目录
一、顺序表的概念
二、顺序表的接口实现
1.顺序表初始化
2.顺序表销毁
3.检查空间并扩容
4.顺序表尾插、顺序表头插
5.顺序表尾删、顺序表头删
6.顺序表查找
7.顺序表在pos位置插入x、删除pos位置的值
三、完整代码
四、总结
一、顺序表的概念
顺序表是用一段物理地址连续的存储单元依次存储数据元素的线性结构,一般情况下采用数组存 储。在数组上完成数据的增删查改。
顺序表一般可以分为:
静态:使用定长数组存储元素
#define N 10
typedef int SLDataType;
typedef struct SeqList
{SLDateType a[N];//定长数组size_t size; //有效数据的个数
}SL;这个就是静态的顺序表的结构体,但是静态的是存在缺陷的,比如我们如果要存11个数据,这样就存不下来,如果我们这个N给的太大,就浪费内存空间,所以我们用动态开辟的方法来实现才是最好的。
动态:使用动态开辟的数组存储
typedef int SLDataType;
typedef struct SeqList
{SLDateType* a; //指向动态开辟的数组int size; //有效数据的个数int capicity //容量空间的大小
}SL;二、顺序表的接口实现
SeqList.h:内容包括头文件的包含,结构体定义和接口函数的声明。顺序表的接口包括顺序表的初始化、增 (头插、尾插、指定下标)删(头删、尾删、指定下标)查改。
//SeqLish.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<assert.h>
typedef int SLDatatype;
typedef struct SeqLish
{ SLDatatype* a;int size;int capacity;
}SL;void SLInit(SL* ps1);//初始化void SLDesttoy(SL* ps1);//结束 释放顺序表void SLPrint(SL* ps1);//打印
void SLCheckCapacity(SL* ps1);//扩容
void SLPushBack(SL* ps1,SLDatatype x); //尾插
void SLPushFront(SL* ps1,SLDatatype x);//头插void SLPopBack(SL* ps1); //尾删
void SLPopFront(SL* ps1);//头删void SLInsert(SL* ps1, int pos,SLDatatype x);//指定增加
void SLErase(SL* ps1, int pos);//指定删除//找到返回下标,没有找到返回-1
int SLFind(SL* ps1, SLDatatype x);//查
void SLModify(SL* ps1, int pos, SLDatatype x);//改SeqList.c:主要内容为函数接口的实现。
1.顺序表初始化
一般先初始化四个元素
void SLInit(SL* ps1)
{ps1->a = (SLDatatype*)malloc(sizeof(SLDatatype*) * 4);if (ps1->a == NULL){perror("malloc err");return;}ps1->capacity = 4;ps1->size = 0;
}2.顺序表销毁
void SLDesttoy(SL* ps1)
{free(ps1->a);ps1->a = NULL;ps1->capacity = 0;ps1->size = 0;
}3.检查空间并扩容
void SLCheckCapacity(SL* ps1)
{if (ps1->size == ps1->capacity){SLDatatype* tmp = (SLDatatype*)realloc(ps1->a, sizeof(SLDatatype) * ps1->capacity * 2);if (tmp == NULL){perror("realloc err");return;}ps1->a = tmp;ps1->capacity *= 2;}
}4.顺序表尾插、顺序表头插
尾插:
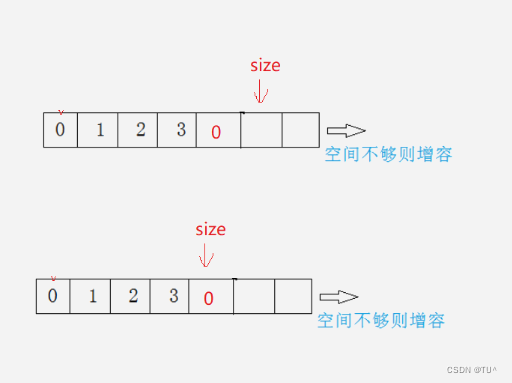
void SLPushBack(SL* ps1, SLDatatype x)
{SLCheckCapacity(ps1);ps1->a[ps1->size] = x;ps1->size++;
}头插:
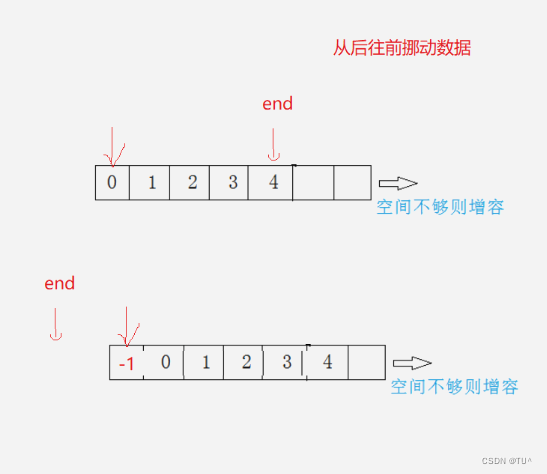
void SLPushFront(SL* ps1, SLDatatype x)
{SLCheckCapacity(ps1);int end = ps1->size - 1;while (end >= 0){ps1->a[end + 1] = ps1->a[end];end--;}ps1->a[0] = x;ps1->size++;
}5.顺序表尾删、顺序表头删
尾删:
size直接--就是尾插
void SLPopBack(SL* ps1)
{assert(ps1->size > 0);ps1->size--;
}
头删:
后往前覆盖数据
void SLPopFront(SL* ps1)
{assert(ps1->size > 0);int strat = 0;while (strat < ps1->size - 1){ps1->a[strat] = ps1->a[strat + 1];strat++;}ps1->size--;
}
6.顺序表查找
int SLFind(SL* ps1, SLDatatype x)
{for (int i = 0; i < ps1->size; i++){if (ps1->a[i] == ps1->a[x]){return i;}}return -1;
}7.顺序表在pos位置插入x、删除pos位置的值
pos插入x
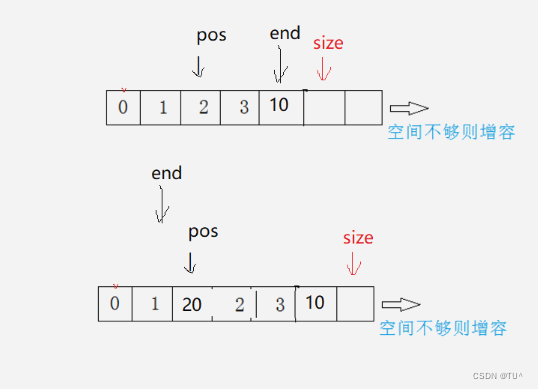
void SLInsert(SL* ps1, int pos, SLDatatype x)
{assert(0 <= pos && pos <= ps1->size);SLCheckCapacity(ps1);int end = ps1->size - 1;while (end >= pos){ps1->a[end + 1] = ps1->a[end];end--;}ps1->a[pos] = x;ps1->size++;
