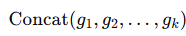文章目录
- 实验结果
- 实现思路
- 思路1
- 思路2
- 进程与线程介绍
- 如何实现
- multiprocessing、Pipe的范例
- 关于时间对比上的问题
- 代码修改
- 收敛为何不稳定
- 技巧
- 进程资源抢占问题
- 线程问题
- cpu和gpu问题
- 进阶(还没看懂/还没实验)
- 附代码
- raw代码
- mul代码
实验结果
实验平台:cpu:i7-10870 8核16线程(intel处理器采用超线程技术,一个核心有两个线程,故物理上是8核,逻辑核心是16核)
pytorch 版本:2.2.2+cu121
numpy 版本:1.24.3
gym 版本:0.26.2
模块:
from torch.multiprocessing import Process, Pipe #这两个结果一致,第一种继承了第二个使得可以应用在GPU上
#from multiprocessing import Process, Pipe
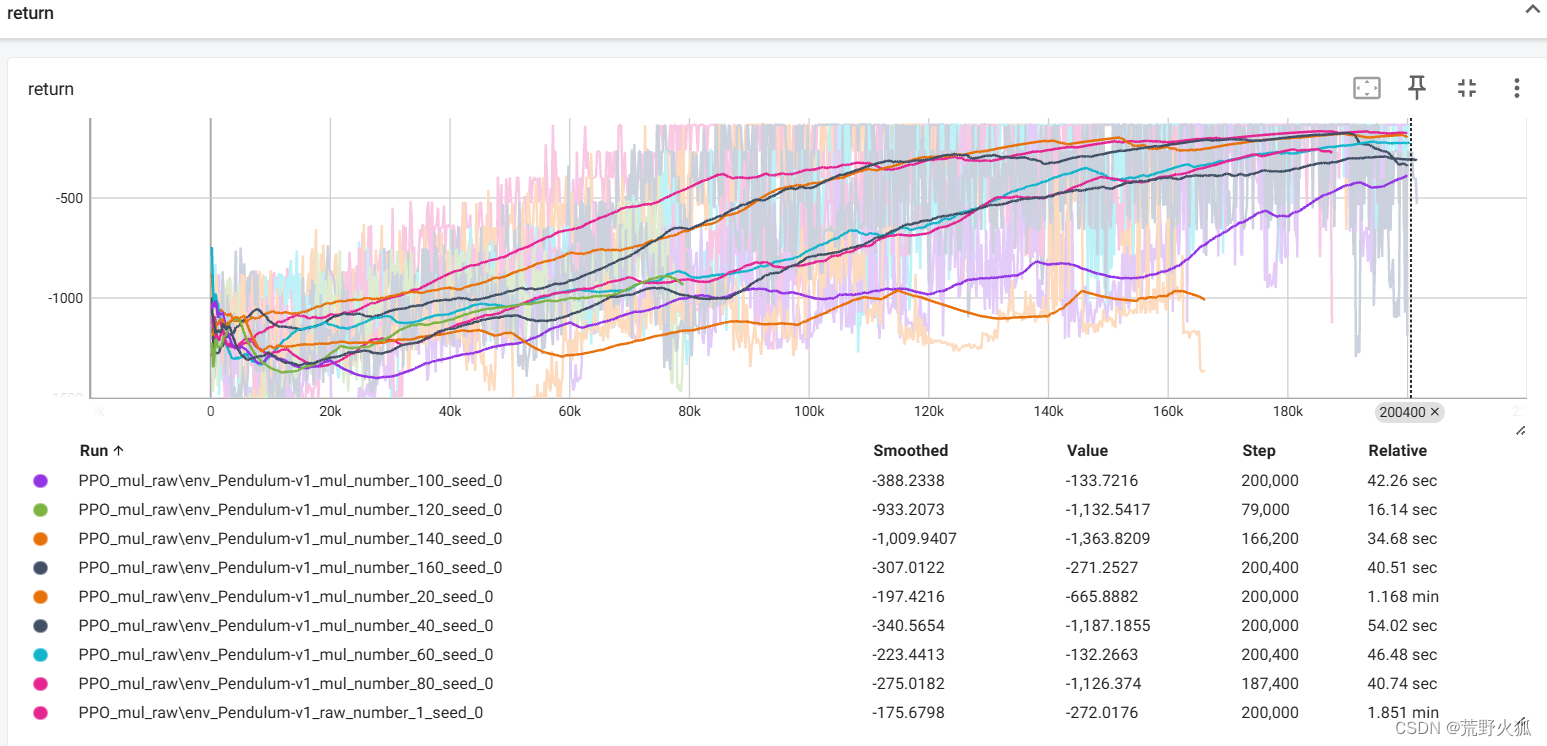
最后一行为 未使用多进程加速的原始代码。前面几行的进程数为 number/10。
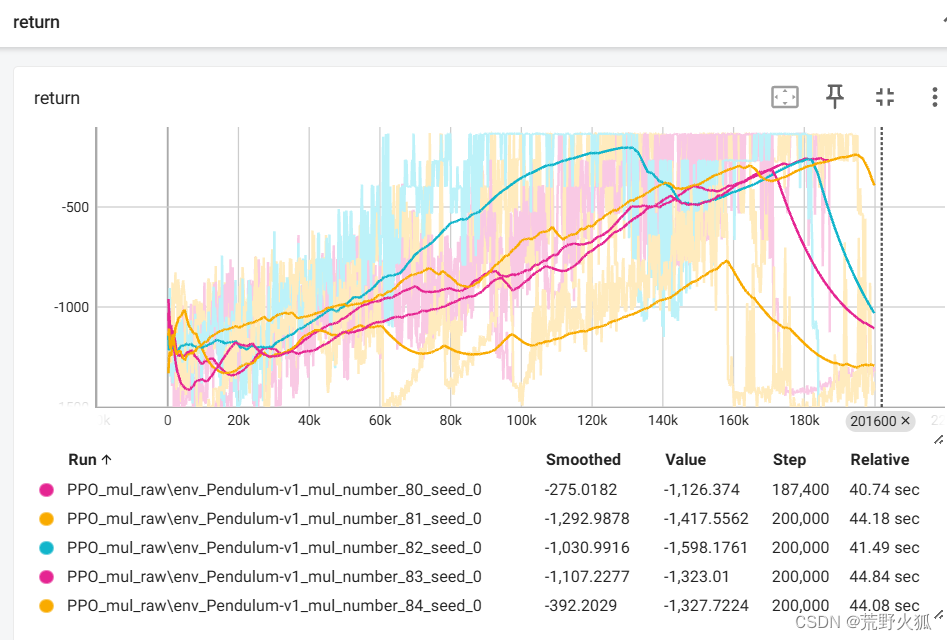
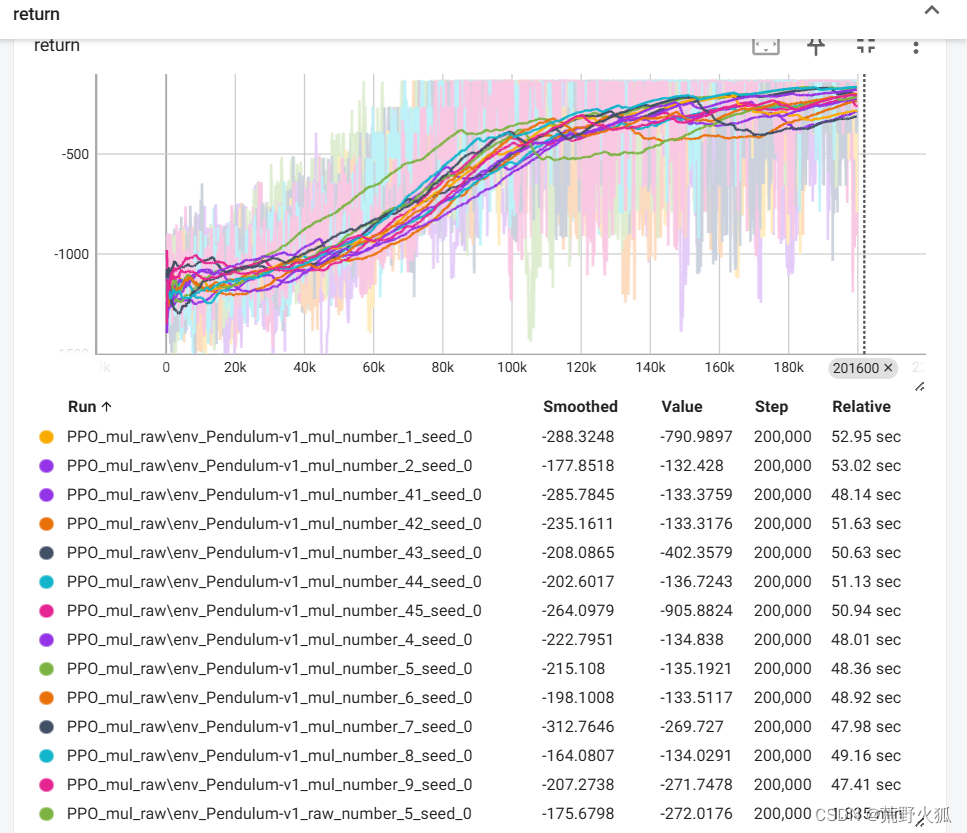
实验结果表明:进程数为cpu物理核心数一半的时候最佳,我是8核,这里实验结果也是4进程的最佳,快了两倍,不过二进程的可能更稳定点,快了1.6倍。其他进程数就不稳定了。
推荐进程数为:物理核心数的一半
以下为8进程时 不稳定展示:
以下为4进程时 稳定性展示:
参考:
1、github代码(参考并修改了这里代码)
2、DPPO深度强化学习算法实现思路(分布式多进程加速)(这里参考了思路2)
3、在Python中优雅地用多进程(->1、这里说明使用Pipe技术运行更快,2、默认为multiprocessing.set_start_method('spawn')好)
4、pytorch模型在multiprocessing下前馈速度明显降低的原因是什么?(->解决了进程中资源抢占的问题)
实现思路
思路1
对于参考2的实现思路1,我感觉作者只是在训练过程中,用了多个进程训练,并在训练后取了平均,也就是说本来是由一个进程训练,现在是多个进程同时训练,两者都在同一个时间线内,并没有起到加速效果,可以说只是起到了平稳训练的作用。(以下为参考2的作者思路1)

在作者的后续实验也表明,确实是这样的效果

其作者的本来想法,我猜测意思是:在训练的时候利用多进程加速。但是训练的时候用的是同一个网络,无法做到在更新完这个网络的同时发送这个网络给训练前的时间点。于是作废。
思路2
这里的实现思路和这里的参考2的思路2本质上是一样的,也是常见的一种思路。
即,在环境采样中使用多进程采样,在训练中单进程更新(训练)。
比方说,在同一时间线内,4个进程同时采样,这样就是同样的时间采样了4条episode,然后在更新时依旧是单条更新。也就是说更新的次数不变,时间不变,且采样次数不变,但采样时间减少了4倍。(由于更新的时间没有减少4倍,所以理论上比原先的速度快1-4倍)
也可以叫做DPPO,D为distributed,分布式的意思,也意为这里的分布式采样。
类似的思想如:A3C
进程与线程介绍
进程:相当于电脑多开了很多应用。
线程:相当于一个应用里,比方说:一个网页浏览器里有一个线程负责渲染页面,另一个线程负责处理用户输入,还有一个线程负责下载文件。这些线程在同一个进程内协作,共同完成浏览器的功能。

比方说上图的VScode是32进程,

这里显示每个进程里有多少个线程,如上图第一个code进程有32个线程。(设置方法见:任务管理器查看线程数、PID值等方法)
了解到此,我们可以了解到上述线程和平时电脑上所说的8核16线程中的线程所区分开,第二个线程说的可以看作逻辑核心数。
实际效果:我这里开了4个进程。看下面python.exe,上面4个为子进程均有34个线程,第5个为主进程,有45个线程。

