文章目录
- 写在前面
- Task 1 - LRU-K Replacement Policy
- Task 2 - Disk Scheduler
- Task 3 - Buffer Pool Manager
- NewPage
- FetchPage
- UnpinPage
- DeletePage
- FlushPage
- 写在最后
写在前面
操作系统为应用程序提供了默认的缓存机制,DBMS作为应用程序,为什么不使用默认的缓存机制呢?因为DBMS需要对数据进行(1)空间控制:将经常使用的page写入到磁盘的连续位置,预读取page, (2)时间控制:何时将数据写回磁盘,何时读取数据到内存,使得磁盘I/O次数最少。为此,DBMS需要高度定制缓存策略。
在Project 1中,你需要实现DBMS的缓存池模块(Buffer Pool Manager),定制缓存策略,负责管理数据在磁盘和内存之间的流动。
Task 1 - LRU-K Replacement Policy
假设内存只能存储n个page,那么我们需要使用n个entry(条目)以表示位于内存中的page. 在Replacer中,通常用frame代替entry这个概念。并且用一个整数(frame_id_t)唯一标识frame. 因此我们只需要维护frame_id_t与page的访问记录,BusTub用std::unordered_map<frame_id_t, std::shared_ptr<LRUKNode>> node_store_表示它们之间的映射关系。
BusTub用LRUKNode描述page的访问记录,用LRUKReplacer描述LRU-K策略替换器。在实现具体函数之前,你需要熟悉这两个类的每个成员变量的含义。
此外,你还需要理解k-instance这一概念:当前时间戳与倒数第k次时间戳之差。这个“当前时间”指的是不断流动的绝对时间,而不是最后一次访问page的时间。k-instance随着时间而不断增大,由于所有frame的k-instance都在以同样的速度增加,我们可以忽略这部分增量,用倒数第k次时间戳表示k-instance.
比如k=2时,以下访问序列将产生的驱逐顺序:
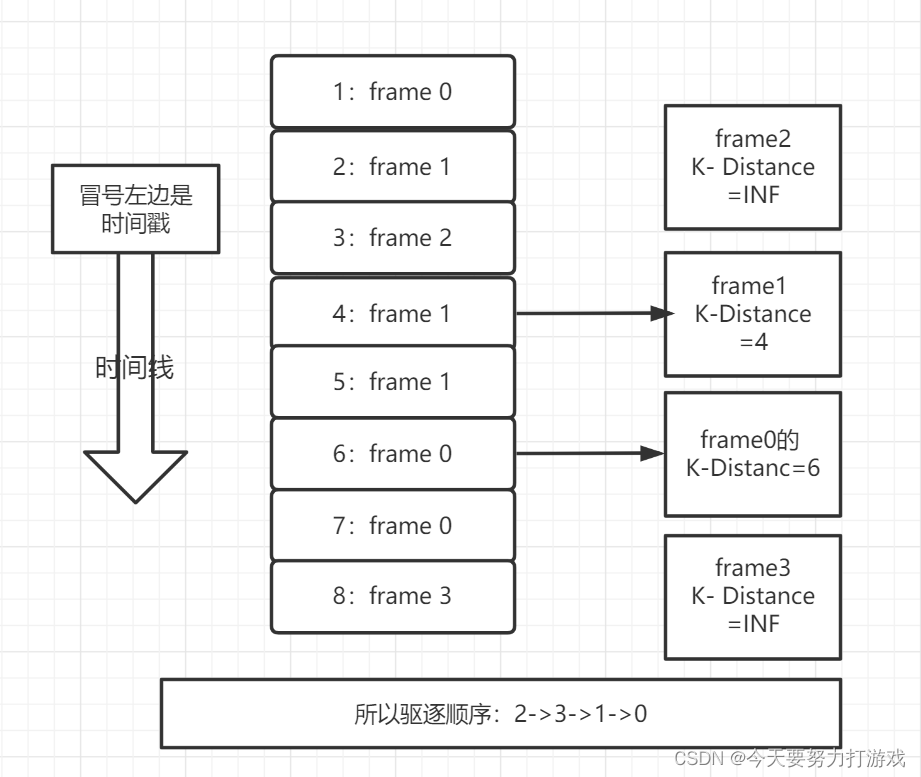
图片来自今天要努力打游戏的博客。
如果你被“之差”误导,你可能会以最后一次访问page的时间戳,与倒数第k次访问page的时间戳“之差”表示k-instance. 这其实是错误的,你没有理解当前时间戳这一概念。
我的具体实现也是用倒数第k次访问page的时间戳表示k-instance, 时间戳越小,表示访问page的时间越早,越有可能被淘汰。因此我用-inf初始化k-instance。注意,这和文档中的描述不同,文档说:k-instance越大,越可能被淘汰。而你应该根据你的具体实现,决定k-instance的大小和被淘汰之间的关系。
值得注意的是LRUKReplacer的size表示可驱逐page的数量,即LRUKNode的is_evictable_为true. 我们需要通过SetEvictable()设置page的is_evictable_,以下是SetEvictable的方法签名:
void LRUKReplacer::SetEvictable(frame_id_t frame_id, bool set_evictable)
当set_evictable为true时,需要将page设置为可驱逐。反之则设置成不可驱逐。而node_store_表示所有位于内存中的page, 包括了可驱逐/不可驱逐。调用Evict()时,我们需要从可驱逐的page中选择一个k-instance最小的page,将其驱逐。显而易见的是,我们需要用其他结构存储不可驱逐的page. 可以是std::priority_queue, 也可以是std::set. 又由于Remove()将驱逐指定page, 所以我们可以选择std::set.
