来自社区用户(SRE运维手记)投稿
背景
在云原生的时代背景下,Kubernetes 已经成为了主流选择。然而,Kubernetes 的原生操作复杂性和学习曲线较高,往往让很多团队在使用和管理上遇到挑战。因此,市面上出现了许多对 Kubernetes 进行封装和优化的工具,其中 KubeSphere 是一个集成了多种开源工具、提供全方位解决方案的企业级容器管理平台。
我们团队早期在持续集成和持续交付(CI/CD)、微服务治理、多租户管理和 DevOps 自动化方面就遇到了不少挑战,如 Jenkins 的权限管理短板、开发调试交互困难、多集群管理分散增加运维成本等。为了提升开发效率和运维质量,我们决定评估和引入一个适合的 Kubernetes 平台工具。经过调研和比较,我们最终选择了 KubeSphere。
选型说明
我们选择了 KubeSphere 3.3.2 版本,在选型过程中,我们主要考量了以下几个因素:
- 易用性:平台是否提供直观的用户界面和简单易懂的操作流程,能够降低学习成本。
- 功能完备性:平台是否集成了 CI/CD、监控、日志管理、微服务治理等功能,能够满足我们现有和未来的需求。
- 扩展性:平台是否支持插件机制,能够方便地集成第三方工具和服务。
- 社区活跃度:平台的社区是否活跃,是否有及时的技术支持和丰富的文档资源。
在对比了几款主流的 Kubernetes 平台工具后,我们发现 KubeSphere 在上述几个方面表现得都非常出色。尤其是在易用性和功能完备性方面,KubeSphere 提供了用户友好的界面和全方位的功能集成,能够显著降低我们的运维难度和学习成本。
实践过程
基础设施与部署架构
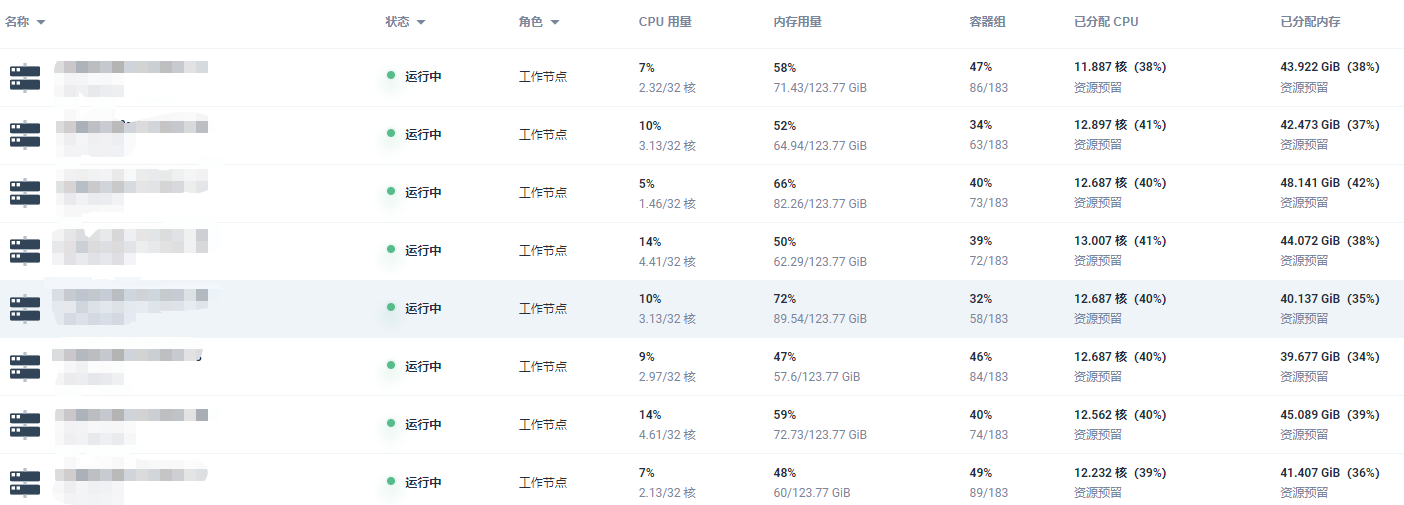
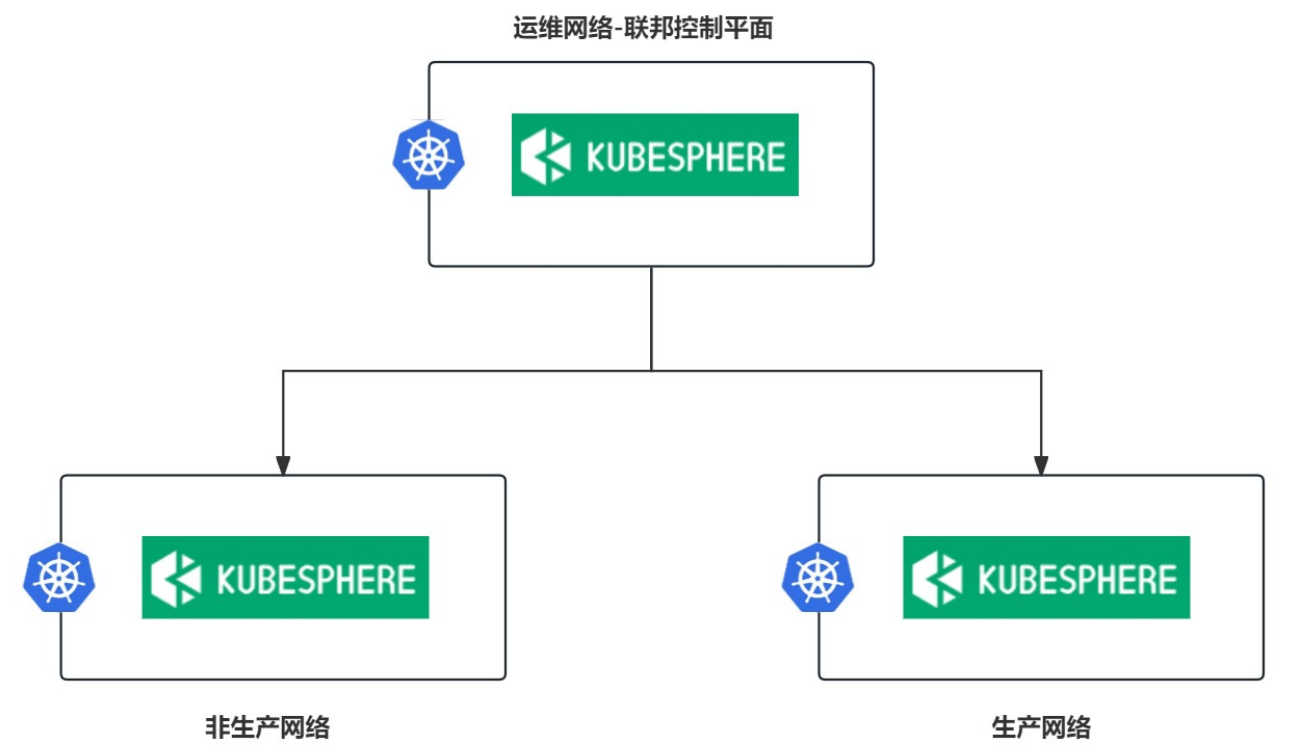
