摘要:本文整理自Apache Yarn && Flink Contributor,阿里巴巴智能引擎事业部技术专家王伟骏(鸿历)老师在 5月16日 Streaming Lakehouse Meetup · Online 上的分享。内容主要分为以下三个部分:
一、 阿里智能引擎 AI 业务背景介绍
二、 引入 Paimon 原因、场景及预期收益
三、 遇到的问题及解法
一、阿里智能引擎 AI 业务背景介绍
首先介绍一下阿里智能引擎事业部中AI相关的业务背景。
1、 业务场景及特点
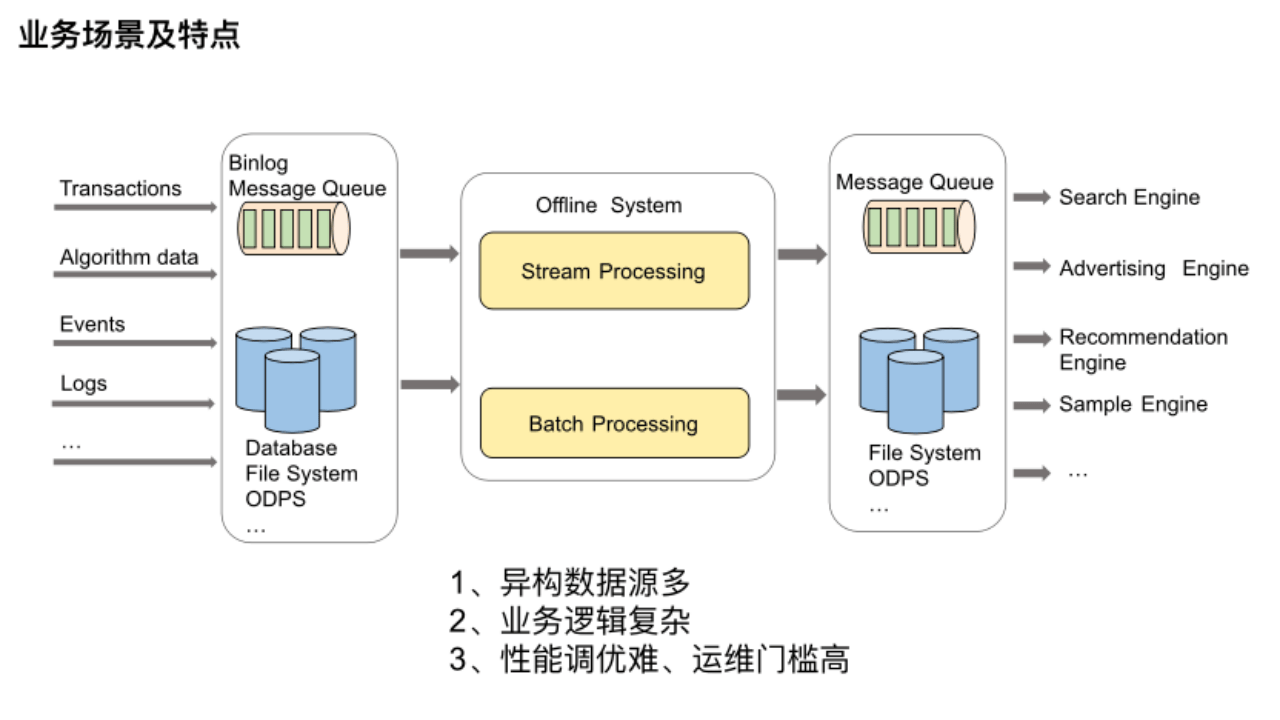 我们平台支持多种大数据离线处理链路,比如说搜推广链路、算法工程链路、模型推理链路等,这些数据处理链路的业务场景基本可以涵盖为上述图示流程。
我们平台支持多种大数据离线处理链路,比如说搜推广链路、算法工程链路、模型推理链路等,这些数据处理链路的业务场景基本可以涵盖为上述图示流程。
最左边是各种搜推广等引擎依赖的原始数据,主要来源于业务的事务数据、算法数据以及用户的点击事件日志等等,它们分布在不同的存储系统中。最右边的引擎想利用这些数据就需要一个离线系统,将不同维度的数据聚合到一起,以提供给不同的引擎使用。可以设想一下要开发这样一个离线系统,需要面临哪些痛点及难点。
(1) 异构数据源多:数据源来源于众多异构数据源,所以我们需要对接各类存储引擎,以此横向扩展平台的功能。
(2) 业务逻辑复杂:业务逻辑非常复杂,所以流批很难一体,很难做到多个批流作业之间的无缝完美衔接。
(3) 性能调优难、运维门槛高:在性能和运维方面由于涉及大数据组件非常多,需要了解很多计算引擎及存储系统的内部实现细节,所以运维排查问题困难,作业性能调优要考虑的因素也很多。
2、 产品介绍及成果
为了降低业务离线开发和运维的门槛,减少业务接入的成本和提高业务迭代的效率,我们研发和建设了大数据离线处理平台,提供 AI 领域端到端的 ETL 数据处理解决方案。
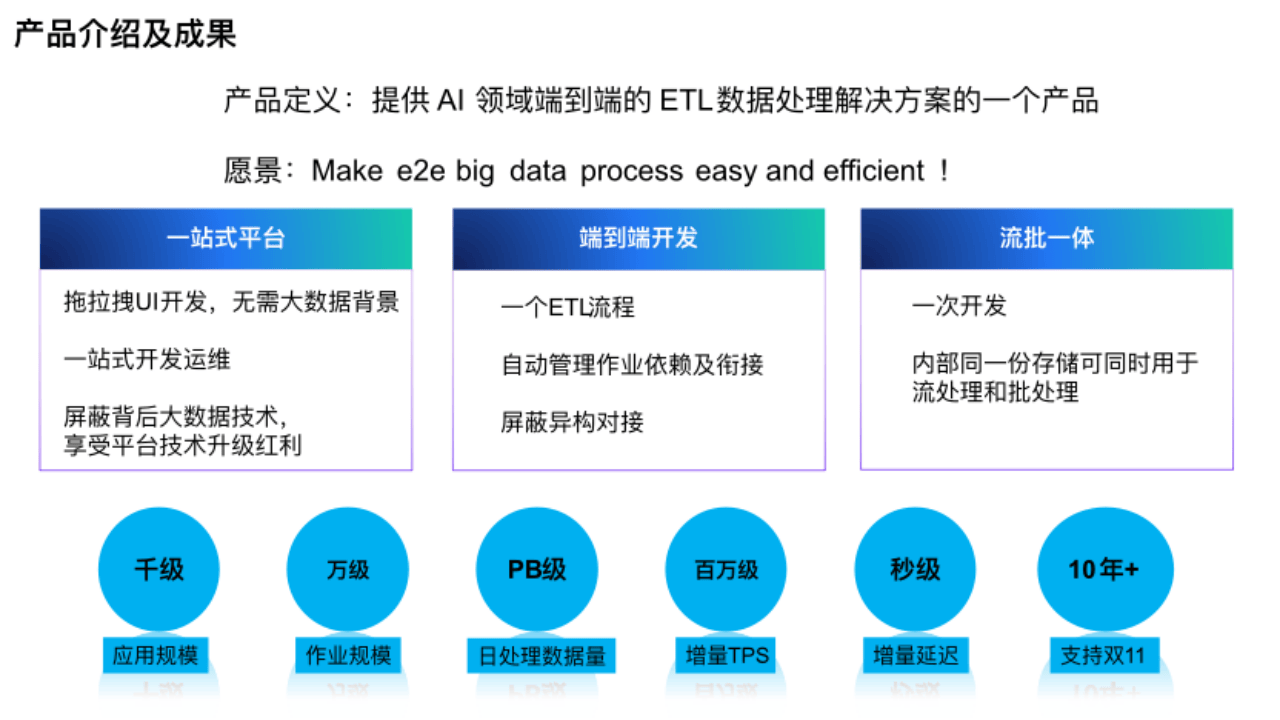
(1)一站式平台
本平台是从开发到运维的一站式平台,用户可以通过拖拉拽 UI 方式开发,没有大数据背景的人也能使用。平台屏蔽了背后的大数据技术,进一步降低用户使用门槛。
