文章目录
- 1、张量基本运算
- 2、阿达玛积
- 3、点积运算
- 4、指定运算设备⭐
- 5、解决在GPU运行PyTorch的问题
🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应用开发、数据结构和算法,初步涉猎人工智能和前端开发。
🦅个人主页:@逐梦苍穹
📕所属专栏:人工智能
🌻gitee地址:xzl的人工智能代码仓库
✈ 您的一键三连,是我创作的最大动力🌹
1、张量基本运算
PyTorch 计算的数据都是以张量形式存在
可以在 CPU 中运算, 也可以在 GPU 中运算.
基本运算中,包括 add、sub、mul、div、neg 等函数,
以及这些函数的带下划线的版本 add_、sub_、mul_、div_、neg_,
其中带下划线的版本为修改原数据。
| 操作类型 | 函数 | 示例代码 | 代码解释 |
|---|---|---|---|
| 创建张量 | torch.randint | data = torch.randint(0, 10, [2, 3]) | 生成一个2x3的随机整数张量,范围在0到9之间。 |
| 不修改原数据 | add | new_data = data.add(10) | 将每个元素加上10,生成一个新张量。 |
| 修改原数据 | add_ | data.add_(10) | 将每个元素加上10,直接修改原数据。 |
| 减法 | sub | data.sub(100) | 将每个元素减去100,生成一个新张量。 |
| 乘法 | mul | data.mul(100) | 将每个元素乘以100,生成一个新张量。 |
| 除法 | div | data.div(100) | 将每个元素除以100,生成一个新张量。 |
| 取反 | neg | data.neg() | 将每个元素取反,生成一个新张量。 |
代码:
# -*- coding: utf-8 -*-
# @Author: CSDN@逐梦苍穹
# @Time: 2024/7/16 1:25# 导入PyTorch库
import torch# 定义测试函数
def test():# 生成一个2x3的随机整数张量,范围在0到9之间data = torch.randint(0, 10, [2, 3])print(data)print('-' * 50)# 1. 不修改原数据# 使用add函数将每个元素加上10,生成一个新张量new_data = data.add(10) # 等价 new_data = data + 10print(new_data)print('-' * 50)# 2. 直接修改原数据# 注意: 带下划线的函数为修改原数据本身# 使用add_函数将每个元素加上10,直接修改原数据data.add_(10) # 等价 data += 10print(data)# 3. 其他函数# 使用sub函数将每个元素减去100,生成一个新张量print(data.sub(100))# 使用mul函数将每个元素乘以100,生成一个新张量print(data.mul(100))# 使用div函数将每个元素除以100,生成一个新张量print(data.div(100))# 使用neg函数将每个元素取反,生成一个新张量print(data.neg())
效果:

2、阿达玛积
阿达玛积(Hadamard Product),又称为元素积(element-wise product),是指两个相同尺寸的矩阵对应元素相乘得到的新矩阵。
阿达玛积与矩阵乘法不同,矩阵乘法是行与列的点积,而阿达玛积只是简单的元素相乘。
# -*- coding: utf-8 -*-
# @Author: CSDN@逐梦苍穹
# @Time: 2024/7/16 2:25
import torchdef test():data1 = torch.tensor([[1, 2], [3, 4]])data2 = torch.tensor([[5, 6], [7, 8]])# 第一种方式data = torch.mul(data1, data2)print(data)print('-' * 50)# 第二种方式data = data1 * data2print(data)print('-' * 50)if __name__ == '__main__':test()

3、点积运算
点积(Dot Product)是向量计算中的一种基本运算,它将两个向量对应元素相乘并求和。
点积在机器学习和深度学习中广泛应用于各种计算,如向量相似性、神经网络中的加权和计算等。

点积运算要求第一个矩阵 shape: (n, m),
第二个矩阵 shape: (m, p),
两个矩阵点积运算 shape 为: (n, p)。
- 运算符 @ 用于进行两个矩阵的点乘运算
- torch.mm 用于进行两个矩阵点乘运算, 要求输入的矩阵为2维
- torch.bmm 用于批量进行矩阵点乘运算, 要求输入的矩阵为3维
- torch.matmul 对进行点乘运算的两矩阵形状没有限定.
- 对于输入都是二维的张量相当于 mm 运算.
- 对于输入都是三维的张量相当于 bmm 运算
- 对数输入的 shape 不同的张量, 对应的最后几个维度必须符合矩阵运算规则
三维矩阵:

torch.randn(3, 4, 5)参数个数不限,从左到右依次是维度。
# -*- coding: utf-8 -*-
# @Author: CSDN@逐梦苍穹
# @Time: 2024/7/16 2:35
import torch# 1. 点积运算
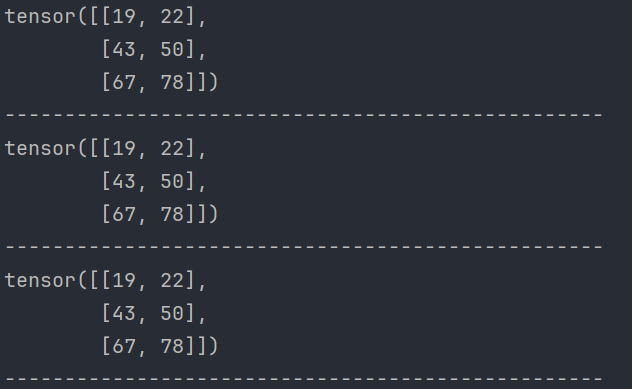
def test01():# 创建两个张量,data1 为 3x2 矩阵,data2 为 2x2 矩阵data1 = torch.tensor([[1, 2], [3, 4], [5, 6]])data2 = torch.tensor([[5, 6], [7, 8]])# 第一种方式:使用 @ 运算符进行矩阵乘法(点积运算)data = data1 @ data2print(data)print('-' * 50)# 第二种方式:使用 torch.mm 函数进行矩阵乘法data = torch.mm(data1, data2)print(data)print('-' * 50)# 第三种方式:使用 torch.matmul 函数进行矩阵乘法data = torch.matmul(data1, data2)print(data)print('-' * 50)# 2. torch.mm 和 torch.matmul 的区别
def test02():# matmul 可以处理不同维度的张量# 第一个张量的形状为 (3, 4, 5)# 第二个张量的形状为 (5, 4)# torch.mm 只能处理二维矩阵的乘法,而 matmul 可以处理高维度张量的乘法print(torch.randn(3, 4, 5))print(torch.matmul(torch.randn(3, 4, 5), torch.randn(5, 4)).shape)# 反转张量的顺序,第二个张量的形状为 (3, 4, 5)# 第一个张量的形状为 (5, 4)# 结果形状仍然符合矩阵乘法规则print(torch.matmul(torch.randn(5, 4), torch.randn(3, 4, 5)).shape)# 3. torch.bmm 函数的用法
def test03():# 批量点积运算# 第一个维度为 batch_size# data1 的形状为 (3, 4, 5)# data2 的形状为 (3, 5, 8)# torch.bmm 可以处理批量的矩阵乘法data1 = torch.randn(3, 4, 5)data2 = torch.randn(3, 5, 8)# 进行批量矩阵乘法运算,结果形状为 (3, 4, 8)data = torch.bmm(data1, data2)print(data.shape)
4、指定运算设备⭐
PyTorch 默认会将张量创建在 CPU 控制的内存中, 即: 默认的运算设备为 CPU。
我们也可以将张量创建在 GPU 上, 能够利用对于矩阵计算的优势加快模型训练。
将张量移动到 GPU 上有两种方法:
- 使用 cuda 方法
- 直接在 GPU 上创建张量
- 使用 to 方法指定设备
| 指定设备的方式 | 示例代码 | 代码解释 |
|---|---|---|
使用 cuda 方法 | python data = torch.tensor([10, 20, 30]) data = data.cuda() | 使用 cuda() 方法将张量从 CPU 移动到 GPU。 |
| 在创建张量时指定设备 | python data = torch.tensor([10, 20, 30], device='cuda:0') | 在创建张量时,通过 device 参数直接指定设备为 GPU。 |
使用 to 方法 | python data = torch.tensor([10, 20, 30]) data = data.to('cuda:0') | 使用 to() 方法将张量从 CPU 移动到 GPU。 |
使用 cpu 方法 | python data = data.cpu() | 使用 cpu() 方法将张量从 GPU 移动到 CPU。 |
使用 torch.device | python device = torch.device("cuda" if torch.cuda.is_available() else "cpu") tensor = torch.randn(3, 4, 5, device=device) | 使用 torch.device 动态选择设备,并在创建张量时指定设备。 |
# -*- coding: utf-8 -*-
# @Author: CSDN@逐梦苍穹
# @Time: 2024/7/16 2:58
import torch
import torchvision# 1. 使用 cuda 方法
def test01():data = torch.tensor([10, 20, 30])print('存储设备:', data.device)# 如果安装的不是 gpu 版本的 PyTorch# 或电脑本身没有 NVIDIA 卡的计算环境# 下面代码可能会报错data = data.cuda()print('存储设备:', data.device)# 使用 cpu 函数将张量移动到 cpu 上data = data.cpu()print('存储设备:', data.device)# 输出结果:# 存储设备: cpu# 存储设备: cuda:0# 存储设备: cpu# 2. 直接将张量创建在 GPU 上
def test02():data = torch.tensor([10, 20, 30], device='cuda:0')print('存储设备:', data.device)# 使用 cpu 函数将张量移动到 cpu 上data = data.cpu()print('存储设备:', data.device)# 输出结果:# 存储设备: cuda:0# 存储设备: cpu# 3. 使用 to 方法
def test03():data = torch.tensor([10, 20, 30])print('存储设备:', data.device)data = data.to('cuda:0')print('存储设备:', data.device)# 输出结果:# 存储设备: cpu# 存储设备: cuda:0# 4. 存储在不同设备的张量不能运算
def test04():data1 = torch.tensor([10, 20, 30], device='cuda:0')data2 = torch.tensor([10, 20, 30])print(data1.device, data2.device)# RuntimeError: Expected all tensors to be on the same device,# but found at least two devices, cuda:0 and cpu!data = data1 + data2print(data)def test05():# 检查CUDA是否可用,并选择设备device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# device = "cpu"print("Using device:", device)# 构建一个形状为 (3, 4, 5) 的随机张量,并指定设备tensor = torch.randn(3, 4, 5, device=device)print("Tensor:", tensor)print("Shape:", tensor.shape)print("Device:", tensor.device)data = torch.randn(5, 4, device=device)print(torch.matmul(tensor, data))def test06():print("PyTorch版本: ", torch.__version__) # 打印PyTorch版本print("torchvision版本 ", torchvision.__version__) # 打印torchvision版本print("CUDA是否可用: ", torch.cuda.is_available()) # 检查CUDA是否可用if __name__ == '__main__':test04()
5、解决在GPU运行PyTorch的问题
请参考我的这篇文章:https://xzl-tech.blog.csdn.net/article/details/140478985


![【BUG】已解决:OSError: [Errno 22] Invalid argument](https://img-blog.csdnimg.cn/direct/df413fc3bbea46f7962bc7fe31fa6a01.png)