我们使用的是公有云环境,划分了 3 个 VPC,分别为非生产网络、生产网络,以及运维网络,其中非生产和生产网络隔离,而运维网络与其他网络打通,我们在运维网络中部署了运维中控平台用于管理这 3 个 VPC 的资源,KubeSphere 则借助其联邦模式,以运维网络的集群为主,其余网络的集群为成员,实现多集群管理,为了方便运维中控平台的管理,服务器推行了标准化,保障规格和配置的一致性,统一采用 32 核 128G 的配置,操作系统为 Centos7.9。
KubeSphere 集群节点界面截图:
部署架构示意图:
相关业务与 KubeSphere 的契合点
在选择和使用 KubeSphere 的过程中,我们发现它与我们现有的业务需求有着高度的契合,具体表现在以下几个方面:
持续集成与持续交付(CI/CD):我们的开发流程高度依赖于 CI/CD 流水线,以确保代码的快速构建、测试和部署。我们采用的是 Jenkins pipeline 的技术方案,恰好 KubeSphere 也集成了 Jenkins,支持 pipeline 的流水线发布,使我们能够快速迁移和集成现有的 CI/CD 流程。
可观测性和日志管理:KubeSphere 集成了 Prometheus、Grafana 和 EFK(Elasticsearch、Fluentd、Kibana)等工具 ,与我们在用的运维技术框架非常相似,也方便我们快速迁移。
易用性和用户体验:Kubernetes 的原生操作复杂性较高,而 KubeSphere 提供了直观的用户界面和简单易懂的操作流程,使得我们的开发和运维人员能够快速上手并高效使用。KubeSphere 的易用性大大降低了我们的学习成本,提升了团队的整体工作效率。
总的来说,KubeSphere 在多个方面与我们的业务需求高度契合,通过其全面的功能集成和优异的用户体验,显著提升了我们的开发和运维效率,确保了业务的持续稳定运行。
存储与网络
存储
因为是公有云环境,我们选择了阿里云 NAS 作为 K8s 集群的存储,走的是 NFS 协议,我们根据存储的性能(通用型和极速型)定义了两个 StorageClass,其中有状态应用使用的是极速型存储,延迟在 0.3ms 左右。另外还安装了 csi-provisioner 插件,赋予集群自动创建和删除卷的能力,提升运维效率。
