1、什么是RDD
RDD:英文全称Resilient Distributed Dataset,叫做弹性分布式数据集,代表一个不可变、可分区、里面的元素可并行计算的分布式的抽象的数据集合。
-
Resilient弹性:RDD的数据可以存储在内存或者磁盘当中,RDD的数据可以分区
-
Distributed分布式:RDD的数据可以分布式存储,可以进行并行计算
-
Dataset数据集:一个用于存放数据的集合
2、RDD的五大特性
1、(必须的)RDD是由一系列分区组成的 2、(必须的)对RDD做计算,相当于对RDD的每个分区做计算 3、(必须的)RDD之间存在着依赖关系(宽依赖和窄依赖) 4、(可选的)对于KV类型的RDD,默认操作的是k,当然我们可以进行自定义分区方案 5、(可选的)移动数据不如移动计算,让计算程序离数据越近越好
3、RDD的五大特点
1、分区:RDD逻辑上是分区的,仅仅是定义分区的规则,并不是直接对数据进行分区操作,因为RDD本身不存储数据。 2、只读:RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD。 3、依赖:RDD之间存在着依赖关系(宽依赖和窄依赖) 4、cache缓存:如果在应用程序中多次使用同一个RDD,可以将该RDD缓存起来,该RDD只有在第一次计算的时候会根据血缘关系得到分区的数据,后续每次直接从缓存获取即可 5、checkpoint检查点:与缓存类似的,都是可以将中间某一个RDD的结果保存起来,只不过checkpoint支持真正持久化保存
如何构建RDD
构建RDD对象的方式主要有两种:
1、通过 parallelize(data): 通过自定义列表的方式初始化RDD对象。(一般用于测试) 2、通过 textFile(data): 通过读取外部文件的方式来初始化RDD对象,实际工作中经常使用。
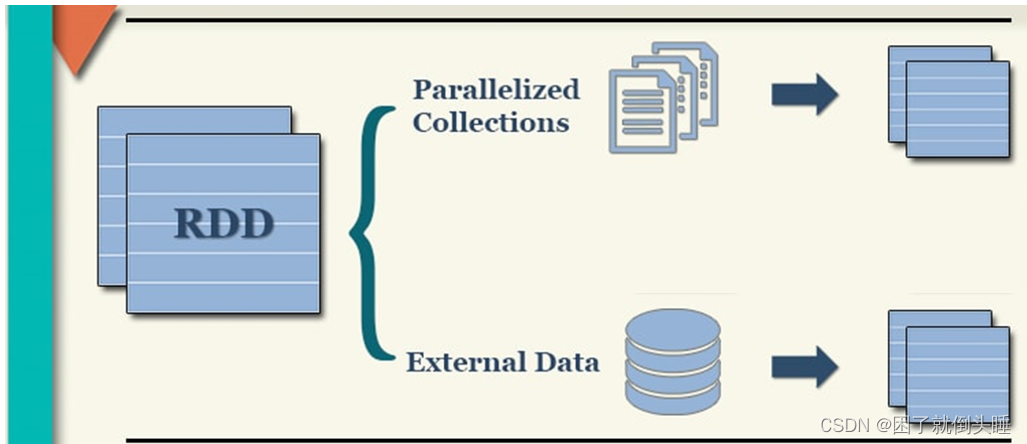
1、并行化本地集合方式
黑窗口中实现:
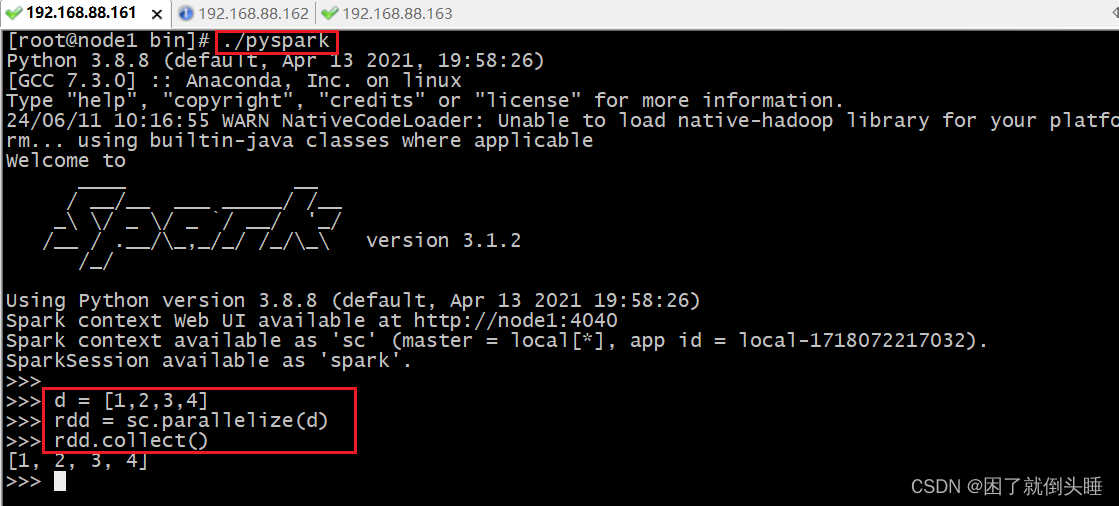
开发工具实现:
# 导包
import os
from pyspark import SparkConf, SparkContext
# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':# 1.创建SparkContext对象conf = SparkConf().setAppName('pyspark_demo').setMaster('local[3]')sc = SparkContext(conf=conf)
# 2.数据输入# 3.数据处理(切分,转换,分组聚合)d = [1, 2, 3, 4]rdd = sc.parallelize(d,numSlices=1)# 4.数据输出print(rdd.collect())# 6.分区演示# 获取分区数print(rdd.getNumPartitions())# 获取各个分区数据print(rdd.glom().collect())
# 5.关闭资源sc.stop()
相关的API:
# parallelize(参数1,参数2) 使用本地数据构建RDD。参数1:本地数据列表;参数2:可选的,表示有多少个分区 # getNumPartitions 查看RDD的分区数量 # glom 查看每个分区的数据内容
修改分区数,效果:
