模型简介
生成式对抗网络(Generative Adversarial Networks,GAN)是一种生成式机器学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。
最初,GAN由Ian J. Goodfellow于2014年发明,并在论文Generative Adversarial Nets中首次进行了描述,其主要由两个不同的模型共同组成——生成器(Generative Model)和判别器(Discriminative Model):
- 生成器的任务是生成看起来像训练图像的“假”图像;
- 判别器需要判断从生成器输出的图像是真实的训练图像还是虚假的图像。
GAN通过设计生成模型和判别模型这两个模块,使其互相博弈学习产生了相当好的输出。
GAN模型的核心在于提出了通过对抗过程来估计生成模型这一全新框架。在这个框架中,将会同时训练两个模型——捕捉数据分布的生成模型 和估计样本是否来自训练数据的判别模型 。
在训练过程中,生成器会不断尝试通过生成更好的假图像来骗过判别器,而判别器在这过程中也会逐步提升判别能力。这种博弈的平衡点是,当生成器生成的假图像和训练数据图像的分布完全一致时,判别器拥有50%的真假判断置信度。
用 代表图像数据,用 表示判别器网络给出图像判定为真实图像的概率。在判别过程中, 需要处理作为二进制文件的大小为 的图像数据。当 来自训练数据时, 数值应该趋近于 ;而当 来自生成器时, 数值应该趋近于 。因此 也可以被认为是传统的二分类器。
用 代表标准正态分布中提取出的隐码(隐向量),用 :表示将隐码(隐向量) 映射到数据空间的生成器函数。函数 的目标是将服从高斯分布的随机噪声 通过生成网络变换为近似于真实分布 的数据分布,我们希望找到 使得 和 尽可能的接近,其中 代表网络参数。
表示生成器 生成的假图像被判定为真实图像的概率,如Generative Adversarial Nets中所述, 和 在进行一场博弈, 想要最大程度的正确分类真图像与假图像,也就是参数 ;而 试图欺骗 来最小化假图像被识别到的概率,也就是参数 。因此GAN的损失函数为:
从理论上讲,此博弈游戏的平衡点是,此时判别器会随机猜测输入是真图像还是假图像。下面我们简要说明生成器和判别器的博弈过程:
- 在训练刚开始的时候,生成器和判别器的质量都比较差,生成器会随机生成一个数据分布。
- 判别器通过求取梯度和损失函数对网络进行优化,将靠近真实数据分布的数据判定为1,将靠近生成器生成出来数据分布的数据判定为0。
- 生成器通过优化,生成出更加贴近真实数据分布的数据。
- 生成器所生成的数据和真实数据达到相同的分布,此时判别器的输出为1/2。
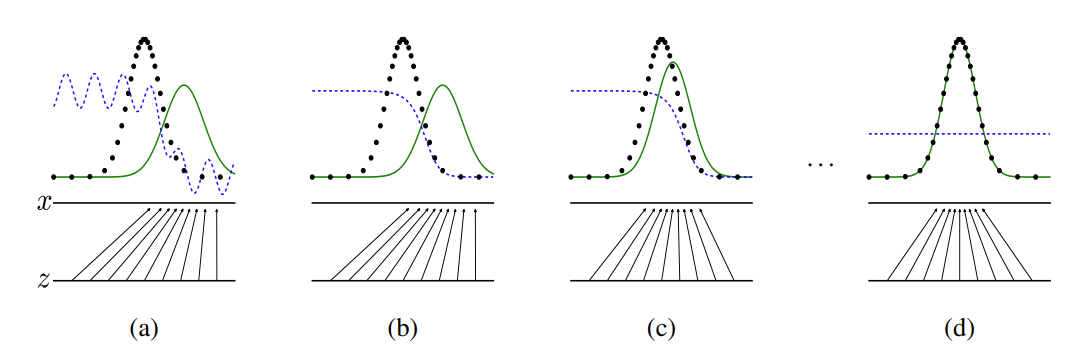
在上图中,蓝色虚线表示判别器,黑色虚线表示真实数据分布,绿色实线表示生成器生成的虚假数据分布, 表示隐码, 表示生成的虚假图像 。该图片来源于Generative Adversarial Nets。详细的训练方法介绍见原论文。
数据集
数据集简介
MNIST手写数字数据集是NIST数据集的子集,共有70000张手写数字图片,包含60000张训练样本和10000张测试样本,数字图片为二进制文件,图片大小为28*28,单通道。图片已经预先进行了尺寸归一化和中心化处理。
本案例将使用MNIST手写数字数据集来训练一个生成式对抗网络,使用该网络模拟生成手写数字图片。
数据集下载
使用download接口下载数据集,并将下载后的数据集自动解压到当前目录下。数据下载之前需要使用pip install download安装download包。
下载解压后的数据集目录结构如下:
./MNIST_Data/
├─ train
│ ├─ train-images-idx3-ubyte
│ └─ train-labels-idx1-ubyte
└─ test├─ t10k-images-idx3-ubyte└─ t10k-labels-idx1-ubyte
数据下载的代码如下:
# 数据下载
from download import download # 导入下载模块url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/MNIST_Data.zip" # 定义数据集的下载链接
download(url, ".", kind="zip", replace=True) # 下载数据集到当前目录,指定文件类型为zip,且如果存在同名文件则进行替换
解析:
from download import download:从download模块导入download函数,用于执行文件下载操作。url = "...":定义一个字符串变量url,存储需要下载的文件的网络地址。download(url, ".", kind="zip", replace=True):url:传入待下载的文件链接。".":指定下载到当前工作目录。kind="zip":指定下载文件的类型为zip压缩包。replace=True:如果目标目录中已存在同名文件,则替换该文件。
数据加载
使用MindSpore自己的MnistDatase接口,读取和解析MNIST数据集的源文件构建数据集。然后对数据进行一些前处理。
import numpy as np # 导入NumPy库,用于数值计算
import mindspore.dataset as ds # 导入MindSpore的数据集模块batch_size = 128 # 定义批量大小
latent_size = 100 # 隐码的长度# 加载MNIST训练集和测试集
train_dataset = ds.MnistDataset(dataset_dir='./MNIST_Data/train') # 加载训练数据集
