2022年是AIGC(AI-Generated Content, 人工智能生成内容)不平静的一年。技术上,Stability AI新开源的Stable Diffusion可以根据一句话在5分钟内定制生成高精度、高完成度的图像。Open AI推出的ChatGPT能够完成智能对话,修改代码bug,构思小说和论文等多个任务。
本文简单地介绍了AI在语言上的研究和应用,即自然语言处理这一分支,希望能有浅显的科普作用。
1 自然语言处理(Natural Language Processing)
NLP是什么
自然语言处理 (NLP) 是语言学、计算机科学和人工智能的一个跨学科子领域。它关注计算机与人类语言之间的交互,特别是如何对计算机进行编程以处理和分析大量自然语言数据。自然语言是指人类使用的语言,如英语、法语、日语和中文等,覆盖范围很广,常见的自然语言有谈话,技术文档,论文等。
自然语言处理的历史可以追溯到20世纪50年代,当时研究者们开始尝试使用机器翻译系统来翻译自然语言文本。早在 1950 年,艾伦图灵(Alan Turing)就发表了一篇题为“计算机器与智能”的文章,其中提出了现在称为图灵测试的智能标准,尽管当时并没有将其作为与人工智能分开的问题进行阐述。提议的测试包括一项涉及自然语言的自动解释和生成的任务。NLP的研究总共经历了三个阶段:
- 1950s-1990s 基于规则和符号:给定一些规则(例如,假设动词后必定接着名词),计算机通过将这些规则应用于它所面对的数据来模拟对自然语言的理解。
- 1990s-2010s 基于统计: 直到 1980 年代,大多数自然语言处理系统都基于复杂的手写规则集。从 20 世纪 80 年代后期开始,用于语言处理的机器学习算法被引入,这些算法的原理一般来自统计学的先验概率,后验概率等。
- 2010s-2020s 基于神经网络: 在 2010 年代,表示学习和深度神经网络式机器学习方法在自然语言处理中得到广泛应用。神经网络的出现为NLP注入了新的血液。
自1950年起,自然语言处理不断地发展,其中最重要的发展是基于深度学习技术的自然语言处理系统。这些系统可以自动识别文本中的实体、主题和情感,从而对文本进行分析和理解。
NLP有哪些任务
自然语言处理有多项任务,常见的有:
• 命名实体识别:识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等
{"text": "她写道:抗战胜利时我从重庆坐民联轮到南京,去中山陵瞻仰,也到秦淮河去过。然后就去北京了。", "label": {"address": {"重庆": [[11, 12]], "南京": [[18, 19]], "北京": [[40, 41]]}, "scene": {"中山陵": [[22, 24]], "秦淮河": [[30, 32]]}}}• 文本分类:输入一个文本,识别出文本所属于的类别
{"label":"news_sports", "text": "詹姆斯G3决杀,你怎么看?"}• 文本摘要:输入一篇文章,输出该文章的摘要内容和观点(下图来自LCSTS数据集)

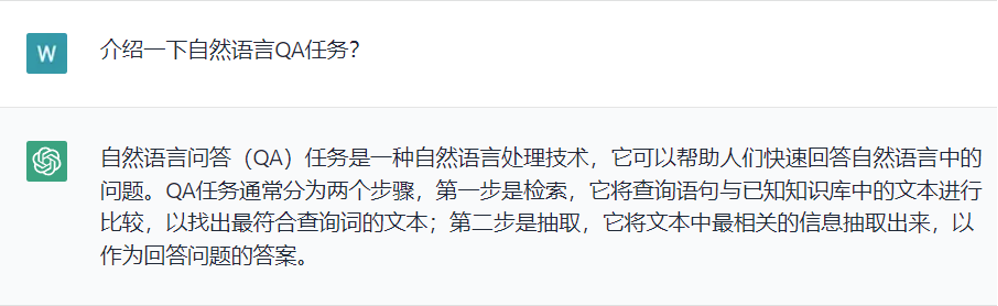
• 问答系统:下图来自ChatGPT
2 自从文字到向量
从机器学习开始,计算机可以学习和分析隐藏在数字序列中的信息,一个经典而简单的例子就是用房子的参数:面积,房间数量等,来预约房价。由于计算机懂的只有0和1,怎么让计算机学习和理解文本,怎么用数字来表现文本,是自然语言处理研究的第一步。概念上,词嵌入指把一个维数为所有词的数量的高维空间嵌入到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量。使用一个向量来表示每一个词,如此一来,就能把一段由许多词组成的文句,转换成一条条词向量来表示,并把这样数值化的资料,送到模型里做后续的应用。本段将介绍基于统计的和基于预测的词嵌入方法。
基于词频的词嵌入
本节将介绍一个比较经典的基于统计的处理文本流程。
• 分词并移除停用词
现在我们有一条文本