以shared_ptr<LRUKNode>为key, 并实现其比较器:如果LRUKNode的k-instance不等,需要满足k-instance的<比较。否则(k-instance只有+inf才会相等),需要满足最早访问时间戳的<比较。这样的话,set的begin()将返回最应该被驱逐的LRUKNode.
你可能会感到疑惑:比较器只实现了<比较,那么find将如何查找相等的key? 比较器可没有实现==比较。实际上,实现了<比较后,我们就可以用以下代码实现==比较:
!Comp(current_element, target_element) && !Comp(target_element, current_element)
当然,你还需要实现时间戳,可以使用依赖硬件,使用系统时钟。但是系统时钟精确度不够,校准后可能产生问题,使得时间戳不是一个递增序列。你也可以使用64位整数表示时钟,每一次page的访问都将使该整数自增。
至于其他注意点,文档已经详细说明了。最后说说RecordAccess()的实现吧:
·检查frame_id是否合法(不超过replacer_size_)
·如果合法,在node_store_中find frame_if·如果page已经存在,维护其访问记录history_, 注意k-instace的维护。·如果page可驱逐,且需要更新k-instance,需要先从set中erase,再insert到set中。直接修改LRUKNode不会触发set的调整,所以你只能手动删除再插入·如果page不存在,make_shared, 向node_store_中插入新的访问记录,当然你需要对LRUKNode进行初始化
Task 2 - Disk Scheduler
disk scheduler使用共享队列(share queue)接收disk requests, 并以先进先出的方式处理这些请求。disk scheduler将启动一个后台线程,用于监听share queue,处理disk requests.
BusTub用DiskRequest描述磁盘请求:
- is_wirte_:读/写
- data_:从磁盘读取数据保存到data_/将data_中的数据写入到磁盘
- page_id_:读取/写入的页号
- callback_:
std::promise<bool>,表示请求是否被处理
用DiskScheduler描述disk scheduler:
- construct:用std::optional.emplace()原地创建后台线程,并使之执行StartWorkerThread函数
- destruct:向share queue中发送std::nullopt,告知调用StartWorkerThread的线程返回
- Schedule():向DiskManager发送DiskRequest
- StartWorkerThread():后台线程需要执行的逻辑。负责获取share queue中的请求并处理:调用Schedule()将DiskRequest发送给DiskManager。如果Schedule()成功,设置DiskRequest的callback_为true,使请求发送方得到“请求被处理”的信息。该函数总是在运行(
while(true)),直到DiskScheduler的生命周期结束
要写的代码不多,不到20行。理清DiskRequest, DiskScheduler, DiskManager之间的关系即可。不过在StartWorkerThread()中,你应该创建一个子线程,使之调用Schedule()处理DiskRequest, 并detach子线程。因为读写操作会占用大量时间。
Task 3 - Buffer Pool Manager
至此,基于前两个Task,我们终于凑齐了Buffer Pool的组件。其中,我们不需要实现磁盘的读取/写入方法,BusTub已经将这些方法封装为DiskManager, 我们只需要使用DiskScheduler调用DiskManager即可。当然,如果你对DiskManager感兴趣,想知道如何与磁盘打交道,那么去看看它的具体实现吧: )。
Page用来描述操作系统的内存资源,是BusTub中资源分配的基本单位。用来保存从磁盘读取,或是将要写入磁盘的数据。Page是一个4KB大小的内存块(BUSTUB_PAGE_SIZE = 4096),数据在磁盘和内存间流动时,我们将重用相同的Page存储不同的物理页(一般情况下,物理页的大小也是4KB)。
当然,你应该仔细阅读文档,了解其pin_count_, is_dirty_字段的具体含义。
回到BufferPoolManager中,其中有一些需要重点关注的成员:
- pool_size_:缓存池大小,表示page/frame的数量。因此frame_id的范围只能在
[0, pool_size_ - 1]之间 pages_[]:类型为Page的数组,在构造函数中用pool_size_个page填充。也就是说,page资源已经提前获取了。同时frame_id将作为pages_的下标,用来访问对应的page资源- free_list_:未被使用的frame_id. 如果大小为n, 说明当前DBMS还能缓存n个page
- page_table_:page_id与frame_id的映射,如果page被写回磁盘,其frame_id应当被设置为-1.