test_dataset = ds.MnistDataset(dataset_dir='./MNIST_Data/test') # 加载测试数据集def data_load(dataset):# 创建生成数据集,指定数据项和是否打乱dataset1 = ds.GeneratorDataset(dataset, ["image", "label"], shuffle=True, python_multiprocessing=False)# 数据增强mnist_ds = dataset1.map(operations=lambda x: (x.astype("float32"), np.random.normal(size=latent_size).astype("float32")),output_columns=["image", "latent_code"]) # 对每个样本进行变换,生成浮点型图像和随机隐码mnist_ds = mnist_ds.project(["image", "latent_code"]) # 只保留图像和隐码两列# 批量操作mnist_ds = mnist_ds.batch(batch_size, True) # 将数据集分批,batch_size为每批样本大小return mnist_ds # 返回处理后的数据集# 加载训练集数据
mnist_ds = data_load(train_dataset)# 获取数据集的迭代器大小
iter_size = mnist_ds.get_dataset_size() # 获取数据集的总批次数
print('Iter size: %d' % iter_size) # 打印迭代器大小
解析:
import numpy as np:导入NumPy库,通常用于高效的数值计算和数组操作。import mindspore.dataset as ds:导入MindSpore的dataset模块,用于处理数据集。batch_size和latent_size:定义批量大小和隐码的长度,用于后续的数据处理。ds.MnistDataset(...):加载MNIST数据集的训练和测试部分。def data_load(dataset)::定义一个函数data_load,用于对输入的数据集进行处理。ds.GeneratorDataset(...):创建生成器数据集,指定数据项(图像和标签),设置是否打乱数据。dataset1.map(...):对每个样本进行映射操作,使用匿名函数(lambda)生成浮点型的图像和随机隐码。mnist_ds.project(...):选择需要保留的数据列,过滤掉不需要的列。mnist_ds.batch(...):对数据集进行批量处理,设置每批的数据量为batch_size。mnist_ds.get_dataset_size():获取数据集的总批次数,即迭代器的大小。
数据集可视化
通过create_dict_iterator函数将数据转换成字典迭代器,然后使用matplotlib模块可视化部分训练数据。
import matplotlib.pyplot as plt # 导入Matplotlib库用于数据可视化# 创建一个数据迭代器,并获取下一个数据批次
data_iter = next(mnist_ds.create_dict_iterator(output_numpy=True))# 设置图形的大小
figure = plt.figure(figsize=(3, 3))cols, rows = 5, 5 # 定义网格的列数和行数
for idx in range(1, cols * rows + 1): # 循环绘制5x5的图像image = data_iter['image'][idx] # 从数据迭代器中获取第idx个图像figure.add_subplot(rows, cols, idx) # 在图形中添加子图plt.axis("off") # 关闭坐标轴plt.imshow(image.squeeze(), cmap="gray") # 显示图像,使用灰度色图plt.show() # 显示图形
解析:
import matplotlib.pyplot as plt:导入Matplotlib库的pyplot模块,用于绘图和数据可视化。data_iter = next(mnist_ds.create_dict_iterator(output_numpy=True)):创建一个字典形式的数据迭代器,并获取下一个批次的数据,设置output_numpy=True使输出为NumPy数组。figure = plt.figure(figsize=(3, 3)):创建一个新的图形,指定图形的大小为3x3英寸。cols, rows = 5, 5:定义绘图网格的列数和行数,这里设置为5列5行,共25个子图。for idx in range(1, cols * rows + 1)::循环遍历,从1到25,绘制25个图像。image = data_iter['image'][idx]:从数据迭代器中提取第idx个图像。figure.add_subplot(rows, cols, idx):在图形中添加一个子图,位置由idx指定。plt.axis("off"):关闭当前子图的坐标轴显示。plt.imshow(image.squeeze(), cmap="gray"):显示图像,使用squeeze()去掉单维度,设置色图为灰度(gray)。plt.show():渲染并显示图形。

隐码构造
为了跟踪生成器的学习进度,我们在训练的过程中的每轮迭代结束后,将一组固定的遵循高斯分布的隐码test_noise输入到生成器中,通过固定隐码所生成的图像效果来评估生成器的好坏。
import random # 导入随机库,用于随机数生成和洗牌
import numpy as np # 导入NumPy库,用于数值计算
from mindspore import Tensor # 从MindSpore中导入Tensor类
from mindspore.common import dtype # 导入数据类型模块# 利用随机种子创建一批隐码
np.random.seed(2323) # 设置NumPy的随机种子,以便于结果可复现
test_noise = Tensor(np.random.normal(size=(25, 100)), dtype.float32) # 生成一个形状为(25, 100)的正态分布隐码,并转换为MindSpore Tensor类型
random.shuffle(test_noise) # 打乱生成的隐码顺序
解析:
