一、序列
序列(sequence)是一组有顺序的值的集合,是计算机科学中的一个强大且基本的抽象概念。序列并不是特定内置类型或抽象数据表示的实例,而是一个包含不同类型数据间共享行为的集合。也就是说,序列有很多种类,但它们都具有共同的行为。特别是:
-
长度(Length):序列的长度是有限的,空序列的长度为 0。
-
元素选择(Element selection):序列中的每个元素都对应一个小于序列长度的非负整数作为其索引,第一个元素的索引从 0 开始。
Python 包含几种内置的序列数据类型,其中最重要的是列表(list)。
1.1、列表
列表(list)是一个可以有任意长度的序列。列表有大量的内置行为,以及用于表达这些行为的特定语法。我们已经见过列表字面量(list literal),它的计算结果是一个 list 实例,以及一个计算结果为列表中元素值的元素选择表达式。list 内置的 len 函数返回序列的长度。如下,digits 是一个包含四个元素的列表,索引为 3 的元素是 8。
>>> digits = [1, 8, 2, 8]
>>> len(digits)
4
>>> digits[3]
8
此外,多个列表间可以相加,并且列表可以乘以整数。对于序列来说,加法和乘法并不是作用在内部元素上的,而是对序列自身进行组合和复制。也就是说,operator 模块中的 add 函数(和 + 运算符)会生成一个为传入列表串联的新列表。operator 中的 mul 函数(和 * 运算符)可接收原列表和整数 k 来返回一个内容为原列表内容 k 次重复的新列表。
>>> [2, 7] + digits * 2
[2, 7, 1, 8, 2, 8, 1, 8, 2, 8]


任何值都可以包含在一个列表中,包括另一个列表。在嵌套列表中可以应用多次元素选择,以选择深度嵌套的元素。
>>> pairs = [[10, 20], [30, 40]]
>>> pairs[1]
[30, 40]
>>> pairs[1][0]
30
1.2、序列遍历
在许多情况下,我们希望依次遍历序列的元素并根据元素值执行一些计算。这种情况十分常见,所以 Python 提供了一个额外的控制语句来处理序列的数据:for 循环语句。
考虑统计一个值在序列中出现了多少次的问题。我们可以使用 while 循环实现一个函数。
>>> def count(s, value):"""统计在序列 s 中出现了多少次值为 value 的元素"""total, index = 0, 0while index < len(s):if s[index] == value:total = total + 1index = index + 1return total
>>> count(digits, 8)
2Python 的 for 循环可以通过直接遍历元素值来简化函数,相比 while 循环无需引入变量名 index。
>>> def count(s, value):"""统计在序列 s 中出现了多少次值为 value 的元素"""total = 0for elem in s:if elem == value:total = total + 1return total
>>> count(digits, 8)
2一个 for 循环语句由如下格式的单个子句组成:
for <name> in <expression>:<suite>for 循环语句按以下过程执行:
- 执行头部(header)中的
<expression>,它必须产生一个可迭代(iterable)的值 - 对该可迭代值中的每个元素,按顺序:
- 将当前帧的
<name>绑定到该元素值 - 执行
<suite>
- 将当前帧的
此执行过程中使用了可迭代值。列表是序列的一种,而序列是可迭代值,它们中的元素按其顺序进行迭代。Python 还包括其它可迭代类型,但我们现在将重点介绍序列。
这个计算过程中的一个重要结果是:执行 for 语句后,<name> 将绑定到序列的最后一个元素。所以 for 循环引入了另一种可以通过语句更新环境的方法。
序列解包(Sequence unpacking):程序中的一个常见情况是序列的元素也是序列,但所有内部序列的长度是固定相同的。for 循环可以在头部的 <name> 中包含多个名称,来将每个元素序列“解包”到各自的元素中。
例如,我们可能有一个包含以列表为元素的 pairs,其中所有内部列表都只包含 2 个元素。
>>> pairs = [[1, 2], [2, 2], [2, 3], [4, 4]]此时我们希望找到有多少第一元素和第二元素相同的内部元素对,下面的 for 循环在头部中包括两个名称,将 x 和 y 分别绑定到每对中的第一个元素和第二个元素。
>>> same_count = 0
>>> for x, y in pairs:if x == y:same_count = same_count + 1
>>> same_count
2这种将多个名称绑定到固定长度序列中的多个值的模式称为序列解包(sequence unpacking),这与赋值语句中将多个名称绑定到多个值的模式类似。
范围(Ranges):range 是 Python 中的另一种内置序列类型,用于表示整数范围。范围是用 range 创建的,它有两个整数参数:起始值和结束值加一。(其实可以有三个参数,第三个参数为步长,感兴趣可以自行搜索)
>>> range(1, 10) # 包括 1,但不包括 10
range(1, 10)将 range 的返回结果传入 list 构造函数,可以构造出一个包含该 range 对象中所有值的列表,从而简单的查看范围中包含的内容。
>>> list(range(5, 8))
[5, 6, 7]如果只给出一个参数,参数将作为双参数中的“结束值加一”,获得从 0 到结束值的范围。(其实单参数就相当于默认了起始值从 0 开始)
>>> list(range(4))
[0, 1, 2, 3]范围通常出现在 for 循环头部中的表达式,以指定 <suite> 应执行的次数。一个惯用的使用方式是:如果 <name> 没有在 <suite> 中被使用到,则用下划线字符 "_" 作为 <name>。
>>> for _ in range(3):print('Go Bears!')Go Bears!