(2) 端到端开发
在开发上,从数据源到引擎,平台会把一个 ETL 流程转换成多个流批作业,平台管理背后所有作业依赖和存储的对接。
(3) 流批一体
在流批一体方面用户只需一次开发就能实现流批一体,内部同一份存储可同时用于流处理和批处理。
目前平台应用规模、作业规模、日数据处理量都很大,在增量 Tps 达到百万级的情况下能给用户带来秒级延时的体验,已经连续支持双 11 多年。
3、 产品技术架构

(1) 依赖组件
①计算
从下往上看,首先在平台的 Runtime 层的计算维度,依赖支持 K8S 协议的统一资源池来提供计算资源。目前主要是通过企业版 Flink 即 VVR 以流批一体的方式,将各种数据源的数据经过大量复杂计算,最终写入不同的存储介质中供下游使用。另外一种业界大家熟知的计算引擎 Spark目前正在接入中,平台很快就会呈现出支持多引擎的状况。由于Spark 的接入,所以我们正在借鉴 Seatunnel 来重构 Connector 模块,统一计算引擎 API 接口,以此在 Connector 层面实现支持多引擎的目的。同样,由于多引擎的接入,我们重新设计 UDxF 组件,用户只需写一套 UDxF 的代码提供给平台,我们自动将其 Translator 成不同计算引擎的 UDxF。通过 VVP 的 JAVA SDK 来统一提交作业,按需在页面上对作业进行更进一步的运维及开发。
②存储
依赖阿里内部自研的 Pangu 和 Swift,作为底层分布式文件系统和消息队列,用 Hologres 来满足业务对于高性能的数据扫描和点查等需求。数据湖格式选用的是Paimon,湖表存储优化服务是我们正在调研的,主要是对大量 Paimon 表做 dedicated-compaction 以及对多种存储引擎底层 SST 文件的存储优化,进而提升大表读写吞吐性能。上面是统一的 Catalog 元数据服务,它集成了各种表的资源创建,资源回收、Meta、版本、订阅及血缘管理的功能。
③调度
平台的依赖 Airflow实现多作业的调度编排,流批作业的衔接等,依赖 Hippo申请集群资源。
(2) 核心功能
通过这些依赖的底层组件我们平台向上提供了很多大数据处理相关功能,比如数据集成,支持用户自定义插件的流批一体计算,样本处理,OLAP 等核心能力。