而原始单进程的话,只有一个进程,这也就解释了为什么多进程会比单进程快的原因。(上述PID = Process ID 进程标识)
如何实现
multiprocessing、Pipe的范例
创建一个子进程、一个管道
## study multiprocessing pipefrom torch.multiprocessing import Process, Pipe
#from multiprocessing import Process, Pipe
import numpy as np
def f(conn):conn.send([42, None, 'hello']) # 子管道发送数据conn.close()if __name__ == '__main__':parent_conn, child_conn = Pipe() # 创建一个管道(双向通信)p = Process(target=f, args=(child_conn,)) # 创建一个子进程 进程函数为fp.start() # 子进程开始print(parent_conn.recv()) #父管道接收 p.join() # 等待子进程结束
'''
[42, None, 'hello']
'''
创建多个子进程、多个管道
from torch.multiprocessing import Process, Pipe
import numpy as npdef f(conn, i):conn.send([42 + i, None, f'hello from process {i}']) # 子管道发送数据conn.close()if __name__ == '__main__':num_processes = 3 # 创建3个进程# 使用列表推导式创建管道和进程parent_conns, child_conns = zip(*[Pipe() for _ in range(num_processes)])processes = [Process(target=f, args=(child_conn, i)) for i, child_conn in enumerate(child_conns)]# 启动所有进程[p.start() for p in processes]# 接收来自所有子进程的数据[print(parent_conn.recv()) for parent_conn in parent_conns]# 等待所有进程结束[p.join() for p in processes]
'''
[42, None, 'hello from process 0']
[43, None, 'hello from process 1']
[44, None, 'hello from process 2']
'''
关于时间对比上的问题
在作者2或者其他部分github上的代码(如下文中的fast-ppo),对比的是在同一个episode下(同一时间下)对比收敛程度,而多进程的收敛太具有不稳定性,(我也完全可以堆一个40进程且某次效果表现良好的一次作为实验对比对象,并且可以吹嘘说比原始的快了近30倍),且如此对比没有显示的对比真实时间。
究其原因,实际是多进程在一个episode时,采样了4条episode,并更新了4次,所以在单个episode时,自然收敛的更快,类似于下图这种形式。

于是采用以环境采样的step为横坐标(现大多库里也都这么写了),看运行同样步数下所需要的时间。
此步数为原始代码中收敛所需要的步数,这样可以把收敛的程度控制,也能显示的对比时间。
这里用了tensorboard来展示训练过程,tensorboard原本也是step为横坐标,这样更贴合
from torch.utils.tensorboard import SummaryWriter
# Build a tensorboard
writer = SummaryWriter(log_dir='runs/PPO_mul_raw/env_{}_raw_number_{}_seed_{}'.format(env_name, number, seed)) #存的位置
writer.add_scalar('return', episode_return, total_steps) #存的数据