1- 默认和setMaster('local[num]')中的num数量有关。如果是*,就是和机器的CPU核数相同。另外可以指定具体的数字,数字是多少,那么分区数就是多少
2- parallelize()中第二个参数numSlices可以手动指定RDD的分区数。如果同时设置了local和numSlices,numSlices的优先级高一些
2、读取外部数据源方式
TextFile API的方式实现:
# 导包
import os
from pyspark import SparkConf, SparkContext
# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':# 1.创建SparkContext对象conf = SparkConf().setAppName('pyspark_demo').setMaster('local[3]')sc = SparkContext(conf=conf)
# 2.数据输入# 3.数据处理(切分,转换,分组聚合)# 注意: 如果要提交到yarn,文件建议使用hdfs路径rdd = sc.textFile('hdfs://node1:8020/source/c1.txt',minPartitions=1)# 4.数据输出print(rdd.collect())# 6.分区演示# 获取分区数print(rdd.getNumPartitions())# 获取各个分区数据print(rdd.glom().collect())
# 5.关闭资源sc.stop()
修改分区数,效果:
到底有多少个分区,一切以getNumPartitions结果为准 分区数据量,当调大local[num]中num的值时候,不生效;调小的时候生效 同时也受minPartitions影响
3、处理小文件的操作
wholeTextFiles: wholeTextFiles既能直接读取文件,也能读取一个目录下的所有小文件
# 导包
import os
from pyspark import SparkConf, SparkContext# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'# 创建main函数
if __name__ == '__main__':# 1.创建SparkContext对象conf = SparkConf().setAppName('pyspark_demo').setMaster('local[10]')sc = SparkContext(conf=conf)# 2.数据输入# 3.数据处理(切分,转换,分组聚合)# 注意: 如果要提交到yarn,文件建议使用hdfs路径# 注意: wholeTextFiles既能直接读取文件,也能读取一个目录下的所有小文件rdd = sc.wholeTextFiles('hdfs://node1:8020/source/c1.txt')# 4.数据输出print(rdd.collect())# 6.分区演示# 获取分区数print(rdd.getNumPartitions())# 获取各个分区数据print(rdd.glom().collect())# 5.关闭资源sc.stop()
