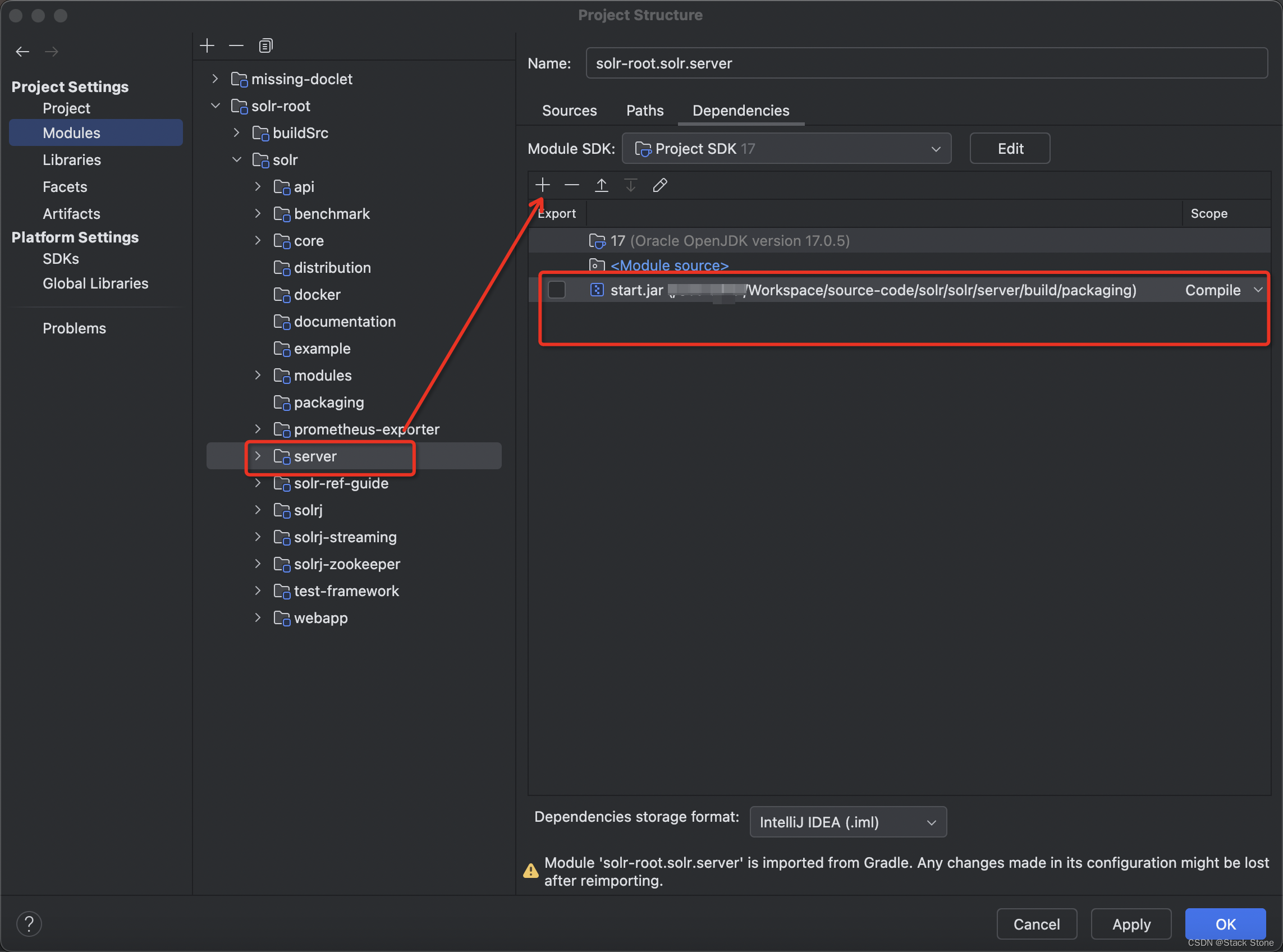
引入 start.jar 依赖项
上面打包后的目录可以看到有一个start.jarjar 包,打开项目结构,选择server模块,将这个 jar 包添加到依赖项中,如下所示:
-
新建 solrcloud 应用
在 IDEA 右上角,如下图所示:

选择Edit Configurations,之后添加一个Application如下所示:

按下图所示编辑应用:
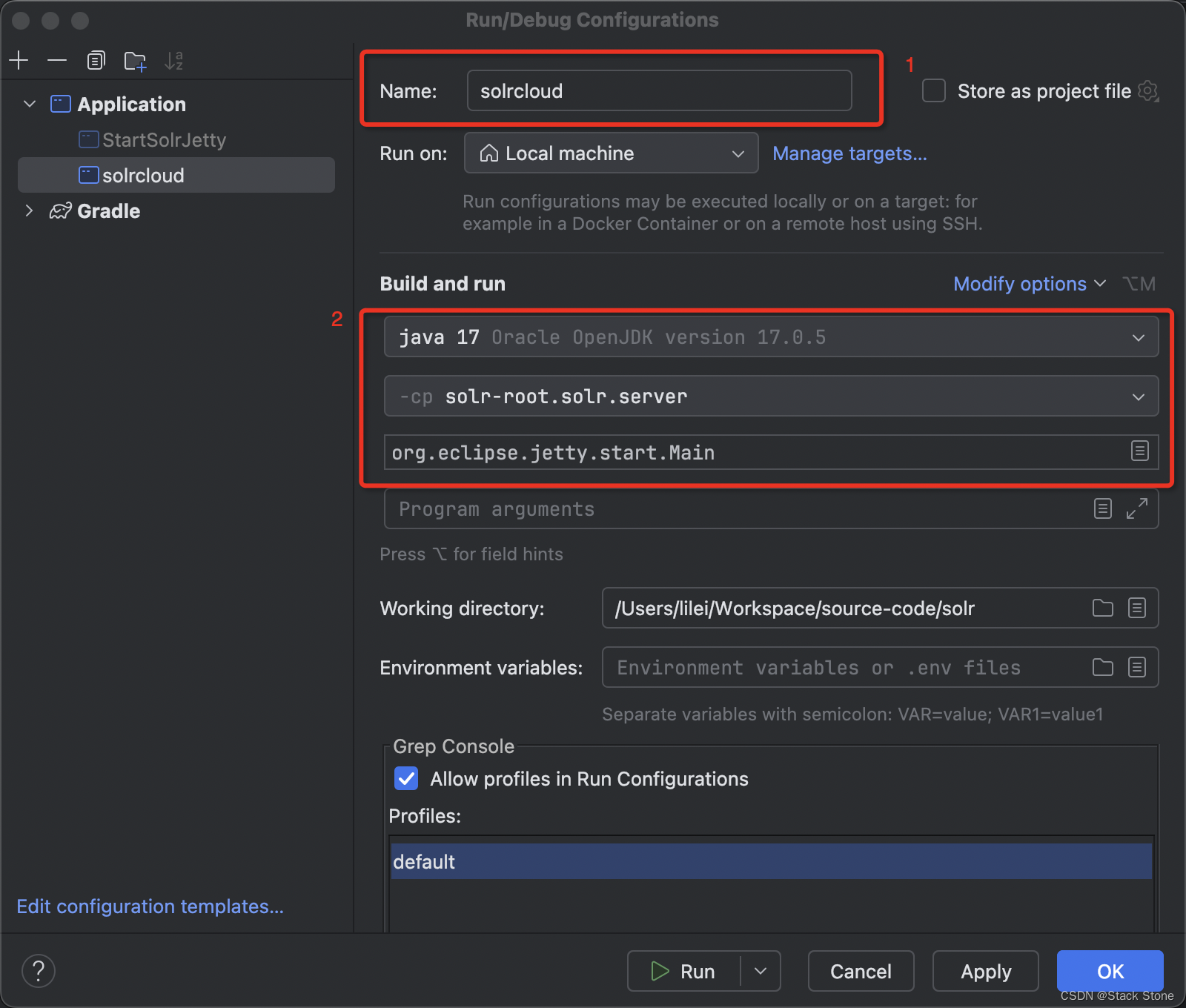
之后选择Modify options->Add VM options
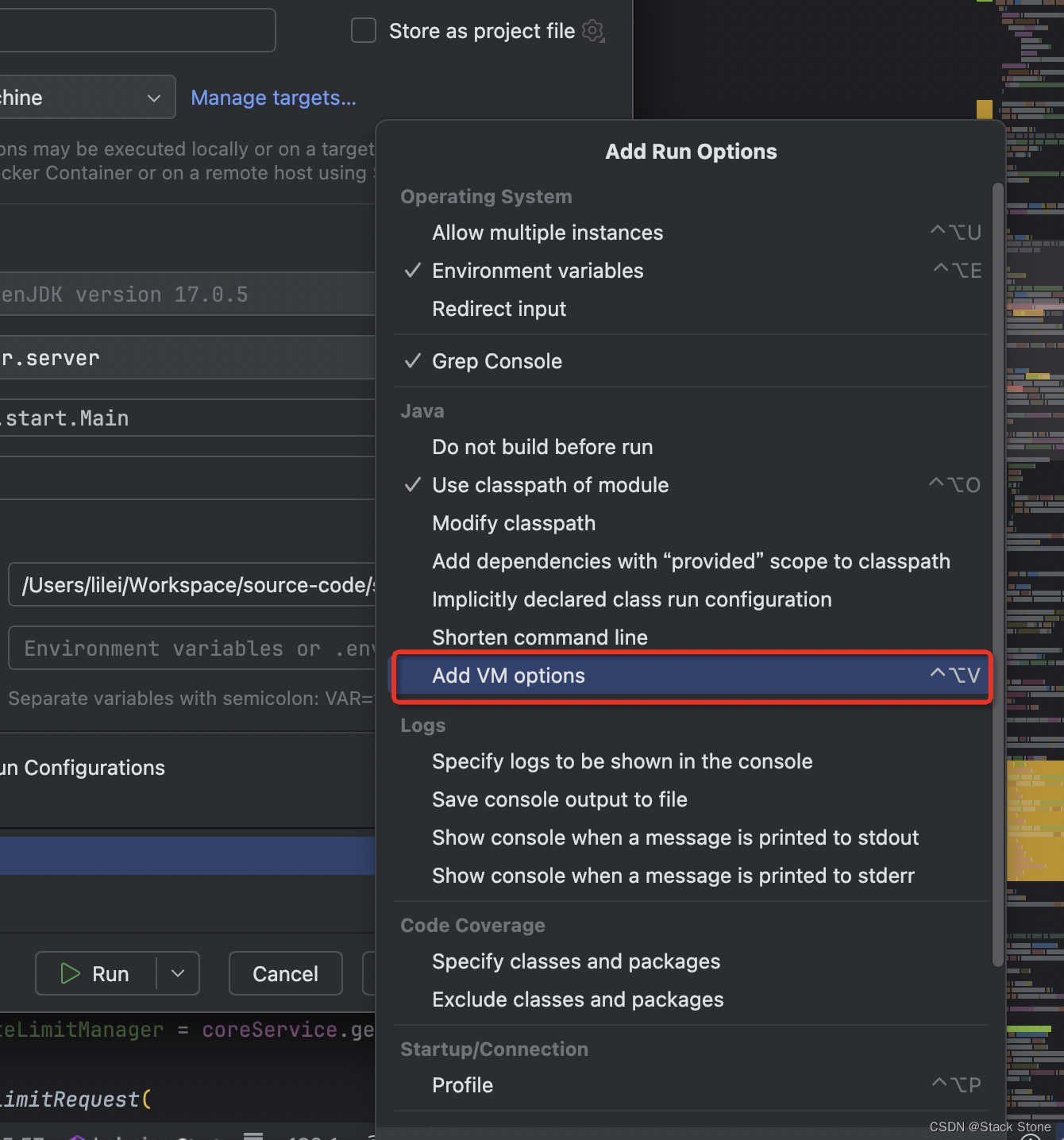