s = 'v我50吧我想要去吃肯德基疯狂星期四'
处理文本的第一个步骤是将文本中的词分割并筛选出来,并去掉停用词。停用词指的是一些没有实际含义的词汇,如“了”、“吧”、“一些”等等。这样处理可以使文本的意思更便于计算机理解并且不会污染词典。
import jieba #jieba是一个非常实用的nlp包,支持多种任务 s = 'v我50吧我想要去吃肯德基疯狂星期四' s = jieba.lcut(s) #分词后 #['v', '我', '50', '吧', '我', '想要', '去', '吃', '肯德基', '疯狂', '星期四'] new_s = [] for word in s: if word not in stop_words_set: new_s.append(word) #移除停用词后 #['v', '50', '想要', '吃', '肯德基', '疯狂', '星期四']• 构建词典
词典(也称语料库)指的是整个文本数据集中出现过的所有词。
• one-hot向量
最简单的文本表示方法,假设这个文本集的词典长度为10,000,也就是有10,000个词,对于每条文本,生成一个长度10,000的向量,向量中的每个值对应词表中的一个单词,该文本有该词出现时为1,否则为0。当然由于生成的向量太过于稀疏,one-hot向量几乎不可能被用到实践上。
• tf-idf向量
tf-idf是一种经典的用于资讯检索与文本挖掘的常用加权技术。它的主要思路为衡量文本中词的重要性。tf-idf认为字词的重要性随着它在该文本中出现的次数(tf, term frequency)成正比增加,但同时会随着它在词库中出现的频率(df, document frequency)成反比下降。因此,对于文本

中的词语 ,它的tf-idf值的公式为:
其中:
1.

表示词语出现在文本中的次数, 同理。
2.
则表示语料库中的文本总数, 表示内容中出现了词语的文本数量。
这样,对于一个10,000词的词库,我们同样会对每个文本生成10,000词的向量,虽然向量还是稀疏的,但已经可以包含一定的文本信息了。这时候的编码方法由于只关注每个词的频率,没有办法理解词语本身的意思。为了让机器学习词的意思,基于预测的词嵌入被发明出来了。
基于预测的词嵌入
一组好的词向量,会使意思相似的词在向量空间上比较靠近彼此,甚至词义上的关联可以用词向量在空间中的关系来表示。如下图所示,这些词的关联性可以用向量表达出来。常见的好用的嵌入方法有谷歌的Word2vec,斯坦福大学的GloVe等。这些方法让机器具备了一定的学习词语的含义的能力。Word2Vec的基本出发点是上下文相似的两个词,它们的词向量也应该相似,比如香蕉和梨在句子中可能经常出现在相同的上下文中,因此这两个词的表示向量应该就比较相似。Word2Vec用神经网络来学习和预测词语
的上下文出现的词的概率,并得到一个词向量矩阵(一般是神经网络中的一个权重矩阵),并将这个矩阵作为单词的向量。
3
从RNN到Transformer
介绍了编码方式后,我们就需要一个模型去处理编好码的文本了。本段将简单介绍NLP研究目前比较重要的神经网络模型。神经网络是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。如下图所示,神经网络通过隐藏层接收和处理输入数据,有着非常好的效果。下图为一个基础的神经网络架构:输入层,隐藏层和输出层。通过神经网络和词向量,计算机能够理解和分析词语的意思。但因为被分好的词是独立地输入到神经网络的,计算机无法理解句子中每个词的关联性,也就没有办法理解整条句子的含义。为了解决这个问题,在输入词语时保留上文的信息,学者们提出了递归神经网络。

递归神经网络(Recurrent neural network) 对具有序列特性的数据非常有效,它在神经网络的基础上添加了如下设定:节点之间的连接可以创建一个自循环,因此允许来自某些节点的输出影响对相同节点的后续输入。RNN对上一个输入的词的信息进行处理后将其和下一个词的信息一起输入到网络,如此循环,使得RNN可以读取到一些句子的关联信息。比如说给出两条文本:
• 我喜欢吃苹果!
