LMB提出了基于CXL协议的内存扩展框架和内核模块。该方案利用CXL内存扩展器作为物理DRAM源,旨在提供一个统一的内存分配接口,使PCIe和CXL设备都能方便地访问扩展的内存资源。通过这个接口,NVMe驱动和CUDA的统一内存内核驱动可以直接高效地访问CXL内存扩展器,让SSD和GPU设备能够像使用板载内存一样轻松地利用LMB提供的内存资源。这一设计旨在消除内存短缺问题,同时保持高性能和灵活性,是解决现代高性能计算和数据中心内存需求增长的有效途径。
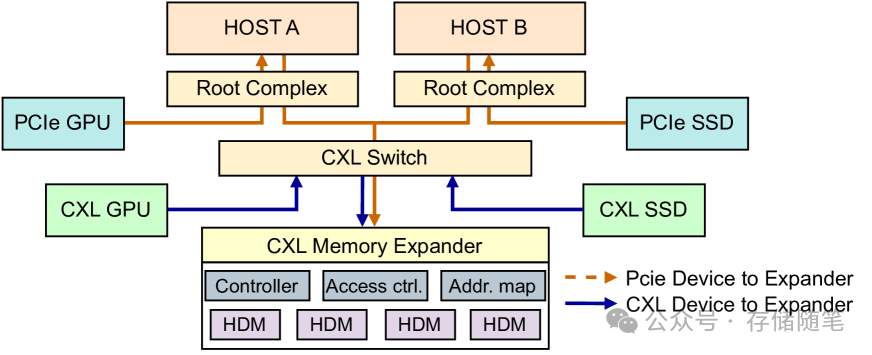
CXL Linked Memory Buffer (LMB) 是一种创新的框架,旨在通过CXL(Compute Express Link)技术扩展设备内存,而非仅仅扩展主机内存。这项技术弥补了现有研究的空白,后者主要集中在通过CXL构建主机内存池上。
LMB的核心在于CXL内存扩展器(CXL Memory Expander)与CXL交换机的结合使用。扩展器通过CXL交换机与主机及CXL/PCIe设备相连,为它们提供一个集中管理的内存池。该内存池包含多个汇集的Host-Managed Device Memories (HDMs),并支持基本的地址映射、访问控制等功能。LMB框架基于CXL协议,将扩展器作为Global Fabric Device (GFD),不仅服务于CXL设备,还能服务主机上的其他PCIe设备。它在内核级别实现了一个统一框架,支持CXL和PCIe设备,并为设备驱动程序提供内存分配、释放和访问控制等API。
LMB组件与功能
-
CXL内存扩展器与Fabric Manager (FM):扩展器作为GFD,由FM直接管理,负责全局内存资源的分配与动态管理。FM可以实现在主机软件中或交换机/设备固件中,管理CXL架构中的设备与资源。宿主机可通过FM的API动态查询和配置扩展器状态,实现多宿主机间动态内存分配。扩展器内部管理HDMs,通过地址映射将宿主机请求中的Host Physical Addresses (HPAs) 转换为Device Physical Addresses (DPAs)。