网络
cni 插件用的是阿里云的 Terway 独占 ENI 模式,为每个 Pod 分配一个独立的 ENI 和 IP 地址,每个 Pod 都拥有自己的网络接口,并且网络性能更接近于传统虚拟机。
平台和应用的日志、监控、APM
日志
为了保持业务埋点数据采集流程不受影响,我们采用 Filebeat+Logstash+Elasticsearch+Kibana 的日志采集和分析方案,在 k8s 集群部署 filebeat deamonset 采集日志至外部 Logstash 集群,经过日志加工处理后存入 Elasticsearch 集群,Elasticsearch 集群采用冷热分层存储,最近 14 天的日志数据会被存储在热节点,超过 14 天的日志数据会被转移到冷节点。
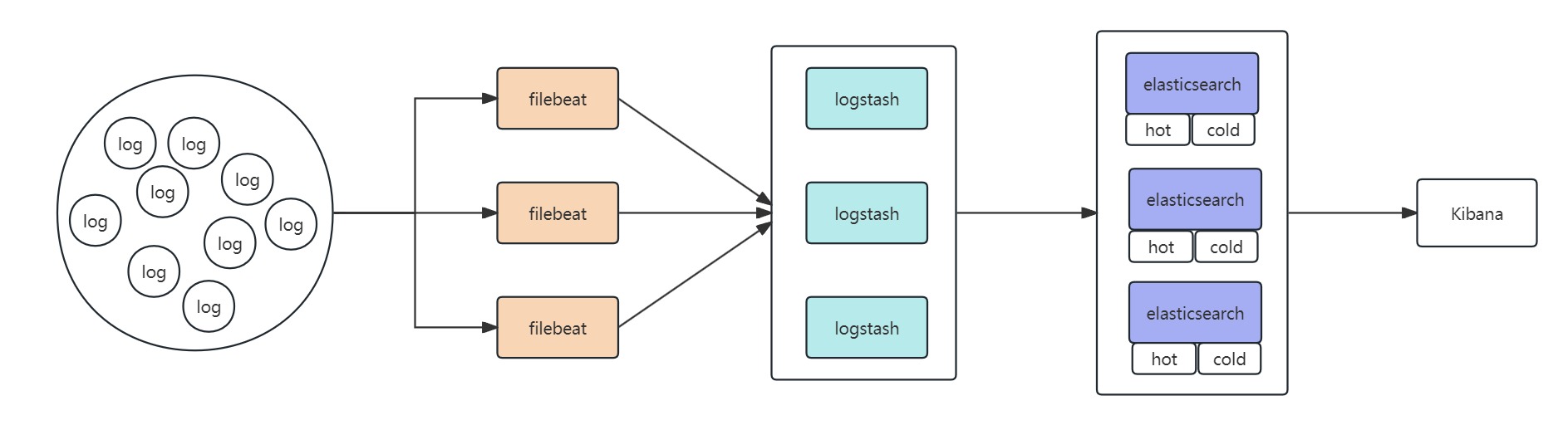
日志告警使用 elastalert2,根据自定义的规则实现日志告警,为了方便规则配置和管理,我们在运维平台开发了 elastalert2 可视化管理界面

监控
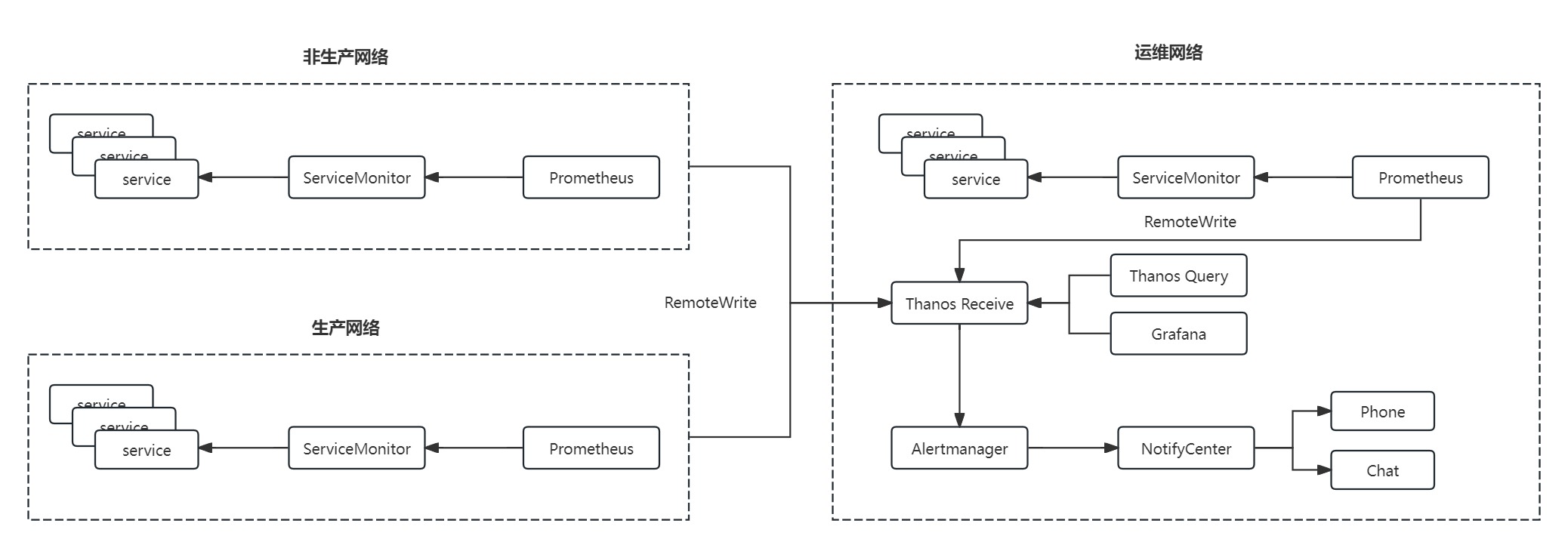
使用 KubeSphere 平台集成的 Prometheus-operator+Grafana,多集群采集的监控指标数据通过 RemoteWrite 的方式传给 Thanos-Receive,再由 Alertmanager 根据策略进行告警,告警的数据会经过我们自主开发的 NotifyCenter 进行数据格式化、告警分组等,最终推送到电话或者聊天会话。
APM
前端使用 Sentry,后端使用 Skywalking,二者之间通过 RequestId 进行打通实现全链路监控,用于异常定位和性能分析。
CI/CD
在 KubeSphere 中,我们通过集成 DevOps 流水线功能和 Jenkins Shared Libraries 提高了 pipeline 的可管理性和代码的可复用性。Shared Libraries 的引入有效地解决了我们以往流水线杂乱和难以管理的局面,使得 CI/CD 流程更加高效和一致。