• 苹果是一家很棒的公司!
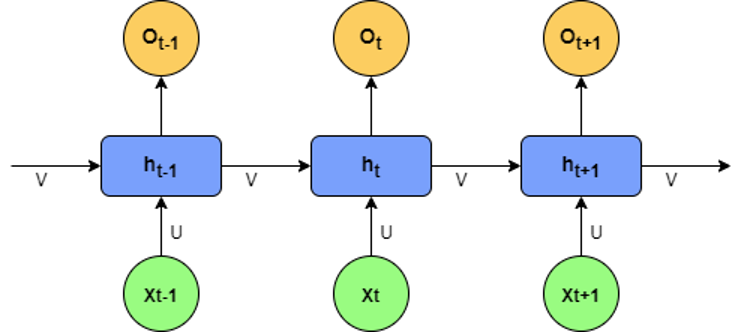
在这里,苹果这一词出现了歧义。普通的神经网络是无法识别出这样的歧义的,RNN可以做到,因为它的输入是序列式并且包含有前一个词的信息。也就是当模型识别第一句话的苹果时,它能够接收到前面吃的信息,识别第二句话时,它也能了解到后面的公司的信息(需要双向RNN),因此RNN会根据句子的意思对词义作出更正确的判断。下图是RNN的基础结构,
代表当前输入的单词,则表示来自上一个词的信息,则是模型接收当前词的输出。RNN的后续改进有LSTM, GRU等。
RNN代表的一系列神经网络虽然可以学习到句子信息,但效果并不特别显著。2017年Google 的研究员在论文 Attention is All you need 中提出了 Transformer 模型,其使用 Self-Attention 结构取代了在 NLP 任务中常用的 RNN 网络结构。相比 RNN 网络结构,它的优点是可以并行计算。从那时起,Transformer模型成为了研究的主流模型并为多项NLP任务带来了惊人的突破。基于Transformer改进的模型有谷歌的BERT,T5和OpenAI的GPT模型等。随着计算机算力的提高,语言模型向着大数据集和大模型的方向进化。谷歌的2020年的BERT-base模型约有1亿400万的参数。OpenAI的新模型GPT3更是力大砖飞,约有1750亿个参数,45TB的数据,是它的上一个版本GPT2的116倍,也因此,他们在去年发布的基于GPT3.5的问答机器人ChatGPT达到了惊人的效果。