终端启动
tensorboard --logdir runs #runs为文件夹名字
代码修改
修改主要部分为训练部分
以下面代码为例
raw代码
def train_on_policy_agent(env, agent, max_train_steps,number,seed):return_list = []# Build a tensorboardwriter = SummaryWriter(log_dir='runs/PPO_mul_raw/env_{}_raw_number_{}_seed_{}'.format(env_name, number, seed))total_steps = 0 while total_steps < max_train_steps: episode_return = 0transition_dict = {'states': [], 'actions': [], 'next_states': [], 'rewards': [], 'dones': []}state = env.reset(seed =0)[0] #1.改 gym 0.26.0版本后,env.reset()返回的是一个字典,所以需要加上[0]done = Falsewhile not done:#action = agent.take_action(state) #action 这里是[-2,2]的动作 action = agent.take_action(state) # forward 无2 这里是[-1,1]的动作next_state, reward,terminated, truncated, _ = env.step([action[0]*2]) done = terminated or truncatedtransition_dict['states'].append(state)transition_dict['actions'].append(action)transition_dict['next_states'].append(next_state)transition_dict['rewards'].append(reward)transition_dict['dones'].append(done)state = next_stateepisode_return += rewardtotal_steps += 1return_list.append(episode_return)agent.update(transition_dict)writer.add_scalar('return', episode_return, total_steps)return return_listactor_lr = 1e-4
critic_lr = 5e-3#1e-1#5e-3
num_episodes = 1000
max_train_steps = 2e5 #1000*200
hidden_dim = 128
gamma = 0.9
lmbda = 0.9
epochs = 10
eps = 0.2
#device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
device = torch.device("cpu")
env_name = 'Pendulum-v1'
env = gym.make(env_name)
#env.seed(0)
torch.manual_seed(0)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0] # 连续动作空间agent = PPOContinuous(state_dim, hidden_dim, action_dim, actor_lr, critic_lr,lmbda, epochs, eps, gamma, device)return_list = train_on_policy_agent(env, agent, max_train_steps,number=5,seed=0)
修改为如下:episode 原本为1000,由于环境的最大长度为200,所以步数为200*1000步,即2e5步