并在 VM options 中添加如下内容:-DzkHost=127.0.0.1:2181/solr9 -Dsolr.jetty.host=0.0.0.0 -Djetty.port=8983 -Duser.timezone=UTC -Djetty.home=/Workspace/source-code/solr/solr/server -Dsolr.solr.home=/Workspace/SolrHome/Solr9/SolrHome_1 -Dsolr.install.dir=/Workspace/source-code/solr/solr -Dsolr.log.dir=/Workspace/SolrHome/Solr9/logs/solr_1 -Dsolr.log=/Workspace/SolrHome/Solr9/logs/solr_1/solr.log -Dlog4j.configurationFile=file:/Workspace/source-code/solr/solr/server/resources/log4j2.xml注意上面启动参数的路径要改成你自己的,而且要确保你本地是有启动 ZooKeeper 的,上面启动项的含义如下:
启动项的详细解释:
- -DzkHost=127.0.0.1:2181/solr9
• 指定 Solr 连接到的 ZooKeeper 主机和端口。此属性对于 SolrCloud 模式是必需的,因为它协调集群状态。127.0.0.1:2181 表示 ZooKeeper 运行在本地机器的 2181 端口上,/solr9 是 Solr 使用的 ZooKeeper 的 chroot 路径,它将所有 Solr 相关的数据隔离在这个路径下。 - -Dsolr.jetty.host=0.0.0.0
• 设置 Jetty 服务器绑定的 IP 地址。使用 0.0.0.0 表示接受所有网络接口上的连接,使得任何远程机器都可以访问此 Solr 实例。 - -Djetty.port=8983
