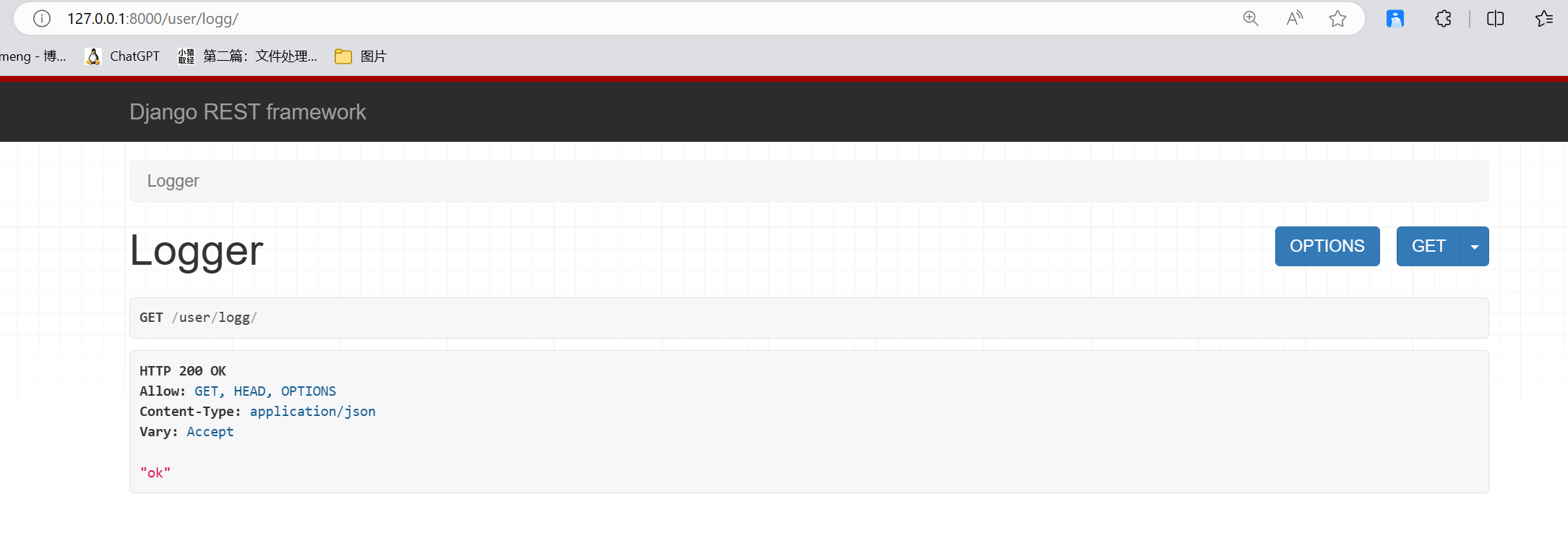
基于MindNLP的文本解码原理
文本解码
文本解码是自然语言处理中的一个关键步骤,特别是在任务如机器翻译、文本摘要、自动回复生成等领域。解码过程涉及将编码器(如语言模型、翻译模型等)的输出转换为可读的文本序列。以下是一些常见的文本解码方法和原理:
1. 自回归解码:
- 这是最常见的解码方式,模型在每个时间步基于之前生成的词序列来预测下一个词。
- 每个词的预测都是独立的,依赖于前面的词。
2. 贪心解码(Greedy Decoding):
- 在每个时间步选择概率最高的词作为输出。
- 简单快速,但可能导致局部最优,不一定产生整体上最佳的序列。
3. 束搜索(Beam Search):
- 同时维护多个候选序列,并在每个时间步扩展这些序列中概率最高的几个。
- 通过设置束宽(beam size)来平衡计算成本和解码质量。
4. Top-k 采样:
- 在每个时间步选择概率最高的k个词作为候选,并从中选择一个词进行扩展。
- 可以增加生成序列的多样性。
5. Top-p 采样(Nucleus Sampling):
- 选择累积概率达到某个阈值p的最小集合的词作为候选。
- 这种方法可以控制生成文本的多样性,避免生成过于常见的词。
6. 随机采样:
- 根据概率分布随机选择词,增加了生成文本的随机性和创造性。
7. 条件束搜索(Constrained Beam Search):
- 在束搜索的基础上加入一些额外的约束条件,如避免重复词、确保语法正确等。
8. 分层解码(Hierarchical Decoding):
- 首先在较高层次上生成句子的主要结构,然后在较低层次上填充细节。
9. 指针网络(Pointer Networks):
- 直接从输入序列中选择词,而不是生成新的词。常用于摘要生成。
10. 变分推断(Variational Inference):
- 使用概率模型来近似解码过程,可以处理不确定性和生成多样性。
11. 强化学习:
- 使用强化学习来优化解码策略,根据奖励信号来调整生成的文本。
12. Transformer 模型:
一种自注意力机制的模型,可以并行处理序列中的所有词,有效处理长距离依赖。
文本解码的目标是生成流畅、准确、符合上下文的文本。不同的解码策略有各自的优势和局限性,选择哪种策略取决于具体任务的需求和资源限制。
自回归语言模型
自回归语言模型是一种自然语言处理中的模型,它基于给定的先前词序列来预测下一个词。这种模型的核心思想是,一个词的出现概率可以通过它前面的词来决定。自回归模型通常使用马尔可夫链的特性,即假设一个词的出现只依赖于它前面的几个词,而与更早的词无关。
自回归模型可以是一阶的,也就是只依赖于前一个词(bigram model),也可以是二阶的,依赖于前两个词(trigram model),依此类推。随着依赖词数的增加,模型的阶数也会增加,但同时模型的复杂度和所需的数据量也会增加。