import random:导入Python的随机库,用于生成随机数和进行随机操作。import numpy as np:导入NumPy库,用于高效的数值计算和数组操作。from mindspore import Tensor:从MindSpore库导入Tensor类,用于创建张量对象。from mindspore.common import dtype:导入MindSpore中的数据类型模块,以便于后续指定张量的数据类型。np.random.seed(2323):设置NumPy的随机种子为2323,这样可以确保每次运行代码时生成相同的随机数。test_noise = Tensor(np.random.normal(size=(25, 100)), dtype.float32):np.random.normal(size=(25, 100)):生成一个形状为(25, 100)的正态分布随机数数组。Tensor(...):将生成的NumPy数组转换为MindSpore的Tensor对象,并指定数据类型为float32。
random.shuffle(test_noise):打乱test_noise数组中的元素顺序(注意:shuffle()方法通常用于列表,不适用于NumPy数组。如果需要打乱NumPy数组,应使用np.random.shuffle())。
模型构建
本案例实现中所搭建的 GAN 模型结构与原论文中提出的 GAN 结构大致相同,但由于所用数据集 MNIST 为单通道小尺寸图片,可识别参数少,便于训练,我们在判别器和生成器中采用全连接网络架构和 ReLU 激活函数即可达到令人满意的效果,且省略了原论文中用于减少参数的 Dropout 策略和可学习激活函数 Maxout。
生成器
生成器 Generator 的功能是将隐码映射到数据空间。由于数据是图像,这一过程也会创建与真实图像大小相同的灰度图像(或 RGB 彩色图像)。在本案例演示中,该功能通过五层 Dense 全连接层来完成的,每层都与 BatchNorm1d 批归一化层和 ReLU 激活层配对,输出数据会经过 Tanh 函数,使其返回 [-1,1] 的数据范围内。注意实例化生成器之后需要修改参数的名称,不然静态图模式下会报错。
from mindspore import nn # 导入MindSpore的神经网络模块
import mindspore.ops as ops # 导入MindSpore的操作模块img_size = 28 # 训练图像的长(宽)class Generator(nn.Cell): # 定义生成器类,继承自nn.Celldef __init__(self, latent_size, auto_prefix=True): # 初始化方法super(Generator, self).__init__(auto_prefix=auto_prefix) # 调用父类构造函数self.model = nn.SequentialCell() # 创建一个顺序模型容器# [N, 100] -> [N, 128]# 输入100维的高斯分布,通过线性层映射到128维self.model.append(nn.Dense(latent_size, 128)) # 添加第一层全连接层self.model.append(nn.ReLU()) # 添加ReLU激活函数# [N, 128] -> [N, 256]self.model.append(nn.Dense(128, 256)) # 添加第二层全连接层self.model.append(nn.BatchNorm1d(256)) # 添加批量归一化层self.model.append(nn.ReLU()) # 添加ReLU激活函数# [N, 256] -> [N, 512]self.model.append(nn.Dense(256, 512)) # 添加第三层全连接层self.model.append(nn.BatchNorm1d(512)) # 添加批量归一化层self.model.append(nn.ReLU()) # 添加ReLU激活函数# [N, 512] -> [N, 1024]self.model.append(nn.Dense(512, 1024)) # 添加第四层全连接层self.model.append(nn.BatchNorm1d(1024)) # 添加批量归一化层self.model.append(nn.ReLU()) # 添加ReLU激活函数# [N, 1024] -> [N, 784]# 线性变换将输出维度变为784self.model.append(nn.Dense(1024, img_size * img_size)) # 添加第五层全连接层# 经过Tanh激活函数将输出范围压缩到[-1, 1]self.model.append(nn.Tanh()) # 添加Tanh激活函数def construct(self, x): # 定义前向传播方法img = self.model(x) # 通过模型获取生成的图像return ops.reshape(img, (-1, 1, 28, 28)) # 将输出重塑为形状 (-1, 1, 28, 28)# 创建生成器实例,latent_size为隐码的维度
net_g = Generator(latent_size)
net_g.update_parameters_name('generator') # 更新网络参数名称为'generator'
解析:
from mindspore import nn:导入MindSpore的神经网络模块(nn),用于构建深度学习模型。import mindspore.ops as ops:导入MindSpore的操作模块(ops),用于执行各种操作。img_size = 28:定义训练图像的长和宽为28。class Generator(nn.Cell)::定义一个生成器类Generator,继承自nn.Cell,表示一个可训练的模型。def __init__(self, latent_size, auto_prefix=True)::初始化生成器,接受隐码的维度latent_size作为参数。super(Generator, self).__init__(auto_prefix=auto_prefix):调用父类的构造方法,初始化模型。self.model = nn.SequentialCell():创建一个顺序模型容器,用于按顺序添加层。- 添加多个全连接层(