• 指定 Jetty 服务器监听的端口号。8983 是 Solr 默认的端口号。 - -Duser.timezone=UTC
• 设置运行 Solr 进程的时区为协调世界时(UTC)。这有助于确保时间的统一性,尤其是在多时区的环境中操作数据时。 - -Djetty.home=/Workspace/source-code/solr/solr/server
• 指定 Jetty 的安装目录。这是 Jetty 服务器寻找其配置文件和库文件的地方。 - -Dsolr.solr.home=/Workspace/SolrHome/Solr9/SolrHome_1
• 设置 Solr 的主目录(SolrHome),Solr 将从这个目录加载其配置文件、核心等信息。 - -Dsolr.install.dir=/Workspace/source-code/solr/solr
• 指定 Solr 的安装目录,Solr 会在这个目录下查找它的一些核心库文件。 - -Dsolr.log.dir=/Workspace/SolrHome/Solr9/logs/solr_1
• 设置 Solr 日志文件的存储目录。这是 Solr 存放日志文件的位置,有助于日志管理和故障排查。 - -Dsolr.log=/Workspace/SolrHome/Solr9/logs/solr_1/solr.log
• 设置 Solr 的日志文件路径。指定具体的日志文件名称和路径,通常用于定制日志文件的存储位置和命名。 - -Dlog4j.configurationFile=file:/Workspace/source-code/solr/solr/server/resources/log4j2.xml