此外还有两个函数:AllocatePage()与DeallocatePage(),前者用于获取page_id, page_id是一个递增序列,和时间戳一样。后者则用于释放page_id, 不过BusTub没有维护被释放的page_id, 比如page_id被使用了0, 1, 2, 3, 4, 现在释放1, 3. 由于BusTub没有维护被释放的1, 3, 所以我们只需要象征性地调用该函数。
接着是需要实现的函数,文档对这部分的说明很简略,你应该阅读.h文件中的注释,我会给出更详细的逻辑。但是在开始前,强调一点:page可能位于磁盘,每个函数都需要考虑Page在磁盘中的情况。特别是Fetch一个在磁盘的Page.
NewPage
创建新的page, 返回其指针与page_id:
auto NewPage(page_id_t *page_id) -> Page *
·判断是否存在存在frame·若不存在,试着evict frame·若evict失败,返回nullptr·若成功evict, 且page is dirty, 你需要刷脏,以及重置Page的data(ResetMemory), 维护page_table_
·成功获取frame后,你需要初始化Page的相关字段
·如AllocatePage()获取page_id, RecordAccess()记录对page的访问,SetEvictable()设置不可驱逐,维护page_table_
获取空闲frame后,如果你不知道如何获取Page *:通过pages_ + 空闲的frame_id即可
以上,你还需要注意:刷脏后,应该维护page_table_使该page指向-1, 表示page位于磁盘。此外,还有一个无关紧要的地方:(1)刷脏时,需要通过DiskRequest的promise获取其future, 判断是否刷脏成功(一般都会成功)
FetchPage
根据page_id获取指定的页:
auto FetchPage(page_id_t page_id) -> Page *;
·find page_table_
·若存在,分为两种情况(1)page在内存中 (2)page在磁盘中(1)若page在内存中,SetEvictable(因为该page被使用了,设置不可驱逐), pin_count_++(2)若page在磁盘中,需要将其加载到内存·检查是否存在空闲frame·若不存在,试着evict frame·若evict失败,返回nullptr·若成功evict, 且page is dirty, 你需要刷脏,以及重置Page的·成功获取frame后,你需要初始化Page的相关字段,当然你需要SetEvictable与pin_count_++·构造read DiskRequest读取page数据到Page中,将其返回
UnpinPage
释放page的pin_count_
auto UnpinPage(page_id_t page_id, bool is_dirty) -> bool;
·如果page_id不存在,或pin_count_已经为0,返回false
·通过page_id与page_table_获取frame_id,进一步可以获取Page *
·pin_count_--,如果pin_count_为0,SetEvictable(设置page为可驱逐)
·设置Page的is_dirty_
当然,如果修改了page,则需要设置is_dirty参数为true.
DeletePage
删除内存中指定的page
·auto DeletePage(page_id_t page_id) -> bool;
·find page_table_: 没有必要删除不存在或者在磁盘中的page
·如果Page不可驱逐(pin_count_ != 0),return false
·replacer_->Remove()在LRUKReplacer删除page使用的frame, page_table_.erase(), free_list_.push_back
·重置Page的data_, 与剩下字段
·最后象征性地调用DeallocatePage()
FlushPage
手动刷脏
auto FlushPage(page_id_t page_id) -> bool
·find page_table_, 若无法找到,返回false
·无论是否为脏页,都构造DiskRequest的写请求,写入数据
·数据写入完成将Page.is_dirty_设置为false
最后,关于并发控制,给每个函数加一把大锁就好了: )
std::lock_guard<std::mutex> lk(this->latch_);
写在最后
如果你对文章的某些描述感到疑惑,或是发现了文章的错误,欢迎在评论区提出: )