nn.Dense)和ReLU激活函数,并使用批量归一化(nn.BatchNorm1d)对中间层进行归一化处理。 - 最后一个全连接层将输出维度变为784(28*28),然后通过
nn.Tanh()激活函数将输出值限制在[-1, 1]之间,使其适合生成图像数据。 def construct(self, x)::定义前向传播方法,接收输入x并通过模型生成图像。ops.reshape(img, (-1, 1, 28, 28)):将生成的图像重塑为形状为(-1, 1, 28, 28)的张量。net_g = Generator(latent_size):创建生成器实例net_g,并传入隐码的维度。net_g.update_parameters_name('generator'):将生成器的参数名称更新为’generator’。
判别器
如前所述,判别器 Discriminator 是一个二分类网络模型,输出判定该图像为真实图的概率。主要通过一系列的 Dense 层和 LeakyReLU 层对其进行处理,最后通过 Sigmoid 激活函数,使其返回 [0, 1] 的数据范围内,得到最终概率。注意实例化判别器之后需要修改参数的名称,不然静态图模式下会报错。
# 判别器
class Discriminator(nn.Cell): # 定义判别器类,继承自nn.Celldef __init__(self, auto_prefix=True): # 初始化方法super().__init__(auto_prefix=auto_prefix) # 调用父类构造函数self.model = nn.SequentialCell() # 创建一个顺序模型容器# [N, 784] -> [N, 512]self.model.append(nn.Dense(img_size * img_size, 512)) # 输入特征数为784,输出为512self.model.append(nn.LeakyReLU()) # 添加LeakyReLU激活函数,默认斜率为0.2# [N, 512] -> [N, 256]self.model.append(nn.Dense(512, 256)) # 进行线性映射,将512维映射到256维self.model.append(nn.LeakyReLU()) # 添加LeakyReLU激活函数# [N, 256] -> [N, 1]self.model.append(nn.Dense(256, 1)) # 进行线性映射,将256维映射到1维self.model.append(nn.Sigmoid()) # 添加Sigmoid激活函数,将输出映射到[0, 1]def construct(self, x): # 定义前向传播方法x_flat = ops.reshape(x, (-1, img_size * img_size)) # 将输入重塑为(-1, 784)的形状return self.model(x_flat) # 通过模型计算并返回结果# 创建判别器实例
net_d = Discriminator()
net_d.update_parameters_name('discriminator') # 更新网络参数名称为'discriminator'
解析:
class Discriminator(nn.Cell)::定义一个判别器类Discriminator,继承自nn.Cell,表示一个可训练的模型。def __init__(self, auto_prefix=True)::初始化判别器,接受一个可选参数auto_prefix。super().__init__(auto_prefix=auto_prefix):调用父类的构造方法,初始化模型。self.model = nn.SequentialCell():创建一个顺序模型容器,用于按顺序添加层。- 添加多个全连接层(
nn.Dense)和LeakyReLU激活函数:- 第一层将输入的784维特征映射到512维。
- 第二层将512维特征映射到256维。
- 最后一层将256维特征映射到1维,输出为判别结果。
self.model.append(nn.Sigmoid()):添加Sigmoid激活函数,将输出值限制在[0, 1]之间,表示输入为假的概率。def construct(self, x)::定义前向传播方法,接收输入x。x_flat = ops.reshape(x, (-1, img_size * img_size)):将输入重塑为形状为(-1, 784)的张量,以适应模型输入。return self.model(x_flat):通过模型计算并返回判别结果。net_d = Discriminator():创建判别器实例net_d。net_d.update_parameters_name('discriminator'):将判别器的参数名称更新为’discriminator’。
损失函数和优化器
定义了 Generator 和 Discriminator 后,损失函数使用MindSpore中二进制交叉熵损失函数BCELoss ;这里生成器和判别器都是使用Adam优化器,但是需要构建两个不同名称的优化器,分别用于更新两个模型的参数,详情见下文代码。注意优化器的参数名称也需要修改。
lr = 0.0002 # 学习率设置为0.0002# 损失函数
adversarial_loss = nn.BCELoss(reduction='mean') # 使用二元交叉熵损失函数,计算生成器和判别器的损失# 优化器
optimizer_d = nn.Adam(net_d.trainable_params(), learning_rate=lr, beta1=0.5, beta2=0.999) # 创建判别器的Adam优化器
optimizer_g = nn.Adam(net_g.trainable_params(), learning_rate=lr, beta1=0.5, beta2=0.999) # 创建生成器的Adam优化器
optimizer_g.update_parameters_name('optim_g') # 更新生成器的优化器参数名称为'optim_g'