此外,为了进一步统一和管理 Kubernetes 配置,我们采用了 Kustomize 来管理 K8s YAML 文件。Kustomize 允许我们通过不同的 overlay 轻松管理各种环境的配置差异,确保配置的一致性和可维护性。
这种整合使得我们在 KubeSphere 中只需创建一个简单而高效的流水线,Jenkinsfile 的复杂度也大大降低,示例如下:

有状态服务管理
我们已经将 Mysql、Redis、Clickhouse、Zookeeper、Etcd 等有状态服务部署到 K8s,使用有将近一年多,很是稳定,同时也避免了传统服务器部署的单点隐患。
使用效果
使用效果主要总结为以下五点:
- 稳定可靠:KubeSphere 在使用过程中表现出极高的稳定性,未出现任何异常。
- 效率提升:KubeSphere 的自动化部署和流水线管理功能显著提升了开发和运维效率。通过集成 CI/CD 流程,减少了手动操作和人为错误,加快了代码发布和部署速度。
- 用户体验:KubeSphere 的直观用户界面简化了操作,降低了学习曲线。统一的管理平台使团队成员能够更高效地进行日常运维和监控管理,提升了整体工作体验。
- 安全管理:KubeSphere 提供了细粒度的权限控制和全面的审计日志功能,增强了系统的安全性。通过统一的安全策略管理,我们能够更好地保护敏感数据和关键应用。
- 降低成本:通过 KubeSphere 的便捷可视化管理,运维可以将部分工作实现开发人员自助化管理,有效降低了运维成本。
未来规划
随着 AI 智能领域的崛起,出现了不少优秀的 AI Agent,也让我们不得不去思考和探索 AIOPS,我们希望未来的运维场景可以跟 AI 有更多的结合,如故障分析、告警自愈和预测分析等等,同时也希望 KubeSphere 有 AI 功能的出现,相信未来的运维会更加精彩。
本文由博客一文多发平台 OpenWrite 发布!