(3) 产品端
通过核心能力,在产品端就能结合各种业务场景来提供多种端到端的大数据处理解决方案。比如在收推场景下的收推平台、样本场景下的样本处理平台等。
(4) 支持业务
有了解决方案,平台目前支持的图中最上方所示阿里内部几乎所有业务线的各种数据处理的需求。
综上所述,平台的核心能力来源于底层依赖的各种计算、存储、调度的组件,它们是给平台上层业务赋能的动力源泉。为了更好的支持各种业务源源不断的复杂新需求,我们必须持续更新迭代底层的计算存储组件,所以我们今年开始引入了 Paimon。
二、引入 Paimon 原因、场景及预期收益
以上是一些关于平台背景的相关内容,下面重点说下平台引入 Paimon 的原因、场景及预期收益。

1、 引入Paimon 原因
引入 Paimon的原因主要是四个方面。
(1) **公司战略 **
公司要建立集团数据湖生态,湖仓协同,促进集团数据资产集中存储,高效使用。
(2) **成本 **
存储成本居高不下,很多实效性要求不高的场景,其实没必要用成本较高的分布式存储服务来支持。
(3) **解决 Lambda 架构缺点 **
Lambda架构开发维护复杂存在资源浪费情况,我们这边也有类似的现象,所以考虑引入Paimon。
(4)优化
我们调用发现数据湖在某些场景下可以解决业务性能瓶颈。
基于以上几个原因,我们深度对比了业界几大数据湖产品(Paimon、Iceberg、Hudi)后,结合业务需求及社区发展情况等因素综合考虑,最终选择了 Apache Paimon 作为我们数据湖的湖格式。
2、探索场景及预期收益一、样本生成链路
以下是样本生成链路的大致处理逻辑,也是要介绍的第一个场景——样本生成链路。

这条链路的特点主要有:第一,时效性要求不高,5 分钟左右;第二、数据量大,所以目前依赖的存储成本很高;第三、计算逻辑相当复杂。
简述:在样本生成过程中,会分别消费用户点击日志和一些Odps表数据,进行宽表加工,及大量 JOIN 操作和复杂的 ETL 等计算逻辑,生成样本特征及label。最终会将生成的样本数据进行持久化,写入到不同的目标系统中。当然实际处理逻辑远比这里要复杂的多。