optimizer_d.update_parameters_name('optim_d') # 更新判别器的优化器参数名称为'optim_d'
解析:
lr = 0.0002:定义学习率,设置为0.0002,这个值通常用于训练生成对抗网络(GAN)。adversarial_loss = nn.BCELoss(reduction='mean'):定义损失函数为二元交叉熵损失(Binary Cross Entropy Loss),用于计算生成器和判别器的损失值,reduction='mean'表示将损失值取平均。optimizer_d = nn.Adam(net_d.trainable_params(), learning_rate=lr, beta1=0.5, beta2=0.999):- 创建判别器的Adam优化器,传入判别器可训练参数
net_d.trainable_params()。 learning_rate=lr设置学习率为0.0002。beta1=0.5和beta2=0.999是Adam优化器的超参数,通常用于控制动量和加速收敛。
- 创建判别器的Adam优化器,传入判别器可训练参数
optimizer_g = nn.Adam(net_g.trainable_params(), learning_rate=lr, beta1=0.5, beta2=0.999):- 创建生成器的Adam优化器,传入生成器可训练参数
net_g.trainable_params(),其余参数与判别器优化器相同。
- 创建生成器的Adam优化器,传入生成器可训练参数
optimizer_g.update_parameters_name('optim_g'):将生成器的优化器参数名称更新为’optim_g’,便于管理和调试。optimizer_d.update_parameters_name('optim_d'):将判别器的优化器参数名称更新为’optim_d’,便于管理和调试。
模型训练
训练分为两个主要部分。
第一部分是训练判别器。训练判别器的目的是最大程度地提高判别图像真伪的概率。按照原论文的方法,通过提高其随机梯度来更新判别器,最大化 的值。
第二部分是训练生成器。如论文所述,最小化 来训练生成器,以产生更好的虚假图像。
在这两个部分中,分别获取训练过程中的损失,并在每轮迭代结束时进行测试,将隐码批量推送到生成器中,以直观地跟踪生成器 Generator 的训练效果。
import os # 导入操作系统模块,用于文件和目录操作
import time # 导入时间模块,用于时间相关功能
import matplotlib.pyplot as plt # 导入matplotlib.pyplot用于绘图
import mindspore as ms # 导入MindSpore框架
from mindspore import Tensor, save_checkpoint # 从MindSpore导入Tensor类和保存检查点的函数total_epoch = 200 # 训练周期数,设置为200
batch_size = 128 # 用于训练的批量大小,设置为128# 加载预训练模型的参数
pred_trained = False # 预训练标志,初始化为False
pred_trained_g = './result/checkpoints/Generator99.ckpt' # 预训练生成器的检查点路径
pred_trained_d = './result/checkpoints/Discriminator99.ckpt' # 预训练判别器的检查点路径checkpoints_path = "./result/checkpoints" # 结果保存路径,用于保存模型检查点
image_path = "./result/images" # 测试结果保存路径,用于保存生成的图像
解析:
import os:导入操作系统模块,提供与操作系统交互的功能,例如文件和目录的操作。import time:导入时间模块,用于获取当前时间、延时操作等。import matplotlib.pyplot as plt:导入Matplotlib库的绘图库,用于可视化数据。import mindspore as ms:导入MindSpore框架,便于构建和训练深度学习模型。from mindspore import Tensor, save_checkpoint:从MindSpore导入Tensor类(用于表示张量)和save_checkpoint函数(用于保存模型检查点)。total_epoch = 200:定义训练的总周期数为200。batch_size = 128:定义训练过程中的批量大小为128,即每次训练使用128个样本。pred_trained = False:初始化预训练标志为False,表示尚未加载预训练模型。pred_trained_g = './result/checkpoints/Generator99.ckpt':定义预训练生成器模型的检查点路径。pred_trained_d = './result/checkpoints/Discriminator99.ckpt':定义预训练判别器模型的检查点路径。checkpoints_path = "./result/checkpoints":定义保存模型检查点的目录路径。image_path = "./result/images":定义保存生成测试结果图像的目录路径。
# 生成器计算损失过程
def generator_forward(test_noises):fake_data = net_g(test_noises) # 使用生成器生成假数据fake_out = net_d(fake_data) # 判别器对假数据的预测loss_g = adversarial_loss(fake_out, ops.ones_like(fake_out)) # 计算生成器损失return loss_g # 返回生成器损失# 判别器计算损失过程