Go Bears!
Go Bears!对解释器而言,这个下划线只是环境中的另一个名称,但对程序员具有约定俗成的含义,表示该名称不会出现在任何未来的表达式中。
1.3、序列处理
序列是复合数据的一种常见形式,常见到整个程序都可能围绕着这个单一的抽象来组织。具有序列作为输入输出的模块化组件可以混用和匹配以实现数据处理。将序列处理流程中的所有操作链接在一起可以定义复杂组件,其中每个操作都是简单和集中的。
列表推导式(List Comprehensions):许多序列操作可以通过对序列中的每个元素使用一个固定表达式进行计算,并将结果值保存在结果序列中。在 Python 中,列表推导式是执行此类计算的表达式。
>>> odds = [1, 3, 5, 7, 9]
>>> [x+1 for x in odds]
[2, 4, 6, 8, 10]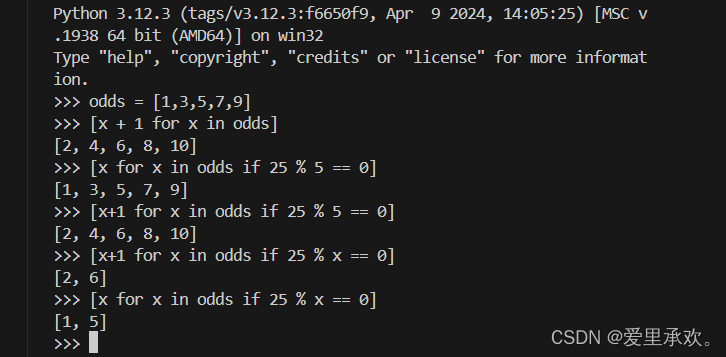
上面的 for 关键字并不是 for 循环的一部分,而是列表推导式的一部分,因为它被包含在方括号里。子表达式 x+1 通过绑定到 odds 中每个元素的变量 x 进行求值,并将结果值收集到列表中。
另一个常见的序列操作是选取原序列中满足某些条件的值。列表推导式也可以表达这种模式,例如选择 odds 中所有可以整除 25 的元素。
>>> [x for x in odds if 25 % x == 0]
[1, 5]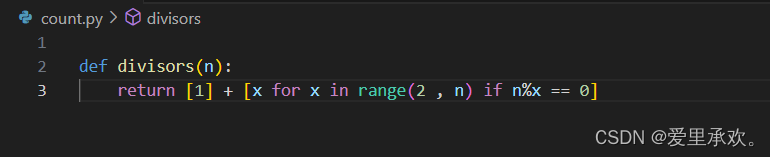

列表推导式的一般形式是:
[<map expression> for <name> in <sequence expression> if <filter expression>]为了计算列表推导式,Python 首先执行 <sequence expression>,它必须返回一个可迭代值。然后将每个元素值按顺序绑定到 <name>,再执行 <filter expression>,如果结果为真值,则计算 <map expression>,<map expression> 的结果将被收集到结果列表中。
聚合(Aggregation):序列处理中的第三种常见模式是将序列中的所有值聚合为一个值。内置函数 sum、min 和 max 都是聚合函数的示例。
通过组合对每个元素进行计算、选择元素子集和聚合元素的模式,我们就可以使用序列处理的方法解决问题。
完美数是等于其约数之和的正整数。n 的约数指的是小于 n 且可以整除 n 的正整数。可以使用列表推导式来列出 n 的所有约数。
>>> def divisors(n):return [1] + [x for x in range(2, n) if n % x == 0]>>> divisors(4)
[1, 2]
>>> divisors(12)
[1, 2, 3, 4, 6]通过 divisors,我们可以使用另一个列表推导式来计算 1 到 1000 的所有完美数。(1 通常也被认为是一个完美数,尽管它不符合我们对约数的定义。)
>>> [n for n in range(1, 1000) if sum(divisors(n)) == n]
[1, 6, 28, 496]我们可以重用定义的 divisors 来解决另一个问题:在给定面积的情况下计算具有整数边长的矩形的最小周长。矩形的面积等于它的高乘以它的宽,因此给定面积和高度,我们可以计算出宽度。
使用 assert 可以规定宽度和高度都能整除面积,以确保边长是整数。
>>> def width(area, height):assert area % height == 0return area // height矩形的周长是其边长之和,由此我们可以定义 perimeter。