思想:
1.新增一个子进程函数:为每个子进程都创建一个环境用来采样步数
2.利用管道技术:在主进程中每次环境采样前传入已更新的网络->在子进程中接收网络并传出episode数据->在主进程中利用episode数据更新网络->回到第一步,直到达到最大步数。
3.利用多进程:在初始位置新增多个子进程,多个管道(两者数目一致),RL开始前子进程开始,RL结束后子进程强制结束。(因为子进程一制开着,得强制结束)
以下代码中: ### 为新增 ## 为4个注意点
###
def child_process(conn, env_name):env = gym.make(env_name)while True:agent = conn.recv() ## 1.这个位置,先传入agenttransition_dict = {'states': [], 'actions': [], 'next_states': [], 'rewards': [], 'dones': []}episode_return = 0episode_steps =0state = env.reset(seed=0)[0]done = Falsewhile not done:action = agent.take_action(state)next_state, reward, terminated, truncated, _ = env.step([action[0] * 2])done = terminated or truncatedtransition_dict['states'].append(state)transition_dict['actions'].append(action)transition_dict['next_states'].append(next_state)transition_dict['rewards'].append(reward)transition_dict['dones'].append(done)state = next_state ## 2.先append再赋值episode_return += rewardepisode_steps +=1conn.send((transition_dict, episode_return, episode_steps))
###
def main():actor_lr = 1e-4critic_lr = 5e-3num_episodes = 200hidden_dim = 128gamma = 0.9lmbda = 0.9epochs = 10eps = 0.2device = torch.device("cpu")env_name = 'Pendulum-v1'env = gym.make(env_name)torch.manual_seed(0)state_dim = env.observation_space.shape[0]action_dim = env.action_space.shape[0]# Build a tensorboardnumber = 45 #5seed = 0writer = SummaryWriter(log_dir='runs/PPO_mul_raw/env_{}_mul_number_{}_seed_{}'.format(env_name, number, seed))agent = PPOContinuous(state_dim, hidden_dim, action_dim, actor_lr, critic_lr, lmbda, epochs, eps, gamma, device)###process_num = 4 ##pipe_dict = dict((i, (pipe1, pipe2)) for i in range(process_num) for pipe1, pipe2 in (Pipe(),)) pipe_dict = {i: Pipe() for i in range(process_num)} #Pipe()返回一个元组: (conn1, conn2) #与上行相同child_process_list = [Process(target=child_process, args=(pipe_dict[i][1], env_name)) for i in range(process_num)]total_steps = 0max_train_steps = 2e5 [p.start() for p in child_process_list]###return_list = []while total_steps < max_train_steps:episode_return = 0[pipe_dict[j][0].send(agent) for j in range(process_num)] ##3.先传入agentfor j in range(process_num): ##4. i,j区分transition_dict, episode_return_,episode_steps = pipe_dict[j][0].recv()agent.update(transition_dict)total_steps += episode_stepswriter.add_scalar('return', episode_return_, total_steps)return_list.append(episode_return_)[p.terminate() for p in child_process_list] #child 用了while True,所以要terminatereturn return_list #单位为episodeif __name__ == '__main__':main()
收敛为何不稳定
管道的传输顺序是固定的,那么收敛不稳定可能是进程导致的,因为进程在同一时刻采样,由于每次采样时智能体的动作实际是不同的,导致最后结果的不同。即使设置了 torch.manual_seed(0),我们不能顺序执行完一个episode的随机种子的同时,将下一个随机种子数发送到另外一个进程的开始时间。顺序上不允许,时间上不允许
(即使设置进程按照进程优先级执行进程也无法实现。)
技巧
进程资源抢占问题
pytorch模型在multiprocessing下前馈速度明显降低的原因是什么?(->解决了进程中资源抢占的问题)
# 设置OMP_WAIT_POLICY为PASSIVE,让等待的线程不消耗CPU资源 #确保在pytorch前设置
os.environ['OMP_WAIT_POLICY'] = 'PASSIVE' #
import torch
设置如上操作时,1、2为设置前,6,7为设置后。
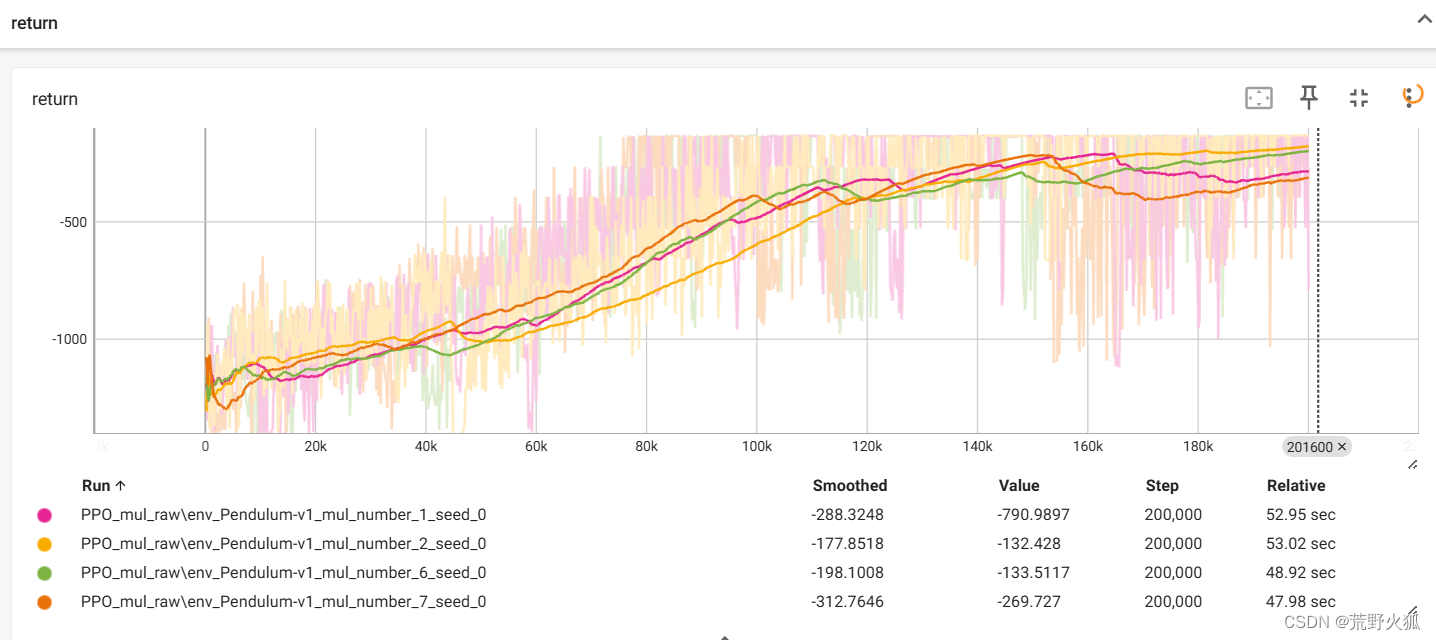
时间快了5s左右且在任务管理器中,cpu的占用也从97%占用降低到了28%左右


线程问题
参考: pytorch官方
根据此和实践实验下,不设置时(线程数为物理核心数)效果最佳。
设置方法1
import os
os.environ['OMP_NUM_THREADS'] = str(8) #默认物理核心数 #我这里是8
设置方法2
torch.set_num_threads(8)
mp中的cpu数和默认线程数查看
#import torch.multiprocessing as mp
import torch
import multiprocessing as mp
num_cpu = int(mp.cpu_count())
print('num_cpu:',num_cpu)
print(torch.get_num_threads())
'''
num_cpu: 16
8
'''
cpu和gpu问题
关于大多数github上代码以及上面作者提到的利用cpu采样、gpu训练加速的技巧,
改法和实现我写在【深度强化学习】如何平衡cpu和gpu来加快训练速度(实录)这里
进阶(还没看懂/还没实验)
并行环境让采样速度快两个量级:Isaac Gym提速强化学习 (利用异步?Envpool)
fast-ppo(利用每个核心的超线程技术?[env1,env2,env3,env4]->[[env1,env2],[env1,env2]])
深度强化学习库的设计思想(还没写完)(双-CPU群-单-GPU?)