}删除pos

void SLErase(SL* ps1, int pos)
{assert(0 <= pos && pos < ps1->size);int strat = pos + 1;while (strat < ps1->size){ps1->a[strat - 1] = ps1->a[strat];strat++;}ps1->size--;
}
三、完整代码
SeqLish.h:
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<assert.h>
typedef int SLDatatype;
typedef struct SeqLish
{ SLDatatype* a;int size;int capacity;
}SL;
void SLInit(SL* ps1);//初始化
void SLDesttoy(SL* ps1);//结束 释放顺序表
void SLPrint(SL* ps1);//打印
void SLCheckCapacity(SL* ps1);//扩容
void SLPushBack(SL* ps1,SLDatatype x); //尾插
void SLPushFront(SL* ps1,SLDatatype x);//头插
void SLPopBack(SL* ps1); //尾删
void SLPopFront(SL* ps1);//头删
void SLInsert(SL* ps1, int pos,SLDatatype x);//指定增加
void SLErase(SL* ps1, int pos);//指定删除
//找到返回下标,没有找到返回-1
int SLFind(SL* ps1, SLDatatype x);//查
void SLModify(SL* ps1, int pos, SLDatatype x);//改SeqLish.c:
#include"SeqList.h"
void SLInit(SL* ps1)
{ps1->a = (SLDatatype*)malloc(sizeof(SLDatatype*) * 4);if (ps1->a == NULL){perror("malloc err");return;}ps1->capacity = 4;ps1->size = 0;
}void SLDesttoy(SL* ps1)
{free(ps1->a);ps1->a = NULL;ps1->capacity = 0;ps1->size = 0;
}void SLPrint(SL* ps1)
{for (int i = 0; i < ps1->size;i++){printf("%d ",ps1->a[i]);}printf("\n");
}void SLCheckCapacity(SL* ps1)
{if (ps1->size == ps1->capacity){SLDatatype* tmp = (SLDatatype*)realloc(ps1->a, sizeof(SLDatatype) * ps1->capacity * 2);if (tmp == NULL){perror("realloc err");return;}ps1->a = tmp;ps1->capacity *= 2;}
}void SLPushBack(SL* ps1, SLDatatype x)
{SLCheckCapacity(ps1);ps1->a[ps1->size] = x;ps1->size++;
}
void SLPushFront(SL* ps1, SLDatatype x)
{SLCheckCapacity(ps1);int end = ps1->size - 1;while (end >= 0){ps1->a[end + 1] = ps1->a[end];end--;}ps1->a[0] = x;ps1->size++;
}void SLPopBack(SL* ps1)
{assert(ps1->size > 0);ps1->size--;
}
void SLPopFront(SL* ps1)
{assert(ps1->size > 0);int strat = 0;while (strat < ps1->size - 1){ps1->a[strat] = ps1->a[strat + 1];strat++;}ps1->size--;
}void SLInsert(SL* ps1, int pos, SLDatatype x)
{assert(0 <= pos && pos <= ps1->size);SLCheckCapacity(ps1);int end = ps1->size - 1;while (end >= pos){ps1->a[end + 1] = ps1->a[end];end--;}ps1->a[pos] = x;ps1->size++;
}
void SLErase(SL* ps1, int pos)
{assert(0 <= pos && pos < ps1->size);int strat = pos + 1;while (strat < ps1->size){ps1->a[strat - 1] = ps1->a[strat];strat++;}ps1->size--;
}int SLFind(SL* ps1, SLDatatype x)
{for (int i = 0; i < ps1->size; i++){if (ps1->a[i] == ps1->a[x]){return i;}}return -1;
}
void SLModify(SL* ps1, int pos, SLDatatype x)
{assert(0 <= pos && pos < ps1->size);ps1->a[pos] = x;
}四、总结
定义:顺序表是用一组连续的存储单元依次存储数据元素的线性结构。
特点:
1. 逻辑顺序与物理顺序一致:元素顺序存储,相邻元素物理位置相邻。
2. 可以快速访问任意元素:通过索引直接访问元素。
优点:
1. 实现简单。
2. 随机访问方便。
缺点:
1. 插入、删除操作可能需要移动大量元素,效率较低。
2. 需要预先确定固定的存储空间,可能造成空间浪费或不足。
基本操作:包括初始化、插入、删除、查找、遍历等。