>>> def perimeter(width, height):return 2 * width + 2 * height对于边长为整数的矩形来说,高度必是面积的约数,所以我们可以考虑所有可能的高度来计算最小周长。
>>> def minimum_perimeter(area):heights = divisors(area)perimeters = [perimeter(width(area, h), h) for h in heights]return min(perimeters)>>> area = 80
>>> width(area, 5)
16
>>> perimeter(16, 5)
42
>>> perimeter(10, 8)
36
>>> minimum_perimeter(area)
36
>>> [minimum_perimeter(n) for n in range(1, 10)]
[4, 6, 8, 8, 12, 10, 16, 12, 12]高阶函数(Higher-Order Functions):序列处理中常见的模式可以使用高阶函数来表示。首先可以将对序列中每个元素进行表达式求值表示为将某个函数应用于序列中每个元素。
>>> def apply_to_all(map_fn, s):return [map_fn(x) for x in s]仅选择满足表达式条件的元素也可以通过对每个元素应用函数来表示。
>>> def keep_if(filter_fn, s):return [x for x in s if filter_fn(x)]最后,许多形式的聚合都可以被表示为:将双参数函数重复应用到 reduced 值,并依次对每个元素应用。
>>> def reduce(reduce_fn, s, initial):reduced = initialfor x in s:reduced = reduce_fn(reduced, x)return reduced例如,reduce 可用于将序列内的所有元素相乘。使用 mul 作为 reduce_fn,1 作为初始值,reduce 可用于将序列内的数字相乘。
>>> reduce(mul, [2, 4, 8], 1)
64同样也可以用这些高阶函数来寻找完美数。
>>> def divisors_of(n):divides_n = lambda x: n % x == 0return [1] + keep_if(divides_n, range(2, n))>>> divisors_of(12)
[1, 2, 3, 4, 6]
>>> from operator import add
>>> def sum_of_divisors(n):return reduce(add, divisors_of(n), 0)>>> def perfect(n):return sum_of_divisors(n) == n>>> keep_if(perfect, range(1, 1000))
[1, 6, 28, 496]约定俗成的名字(Conventional Names):在计算机科学中,apply_to_all 更常用的名称是 map,而 keep_if 更常用的名称是 filter。Python 中内置的 map 和 filter 是以上函数的不以列表为返回值的泛化形式,这些函数在第 4 章中介绍。上面的定义等效于将内置 map 和 filter 函数的结果传入 list 构造函数。
>>> apply_to_all = lambda map_fn, s: list(map(map_fn, s))
>>> keep_if = lambda filter_fn, s: list(filter(filter_fn, s))reduce 函数内置于 Python 标准库的 functools 模块中。在此版本中,initial 参数是可选的。