附代码
raw代码
import gym
import os
# 设置OMP_WAIT_POLICY为PASSIVE,让等待的线程不消耗CPU资源
os.environ['OMP_WAIT_POLICY'] = 'PASSIVE'
import torch
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
import rl_utils
import timefrom torch.utils.tensorboard import SummaryWriter ##1.TBdef compute_advantage(gamma, lmbda, td_delta):td_delta = td_delta.detach().numpy()advantage_list = []advantage = 0.0for delta in td_delta[::-1]:advantage = gamma * lmbda * advantage + deltaadvantage_list.append(advantage)advantage_list.reverse()return torch.tensor(np.array(advantage_list), dtype=torch.float)class PolicyNetContinuous(torch.nn.Module):def __init__(self, state_dim, hidden_dim, action_dim):super(PolicyNetContinuous, self).__init__()self.fc1 = torch.nn.Linear(state_dim, hidden_dim)self.fc_mu = torch.nn.Linear(hidden_dim, action_dim) # 均值 #虽然步骤一样,但里面的权重和偏置不一样self.fc_std = torch.nn.Linear(hidden_dim, action_dim) # 方差def forward(self, x):x = F.relu(self.fc1(x)) # 激活函数mu = torch.tanh(self.fc_mu(x)) #从[-1,1]*2 确保均值范围为[-2,2] #测试时候归一化时无2std = F.softplus(self.fc_std(x)) # 保证方差为正数 softplus = log(1+exp(x))return mu, std # 返回高斯分布的均值和方差class ValueNet(torch.nn.Module):def __init__(self, state_dim, hidden_dim):super(ValueNet, self).__init__() # 继承父类的所有属性self.fc1 = torch.nn.Linear(state_dim, hidden_dim)self.fc1_2 = torch.nn.Linear(hidden_dim, hidden_dim)self.fc2 = torch.nn.Linear(hidden_dim, 1)def forward(self, x):x = F.relu(self.fc1(x))x = F.relu(self.fc1_2(x))return self.fc2(x)class PPOContinuous:''' 处理连续动作的PPO算法 '''def __init__(self, state_dim, hidden_dim, action_dim, actor_lr, critic_lr,lmbda, epochs, eps, gamma, device):self.actor = PolicyNetContinuous(state_dim, hidden_dim,action_dim).to(device)self.critic = ValueNet(state_dim, hidden_dim).to(device)self.actor_optimizer = torch.optim.Adam(self.actor.parameters(),lr=actor_lr)self.critic_optimizer = torch.optim.Adam(self.critic.parameters(),lr=critic_lr)self.gamma = gammaself.lmbda = lmbdaself.epochs = epochsself.eps = epsself.device = devicedef take_action(self, state):state = torch.tensor(np.array([state]), dtype=torch.float).to(self.device)mu, sigma = self.actor(state)action_dist = torch.distributions.Normal(mu, sigma) # normal是正态分布action = action_dist.sample()return [action.item()] # 返回一个动作 这里[]是因为返回的是一个列表def update(self, transition_dict):states = torch.tensor(np.array(transition_dict['states']),dtype=torch.float).to(self.device)actions = torch.tensor(np.array(transition_dict['actions']),dtype=torch.float).view(-1, 1).to(self.device)rewards = torch.tensor(np.array(transition_dict['rewards']),dtype=torch.float).view(-1, 1).to(self.device)next_states = torch.tensor(np.array(transition_dict['next_states']),dtype=torch.float).to(self.device)dones = torch.tensor(np.array(transition_dict['dones']),dtype=torch.float).view(-1, 1).to(self.device)rewards = (rewards + 4.0) / 4.0 # 和TRPO一样,对奖励进行修改,方便训练 #其中rewards +8td_target = rewards + self.gamma * self.critic(next_states) * (1 -dones)td_delta = td_target - self.critic(states)#print(td_target)#print(self.critic(states)) #.cpu 当你需要将张量转换为 NumPy 数组时,因为 NumPy 不能直接处理 GPU 上的张量。advantage = compute_advantage(self.gamma, self.lmbda,td_delta.cpu()).to(self.device)# 这三步和离散动作的PPO不一样mu, std = self.actor(states) action_dists = torch.distributions.Normal(mu.detach(), std.detach())### # 动作是正态分布 得出动作的概率old_log_probs = action_dists.log_prob(actions)#print("mu",mu,"std",std)for _ in range(self.epochs):mu, std = self.actor(states) ##action_dists = torch.distributions.Normal(mu, std) ##log_probs = action_dists.log_prob(actions)ratio = torch.exp(log_probs - old_log_probs)surr1 = ratio * advantagesurr2 = torch.clamp(ratio, 1 - self.eps, 1 + self.eps) * advantageactor_loss = torch.mean(-torch.min(surr1, surr2)) critic_loss = torch.mean(F.mse_loss(self.critic(states), td_target.detach()))self.actor_optimizer.zero_grad()self.critic_optimizer.zero_grad()actor_loss.backward()critic_loss.backward()self.actor_optimizer.step()self.critic_optimizer.step()def train_on_policy_agent(env, agent, max_train_steps,number,seed):return_list = []# Build a tensorboardwriter = SummaryWriter(log_dir='runs/PPO_mul_raw/env_{}_raw_number_{}_seed_{}'.format(env_name, number, seed))total_steps = 0 while total_steps < max_train_steps: episode_return = 0transition_dict = {'states': [], 'actions': [], 'next_states': [], 'rewards': [], 'dones': []}state = env.reset(seed =0)[0] #1.