这条数据处理链路中,流批是完全分开的两条链路,计算存储均没做到统一,开发维护成本偏高。更重要的是,这条时效性要求不高的链路的存储成本却一直居高不下,所以我们目前正在探索、尝试将 Paimon 引入进来。

以上便是我们目前正在探索和尝试的新架构。全链路不再有分布式 KV 存储服务,而是用 Paimon 作为数据镜像及 DimJoin 维表等来实现样本处理过程中的数据存储需求。
预期达到的收益:
(1) 做到真正的流批一体,流批计算引擎统一为 Flink,存储统一为 Paimon,同一份存储,既可以被用于流处理,也可以被用于批处理。明显可以降低业务开发维护的成本。
(2) 可根据业务逻辑来决定是否共享部分存储资源,如图中间的paimon 表。
(3) 在某些情况下用 DimJoin 替换以前的 SortMergeJoin,提升性能。
(4) 由于没有了分布式 KV 存储服务,可以减少很多存储服务的成本。
3、 探索场景及预期收益二、批样本存储链路
这是第二个场景——批样本存储链路,该链路是将样本平台产出的批样本发往消息队列给索引平台 Build 成在线检索引擎所需的 ORC 格式文件,以共用户分析使用。

该链路有明显的几个缺点:
第一,索引平台读取消息队列中的样本数据 Build 索引的过程会有长尾,导致产出延迟。
第二,依赖组件多,整体链路太绕,导致运维成本高,可控性差。
所以我们探索是否能让在线检索引擎支持识别 Paimon 这种湖格式,样本平台就可以直接将样本数据写入 Paimon 中。如果实现,那依赖组件减少,产出延迟也就可控,运维及费用成本均可降低。
4、 探索场景及预期收益三、图片特征计算链路
这是探索的第三个场景——图片特征计算链路。在图片特征计算场景下,该链路的时效性要求不高,主要是计算图片的特征。但是由于图片数量多,达到百亿级,所以通过 TFS / OSS 拉取图片经常导致服务端压力过高,甚至雪崩、限流也经常发生,所以我们引入了 KV系统作为 Cache。该链路是利用Flink作业动态分析图片的计算特征,当 Flink Batch Job 查询该服务发现图片不存在时,则会通过 HTTP 向 TFS 也就是图片中心服务请求图片,然后发往消息队列中来更新 Cache。
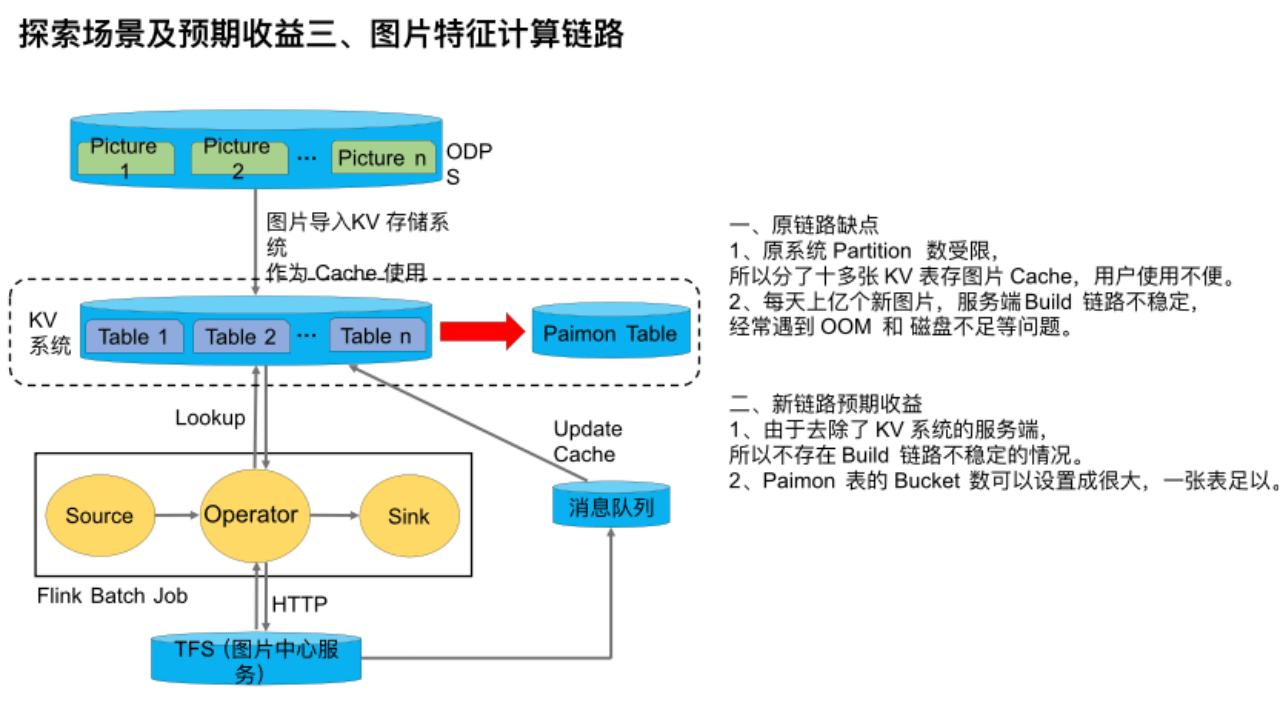
该链路有几个缺点:
第一,原系统 Partition 数受限,所以我们分了十多张 KV 表存图片 Cache,用户使用不便。
第二,每天上亿个新图片,服务端 Build 链路不稳定,经常遇到 OOM 和 磁盘不足等问题。
由于 Paimon 支持作为维表被点查的,所以我们目前正在尝试将 Paimon 引入进来当 Cache,替换原 KV 系统。
如果能实现,则预期收益是:
第一,由于去除了 KV 系统的服务端,所以不存在 Build 链路不稳定的情况,成本也能相应下降。
第二,Paimon 表的 Bucket 数可以设置成很大,一张表足以,方便用户使用。
5、 探索场景及预期收益四、搜索离线链路
该链路是搜索平台较典型离线处理链路。
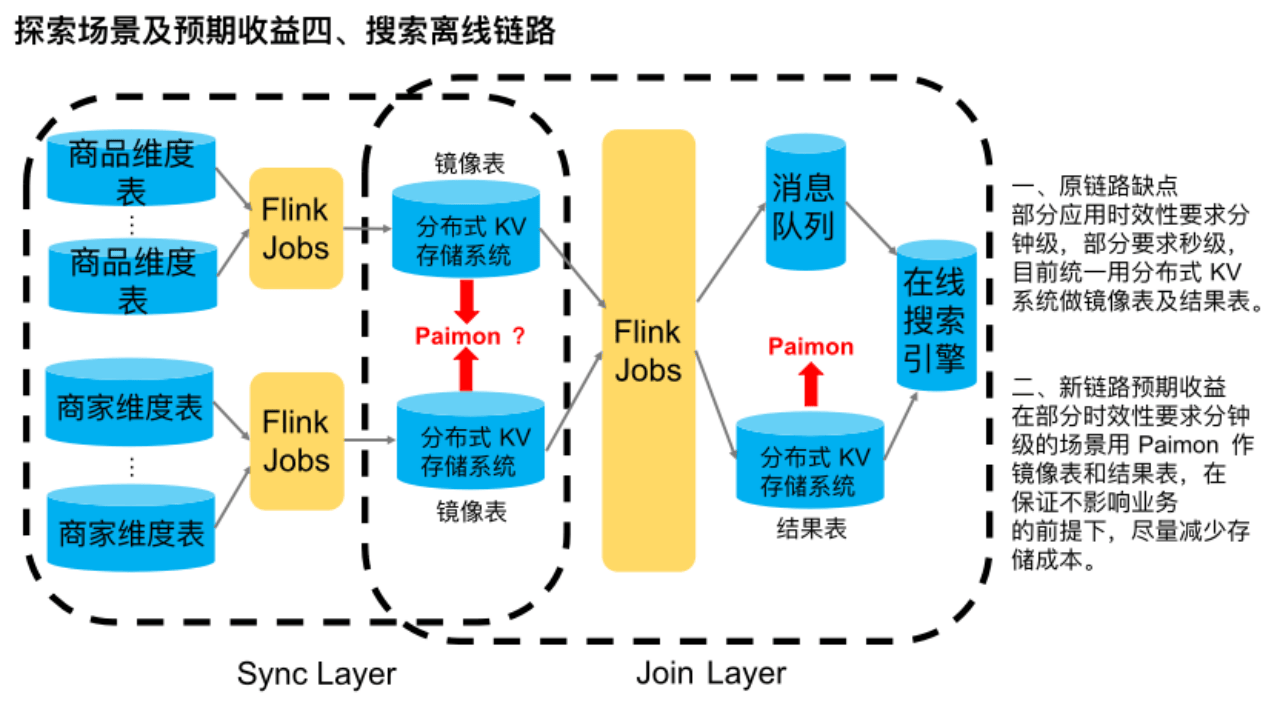
简单介绍下,首先在同步层,多个商品维度源表与多个商家维度源表分别通过 Flink 流批作业全增量同步到分布式 KV 存储系统中,作镜像表使用。在 Join 层,通过一些 Flink 流批作业将各维度的镜像表数据合并在一起做打宽处理,最终得到淘宝一件商品的完整数据信息。然后全增量分别写到分布式 KV 存储系统和消息队列中,供下游的在线搜索引擎消费建索引等。该链路主要是用于时效性要求很高的场景,业务要求在源头触发增量以后,能在下游搜索引擎立马查到最新的商品信息。
这条链路目前的主要缺点是,所有应用不管时效性是分钟级还是秒级,都统一用分布式 KV 系统做镜像表及结果表,存储成本偏高。
我们调研到,由于 Paimon 支持流读流写、批读批写、以及作为维表被点查,所以我们目前正在探索是否能用 Paimon 来替换该链路中的分布式 KV 存储系统,来满足一些时效性要求在分钟级别以上的业务需求,以此来实现成本的下降。目前结果表正在落地过程中,而镜像表则还在探索调研中,属于未来规划。
6、 探索场景及预期收益五、搜索全量拉库链路

最后一个场景来源于刚刚那个场景的源头。也就是用户在做大全量时,需要去拉分库分表的Mysql数据,目前是各应用都去拉,很明显有几个缺点:
第一,拉取分库分表Mysql时,并发有上限限制,吞吐受限,而盲目加并发有拉挂库的风险。
第二,公司有些核心库只允许晚上拉取,这直接影响到业务迭代。
第三,每个应用都要分别去拉取 Mysql 表,无法做到共享。