>>> from functools import reduce
>>> from operator import mul
>>> def product(s):return reduce(mul, s)>>> product([1, 2, 3, 4, 5])
120在 Python 程序中,更常见的是直接使用列表推导式而不是高阶函数,但这两种序列处理方法都被广泛使用。
1.4、序列抽象
成员资格(Membership):可用于测试某个值在序列中的成员资格。Python 有两个运算符 in 和 not in,它们的计算结果为 True 或 False,取决于元素是否出现在序列中。
>>> digits
[1, 8, 2, 8]
>>> 2 in digits
True
>>> 1828 not in digits
True切片(Slicing):一个切片是原始序列的任意一段连续范围,由一对整数指定。和 range 构造函数一样,第一个整数表示起始索引,第二个整数是结束索引加一。(译者注:和前面的 range 一样,其实还有第三个参数代表步长,最经典的例子是使用 s[::-1] 得到 s 的逆序排列,具体可以自行搜索)
在 Python 中,序列切片的表达方式类似于元素选择,都使用方括号,方括号中的冒号用于分隔起始索引和结束索引。
如果起始索引或结束索引被省略则默认为极值:当起始索引被省略,则起始索引为 0;当结束索引被省略,则结束索引为序列长度,即取到序列最后一位。
>>> digits[0:2]
[1, 8]
>>> digits[1:]
[8, 2, 8]1.5、字符串
Python 中文本值的内置数据类型称为字符串(string),对应构造函数 str。在 Python 中,表示、表达和操作字符串的细节有很多。
字符串字面量(string literals)可以表示任意文本,使用时将内容用单引号或双引号括起来。
>>> 'I am string!'
'I am string!'
>>> "I've got an apostrophe"
"I've got an apostrophe"
>>> '您好'
'您好'我们已经在代码中看到过字符串,比如文档字符串(docstring)、print 的调用中,以及 assert 语句中的错误消息。
字符串同样满足我们在本节开头介绍的序列的两个基本条件:它们具有长度且支持元素选择。字符串中的元素是只有一个字符的字符串。字符可以是字母表中的任何单个字母、标点符号或其他符号。
与其他编程语言不同,Python 没有单独的字符类型,任何文本都是字符串。表示单个字符的字符串的长度为 1。
>>> city = 'Berkeley'
>>> len(city)
8
>>> city[3]
'k'与列表一样,字符串也可以通过加法和乘法进行组合。
>>> 'Berkeley' + ', CA'
'Berkeley, CA'
>>> 'Shabu ' * 2
'Shabu Shabu '成员资格(Membership):字符串的行为与 Python 中的其他序列类型有所不同。字符串抽象不符合我们对列表和范围描述的完整序列抽象。具体来说,成员运算符 in 应用于字符串时的行为与应用于序列时完全不同,它匹配的是子字符串而不是元素。(如果字符串的行为和列表的一样,则应该匹配字符串的元素,即单个字符,但实际上匹配的是任意子字符串)
>>> 'here' in "Where's Waldo?"
True
多行字面量(Multiline Literals):字符串可以不限于一行。跨越多行的字符串字面量可以用三重引号括起,我们已经在文档字符串中广泛使用了这种三重引号。
>>> """The Zen of Python
claims, Readability counts.
Read more: import this."""
