1.索引失效的情况
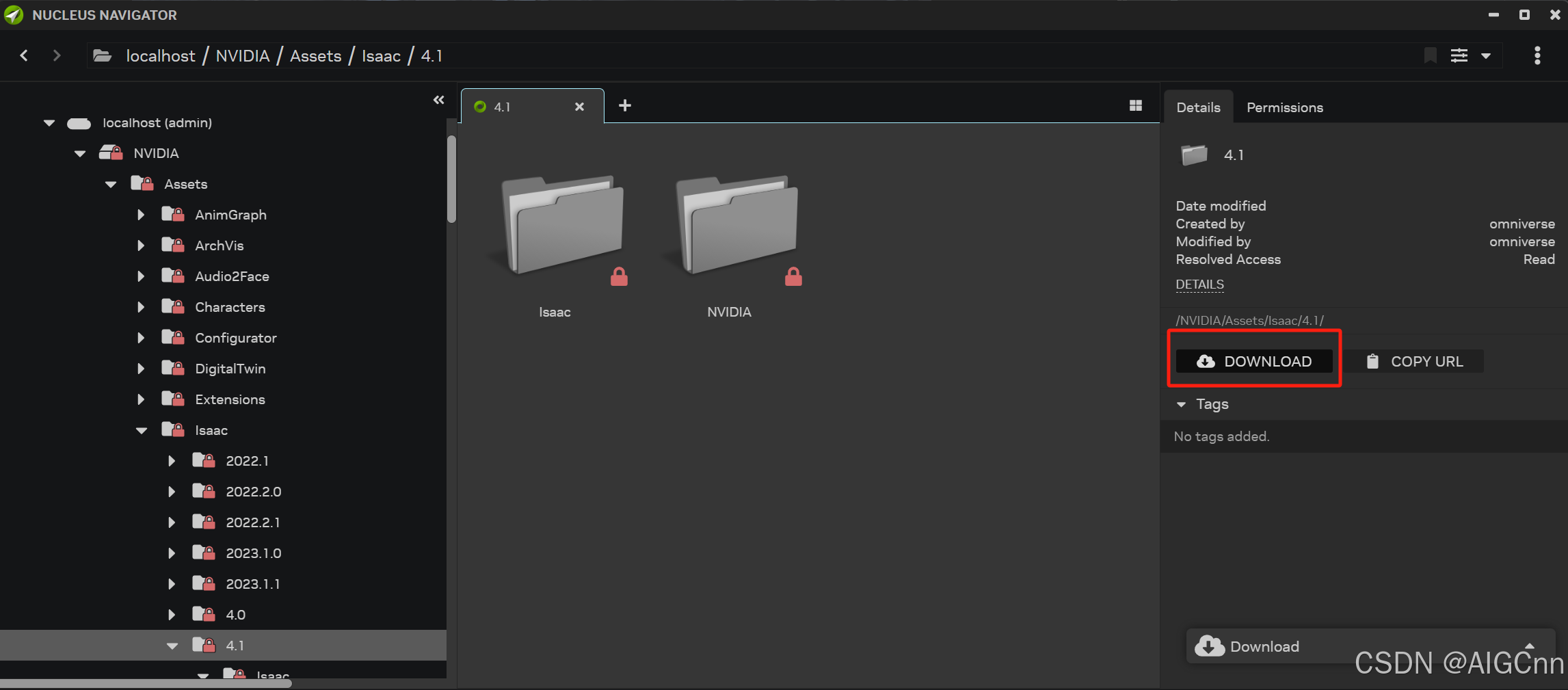
以tb_user表举例,id为主键索引、name和phone字段上建立了一个普通索引,name和phone均为varchar类型。
索引列运算
当在
WHERE子句或JOIN子句中对列使用函数或表达式时,索引会失效。
执行以下语句,可以发现执行计划中索引已经生效。
explain select * from tb_user where name = 'Jack';

如果我们使用substring函数只取前三个字符,则索引失效。
explain select * from tb_user where SUBSTRING(name, 1, 3) = 'Jac';
可以发现type为ALL,key为null,说明本次查询没有执行索引,走的是全表扫描。