def discriminator_forward(real_data, test_noises):fake_data = net_g(test_noises) # 使用生成器生成假数据fake_out = net_d(fake_data) # 判别器对假数据的预测real_out = net_d(real_data) # 判别器对真实数据的预测real_loss = adversarial_loss(real_out, ops.ones_like(real_out)) # 计算真实数据损失fake_loss = adversarial_loss(fake_out, ops.zeros_like(fake_out)) # 计算假数据损失loss_d = real_loss + fake_loss # 总判别器损失return loss_d # 返回判别器损失# 梯度方法
grad_g = ms.value_and_grad(generator_forward, None, net_g.trainable_params()) # 生成器的梯度计算
grad_d = ms.value_and_grad(discriminator_forward, None, net_d.trainable_params()) # 判别器的梯度计算def train_step(real_data, latent_code):# 计算判别器损失和梯度loss_d, grads_d = grad_d(real_data, latent_code) # 计算判别器损失及其梯度optimizer_d(grads_d) # 更新判别器参数loss_g, grads_g = grad_g(latent_code) # 计算生成器损失及其梯度optimizer_g(grads_g) # 更新生成器参数return loss_d, loss_g # 返回损失# 保存生成的图片
def save_imgs(gen_imgs1, idx):for i3 in range(gen_imgs1.shape[0]):plt.subplot(5, 5, i3 + 1) # 创建5x5的子图plt.imshow(gen_imgs1[i3, 0, :, :] / 2 + 0.5, cmap="gray") # 显示生成的图像plt.axis("off") # 不显示坐标轴plt.savefig(image_path + "/test_{}.png".format(idx)) # 保存生成的图像# 设置参数保存路径
os.makedirs(checkpoints_path, exist_ok=True) # 创建检查点保存路径
# 设置中间过程生成图片保存路径
os.makedirs(image_path, exist_ok=True) # 创建生成图片保存路径net_g.set_train() # 设置生成器为训练模式
net_d.set_train() # 设置判别器为训练模式# 储存生成器和判别器损失
losses_g, losses_d = [], [] # 初始化损失列表for epoch in range(total_epoch): # 进行训练周期start = time.time() # 记录开始时间for (iter, data) in enumerate(mnist_ds): # 遍历训练数据集start1 = time.time() # 记录每一步开始时间image, latent_code = data # 获取真实图像和潜在编码image = (image - 127.5) / 127.5 # 归一化图像到[-1, 1]image = image.reshape(image.shape[0], 1, image.shape[1], image.shape[2]) # 重塑图像形状d_loss, g_loss = train_step(image, latent_code) # 进行训练步骤end1 = time.time() # 记录每一步结束时间if iter % 10 == 0: # 每10步输出一次信息print(f"Epoch:[{int(epoch):>3d}/{int(total_epoch):>3d}], "f"step:[{int(iter):>4d}/{int(iter_size):>4d}], "f"loss_d:{d_loss.asnumpy():>4f} , "f"loss_g:{g_loss.asnumpy():>4f} , "f"time:{(end1 - start1):>3f}s, "f"lr:{lr:>6f}")end = time.time() # 记录每个epoch结束时间print("time of epoch {} is {:.2f}s".format(epoch + 1, end - start)) # 输出每个epoch耗时losses_d.append(d_loss.asnumpy()) # 保存判别器损失losses_g.append(g_loss.asnumpy()) # 保存生成器损失# 每个epoch结束后,使用生成器生成一组图片gen_imgs = net_g(test_noise) # 生成测试图像save_imgs(gen_imgs.asnumpy(), epoch) # 保存生成的图像# 根据epoch保存模型权重文件if epoch % 1 == 0: # 每个epoch保存一次save_checkpoint(net_g, checkpoints_path + "/Generator%d.ckpt" % (epoch)) # 保存生成器检查点save_checkpoint(net_d, checkpoints_path + "/Discriminator%d.ckpt" % (epoch)) # 保存判别器检查点
解析:
def generator_forward(test_noises)::定义生成器前向传播函数,计算生成器损失。fake_data = net_g(test_noises):生成器生成假数据。fake_out = net_d(fake_data):判别器对假数据进行分类。loss_g = adversarial_loss(fake_out, ops.ones_like(fake_out)):计算生成器损失。return loss_g:返回损失值。