4 ChatGPT
ChatGPT是美国OpenAI公司去年发布的一款强大的聊天机器人,最近收到多个。ChatGPT的训练模型为OpenAI改进过的GPT3.5,ChatGPT可以根据输入的问题自动生成答案。还具有编写和调试计算机程序的能力。在问答的基础上它还有如下功能:
1. 记住用户在前面对话中说的话
2. 允许用户更正ChatGPT的输出内容
3. 拒绝不当请求
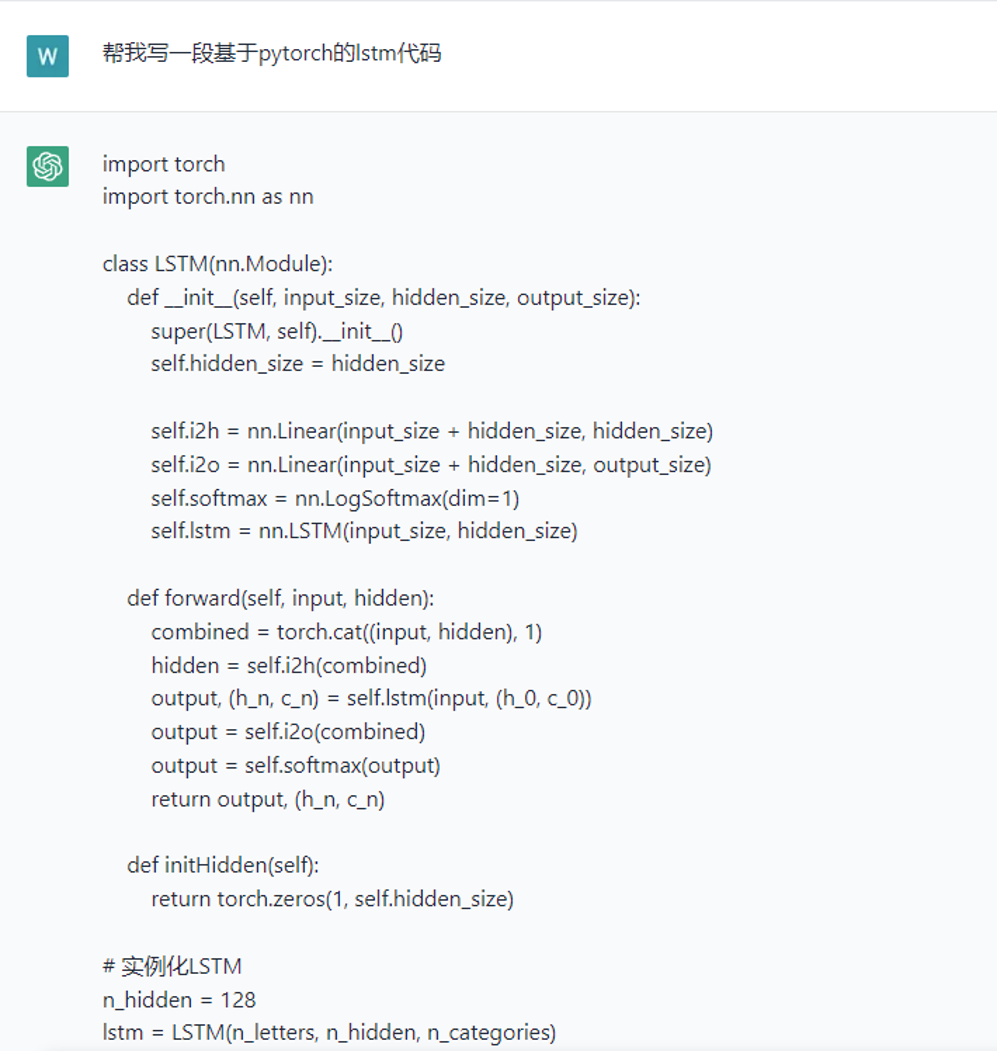
下图展示了ChatGPT的代码编码生成功能,可以看到代码可以复制即用。由于某些原因,ChatGPT并不对中国地区开放,最先进的ChatGPT(官网版)无法在这里演示。网络上有着许多对其的介绍文章可供观看。一个比较受到关注的问题是ChatGPT是否成为了强人工智能,也就是具备了意识,如同《流浪地球2》中的MOSS一般。这个问题的答案是否定的。ChatGPT依旧属于普通的QA模型,它强劲的表现来自于训练它的超大模型和超大数据集(GPT3有1750亿的参数和45TB的数据,ChatGPT应该更大)。我们距离真正的人工智能虽然还有一段不小的距离,但用生成式AI提高生产力已然是一个新的技术热点。
本文有两小段内容其实是由ChatGPT所写,不知读者能否分辨出来。
5 总结
本文介绍和梳理了自然语言处理的发展历程,并简单地介绍了让计算机读懂人类文字的编码方法,应用在NLP领域的神经网络模型和目前业内领先的ChatGPT。希望能让读者对自然语言处理这一AI的分支有更好的理解。