'The Zen of Python\nclaims, "Readability counts."\nRead more: import this.'在上面的打印结果中,\n(读作“反斜杠 n”)是一个表示换行的单个元素。尽管它显示为两个字符(反斜杠和 "n" ),但为了便于计算长度和元素选择,它被视为单个字符。
字符串强制转换(String Coercion):通过以对象值作为参数调用 str 的构造函数,可以从 Python 中的任何对象创建字符串。字符串的这一特性在用构造各种类型对象的描述性字符串时非常有用。
>>> str(2) + ' is an element of ' + str(digits)
'2 is an element of [1, 8, 2, 8]'二、数据抽象
2.1、示例:有理数
有理数是整数的比值,并且有理数是实数的一个重要子类。 1/3 或 17/29 等有理数通常写为:
<分子>/<分母>其中 <分子> 和 <分母> 都是整数值的占位符,这两个部分能够准确表示有理数的值。实际上的整数除以会产生 float 近似值,失去整数的精确精度。
>>> 1/3
0.3333333333333333
>>> 1/3 == 0.333333333333333300000 # 整数除法得到近似值
True但是,我们可以通过将分子和分母组合在一起来创建有理数的精确表示。
通过使用函数抽象,我们可以在实现程序的某些部分之前开始高效地编程。我们首先假设已经存在了一个从分子和分母构造有理数的方法,再假设有方法得到一个给定有理数的分子和分母。进一步假设得到以下三个函数:
rational(n, d)返回分子为n、分母为d的有理数numer(x)返回有理数x的分子denom(x)返回有理数x的分母
我们在这里使用了一个强大的程序设计策略:一厢情愿(wishful thinking)。即使我们还没有想好有理数是如何表示的,或者函数 numer、denom 和 rational 应该如何实现。但是如果我们确实定义了这三个函数,我们就可以进行加法、乘法、打印和测试有理数是否相等:
>>> def add_rationals(x, y):nx, dx = numer(x), denom(x)ny, dy = numer(y), denom(y)return rational(nx * dy + ny * dx, dx * dy)>>> def mul_rationals(x, y):return rational(numer(x) * numer(y), denom(x) * denom(y))>>> def print_rational(x):print(numer(x), '/', denom(x))>>> def rationals_are_equal(x, y):return numer(x) * denom(y) == numer(y) * denom(x)现在我们有了选择器函数 numer 和 denom 以及构造函数 rational 定义的有理数运算,但还没有定义这些函数。我们需要某种方法将分子和分母粘合在一起形成一个复合值。
2.2、对
为了使我们能够实现具体的数据抽象,Python 提供了一个名为 list 列表的复合结构,可以通过将表达式放在以逗号分隔的方括号内来构造。这样的表达式称为列表字面量。
>>> [10, 20]
[10, 20]可以通过两种方式访问 列表元素。第一种方法是通过我们熟悉的多重赋值方法,它将列表解构为单个元素并将每个元素与不同的名称绑定。
>>> pair = [10, 20]
>>> pair
[10, 20]
>>> x, y = pair
>>> x
10
>>> y
20访问列表中元素的第二种方法是通过元素选择运算符,也使用方括号表示。与列表字面量不同,直接跟在另一个表达式之后的方括号表达式不会计算为 list 值,而是从前面表达式的值中选择一个元素。
>>> pair[0]
10
>>> pair[1]
20Python 中的列表(以及大多数其他编程语言中的序列)是从 0 开始索引的,这意味着索引 0 选择第一个元素,索引 1 选择第二个元素,以此类推。对于这种索引约定的一种直觉是,索引表示元素距列表开头的偏移量。
元素选择运算符的等效函数称为 getitem ,它也使用 0 索引位置从列表中选择元素。
>>> from operator import getitem
>>> getitem(pair, 0)
10
>>> getitem(pair, 1)
20双元素列表并不是 Python 中表示对的唯一方法。将两个值捆绑在一起成为一个值的任何方式都可以被认为是一对。列表是一种常用的方法,它也可以包含两个以上的元素,我们将在本章后面进行探讨。
代表有理数:我们现在可以将有理数表示为两个整数的对:一个分子和一个分母。
>>> def rational(n, d):return [n, d]>>> def numer(x):return x[0]>>> def denom(x):return x[1]连同之前定义的算术运算,我们可以使用我们定义的函数来操作有理数。