隐式类型转换
当列的类型和查询中的值类型不同时,MySQL 可能会进行隐式类型转换,导致索引失效。
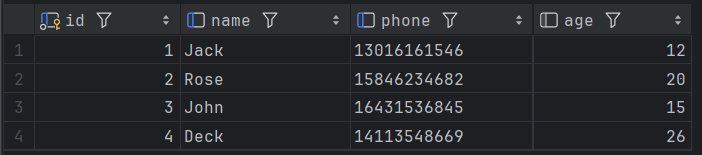
执行以下语句,phone为varchar类型,如果等号右侧不加引号,则发生隐式转换,索引失效。
explain select * from tb_user where phone = 13016161546;

前导通配符查询
使用通配符查询时,如果通配符在字符串的前面,索引会失效。
执行以下语句,查询name字段后缀为ack的数据,索引失效。
explain select * from tb_user where name like '%ack';
or连接条件
当 or 条件中某个列没有索引时,索引会失效
执行以下语句,因为name和phone都是索引字段,索引正常生效。
explain select * from tb_user where name = 'Jack' or phone = '15846234682';

执行以下语句,因为age字段没有设置索引,所以索引失效查询。
explain select * from tb_user where name = 'Jack' or age = '20';

最左匹配原则
对于联合索引(多个列组成的索引),如果查询条件不包含索引的最左前缀部分,索引会失效。
TIPS: 这里指的最左是联合索引中的顺序,而不是SQL语句查询条件的顺序。
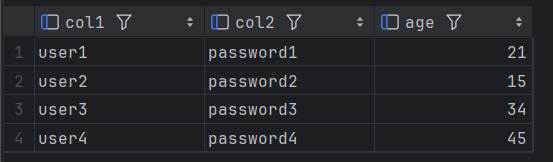
在本例中,我们新建一个表table,给字段col1、col2、age建立联合索引(col1, col2, age)
- 遵循最左匹配发展
按照最左前缀法则查询数据。
explain select * from `table` where col1 = 'user' and col2 = 'password' and age = 21;
可以发现,联合索引的总长度为107

- 不遵循最左匹配法则(查询条件中不包括联合索引的最左前缀部分)
如果不按照最左匹配法则,直接查询col2的数据
explain select * from `table` where col2 = 'password';
本次查询走的是index全索引扫描,性能上要低于ref。

- 不遵循最左匹配法则(查询条件中包含
> <范围查询)
如果查询条件中使用了> <,则不遵循最左匹配法则(可以使用其他范围查询符号),范围查询右侧的索引失效。
执行以下语句,由于age在联合索引(col1, col2, age)中是最后一个,所以不存在其右侧索引失效的情况。
explain select * from `table` where col1 = 'user' and col2 = 'password' and age > 21;