改 gym 0.26.0版本后,env.reset()返回的是一个字典,所以需要加上[0]#print('state:',state)#state= state_norm(state) ### 这里状态归一化done = Falsewhile not done:#action = agent.take_action(state) #action 这里是[-2,2]的动作 action = agent.take_action(state) # forward 无2 这里是[-1,1]的动作#next_state, reward, done, _ = env.step(action)[0:4] #2.改#next_state, reward,terminated, truncated, _ = env.step(action) #2.改看gym版本0.26.2版本的#next_state, reward,terminated, truncated, _ = env.step([np.clip(action[0]*2,-2,2)]) next_state, reward,terminated, truncated, _ = env.step([action[0]*2]) done = terminated or truncatedtransition_dict['states'].append(state)transition_dict['actions'].append(action)transition_dict['next_states'].append(next_state)transition_dict['rewards'].append(reward)transition_dict['dones'].append(done)#print(transition_dict)state = next_stateepisode_return += rewardtotal_steps += 1return_list.append(episode_return)agent.update(transition_dict)# if (i_episode+1) % 10 == 0:# pbar.set_postfix({'episode': '%d' % (num_episodes/10 * i + i_episode+1), 'return': '%.3f' % np.mean(return_list[-10:])})# pbar.update(1)#if (total_steps) % 200 == 0:#print('episode:',total_steps,'return:',np.mean(return_list[-10:]))writer.add_scalar('return', episode_return, total_steps)return return_listactor_lr = 1e-4
critic_lr = 5e-3#1e-1#5e-3
num_episodes = 1000
max_train_steps = 2e5 #1000*200
hidden_dim = 128
gamma = 0.9
lmbda = 0.9
epochs = 10
eps = 0.2
#device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
device = torch.device("cpu")
env_name = 'Pendulum-v1'
env = gym.make(env_name)
#env.seed(0)
torch.manual_seed(0)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0] # 连续动作空间agent = PPOContinuous(state_dim, hidden_dim, action_dim, actor_lr, critic_lr,lmbda, epochs, eps, gamma, device)return_list = train_on_policy_agent(env, agent, max_train_steps,number=5,seed=0)
mul代码
import gym
import os
# 设置OMP_WAIT_POLICY为PASSIVE,让等待的线程不消耗CPU资源 #确保在pytorch前设置
os.environ['OMP_WAIT_POLICY'] = 'PASSIVE' #
import torch
import torch.nn.functional as F
import numpy as np
from multiprocessing import Process, Pipe
from tqdm import tqdm
import time
from torch.utils.tensorboard import SummaryWriter ##1.TBdef compute_advantage(gamma, lmbda, td_delta):td_delta = td_delta.detach().numpy()advantage_list = []advantage = 0.0for delta in td_delta[::-1]:advantage = gamma * lmbda * advantage + deltaadvantage_list.append(advantage)advantage_list.reverse()return torch.tensor(np.array(advantage_list), dtype=torch.float32)class PolicyNetContinuous(torch.nn.Module):def __init__(self, state_dim, hidden_dim, action_dim):super(PolicyNetContinuous, self).__init__()self.fc1 = torch.nn.Linear(state_dim, hidden_dim)self.fc_mu = torch.nn.Linear(hidden_dim, action_dim)self.fc_std = torch.nn.Linear(hidden_dim, action_dim)def forward(self, x):x = F.relu(self.fc1(x))mu = torch.tanh(self.fc_mu(x))std = F.softplus(self.fc_std(x))return mu, stdclass ValueNet(torch.nn.Module):def __init__(self, state_dim, hidden_dim):super(ValueNet, self).__init__()self.fc1 = torch.nn.Linear(state_dim, hidden_dim)self.fc2 = torch.nn.Linear(hidden_dim, 1)def forward(self, x):x = F.relu(self.fc1(x))return self.fc2(x)class PPOContinuous:def __init__(self, state_dim, hidden_dim, action_dim, actor_lr, critic_lr, lmbda, epochs, eps, gamma, device):self.actor = PolicyNetContinuous(state_dim, hidden_dim, action_dim).to(device)self.critic = ValueNet(state_dim, hidden_dim).to(device)self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)self.gamma = gammaself.lmbda = lmbdaself.epochs = epochsself.eps = epsself.device = devicedef take_action(self, state):state = torch.tensor(np.array([state]), dtype=torch.float).to(self.device)mu, sigma = self.actor(state)action_dist = torch.distributions.Normal(mu, sigma)action = action_dist.sample()return [action.item()]def update(self, transition_dict):states = torch.tensor(np.array(transition_dict['states']), dtype=torch.float).to(self.device)actions = torch.tensor(np.array(transition_dict['actions']), dtype=torch.float).view(-1, 1).to(self.device)rewards = torch.tensor(np.array(transition_dict['rewards']), dtype=torch.float).view(-1, 1).to(self.device)next_states = torch.tensor(np.array(transition_dict['next_states']), dtype=torch.float).to(self.device)dones = torch.tensor(np.array(transition_dict['dones']), dtype=torch.float).view(-1, 1).to(self.device)rewards = (rewards + 4.0) / 4.0td_target = rewards + self.gamma * self.critic(next_states) * (1 - dones)td_delta = td_target - self.critic(states)advantage = compute_advantage(self.gamma, self.lmbda, td_delta.cpu()).to(self.device)mu, std = self.actor(states)action_dists = torch.distributions.Normal(mu.detach(), std.detach())old_log_probs = action_dists.log_prob(actions)for _ in range(self.epochs):mu, std = self.actor(states)action_dists = torch.distributions.Normal(mu, std)log_probs = action_dists.log_prob(actions)ratio = torch.exp(log_probs - old_log_probs)surr1 = ratio * advantagesurr2 = torch.clamp(ratio, 1 - self.eps, 1 + self.eps) * advantageactor_loss = torch.mean(-torch.min(surr1, surr2))critic_loss = torch.mean(F.mse_loss(self.critic(states), td_target.detach()))self.actor_optimizer.zero_grad()self.critic_optimizer.zero_grad()actor_loss.backward()critic_loss.backward()self.actor_optimizer.step()self.critic_optimizer.step()
###
def child_process(conn, env_name):#os.environ['OMP_NUM_THREADS'] = str(4) #默认8env = gym.make(env_name)while True:agent = conn.recv() ## 1.这个位置,先传入agenttransition_dict = {'states': [], 'actions': [], 'next_states': [], 'rewards': [], 'dones': []}episode_return = 0episode_steps =0state = env.reset(seed=0)[0]done = Falsewhile not done:action = agent.take_action(state)next_state, reward, terminated, truncated, _ = env.step([action[0] * 2])done = terminated or truncatedtransition_dict['states'].append(state)transition_dict['actions'].append(action)transition_dict['next_states'].append(next_state)transition_dict['rewards'].append(reward)transition_dict['dones'].append(done)state = next_state ## 2.先append再赋值episode_return += rewardepisode_steps +=1conn.send((transition_dict, episode_return, episode_steps))
###
def main():actor_lr = 1e-4critic_lr = 5e-3num_episodes = 200hidden_dim = 128gamma = 0.9lmbda = 0.9epochs = 10eps = 0.2device = torch.device("cpu")env_name = 'Pendulum-v1'env = gym.make(env_name)torch.manual_seed(0)state_dim = env.observation_space.shape[0]action_dim = env.action_space.shape[0]# Build a tensorboardnumber = 46 #5seed = 0writer = SummaryWriter(log_dir='runs/PPO_mul_raw/env_{}_mul_number_{}_seed_{}'.format(env_name, number, seed))agent = PPOContinuous(state_dim, hidden_dim, action_dim, actor_lr, critic_lr, lmbda, epochs, eps, gamma, device)###process_num = 4 ##pipe_dict = dict((i, (pipe1, pipe2)) for i in range(process_num) for pipe1, pipe2 in (Pipe(),)) pipe_dict = {i: Pipe() for i in range(process_num)} #Pipe()返回一个元组: (conn1, conn2) #与上行相同child_process_list = [Process(target=child_process, args=(pipe_dict[i][1], env_name)) for i in range(process_num)]#timeList = list()total_steps = 0max_train_steps = 2e5#begin = time.time()# for p in child_process_list:# p.start()[p.start() for p in child_process_list]return_list = []while total_steps < max_train_steps:episode_return = 0# for j in range(process_num):# pipe_dict[j][0].send(agent)[pipe_dict[j][0].send(agent) for j in range(process_num)] ##3.先传入agentfor j in range(process_num): ##4. i,j区分transition_dict, episode_return_,episode_steps = pipe_dict[j][0].recv()agent.update(transition_dict)#episode_return += episode_return_total_steps += episode_stepswriter.add_scalar('return', episode_return_, total_steps)return_list.append(episode_return_)#return_list.append(episode_return / process_num)#timeList.append(time.time()-begin)# if (i + 1) % 10 == 0:# print(f'Episode: {i + 1}, Average Return: {np.mean(return_list[-10:])}, Time: {timeList[-1]}')# if (total_steps) % 200 == 0:# print('episode:',total_steps,'return:',np.mean(return_list[-10:]))# for p in child_process_list:# p.terminate()[p.terminate() for p in child_process_list] #child 用了while True,所以要terminatereturn return_list #单位为episode
if __name__ == '__main__':main()