• 指定 Log4j 2 的配置文件路径。这个文件定义了日志管理的配置,包括日志级别、输出格式和输出目的地等。
之后选择 Working directory 为 项目的
solr/server/build/packaging目录,如下所示:

填写Program arguments为--module=http,配置完毕如下所示:
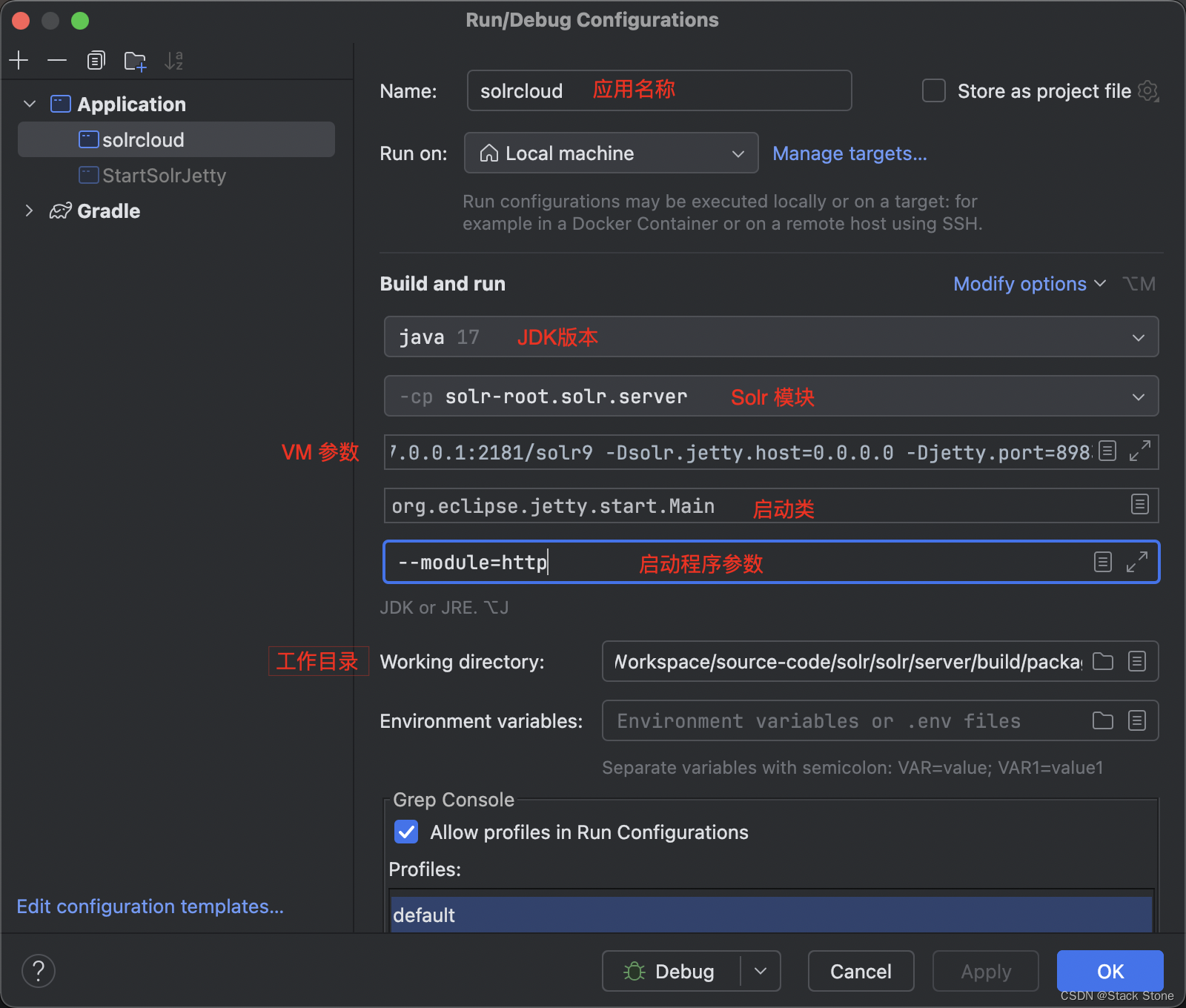
点击应用并确定。 - -DzkHost=127.0.0.1:2181/solr9
-
运行调试程序
如下所示以 Debug 方式运行

由于我本地启动了 ZooKeeper,solr9 路径如下:
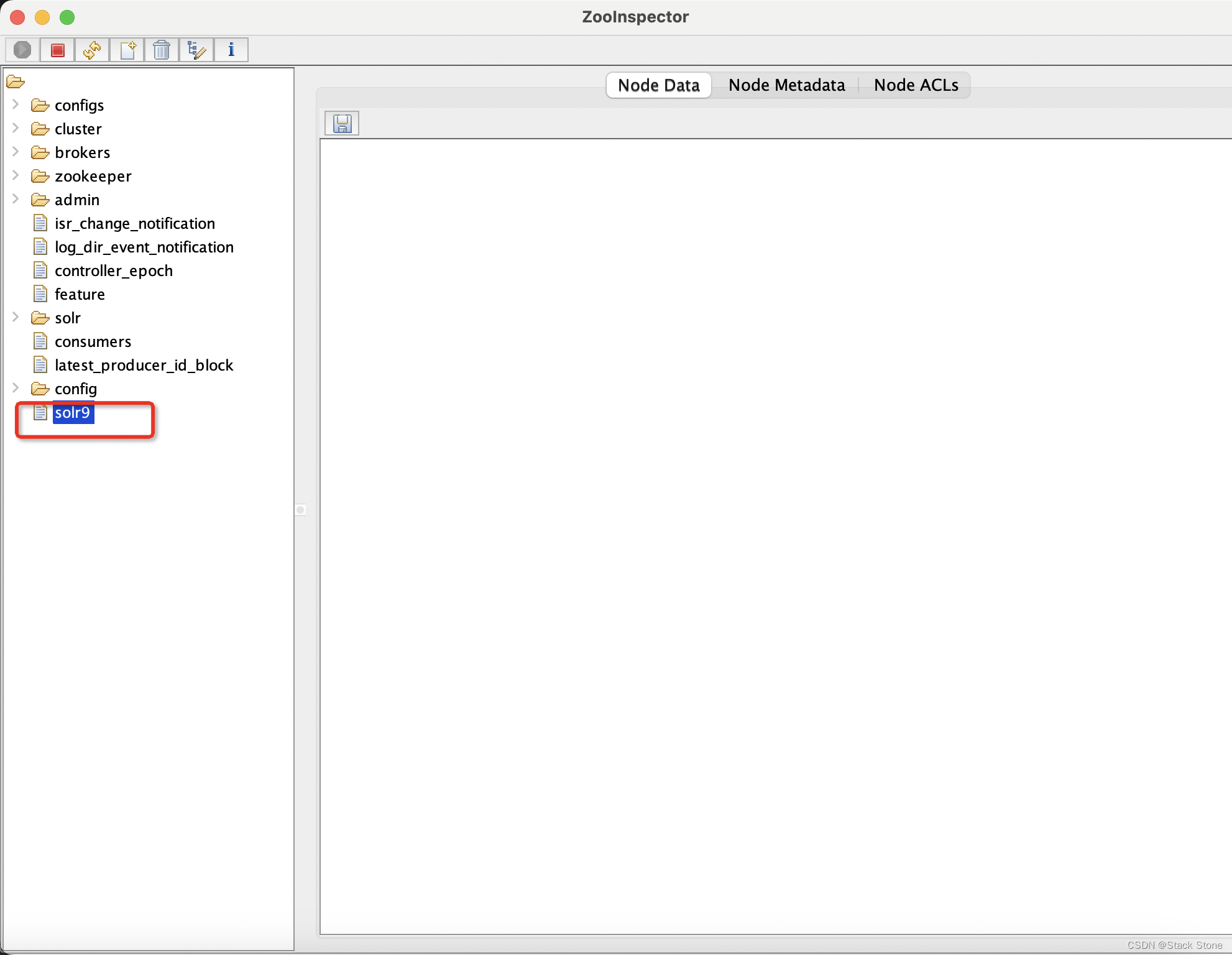
启动 solrcloud 后,会初始化一些配置到 ZooKeeper 中,如下所示:
