1. TSFEL
时间序列作为主要TSFEL提取方法的输入传递,要么作为先前加载在内存中的数组传递,要么存储在数据集中的文件中。 由于TSFEL可以处理多维时间序列,因此随后应用了一套预处理方法,以确保信号质量足够和时间序列同步,从而适当地实现窗口计算过程。 特征提取后,使用标准模式保存结果,供大多数分类和数据挖掘平台消化。 每一行对应一个窗口,特征提取方法的结果与相应的时间序列一起存储,作为主要TSFEL提取方法的输入传递,要么作为先前加载在内存中的数组,要么存储在数据集中的文件中。 由于TSFEL可以处理多维时间序列,因此随后应用了一套预处理方法,以确保信号质量足够和时间序列同步,从而适当地实现窗口计算过程。 特征提取后,使用标准模式保存结果,供大多数分类和数据挖掘平台消化。 每行对应一个窗口,其中包含与相应列一起存储的特征提取方法的结果。
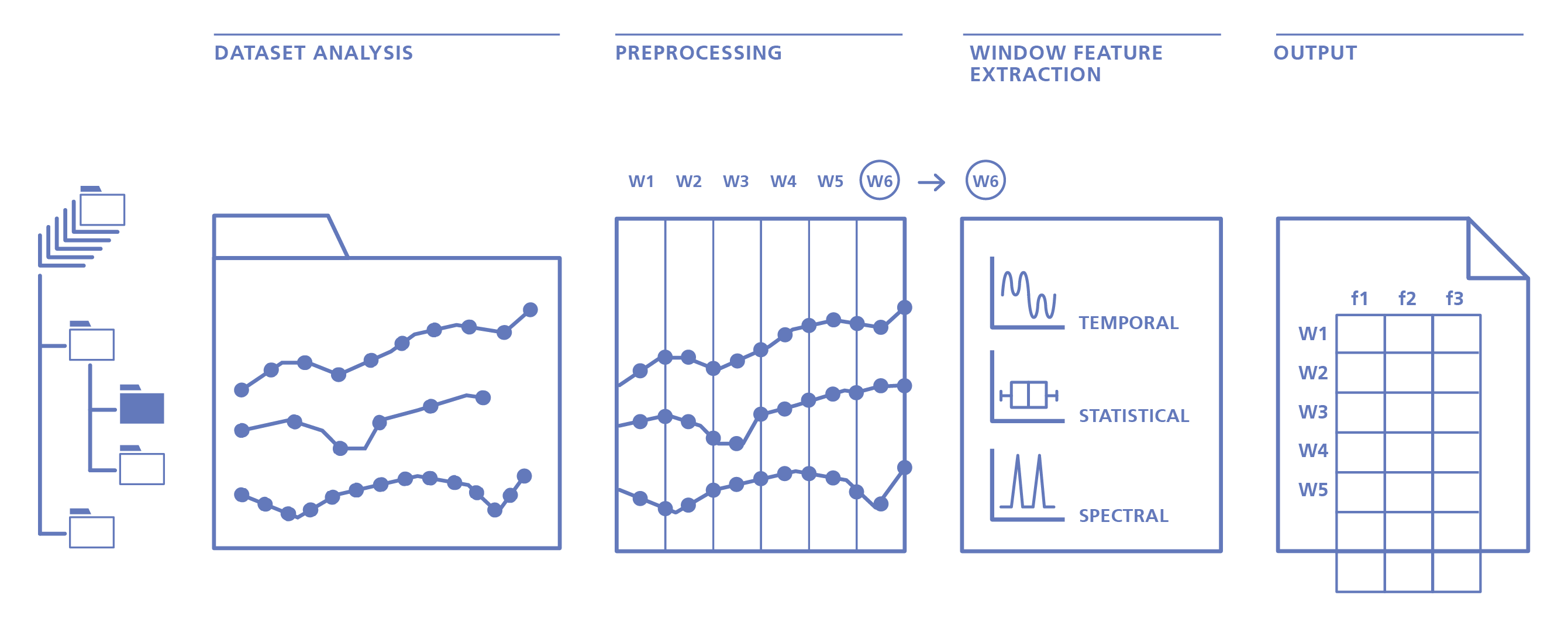
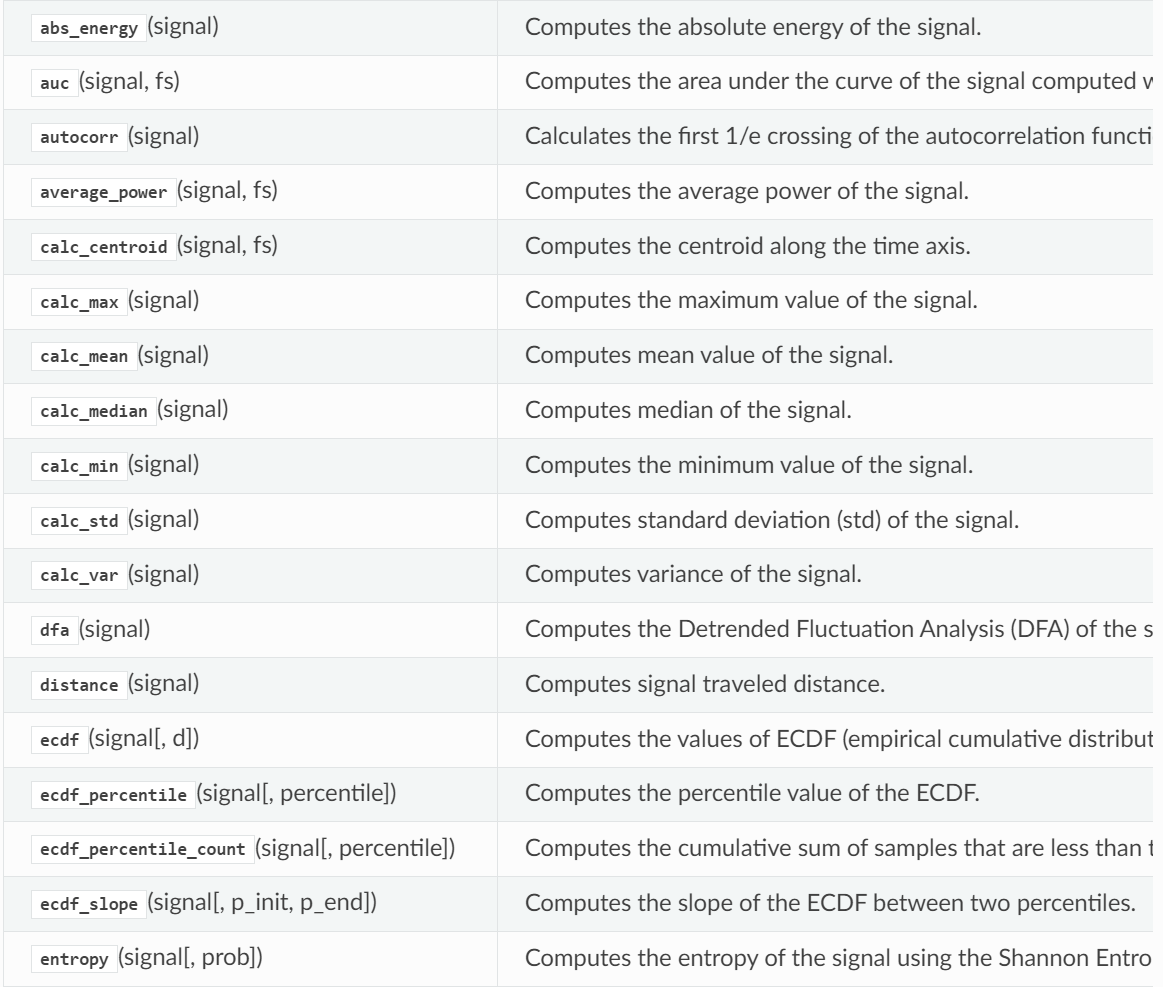
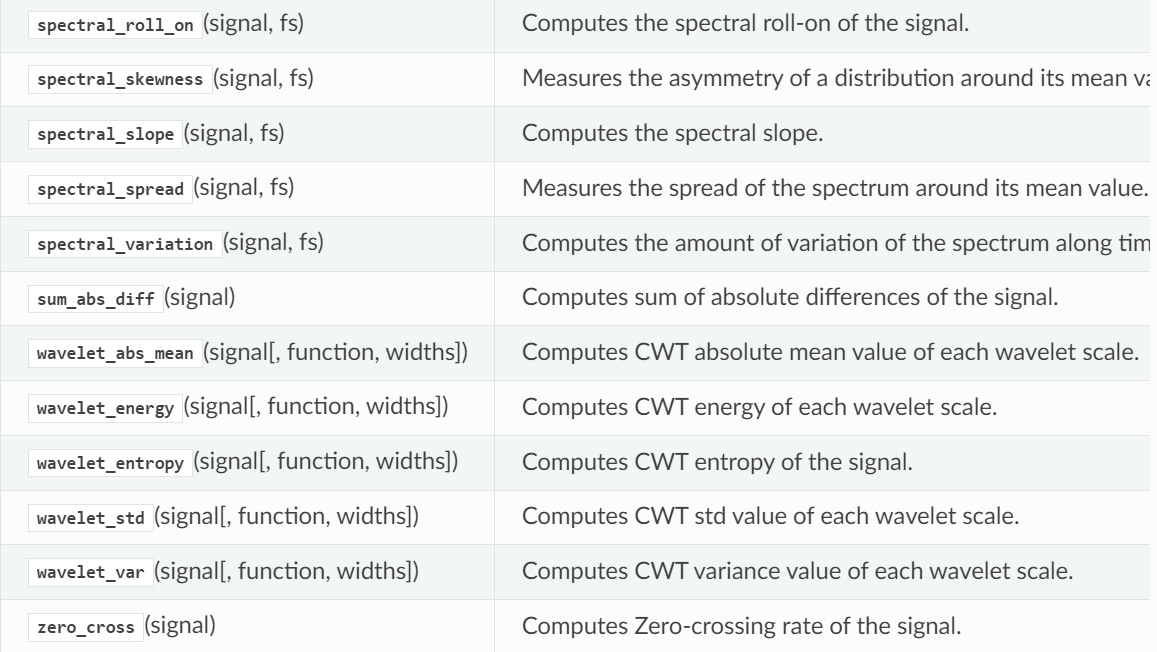
下表提供了TSFEL当前版本中可用特性的概述。


2. 从时间序列中提取数组对象
让我们从下载一些数据开始。 完整的数据集描述可在1中找到。 在本例中,我们将使用加速度计传感器以50Hz采样的时间序列。
import tsfel
import zipfile
import numpy as np
import pandas as pd# Load the dataset from online repository
!wget https://archive.ics.uci.edu/ml/machine-learning-databases/00240/UCI%20HAR%20Dataset.zip# Unzip the dataset
zip_ref = zipfile.ZipFile("UCI HAR Dataset.zip", 'r')
zip_ref.extractall()
zip_ref.close()# Store the dataset as a Pandas dataframe.