-
LMB内核模块:考虑到PCIe设备与CXL设备访问内存协议的不同,以及现有CXL内存池设计难以兼容PCIe设备,LMB内核模块被设计成一座桥梁,提供统一的内存分配和共享接口。该模块首先向FM请求内存块,然后与设备驱动交互完成内存分配,并通过提升加载优先级避免PCIe设备初始化阶段的内存请求失败。
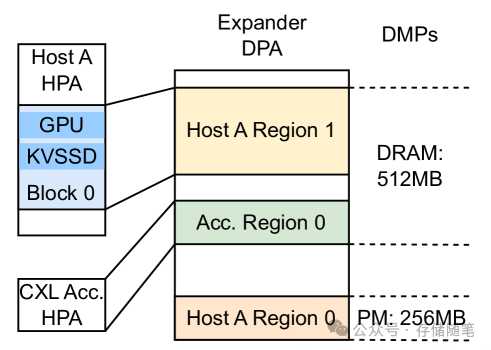
内存管理
-
内存分配器:内核模块通过FM API向扩展器请求内存,映射到主机物理地址空间后等待分配给本地设备。当内存不足时,模块会请求256MB的内存块。所有设备内存释放后,模块会将内存区域归还给FM。通过在主机上维护内存分配器元数据,可以优化大内存映射对齐,减少CXL内存访问次数。
-
数据路径:PCIe设备不能直接使用CXL协议访问扩展器,但可以通过CPU将PCIe TLP转换为CXL.mem协议中的MemRd/MemWr命令,访问映射到物理地址的HDM。由于PCIe设备不支持CXL缓存一致性,所以内存被设置为非缓存类型。尽管PCIe设备和CXL设备共享内存时,PCIe设备收不到回写的监听信息,但这不会引起一致性问题。(浅析CXL P2P DMA加速数据传输的原理)
LMB API提供与设备驱动交互
LMB内核模块为支持分配、释放和共享操作的设备驱动程序提供了一系列API接口,使得驱动程序能够调用这些API来高效地管理外部扩展内存。这些API包括但不限于分配内存(lmb_PCIe_alloc, lmb_CXL_alloc)、释放内存(lmb_PCIe_free, lmb_CXL_free)以及内存共享(lmb_PCIe_share, lmb_CXL_share)。
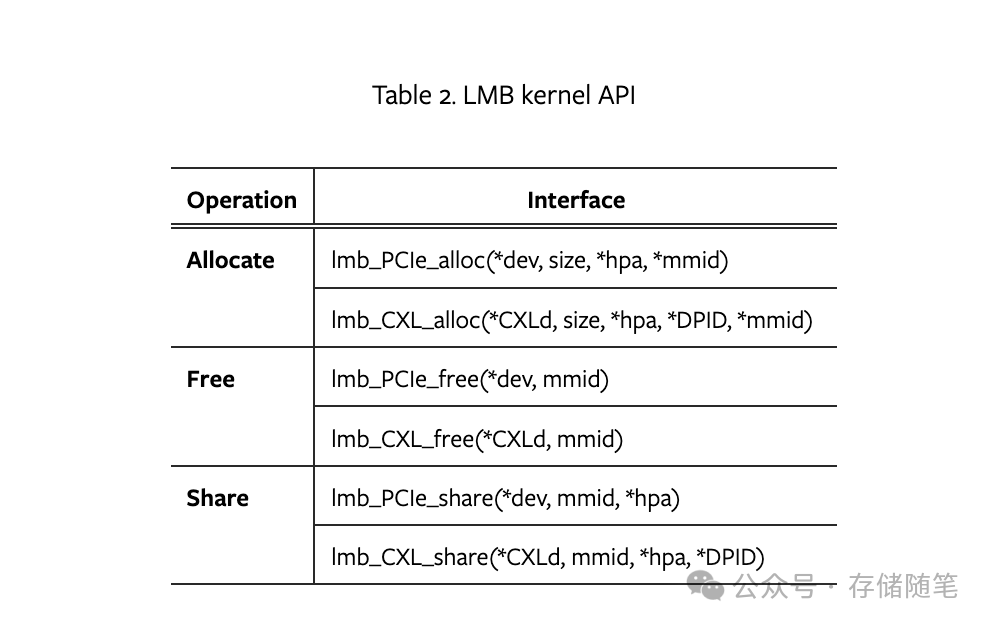
SSD应用LMB存储L2P表的流程