def discriminator_forward(real_data, test_noises)::定义判别器前向传播函数,计算判别器损失。fake_data = net_g(test_noises):生成器生成假数据。fake_out = net_d(fake_data):判别器对假数据进行分类。real_out = net_d(real_data):判别器对真实数据进行分类。real_loss = adversarial_loss(real_out, ops.ones_like(real_out)):计算真实数据损失。fake_loss = adversarial_loss(fake_out, ops.zeros_like(fake_out)):计算假数据损失。loss_d = real_loss + fake_loss:总判别器损失。return loss_d:返回损失值。
grad_g = ms.value_and_grad(generator_forward, None, net_g.trainable_params()):计算生成器的损失和梯度。grad_d = ms.value_and_grad(discriminator_forward, None, net_d.trainable_params()):计算判别器的损失和梯度。def train_step(real_data, latent_code)::定义训练步骤,计算损失并更新模型。loss_d, grads_d = grad_d(real_data, latent_code):计算判别器损失和梯度。optimizer_d(grads_d):更新判别器参数。loss_g, grads_g = grad_g(latent_code):计算生成器损失和梯度。optimizer_g(grads_g):更新生成器参数。return loss_d, loss_g:返回损失。
def save_imgs(gen_imgs1, idx)::定义保存生成图像的函数。- 使用
plt.imshow显示图像,并使用plt.savefig保存图像。
- 使用
os.makedirs(checkpoints_path, exist_ok=True)和os.makedirs(image_path, exist_ok=True):创建保存检查点和图像的目录。net_g.set_train()和net_d.set_train():设置生成器和判别器为训练模式。- 训练循环:进行训练,计算损失,并每隔一定步数输出信息。
losses_d.append(d_loss.asnumpy())和losses_g.append(g_loss.asnumpy()):记录损失值。- 每个epoch结束后,生成并保存一组图像。
- 根据epoch保存模型权重。
效果展示
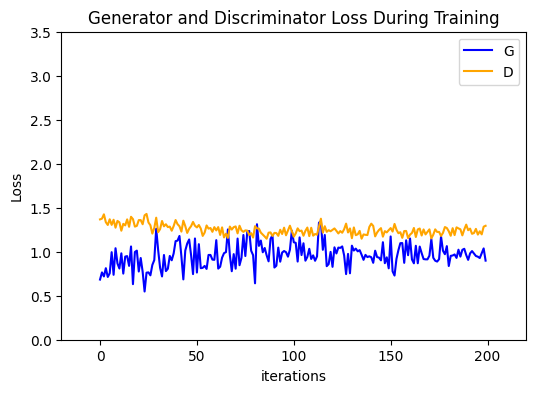
运行下面代码,描绘D和G损失与训练迭代的关系图:
plt.figure(figsize=(6, 4)) # 创建一个新的图形,设置大小为6x4英寸
plt.title("Generator and Discriminator Loss During Training") # 设置图形标题
plt.plot(losses_g, label="G", color='blue') # 绘制生成器损失曲线,标签为"G",颜色为蓝色
plt.plot(losses_d, label="D", color='orange') # 绘制判别器损失曲线,标签为"D",颜色为橙色
plt.xlim(-20, 220) # 设置x轴的范围
plt.ylim(0, 3.5) # 设置y轴的范围
plt.xlabel("iterations") # 设置x轴标签
plt.ylabel("Loss") # 设置y轴标签
plt.legend() # 显示图例
plt.show() # 展示图形
解析:
plt.figure(figsize=(6, 4)):创建一个新的图形,并设置其大小为6英寸宽、4英寸高。plt.title("Generator and Discriminator Loss During Training"):设置图形的标题为“训练过程中生成器和判别器的损失”。plt.plot(losses_g, label="G", color='blue'):绘制生成器损失的曲线,设置标签为"G"并使用蓝色。plt.plot(losses_d, label="D", color='orange'):绘制判别器损失的曲线,设置标签为"D"并使用橙色。plt.xlim(-20, 220):设置x轴的显示范围为-20到220。plt.ylim(0, 3.5):设置y轴的显示范围为0到3.5。plt.xlabel("iterations"):设置x轴的标签为“迭代次数”。plt.ylabel("Loss"):设置y轴的标签为“损失”。plt.legend():显示图例,标识不同的曲线。plt.show():展示绘制的图形。
可视化训练过程中通过隐向量生成的图像。
import cv2 # 导入OpenCV库用于图像处理
import matplotlib.animation as animation # 导入Matplotlib的动画模块# 将训练过程中生成的测试图转为动态图
image_list = [] # 初始化图像列表
for i in range(total_epoch): # 遍历每个epochimage_list.append(cv2.imread(image_path + "/test_{}.png".format(i), cv2.IMREAD_GRAYSCALE)) # 读取图像并添加到列表中,使用灰度模式show_list = [] # 初始化显示列表
fig = plt.figure(dpi=70) # 创建图形,设置分辨率为70 DPI
for epoch in range(0, len(image_list), 5): # 每5个epoch选择一个图像plt.axis("off") # 关闭坐标轴show_list.append([plt.imshow(image_list[epoch], cmap='gray')]) # 将图像添加到显示列表中,使用灰度色图# 创建动画