>>> half = rational(1, 2)
>>> print_rational(half)
1 / 2
>>> third = rational(1, 3)
>>> print_rational(mul_rationals(half, third))
1 / 6
>>> print_rational(add_rationals(third, third))
6 / 9如上面的示例所示,我们的有理数实现不会将有理数简化为最小项。可以通过更改 rational 的实现来弥补这个缺陷。如果我们有一个计算两个整数的最大公分母的函数,我们可以用它在构造对之前将分子和分母减少到最低项。与许多有用的工具一样,这样的功能已经存在于 Python 库中。
>>> from fractions import gcd # python3.10变from math import gcd
>>> def rational(n, d):g = gcd(n, d)return (n//g, d//g)// 表示整数除法,它会将除法结果的小数部分向下舍入。因为我们知道 g 会将 n 和 d 均分,所以在这种情况下整数除法是精确的。这个修改后的 rational 实现会确保有理数以最小项表示。
>>> print_rational(add_rationals(third, third))
2 / 3这种改进是通过更改构造函数而不更改任何实现实际算术运算的函数来实现的。
2.3、抽象屏障
在继续更多复合数据和数据抽象的示例之前,让我们考虑一下有理数示例引发的一些问题。我们根据构造函数 rational 和选择器函数 numer 和 denom 来定义操作。一般来说,数据抽象的基本思想是确定一组基本操作,根据这些操作可以表达对某种值的所有操作,然后仅使用这些操作来操作数据。通过以这种方式限制操作的使用,在不改变程序行为的情况下改变抽象数据的表示会容易得多。
对于有理数,程序的不同部分使用不同的操作来处理有理数,如此表中所述。
| 该程序的一部分... | 把有理数当作... | 仅使用... |
|---|---|---|
| 使用有理数进行计算 | 整个数据值 | add_rational, mul_rational, rationals_are_equal, print_rational |
| 创建有理数或操作有理数 | 分子和分母 | rational, numer, denom |
| 为有理数实现选择器和构造器 | 二元列表 | 列表字面量和元素选择 |
在上面的每一层中,最后一列中的函数会强制实施抽象屏障(abstraction barrier)。这些功能会由更高层次调用,并使用较低层次的抽象实现。
当程序中有一部分本可以使用更高级别函数但却使用了低级函数时,就会违反抽象屏障。例如,计算有理数平方的函数最好用 mul_rational 实现,它不对有理数的实现做任何假设。
>>> def square_rational(x):return mul_rational(x, x)直接引用分子和分母会违反一个抽象屏障。
>>> def square_rational_violating_once(x):return rational(numer(x) * numer(x), denom(x) * denom(x))假设有理数会表示为双元素列表将违反两个抽象屏障。
>>> def square_rational_violating_twice(x):return [x[0] * x[0], x[1] * x[1]]抽象屏障使程序更易于维护和修改。依赖于特定表示的函数越少,想要更改该表示时所需的更改就越少。计算有理数平方的所有这些实现都具有正确的行为,但只有第一个函数对未来的更改是健壮的。即使我们修改了有理数的表示,square_rational 函数也不需要更新。相比之下,当选择器函数或构造函数签名发生变化后,square_rational_violating_once 就需要更改,而只要有理数的实现发生变化,square_rational_violating_twice 就需要更新。
2.4、数据的属性
抽象屏障塑造了我们思考数据的方式。有理数的表示不限于任何特定的实现(例如二元素列表);它就是由 rational 返回的值,然后可以传递给 numer 和 denom 。此外,构造器和选择器之间必须保持适当的关系。也就是说,如果我们从整数 n 和 d 构造一个有理数 x ,那么 numer(x)/denom(x) 应该等于 n/d 。
通常,我们可以使用选择器和构造器的集合以及一些行为条件来表达抽象数据。只要满足行为条件(比如上面的除法属性),选择器和构造器就构成了一种数据的有效表示。抽象屏障下的实现细节可能会改变,但只要行为没有改变,那么数据抽象就仍然有效,并且使用该数据抽象编写的任何程序都将保持正确。
这种观点可以广泛应用,包括我们用来实现有理数的对。我们从来没有真正谈论什么是一对,只是语言提供了创建和操作二元列表的方法。我们需要实现一对的行为是它将两个值粘合在一起。作为一种行为条件,