我们调研引入 Paimon 来解决该场景下的性能瓶颈问题,先将 mysql 表数据全增量同步到一张 Paimon 表中,然后下游全量来拉取这张 Paimon 表,增量可以根据时效性要求高低而决定选择是走 DRC 原链路,还是消费 Paimon 的 changelog。目前正在落地过程中,预期收益其实很明显,未来并发无上限了,释放了吞吐和加快全量速度,全天24小时均可拉取,且能做到各应用共享 Paimon 表。
三、遇到的问题及解法
最后介绍下在落地过程中遇到的问题及解法。
1、 问题一及解法、Snapshot Expire 导致批作业运行失败

Snapshot用户去拉取时,会存在过期的可能,且在过程中发现会有非常多的错误,原因很简单,就是全用户全量拉过期的Paimon表,文件被删,导致作业全量失败。
有以下三种解法:第一,将 Consume-id 从流场景扩展到批场景,但调研详细代码的实现后,发现consumer ID有局限性。第二,统一加大 Snapshot Expire 时间,这样,所有应用去拉Paimon表时都不会过期,但这样有一个缺点就如图中左边所示,不同APP业务的逻辑不同,导致用户每个作业的运行时长不同,有些作业只需读Paimon表,中间没有任何计算逻辑,直接落到KV存储中,有些任务可能有DimJoin、UDTF等复杂的算法逻辑,算特征、算label等等。线上的作业实践下来,发现同一张mysql表,快则十多分钟拉完,慢则好几个小时。第三,各 App 分别创建 Tag,作业结束后,每个应用负责删除自己创建的Tag。因为平台目前支持的上千个业务,每个业务都通过air flow去调度,用户经常自己操作air flow,直接停止调度或重新clear调度节点,这样会导致tag残留,平台无法保证用户自己手工操作而产生的一些错误的运维手段。
最后,和社区一起讨论,最后讨论的解法如下:首先 Tag 支持精细化 TTL,然后 App 不再 Scan Snapshot,而是 Scan Tag With TTL。其次,每个业务知道自己的业务逻辑,所以可以设置自己需要的 TTL。同时,该方法也可以给平台兜底,防止漏删 Tag 的情况发生。另外,我们对老版本 Tag 及 Snapshot 都做了兼容。具体的实现是新建Class Tag extends Snapshot,详细的开发的代码及逻辑,可看下面的PIP。