ani = animation.ArtistAnimation(fig, show_list, interval=1000, repeat_delay=1000, blit=True) # 设置动画参数
ani.save('train_test.gif', writer='pillow', fps=1) # 保存动画为GIF文件,帧率为1 FPS
解析:
import cv2:导入OpenCV库,用于处理图像文件。import matplotlib.animation as animation:导入Matplotlib的动画模块,用于制作动态图像。image_list = []:初始化一个空列表,用于存储读取的图像。for i in range(total_epoch)::遍历每个训练周期。image_list.append(cv2.imread(image_path + "/test_{}.png".format(i), cv2.IMREAD_GRAYSCALE)):读取指定路径下的图像文件并以灰度模式存储到image_list中。
show_list = []:初始化一个空列表,用于存储将要显示的图像帧。fig = plt.figure(dpi=70):创建一个新的图形,设置图形的分辨率为70 DPI。for epoch in range(0, len(image_list), 5)::每隔5个epoch选择一个图像进行显示。plt.axis("off"):关闭图形的坐标轴。show_list.append([plt.imshow(image_list[epoch], cmap='gray')]):将当前选择的图像以灰度色图形式添加到show_list中。
ani = animation.ArtistAnimation(fig, show_list, interval=1000, repeat_delay=1000, blit=True):创建动画对象,设置每帧间隔为1000毫秒,重复延迟为1000毫秒,启用blit优化。ani.save('train_test.gif', writer='pillow', fps=1):将创建的动画保存为名为train_test.gif的GIF文件,帧率设置为1帧每秒。
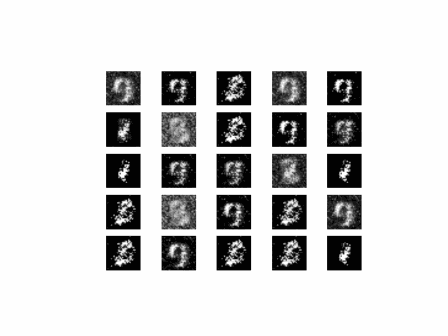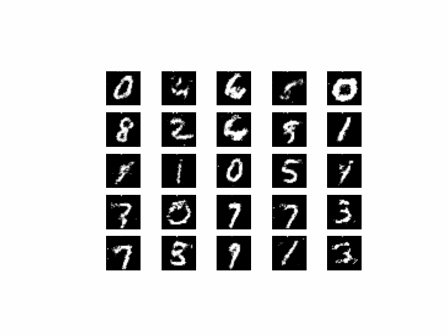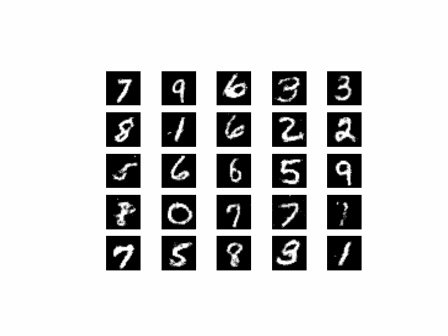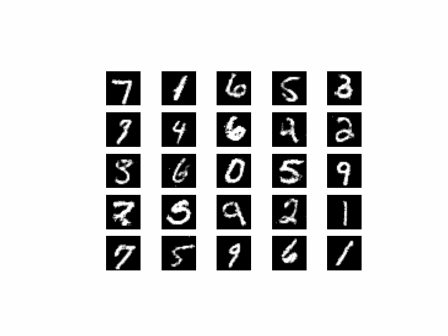
从上面的图像可以看出,随着训练次数的增多,图像质量也越来越好。如果增大训练周期数,当 epoch 达到100以上时,生成的手写数字图片与数据集中的较为相似。下面我们通过加载生成器网络模型参数文件来生成图像,代码如下:
模型推理
下面我们通过加载生成器网络模型参数文件来生成图像,代码如下:
import mindspore as ms # 导入MindSpore库# 指定要加载的检查点路径
test_ckpt = './result/checkpoints/Generator199.ckpt'# 加载模型参数
parameter = ms.load_checkpoint(test_ckpt) # 从指定路径加载检查点
ms.load_param_into_net(net_g, parameter) # 将参数加载到生成器网络net_g中# 模型生成结果
test_data = Tensor(np.random.normal(0, 1, (25, 100)).astype(np.float32)) # 生成随机噪声作为输入
images = net_g(test_data).transpose(0, 2, 3, 1).asnumpy() # 使用生成器生成图像并转换为NumPy数组# 结果展示
fig = plt.figure(figsize=(3, 3), dpi=120) # 创建一个新的图形,设置大小和分辨率
for i in range(25): # 遍历生成的25张图像fig.add_subplot(5, 5, i + 1) # 创建5x5的子图布局plt.axis("off") # 关闭坐标轴plt.imshow(images[i].squeeze(), cmap="gray") # 显示图像,使用灰度色图
plt.show() # 展示图形
解析:
import mindspore as ms:导入MindSpore库,用于深度学习框架的操作。test_ckpt = './result/checkpoints/Generator199.ckpt':指定要加载的生成器模型的检查点文件路径。parameter = ms.load_checkpoint(test_ckpt):使用ms.load_checkpoint函数从指定路径加载模型参数。ms.load_param_into_net(net_g, parameter):将加载的参数导入到生成器网络net_g中,使其可以使用这些参数生成图像。test_data = Tensor(np.random.normal(0, 1, (25, 100)).astype(np.float32)):生成一个形状为(25, 100)的随机噪声张量,符合标准正态分布,并转换为浮点数类型,以作为生成器的输入。images = net_g(test_data).transpose(0, 2, 3, 1).asnumpy():将随机噪声传入生成器net_g,生成图像,然后转换图像的维度并转为NumPy数组格式。fig = plt.figure(figsize=(3, 3), dpi=120):创建一个新的图形,设置大小为3x3英寸,分辨率为120 DPI。for i in range(25)::遍历生成的25张图像。fig.add_subplot(5, 5, i + 1):在5x5的子图布局中添加子图。plt.axis("off"):关闭子图的坐标轴。plt.imshow(images[i].squeeze(), cmap="gray"):显示当前图像,使用灰度色图,并去掉多余的维度。
plt.show():展示生成的图像。