- 如果一对
p由值x和y构成,则select(p, 0)返回x,select(p, 1)返回y
我们实际上并不一定需要 list 类型来创建对,作为替代,我们可以用两个函数 pair 和 select 来实现这个描述以及一个二元列表。
>>> def pair(x, y):"""Return a function that represents a pair."""def get(index):if index == 0:return xelif index == 1:return yreturn get>>> def select(p, i):"""Return the element at index i of pair p."""return p(i)通过这个实现,我们可以创建和操作对。
>>> p = pair(20, 14)
>>> select(p, 0)
20
>>> select(p, 1)
14这种高阶函数的使用完全不符合我们对数据应该是什么的直觉概念。但尽管如此,这些函数足以在我们的程序中表示对,也足以表示复合数据。
这种表示对的函数表示的重点并不是 Python 实际上以这种方式工作(出于效率原因,列表更直接地实现),而是它可以以这种方式工作。函数表示虽然晦涩难懂,但却是表示对的一个完全合适的方法,因为它满足了表示对需要满足的唯一条件。数据抽象的实践使我们能够轻松地在表示之间切换。
2.5、字典
字典(Dictionary)是 Python 的内置类型,用来存储和操作带有映射关系的数据。一个字典包含一组键值对(key-value pairs),其中键和值都是对象。字典的主要目的是抽象一组基于键值对的数据,在字典中,数据的存取都是基于带有描述性信息的键而不是连续递增的数字。
字典的 key 一般都是字符串(String),因为我们习惯用字符串来表示某个事物的名称。下面这个字典字面量表示了一组罗马数字:
>>> numerals = {'I': 1.0, 'V': 5, 'X': 10}在字典元素中查找某个 key 对应的 value,与我们之前在列表中使用的操作符相同:
>>> numerals['X']
10在字典中,一个 key 只能对应一个 value。无论是向字典中增加新的键值对,还是修改某个 key 值对应的 value,都可以使用赋值语句实现:
>>> numerals['I'] = 1
>>> numerals['L'] = 50
>>> numerals
{'I': 1, 'X': 10, 'L': 50, 'V': 5}注意上面的打印输出,'L' 并没有被插入到字典的末尾。字典是无序的。当我们打印一个字典的时候,键值对会以某种顺序被渲染在页面上,但作为 Python 语言的使用者,我们无法预测这个顺序是什么样的。如果我们多运行几次这个程序,字典输出的顺序可能会有所变化。
Python 3.7 及以上版本的字典顺序会确保为插入顺序,此行为是自 3.6 版开始的 CPython 实现细节,字典会保留插入时的顺序,对键的更新也不会影响顺序,删除后再次添加的键将被插入到末尾
字典类型也提供了一系列遍历字典内容的方法。keys、values 和 items 方法都返回一个可以被遍历的值。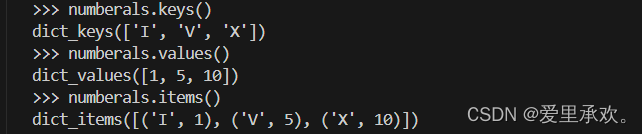
>>> sum(numerals.values())
66利用 dictionary 构造方法,我们可以将一个由键值对组成的列表转化为一个字典对象。
>>> dict([(3, 9), (4, 16), (5, 25)])
{3: 9, 4: 16, 5: 25}但是字典类型也有一些限制:
- 字典的 key 不可以是可变数据,也不能包含可变数据
- 一个 key 只能对应一个 value
第一个限制是由于字典在 Python 内部的实现机制导致的。字典类型具体的实现机制不在这里展开。简单来说,假设是 key 值告诉 Python 应该去内存中的什么位置找对应的键值对,如果 key 值本身发生了变化,那键值对在内存中的位置信息也就丢失了。比如,元组可以被用来做字典的 key 值,但是列表就不可以。
第二个限制是因为字典本身被设计为根据 key 去查找 value,只有 key 和 value 的绑定关系是唯一确定的,我们才能够找到对应的数据。
字典中一个很有用的方法是 get,它返回指定 key 在字典中对应的 value;如果该 key 在字典中不存在,则返回默认值。get 方法接收两个参数,一个 key,一个默认值。
>>> numerals.get('A', 0)
0
>>> numerals.get('V', 0)
5与列表类似,字典也有推导式语法。其中,key 和 value 使用冒号分隔。字典推导式会创建一个新的字典对象。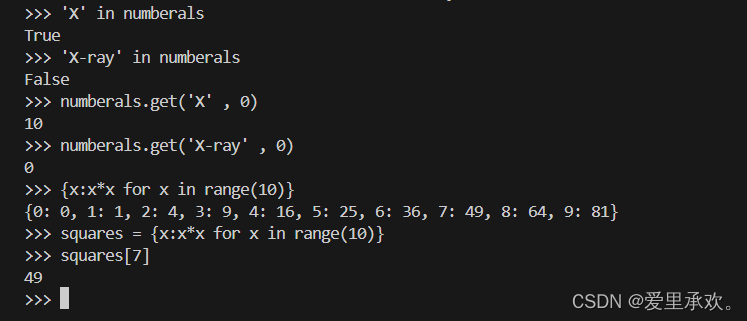
>>> {x: x*x for x in range(3,6)}
{3: 9, 4: 16, 5: 25}
键不可以是列表、字典或语言中任何可变类型。