但是如果我们将col2和age调换顺序,改为(col1, age, col2),则col2索引失效。


数据分布情况
MySQL会根据表中数据的分布情况,决定是否使用索引
举一个简单的例子,如果表中的age字段最小值为10,查询条件为age >= 10。则在查询时可能不会走索引,因为走索引和不走索引都需要查询表中的全部数据,不过判断一个语句是否走索引还是要根据explain关键字返回的结果进行判断。
2.回表查询
回表查询是指在使用辅助索引(二级索引)进行查询时,由于辅助索引中不包含查询所需的所有列数据,数据库必须通过索引找到对应的数据行位置,再去实际的数据表(即“回表”)中读取完整的数据行。这种操作会增加额外的 I/O 开销,因此回表查询通常比直接从索引中获取数据的查询更慢。
回表查询示例
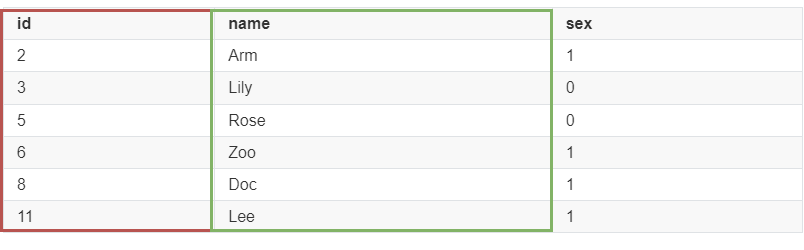
假设有以下表数据,id为主键索引,name为普通索引。
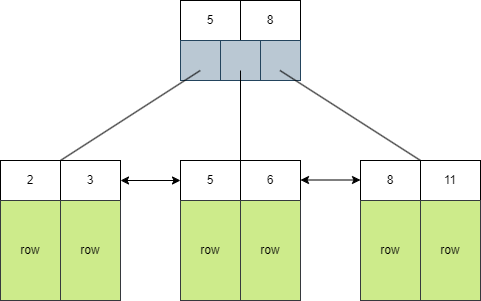
主键索引(id)的索引结构如下图,在叶子节点中存储的是每一行的数据。如果我们直接根据id查询,就可以在遍历索引时直接拿到每一行的数据。
select * from tb_user where id = 2;
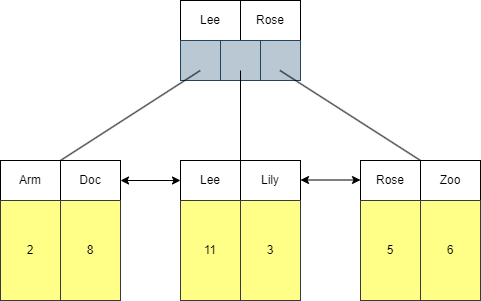
辅助索引(name)的索引结构如下,叶子节点存储的是该行的主键(id),如果需要查询该行的数据,则需要遍历索引后获得主键id,再根据这个主键id前往主键索引中查询,这个过程就是回表查询。
select * from tb_user where name = 'Arm';
避免回表查询
避免回表查询很简单,只需要保证查询的列能够被索引结构覆盖即可。通过创建一个包含所有查询所需列的索引,数据库可以直接从索引中获取所有需要的数据,无需回表。
覆盖索引(Covering Index)是指查询所需的所有列都包含在同一个索引中,从而避免回表操作。这样可以显著提高查询性能。
比如我们直接使用以下语句,就可以避免回表查询,因为name索引中包含了name和id的数据,而无需回到数据库进行查询。
select name from tb_user where name = 'Arm';select id, name from tb_user where name = 'Arm';
3.索引下推
索引下推(Index Condition Pushdown,ICP) 是 MySQL 5.6 及以上版本中引入的一种优化技术,用于提高使用索引查询的效率。ICP 可以减少回表操作(即从索引表跳回数据表读取完整行数据)的次数,从而提高查询性能。
除了可以减少回表次数之外,索引下推还可以减少存储引擎层和 Server 层的数据传输量。
工作原理
在没有索引下推的情况下,MySQL 的查询执行流程通常是:
- 索引扫描:存储引擎使用索引查找满足索引条件的记录。
- 返回记录:将这些记录返回给 MySQL 服务器。
- 行过滤:MySQL 服务器根据剩余的查询条件进一步过滤这些记录。
使用索引下推后,MySQL 优化器会在索引扫描阶段尽可能多地应用查询条件,只有在通过索引扫描无法完全过滤的情况下,才进行回表操作。
适用场景
索引下推在以下场景中尤其有效:
- 范围查询:对索引列进行范围查询时,例如
BETWEEN、<、>等。 - 联合索引查询:在联合索引的前缀列上进行查询,并且查询条件涉及非索引列时。
- 复杂条件查询:查询条件包含多个过滤条件时,例如
AND、OR等。
示例
假设有一个包含联合索引 idx_name_age 的表 tb_user:
CREATE TABLE tb_user (id INT PRIMARY KEY,name VARCHAR(50),age INT,address VARCHAR(255),INDEX idx_name_age (name, age)
);
查询语句:
explain select * from tb_user where name = 'John' and age > 30 and address like '%Street%';
在没有索引下推的情况下,MySQL 会:
- 使用索引
idx_name_age找到name = 'John'的所有记录。 - 回表读取每一条记录的实际数据。
- 对回表后的数据应用剩余条件
age > 30和address LIKE '%Street%'进行过滤。
在启用索引下推的情况下,MySQL 会:
- 使用索引
idx_name_age找到name = 'John'且age > 30的记录(在索引扫描阶段应用部分条件)。 - 仅对符合前两个条件的记录进行回表操作。
- 对回表后的数据应用剩余条件
address LIKE '%Street%'进行最终过滤。