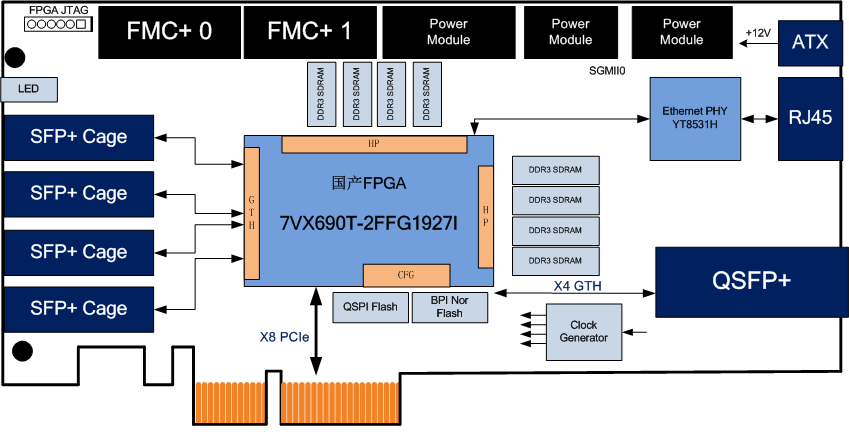
一、数据并行
- 这是最常用的方法。
- 整个模型复制到每个GPU上。
- 训练数据被均匀分割,每个GPU处理一部分数据。
- 所有GPU上的梯度被收集并求平均。通常使用NCCL(NVIDIA Collective Communications Library)等通信库实现。
- 参数更新
- 使用同步后的梯度更新模型参数。
- 确保所有GPU上的模型保持一致。
- 有效批次大小 = 单GPU批次大小 × GPU数量
- GPU间通信可能成为瓶颈。高速互联(如NVLink)可以减少这一问题。
二、解决数据并行的不足

a) 模型并行:
- 将模型的不同部分分配到不同的GPU上。
- 例如,Transformer模型的不同层可以放在不同GPU上。
- 优点是可以处理超大模型,但需要仔细设计以最小化GPU间通信。
b) ZeRO(Zero Redundancy Optimizer):
- 由微软开发,是一种高效的内存优化技术。
- 将优化器状态、梯度和模型参数分片到不同的GPU上。
- 可以显著减少每个GPU上的内存使用,同时保持类似于数据并行的简单性。
c) 流水线并行:
- 将模型分成几个阶段,每个阶段在不同的GPU上。
- 数据以mini-batch的形式在这些阶段间流动。
- 可以有效平衡计算和通信,适合处理非常大的模型。
三、大语言模型(Large Language Models,LLMs)训练广泛采用了模型并行技术
1. 混合并行策略
大语言模型训练通常采用混合并行策略,结合了多种并行化技术:
- 模型并行(Model Parallelism)
- 数据并行(Data Parallelism)
- 流水线并行(Pipeline Parallelism)
- 张量并行(Tensor Parallelism)
2. 模型并行在LLM中的应用
模型并行确实是LLM训练中的关键组成部分,主要原因如下:
- 模型规模:现代LLM(如GPT-3、PaLM、LLaMA等)的参数量巨大,无法装入单个GPU的内存。
- 计算效率:合理的模型切分可以提高计算效率,减少GPU间通信开销。
3. 其他并行技术在LLM训练中的应用
a) 数据并行:
- 仍然被使用,但通常与其他形式的并行相结合。
- 有助于提高总体吞吐量,特别是在处理大规模数据集时。
b) 流水线并行:
- 将模型的不同层分配到不同的GPU或节点上。
- 减少激活值的内存占用,提高硬件利用率。
c) 张量并行:
- 将单个张量(如注意力矩阵)跨多个设备分割。
- 减少单个操作的内存需求,允许训练更大的模型。
4. 实际案例
让我们看几个具体的例子来说明LLM训练中的并行策略:
a) GPT-3:
- 使用模型并行和数据并行的组合。
- 模型被分割到多个GPU上,同时使用数据并行来提高吞吐量。
b) Megatron-LM:
- NVIDIA开发的框架,用于训练大规模语言模型。
- 结合了张量并行、流水线并行和数据并行。
c) DeepSpeed ZeRO:
- 微软开发的技术,结合了数据并行与高效的内存优化。
- ZeRO-3阶段允许训练超大模型,同时保持高效率。
5. 挑战与考虑因素
尽管模型并行是LLM训练的重要组成部分,但它也带来了一些挑战:
- 通信开销:不同GPU间的频繁通信可能成为瓶颈。
- 负载均衡:确保各个GPU的工作负载均衡是一个挑战。
- 编程复杂性:实现高效的模型并行需要复杂的编程技巧。
6. 未来趋势
随着LLM继续发展,我们可能会看到:
- 更高效的混合并行策略。
- 专门针对大规模模型训练的新硬件设计。
- 自动化工具,简化复杂并行策略的实现。
总的来说,虽然模型并行确实是大语言模型训练的核心组成部分,但现代LLM训练策略通常是多种并行技术的精心组合,以实现最佳的计算效率和资源利用。