一个文本序列的概率分布可以分解为每个词基于其上文的条件概率的乘积

MindNLP/huggingface Transformers提供的文本生成方法

Greedy search
Greedy search 是一种在序列生成任务中常用的解码策略,特别是在自回归语言模型中。在每个时间步 t,greedy search 选择概率最高的词作为当前的输出词。这种方法简单直观,但可能不是最优的,因为它只考虑了局部最优,而没有考虑全局最优。
具体来说,假设我们有一个语言模型,它在时间步 t 时,根据前 t−1 个词的序列 w1,w2,…,wt−1 来预测下一个词 wt 的概率分布 P(wt∣w1,w2,…,wt−1)。Greedy search 会从这个概率分布中选择概率最高的词作为输出:
wt=argmaxwP(w∣w1,w2,…,wt−1)
这个过程会一直重复,直到生成了足够的词,或者生成了一个结束标记(如句号或特殊的结束符号)。
Greedy search 的优点是简单和快速,但它的缺点是可能会陷入局部最优,导致生成的序列在全局上不是最优的。例如,它可能会生成一个在语法上正确但在语义上不合理的句子。为了解决这个问题,研究人员提出了其他更复杂的解码策略,比如束搜索(Beam Search)和采样方法,这些方法在考虑局部最优的同时,也试图找到全局上更好的序列。
自回归模型的应用场景
自回归模型的一个关键应用是语言生成,例如文本合成、机器翻译等。通过训练一个足够大的语料库,模型可以学习到语言的统计特性,并生成符合语法和语义的新句子。
自回归模型的不足
自回归模型在长序列生成时可能会遇到效率问题,因为生成每个词都需要等待前一个词的完成。为了解决这个问题,一些模型采用了非自回归的方法,比如Transformer的变体,它们可以并行生成整个序列的词。
基于MindNLP的文本解码实践
基础环境准备
python版本信息:Python 3.9.19
运行本实践需要内存至少:19GB
准备所需依赖
pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14pip uninstall mindvision -y
pip uninstall mindinsight -ypip install mindnlp
完整依赖库信息如下:
$ pip list
Package Version
------------------------------ --------------
absl-py 2.1.0
addict 2.4.0
aiofiles 22.1.0
aiohttp 3.9.5
aiosignal 1.3.1
aiosqlite 0.20.0
altair 5.3.0
annotated-types 0.7.0
anyio 4.4.0
argon2-cffi 23.1.0
argon2-cffi-bindings 21.2.0
arrow 1.3.0
astroid 3.2.2
asttokens 2.0.5
astunparse 1.6.3
async-timeout 4.0.3
attrs 23.2.0
auto-tune 0.1.0
autopep8 1.5.5
Babel 2.15.0
backcall 0.2.0
beautifulsoup4 4.12.3
black 24.4.2
bleach 6.1.0
certifi 2024.6.2
cffi 1.16.0
charset-normalizer 3.3.2
click 8.1.7
cloudpickle 3.0.0
colorama 0.4.6
comm