下图展示了SSD如何利用LMB申请内存来存储其逻辑到物理(L2P)映射表的过程。在这个过程中,PCIe设备通过LMB获取到设备可访问的总线地址和在本地主机上的唯一内存标识符。除了获取GFAM(Global Fabric-Attached Memory)的HPA(Host Physical Address)之外,CXL设备还会得到扩展器PID(Process ID),以便发起P2P请求。这样,共享内存可以充当IO缓冲区,减少设备间的数据复制操作,例如,通过共享内存直接从SSD发送数据到加速器进行计算,实现了零拷贝数据路径,极大地提升了数据传输效率。
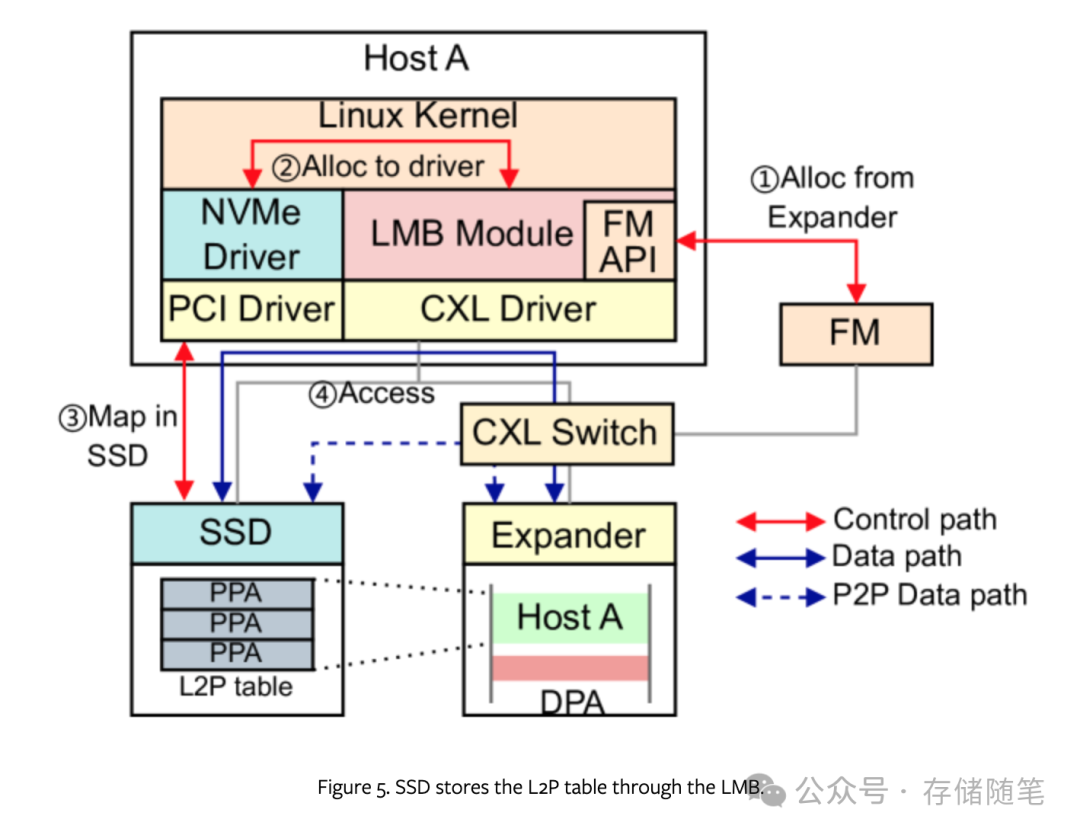
内核模块负责维护HPA和总线地址到物理地址的映射关系,通过地址翻译机制实现PCIe设备与CXL设备之间的内存共享,无需数据复制,从而优化了内存使用效率。
为了确保不同设备间内存访问的安全性,LMB整合了两种访问控制模式:
-
对于PCIe设备,采用IOMMU来限制设备只能访问分配给它的内存范围,避免非法访问。
-
对于CXL设备,通过SPID Access Table (SAT) 来管理对Global Fabric Device (GFD)的访问控制。GFD能够根据内存请求中的SPID字段识别请求发起方是CXL设备还是主机。内核模块在分配内存给PCIe设备时创建IOMMU页表,在CXL设备请求内存时将其SPID添加到SAT中。当内存释放或共享时,相关的表项会被相应更新,确保访问权限的实时性和准确性。
LMB方案通过统一的API接口、高效的内存共享机制以及严格的访问控制策略,有效解决了PCIe和CXL设备内存扩展和访问安全问题,提升了系统整体的性能和效率。
论文中展示了初步的模拟结果,以证明LMB(Linked Memory Buffer)在扩展SSD DRAM用于L2P索引方面的有效性。研究对比了LMB方案与理想情况(即所有映射表均存储于板载DRAM中)以及DFTL(一种动态闪存转换层技术)方案的性能。LMB方案进一步细分为LMB-CXL和LMB-PCIe,以评估不同设备通过CXL或PCIe接口访问外部内存的场景。
此外,还利用了PCIe Gen4和Gen5标准的SSD进行测试,以考察不同PCIe标准的影响。评估工作负载包括随机/顺序读写,使用FIO工具进行,配置了队列深度为64、IO大小为4KB的libaio IO引擎。