修改分区数,效果:
wholeTextFiles: 读取小文件。1-支持本地文件系统和HDFS文件系统。参数minPartitions指定最小的分区数。2-通过该方式读取文件,会尽可能使用少的分区数,可能会将多个小文件的数据放到同一个分区中进行处理。3-一个文件要完整的存放在一个元组中,也就是不能将一个文件分成多个进行读取。文件是不可分割的。4-RDD分区数量既受到minPartitions参数的影响,同时受到小文件个数的影响
4、RDD分区数量如何确定
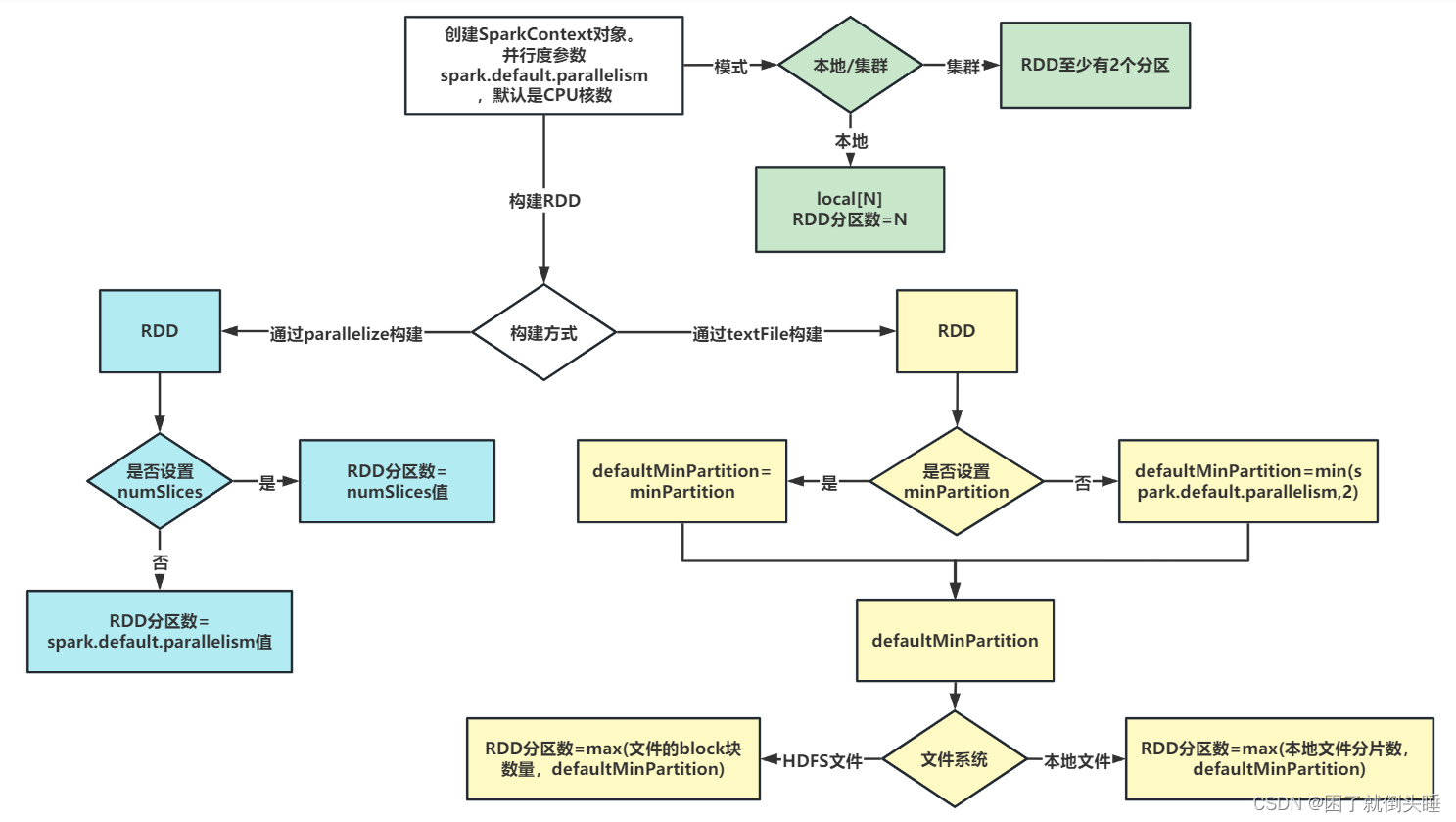
1- RDD的分区数量,一般设置为机器CPU核数的2-3倍。为了充分利用服务器的硬件资源
2- RDD的分区数据量受到多个因素的影响,例如:机器CPU的核数、调用的算子、算子中参数的设置、集群的类型等。RDD具体有多少个分区,直接通过getNumPartitions查看
3- 当初始化SparkContext对象的时候,其实就确定了一个参数spark.default.parallelism,默认为CPU的核数。如果是本地集群,就取决于local[num]中设置的数字大小;如果是集群,默认至少有2个分区
4- 通过parallelize来构建RDD,如果没有指定分区数,默认就取spark.default.parallelism参数值;如果指定了分区数,也就是numSlices参数,那么numSlices的优先级会更高一些,最终RDD的分区数取该参数的值。
5- 通过textFile来构建RDD
5.1- 首先确认defaultMinPartition参数的值。该参数的值,如果没有指定textFile的minPartition参数,那么就根据公式min(spark.default.parallelism,2);如果有指定textFile的minPartition参数,那么就取设置的值
5.2- 再根据读取文件所在的文件系统的不同,来决定最终RDD的分区数:
5.2.1- 本地文件系统: RDD分区数 = max(本地文件分片数,defaultMinPartition)
5.2.2- HDFS文件系统: RDD分区数 = max(文件block块的数量,defaultMinPartition)
常规处理小文件的办法: 1- 大数据框架提供的现有的工具或者命令 1.1- 合并hdfs中多个小文件到linux本地: hadoop fs -getmerge 小文件路径 linux输出路径/文件名.后缀名
举例: [root@node1 ~]# hadoop fs -getmerge /data/*.txt /merged_file.txt
1.2- 归档hdfs中多个小文件到hdfs: hadoop archive -archiveName 归档名.har -p 小文件路径 hdfs输出路径
举例: [root@node1 ~]# hadoop archive -archiveName merged_file.har -p /data/ /
2- 可以通过编写自定义的代码,将小文件读取进来,在代码中输出的时候,输出形成大的文件
![[Leetcode 136][Easy]-只出现一次的数字](https://img-blog.csdnimg.cn/direct/9683f9b9cb97453e9b4a0ba9a726db96.png)