x_train_sig = np.loadtxt('UCI HAR Dataset/train/Inertial Signals/total_acc_x_train.txt', dtype='float32')
X_train_sig = pd.DataFrame(np.hstack(x_train_sig), columns=["total_acc_x"])
现在我们有了一个DataFrame,它由一个具有关联列名的唯一列组成。 注意,TSFEL还可以处理多维数据流。 在这种情况下,有必要将额外的时间序列作为数据框架中的额外列传递。
现在我们有了输入数据,我们就可以开始特征提取步骤了。 TSFEL依赖于字典来设置提取的配置。 我们提供了一组可以开箱即用的模板配置字典。 在本例中,我们将使用提取TSFEL所有可用特征的示例。 我们将配置TSFEL将我们的时间序列划分为大小为250个点(对应于5秒)的等长窗口。
cfg_file = tsfel.get_features_by_domain() # If no argument is passed retrieves all available features
X_train = tsfel.time_series_features_extractor(cfg_file, X_train_sig, fs=50, window_size=250) # Receives a time series sampled at 50 Hz, divides into windows of size 250 (i.e. 5 seconds) and extracts all features
我们现在终于有了X_train作为最后的特征向量,它由为每个3764个提取窗口计算的205个特征组成。
3. 从存储在数据集中的时间序列中提取
在上一节中,我们观察了如何使用TSFEL对存储在内存中的时间序列进行特征提取。 训练机器学习模型的过程需要大量的数据。 时间序列数据集通常组织在由收集和管理数据的实体定义的多种不同模式中。 TSFEL提供了一种在数据集中存储的多个文件上提取特征时增加灵活性的方法。 在使用这种方法时,我们提供了以下假设列表以及TSFEL如何处理它:
时间序列存储在不同的文件位置
a) TSFEL在给定的数据集根目录上爬行,并从与用户提供的文件名匹配的所有文本文件中提取特征
b) 文件以分隔格式存储时间序列
c) TSFEL期望第一列必须包含时间戳,后面的列包含时间序列值。
d) 文件可能无法及时同步 ,TSFEL通过进行线性插值来处理这个假设,以确保所有的时间序列在特征提取之前及时同步。 重采样频率由用户自行设置。
下面的代码块从所有名为Accelerometer.txt的文件中提取驻留在main_directory上的数据的特性。 时间戳以纳秒为单位记录,重采样频率设置为100hz。
import tsfelmain_directory = '/my_root_dataset_directory/' # The root directory of the dataset
output_directory = '/my_output_feature_directory/' # The resulted file from the feature extraction will be saved on this directorydata = tsfel.dataset_features_extractor(main_directory, tsfel.get_features_by_domain(), search_criteria="Accelerometer.txt",time_unit=1e-9, resample_rate=100, window_size=250,output_directory=output_directory)
4. 设置特征提取配置文件
TSFEL的主要优点之一是提供了大量开箱即用的时间序列特征。 然而,在某些情况下,您可能对提取完整的集合不感兴趣。 示例包括将模型部署在低功耗嵌入式设备中的场景,或者您只是想更具体地提取哪些特征。
TSFEL将可用的特征分为三个领域:统计、时间和光谱。 上面解释的提取特性的两种方法需要一个配置文件——feat_dict——一个包含将要使用的特性和超参数的字典。
下面,我们列出了四个示例来建立配置字典。
import tsfelcfg_file = tsfel.get_features_by_domain() # All features will be extracted.
cgf_file = tsfel.get_features_by_domain("statistical") # All statistical domain features will be extracted
cgf_file = tsfel.get_features_by_domain("temporal") # All temporal domain features will be extracted
cgf_file = tsfel.get_features_by_domain("spectral") # All spectral domain features will be extracted
如果您需要自定义的一组功能或来自多个域的功能组合,则可能需要编辑配置字典(JSON)。 必须根据需要将键用法的值编辑为yes或no。 您可以加载任何先前的配置字典,并将您不感兴趣的特性设置为“使用”:“否”,或者手动或编程编辑字典,并根据需要将使用设置为“是”或“否”。







![[C/C++][VsCode]使用VsCode在Linux上开发和Vscode在线调试](https://img-blog.csdnimg.cn/direct/edbe6ca835b9429ba69e2a5e7427bec7.png)