2、 问题二及解法、Schema Evolution

遇到的第二个问题是Schema Evolution, 这是DRC数据,即集团内解析Binlog,吐出增量的组件。我们把它写作Paimon表时,希望用户的源头数据变更可以动态的让Paimon表生效。目前这个功能我们调研到社区以及公司的做法,决定用克隆表的方式来做。
(1) 不依赖 Flink-CDC 来实现 Schema Evloution 的原因
①Flink-CDC 不支持集团 TDDL (基于 Java 语言的分布式数据库系统,提供分表分库等功能)
②Debezium 不支持集团用的 Mysql 版本
(2)没采用 Paimon 官网的 RichCdcSinkBuilder API 实现 Schema Evloution 的原因:
平台全部作业统一用 Flink SQL,暂无支持 DataStream 的计划。
所以我们另辟蹊径,用 Clone Table 来支持 Schema Evloution。简述是源头DRC的增量会同步到Paimon表。此时用户有了Schema Evloution需求,然后调用社区的Clone Table将Paimon表1克隆到Paimon表2,克隆最后一个snapshot,这个Paimon表会执行Alter Schema操作。执行完后,再拉全量同步mysql表新加的字段,只需d字段,再回溯增量,把a、b、c、d,4个字段回溯写入Paimon表2。以此支持用户Schema Evloution。目前这个方法也在尝试落地中。
3、问题三及解法、Data Migration

第三个问题是数据迁移的情况,即业务遇到 DFS 集群裁撤,需要数据从 DFS 集群 A 迁移到 DFS 集群 B。还有是由于阿里云降价,所以有云上用户想将数据从别的云厂商的云迁移到 AliYun 上。针对这种数据迁移的场景,不可能重新把业务全量扫描。针对以上两种情况的解法:第一,我们决定去社区开发克隆表这种数据迁移工具,提供 Clone Table 这种 Data Migration 工具。第二,支持 Catalog、Database、Table、Snapshot、Tag 等 CloneType。