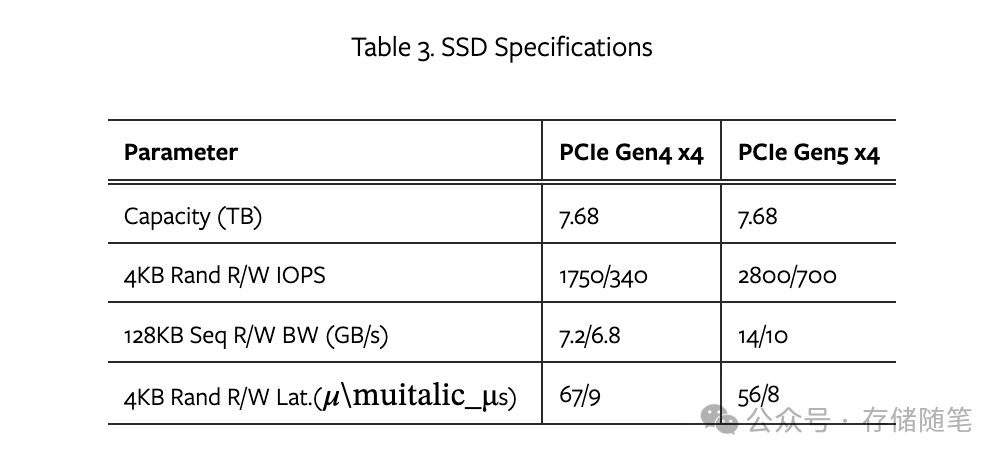
由于真实CXL开发板的稀缺,LMB-CXL和LMB-PCIe的模拟是在修改了固件(特别是L2P索引模块)的PCIe Gen4和Gen5 SSD上进行的。通过比较这两种不同性能基线的SSD,观察CXL额外延迟对不同性能级别设备的潜在影响。
在理想情况方案中,为了模拟LMB和DFTL方案,特意在L2P索引操作中加入了延迟。模拟DFTL缓存未命中时,在理想方案中增加了25微秒的延迟;对于LMB-PCIe,分别在PCIe Gen4和Gen5 SSD上增加了880纳秒和1190纳秒的延迟;LMB-CXL则增加了190纳秒的延迟。
PCIe Gen4 SSD性能评估
在主流的PCIe Gen4 SSD上,LMB-CXL和LMB-PCIe在写工作负载下与理想方案的吞吐量相当,比DFTL方案高出7倍。在读工作负载下,LMB-CXL保持接近理想方案的表现,而LMB-PCIe在顺序和随机读取上分别下降了16.6%和13.3%,但仍优于DFTL方案14倍。这表明LMB机制对于解决高容量QLC SSD的板载内存短缺问题非常有效。
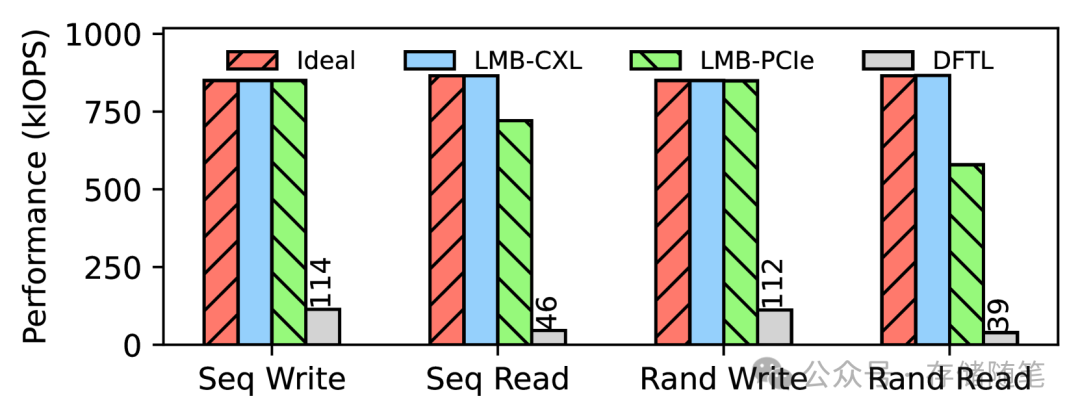
PCIe Gen5 SSD性能评估
在更高速的PCIe Gen5 SSD上,LMB-CXL和LMB-PCIe在写工作负载下与理想方案表现一致,吞吐量比DFTL方案高出20倍。然而,在读工作负载下,两者性能都有所下降,LMB-CXL在顺序和随机读取上分别低了8%和56%,而LMB-PCIe的性能降级更为严重,分别低了62%和70%。即便如此,LMB-PCIe依然比DFTL方案高出20倍的吞吐量。
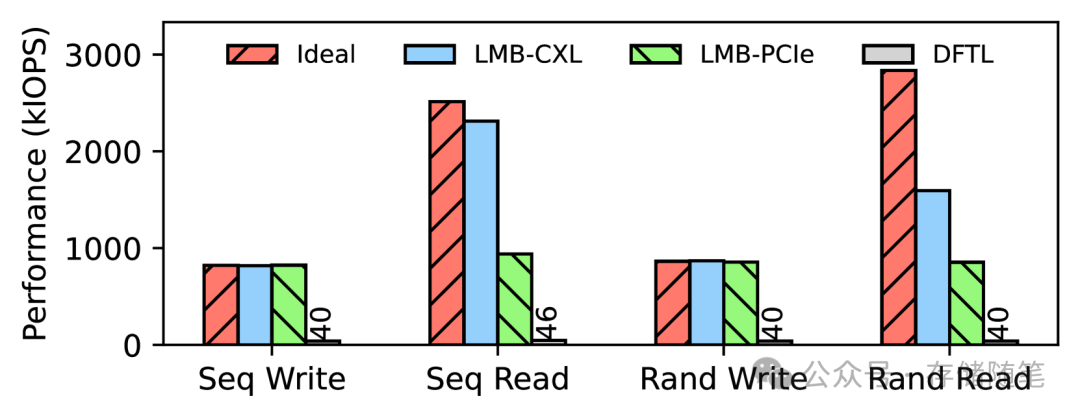
模拟结果显示,尽管在索引操作中引入数百纳秒的CXL延迟显著影响了高性能SSD的性能,但这些结果是基于所有索引完全依赖于CXL扩展内存的假设。在实际工作负载中,如果大多数索引都能命中板载内存,利用数据访问的局部性,CXL二级索引对设备性能的影响将大大减少。因此,LMB方案特别是LMB-CXL,在解决高密度存储设备的DRAM短缺问题上展现出了潜力,特别是在能够有效利用混合存储方案和优化数据布局的情况下。
