场景:
chatgpt帮你写爬虫程序,轻松获取工作需要的数据
方法
安装python环境

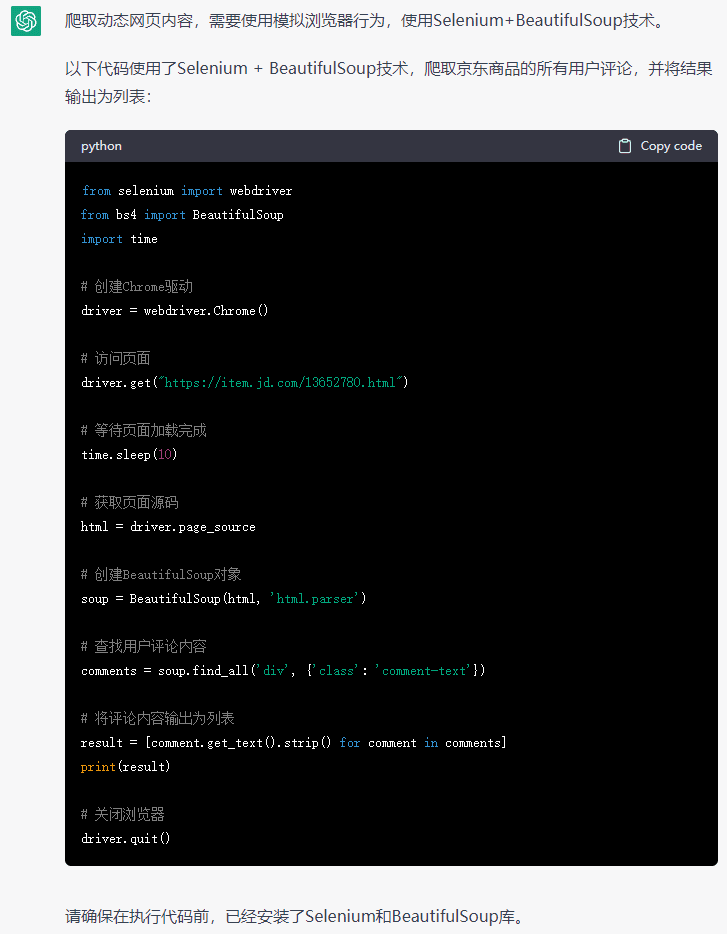
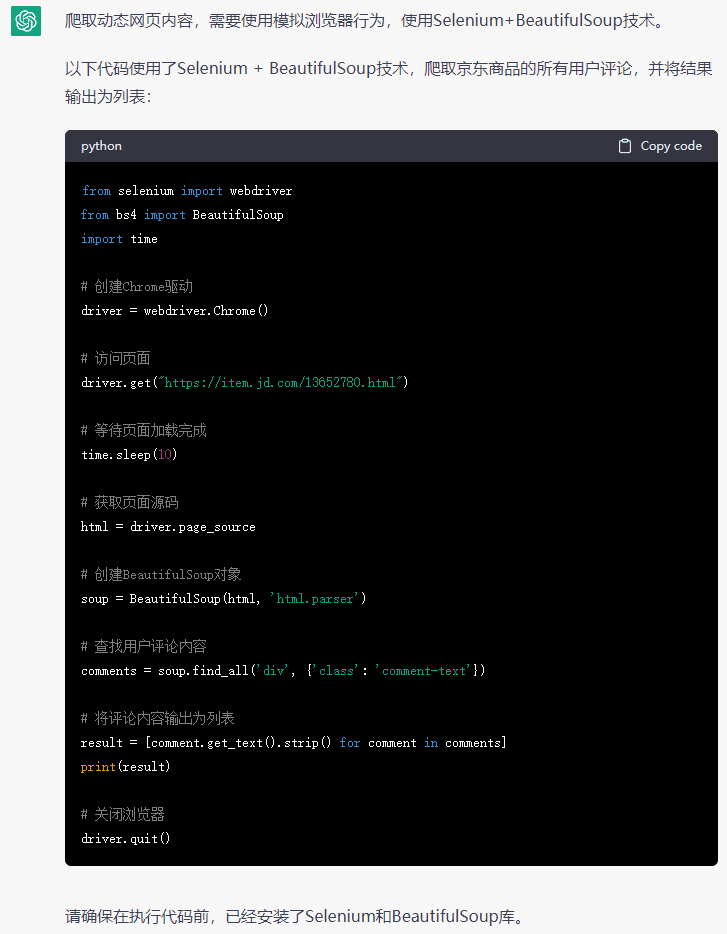
import requests
from bs4 import BeautifulSoup
import pandas as pd# 设置请求头部,模拟浏览器访问
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}# 豆瓣电影排行榜URL
url = 'https://movie.douban.com/chart'# 发送GET请求
response = requests.get(url, headers=headers)# 解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')# 获取电影列表
movie_list = soup.find('div', class_='article').find_all('div', class_='pl2')# 创建空列表,用于保存电影信息
movies = []# 循环遍历电影列表
for movie in movie_list:# 获取电影名称和链接title = movie.find('a').text.strip()link = movie.find('a')['href']# 获取电影评分rating = movie.find('span', class_='rating_nums').text.strip()# 将电影信息添加到列表中movies.append((title, link, rating))# 将电影信息转换为Pandas数据帧
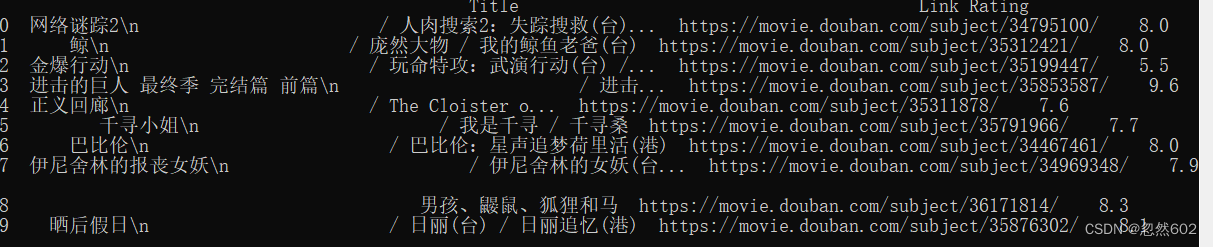
df = pd.DataFrame(movies, columns=['Title', 'Link', 'Rating'])# 输出前50名电影的信息
print(df.head(50))把chatgpt回复的代码保存为.py文件,所有文件类型在cmd中运行即可 python 文件名.py,回车键