4、Clone Table 实现方法
最后详细介绍一下Clone Table 实现方法。
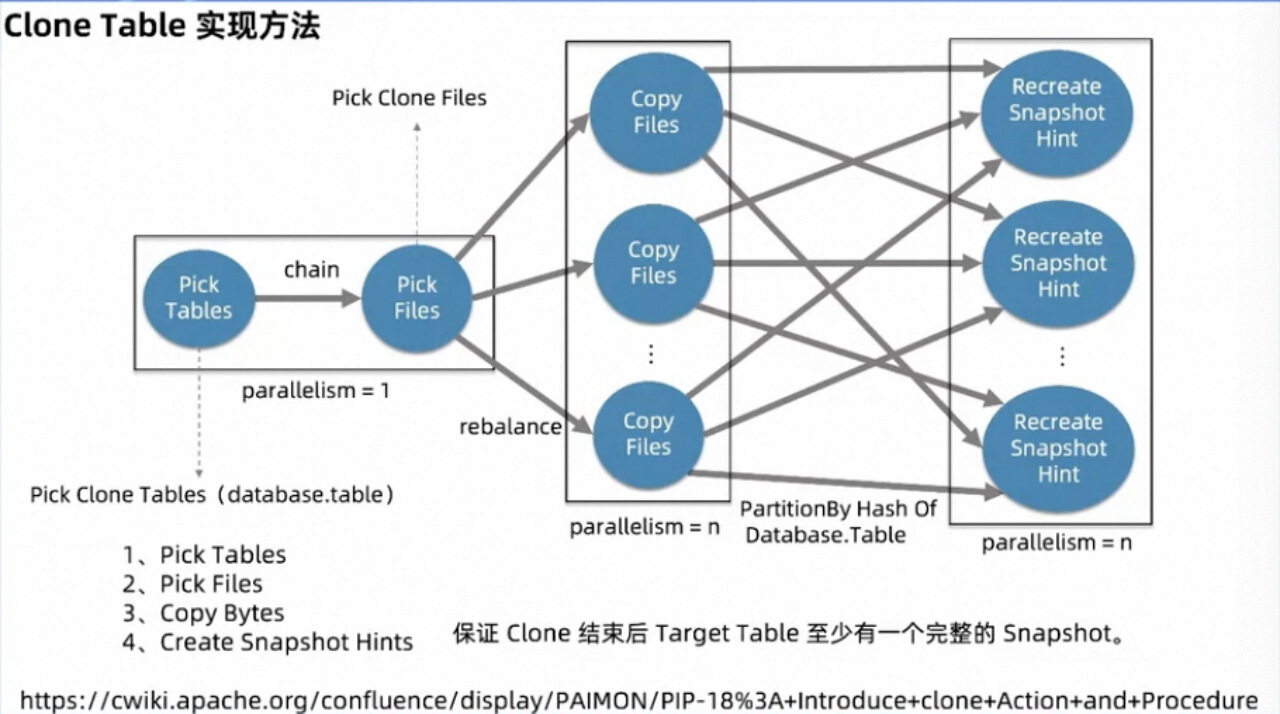
具体实现上来看,由于要 copy 的文件有可能很多,所以我们没有在客户端单点执行 copy File,而是起分布式任务来执行。
作业拓扑大致分为四个 Operator:
第一个 Operator,用来根据用户传递的参数查询要 copy 的表,封装为 Record 发给第二个 Operator, 这个节点的设置主要是为了方便用户一键 copy 多个表,整个 db或整个 catalog 下的所有表,而不是每 copy 一个表就要起一个作业。
第二个 Operator 在收到第一个节点的 Record 之后,会访问该表最后一个 Snapshot 对应的 Manifest 等相关元数据文件,进而 pick 出相关数据、Schema 等文件。最后将文件信息 Rebalance 给第三个节点。
第三个 Operator,负责分布式执行文件复制,主要是通过 InputStream + OutputStream 的方式对文件进行逐字节 Copy。然后对 Database 和 Table 求 MurmurHash 来重新 Partition 发往下游最后一个节点。
最后一个 Operator,主要是负责一个表的文件复制完以后创建 snapshot 的 Hint 文件,代表着该 Snapshot 可供下游使用了。
由于用户可能将Snapshot过去时间设置的时间很短,导致在执行Clone作业的过程中,Snapshot可能过期删除, 导致Clone作业失败。
因此为解决这个问题,我们会通过作业失败的重启后,来比较文件的size和文件名,这样就会过滤掉已经copy的文件,以此加速作业整体执行速度。从而第二次的Clone job就能顺利完成,生产实践后发现这种方法是完全可用的。对于该功能详细的逻辑以及代码,可参考这个pip(https://cwiki.apache.org/confluence/display/PAIMON/PIP-18%3A+Introduce+clone+Action+and+Procedure)。