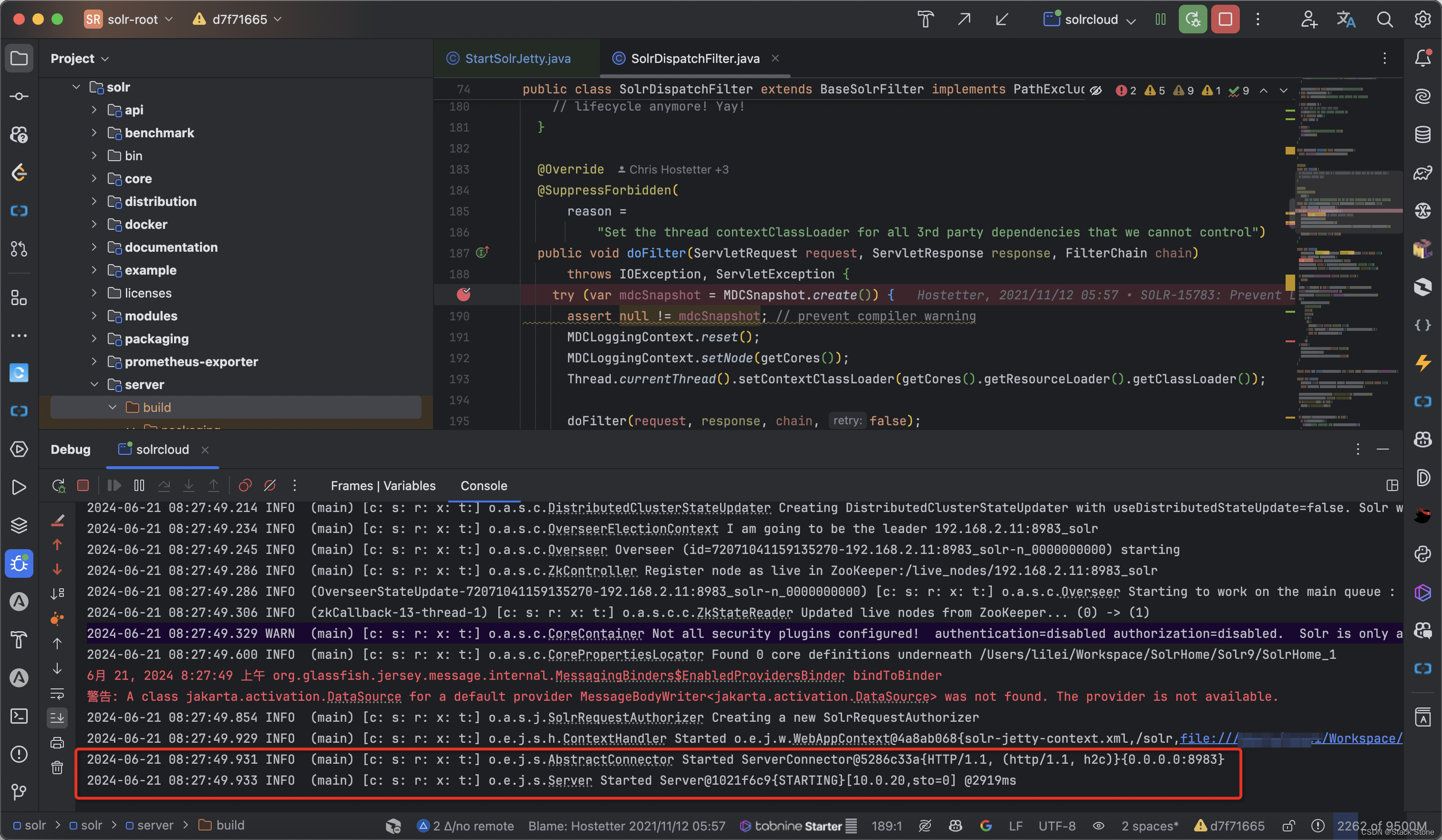
程序启动成功,同时:
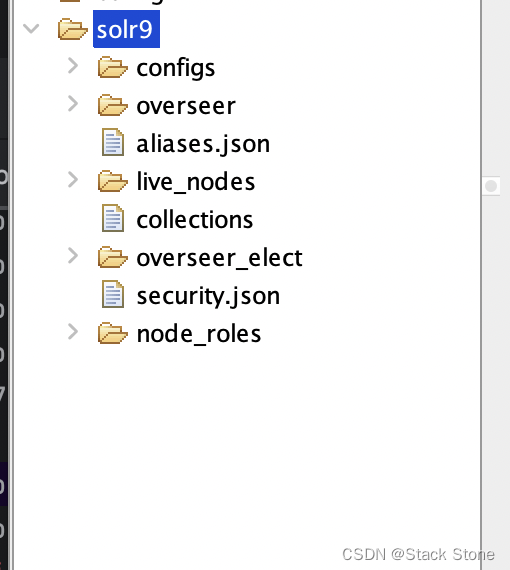
Zookeeper 节点写入了一些数据
访问 http://localhost:8983/solr 页面如下:
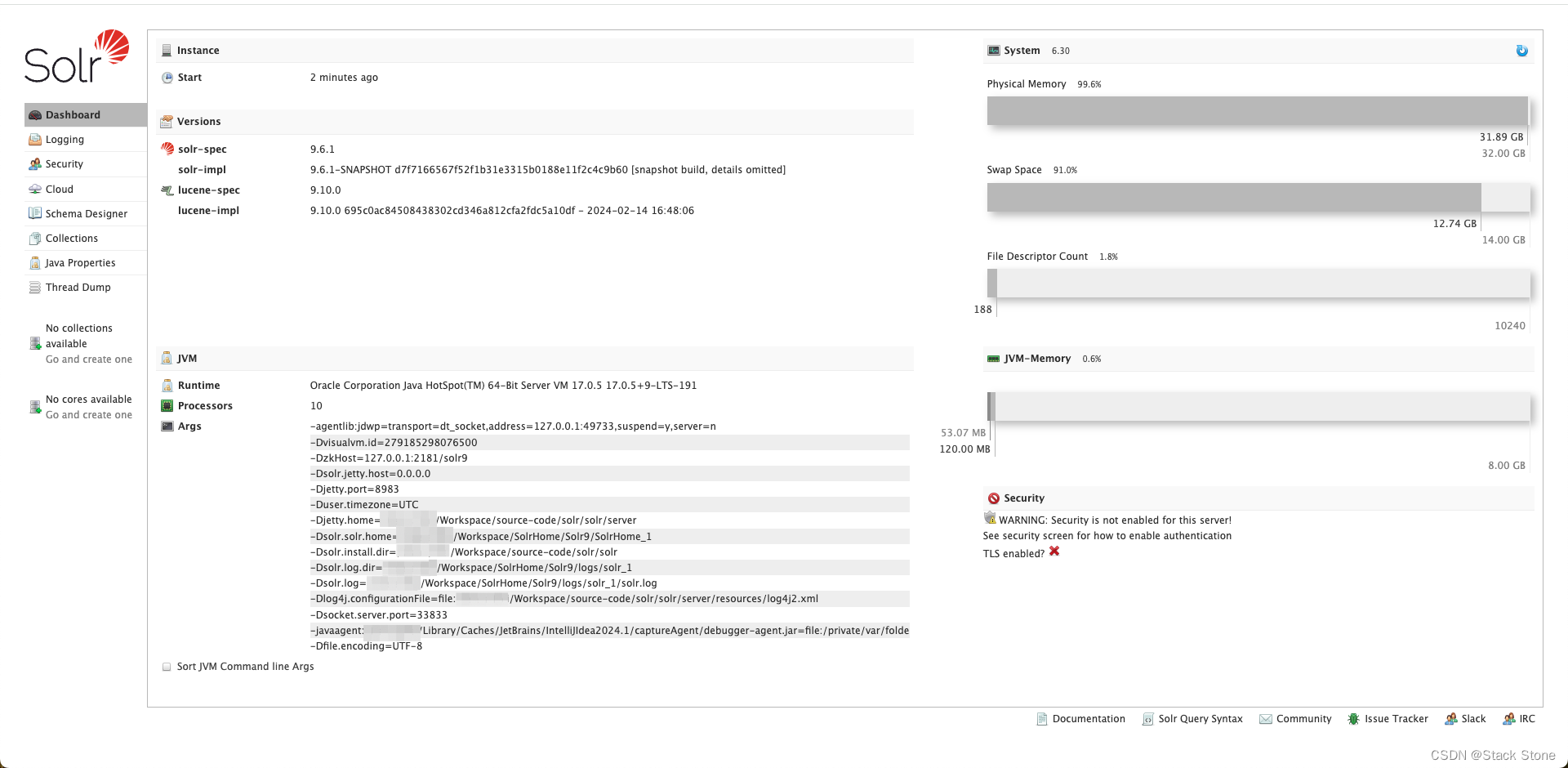
可以看到 SolrCloud 模式下页面有些许不同,当然我们也可以在SolrDispatchFilter中打断点,断点依旧会进来:
SolrCloud 模式下上传配置和创建 Collection
此时由于 Zookeeper 中没有 Collection 的配置所以此时我们只能创建 _default 配置的 Collection,此时我们可以运行 Solr 代码的 ZkCLI 的 main 方法把我们本地的 Collection 配置上传至 Zookeeper 中。