本文提出的LMB方案是针对PCIe设备DRAM短缺问题的一次重要探索,通过结合CXL技术,不仅为高性能计算领域带来了新的解决方案,也为未来的存储和计算架构设计提供了新思路。随着CXL技术的成熟与普及,LMB有望成为提升数据中心效率、支持大规模数据处理和复杂模型训练的关键技术之一。未来,继续优化LMB的设计与实施,降低延迟影响,提高内存扩展效率,将是持续的研究方向。
如果您看完有所受益,欢迎点击文章底部左下角“关注”并点击“分享”、“在看”,非常感谢!
精彩推荐:
-
数据中心:AI范式下的内存挑战与机遇
-
WDC西部数据闪存业务救赎之路,会成功吗?
-
属于PCIe 7.0的那道光来了~
-
深度剖析:AI存储架构的挑战与解决方案
-
浅析英伟达GPU NCCL P2P与共享内存
-
3D NAND原厂:哪家芯片存储效率更高?
-
大厂阿里、字节、腾讯都在关注这个事情!
-
磁带存储:“不老的传说”依然在继续
-
浅析3D NAND多层架构的可靠性问题
-
SSD LDPC软错误探测方案解读
-
关于SSD LDPC纠错能力的基础探究
-
存储系统如何规避数据静默错误?
-
PCIe P2P DMA全景解读
-
深度解读NVMe计算存储协议
-
浅析不同NAND架构的差异与影响
-
SSD基础架构与NAND IO并发问题探讨
-
字节跳动ZNS SSD应用案例解析
-
CXL崛起:2024启航,2025年开启新时代
-
NVMe SSD:ZNS与FDP对决,你选谁?
-
浅析PCI配置空间
-
浅析PCIe系统性能
-
存储随笔《NVMe专题》大合集及PDF版正式发布!

如果您也想针对存储行业分享自己的想法和经验,诚挚欢迎您的大作。
投稿邮箱:Memory_logger@163.com (投稿就有惊喜哦~)
《存储随笔》自媒体矩阵

更多存储随笔科普视频讲解,请移步B站账号:
如您有任何的建议与指正,敬请在文章底部留言,感谢您不吝指教!如有相关合作意向,请后台私信,小编会尽快给您取得联系,谢谢!