如下所示:
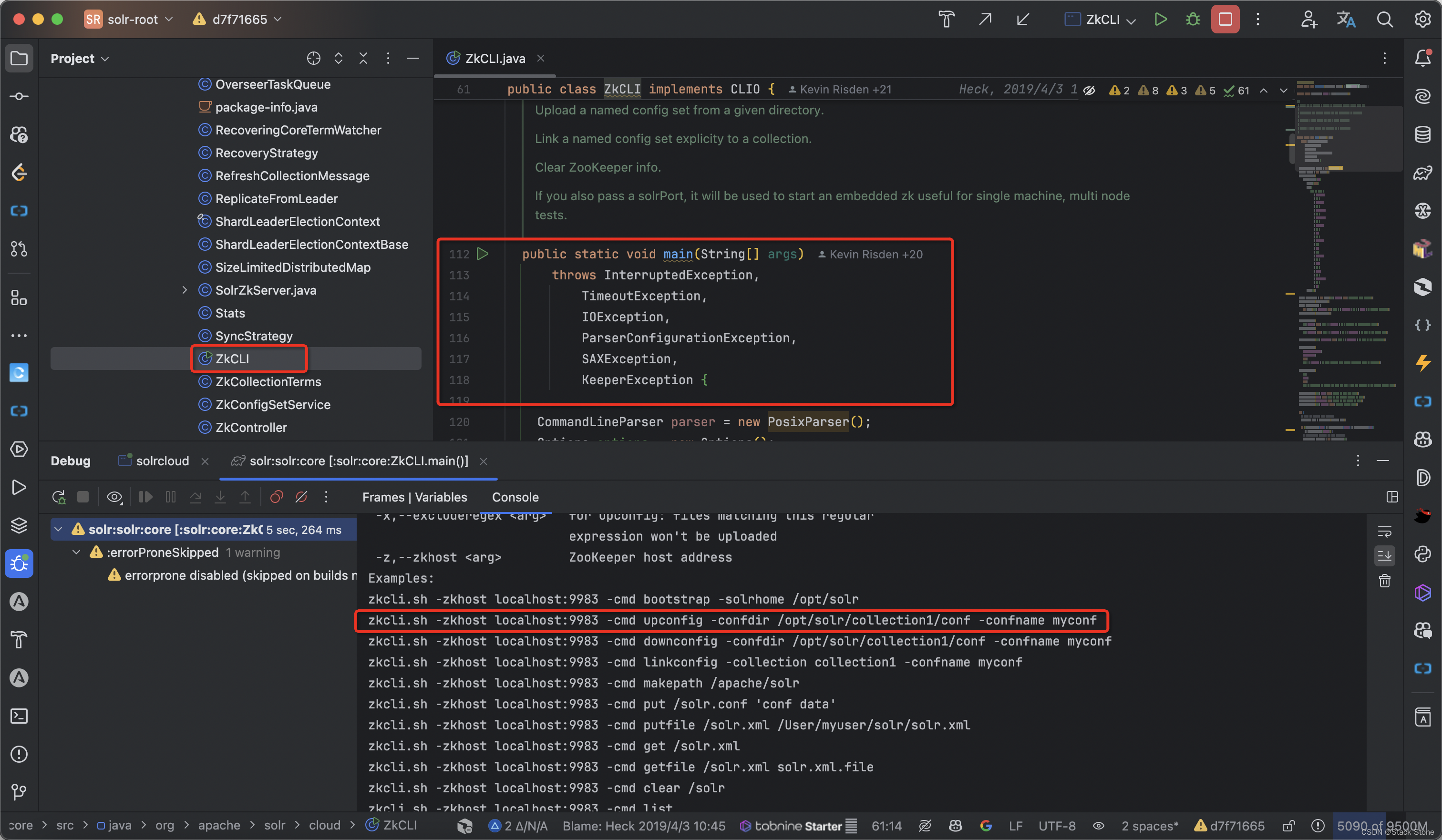
源码中我们找到 org.apache.solr.cloud.ZkCLI 这个类,运行 main 方法后,控制台会打印出使用帮助,由此可知如何上传配置,比如我本地有一个 MOVIE 的配置文件,如下所示:
这时,我们需要编辑 ZkCLI 的程序参数,在程序启动参数(Program Arguments)中填写如下内容:
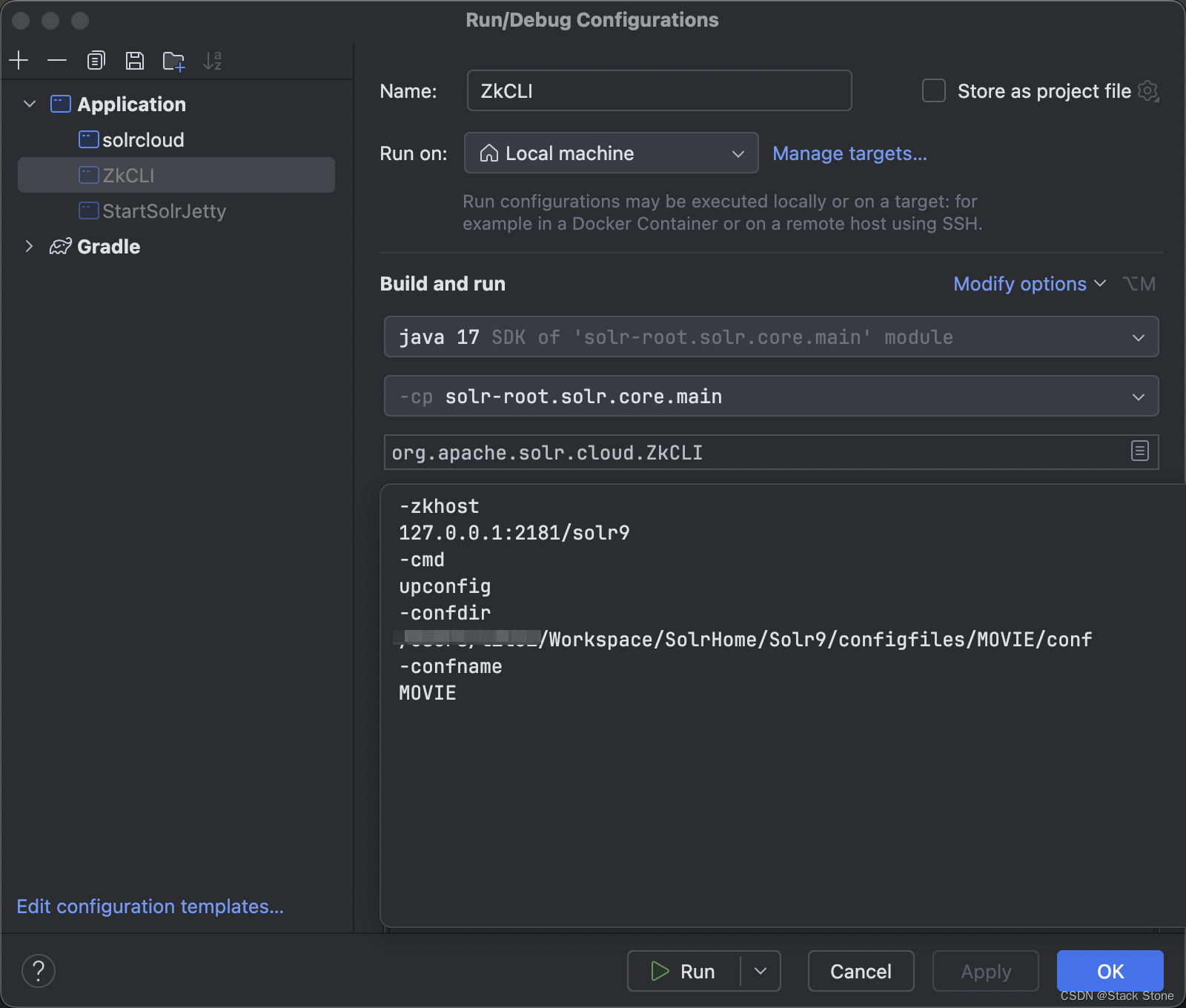
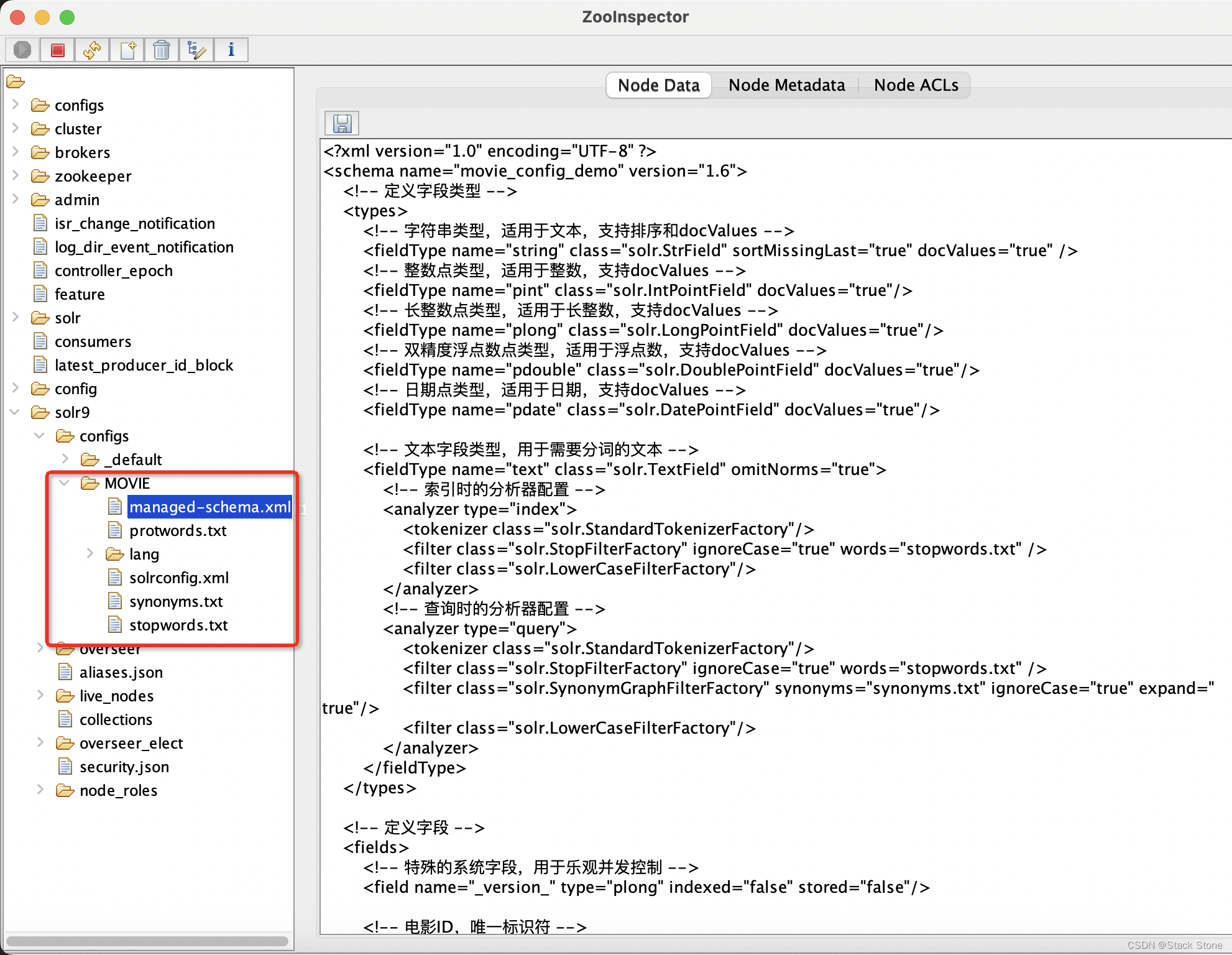
之后运行程序,访问 Zookeeper,如下所示,可以看到配置文件已上传到指定的 ZK 目录下
在创建 Collection 的页面上也可同时看到有了 MOVIE 的选项: